
Abstract
The paper presents a fundamental parametric approach to simultaneous forecasting of a vector of functionally dependent random variables. The motivation behind the proposed method is the following: each random variable at interest is forecasted by its own model and then adjusted in accordance with the functional link. The method incorporates the assumption that models’ errors are independent or weekly dependent. Proposed adjustment is explicit and extremely easy-to-use. Not only does it allow adjusting point forecasts, but also it is possible to adjust the expected variance of errors, that is useful for computation of confidence intervals. Conducted thorough simulation and empirical testing confirms, that proposed method allows to achieve a steady decrease in the mean-squared forecast error for each of predicted variables.
Keywords
Introduction
Very often when modeling some economic entity we encounter a problem of simultaneous time series prediction. In the majority of cases these time series are somehow interconnected as they describe a single object, e.g. a firm, a region, an industry, a country etc. However, many researchers still predict each of the considered economic indicators according to the model specially constructed for it, i.e. separately from the others. Thus, the predicted indicators often appear to be incoherent with each other as above-mentioned interconnections are omitted. If modeled time series are functionally dependent, one can try to tackle this problem with well-known simultaneous equation model (SEM) when all endogenous variables in the structural form are modeled via exogenous ones (reduced form). For example, when predicting indices of the Gross Domestic Product (GDP), the GDP deflator and GDP in constant prices one may use a trivial functional relation, more specifically the GDP index is equal to the product of the GDP deflator index and the real GDP index. This approach preserves the functional link but significantly lacks flexibility and suffers from excessive number of parameters, that dramatically decreases the accuracy of constructed models, see for example Turlach et al. (2005), Yuan and Lin (2006), Yuan et al. (2007) and Gura et al. (2020). Another popular approach to modeling interconnected random variables is seemingly unrelated regressions (SUR), originally proposed by Zellner (1962) and later elaborated by Breiman and Friedman (1997). This method considers regression with multiple responses, i.e. modeling a vector of the target variables. Such models consist of a system of regression equations with the assumption of some degree of correlation between the error terms. A number of papers have been devoted to nonparametric models with two target variables (biresponse models) estimated using smoothing splines, see for example Welsh et al. (2002), Lestari et al. (2010) and Chen and Wang (2011), as well as using the polynomial approximation, see Chamidah et al. (2012). The purpose of such models with multiple responses is to obtain more accurate predictions, since we add information about the interdependence between the errors of predicted variables. This interdependence is usually represented in the form of the variance-covariance matrix of errors, whose inverse is used to weigh observed residuals in calculating the estimates of true model parameters by analogy with the generalized least-squares method. The maximum effect in this case is achieved if there is a sufficiently strong correlation between the errors of modeled processes, which is clearly shown in the works of Ruchstuhl et al. (2000), Guo (2002) and Guo et al. (2011). The downside of SUR is that there is no clear way to compute the variance-covariance matrix of error terms and the majority of papers, devoted to multiple responses topic, are focused on that, see for example Rothman et al. (2008), Rothman et al. (2010), Lee and Liu (2012), Nyangarika et al. (2018) and Nyangarika et al. (2019). Besides that, these models do not fully bring considered random variables into accordance with stated functional link, but rather only decrease the variance of parameters’ estimates. Typically, regression models with multiple responses are widely used in the analysis of categorical or panel data in the field of medicine and sociology, see Wang et al. (2000), Welsh and Yee (2006), Antoniadis and Sapatinas (2007) and Chen and Wang (2011). However, in the field of economics, approaches that share similar idea can produce models of higher quality. This statement is reasoned by the ubiquitous presence of functional dependence among economic indicators of an object of interest. Therefore, in this paper we focus on the general framework of incorporating known functional dependence into the system of equations, which was proposed by Moiseev and Volodin (2019). We expresses an idea that it is possible to improve the accuracy of predictions of functionally dependent indicators by taking into account the dependencies between them. Since almost all functional links between economic indicators are linear (balance sheet, profit and loss account, cash flow statement, system of national accounts, etc.) or can be trivially linearized, we aim at deriving an explicit analytical form for these adjustments for the linear case. It is also worth noting, that this framework of adjustments, besides increasing the forecast accuracy and bringing modeled variables into accordance with their functional link, also does not impose any constraints on the type of constructed models, that tremendously expands its sphere of application.
The paper has the following structure. In Section 2 we propose a method of adjustments, accounting for linear dependencies between modeled indicators when they are simultaneously predicted by models of any nature. Section 3 is devoted to simulation and empirical investigation of proposed method in order to demonstrate its efficiency. Section 4 summarizes the obtained results, highlights the key characteristics of the proposed method and discusses directions for further research.
The method
Let
where
The only requirement for such model is that it returns an unbiased forecast and mean squared forecast error, which is subject to normal distribution. Further, suppose that there is a set of target variables
where
Hence we make the following assumption to ensure the reliability of further derivations.
Then according to Moiseev and Volodin (2019) it is possible to correct obtained predictions, taking into account their probability density functions
Thus, the procedure of adjusting the forecasts is reduced to finding such values of predicted random variables that would maximize expression Eq. (3). In order to reduce computational complexity of calculating the optimal parameters when maximizing the likelihood function Eq. (3), we resort to the maximization procedure for its log-likelihood function.
Therefore, by applying the correction by maximizing the log-likelihood function Eq. (4) we adjust obtained forecasts in order to bring them into coherence by initially stated functional link. In addition to proposed adjustments to traditional predictions, it is also possible to obtain the adjusted probability density function for all target variables under consideration. This procedure is proposed to be carried out by calculating the marginal distribution for the analyzed target variable, which takes into account probability distributions of the remaining target variables and the functional relationship between them. Thus, according to this method, corrected probability density function is calculated as shown below:
where the normalizing constant in the denominator is an integral of the likelihood function over all target variables under consideration, and
Hence, for the sake of simplicity we slightly change notation as follows:
In this paper we will focus on a particular case where modeled target variables represent a simple linear equation
that can be easily extended to any
Thus, we propose an easy-to-make adjustment for simultaneous prediction of linearly dependent random variables that does not impose any requirements on the model’s nature, for instance one target variable can be modeled by ARIMA model, another – by neural network and so on. The only important thing is that these models are supposed to return unbiased point forecast and its variance. Such adjustment helps increase the accuracy of constructed models by adding information about the functional link of predicted processes.
In order to test efficiency of the method proposed in this paper, we carry out simulation and empirical experiments. First, we check how well these adjustments work for generated data. Let us consider a simple case, when a set of target variables
Error terms
Simulation experiment designs
Simulation experiment results, MSRFE for design 1
Generated time series were then forecasted one-step-ahead by auto.arima function from R environment, which selects the form of SARIMA class model by minimizing Akaike information criterion (AIC). To provide a comprehensive simulation experiment, all designs were tested on windows of different lengths
Table 2 shows the mean square realized forecast error for models for design 1, numbered respectively. The last column labeled “
As it can be seen from Table 2, proposed method of correcting predicted target variables exceeds initial models in accuracy for almost any data frame under consideration (highlighted in bold). The only exception is the mean-squared realized error for
Table 3 displays the mean square realized forecast error for models for design 2, numbered respectively.
Simulation experiment results, MSRFE for design 2
Simulation experiment results, MSRFE for design 1.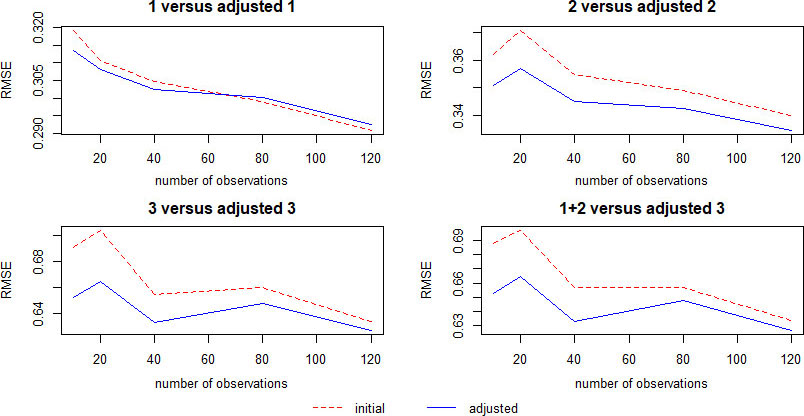
Analyzing results from Table 3 we observe almost the same pattern as from Table 2. Proposed method slightly underperforms for initial models with relatively low MSRFE (
Simulation experiment results, MSRFE for design 2.
It is also worth noticing, that for all target variables and both methods under consideration, the accuracy of the prediction increases with the extension of the window, the difference between adjusted forecasts and initial ones also shrinks. However, when analyzing time series of economic processes, one very often has to work under conditions of the scarcity of statistical data. It is well known that a too long data frame yields just as inaccurate forecasts as does a too short one. Therefore, when analyzing economic processes, application of proposed adjustments allows a significant reduction of the forecast error.
Next, let us proceed to the empirical testing of the method, which takes into account the linear dependence of the modeled target variables. Consider the simplest three-factor macroeconomic equation
which can be easily linearized as follows:
We took the quarterly statistics for the USA for these indicators, starting from Q1.1947 to Q2.2019. Thus, the set of statistical data for carrying out the empirical experiment constitutes 290 observations. Table 4 shows the mean-squared realized forecast error of models for each variable in Eq. (10), constructed by one-step-ahead rolling window procedure, using auto.arima function from R environment, and their adjustments according to proposed method.
Empirical experiment results, MSRFE for RGDP, Deflator and GDP
As it can be seen from Table 4 almost for all
Empirical experiment results, MSRFE for RGDP, Deflator and GDP.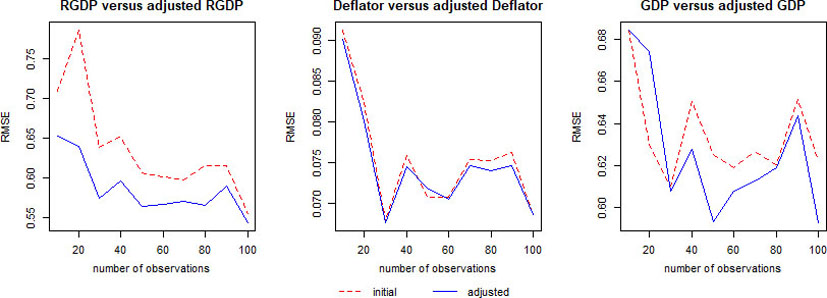
Thus, we can conclude, that proposed method results in a significant improvement of simultaneous forecasts of linearly dependent random variables, what is especially distinct under conditions of a short window. Though assumptions, imposed in Section 2, very rarely hold in practice, nevertheless the method performs well even if they are not fully met. The reason for such an improvement is that by incorporating known functional link we reduce the uncertainty concerning model specification and parameters estimates. Moreover, in distinct from SUR, proposed method does not impose any requirements on model’s nature. It is obvious, that positive effect from these adjustments is gradually canceled out with increasing number of observations. However, despite the fact that for a long data frame, the difference between the analyzed approaches is minimal, this method is still relevant, because when modeling economic processes the sufficiency of statistical data is extremely rare.
The paper presents a method of increasing the forecast accuracy when simultaneously predicting a set of linearly connected random variables. In the first step each target variable is predicted by its own model (without any requirements on model’s nature); afterwards obtained predictions are adjusted to satisfy their linear connection, using explicit and easy-to-use formula. Along with correcting predictions, we also explicitly correct the expected forecast variance, that allows one to easily compute the interval forecast. The simulation and empirical experiments show, on fairly trivial examples, practical benefits of proposed method. When making such corrections, obtained forecasts become coherent with each other, that positively affects their quality. In general, developed methods result in a significant improvement in the quality of forecasts in comparison with the regression equations that model each target variable separately. This positive effect is achieved due to the use of information about the form of the functional or dependence between the forecasted target variables. Since we can functionally bind the majority of economic indicators, proposed method can be considered relevant for complex simultaneous forecasting of economic processes.
Footnotes
Acknowledgments
This research was performed in the framework of the state task in the field of scientific activity of the Ministry of Science and Higher Education of the Russian Federation, project “Development of the methodology and a software platform for the construction of digital twins, intellectual analysis and forecast of complex economic systems”, grant no. FSSW-2020-0008.
Appendix
where
where
Besides that
Proof In order to prove it we integrate the equation Eq. (7) and get
By definition of gaussian distribution, from Eq. (14) it is clear, that the adjusted variance and mean are explicitly expressed like in Eqs (11)–(13). Given the derived analytical form for
Detailed proof can be provided upon request.