
Abstract
In this paper, we order to evaluate via Monte Carlo simulations the performance of sample properties of the estimates of the estimates for Sushila distribution, introduced by Shanker et al. (2013). We consider estimates obtained by six estimation methods, the known approaches of maximum likelihood, moments and Bayesian method, and other less traditional methods: L-moments, ordinary least-squares and weighted least-squares. As a comparison criterion, the biases and the roots of mean-squared errors were used through nine scenarios with samples ranging from 30 to 300 (every 30rd). In addition, we also considered a simulation and a real data application to illustrate the applicability of the proposed estimators as well as the computation time to get the estimates. In this case, the Bayesian method was also considered. The aim of the study was to find an estimation method to be considered as a better alternative or at least interchangeable with the traditional maximum likelihood method considering small or large sample sizes and with low computational cost.
Keywords
Introduction
The Sushila distribution was introduced by Shanker et al. (2013). This distribution includes the one-parameter Lindley distribution (Ghitany et al., 2008; Lindley, 1958) as a particular case and can also be written as a mixture of distributions in the same way of the Lindley distribution. Its probability density function (pdf) is given by,
where
The mode of Sushila distribution is restricted to
The corresponding cumulative distribution function (cdf) and survival function (sf) are given, respectively by,
and,
The hazard function, according to Shanker et al. (2013), is an increasing function as the hazard function of the Lindley distribution and it is given by,
For the estimation of the parameters of the Sushila distribution, Shanker et al. (2013) considered only maximum likelihood (ML) and moments (MO) estimation methods from where it could be seen that the moments estimator for
The main goal of this paper is to compare the six above cited different estimate methods via extensive simulation studies assuming complete data with small and large samples sizes. Another similar studies considring differents distributions can being see in, Kundu and Raqab (2005); Dey et al. (2014); Shawky and Bakoban (2012); Kim et al. (2010); Mazucheli et al. (2013); Teimouri et al. (2013) and others. This paper is organized as follows: In Section 2, it is discussed the six estimation methods considered in this paper. The comparison of these methods in terms of bias and root-mean-squared error as well applications involving simulated data are presented in Section 3. In Section 4, a real dataset is considered to compare the performance of the six estimation methods. Finally, in Section 5 it is presented some conclusions remarks and discussion of the obtained results.
Maximum likelihood
Let
where
where
The method of moments is also traditional approach used in parameter estimation of a distribution. In this method is is necessary in order to understand the first moments of the distribution. Considering the Sushila distribution, we have to the first two raw moments are given, respectively, by,
The methods of moments estimators
where
The method of L-moments, is defined in terms of linear functions of population order statistics and their sample counterparts. This method was introduced by Hosking (1990). Considering the Sushila distribution, the first two population L-moments are, respectively, given by,
where
The L-moments estimators
where
Considering
For the Sushila distribution, the least squares estimates
On other hand, the weighted least-squares estimates
where the cdf of the order statistics,
In order to determine the Bayesian estimators for the unknown parameters of the Sushila distribution based on the squared error loss function,
Such that, the gamma distribution with mean
where
Step 1: Choose initial values, Step 2: Generate Step 3: Repeat step 2, Step 4: Calculate the Monte Carlo Bayes estimate of
To simulate samples from the joint posterior distribution, we could consider the use of algorithms implemented in the JAGS software (Plummer, 2003), where we just need to specify the data distribution and the prior distribution for the parameters.
Generation algorithms
In this subsection, two different algorithms for generating random data from the Sushila distribution are presented as follows:
The first algorithm is based on generating random data from Sushila distribution using the exponential-gamma mixture form; The second algorithm is based on generating random data from the inverse cdf in Eq. (2) of the Sushila distribution.
This subsection reports the results of a simulation study carried out to assess the performance of the ML, Bayes, MO, LMO, OLS and WLS estimators for the Sushila distribution assuming complete data. The simulation study was performed in R (R Core Team, 2018) software using the packages maxLik (Henningsen & Toomet, 2011) for ML estimators, nleqslv (Hasselman, 2018) for MO and LMO estimators and optim function for OLS and WLS estimators. The Broyden-Fletcher-Goldfarb-Shanno (BFGS) and Newton optimization methods were considered as optim.method. For the Bayesian approach, the R2jags package (Su & Yajima, 2015) was considered to get the inferences of interest, and we assumed approximately non-informative gamma prior distributions with hyperparameter values equal to (0.001, 0.001). Also, the Algorithm 2 (inverse cdf) was considered to generate random samples from the Sushila distribution.
The simulation study was performed under nine scenarios considering the assumed parameter values as the combination of
where
Assuming the ML estimators of both parameters, it could be seen that the ML estimators are asymptotically non-biased since Assuming the Bayes estimators of both parameters, it could be seen that the Bayes estimators are asymptotically non-biased for the parameter Assuming the MO estimators of both parameters, it could be seen that the MO estimators are asymptotically non-biased since In the same way of MO estimators for both parameters, it could be seen that the LMO estimators are asymptotically non-biased since Assuming the OLS estimators, it could be seen that the OLS estimator for In the same way as for the OLS estimators, it could be seen that the WLS estimator for Based on these simulation results and using the Algorithm 2 to generate the simulated data, it could be concluded that the MO, LMO, Bayes and MLE estimators are the best estimators to get inferences of interest assuming the Sushila distribution due to their performance in the simulation studies and the fact that they are not biased when the sample size increases and the RMSE values tend to zero, mainly observed in MLE and Bayes estimators. The OLS and WLS should not be used to get estimators for the parameters of the Sushila since these estimators could be strongly biased. In conclusion, the Sushila distribution could be used as good alternative to other existing continuous univariate distributions to describe univariate lifetimes with good accuracy if the MO, LMO, Bayes and MLE estimators are considered; also, the results could be improved assuming the Algorithm 1 to generate the random data.
The biases and RMSEs for both parameters assuming the Sushila distribution for each considered scenario considering the ML estimators assuming complete data (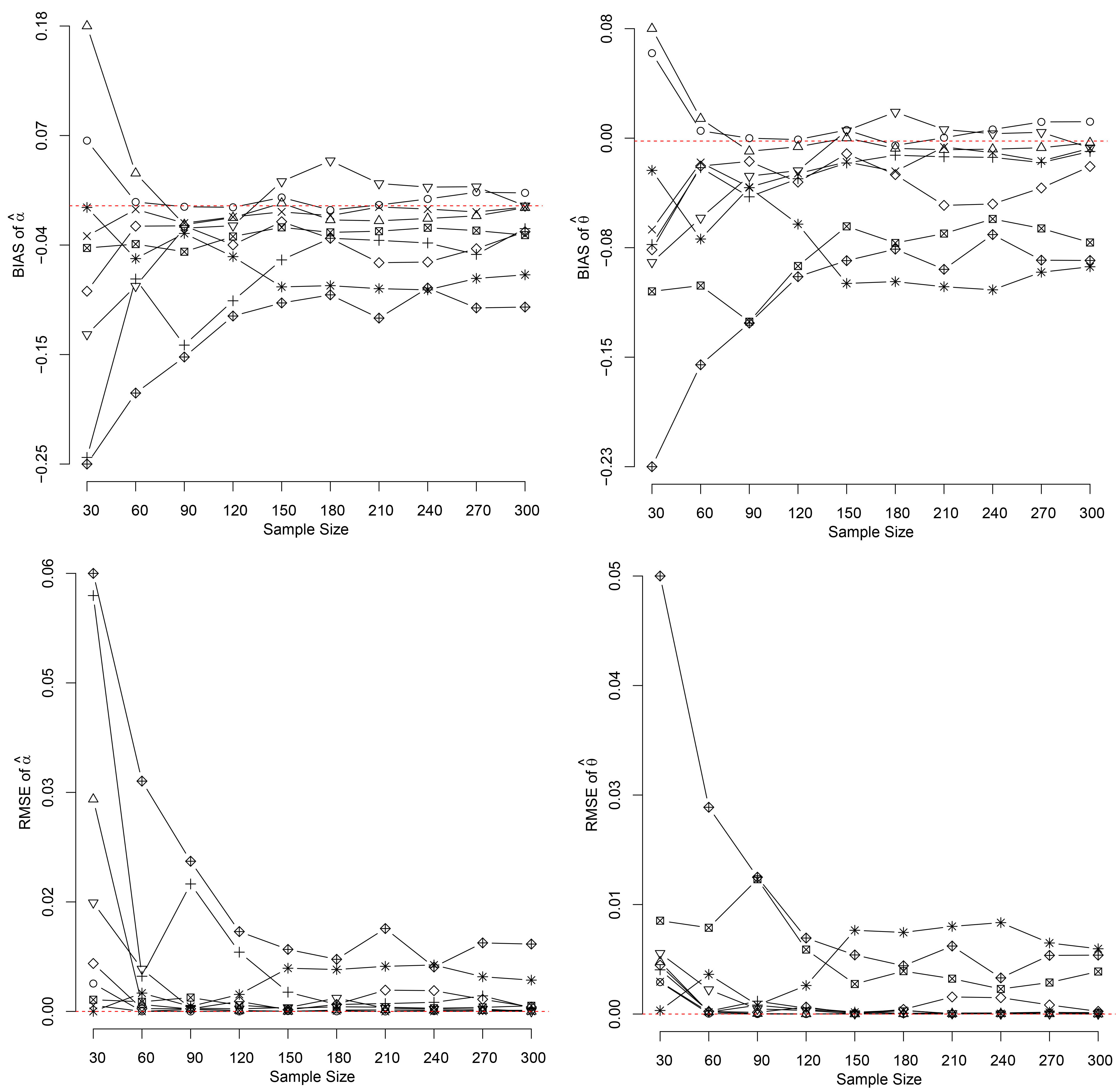
The biases and RMSEs for both parameters assuming the Sushila distribution for each considered scenario considering the Bayes estimators assuming complete data (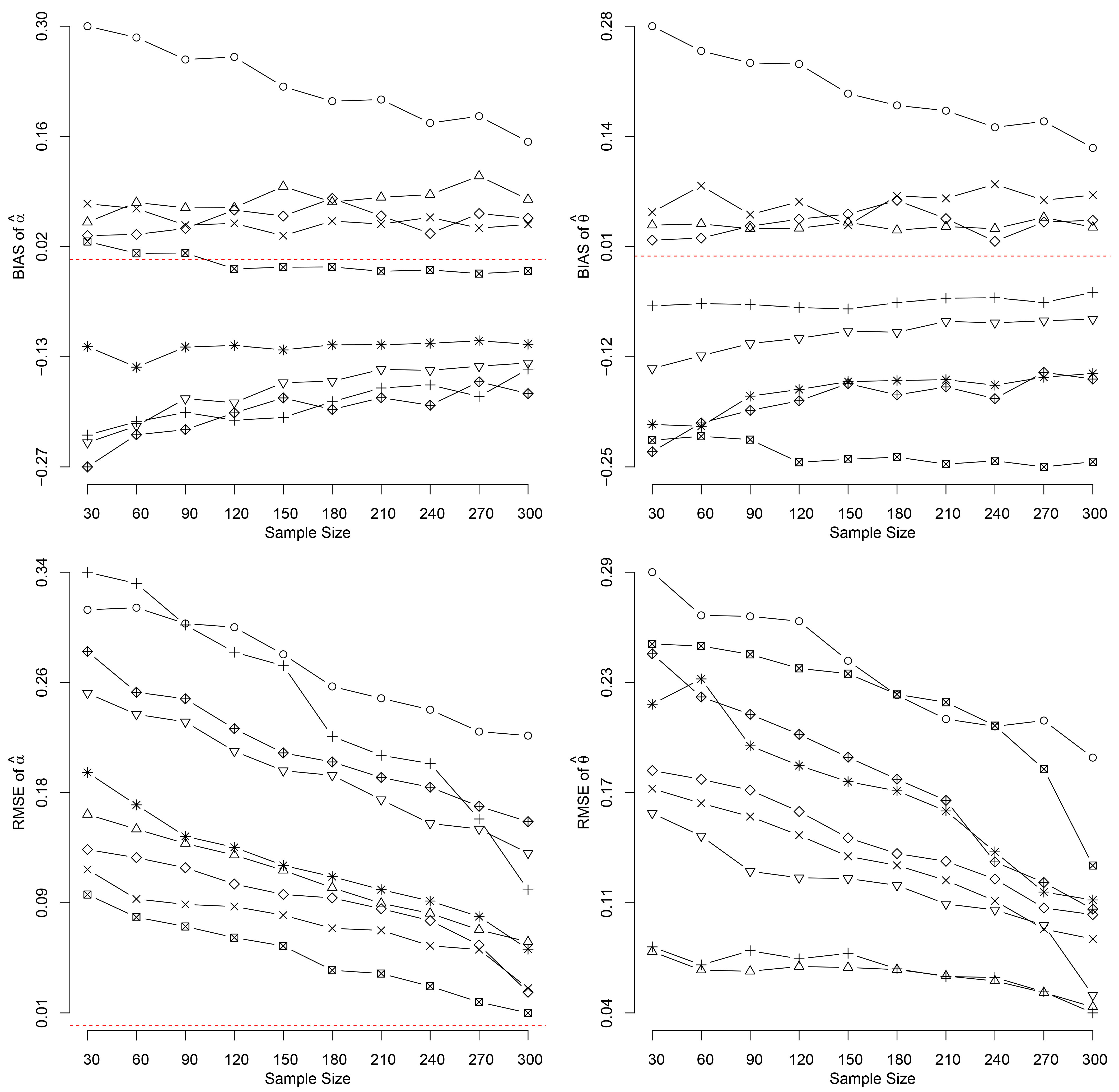
The obtained simulation results for each scenario of the best estimators assuming complete data are illustrated in Figs 1 and 2 for ML and Bayes, respectively.
Let us consider now
For the statistical analysis, it is considered all methods of estimation presented in Section 2, and for Bayesian approach, we assumed approximately non-informative uniform prior distributions with hyperparameter values equal to (0, 1) instead of gamma (0.001, 0.001) prior distributions. The results are presented in Table 2, and as comparative criteria, we considered the highest
Simulated lifetimes from a Sushila distribution with nominal parameters values
and
Simulated lifetimes from a Sushila distribution with nominal parameters values
Inference summaries for Sushila distribution with nominal parameters values
From the results of Table 2 and by comparison of the obtained estimates with the to the true parameter values adopted in this simulated dataset, it is possible to conclude that the ML and Bayes methods satisfies the adopted criteria, that is, highest
Now, to close our study of the proposed inference methods for Sushila distribution, let us consider a real dataset related to lifetimes of 20 electronic components introduced by Razali and Salih (2009) (dataset in Table 1) to evaluate the performance of the proposed estimators in a real data situation. For the statistical analysis, it is considered all methods of estimation presented in Section 2 and for the Bayesian approach we assumed approximately non-informative gamma prior distributions with hyperparameter values equal to gamma (0.001, 0.001). The results are presented in Table 2, and as comparative criteria, we considered the highest
Lifetimes of 20 electronic components
Lifetimes of 20 electronic components
Inference summaries for Sushila distribution assuming the lifetimes of 20 electronic components data
From the obtained results of Table 4, it is possible again, to conclude that the ML and Bayes methods satisfies the adopted criteria, that is, highest
The present study sought to compare by extensive simulation experiments, the efficiency of estimation of the parameters of the Sushila distribution considering six well-known estimation methods. The methods used in this paper were, the maximum likelihood, the method of moments, the method of L-moments, ordinary and weighted least-squares, and the Bayesian method. The simulation study concludes that the maximum likelihood and Bayesian methods are highly recommended for most practical sample sizes. The simulation study also showed that the ordinary least-squares and weighted least-squares inference methods are not recommended for the Sushila distribution since those estimators are biased. This is supported by the analysis of the real data analysis presented in Section 4 of this manuscript.