
Abstract
Volatility is a matter of concern for time series modeling. It provides valuable insights into the fluctuation and stability of concerning variables over time. Volatility patterns in historical data can provide valuable information for predicting future behaviour. Nonlinear time series models such as the autoregressive conditional heteroscedastic (ARCH) and the generalized version of the ARCH model, i.e. generalized ARCH (GARCH) models are popularly used for capturing the volatility of a time series. The realization of any time series may have significant statistical dependencies on its distant counterpart. This phenomenon is known as the long memory process. Long memory structure can also be present in volatility. Fractionally integrated volatility models such as the fractionally integrated GARCH (FIGARCH) model can be used to capture the long memory in volatility. In this paper, we derived the out-of-sample forecast formulae along with the forecast error variances for the AR (1) -FIGARCH (1,
Introduction
The autoregressive integrated moving average (ARIMA) model paved the way for the development of time series modeling (Box and Jenkins, 1970). The ARIMA methodology is structured based on the assumption of linearity and homoscedasticity of prediction error variances. In reality, many time series data sets did not adhere to these assumptions due to the presence of volatility. Engle (1982) proposed the autoregressive conditional heteroscedastic (ARCH) model to capture the time-varying volatility observed in financial returns. Bollerslev (1986) and Taylor (1986) independent of each other, proposed the generalized ARCH (GARCH) model. Later the fractional integration term has been incorporated into the GARCH model to capture the long memory and it is termed as the fractionally integrated GARCH (FIGARCH) model (Baillie et al., 1996).
Agricultural commodities exhibit volatility in their prices. The possible causes of price volatility may be the shocks due to the sudden disruption in the supply chain (Paul and Birthal, 2021; Paul and Yeasin, 2022; Ruan et al., 2021) or natural phenomena such as rainfall, flood, drought, pest and disease attack, etc. The volatility study of agricultural time series can be found in the literature (Gurung et al., 2017; Mitra and Paul, 2017; Anjoy and Paul, 2019; Paul and Garai, 2021; Paul and Karak, 2022; Rakshit et al., 2023). Again, the prices of agricultural commodities can have long term persistence in the mean model (Mitra and Paul, 2021; Paul et al., 2021; Paul et al., 2022), in the variance model (Paul et al., 2016; Rakshit and Paul, 2023) or both (Mitra et al. 2018).
In modeling, the in-sample forecasts are obtained and compared with the observations in the model validation set to measure the efficacy of the selected model. The out-of-sample forecasting of future observations can be done by using the naïve approach. In this approach, at first, a one-step-ahead forecast is done. This realization is considered as the original observation and included in the model building set. Again, the parameters are re-estimated to forecast for its next one-step-ahead forecast. In this step-by-step process, a multi-step ahead forecast is executed. No direct forecasting formula is available in the literature for multi-step ahead forecasts for fractionally integrated variance models like the FIGARCH model. In this research paper, we derived the formulae for out-of-sample forecast and forecast error variances for the AR(1)- FIGARCH (1,
Materials and methods
The ARCH/GARCH model
The ARCH model is designed to address the heteroscedasticity present in any time series, where volatility tends to cluster over certain periods. The key idea behind the ARCH model is that the conditional variance of a time series is related to its past squared residuals or shocks. The ARCH model assumes that shocks of the time series have a direct impact on the volatility, creating a feedback mechanism. If the past squared residuals have a significant impact on the current conditional variance, it suggests the presence of ARCH effects.
Let
where
The conditional variance
An extension of the ARCH model is the GARCH model, which incorporates both lagged squared residuals and lagged conditional variances in the model equation. The GARCH model is a more parsimonious model than the ARCH model. The GARCH (
The FIGARCH model allows for the estimation of the long memory parameter present in the conditional variance, which indicates the degree of persistence in volatility over time. A detailed review of the FIGARCH model can be found in Tayefi and Ramanathan (2012).
The conditional variance equation of GARCH (
This representation can also be expressed as an equivalent ARMA type representation as
where
This equation can be expressed as an ARMA (
where,
From this integrated GARCH process the FIGARCH models can be obtained by taking the fractional differencing operator
For any value of the differencing parameter
where,
and
In the context of modeling, a common practice is to divide the available dataset into two subsets: the model building set and the model validation set. The model building set is used to develop and estimate the parameters of the model.
Suppose,
Let the mean model AR (1) be fitted on the time series data as the linear model. Hence,
where,
(the proof is given in Appendix 1).
(the proof is given in Appendix 2).
The daily time series data for the modal spot prices (Rs./q) of onions for the markets in Delhi, Lasalgaon, and Bengaluru from 1st January 2008 to 30th June 2022 are obtained from the Ministry of Agriculture & Farmers’ Welfare, Government of India. S&P 500 index data (close) for the same period are also obtained from the website of Yahoo Finance. For the daily price series, the total number of observations is 5295 and for the S&P 500 index, it is 3650. All the analysis is done based on the log return series of the daily data series since the square of return is regarded as the realization of volatility. Another advantage of using the return series is that it dismisses the presence of seasonal effects. The log return series
The reason behind taking the daily series is that the daily series over a long period has a large number of realizations which has a greater possibility to show long term persistence in volatility. The log return series of the selected time series are divided into two parts, the last 250 realizations are considered the model validation set and the remaining previous portion as the model building set.
Descriptive statistics of selected onion price series and S&P 500 index (close)
Time plot of the selected time series, onion price series of (a) Delhi, (b) Lasalgaon, (c) Bengaluru markets, and (d) S&P 500 index (close).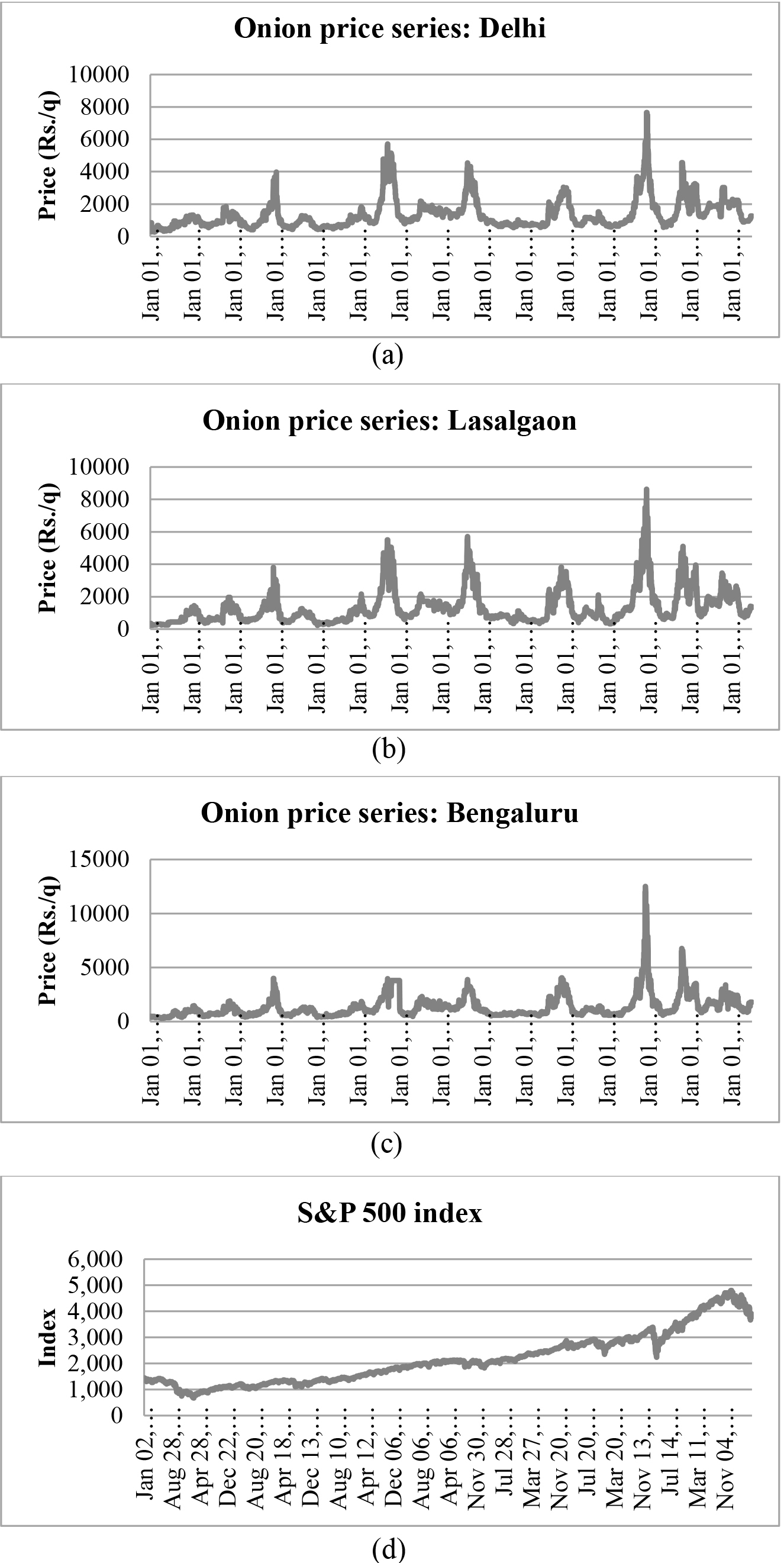
The descriptive statistics of the selected time series are given in Table 1. A relatively high level of C. V. percentage can be seen for all the price series. The S&P 500 index has a relatively lower C. V. percentage than them. The selected price series are more positively skewed than the S&P 500 index. All the price series are leptokurtic and the Bengaluru market price series exhibits a high degree of leptokurtosis. But, the S&P 500 index is platykurtic. The time plot of the selected series is given in Fig. 1. From Fig. 1, it can be seen that all three onion price series follow a similar pattern. The price rise and fall occurred at the very same time for all three markets. The S&P 500 index has two major downfalls during the study period, one during the 2008 financial crisis and another one during the 2020 COVID-19 pandemic.
Test for stationarity of the selected series
Stationarity is a fundamental assumption in time series analysis and modeling. Stationarity is often a requirement for estimating time series models accurately. Non-stationary data can lead to biased parameter estimates, unreliable model diagnostics, and incorrect inferences. The stationarity of the log return series and the squared log return series of the selected series are tested (Table 2) using the Augmented Dickey-Fuller (ADF) test (Dickey and Fuller, 1979) and Phillips-Perron (PP) test (Phillips and Perron, 1988). The null hypothesis for both tests is that the unit root is present in the time series. It is seen that both tests are significant for all the selected series and the null hypothesis has been rejected. As the selected log return series are stationary, the AR model can be fitted directly without any differentiation.
The ACF plots for the squared log return series of (a) Delhi, (b) Lasalgaon, (c) Bengaluru markets, and (d) S&P 500 index (close).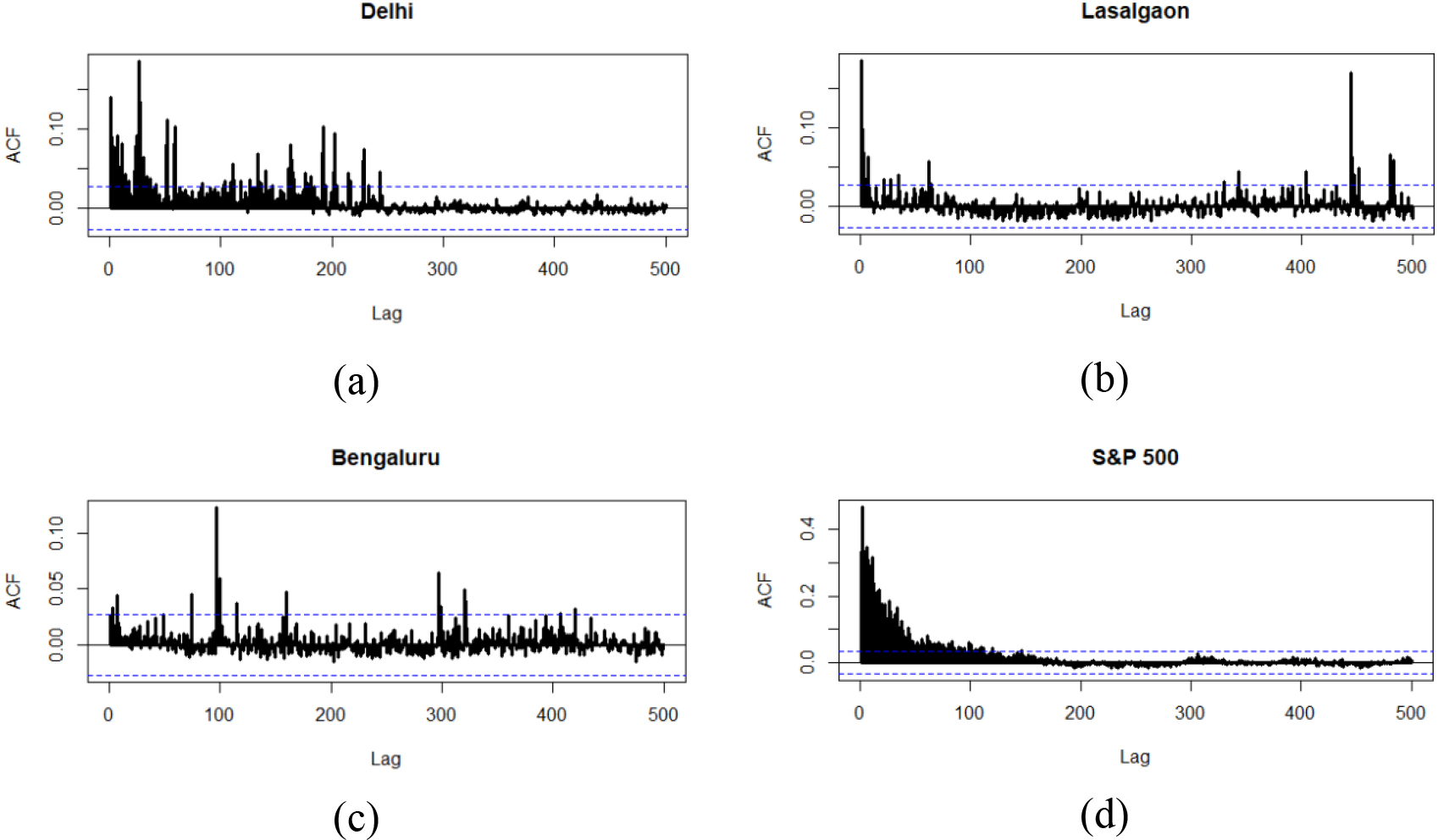
Long term persistence of a time series is a phenomenon which arises when there is significant statistical dependence among the realizations of the process occurring at distant lags. Long memory can exist both in linear and nonlinear dynamics of the time series data. The autocorrelation function (ACF) and partial autocorrelation function (PACF) plots are commonly used as a visualizing tool for indicating the statistical dependencies and relationships among the successive realizations of a time series. If long term persistence among the realizations is present then, the autocorrelation function (ACF) decays slowly (hyperbolic decay). Otherwise, ACF decays at a much faster rate (exponential decay). For the instance of long memory in volatility, the ACF of the squared return series has hyperbolic decay. From the ACF and PACF plots of the log return series of the selected series, it is revealed that significant statistical dependencies are present among the successive observations. Again, these ACF and PACF plots exhibited exponential decay. The ACF plots of the corresponding squared series for up to 500 lag are given in Fig. 2((a)–(d)). The dotted line indicates the confidence interval at a 95% significance level. From the ACF plots of the squared log return series, it can be seen that significant autocorrelation is present among the distant realizations. This indicates the presence of the long memory phenomenon in the variance model. This is very much prominent for the ACF plots of the squared log return series of Delhi’s onion price series and the S&P 500 index.
The GPH test: Test for long memory
Parameter estimates of the fitted AR(1)- FIGARCH (1,
***p < 0.01, **p < 0.05, * p < 0.10; S.E. is in parenthesis.
After visualizing the presence of long memory in volatility, it is tested by the GPH test (Geweke & Porter-Hudak, 1983). From Table 3 it can be seen that for the selected log return series the estimates of the fractional differencing parameters are not significant. However, for the squared log return series, the estimates of the fractional differencing parameters are significant. It suggests that all the squared log return series contain a long memory structure. Hence, the presence of long term persistence in the volatility is confirmed. This result supports the inferences drawn from the ACF and PACF plots.
In-sample forecasting performance in the model validation set for the selected return series
As the log return series of the selected time series are stationary, the AR(1) model is fitted as the mean model to each of them in the model building set. After fitting the AR(1) model, the residuals are calculated and the ARCH-LM test is used to evaluate the presence of conditional heteroscedasticity. The null hypothesis for the ARCH-LM test is the absence of the ARCH effect in the residual series. For each of the empirical cases, the test is significant. Once the presence of conditional heteroscedasticity is confirmed, the FIGARCH (1,
where
Out-of-sample forecast of the return series along with forecast error variance
The out-of-sample forecast for the next three horizons from the derived formula of the AR (1) -FIGARCH (1,
In this paper, we derived the out-of-sample forecast formulae and the forecast error variance for the AR (1) -FIGARCH (1,
Footnotes
Acknowledgments
The authors are thankful to the Director, ICAR-IASRI; the Joint Director (Education) & Dean, The Graduate School, ICAR-IARI and the Director, ICAR-IARI for providing the required research facilities.
Appendix 1
The
Similarly, the
Similarly, the
Going forward this way, the ith-step ahead out-of-sample forecast can be obtained by recursive use of conditional expectation as
Appendix 2
To estimate the forecast error variance, let
The conditional variance
Hence, the conditional variance
(taking up to the first order of approximation for the binomial expansion
For the fitted model AR (1)-FIGARCH (1,
Again, the two-step ahead out-of-sample forecast error variance is
Now,
Now, as per the assumption
Hence,
For
Here,
After taking the expectations, expanding the conditional variance term and replacing the square residuals
and similarly,
Hence, it can be generalized as