
Abstract
Churn handling has become an active area of research due to increased complexity, high dynamicity of participating nodes and its effect on the performance of overlay network. In this paper, we systematically analyse churn, its causes and implications along with churn handling strategies employed in various state of the art structured overlay network. These churn handling strategies are classified into two main categories based on addressing effects of churn: Churn Resilience and Dynamic repair strategies. These techniques are further classified into sub categories based on their inherent mechanism for addressing a particular concern. In addition, this paper pinpoints various concerns related to the future research for handling participant’s churn.
Introduction
The structured overlay networks are realized as an effective approach for management and utilization of a large number of available high configuration, interconnected computing devices, which otherwise remain idle. These high configuration devices voluntarily pool their resources for sharing them to a group of machines using structured overlay networks. The idea of structure here refers to the maintenance of tightly controlled topology as the network evolves and deterministic placement of resources on the overlay nodes. These structured overlay networks serve as a platform for many popular applications including file sharing (bit torrent), media streaming and internet telephony. The recent study has revealed that the overlay networks are the biggest consumers of the internet bandwidth and has a great future [1].
The operating environment of structured overlay networks becomes more inhospitable with the participation of multitude of heterogeneous, dynamic and mobile participants. This heterogeneity and dynamicity of overlay participants raises serious questions about the reliability of structured overlay networks under churn. The churn is a condition, where a large number of participants simultaneously join or leave the network such that stabilization of a network results in a significant down time. The churn becomes more severe due to presence of malicious users on the structured overlay network, who can plan random or strategic attack against legitimate users by exploiting the structural properties of overlay network. Thus, churn handling in structured overlay networks is the most critical issue to provide high and predictable level of service. This motivates the research community to focus their research interests towards churn handling strategies to guarantee the performance of structured overlay networks in highly dynamic environments [3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14].
In this paper, we overview a number of research works on the maintenance of structured overlays, while categorizing them according to their approaches. These diverse research efforts of research community can be divided two main classes based on their underlying mechanism of handling churn: churn resilience and Dynamic Repair. The churn resilience strategy is based on the idea of maintaining the acceptable performance of overlay network even under multiple node failures. The second class of topology maintenance strategy is dynamic repair that concentrates on reducing the impact of churn on overlay topology by dynamically updating the routing table in the face of churn. These categories are further divided into subcategories according to their working behaviour.
Most of the previous review papers [15, 16, 17, 18, 19, 20, 21, 22, 23] focused on the survey of different overlay network schemes or their applications, security or vulnerabilities of overlay networks. However, this review paper concentrates on effectiveness of existing churn handling strategies of structured overlay networks to ensure its performance in dynamic environments. These churn handling strategies are the backbone mechanism of structured overlay network to maintain its structure in the face of participant dynamics. Below are some of the key advantages of our systematic reviews over other available surveys in this field:
This review answers the most basic question of overlay network community “Is there any protocol that provides resilient overlay network, which regain system performance in the face of churn without compromising the openness of the system”. A comprehensive detailing of churn issues in structured overlay network to simplify the understanding the pool of related work. A taxonomy analysis of different topology maintenance schemes.
This article is organized as follows. In the Section 2, we will discuss the basic concepts such as structured overlay networks, different churn definitions, factors affecting the churn and evolution of normal churn to intentional churn attack to target the availability of services on the structured overlay networks. This section also discusses the various design challenges and characteristics of an effective churn handling strategy. Section 3 provides the taxonomy of different churn handling mechanism. Sections 4 and 5 discuss the individual approaches of the proposed taxonomy in detail. Section 6 concludes this paper along with the discussion of the main research issues that need to be handled in future.
Basic concepts
The correctness and the performance of structured overlay networks mainly depend on its up to date routing table entries that together form an overlay topology with specific structural constraints (e.g. ring structure in the chord overlay network). But, due to their open nature in the real world, where nodes may join or leave the overlay network at any time. This continuous dynamism of peer participants in the form of continuous joining, leaving, and failure from the overlay network is known as churn. Churn has significant impact on the performance of structured overlay networks as it may generate a considerable traffic to accommodate the rebalancing of data among overlay participants and to update the routing table entries accordingly. Thus, significant churn may result in blocking of the normal search operation and result in lookup failures or inconsistent lookups. The most common causes of node’s unavailability are network failures, mobility, overload, crashes, or a nightly-shutoff schedule. Before discussing the existing overlay maintenance strategies, we provide a brief introduction to the basic concepts of structured overlay network in relation to the topology maintenance. It includes churn definition; churn attack, churn patterns of overlay participants in the real world applications and the need of the churn handling mechanism to aid the better understanding of the different churn handling procedures.
Churn
Lifetime of a node.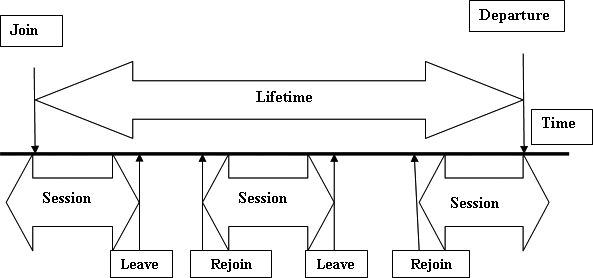
The churn can be defined as the participation dynamics of autonomic overlay network participants. Each participating node may join or leave the overlay at any time. This continuous join and leave operations in a structured overlay network result in content unavailability and outdated routing tables. Because of this dynamics, the routing topology and content availability need to be maintained in order to guarantee overlay network performance. Autonomic computing principles are an attractive solution to tackle the problem of self organization of dynamic network, mainly due to node heterogeneity and high churn. There are mainly two definitions of churn available in the literature:
Definition (Global Churn): Churn can be defined as a measure of the total number of nodes joining or leaving the overlay network over a given time, also known as node turnover.
Definition (Local Churn): Churn is defined as several online (participating in overlay) and offline sessions in a node’s lifetime (starts with initial creation and ends with permanent departure) as shown in Fig. 1.
Churn is a constant problem often offsetting the advantages of structured overlay networks. The literature on the structured overlay networks addresses churn as a legitimate failure scenario to be handled by the inbuilt fault tolerance or self management capabilities of structured overlay networks. Researchers have conducted different studies [24, 25, 26, 27, 28, 29, 30] to understand the churn behaviour of participating nodes. These studies have reported the daily or weekly periodic uptime pattern in different file sharing applications [24, 25, 27, 28], instant messaging [30] and distributed computing applications [29]. Douceur studies the churn behaviour of Microsoft machines and observed that, some of the participating hosts have always on characteristic, while others have cyclic on/off patterns. This cyclic behaviour pattern of overlay nodes is exploited to propose a predictive stabilization strategy to schedule the stabilization operation appropriately.
Churn can be exploited as a tool to attack, the availability of overlay network by generating peers, joining and leaving the network quickly in order to corrupt the functionality of the overlay network. Churn attack is a peer to peer version of Denial of services (DoS) attacks in which malicious peers frequently join and leave the overlay network to induce a large amount of communication and processing overhead to make it incapable to serve legitimate overlay participants. These efforts of malicious attackers can be categorized into two main categories based on attacker’s capability: Random churn attack and Strategic churn attack.
In random intentional churn attack, an attacker can exploit the churn effect by triggering the fast join/ leave of a number of slave nodes to destabilize the routing infrastructure. This attack is a type of DDoS (Distributed Denial of services) attack on overlay networks and its impact can be amplified by Sybil nodes.
In strategic churn attack, an intelligent adversary can plan a strategic attack against a structured overlay network by continuously attacking its weakest part or pinpointing the attack to specified targets only. Such an attacker learns the topology of the overlay by inserting a crawler and then plans its attack accordingly to partition the overlay network.
Churn attacks are an artificially induced churn with potentially high rates to cause bandwidth consumption due to overlay maintenance. This leads to the worst case to denial of service or service degradation. Cooperative web caching [31] is an attractive application of structured overlay networks to eliminate the use of proxy servers by storing meta-information in the overlay nodes. However, this application is vulnerable to churn attack as an attacker can easily mount a distributed denial of service attack by crippling the sharing mechanism. For this, attackers can pose extreme stress in the form of maintenance overhead generated by a large number of concurrent nodes join/leave procedures, which otherwise considered non-malicious.
Churn patterns
The recent years have witnessed a lot of research from the overlay networks community to make them more robust in the churn periods. But, most of the researchers have presumed that the overlay nodes will join and leave the overlay networks unpredictably and their churn behaviour has no specific patterns. Thus; most of the research efforts focus on the development of the different ways to recover, maintain connectivity or to ensure availability of services in the face of churn.
However, several studies [25, 32, 33] have shown that the churn behaviour usually obeys a particular pattern and the state of the overlay node can be predicted from their online time history [29]. These works clearly show the recurrence in the online and offline behaviour of overlay nodes. The dynamic behaviour of overlay nodes depends on many factors such as underlying user’s online behaviour, geographical position, time of the day, day of the week etc. as reported in many overlay applications. Based on this observation, overlay nodes will have daily and weekly behaviour patterns based on the working habits of their underlying users. Different users will have different behaviour patterns.
The different overlay network applications will have different online patterns of overlay nodes, depending on their use. The news and communication applications may have their nodes online during the working hours of the region they belong, whereas media streaming applications and social network users may be online during non-working hours, weekends or during their breaks. The main aspect of this observation is that, these patterns are recurrent as users will have the same routine every day, every week or other repeating period. So, we can easily predict the future state of the overlay node based on the past observations. We can exploit these characteristics for efficient maintenance of structured overlay networks by implementing an intelligent prediction framework based on this human factor based workload for setting stabilization parameters appropriately. Researchers [34, 35, 36] have utilized this recurrent behaviour patterns for availability prediction and intelligent replica placement algorithm.
Most of the state of the art structured overlay networks [3, 4, 5, 6, 11] does nothing in order to ensure the connectivity of the overlay nodes ahead of time, rather they only react to the disconnection caused by the churn behaviour of the participant nodes. Some of the researchers [37] have proposed a statically resilient structured overlay network, but at the cost of larger routing table overhead.
Churn is an inherent dynamic characteristic of the overlay networks. Thus; it is a good idea to prepare for it ahead of time. Intelligent prediction of neighbouring node dynamism is helpful to improve the resilience and can reduce the overhead associated with topology maintenance of structured overlay networks. The short-term availability prediction of neighbouring nodes can serve as an important basis for scheduling maintenance operation on a particular structured overlay network node. This review paper proposes the use of a sophisticated predictive stabilization approach to schedule the next stabilization action by assessing the risk of failure of the neighbouring node for some time in the future.
Need of churn handling
The overlay networks are fundamentally open networks, where nodes may join or leave the overlay network at any time. The joining of a new node have a necessary condition to contact an existing node, whereas existing nodes may leave the overlay network ungracefully (without informing other nodes). This dynamicity raises the need of monitoring and maintenance of network connections to keep the routing table and the overlay structure up to date. The main idea is to enable the self organization of the overlay nodes in an autonomic manner.
Without employing a maintenance mechanism, the routing table entries may get stale and results in performance degradation as new nodes join or existing nodes leave the overlay network. The stabilization mechanism comprises of two parts: failure detection and node replacement. The failure detection mechanism periodically pings the neighbours to discover ungraceful leaves. After the detection of the failed routing table entry, it will be replaced by another appropriate alive node in the network. The method of detection and replacement of the failed node to ensure the structural integrity of the overlay network is known as stabilization mechanism.
A stabilization strategy is required to maintain the structural integrity by keeping the routing table entries (finger tables and successor pointers in case of chord) up to date in case of peer failure. The stabilization algorithm ensures the timely detection of node failures and keeps the routing table full with up-to-date entries. Thus, the stabilization mechanism is defined as the process of maintaining geometric and routing properties of an overlay network experiencing churn.
Design issues of a churn handling mechanism
The structured overlay networks are self organizing networks capable to handle high node dynamism. This self organization property ensures the legitimate configuration of overlay network in dynamic situation to maintain acceptable performance to its participants. But, to achieve this self organization, practical churn handling techniques are needed, which provide guaranteed overlay services without compromising the openness of overlay networks. Here, we highlight the issues and requirements of practical churn handling mechanism for the structured overlay network. The main issues while designing a practical churn handling mechanism are:
Overlay networks are practically open networks in which any new node can join or leave the network at any time. Thus a practical churn handling mechanism is needed that provide resilient overlay network structure in dynamic scenarios without compromising the openness of the system.
The majority of the internet devices connected to the internet is mobile devices with wireless links. So, most of the overlay network participants are mobile. Thus, an effective churn handling mechanism should be able to handle churn in mobile environment.
The overlay networks are composed of a large number of geographically distributed peers. Heterogeneous internet connectivity patterns and underlying user behaviour results in the variation of node behaviour. Whereas, most of the churn handling mechanisms either be designed by considering the capabilities of the weakest component (negative in mind) or by strongest component (positive in mind).
The overlay network is a set of independent nodes with no central administration. This decentralized nature of peer to peer networks offers many advantages, but it makes the monitoring and resilience to failure a complex task. Thus, while designing a churn handling mechanism; we need to keep in mind this decentralization and lack of global knowledge about the arrival/departure of nodes into account.
Due to the open nature of structured overlay networks, malicious nodes can easily become the part of the legitimate overlay network and can perform various malicious activities such as a DDoS attack, network partitioning and churn attack. Thus, along with the inherent churn feature of participants an effective maintenance strategy should be robust to this malicious behaviour.
Requirements of a practical churn handling mechanism
The churn handling mechanism requires efficient methods to find and replace stale routing table entries to retain the desired structure of the overlay network. The main requirements of a practical churn handling mechanism are as follows:
A practical and effective churn handling strategy must not induce high maintenance overhead for maintaining the structure of the overlay network. The excessive bandwidth requirements for the maintenance traffic will make the system impractical. Thus, a practical churn handling strategy has to maintain a balance between the maintenance traffic imposed, and desired performance level of the network.
A good churn handling strategy should be able to detect and correct the stale routing table entries timely to ensure the acceptable level of performance in terms of average number of successful query lookups.
Some researchers advocate the fact that an effective maintenance strategy should react to the changes in the environment, e.g. the churn handling strategy should behave according to the varying levels of churn. But, this feature could be exploited by the attackers to perform an attack on the availability of the overlay network by engaging its maximum bandwidth for maintenance action only. So, a good maintenance strategy should maintain a balance between reactivity to changes and performance of a structured overlay network.
The churn handling strategy should be efficient enough to maintain the desired performance level of structured overlay network without constraining their ever evolving nature. That is, a good churn handling strategy should not bind the arbitrary behaviour of overlay network participants.
A good churn handling strategy should be able to differentiate between malicious user induced churn and a legitimate churn. The inability to make this differentiation result in an inefficient maintenance mechanism that itself collapses the whole network.
A practical churn handling strategy should be decentralized that is, it should be able to maintain the structure of overlay network without requiring any centralized stabilization agent.
Classification of churn handling strategies.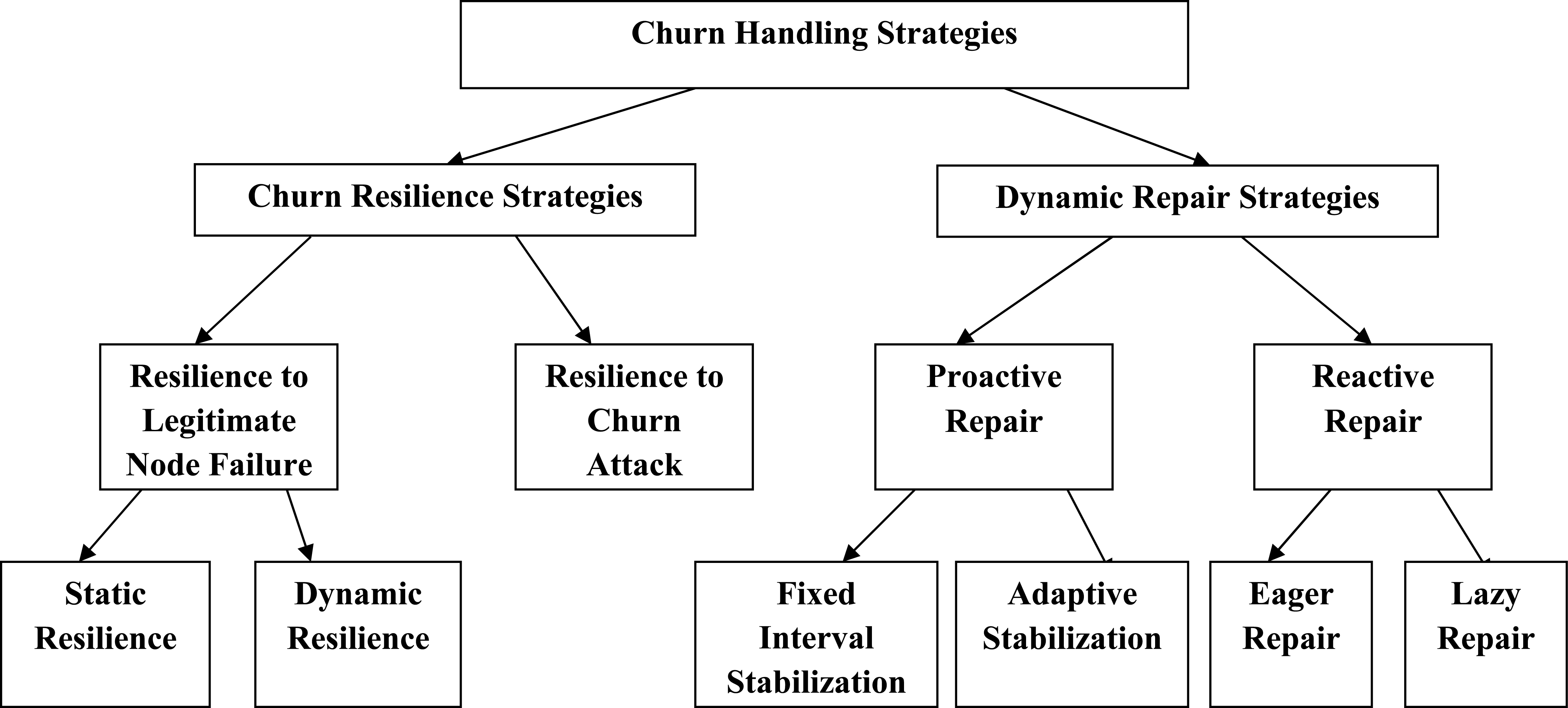
Structured overlay networks are used for maintaining membership and exchanging queries and responses. In this class of overlays, the main goal of the overlay construction is reachability and resiliency and therefore the overlays are often richly connected. The following are some examples of the overlay network churn handling strategies, categorized by their underlying principle of handling churn: (1) Churn Resilience and (2) Dynamic repair strategies. These categories are further divided into sub-categories based on their underlying mechanism of topology maintenance. The Fig. 2 classifies the existing churn handling strategies based on their underlying principle.
Churn resilience strategies
Churn resilience is the ability of maintaining system invariants (i.e., overlay topology, lookup performance, etc.) despite the node arrival and departure. In other words, the arrival of new nodes or departure of participating nodes must not disrupt the functionality of the overlay networks. Existing churn resilience strategies are classified into two main approaches based on the churn behaviour they are addressing: Resilience to legitimate node failures and Resilience to churn attack. The resilience to node failure approach considers the legitimate churn behaviour of participants that is they may go offline due to their inherent nature or due to occasional failure. Whereas, the resilience to churn attack approaches makes the system capable to defend against intentional churn attack orchestrated by a malicious attacker.
Resilience to legitimate node failures
The resilience to node failures approaches will maintain the system performance under the legitimate node dynamics. These approaches can be classified into two main categories based on their underlying strategy to maintain the functional structured overlay network in the face of churn: static resilience and dynamic resilience approaches. The static resilience approach is based on the idea to maintain an acceptable level of performance in the churn scenario. That is, although the system is not fully repaired in churn scenario, but it should be fully functional. Whereas dynamic resilience approaches concentrate on improving the overlay network resilience dynamically by providing flexibility in the selection of certain design parameters such as routing table size and neighbour selection.
Static resilience
The functioning of structured overlay networks relies on unreliable peers that may fail or leave the network at any time. So, the designers of these networks focus on the formation of the resilient geometry of the structured overlay networks that can cope with legitimate node failures without any recovery mechanism. The static resilience is the structural resilience that is how robust is the topology of a structured overlay network to the failure of the participating nodes. Thus, the idea here is to introduce topologically rich architectures to improve the structural resilience in churn scenarios. Inherently resilient overlay architectures need less frequent stabilization routines for topology maintenance.
Summary of the state of art structured overlay network geometries
Summary of the state of art structured overlay network geometries
Till date, various researchers have studied the static resilience of different routing geometries [4, 38, 39, 40]. Some of the researchers also study the resilience of state of the art geometries to random failure of the nodes and targeted attacks. These works have classified the overlay geometries into six main categories: Ring, Hypercube, Butterfly, Tree, XOR and Hybrid geometry. These geometries along with their advantages and disadvantages are discussed in Table 1. It is beyond the scope of our review to discuss these geometries in detail.
The Table 2 compares the routing performance of these geometries with respect to the following criteria’s: Flexibility of Neighbour Selection, Flexibility of Route Selection and their Fault Tolerance Capability. In this subsection, we discuss the robustness property of the state of the art flat geometries to accommodate the dynamic behaviour of its participating nodes.
Flexibility in neighbour selection: The flexibility of neighbour selection is defined as the number of choices available for the selection of its neighbouring nodes. This freedom of neighbour selection boosts the resiliency of structured overlay network to dynamic peer behaviour.
Flexibility in route selection: The route selection flexibility is defined as the freedom of selection of next hop in order to forward the lookup query towards the destination. The resiliency of a structured overlay network is more for more flexible overlay geometry.
Routing table size: The size of the routing table is defined as the number of overlay node’s connections that a particular node has to maintain in the form of routing address. The more is the number of connections an overlay node has to maintain more will be the flexibility of route selection. However, the higher degree corresponds to higher maintenance overhead in case of joining, leaving or failure of nodes.
The static resilience of the DHTs (Distributed Hash Table) is analysed based on their underlying geometries. The main feature to determine the robustness of the geometry is the offered alternating paths to a destination. The more is the number of alternating paths available, more will be the resilience to churn. However, the number of alternate path corresponds to the high node degree, which implies more overhead in case of joining, leaving or failure of nodes. Table 2 summarizes the route and neighbour selection flexibility provided by different geometries. The flexibility to choose neighbours allows the selection of closer and highly available peers, thus improve routing latency or may result in dynamic resilience to failures in case of dynamic systems. While, the route selection flexibility will result in increased fault tolerance in case of route failures due to departed neighbours and have a small impact on the routing latency too.
Routing performance comparison of structured overlay geometries
The experimental results of [39] confirm the hypothesis that more paths, offer better resilience to the dynamic overlay participants. Their analysis results clearly specify that, the ring and hypercube geometries have high resilience, whereas the tree and butterfly geometries have low resilience among the analysed DHTs (Distributed Hash Table).
Dynamic resilience is the resilience achieved by the flexible selection of design parameters such as the intelligent selection of neighbouring nodes and node degree of the overlay network participants to increase the routing redundancy to sustain acceptable performance in the face of churn. The selection of these parameters has a different impact on the resilience of structured overlay networks in churn scenarios.
The implementation of structured overlay networks in the practical environment has to consider a trade-off between the routing performance and maintenance cost by the appropriate selection of routing table size and expected hop count. At one end of the spectrum, there are designs that route lookups within the logarithmic bounds (logarithmic to the size of the network), with the maintenance of small routing tables per node. Thus, enhances the scalability of the architecture and ensures the lower maintenance overhead in the face of churn (nodes join and leave the network). The examples of structured overlay networks with logarithmic lookup bounds include Chord [5], Pastry [4] Kademlia [41] and Tapestry [3] with the routing table size O(
Taxonomy of notable structured overlay networks
Taxonomy of notable structured overlay networks
At the other end of the spectrum, there are overlay network designs with larger routing table size and have a constant lookup hop count to route a lookup query to the destination node. However, this larger routing table size requires more bandwidth to maintain the routing state up to date under churn. Thus; are not suitable for the applications that are prone to churn. Examples of these structured overlay network designs include EpiChord [11] and D1HT [37], that maintain sufficient routing information to resolve lookups in a single hop count irrespective of the size of the overlay. The performance comparison of different structured overlay network designs in terms of the lookup hop count, join/leave cost and routing table size is provided in Table 3.
For the performance improvement of structured overlay networks in churn scenario, researchers [42, 43, 44] have analysed the impact of node degree, neighbour selection and neighbour replacement strategies on (selection of neighbours is random instead of sequential) the state of the art structured overlay networks. The resilience of structured overlay networks is very sensitive to these low level design choices, but this feature is still least explored in the peer to peer literature. So, in this section we will discuss these design choices and their impact on the performance of the structured overlay networks.
Node degree or dynamic routing table size: The overlay network designers can tune the node degree of the overlay nodes to achieve different tradeoffs between lookup latency and maintenance traffic in the churn scenario. Most of the proposed structured overlay network designs offer some flexibility in the size of per node routing table. Thus, overlay designers can exploit this feature to adjust the fault resilience and efficiency of the overlay network at the cost of maintaining the larger routing table per node. The higher node degree usually induces strong connectivity and therefore good resilience in the face of churn. However, they will require more maintenance traffic to keep them up to date. So, a careful parameter choice will result in demanding fault tolerance with acceptable maintenance traffic under a certain percentage of node failure.
Several researchers [45, 46] have explored this trade-off to suggest a fixed degree overlay network with provably minimum lookup latency and maximum connectivity with bounded bandwidth overhead in the face of churn. The first study is conducted by Liben-Nowell et al. in 2002 to examine the fault resilience of the chord overlay network to derive lower bounds on the node degree of overlay nodes to maintain a sufficient level of performance under concurrent join/leave of nodes. In 2005, Li et al. have proposed a bandwidth efficient routing table management protocol that adapts its routing table size to provide best performance according to the user’s bandwidth budget. This system mainly maintains large routing tables for small and stable overlay networks and shrinks the size of the overlay network with increased churn in order to reduce the maintenance overhead.
Neighbour selection strategies: The flexibility of neighbour selection property can be exploited to improve the performance of structured overlay networks in the churn scenario by intelligent or randomized selection of neighbouring nodes (fingers in case of chord) instead of using predefined node identifier combinations. This flexibility provides the opportunity to consider different factors such as node lifespan, availability, etc. other than node identifiers to reduce the impact of churn.
The researchers have compared the performance of different intelligent neighbour selection policies [44] including randomized neighbour selection [9, 39, 43, 47] policies in terms of their lookup performance and resilience to churn. The main factors that will influence the selection of neighbouring nodes are the proximity and their liveness information. The liveness information of the overlay nodes can be used to predict their remaining uptime or to consider the node with the longest current uptime as the most reliable one to be the neighbour. These factors results in three main neighbour selection policies: Proximity Neighbour Selection (PNS), Random Neighbour Selection (RNS) and Liveness Neighbour Selection (LNS). The proximity neighbour selection policy improves the lookup performance by choosing physically close nodes as neighbours whereas random neighbour selection algorithm uses a uniform random node selection policy instead of using any predefined criteria. The Liveness neighbour selection policy populates its neighbouring table with the nodes that tends to stay alive for a long time. The LNS (Liveness Neighbour Selection) policy will result in stable neighbourhood and reduces the bandwidth consumption due to periodic probing and timeouts due to neighbour failures. The careful analysis of these policies shows the significant performance improvement by using LNS (Liveness Neighbour Selection) policy in churn scenario. These policies mainly find rules for intelligently selecting
In 2013, the researchers [48] have come up with a new idea of couple nodes to eliminate the churn effect by utilizing the complementary nature of their join and leave behaviour. In this scheme coupled nodes cache resources and monitor each other. In case of departure of one node, its spouse node will hold its responsibility for resource services temporarily.
Parallel Lookups: The phenomenon of churn degrades the lookup performance and increases the lookup latency of overlay networks either due to route failure or node failure. A large number of researchers [11, 41, 46] have examined the improvement in the performance of structured overlay networks by employing lookup parallelism in the churn scenario. In a parallel lookup scenario, the requestor will initiate multiple lookups simultaneously, some of these lookup requests will fail due to stale routing table entries, and the lookup process can continue process without being blocked. However, the selection of optimal degree of parallelism is important for the balancing between message overhead and latency reduction. In 2007, Wu et al. [49] have provided a simulation study to select the optimal degree of parallelism. However, existing studies still are not sufficient to answer the optimal parallelism degree and whether periodic pinging to check routing entry liveness is a more efficient use of bandwidth than sending parallel lookups.
Churn is an attractive tool for an adversary to destabilize the structured overlay network [31]. In this attack, a large number of malicious users will join and leave the network frequently in order to increase the bandwidth consumption due to overlay maintenance. The state of the art structured overlay network architectures [4, 5, 9, 50, 51, 52] consider churn as a legitimate node behaviour and provide simple maintenance mechanisms with significant recovery time to handle a set of node failures [44, 48, 53]. Researchers have been aware of this attack for quite a while [18, 54, 55, 56, 57] and various solutions have been presented to thwart this attack [3, 51, 58, 59, 60] but until recently no solution can provably cope with this attack without compromising the openness of the overlay network. Moreover, most of the proposed solutions [58, 59] are static as they can handle only bounded number of node failures. Kuhn et al. [58] have proposed an efficient but a complex architecture to counter an intelligent adversary by continuously shifting newly joined nodes to less sparse areas. In contrast, our proposed technique is simpler and addresses more realistic random intentional churn attack by allowing the new nodes to join as a leaf node and thereby isolating the effect of leave of malicious nodes without affecting the rest of the overlay.
A large number of researchers are currently working on structuring the overlay networks in a hierarchical manner [61, 62, 63, 64, 65, 66, 67, 68, 69, 70] in order to achieve better efficiency, performance, maintenance cost and load balancing. Mariela et al. [69] have evaluated the hierarchical DHTs in the churn scenario of mobile nodes and clearly state the effectiveness of hierarchical DHTs as compared to flat DHTs. However, they have not considered the effect of malicious adversary, who maliciously triggers a large number of join requests for limited lifetime to bring the entire system down.
Table 4 summarizes the comparison of performance of different state of the art flat and hierarchical structured overlay networks in terms of lookup hop count and cost of join and leave in the form of messages sent per join/leave event.
Dynamic repair strategies
The dynamic participation of overlay network nodes results in stale routing table entries of the structured overlay network. The dynamic repair is the process of dynamically updating these routing table entries to maintain the structural integrity of the overlay network to accommodate the churn behaviour of the overlay network participants. The static and dynamic resilience of structured overlay networks deals with their ability to survive the churn behaviour before taking any repair action. The comparison of these three strategies is provided in Table 5.
The dynamic repair, also known as the maintenance strategy is needed to maintain the structural integrity by compensating for the changes in the overlay structure due to peer failure or network connection failure. The structured overlay network implementation has an explicit node join mechanisms, but leaving is implicit as nodes may simply go offline or crash. Both graceful leave and unexpected failure of participating nodes require the implementation of a maintenance strategy to repair the routing tables of online nodes. Thus, a maintenance strategy can be defined as a routine to maintain the structural integrity in case of peer or network connection failure. This maintenance routine will be responsible for ensuring node failures are detected, and the routing tables are kept as full and up-to-date as possible.
Comparison of performance of different overlay architectures
Comparison of performance of different overlay architectures
In case of super peer failure. Where N is the number of super peers.
Comparison of different churn handling approaches
The dynamic repair can be characterized into two main types: proactive and reactive repair. The proactive repair strategy executes the maintenance routine periodically whereas in the reactive maintenance strategy the maintenance routine is triggered immediately after the failure detection.
The proactive repair [3, 4, 5] strategies maintain the overlay network structure by running a stabilization routine periodically. Periodic maintenance is employed by using scheduled probing to check the health of neighbouring nodes, even when it is not needed. The main purpose of the periodic stabilization is to incorporate the new nodes and remove the failed nodes from the overlay network. But, this joining and leaving of node may occur at any time and do not have any fixed interval. So, the performance of the periodic stabilization depends on the period (stabilization interval chosen). The choice of stabilization interval further classifies the proactive repair in two categories: Fixed interval and Adaptive Stabilization.
Fixed interval stabilization
The fixed interval proactive maintenance [3, 4, 5] approaches keep-up the overlay network structure by using a periodic stabilization mechanism, where period is chosen without taking into consideration the churn rate of the overlay network. The performance of the periodic stabilization [3, 4, 5] technique depends on the stabilization interval chosen. If stabilization interval is selected pessimistically, it may result in performance degradation in case interval chosen is longer as compared to the frequency of network change. However, the optimistic choice of stabilization interval may lead to higher overhead as it will select frequent stabilization. Thus, the appropriate selection of stabilization interval is critical for the achievement of desirable reliability and performance.
The current approach for configuring the structure overlay network is static. That is, design parameters such as stabilization interval, routing table size etc. are selected statically. This setting will result in optimal performance, if either the perfect information about the future is available or the network and operating conditions remain static throughout the system lifetime. As the structure overlay network evolves over time, thus static configuration will result in a low lookup success ratio, high failure rate and more communication overhead [13].
State-of-the-art structured overlay networks [3, 4, 5] employ a periodic stabilization scheme, where each node periodically contact its neighbours to check whether they are online or offline and update their routing table in order to improve the robustness under churn. This approach uses a fixed stabilization interval without taking churn rate of the network into account. However, various studies [13] argue that churn rate is not fixed. So, selection of appropriate stabilization interval has significant impact on the performance of overlay both in terms of robustness and control overhead.
Researchers [9, 13] have analyzed the various inconsistencies in the performance of structured overlay networks employing proactive stabilization in the face of churn. Krishnamurthy et al. [14] analytically studied the chord [5] architecture under churn and observed a significant degradation in the routing efficiency due to incorrect or dead entry in the longest finger. Thus, the stabilization mechanism needs to be triggered frequently to ensure the correct and efficient working of overlay networks.
Adaptive stabilization
Due to the criticality of the period selected in fixed interval stabilization techniques, several researchers have come up with the idea of adaptive stabilization that will choose the period for stabilization routine by considering the present network conditions and adjust it dynamically. The adaptive stabilization procedure considers the continuous evolution of network conditions of structured overlay networks and tries to adapt to them by continuous collection and processing of statistical data about network dynamics and adjusting its design parameters accordingly. This technique is quite effective as compared to the fixed interval stabilization where period is chosen passively [13].
Several researchers [71, 72] have worked on improving the performance fixed period stabilization techniques by adjusting the stabilization rate, according to churn conditions or by sharing the probe load among the nodes having common neighbours or by limiting the sending of stabilization messages to its direct successors and failure of successor will be broadcasted to all the routing table entries. In the adaptive stabilization framework [13], a node will estimate the churn, build a stochastic network model and then adjust stabilization rate by using statistical analysis to satisfy the QoS requirements.
Researchers [73] have extended the periodic stabilization process to handle extreme events like network partitions in the face of churn by introducing a new mechanism of merger. The merger messages will die out when the overlay architecture converges to a ring again. In 2015, Paul et al. [74] has modified this mechanism to trigger the merger in a proactive manner by maintaining a knowledge base at each participating node.
Comparison of proactive and reactive repair strategies
Comparison of proactive and reactive repair strategies
In contrast to proactive repair, the reactive repair strategies [7, 10, 11] are based on the concept of triggered stabilization in view of sporadic churn behaviour of overlay participants. Thus; maintenance routine will be called only after the detection of node failure. The Table 6 provides the comparison of the proactive and reactive repair strategies. The reactive repair strategies involve two phases: failure detection phase and failure recovery phase. In the recovery phase, the missing entry in the routing table of the peer is replaced by sending a contact request to a new peer. The reactive repair strategies can be classified into two categories based on the execution time of recovery phase: Eager and Lazy maintenance. The eager techniques execute the recovery action as soon as a change is detected. Whereas, the lazy repair strategies delay the implementation of recovery action either up to the failure to deliver a data packet or until all the routing table entries of a node become stale. In this sub-section, we will discuss different reactive maintenance strategies in detail.
Eager repair
The eager repair strategy will trigger the maintenance action as soon as a failure is detected. This strategy is also known as correction-on-change strategy as the maintenance action will be taken as soon as any change in the form of join/leave/failure of a node is detected. The maintenance action comprises of updating of successor and predecessor pointers along with the triggered update of finger table. In Correction-on-change- technique, whenever a change is detected, all nodes that depend on the node where the change occurred are corrected [7].
However, Krishnamurthy et al. [14] highlighted that the eager repair strategy is vulnerable to network congestion as it can create a positive feedback loop and exacerbating existing problems.
Lazy repair
The lazy repair strategy delays the maintenance action, even after the detection of failure of few nodes. This technique tries to remove the vulnerability of eager repair techniques to attack the structured overlay network’s availability by triggering the maintenance action simultaneously over many nodes. The lazy repair strategy is further of two types: Correction on use or correction on failure. These two techniques, correction on use and correction on failure, update the routing tables lazily after detecting the failure of data packet during system use or when all the routing table entries become stale.
In the correction-on-use technique, the failure of the neighbouring node is detected, when a message sent to the neighbour is not acknowledged within the given time. This failure should be tackled by performing finger table updating in the form of piggybacked maintenance messages on the lookup requests. So, the more network usage will result in more accurate finger tables without incurring extra maintenance message overhead. This scheme will not apply any probe based ping mechanism; instead the failure of the node will only be detected on the use of each route for message delivery. This technique is also known as the opportunistic maintenance strategy, as it performs maintenance opportunistically by piggybacking the maintenance messages over application traffic. In 2003, Alima et al. [7] have provided a new infrastructure for overlay networks that eliminate the unnecessary bandwidth consumption for maintenance by correcting routing table entries on-the-fly while performing lookups. As an example, Epichord [11] have used the opportunistic routing table maintenance. The main opportunistic aspect of Epichord’s routing table maintenance algorithm is the addition of new neighbours to the routing table only upon receiving the lookup request from them and removing peers after considering them dead. In 2005, Li et al. have proposed a new routing protocol Accordion [46], which adjusts its routing table size according to node’s bandwidth limit and network churn rates. The adjustment of the routing table size is done using opportunistic aspect, as each node will learn about its neighbours based on the ordinary lookup messages. Each Accordion node will keep only those neighbours in its routing tables from which it has recently been heard from and a new neighbour will only be added upon receiving a lookup request only.
In the correction-on-failure maintenance technique, the maintenance technique relies on the high degree of redundancy in the routing tables. Thus, instead of repairing it immediately or opportunistically, this scheme will perform maintenance only when the routing fails or when all the routing table entries of a node becomes stale and further routing is not possible. This scheme is very suitable for the networks, where the nodes will only be temporarily offline and will reappear after some time.
Proactive vs. reactive repair
A good maintenance strategy should be adaptable to the varying levels of churn with minimum overhead. Performing periodic maintenance, when it is not needed leads to increased overhead and reactive maintenance occurs only after causing routing inconsistencies. Although, reactive maintenance has minimum overhead and triggered immediately after the detection of the failure, but this reactive maintenance strategy can bring down the network instead of repairing it by congesting the network with maintenance traffic or can easily be exploited by a malicious attacker.
The main driving factor behind the implementation of the predictive stabilization is to provide affordable, preventive maintenance for the structured overlay networks. For predictive maintenance, researchers [75, 76] have proposed two main data driven approaches for prediction: Hidden Markov Model (HMM) and Neuro-Fuzzy, and compare their performance to forecast the failure of neighbouring nodes in order to schedule the next stabilization routine. The HMM is a statistical model, which finds the relationship between different variables to predict the failure of nodes. Whereas, Neuro-Fuzzy is an artificial intelligence based models that learns from the data instead of using explicitly programmed instructions.
The Table 6 concludes that, both periodic and reactive maintenance approaches have drawbacks that make them unsuitable in certain situations. Performing periodic maintenance, when it is not needed leads to increased overhead and reactive maintenance occurs only after causing routing inconsistencies. Thus, recently researchers have [75, 76] have proposed a new class of maintenance mechanism: Predictive Maintenance. The predictive maintenance strategy comes into play after predicting the failure of neighbouring nodes and before causing any routing inconsistency unlike reactive stabilization. The ability to predict or estimate the node failure enables to perform preventive maintenance on abnormal nodes instead of all nodes and results in affordable system operation by providing triggered maintenance.
Conclusion and future directions
In this paper, we have analyzed the problem of churn in the decentralized structured overlay networks along with the detailed study of the existing churn handling mechanism by categorizing them according to their underlying principle of handling churn: Churn resilience and Dynamic Repair. We have also explored the issues involved in designing and implementing efficient maintenance techniques to improve the performance and reliability of structured overlay networks. These discussions lead to some interesting conclusions. First, although static resilience is an important first step while choosing structured overlay network’s ability to handle node failures and an important design parameter, but it does not provide the clear picture of system resilience unde continuous churn and repair mechanisms. The main function of static resilience is to determine the desirable quickness of dynamic repair algorithm to ensure the trouble free operation of the overlay networks. Second, the main purpose of the dynamic resilience is to enhance the resilience of the system under node failures by the appropriate selection of design parameters. This can be achieved by tuning different overlay design parameters under different work loads and network conditions to determine the competitive performance of overlay network architecture. The dynamic resilience provides the clear idea of system resilience under continuous churn and repair mechanism. However, both, the static and dynamic resilience of structured overlay networks deals with their ability to survive the churn behaviour and do not accommodate it by taking any repair action. Third, the dynamic repair strategies can accommodate the churn behaviour of overlay nodes by repopulating the routing tables of live nodes with updated neighbour list. This repair action can be scheduled proactively or reactively for structural integrity maintenance. However, the cost of proactive repair and vulnerability of reactive repair strategies to churn attack highlight the need of predictive repair mechanism for the affordable and preventive maintenance of structured overlay networks. Fourth, the open nature of the overlay networks makes it vulnerable to malicious attackers, who can easily exploit the churn handling mechanisms to attack the availability of the structured overlay networks. So, appropriate measures should be taken to propose churn handling mechanisms robust to such attacks. The research issues discussed in this paper highlights some issues that should be considered in the further research. First, the heterogeneity and mobility properties of the overlay nodes results in a complex operating environment for overlay applications. Thus; more sophisticated behaviour studies of the overlay nodes are required for understanding and modelling of churn behaviour. These behaviour studies will form an important basis for the design of churn handling mechanisms. Second, the overlay network applications involve a large number of geographically distributed overlay hosts with different time zones. Depending on these time zones, different overlay nodes will have different business hours and their online behaviour may vary accordingly and results in a different churn patterns. Thus, researchers can utilize this diversity for the churn handling and replica placement for the development of more fault-tolerant overlay architectures. Third, Churn is an attractive tool for an adversary to destabilize the structured overlay network. Researchers have been aware of this attack since quite a while and various solutions have been presented to thwart this attack, but until recently no solution can provably cope with this attack without compromising the openness of the overlay network. Fourth, the maintenance protocol of structured overlay networks itself is attackable. For example, the reactive maintenance strategy can be exploited to bring down the network instead of repairing it by congesting the network with maintenance traffic by generating a false detection. Similarly, the maintenance protocol can also be exploited to launch an eclipse attack against the overlay network by routing table poisoning. Thus, the future research work should concentrate on the development of churn aware routing table updation for the development of efficient structured overlay networks and appropriate measures should be taken to secure the overlay network against malicious attackers without compromising its open nature.
Footnotes
Authors’ Bios