
Abstract
Data stored on a cloud is becoming more and more important. Thus, data replication across multiple cloud nodes is considered an effective solution to achieve good performance in terms of response time, load balancing and most importantly, high data availability and reliability. To maximize the benefit of data replication, strategic placement of replicas in the system is critical. In this paper, the vision of replicas management is turned to multi-criteria optimization methods, again known as Multiple-Criteria Decision Analysis (MCDA) for decision support system. For this, we propose a data replication strategy in a cloud environment based on two different methods. The first is based on the Analytic Hierarchy Process (AHP), and the second is based on the ELECTRE-I multi-criteria decision support method. The main aim is to propose and demonstrate the use of an AHP and ELECTRE-I models for cloud data replication. The results of simulations of our strategy were satisfactory and improved performances, with the two methods, by comparing it with other strategy proposed in the literature.
Introduction
Today, the field of information and communication technologies has become one of the pillars of modern society. The development of the cloud computing concept has been a major step towards the democratization of this field. Data management becomes one of the crucial elements of the infrastructure [13]. It plays a central and major role in the cloud and, as such, it needs to be given greater attention so that it is always available.
Data replication is a very well known and researched data management technique that has been used for decades in many systems [7]. Benefits of data replication include increased performance by strategic placement of replicas, improved availability by having multiple copies of data files and better fault-tolerance against possible failures of servers.
Multiple-Criteria Decision Analysis (MCDA) is a major area of study for operational research. There are methods and calculations to choose the best solution or the optimal solution among a whole set of solutions.
The formulation of an MCDA problem requires four steps:
List the potential actions; List the criteria to be considered; Establish the performances chart; Aggregate performances.
The first three steps are common to all methods. So the step of aggregate performances that makes the difference between methods. According to the mode of aggregation, there are three main families of methods: complete aggregation methods, partial aggregation methods, and local aggregation methods [3, 2].
Complete aggregation methods are based on a mathematical function that produces a unique value from the evaluations of the different criteria thus allowing compensation between the criteria. The result of the function used makes it possible to choose a solution globally. Among these methods, we mention the Weight Sum Method (WSM) and the Weight Product Method (WPM), which are the simplest forms of the function used. We can also mention other methods such as MAUT (Multi Attribute Utility Theory) [15], the UTA method (Utility Additive) [6], as well as the AHP method (Analytic Hierarchy Process) [18].
Partial aggregation methods (also called outranking relation methods) are based on the comparison of pair wise actions. This comparison is carried out for each criterion and makes it possible to determine the relation which links each pair of actions. The relation can be a relationship of preference, indifference or incomparability. Using these relationships, we can determine either the best action, or some of the dominant actions. Among these methods, we quote the family of ELECTRE methods (ELimination and Choice Expressing REality) developed by Roy [3], and PROMETHEE method [8].
A replica placement strategy has inputs and outputs. as input each strategy proposes a set of criteria to calculate and evaluate for each site of the system; then to choose the candidate site to place a replica, strategies used a very simple technique called the weighted sum to calculate the replicas placement cost (output) necessary for each site, then choose the site having the least cost. The principle of the weighted sum is to calculate the sum of, the products of each criterion with its coefficient, to have a unique value that makes it possible to compare the results of each site.
In order to handle the placement of replicas in a cloud environment, we propose a data replication strategy using two different MCDA methods. The goal of our strategy is to choose the best candidate site to place a replica. With the first method, we calculate a cost function based on a multi-criteria optimization method called AHP (Analytic Hierarchy Process). This method allows us to calculate in a formal way the coefficient of each criterion after having introduced the weight of each criteria proposed by the user. The second method used is called ELECTRE-I, which aims to select a subset of solutions from an initial set of actions. This method consists of three phases, named respectively, introduction of weight of criteria and calculation of the concordance indices, calculation of the discordance indices, and extraction of over-ranking relationships.
Our contribution is to put in place a more adapted approach that models the system as a multi-criteria optimization problem, in which we applied two multi-criteria optimization methods called AHP and ELECTRE-I. Our work is focused on the evaluation of MCDA techniques for cloud data replication.
Our data replication strategy considers replacing replicas in case there is not enough space to store the replica.
The remainder of the paper is organized as follows. Section 2 presents the most related works on existing data replication strategies in cloud. Section 3 presents our model and the detailed steps of the proposed data placement approach. Section 4 demonstrates the simulation results and the evaluation we have adopted. Finally, Section 5 addresses our conclusions and future work.
The main goal of replicas placement strategies is to select the best sites to place replicas to improve performances. Replica placement belongs to the NP-complete class of problems [17, 24].
In the literature, several works have dealt with the problem of managing replicas in clouds, and more precisely the replicas placement. MCDA techniques have not been widely applied to replication strategies in the clouds, and only recently.
Data replication strategies without multiple-criteria decision techniques
Wei et al. [12] presented a Cost-effective Dynamic Replication Management scheme (CDRM). They propose a model that studies the relationship between replica number and availability. The purpose of this model is to limit the number of replicas while meeting availability requirements. According to CDRM, the data replica placement is based on several parameters such as CPU power, memory capacity, network bandwidth and the saturation of data nodes storage system. They implemented CDRM in Hadoop distributed file system (HDFS). CDRM was compared to the default replication management of HDFS and evaluation results obviously show that CDRM improved performance and load balancing. However, the replicas replacement was not taken into consideration.
Yuan et al. [5] proposed a matrix based k-means clustering strategy for data placement in scientific cloud workflows systems. In their strategy, they attempt to keep the datasets in one data center, with the goal that when jobs were scheduled to this data center, most, if not all, of the data they need are stored locally. Their idea was to study and determine dependency matrix for all the application data, which shows the dependencies between all the datasets including the datasets that may have fixed locations. Then they introduced the BEA algorithm [22] to cluster the matrix and partition it that datasets in every partition are highly dependent upon each other. The simulation results indicate that with this strategy, the data movement between the data centers is significantly reduced compared to a random data placement.
Li et al. [21] presented a new cost-effective dynamic data replication strategy named Cost effective Incremental Replication (CIR). Their strategy has the objective to reduce the storage cost and meet the data reliability requirement at the same time. CIR is a data reliability strategy for Cloud-based applications in which the focus is for cost-effectively managing the data reliability issue in a data-center. The approach proposed in CIR is to calculating the replica creation time point, which indicates the storage duration that the reliability requirement can be met. In order to guarantee the reliability requirement, CIR dynamically increases the number of replicas by predicting when an additional replica is needed. The data storage model used in CIR exploits the relationship between the number of replicas and the storage duration. The simulation results demonstrate that CIR strategy can significantly reduce the number of replicas in a data-center, and consequently, the storage cost of the whole storage system can be considerably reduced. Nonetheless, CIR did not consider the issue of the trade-offs between cost and performance.
Hussein and Mousa [9] proposed a data replication strategy which adaptively selects the data files for replication in order to improve the availability and efficient access of files in data centers. This strategy determines the popular files that are identified by analyzing the access history of the file. The popularity of a file is determined by the rate of access to that file by the clients. Once the access number of a popular file exceeds a predefined threshold, the replication system is triggered. Hence, the adaptive strategy finds the appropriate replication location based on a heuristic search for the best replication factor of each file. Simulation results show that the adaptive strategy improves the availability of the cloud system under study, but it doesn’t take into account the load balancing of the system.
Rajalakshmi et al. [1] presented a dynamic replica selection and placement (DRSP) architecture for managing replicas in cloud environment. The proposed strategy concentrates on designing an algorithm for suitable optimal replica selection and placement to increase availability of data in the cloud. In a first phase, the strategy consists of locating and creating replicas using catalog and index. The index is used for storing replica file into local or remote candidate site. In the second phase, the policy determines whether there is enough space, or not, in the candidate site to store the requested file. Experimental evaluation shows that DRSP stores data efficiently in selected sites and improves the performance of access and bandwidth utilization. Further, this strategy has not dealt with the storage usage issue and consistency of data file.
Data replication strategies with multiple-criteria decision techniques
In another work [10], the author presented a Replicas Placement strategy based on Analytic Hierarchy Process in cloud data storage (RPAHP). Replicas placement was modeled as a classical Multi-Attribute Decision Making (MADM) problem. The analytic hierarchy process (AHP) is a structured technique for organizing and analyzing complex decisions. RPAHP considered six attributes (criteria), namely, CPU, Memory, Bandwidth, CPU Utilization, Memory Utilization, and Bandwidth Utilization, which characterized the Data Center and affected the DC performance. We noticed that the optimization criteria that have been chosen for the replicas placement concerned only data center components. The author neglected criteria judged much more important for a better choice of candidate sites for replicas placement such as: the response time, load variance, replicas frequently. AHP method was also used in other work of [23]. An algorithm based on fuzzy comprehensive evaluation, based on AHP method, was implemented. A QoS (quality of service) model of cloud storage service was proposed. Then, a QoS preference-aware algorithm was introduced to deal with individual QoS sensitivity (IQS) constraints.
Mansouri [11] proposed an approach called “Adaptive Data Replication Strategy (ADRS) in cloud computing for performance improvement”. She proposed replicas placement strategy based on five parameters: mean service time, failure probability, load variance, latency and storage usage. At the base of these parameters, she calculated the cost function for each site. The smaller the Cost-Function value, the better the individual’s fitness. When a new replica was generated, the ADRS chose one of light-load sites to store the new replica. The simulation results showed that ADRS gave better performances compared to other works such as CIR [20], DRSP [1] and CDRM [11], according to the five parameters cited above.
Discussion
The main goal of replication strategies differs from one strategy to another. In a typical cloud environment, where frequent access requests are placed on large-scale data, response time and high availability are crucial for users. As in many systems, a number of data replication strategies have been proposed (Hussein and Mousa [9]; Wu and Guan [23]) to improve the service quality through SLA-awareness in cloud systems.
Some of the proposed replication strategies focus on minimizing the consumption of a certain cloud resource (Rajaklashmi et al. [1]), e.g., Bandwidth, while others limit the number of replicas to reduce the storage cost (Li et al. [21]) and improve the load balancing of the system (Wei et al. [12]). In data replication strategies, only a few studies are particularly interested in improving the response time (Mansouri [11]) to improve performances.
According to this bibliographic study, we noticed that each strategy improved performances but in a well specified context. Meanwhile, each of these strategies has some limitations, we quote as an example, the load balancing criterion that was not taken into consideration by [9, 10], or the strategy [1] which has not dealt with the storage usage issue and consistency of data file, and so on.
Among the works cited in this section, we look to the strategy proposed by N. Mansouri called (ADRS) [11] which used a maximum of criteria (5 criteria). Meanwhile, her strategy has been compared with some works cited above (CIR, CDRM, DRSP), and improved performances compared to the Average Response Time, Load Variance, Effective Network Usage, Replication Frequency and Storage Used. She calculated a cost function, for each site, based on service time, load variance, storage usage, failure probability and latency. The cost function that she used was calculated by applying the weighted sum method where the user proposed weights for each criterion. Nevertheless, this method, the weighted sum, had several limitations:
The choice of weights is critical. The user sometimes finds it difficult to determine the values of The underlying aggregation logic is totally compensatory. A very low weight on one criterion can be offset by one or more high weights on other criteria. Some efficient (non-dominated) data nodes may never appear as an optimal solution for a weighted sum regardless of the set of weights selected. High sensitivity to small variations in weightings. Very slight variations in weight values can lead to radically different solutions No intuitive correspondence between the values of the weights and the optimal solution obtained by a weighted sum.
In order to overcome these limitations we propose an approach using two MCDA methods, respectively, AHP (CF-AHP) and ELECTRE-I (DRS-ELECTRE-I).
The details of the proposed approach will be described in the following section.
In this section we present our approach based on two methods called Cost Function based AHP method (CF-AHP) and Data Replication Strategy based on ELECTRE-I method (DRS-ELECTRE-I). This section is organized as follows. First, we describe the model of the system used. Then we briefly mention the criteria used in our model. Next, we present the first approach proposed CF-AHP and finally, we present our second approach DRS-ELECTRE-I.
System model
Before discussing our replication strategy, we must first define the system model of replication management used. The cloud storage cluster we propose in this paper is composed of m independent heterogeneous data nodes
Most file systems [20] suppose that each access to file
System model of replication management.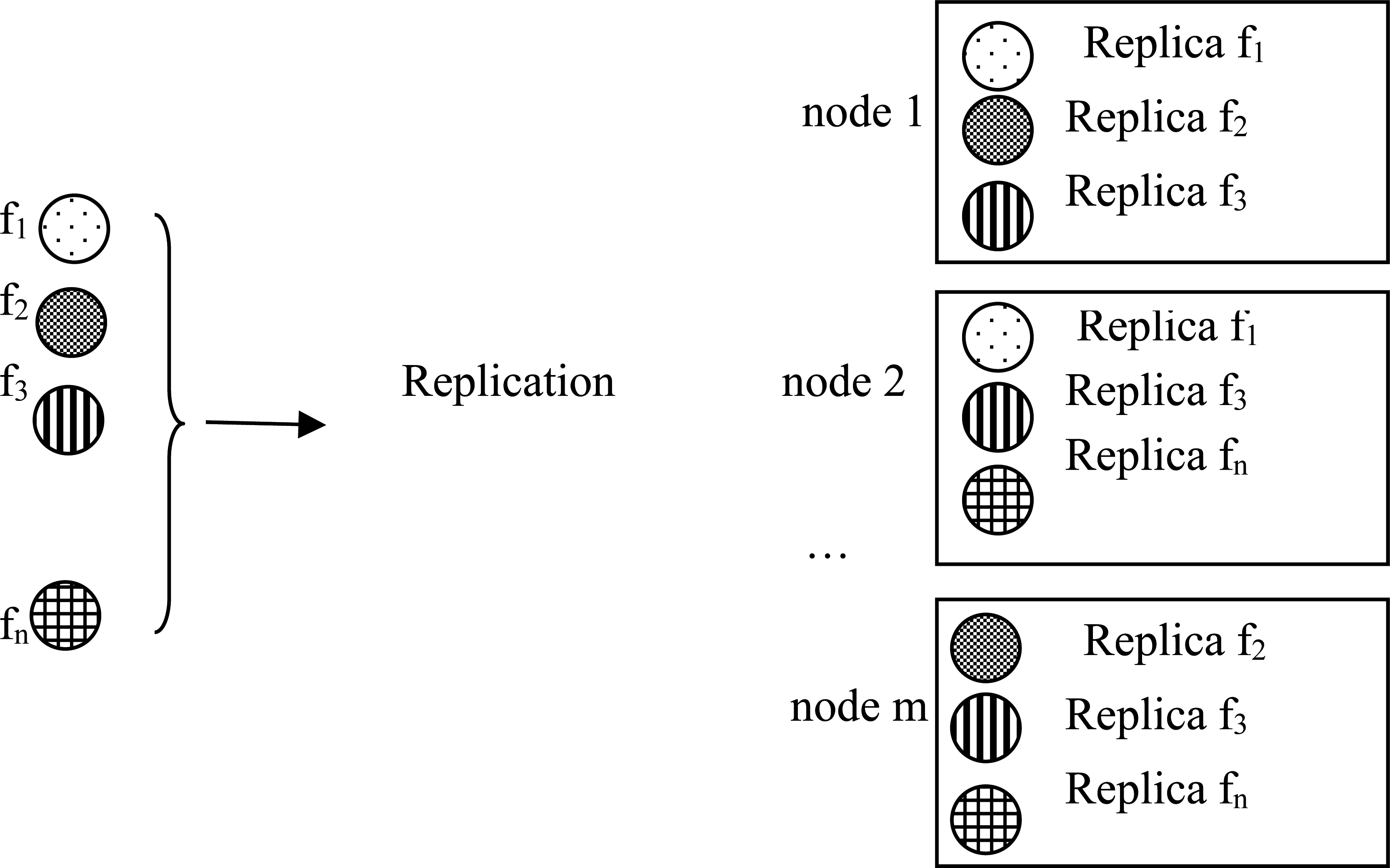
We kept the criteria used in [10], which are as follows:
Mean service time (MST):
where:
where:
The mean service time of file
The mean service time of the system is given by the following:
Load variance (LV): Data node load variance is the standard deviation of data node load of all data nodes in the cloud storage cluster which can be used to show the degree of load balancing of the system. The lower value of load variance, the better load balancing is achieved. It is calculated as follows:
Storage usage (SU): It is the storage space used in each node.
Failure probability (FP): If one node fails, a replica of the failed service will be possibly created on a different node in order to process the requests. Thus, it is better to place popular files in data nodes with low failure probability to minimize their latency.
Latency (L): The mean latency
Each file
In this approach we propose a multi-criteria optimized data replication strategy for cloud storage. We take into account several factors such as mean service time, load variance, storage usage, failure probability and latency to select candidate data nodes for replica placement.
Our system is modeled as a multi-criteria optimization model. The weighted sum method that was used in [10] has presented several limits, for this we have chosen to use the AHP method which gives more flexibility to the users.
This generic method of decision-making aid can be used with each time we have to make a decision on the basis of several criteria [19]. The cost function is used to determine the best sites candidates to place replicas.
The cost function is calculated as follows:
where MST, LV, SU, FP and
For the whole of the criteria, we calculate a matrix of analysis per pair to evaluate the importance of each one of them.
Saaty and Vargas in [18] proposed an evaluation on 5 levels according to Table 1.
Relative scores
Relative scores
On the base of this table, we build a square matrix whose elements of the lines and columns are the 5 criteria of the cost function (MST, LV, SU, FP and
In the preceding step, we built a square matrix which rises from an evaluation 2 to 2 of the criteria. In order to calculate the coefficients of the criteria based on the values of our matrix, we have to calculate the sum by column, then, we divide each value of the column by the sum of those, and finally, the coefficient (which corresponds to the value of the matrix) is given by calculating the average of each line.
The AHP method will enable us to calculate the coefficients
Data replication strategy using ELECTRE-I
In this approach we propose a multi-criteria optimized data replication strategy based on ELECTRE-I method.
For an ELECTRE application, there are two main parts. First, the construction of one or several outranking relations, which aims at comparing in a comprehensive way each pair of actions. And second, a phase of exploitation and development of the recommendations obtained in the first phase. In ELECTRE methods, criteria have two distinct sets of parameters: the importance coefficients and the veto thresholds.
Choosing sites for replica placement is a crucial problem. In the proposed approach, we will choose the candidate site to place a replica based on the ELECTRE-1 method.
Criterion weight and concordance matrix
The importance of each criterion is reflected by a weight proposed by the user. To normalize the calculations, the sum of weights must be equal to 10.
The problem to solve is to choose the best candidate site to place a replica. Let
The discordance index
where
The over-ranking relationship for Electre-I is constructed by comparing concordance and discordance indices at thresholds of concordance
The concordance and discordance thresholds are defined as the max value of the concordance matrix and the min value of the discordance matrix respectively.
The over-ranking relationship allows us to determine the site which dominates the most of the other sites, and in which we can place a replica.
Our strategy takes into consideration the replica replacement phase in case there is not enough storage space in the candidate sites. The problem that existed for these kinds of strategies before is that at the beginning of the system launch, if a subset of files is frequently requested and these files are unavailable on the replica servers, the system will launch one or multiple replications of these files, and in case there is not enough space, the concerned strategy will be forced to delete one of the files to free up space; while this deleted file could be one of the files that was not requested at first but after a moment the file will be solicited, knowing that it has been deleted. In our replication strategies, the novelty of the replica replacement phase was to mark the initial files as master files, and the replicas generated as a slave files, so even if we do not have enough space, we will not be able to delete a master file. So we can keep the integrity of the files.
In replicas replacement case, one or more files will be deleted based on several parameters such as:
Non frequently used files; Replicas size; File availability in other sites; Replicas access history.
Replicas access history allows us to have two important parameters, access number (AN) and the last time the replica was requested (LT). From there, we can define an indication of the probability of requesting the replica again. Another important parameter for replica replacement is the file size (S), it is better to replace files with large size to reduce the number of replica replacement.
We can calculate the potentiality (PT) of each replica with the following formula:
where FA is the file availability, CT is the current time and the value of
Replicas placement and replacement for the two proposed methods can be summarized as illustrated in Algorithms 1 and 2.
In our study we use the simulator CloudSim which is the best tool simulation known and used in domain of cloud simulation [16].
To start the simulation, the user uses the method startSimulation in its code. This method calls other methods such as run, runClockTick, runStart and runStop. All these methods dispose of entered cloudlets by a FCFS scheduling policy [14].
In our experimentation, file accesses show Poisson arrival rates and fixed service times. We only consider that all the data are read only, and thus no data consistency strategy is needed.
Cloud data server architecture.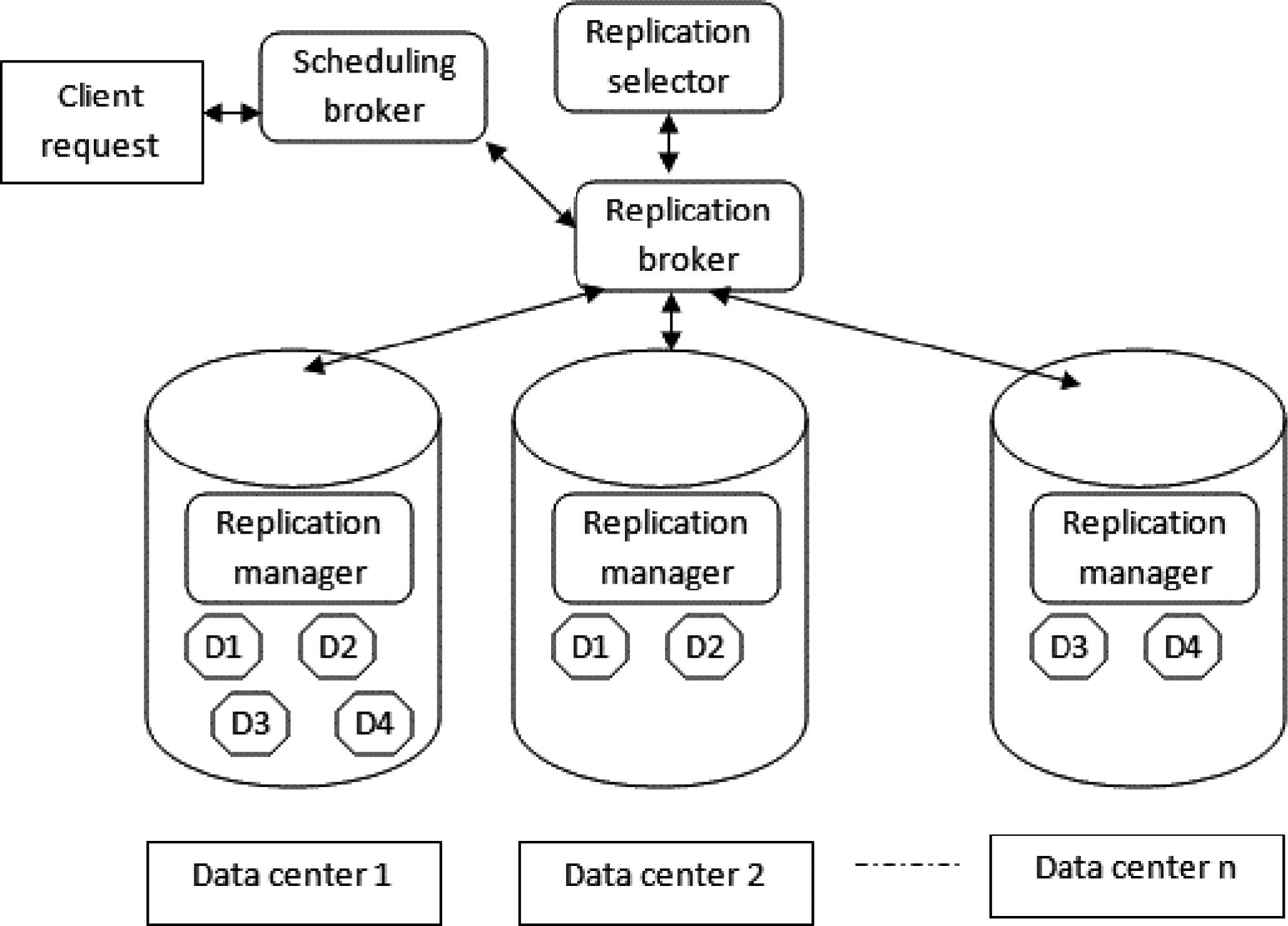
Mean response time based on varying number of tasks.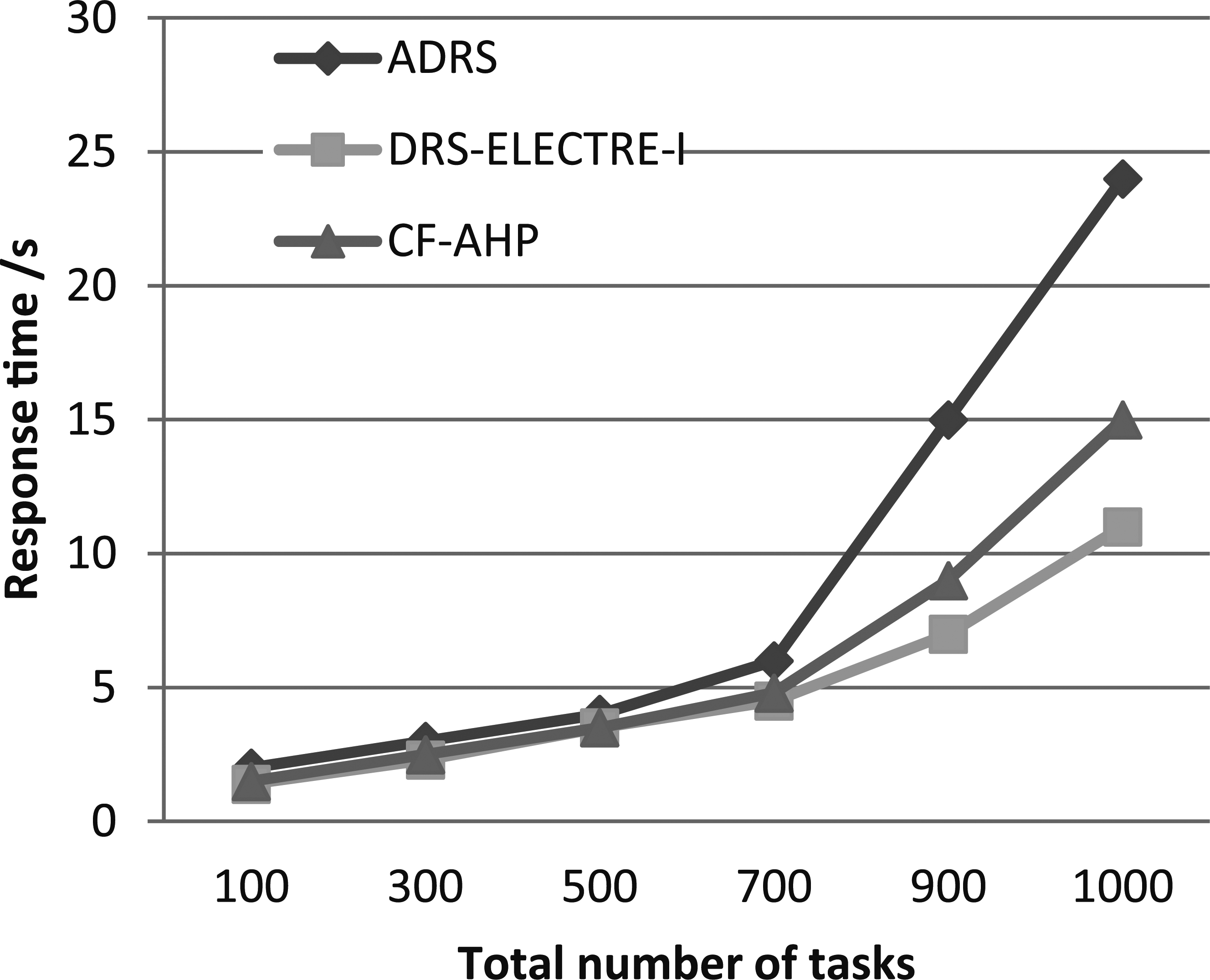
In the work of [11], the author compared her strategy called ADRS with other ARS, DRSP, CIR, CDRM and Build-time. According to experimentation results ADRS gave better results.
In our experiment we opted to compare our strategies CF-AHP and DRS-ELECTRE-I with ADRS which was already validated in the paper [11]. For that we used the same configurations that were installed in [11]. We configure 64 datacenters geographically distributed in cloud with the corresponding topology shown in Fig. 2. The service providers are represented by 1000 virtual machines. Each virtual machine (VM) is configured as 512 MB RAM, 1000 MIPS, 1000 M bandwidth, and single processer. A hundred different data files are placed in the cloud storage environment, with each size in the range of [0.1, 10] GB. 1000 tasks are submitted to the service providers using Poisson distribution and ensure their processing requirements larger than 10 MI, as well as adopt Random function to assign tasks file size and output file size. Each task requires one or two data files randomly. The host allocates query requests to each VM by the VMSchedulerTimeShared policy.
Initially, the number of replicas of each data file is 1 and replicas are placed randomly.
In order to compare our CF-AHP, DRS-ELECTRE-I and ADRS replication strategy, we use several metrics which are: Average response time (ART), Effective network usage (ENU), Load variance (LV), Replication frequency (RF) and Storage usage (SU).
The calculation of each criterion is as follows:
ART: for each data file, we can calculate the response time, which is the interval between the submission time of the task and return time of the result. The average response time of the system is the mean value of the response time for all data request tasks of the users, which can be obtained by the following equation:
If our system is composed of m users (
Where
ENU: we have used the formula of [4] where ENU is given as follows:
where
LV: Data node load variance is the standard deviation of data node load of all data nodes in the cloud storage cluster. Load variance is used to represent the degree of load balancing of the system. The lower value of load variance, the better load balancing is achieved.
RF: it is the number of replications generated per data access. The lower value indicates that strategies are better at putting data in the proper nodes.
SU: it is determined as the ratio of filled space available in total space. The lower value indicates that strategies are better at placement and replacement of replicas in the system.
After configuring the cloud environment of our simulator, we proceed to configure the different weights of the criteria for each implemented strategy (i.e., ADRS, CF-AHP and DRS-ELECTRE-I). Once the simulation is complete, we present in the following the results of the different strategies with respect to each evaluation criterion presented in the previous Section 4.1).
Average response time (ART)
Figure 3 shows the average run time of spots based on the number of spots. According to Fig. 3, the difference between ADRS and our two strategies, DRS-ELECTRE-I and CF-AHP, is clear especially by exceeding 700 tasks. CF-AHP and DRS-ELECTRE-I significantly reduced the average execution time of tasks by selecting the best replica location for task execution, taking into account the cost of replicas.
In the ADRS strategy, the author has calculated the cost function based on the weighted sum method, while the cost function of our CF-AHP strategy is based on the AHP method, and again the DRS-ELECTRE-I strategy is based on the multi-criteria method ELECTRE-I, which made the difference on the choice of the candidate sites for the placement of the replicas. Therefore, the placement of the replicas influenced the average execution time of the tasks and even the other criteria.
It is clear that the DRS-ELECTRE-I replication strategy improves response time and keeps response time at a stable level in a short time. The main reason is that in DRS-ELECTRE-I, the total number of local accesses has been increased by placing the replica in the best site and avoiding unnecessary replication. As a result, the total number of replications and remote access has been reduced and, as a result, the response rate has been decreased.
Effective network usage.
Load variance based on varying number of files.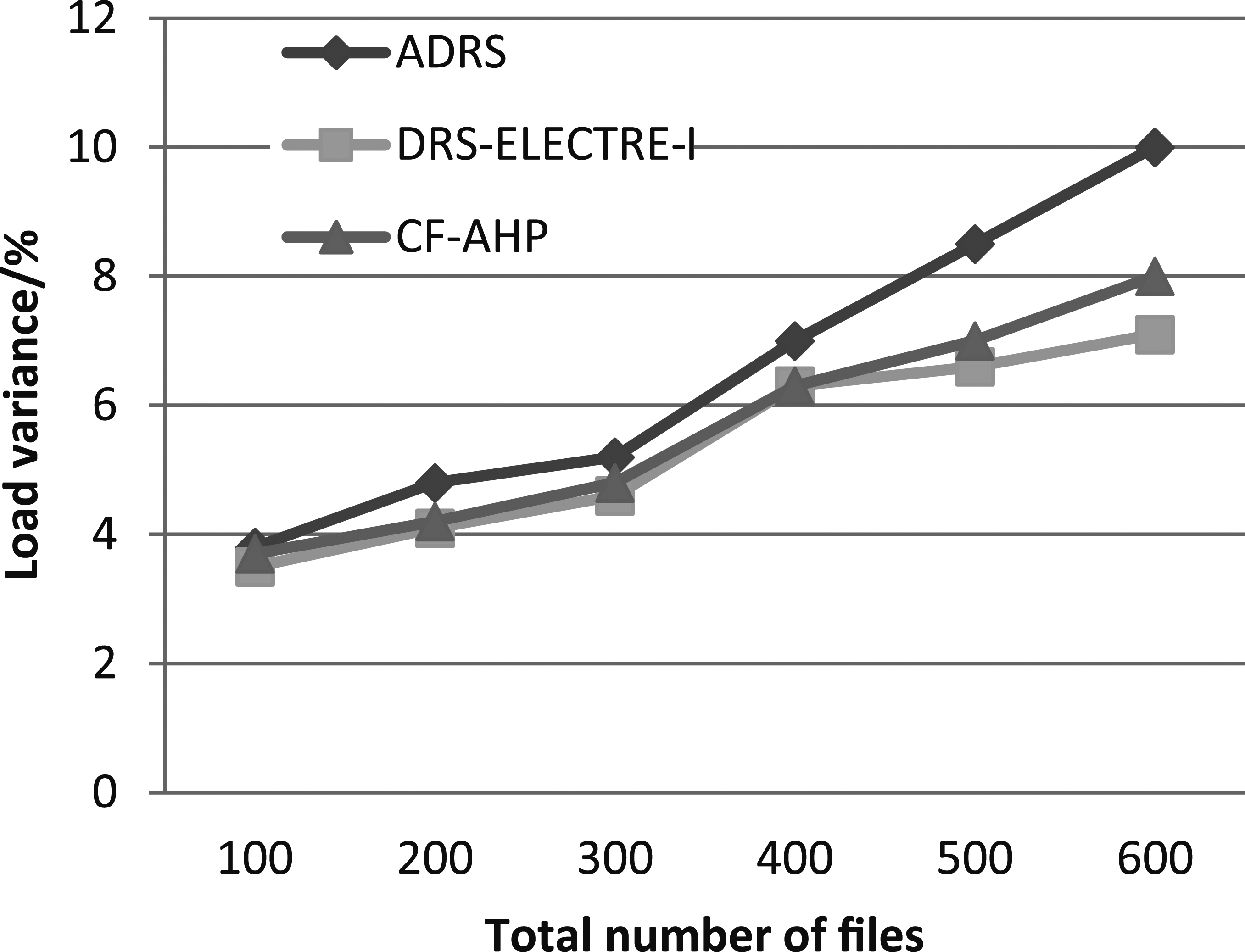
Data replication takes time and consumes network bandwidth. However, a non-replication-based strategy is inefficient compared to the simplest replication strategy. Any replication has an interest in reducing network traffic. ENU is calculated based on the ratio of the files transferred to the requested files, so a low value indicates that the strategy used is better to put the files in the right place. The effective use of the network for the three strategies is illustrated in Fig. 4. ENU of the DRS-ELECTRE-I strategy is about 52% lower compared to the ADRS strategy, and 28% than the CF-AHP strategy. The main reason is that the sites will have their files needed at the time of need, hence the total number of replicas will decrease and the total number of local accesses will increase. The DRS-ELECTRE-I strategy is optimized to minimize bandwidth consumption and reduce network traffic.
Load variance (LV)
Regarding another criterion, LV (Load Variance), we took into consideration the load balancing of data centers. The simulation showed that the load variance of the three strategies converges, up to 400 files, but subsequently, the DRS-ELECTRE-I consistently outperforms the other two strategies. Figure 5 shows the simulation results of load variance based on the number of files.
Replication frequency.
Storage usage.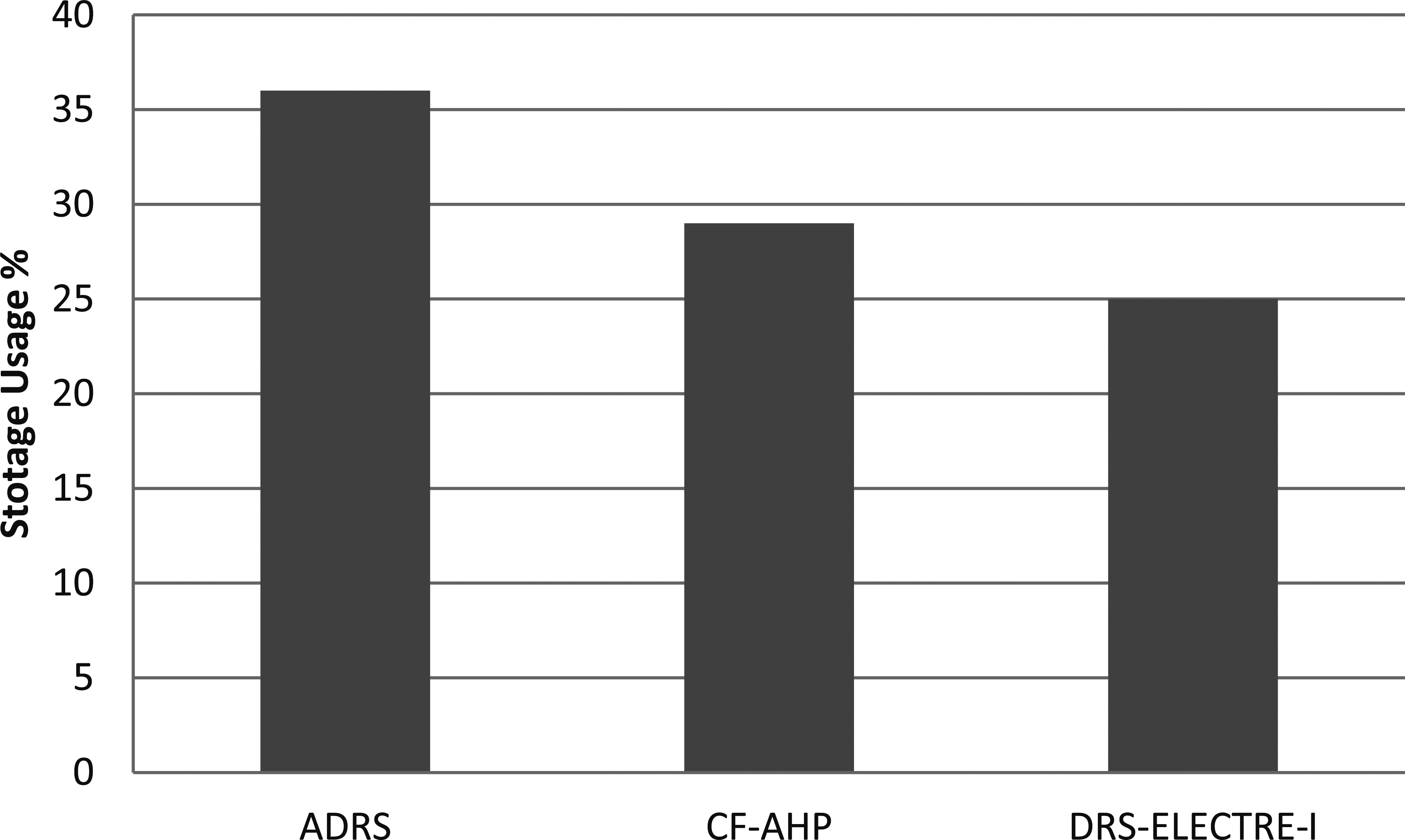
In the following experiment, we study the replicas frequency, i.e., the number of replicas generated. When the system initiates replication, not only the network bandwidth resource is consumed, but the replica server load also increases due to disk I/O and processor usage. Therefore, the frequency of the replication operation must be limited to avoid significant overhead of the network and the replica server. The replication frequency results are shown in Fig. 6. The replication frequency of ADRS is approximately 0.09, i.e., at most nine replicas are created for 100 data access, but for our two strategies, they have 0.07 and 0.06 for CF-AHP and DRS-ELECTRE-I respectively. The proposed policy can adapt to the changing environment and maintain rational replica placement, which not only satisfies availability, but also reduces unnecessary replication. The difference in the replication rate will be clear by increasing the number of data accesses. The results presented in Fig. 6 are given at the rate of 100 data accesses.
Storage usage (SU)
The storage utilization percentages for the three strategies are shown in Fig. 7. The DRS-ELECTRE-I algorithm creates replicas dynamically in advance. Instead of storing files in many sites, they can be stored in a particular site so that storage usage can be reduced. This indicates that with DRS-ELECTRE-I, we can expect fewer replicas, which leads to better performance than the other two strategies.
As shown in Fig. 7, the DRS-ELECTRE-I strategy reduces storage usage to 29% compared to ADRS, this is obvious, as long as this strategy generates fewer replicas and therefore it takes up less storage space.
In conclusion of the results, we note that the strategy DRS-ELECTRE-I improves the performances of the five studied criteria, and this thanks to the choice of the optimization multi-criteria method which selects the best candidate site to place the replica. Meanwhile, the different simulation results also show the performances presented by the CF-AHP strategy comparing with ADRS.
Conclusion
The purpose of data replication works in cloud environment differs from one strategy to another, those focuses on optimizing system performance, such as load balancing and storage space reduction, and others that aim to satisfy users by meeting criteria such as response time and data availability. Mansouri’s work [11] met several criteria satisfying the system and the users, for that we concentrated on this work. In our approach we were able to improve mansouri’s performance by adopting two MCDA methods named AHP and ELECTRE-I. The application of the two multiple-criteria decision analysis methods has as objective to select the best candidate site to place a replica by optimizing a set of criteria. These criteria are: mean service time, failure probability, load variance, latency and storage usage. We used the CloudSim simulator to compare Cf-AHP and DRS-ELECTRE-I with ADRS which gave better performances before. The simulation results showed that DRS-ELECTRE-I outperforms CF-AHP and ADRS compared to metrics: Mean response time, load variance and replicas frequency. Especially, its performance becomes better and better with the incensement of the number of tasks.
However, these strategies present some limitations. They don’t integrate the economic concept and energy economic with the criteria used, because these are very crucial points in cloud environment. For that, we have as perspective to integrate them in future works.
Footnotes
Authors’ Bios