
Abstract
Fog computing, a popular ambient computing technology has become a basic need for IoT as its characteristics outperform cloud computing in terms of cost, time and security. Fog lies between the cloud and the end users. The edge resources such as switches and routers could not cope up with the growing IoT needs and moreover, expanding fog resources require large investments from the perspective of the service providers. Instead, managing the need in the smarter way would bring profitable benefits. Research focusing on efficient resource provisioning to fog computing has come up with innovative solutions such as resource cooperation and resource sharing models. The main factor that drives resource sharing and resource cooperation is the user’s participation in resource funding which is in turn influenced by incentives provided to the contributors. An effective incentive design to bring out the benefits of the crowdsourcing model successfully is essential. The existing crowdsourcing models for fog resource provisioning lacks an incentive mechanism to attract more contributors to fund their idle resources. Hence, an effective demand-based incentive mechanism is proposed to encourage users to fund their idle resources concerning to the demand in their location. Simulation is carried out and the results show that the proposed model is effective and the properties of the incentive mechanism are validated through evaluations.
Introduction
In the recent past, the use of smartphones has grown tremendously, as the home computer’s need is replaced with smart devices. The technological evolution on the internet has made IoT a basic need for modern communications. The increasing popularity of IoT needs low latency and location-aware services with low energy consumption. Fog computing is emerging as a backbone of IoT applications. The physical resources available at the datacenters are the basic requirements for cloud computing. Fog computing is defined by Cisco as the computing that “facilitates the operation of computing, storage, and networking services between end devices and cloud computing data centers”. The resources that are available at the edge such as routers and switches have scarce availability of physical resources. Building data centers with huge servers at the edge network would require a large investment. Instead, managing the resources without much investment would bring fruitful results. In recent works, researchers are keen on building a model to expand or manage the fog resources with smarter approaches such as resource sharing models, and resource cooperation. Resource sharing models enable end users or service providers to cooperatively share their idle resources for fog computing services.
A typical crowdsourcing system appeals for paying the participants by virtual coins, social status, monetary rewards, and credit systems. The sole success of the crowdsourcing system depends on individuals readiness to take part in the crowdsourcing activity. The crowdsourcing platforms are growing with increased mobile users and their mobility supporting content creation based on their locations. In many models, participants are captivated by the gaming system in which the participants are entertained with games. Though the gaming systems are popular in crowdsourcer based rewarding, monetary rewards have to be emphasized to attract many participants in funding their own resources for others benefits. The monetary-reward system, when built in a one-sided view may throwback losses. Hence, a demand-based incentive mechanism is formulated for resource provisioning in fog computing.
The contributions of the study are listed below:
A novel demand based incentive mechanism that can vary according to the requirements in a particular location is proposed. The assurance time defined as the “promised time” is incorporated to assure the availability of the resources with the cloud vendors. To trace the quality of the users and their resource funding, reputation is managed for each user based on their funding period as “status S”.
Incentive schemes with crowdsourcing models
In [1], authors have proposed crowdsourcing based software development. The crowdsourcing methods have triggered the traditional software development methods. Through online, a large group of people can collaborate or compete in the development process. However, the trust between the crowd and the cloud is not discussed in detail, in order to ensure the quality of the software development. The Rebate mechanism with a fixed budget was designed [2], to reduce internet congestion in the peak congestion hours. Users who contribute for reducing the peak time congestion get reward points, which they use in later hours for their own usage. However, users who need connectivity usually during peak congestion hours suffer from low response rates and limited access to certain portals. The STAR [3] (Social Trust Assisted Reciprocity), replaces monetary reward with social trust-based reciprocity, recognizing the importance of the social media and its reach towards common people. On the other hand, the social reciprocity among social friends may not always be trustworthy. The crowdsourcing model in [4], proposed with social awareness and reputation has focused on appointing the participants to take part in crowdsourcing. The main aim of their model is to allocate the task to the appropriate participant that fully depend on their social attribute and the reputation they have gained based on their previous performance. This may not work all the time as participants status and abilities may not always depend on their past. However, new participants get lesser chances to participate in crowdsourcing. Socially influenced user selection model proposes [5], the incentive model for a single time window and multiple time windows. Auction mechanism proposed in single time window may encourage only the winner to participate repeatedly in the task, whereas the losers get discouraged and lose the cost they spent on sensing. Focusing on eliminating free riding and false reporting [6], the authors have introduced periodic updating about their task. Periodic updates will create an overhead at cloud and consume extra time and this may prolong the sensing task as well. Hysense model [7] aims in a uniform distribution of the sensing task to the sensing nodes. In cases of unavailability of participants for sensing, the static nodes work instead of humans.
In [8], crowdsourcing with smartphones elaborates two types of incentive mechanisms such as crowdsourcer-based and user-based. In crowdsourcer-based, crowdsourcer fixes the budget and participants cannot increase their utility in any way, and in user-based, participants can increase their utility by competing with the co-participants. In the crowdsourcer-based model, crowdsourcer optimizes the budget of the task, and in user-based users compete, and increase their utility. Cloud-assisted crowdsourcing model [9] aims in defeating the problem of resource-constrained mobile devices. Users can make use of the cloud to store their sensing task and the crowdsourcer will extract the results from the cloud. In [10], Incentive with privacy protection, a two-level auction mechanism is designed, wherein the first level users upload bidding and in second stage winners are selected for the task. Online reputation system overcomes the free-riding problem with reputation retained for each user to rank the users based on their performance. The model designed in [11] enables users to select more than one sensing task at once. In order to assure the quality of sensing third-party servers are involved. Third party servers verify the relationship between the multiple sensing tasks chosen by the single user.
In [12], focus on optimizing budget by preferring participants who are in the sensing locations is discussed. In this approach, participants do not have to travel for sensing, and hence it reduces the sensing budget. Authors of [13], have used a reference set to increase the quality of the sensing task while assessing the participants. This innovation can make evaluation faster than the traditional method. In contrast, maintaining a reference set for all the task becomes complex. In [14], authors have proposed crowdsourcing-based cyber security system for emergency situations. This study highlights the situation such as finding a missing individual in the crowd. The study incorporates a gaming system for incentive mechanisms. In such a situation, gaming may not influence enough participants to take part in crowdsourcing. Authors of the study in [15], have emphasized the importance of social friends in crowdsourcing models. The participants influence their social friends to take part in crowdsourcing. The social friends are selected based on their level of trust, as the behavior of the chosen friend will reflect on the payment of the participant. The study designed in [16], have a model for participants to choose their sensing task based on their wish. This model could suffer from a prolonged time for handling the complex task. Participants would wish to complete, easy and lesser complex task, to finish their task faster. Virtual reward system in [17], discusses the possibilities of incorporating gaming into the crowdsourcing systems. The model highlights the scenarios based on how the virtual reward system reaches out successfully towards people instead of volunteerism and monetary rewards.
Resource provisioning algorithms for fog computing
In 2011, authors of the study in [18], related neural system of a human with the architecture of the IoT. The central control lies in the brain and the smaller task get distributed among the small nodes lying below the brain. Similarly, the central cloud control gets distributed to smaller nodes reducing the pressure on central cloud datacenters. The social structure model for IoT in [19], highlights the advance IoT objects relationships and its coexistence. Authors have highlighted the trust relationships, identity relationships, services and so on to structure the IoT objects. Cooperative resource sharing based on game theory designed in [20], explores the cooperative resource sharing that increases the revenue of the service providers compared to individual resource provisioning. The revenue sharing model was also discussed, which was based on contribution based sharing in which the amount of contribution is directly proportional to the revenue share of the provider. Federated clouds, voluntary resource cooperation designed in [21], documented the storage provisioning and its feasibilities in community clouds. However, the storage provisioning in community clouds suffer from ownership of resources provisioned, and hence voluntary provisioning is not possible. Resource prediction and estimation model proposed in [22], has covered the resource provisioning to the IoT. Based on the history of services used by the end users, the services are designed in the fog layer. Prior prediction can help in planning the services, yet the new users would suffer from prolonged service times. Efficient resource provisioning algorithm designed in [23] modeled the architecture of fog computing. The authors have clearly explained the scare resources at the fog layer and fog can efficiently pre-process the task before forwarding it to the cloud datacenters. In addition, the networking resources and its capabilities based on its feasibility to provide services to IoT devices is presented. The model of the three-layered architecture of fog and cloud are presented in [24], in which the fog computing architecture and the resource availabilities are clearly described. Based on the availability of the resources at the fog layer, the task to be processed in fog or cloud is very clear. Bargaining-based incentive mechanisms proposed in [25], aimed at reducing internet traffic by sharing the internet among the neighboring users. Authors have numerically-derived the results and showed that their model can reduce up to 30% of the traffic. Resource sharing model for fog computing in [26], designed based on repeated game theory modeled the task distribution among the users with available resources. The task completion is encouraged by rewards and task incompletions are punished with penalties.
Most of the existing studies focus on game theory based incentives for crowdsourcing. In general, the gaming system assumes that the participants are trained in a particular procedure; however, not all participants are experts. The focus on resource funding for fog computing is very limited with very few studies involved. Moreover, the existing studies lack in mutual benefits of the involving actors. Also, in resource funding for fog, the assurance of how long the contributed resources are going to exist with crowdsourcer has not been focused since. An efficient incentive mechanism should be flexible, that can change according to the situations. The proposed approach steps forward to mutually benefit the resource contributors as well as cloud vendors.
Proposed methodology
Notations and abbreviations are listed in Table 1.
Notations and abbreviations
Notations and abbreviations
Architecture of resource provisioning in fog computing using crowdsourcing.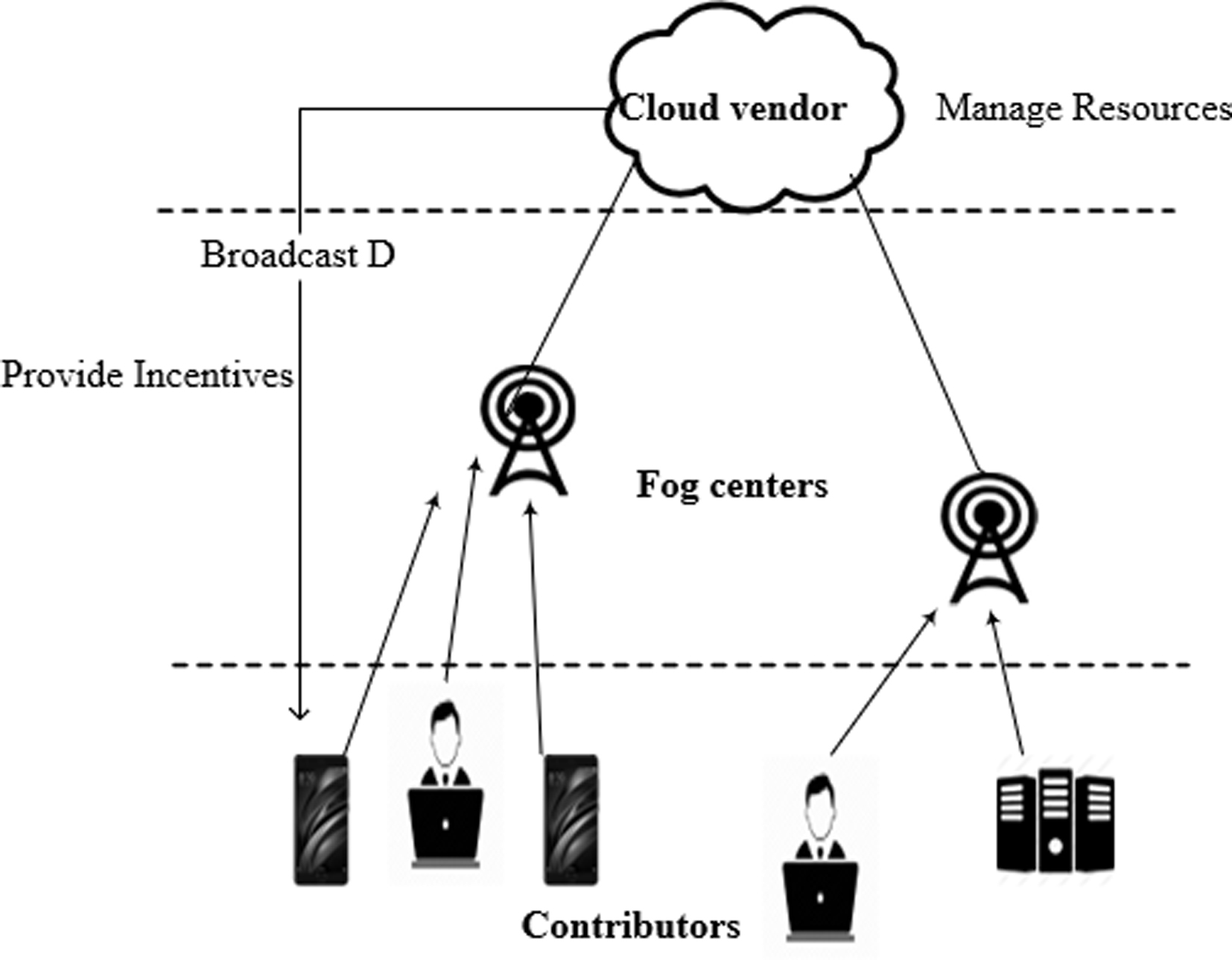
The architecture of resource provisioning for fog computing using crowdsourcing is shown in Fig. 1. The cloud vendor determines the resource requirement of each location to set the demand for the location. Based on the demand, end users come forward to contribute their resources for fog computing services that are managed under cloud vendors. The contributor’s incentives are calculated and distributed by the cloud vendors. Demand is dynamic and keeps changing periodically based on the resource requirements at that location.
The cloud vendors aim to construct fog centers without the need for investing in deploying the physical resources at the edge of the network. Instead, the proposed model enables them to set up their local datacenters with the help of end users idle resources. As the user’s resources are not engaged all the time the end users who own the physical resources can contribute their idle resources for purpose of the fog centers locally and benefit by the incentives and free cloud services received from the cloud vendor. The influencing factors of the incentives are the demand of the location, promised time, contribution time and the quantity of resources contributed by the users.
Demand (D) of the location (L) is decided by the cloud vendor, based on the request rate arrival of that location to the cloud. When the request arrival rate of a particular location is high, then the need for local processing in that location is also high. Users can check demand of the locations before contributing their resources. Resource owners willing to contribute their resources for the fog centers are participants. Cloud Vendors (CV) are cloud service providers, who set up the fog centers at the edge of the network. They divide the locations into different zones and rank them according to the request arrival rate. Ranking helps them in fixing the demand. Based on the request arrival rates, the demand and the unit cost (UC) of the resources are broadcasted to the users.
Users’ participation is triggered by the demand of the location from where they fund and the promised time (PT). PT is the commitment to fund resources for a particular duration. Demand influences the users to contribute their idle resources at highly required locations. For example, fog centers are required wherever the cloud datacenters receive more number of requests. Hence, in such locations, the demand to appeal to more users to participate in contribution is high. In addition to the incentive they receive for their contribution, status (S) is an additional benefit that cloud vendors provide, in order to appeal contributors to contribute their resources for longer hours. The contributors receive status based on their promised time and contribution time. Promised time (PT) is the period of time that the users commit; regarding how long they would be able to fund the resources. Users commitment based on the promised time confirms that the resources are available for a certain period, and the cloud vendors can better use the resources for fog services. Promised time has to be decided by the contributors at the beginning of the contribution. Contribution time is measured based on the period of time contributors contribute their resources. It is important that promised time may not be always equal to contribution time, as the contributors can take back their resources at any point in time. Based on the status, contributors are provided with free cloud services.
Crowdsourcing model
Cloud vendors aim at constructing fog centers for improving the quality of the cloud services. Fog centers reduce the burden of the cloud data centers by pre-processing the request from the users at the user’s end. They build the fog centers by coordinating the idle resources from the end users. The vendors calculate the demand of the particular location based on the request arrival rates from that location. Based on the demand, the users decide on funding their resources for fog centers. The value of the demand fluctuates based on the request arrival rates and the amount of resources contributed. The rationality of cloud vendors and the resources funders always aim at increasing their own benefits. The focus of the proposed model is to design an effective incentive model that can satisfy both the contributor and the cloud vendor. Crowdsourcer can take control of the incentives by fluctuating the demand at any time based on the amount of resources contributed and the request arrival rates. At the same time, contributors can also take control over the incentive they receive based on the time they contribute. Hence, the proposed incentive model mutually benefits the contributor as well as the cloud vendor.
Utility model
Consider the request arrival rate Rrr from the location L. The cloud vendor aim in creating the fog center at location L by setting the unit cost of the resources as UC and the demand D as D
Flow diagram of demand-based incentive algorithm.
The users from the location L decide on the contribution and submit PT and amount of resource (AR), such that PT
The utility of the cloud vendor can be defined as the difference between the total benefit they get from resource contribution and the total incentives they provide for the resource contributors. Similarly, the utility of the resource contributors can be defined as the difference between the total incentive they receive for the contribution and the total cost they spent in contributing their resources. The cloud vendor benefit (CVB) is the total resources that the cloud vendors get from the resource contributors and the cloud vendor utility (CVU) is the profit that they receive from the resources.
The cloud vendor benefit (CVB) is shown in Eq. (1).
where
With the CVB, the cloud vendor utility is calculated based on the Eq. (2)
where TI
where the cost C depends on the type of resources that the users contribute and I is incentive for the resources contributed.
User’s contributions are classified as random and promised contribution. The flow diagram of Demand-based incentive algorithm is represented in Fig. 2. The amount of resources, to be contributed and the promised time of the contribution are mentioned at the time of contribution by the contributors. Each contributor is provided with the unique contribution identity Uid. When contributors are not sure about the period of contribution, they choose the random approach. The demand (D) of the location does not influence the incentives of the random contributors (R). In addition, random contributors do not enjoy status updates. Incentives I
Where I
Promised contributors mention their Promised Time (PT) when they are sure about the duration of their contribution. Based on Demand (D), the incentive for each contributor is calculated and they enjoy the status updates. The incentive I
where
where
where P
Equation (5) shows the incentives determination for promised successful I
The cloud vendors and contributors aim to earn the highest profit in return. The cloud vendors cannot provide with high demand value at all the time. Targeting many users to contribute their resources, if cloud vendors try to fix the demand high at all the time, it results in lowering the utility rates for them, as they need to provide a high incentive for contributors. Instead, they fluctuate the demand based on the requirement of the resources at the location, so that the resources are contributed based on the demand of the location. This will ensure the contributors and cloud vendors to yield mutual benefit.
Competitiveness
The competitiveness of the model lies in status updates of the contributors they receive for the resource contribution. Based on the status updates, contributors are encouraged by providing free cloud services.
Rational
The proposed model mutually benefits contributors and cloud vendors. The contributors receive incentive I and status S from the resource contributions. The cloud vendors benefit from providing fog services to the users.
Computational efficiency
A model that runs in polynomial time is computationally efficient. The proposed model can run in polynomial time and hence the model is computationally efficient.
Incentive evaluations
Implementation is carried out using Matlab. The user’s samples are taken manually with varying data inputs. Incentives are determined based on their resource contribution, considering the demand (D) as 9 and the unit cost of the resource as 20 rupees. A sample of fifteen users are considered as random users, and a sample of fifteen users are considered as promised successful users, and a sample of fifteen users as promised unsuccessful users. The value of AR is varied from 10 to 150. The promised time is varied from 3 to 17 for promised successful and promise unsuccessful users and as zero for random users. The contribution is varied from 3 to 17 for random and promised successful users and 2 for all promised unsuccessful users. The incentives and status updates are determined for the users based on their AR, PT, and CT.
The incentive and the status are determined based on Eq. (4) for the random contributors, based on Eq. (5) for the promised successful contributors and based on Eq. (3.3) for the promised unsuccessful contributors. Figure 3 presents the incentives received by the users. As represented in the figure, the promised successful users receive more incentives than unsuccessful and random users. For successful users, the incentives are increasing as their contribution time increases. When comparing the incentives of random users and incentives of promised unsuccessful users, random users receive more incentives than promised unsuccessful users. As the contribution time is increasing, the incentives are increasing for random users whereas for promised unsuccessful users as the contribution time increases their incentives decreases. Figure 4 unfolds the status updates of promised successful users and promised unsuccessful users. Random users will not receive any status updates according to the model.
Comparison of the incentives of the users with different values of contribution time.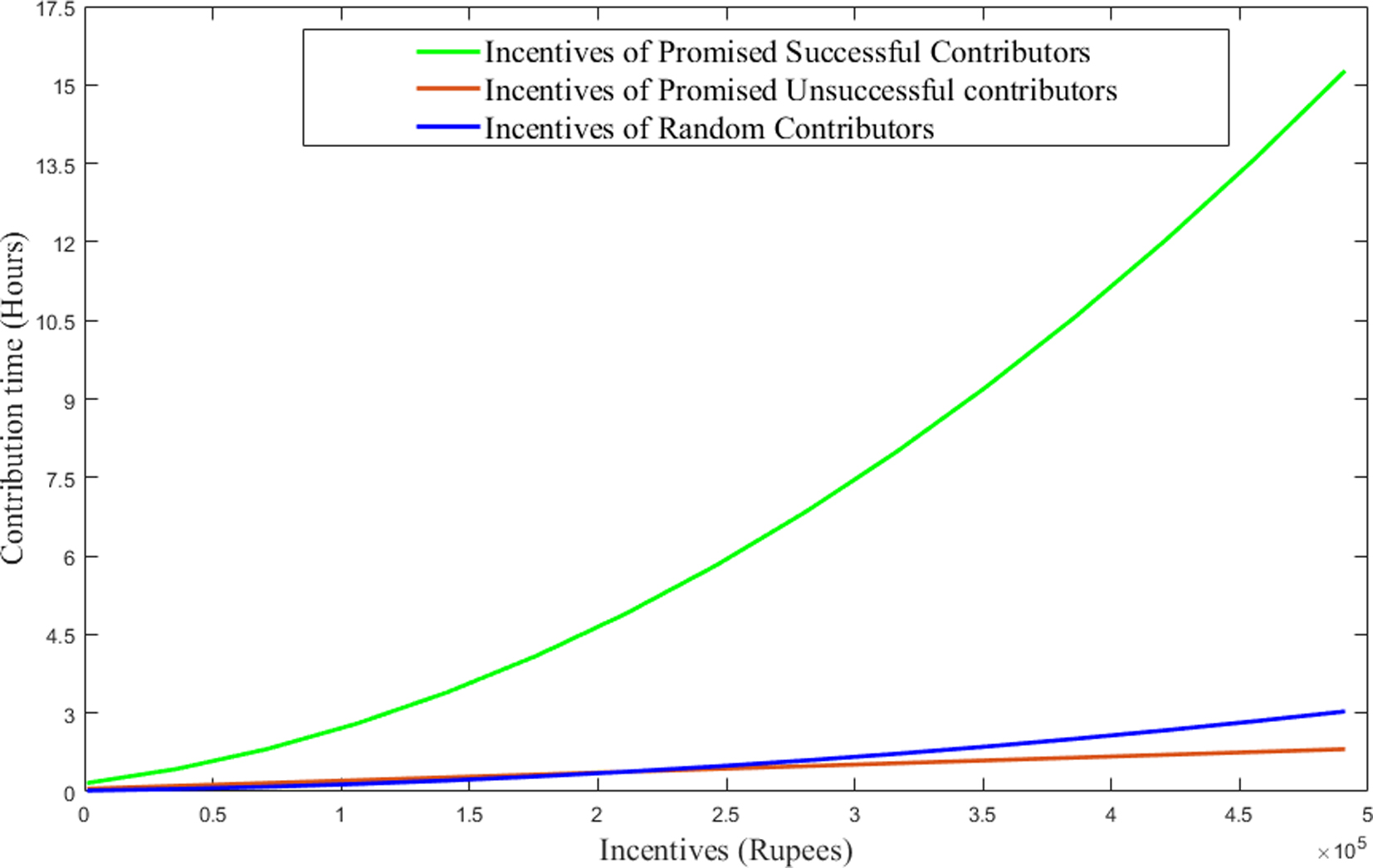
Comparison of status updates of the users with different values of promised time.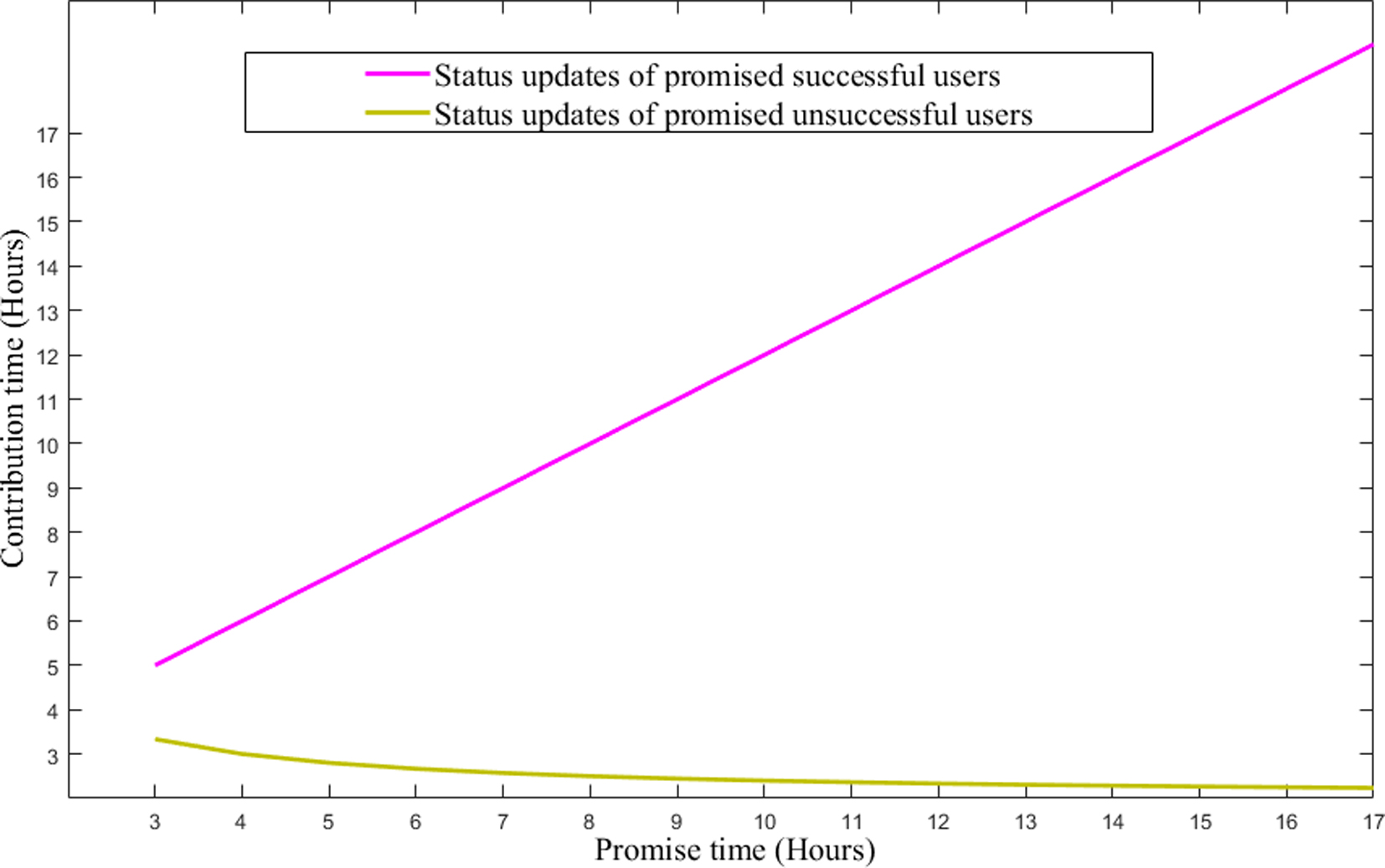
The status updates of successful users increase as the promised time and the contribution time is increased. For promised unsuccessful users the status decreases as the promised time increases. As the users promised time is increasing, the contribution time remains the same and their status decreases. Moreover, it is better to contribute in a random way rather than failing to maintain the committed promised time. Failing to maintain the committed promised time will decrease the status of contributors and cloud vendors will not have confidence in the availability of the fog resources to provide sustainable fog services.
The evaluation of the Incentive mechanism was simulated using a java and was implemented based on experimenting the cloud vendor utility and demand values. The cloud vendors can better control the impact of the number of participants to not to influence their utility. The main aim of the cloud vendor is to reduce the pressure on the central cloud data centers. The cloud vendor benefits are the profit they receive from the utilization of the fog centers that are set up with the help of the resource funding from the users. Based on the resource requirements of the particular location, cloud vendors can vary the demand D. The cloud vendors have to increase the value of D in locations where the resource requirement increases and should decrease the value of D in locations where the resource requirements decrease. The cloud vendors can manage their utility to stable by oscillating the demand value.
The impact of incentive I on demand D
The experiment shows the impact of various parameters on Incentive I and the cloud vendor utility CVU. In order to gain insights about the incentive on various demands D, the Range of D is uniformly distributed from 50 to 100, increasing at the rate of 10. The unit value is set for Unit cost UC, and Promised time PT, whereas the amount of resources AR is set as 10. Figure 5 shows the impact of Incentive I on various ranges of values of D. Incentive I, increases linearly as the demand D increases.
The impact of cloud vendor utility CVU on the number of contributors n and demand D
It is observed that the cloud vendor utility decreases linearly as the number of contributors and demand increases as shown in Fig. 6. To observe the effect of CVU on n and D, the other parameters are set constant. If the demand D increases uniformly, it attracts more number of contributors to contribute their resources.
Impact of Incentive I on Demand D.
Impact of Cloud Vendor Utility CVU on Demand D.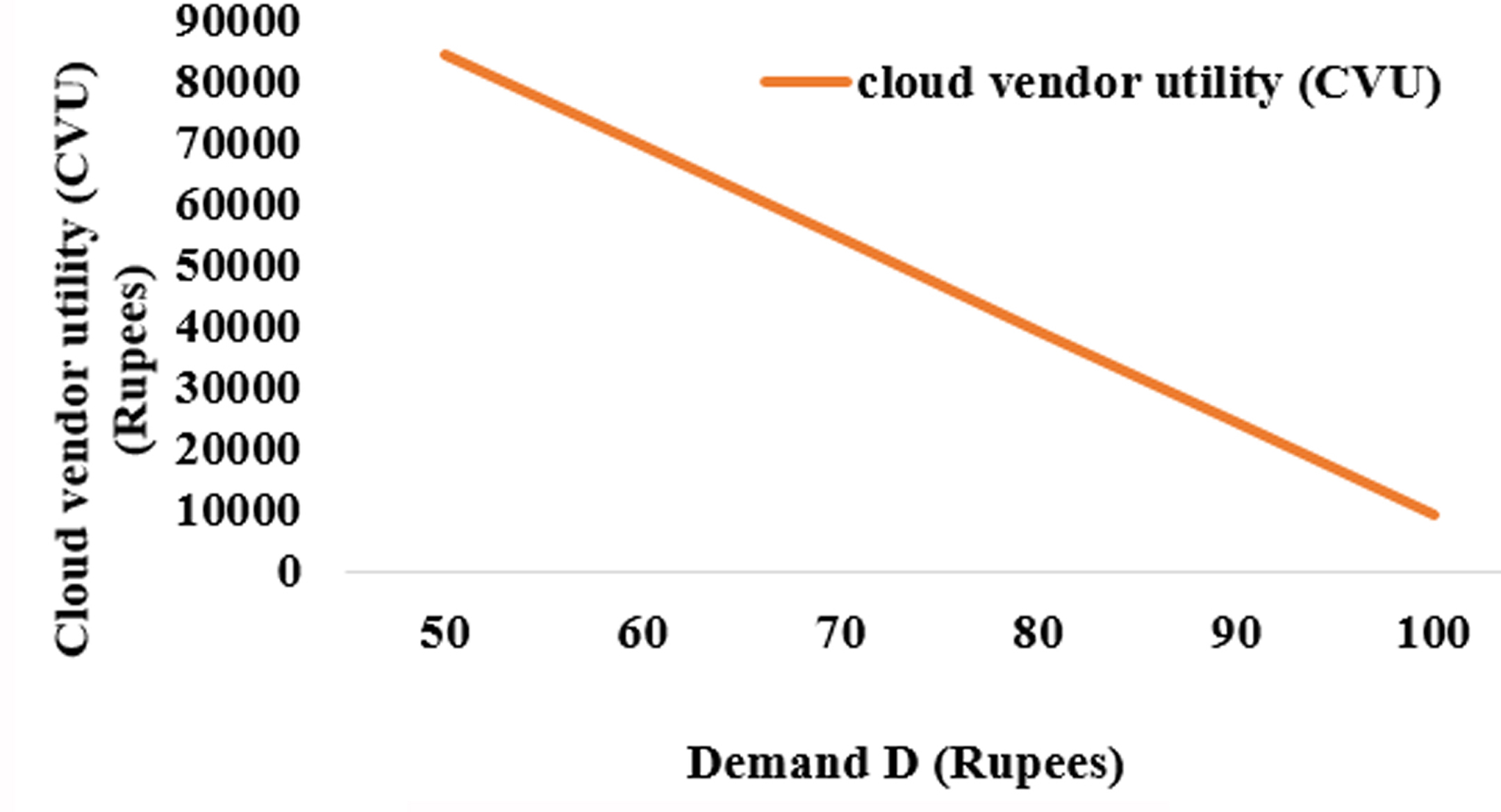
From Fig. 7, it is observed that the cloud vendor utility decreases as the number of participants increase when the value of demand D is set constant. The other parameters such as the amount of resources AR, unit cost UC and, the promised time PT are set as constant. From the results, it is observed that, as the number of contributors increase, the cloud vendor utility decreases, with the demand set as constant. When the number of contributors increases, the demand must be decreased, in order to maintain stable utility for the cloud vendors.
Impact of cloud vendor utility on number of contributors.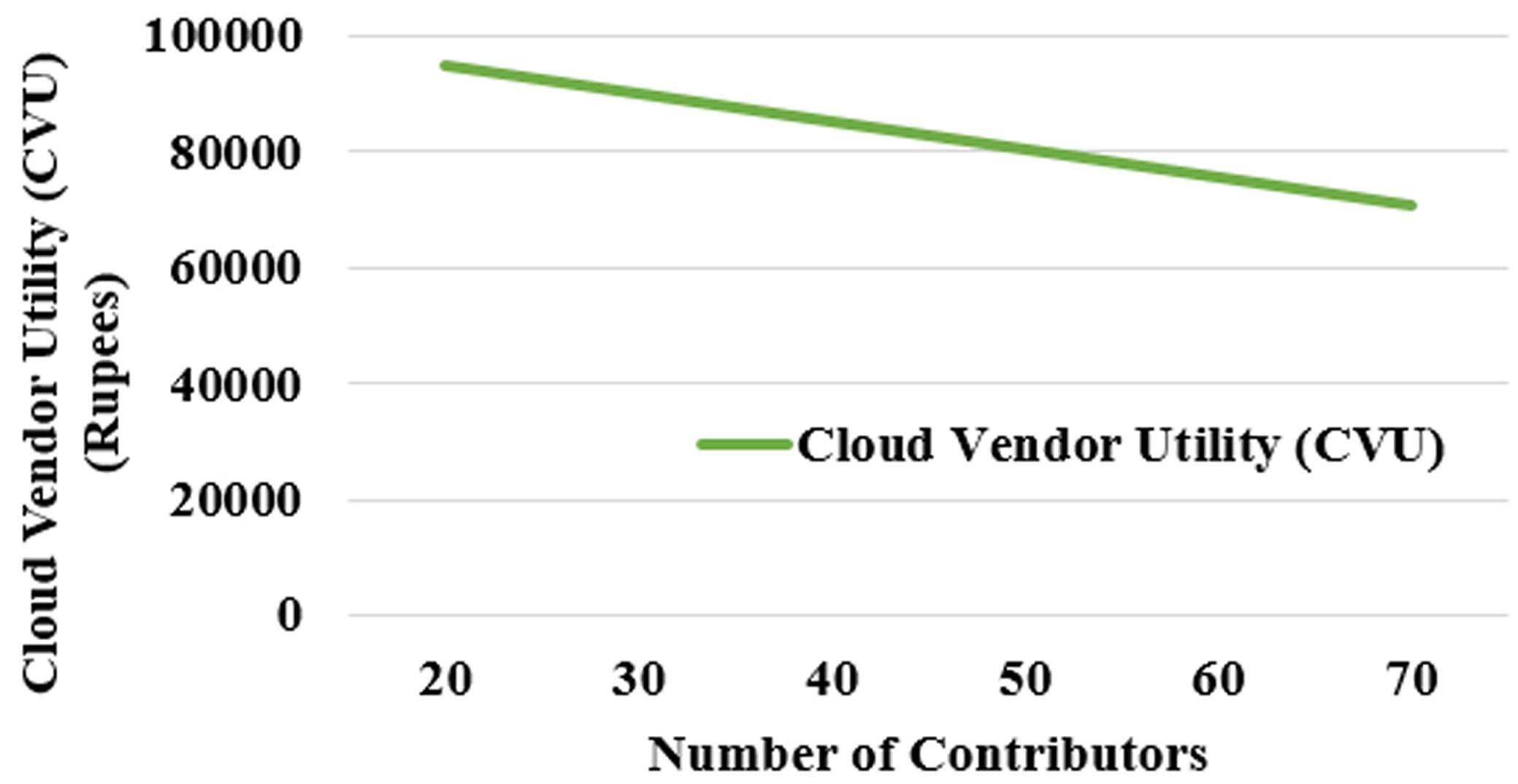
Figure 8 shows the effect of cloud vendor utility CVU on the number of contributors. The demand is decreased as the contributor count increased, in order to make the cloud vendor utility positive.
Impact of cloud vendor utility on a number of contributors with reducing demand.
Cloud vendors can handle the number of contributors at any time by oscillating the demand D. The demand D plays a vital role in contributions from the users. In order to attract more contributors in locations where the resource requirements are high, the demand D is set high at such locations. The demand D influences the cloud vendor utility as well. Cloud vendors cannot selfishly increase their utility by setting the demand low, as the contributions number will fall down when the demand is set low. The resource contributions become useless when the duration of the contribution is small. To attract contributors to set promised time as high, status S is introduced. In addition to incentives provided, status S is also maintained for the contributors based on the period of contribution.
To evaluate the performance of the demand-based incentive mechanism, the value of demand, amount of resources, the unit cost of the resources are considered as constant. The contribution time is varied from 1 to 10, for 10 to 100 users increasing at the rate of 10. The performance of the demand-based incentive model is compared to existing Repeated-game theory based incentive model. The repeated game theory was modeled based on Eq. (7) to determine an incentive for the contributor.
Where U
The incentives that the platform provides for the contributors in repeated game theory are very much higher when compared with demand-based incentive model. The incentives were determined based on incrementing the contribution time and the number of users. The incentives of the demand-based model is linearly increasing with the number of users and the contribution time whereas, the incentive values of the repeated game theory grows drastically with the number of users and contribution time, as shown in Fig. 9. For the same amount of resources and the users, the incentive that the demand-based model provides for the contributors are less when compared to repeated game theory.
Comparison of Incentives received by contributors with different contribution time.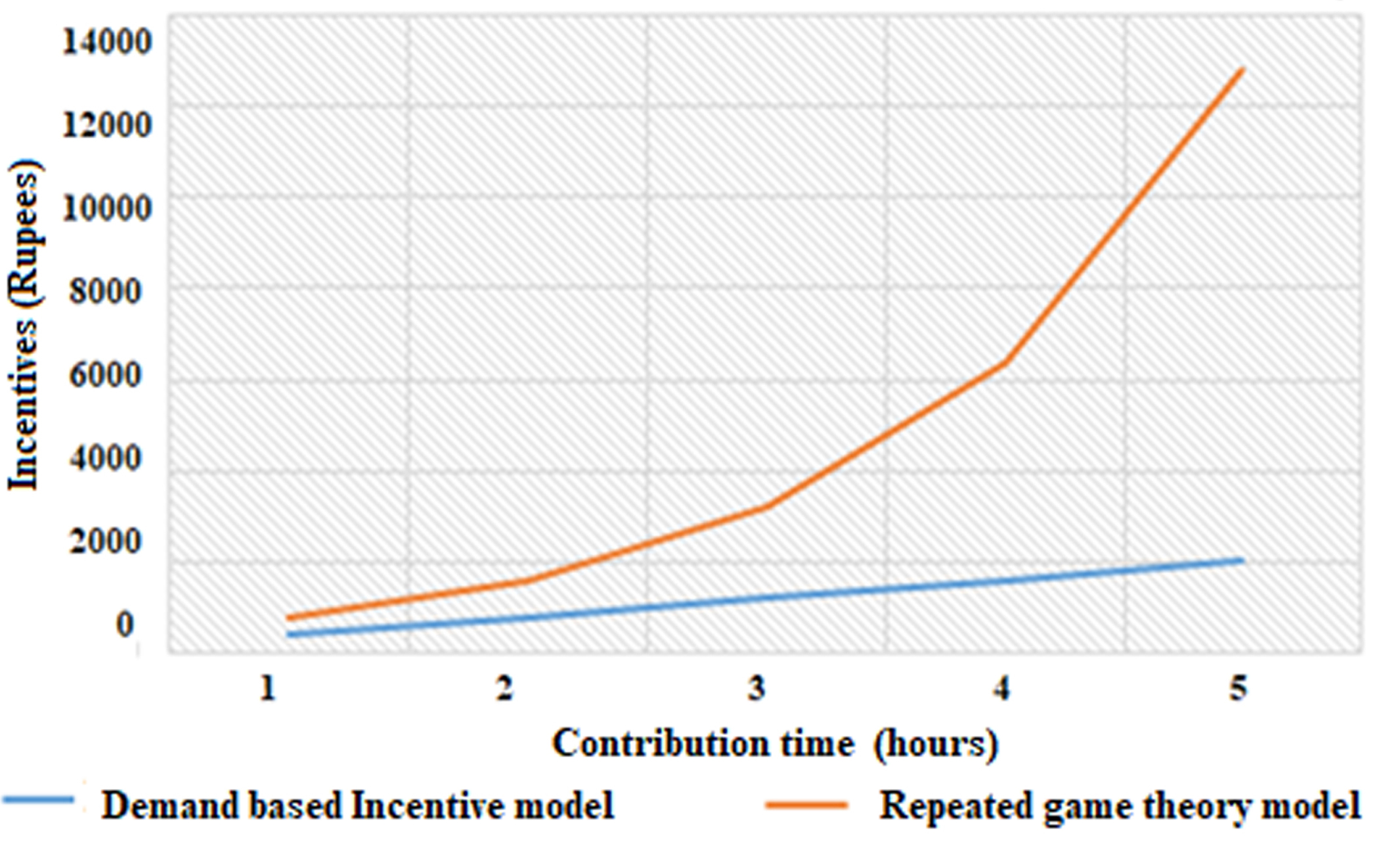
Comparison of platform utility received by both models with different contribution time.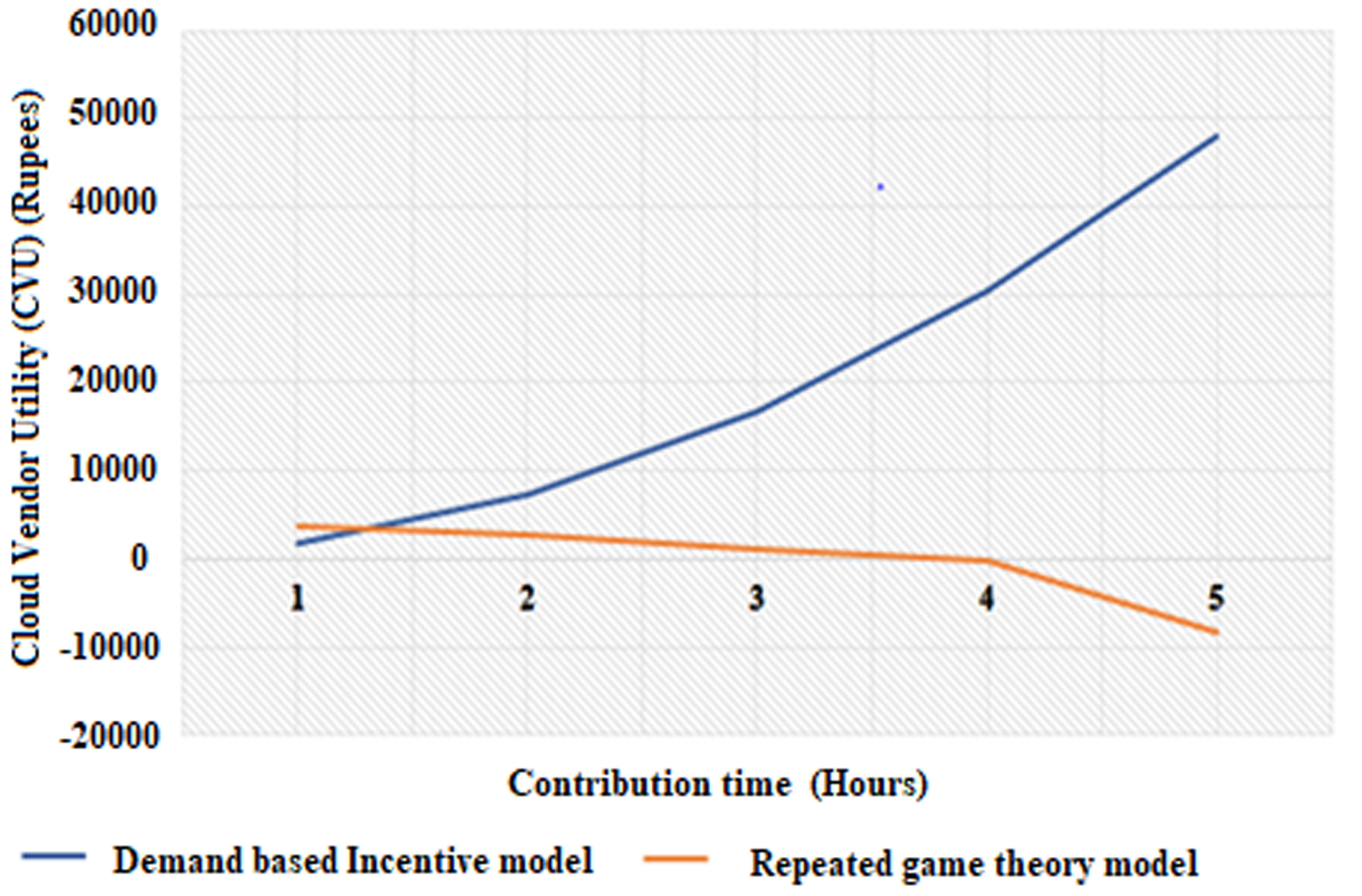
The proposed model considers various values such as demand, contribution time and utility, hence the incentives are linearly increasing and lesser when compared to repeated game theory. In contrast, repeated game theory considers the patience of the participants in the game. Hence, the incentives that the contributors receive are higher than the demand based incentive model. The platform utility of demand based incentive model is linearly increased as the number of users and the contribution time is increasing, in contrast, the platform utility of the repeated game theory is drastically decreasing as the number of users and the number of contributions is increasing as shown in Fig. 10. The platform utility is the benefit that the crowdsourcer gets from the resource contributions. Based on the comparison it is perceived that the demand based incentive model is better than the repeated game theory. The repeated game theory focuses on the patience of the participants staying in the game, whereas it fails to consider the platform utility and the demand of the location. The repeated game theory will suffer from overwhelming resource contribution, as it does not consider the requirement of the location. The demand-based incentive model can withstand overwhelming resource contributions by fluctuating demand and encourage users to contribute the resources at the required locations. The proposed demand based incentive model can mutually benefit the platform as well as the participants.
A Cloud Simulation Environment is used for evaluating the performance of the fog computing with cloud computing. CloudSim toolkit version 3.0.3 is used for evaluation [6]. CloudSim package is installed on HP DESKTOP-QLLNA01 intel corei3 processor, that has 1 TB storage capacity and 4 GB RAM with Windows 10 Operating system. Apache commons-math is imported into the CloudSim package. Using CloudSim, various performance metrics can be evaluated such as total time taken for the task processing, the total bandwidth consumption, total heat dissipated, total CPU utilization, total power consumption, total cost and so on. CloudSim acts as a toolkit that can be extended for various research level experimentation where real cloud implementation is not feasible in many cases [5]. For the purpose of evaluating the fog computing performance with the cloud computing, fog datacenter and cloud datacenter are configured in the simulation environment. The cloud-based data center has 5 hosts with each host having 1000 MIPS core, 2 GB RAM and 1 Terabyte of storage. The task is distributed among 40 VMS which has 1 CPU core, 256 MB of RAM and storage of 1 GB. The fog based data centers are set with a data center having 5 hosts with each host having the same configuration as the cloud-based data center. In the cloud-based datacenter, the processing elements are costlier and have high capacity whereas in fog based datacenter the processing elements are cheaper and have less capacity. In cloud-based datacenter the computational cost per second is set as 0.5, cost per memory as 0.6, cost per storage as 1.5 and cost per bandwidth as 0.5. In the fog based datacenter, the computational cost per second is set as 0.05, cost per memory is set as 0.02, cost per storage as 0.05 and cost per bandwidth as 0.5. For evaluating performance, four performance metrics are chosen such as total time taken for task processing, the total cost of the task processing, the total bandwidth consumed and the total power consumed.
Performance metrics such as total time, total cost, total bandwidth, and total power dissipated are evaluated to determine the effectiveness of fog computing. The comparison of total time taken for task processing in cloud and fog computing is shown in Fig. 11. The results show that the total time required for task processing in the cloud is comparatively lesser than the time required in fog. The total time is the time taken from the task input to the result produced. Though fog lies closer to the users, the fog has less powerful resources than cloud and hence, the processing time of cloud is lesser. In the simulation carried out in CloudSim, the same number of the tasks is submitted to fog as well as cloud whereas, in real time fog computing encounters a lesser number of a task than cloud. The task from the only particular geographical location is submitted to fog whereas the task from all the geographical location is submitted to the cloud. Figure 11 gives the comparative analysis of the total time taken for the task to get processed in fog and cloud. The task submitted to the cloud has completed its processing faster than the fog.
The total cost required for the task processing in fog and cloud is evaluated and the comparative analysis showing the total cost requirements is shown in Fig. 12. The total cost is evaluated in both fog and cloud with various number of task inputs. It is evident from the results that the task processing in cloud computing incurs more cost than fog.
The total processing cost depends on bandwidth requirement, cost and file length of the input task and computational cost. As fog computing consumes lesser bandwidth and the computational cost than cloud, the total cost required for task processing in fog is lesser than cloud computing.
Time taken for task processing in cloud and fog environment.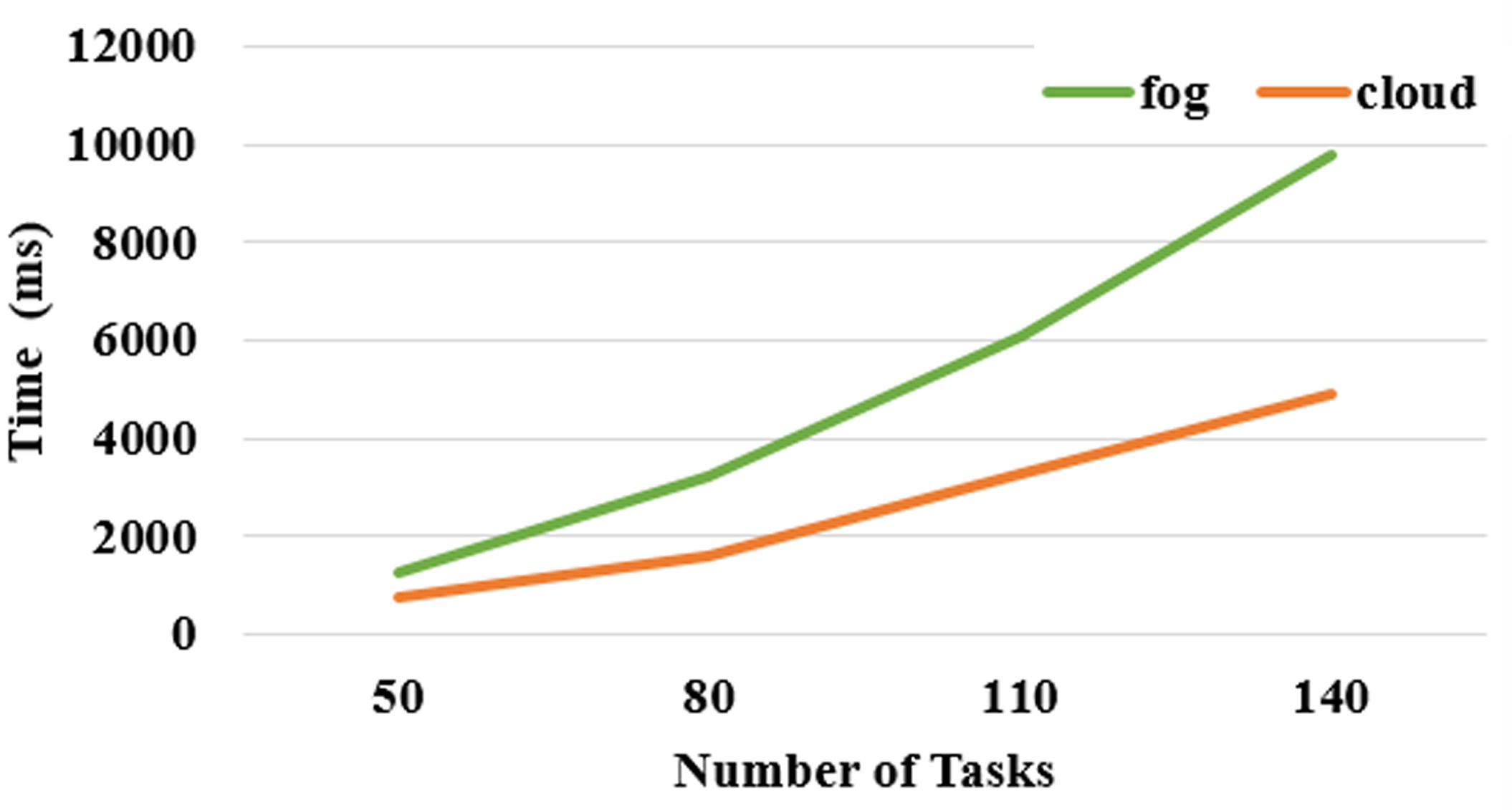
Cost incurred for task processing in cloud and fog environment.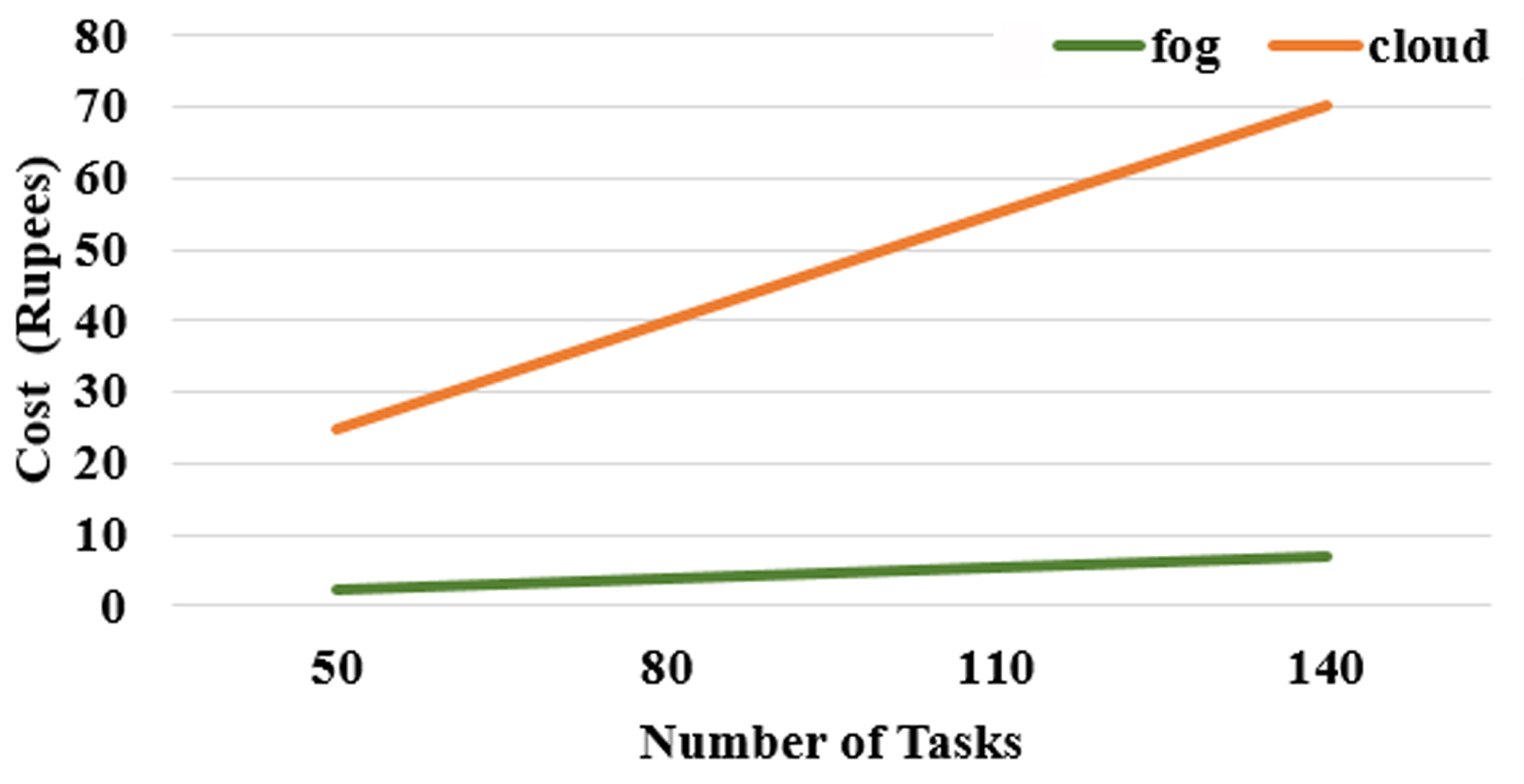
Bandwidth consumed for task processing in cloud and fog environment.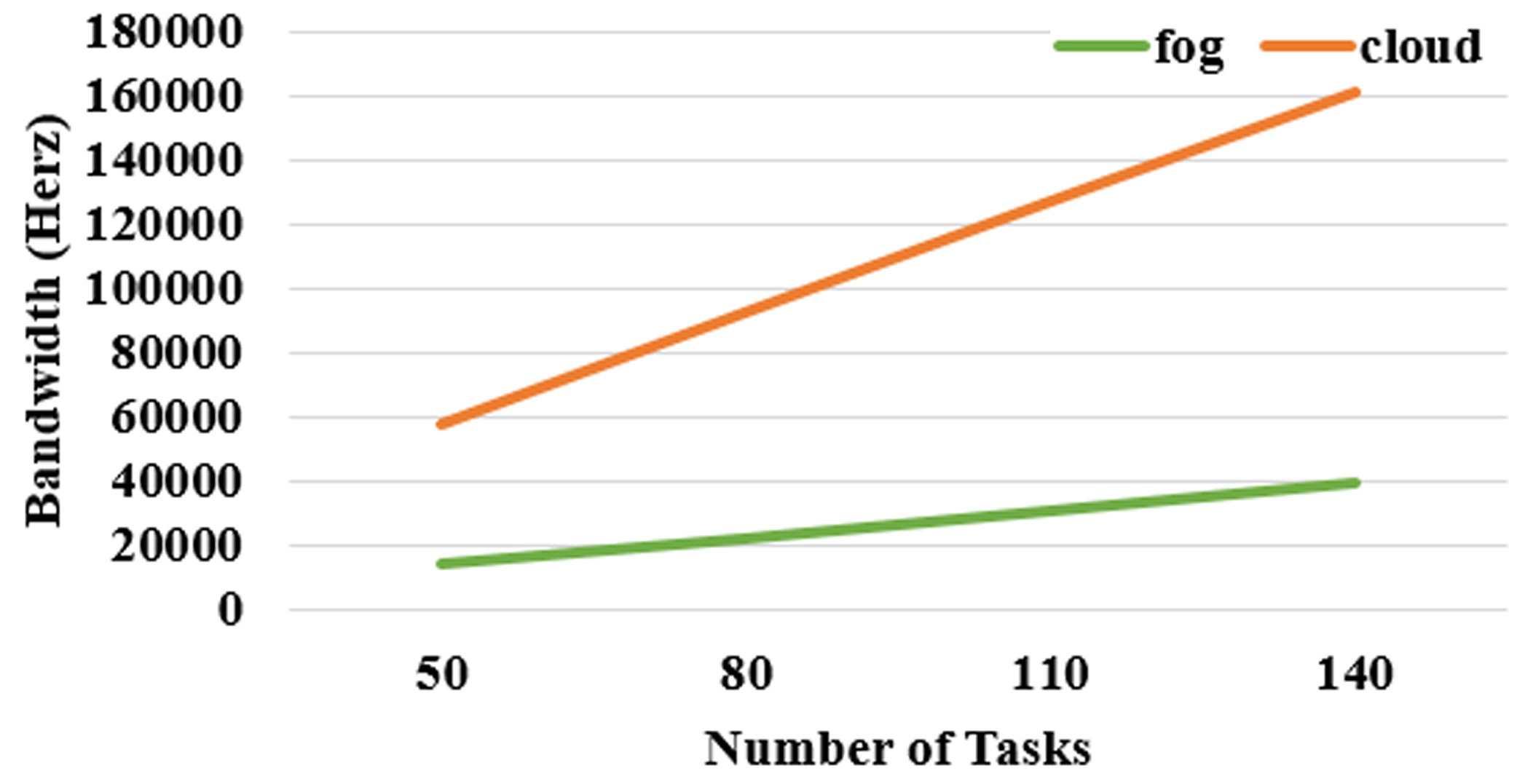
The total bandwidth consumed in fog and cloud computing is evaluated for varying number of task inputs. The comparative results are shown in Fig. 13. It is evident that the bandwidth consumption is higher for cloud compared to fog as fog requires lesser bandwidth than the task to reach the cloud datacenters.
Power consumed for task processing in cloud and fog environment.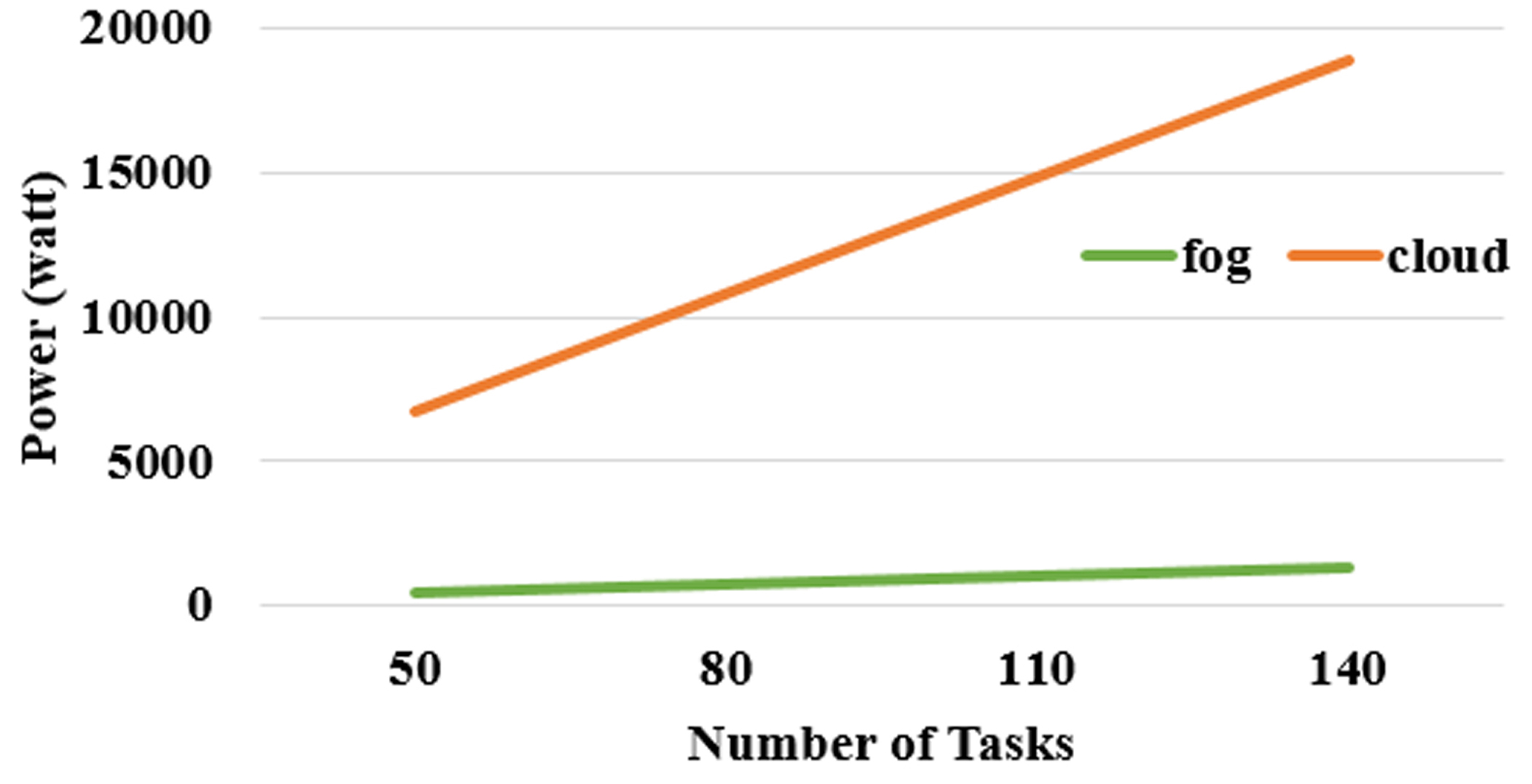
The comparison of the total power consumed by the fog and cloud is shown in the Fig. 14. It is very clear that the power consumption in accessing the cloud resources is higher compared to fog. The total power is the power required for task processing in cloud and fog. Fog computing processes the task in the edge of the networks and hence the edge resources consume lesser power than the central datacenters. In addition, in the central datacenters cooling system is required to cool the huge servers in order to reduce the heat produced by the huge servers whereas, in the fog data center, the cooling system is not required. Hence, the power consumed by the cloud data centers is higher than the fog datacenters.
In this study, a basic model of resource provisioning to fog computing using demand-based incentive mechanism is proposed. The study emphasizes, the requirement based resource provisioning in setting up the fog centers. In using crowdsourcing-based resource funding, the availability of the resources for fog processing is defined with the promised time. The utility of the users is modeled to increase based on the quality of their funding. The quality factor including the period of their contribution, amount of resources they fund, and the term demand that influences their incentive is the greater impact. The demand acts as a deciding factor for contributors, and similarly, it acts as the control factor to manage the resource contribution for cloud vendors. As a future extension, the security issues related to processing the content in the fog resources will be focused.
Footnotes
Authors’ Bios