
Abstract
With big data, the volume of the manipulated data is rapidly growing, we find several business sectors contributing to this expansion such as: (i) the social networks, (ii) the use of the sensors, (iii) the commercial transactions. To integrate this actual reality, the management of small, medium, large business sectors needs analytical applications, such as scalable data warehouse, to answer effectively big and interacted queries. This interaction is exploited in the phase of the physical design of data warehouse using optimizations structure such as the materialized view. Selecting an appropriate set of views to materialize under some resource constraints is known as view selection problem (VSP). In this paper, we propose an approach to solve VSP by profiting the world of multi-query optimization in order to generate the global execution plan integrating new dimensions Big and Interacted Queries, to ensure scalability, we use the clustering technique K-means and operations of refinement in order to capture volume of interacted queries without passing by enumeration of all logical plans of the queries and we use our plan to materialize views. Finally, experiments are conducted to show the scalability of our approach.
Introduction
Big data concern every business and every life on the planet in regard to the huge amount of generated data on different social network platforms, the deployment of different kinds of sensors and the explosion of the usage of the Internet. According to a report of IBM in 2018, every minute there are 72 hours of footage uploaded on YouTube, 216.000 Instagram posts and 204.000.000 emails sent. In addition, the rate of global Internet traffic is estimated at 50.000 GB per second. With this data volume, the business leaders have to analyze it in order to make decisions. Thus, it is necessary to develop new analytical applications that answer the new needs of scalability. Among existing analytical applications, we are interested in the development of scalable data warehouse (DW). The scalability of data warehouse is possible through query optimization and physical design, in order to quickly and effectively answer high and a complex number of Online Analytical Processing (OLAP) queries known as “big queries phenomenon” [30]. This phenomenon considers the repetitive nature of the queries, which are in “big interaction” by sharing several algebraic operations such as the join operation, the aggregation, etc. This interaction is due to the modeling data warehouse in a star schema, or its variants, which need systematically queries, passing by the fact table to run the operations of joins. The interaction is exploited in the phase of the physical design of the data warehouse by the database administrator in order to optimize the whole of these queries using the optimization structures such as the materialized view.
A materialized view is one of the techniques of redundant structure optimization which minimizes the queries response time. It consists of pre-computing the most expensive operations, like the joins and aggregations, and storing their results in the database [1]. These queries are effectively processed using the data stored in views without needing to reach the original data. The database administrator cannot materialize all the possible views, although they improve the performances of the queries as they generate the following problems: (i) the base tables of the data warehouse change and evolve through updates that impose that these changes must be deferred in the materialized view, (ii) we must rewrite the queries according to these views [26] which is a difficult task because we must find a better rewriting equivalent of the original query, (iii) and the storage of all these views requires a bigger disk space. The problem that arises is to select the most beneficial view to materialize in order to minimize the cost of total execution of the workload by respecting some constraints, such as the storage and the maintenance cost. This problem is known as “the View Selection Problem (VSP)”.
VSP can be formalized as follows: a workload of queries given
In order to deal with these weaknesses, some works were based on the interaction of queries [7, 15]. The concept of the interaction of queries was already identified by Timos Sellis, who gives rise to another problem known as “Multi-Query Optimization (MQO)” which consists in optimizing the total performance of the workload by generation a global execution plan [4]. Getting this plan is NP-hard problem, the work of Yang et al. [7], was the first which has to merge between the generation of this plan and the selection of materialized views. The main problem with these works their scalability as they do not take into account the Big Queries phenomenon, in particular: volume data, query volume and the big interaction between queries. Traditional VSP methods should, therefore, integrate new aspects to deal with these big queries issues. To the best of our knowledge, only Boukorca et al. work which proposed a scalable solution by borrowing a graph partitioning tool used in the electronic design automation domain [24]. However, this tool suffers from data preprocessing cost and it does not ensure any dynamicity.
In this study, we focus on a data mining technique, especially the clustering method K-means which allows scalability by handling an extremely large database, currently is implemented on Hadoop MapReduce framework [5]. K-means exploits the workload (i.e., big queries) to get the interaction between queries. We propose grouping initially these queries which are similar according to the most expensive operator who is the join operator, into clusters. To maximize this interaction, we apply the operations of refinement which reduces the number of the resulting clusters by k-means. This method consists in using an intra-cluster function which merges the clusters that share join operators to increase the reuse of these operators. K-means and the intra-cluster function are used to model the big interaction between queries without passing by the logical plans of each query in order to generate the global plan execution who guides us to select views to be materialized.
The paper is organized as follows: Section 2 presents the related work. In Section 3, we explain our contribution by modeling the interaction of the queries in order to select the views to be materialized. Section 4 presents our results to select materialized views. Finally, we conclude the paper by discussing the obtained results.
Literature review
Several works were developed to solve view selection problem in several contexts, such as the semantic databases [19, 20], the distributed database [21] and the physical design of data warehouse for optimizing queries OLAP [7]. In the paper of Mani and Bellahsene [3] have provided a classification of VSP studies, with the following dimensions:
According to the dimension without or with constraints, the first studies on VSP assume the absence of constraints [7, 8]. The first problem in these works may be that the storage of selected views takes more than the available space, so storage space the main constraint that the selection process has integrated [29]. The second problem, if updated in the base tables, selected views must be updated, then, the maintenance cost becomes an important constraint [1].
In the studies that flow non-functional requirements dimension, selected views must satisfy certain objectives, such as the minimization of query response time [9], maintenance cost [1], the satisfaction of the energy consumption [10]. These objectives can be combined to give rise to a multi-objective formalization of the VSP as in [7] where response time and maintenance cost were considered.
In the dimension algorithm of resolution, simple and advanced algorithms are proposed to solve VSP, such as the deterministic algorithms [2, 9, 22], randomized algorithms [18, 23, 26, 27], evolutionary algorithms [28, 29], hybrid algorithms [7, 17].
In the dimension nature of the selection the views, static approach suppose that the workload of the queries is fixed [7, 11, 24] and dynamic approach is applied when a query arrives consequently the workload is built incrementally and changes over time [12, 13, 14].
Each work on VSP combines one or more dimensions presented above. In this paper, we review studies on VSP by multi-query optimization (MQO) dimension. Most of these studies consist of detecting the common sub-expressions between the queries of the workload by the fusion of their execution plans into a single global plan. This plan is used as a data structure for the view selection problem, the most used data structures in literature are:
AND/OR graph data structure is a directed acyclic graph (DAG) which represents the union of all possible execution plans of each query, this plan has been defined by Roy et al. [16], it is composed of two types of nodes: operation (selection, join, projection, etc.), and equivalence nodes. In the work of Gupta [22], the authors used this AND-OR data structure, to develop a theoretical framework for VSP under the storage space constraint, they proposed a greedy algorithm, which each iteration selects the view having the maximal benefit per unit of space, the execution time of this algorithm is O(In2) where I, it is the number of iterations and
In the work of Lee and Hammer [23], the authors used OR DAG for VSP under the maintenance cost constraint, each node in the graph represents a view, the genetic algorithm was applied such as the chromosome represents the set of the views to be materialized, it is coded in a string format
Data Cube Lattice data structure is a plan used in the context of multi-dimensional data warehousing, which the nodes represent the views that contain operations of grouping, and edges define the relation between the views. Harinarayan et al. [2] proposed an algorithm greedy, which uses this Data Cube lattice, with the storage constraint, the authors showed that their algorithm presents performances very close to the optimal. However, it traverses the space of solution possible with a high level of granularity and can possibly leave an escape of a good solution. In the work [26] found in their implementation of the algorithm the Harinarayan et al. [2], it ran for over six hours in order to select a set of views that fit in 1% of the data cube space for a flat fact table with 14 dimensions, it is not effective for numerous dimensions. The authors adapted the randomized search methods for the VSP by respecting the storage constraint and maintenance cost, they proposed transformation rules that help the algorithms move through the search space of valid view selections, in order to identify sets of views that minimize the query cost. Their experiments of the randomized algorithms have provided solutions very close to the optimal in a limited time comparing with the work [2]. We note that the found results depend on the transformation rules suggested.
Multi-View Processing Plan (MVPP) data structure is a directed acyclic graph in which root nodes represent the queries, the leaf nodes are the base tables, and the intermediate nodes are an algebraic operator such as selection, join, projection, etc. In this paper, we intend to use MVPP. This data structure has been described by Yang et al. [7], the authors proposed two algorithms for constructing this MVPP. The first algorithm proposed called “A feasible Solution”, which starts with the identification of the optimal plans for each query and after that order them according to the frequency of query multiply by the query processing cost. Once the order of the optimal plans is fixed, the algorithm takes the first optimal plan and merges it with the second by using the common sub-expressions, then, the first two plans with the third, and so on. This procedure will be repeated until all the plans are considered. For each generated MVPP, they push down the unary operators (selection and projection) as far as possible in MVPP and applied the algorithm of selection of the view to be materialized according to the maintenance cost constraint to each MVPP and calculated its cost. The algorithm chooses the MVPP which has the optimal combination between the maintenance cost of the views and query processing cost. This algorithm is very expensive in terms of calculation and does not guarantee the optimal MVPP. In order to overcome the limitations of the previous algorithm a second algorithm was proposed based on 0–1 integer programming, determined by the following steps [7]:
Generate for each query qi all the join plans possible To identify all sub-trees join possible for each generated plan Build usage matrix A, where the coefficient Build usage matrix B, where the coefficient
Finally, the problem of selection of optimal MVPP is reduced to the selection of a set of plans
where
Most works developed to study the impact of Multi-View Processing Plan (MVPP) on solving VSP are based on the enumeration of all the logical plans of the queries to build an MVPP. These plans can be optimal or not, which return these works suffer from scalability. To overcome this problem, Boukorca et al proposed to use a hypergraph structure which groups the queries in several connected components [24]. Each component contains the queries which a high interaction, this approach of generating the MVPP occurs by the following stages:
Constructing the hypergraph of joins: in the graph theory, a hypergraph H is a set of vertices V and a set of hyperedges E. In their case, a hypergraph H is a set of V which represents the set of the join nodes and E represent the workload of query Q. A hyperedge Partitioning the hypergraph: the authors adapted an existing algorithm resulting from the graph theory HMETIS to divide a hypergraph into Transforming of a hypergraph into directed graph MVPP: it consists of finding an order between the join nodes in each small hypergraph, for that, they used three algorithms: the first allows to find the pivot node which corresponds to the first operation of join in MVPP. The second algorithm describes the steps to be followed to transform a hypergraph into MVPP by using the pivot node of maximum benefit. The third algorithm allows splitting a hypergraph into two hypergraphs following a pivot node. The first hypergraph contains the hyperedges which use the pivot, and the second contains the other hyperedges. Finally, they selected the views to be materialized under the storage constraint and the maintenance cost for each component.
The experimental results show the effectiveness of this approach and its scalability on a large workload of queries to select materialized views. However, the authors used a graph partitioning tools, e.g. HMETIS which is known by its phase of data preprocessing to prepare the data a priori (hypergraph) in the form of the files to pass to the partitioning phase, therefore it suffers from preprocessing cost as was shown by the authors of work [6]. In addition, this approach does not ensure any dynamicity, for example, the resulting partitions are static, therefore, in the case of a change of the query workload, it is necessary to redo the phases of preprocessing and partitioning to find new partitions.
In order to generate the multi-view processing plan which will be used to select the views to be materialized, we propose an approach that follows the divide-conquer principle. We use K-means clustering and operations of refinement to divide the search space into disjoint subsets spaces which can be executed in parallel. We define similarity and dissimilarity measures in order to quickly find desirable clustering in only one execution of K-means. The objective is to ensure dynamicity by adapting to change of workload of the resulting clusters using these similarity and dissimilarity measures.
After the analysis of state-of-art studies on VSP in conjunction with the use multi-query optimization (MQO) dimension, we noted that these works are not scalable in terms the volume of queries processed, because they have based on the enumeration of all the logical plans of each query to build a Multi-View Processing Plan (MVPP), which makes the search space very large to find the best MVPP that will be used to select a suitable set of views to materialize, however, they cannot process the big queries phenomenon. Therefore, to ensure scalability in our approach we propose to build an MVPP without passing by the logical plans of each query in order to avoid having large search space, and to contribute in reducing the complexity of generating of this MVPP by integrating this big queries phenomenon, our approach follows the divide-conquer principle by dividing the search space into several small disjoint sub-spaces, which can be executed in parallel, knowing that each space contains the queries that have high interaction among them. To realize this scalability, we assume that all the joins of the workload have the same priority to be candidates in the first join of the global execution plan of this MVPP. There is no order between these joins of each query and, the MVPP results which determine the optimal execution plans of the queries.
We present every query in the workload by a set of sub-plan with a single join and two selection predicates, and then the union between these sets gives us sub-plan candidates possible to build our MVPP. The idea of the approach is to group the queries that are similar in the same cluster following the most expensive sub-plan with a single join, this motives us to use clustering K-means with similarity and dissimilarity measures proposed and intra-cluster function in dealing with large volume of interacted queries, then to find the MVPP associated to each cluster independently which will be used for VSP. We detail below, the stages of our approach illustrated in Fig. 1.
Multi-view processing plan (MVPP) generation approach.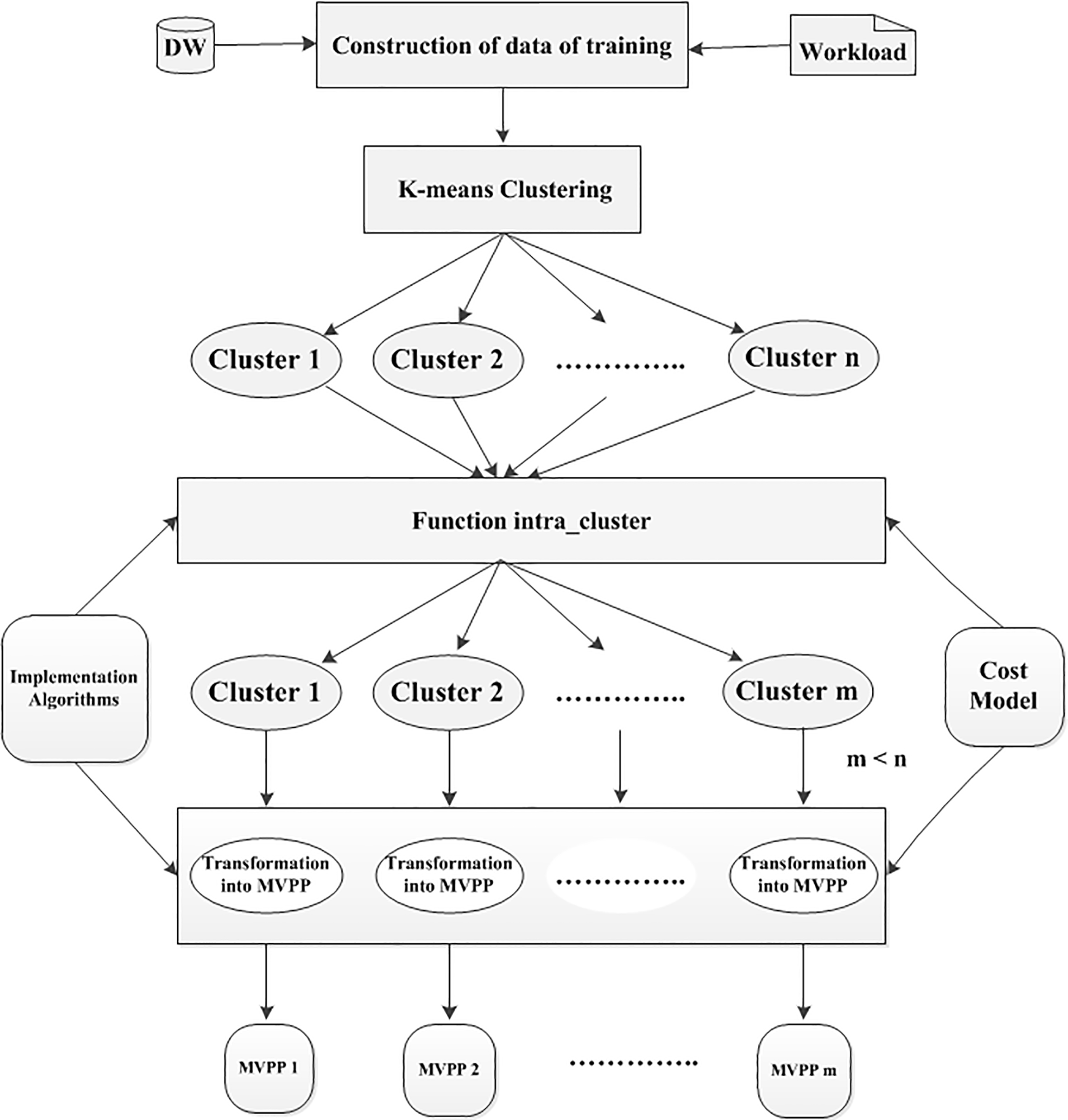
The first stage is query workload analysis in order to build the clustering context. The workload, we consider are set of SJP (Selection, Join, Projection) queries. Each SJP query is composed of the operator selection, join and projection. Firstly, we build all sub-plan with a single join and two selection operators, therefore we make the syntactic analysis of each query starting from his code SQL
From this knowledge on the workload of queries, we build the training dataset represented by a matrix QP where lines represent the queries
Example: Consider a workload of the 10 queries OLAP (Online Analytical Processing) generated from Star Schema Benchmark (SSB) [25] contains a fact table Lineorder, and four dimension tables: Customer, Supplier, Part, and Dates.
Sub-plans candidates possible for each query.
From these sub-plans, defined for each query, we obtain a set of sub-plans candidates
Training dataset
In this step, we first apply the algorithm K-means by using a training dataset above for partitioning the Big queries workload according to the set P. We group in the cluster the queries which are totally similar. Totally similar queries are queries having an identical binary representation in the matrix QP. For that, we define a similarity measure between two queries by the function sim (
We define the dissimilarity measure between two queries considering the set P by the following function diss(
For example, diss (
We apply clustering K-means with the similarity and dissimilarity measures proposed in the previous example. We initially obtain the following clusters:
In this stage, we apply an operation of refinement in order to reduce the numbers of the clusters initially found by K-means, which contain common sub-plans with a single join between them. There are interactions between these clusters that it is necessary to collect them in order to maximize the reuse of the sub-plans by the various queries. Therefore, we can merge these clusters according to a sub-plan, which is the most expensive and most used by the clusters, i.e., it groups a maximal number of queries, one it calls the score sub-plan. We use the following algorithm to find this score sub-plan S:
In Algorithm 1, we calculate for each sub-plan (
We apply Algorithm 2 to the example above, we obtain new clusters after the fusion of
Checking the independence between the clusters
At this level, we ensure that there is not a common sub-plan between the final clusters. When we find a cluster using a sub-plan already used by another cluster, this sub-plan will be duplicated by changing its identifier. For instance, if a cluster
Transformation of a cluster into a directed graph MVPP
The generation of MVPP at this step consists in the simple transformation of each cluster into a directed graph MVPP. We assume that the query of our workload is presented by a depth left tree and the first join in each query it is score sub-plan found. From these score sub-plans, we arrange the order of the sub-plans p in each cluster in descending order using the following formula:
The formula in Eq. (4) finds the sub-plans to give the best benefit possible in terms of the number of reuse of its result multiplied by its processing cost. Once this order between these sub-plans in each cluster is found, we represent each cluster by a directed graph MVPP by making an update at the node left of each sub-plan. In the case of conflict on even the sub-plan with two nodes left various this sub-plan will be duplicated.
We build the MVPP associated to the cluster
We propose an algorithm (Algorithm 3) which individually handles the clusters by selecting the views which have a maximum of benefit and satisfy the storage space constraint. In this way, the storage space is allocated to each cluster. All the selected views optimize the big queries workload. Algorithm 3 describes the steps of the selection process of the views which work in a cyclic way on the cluster as long as the storage constraint is satisfied. We identify for each cluster
Transformation steps of a cluster into a directed graph MVPP.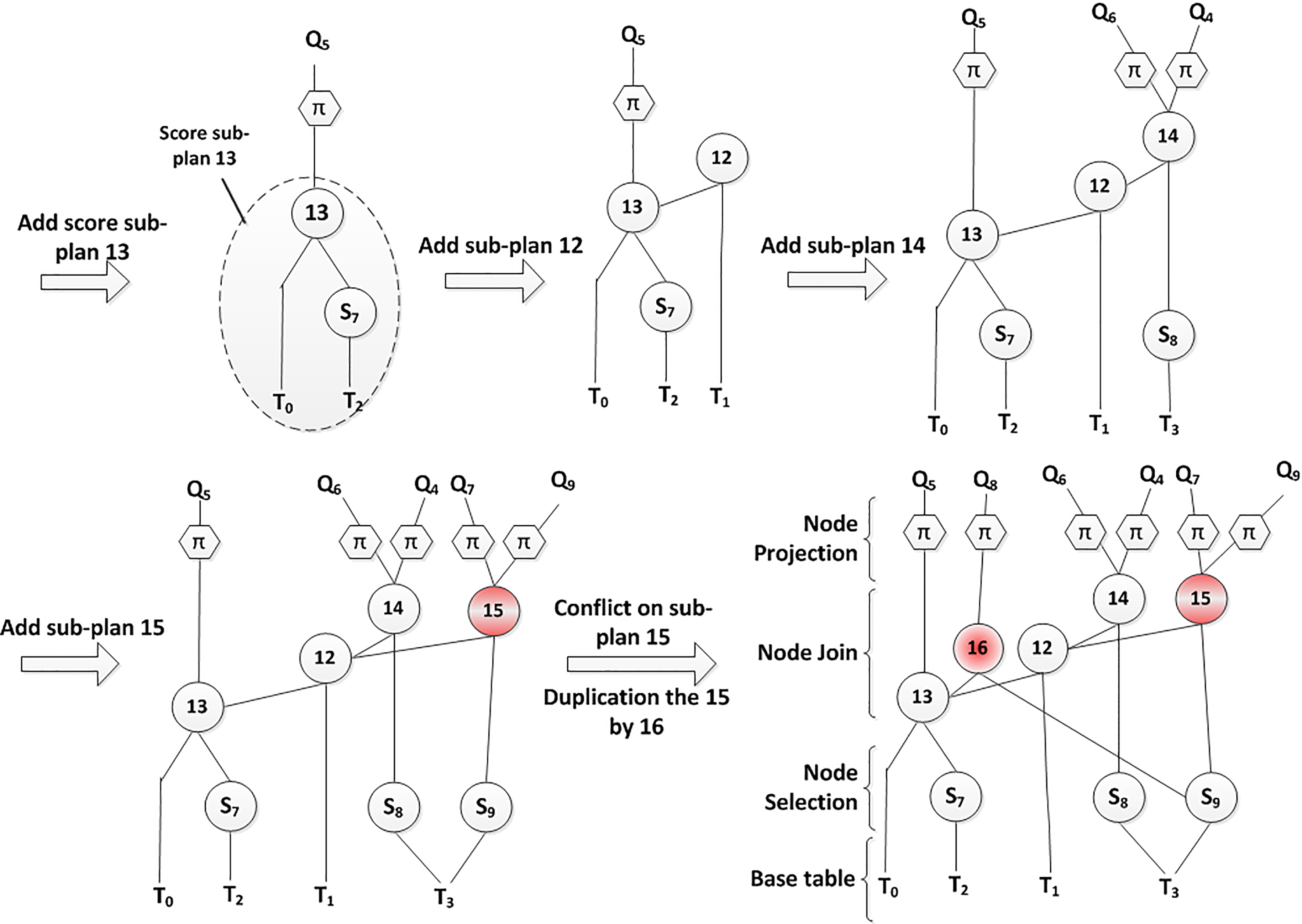
We developed a simulator tool in Java Environment that aims to extract all the knowledge on the workload (the sub-plan, selection, projection, and aggregation) and from this knowledge; it builds the training dataset. This data are stored in a CSV file. We imported package weka (weka.jar) [31] into our tool in order to implement K-means clustering using the methods and class offered by this package such as:
BuildClusterer(Data) method, which read training data from CSV file already prepared, in order to generate a clusterer. ClusterEvaluation(package weka.clusterers), class for evaluating clustering models, setNumClusters(int K) method: the variable K represents the number of the desired clusters, to determine its value we have programmed the similarity and dissimilarity measures to guarantee the best clustering in only one execution of K-means.
One the clusters have been found, the merger to these clusters which are in interaction according to score sub-plan with a single join is applied. After, our tool generates the MVPP adapted to every cluster following a function which maximizes the benefit of reuse of sub-plans by the queries. Finally, this tool includes the implementation of the algorithm of selection of the view and, we developed a cost model which estimates the cost of query processing in terms the number of Inputs/Outputs pages required for executing a given query. this cost model use database parameters (number of tuples of the relation, number the page on which the relation is stored, etc.) and parameters of the query (number of distinct values of the attribute, selectivity factor of the algebraic operator, etc.), to estimate the cardinality of intermediate results.
We used the dataset of the Star Schema Benchmark (SSB) to evaluate the approach [25], the size 1 G. This SSB data warehouse deployed in Oracle 11 g, it contains a fact table Lineorder of 600 millions of tuples, and four dimension tables: Customer, Supplier, Part and Dates as illustrated in Fig. 4. We used the dbgen tool provided by SSB to generate the dataset, once this set is generated, scripts are used to populate the tables using the SQL loader tool provided by Oracle.
SSB contains 13 decision support queries, we have generated randomly workloads of varying sizes 30 to 10000 from these queries proposed by SSB, using SSB generator query. Our queries cover most types of OLAP queries.
Star Schema Benchmark (SSB).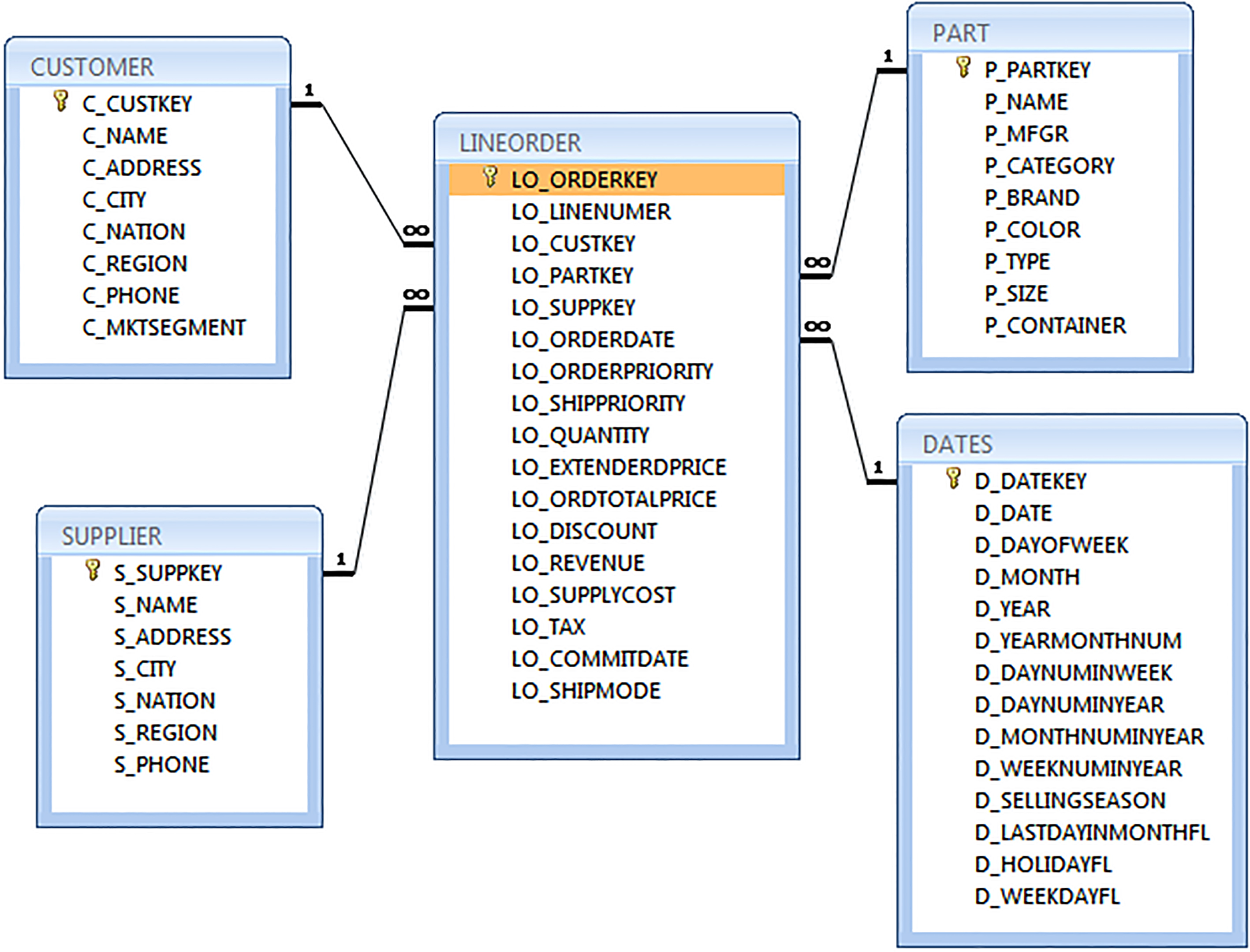
In the first experiment, we evaluated the required time to generate an MVPP compared to a classical approach of Yang et al. [7] and Boukorca et al. approach proved its scalability [24], In each test, we change the number of queries as input to evaluate each approach. Figure 5 summarizes the obtained results.
The results show that our approach is more effective in terms of execution time compared with the approach of Yang et al. which increases exponentially with the number of queries and it is the concurrent approach of Boukorca et al, which proves the scalability of our approach.
The execution time to generate multi-view processing plan (MVPP).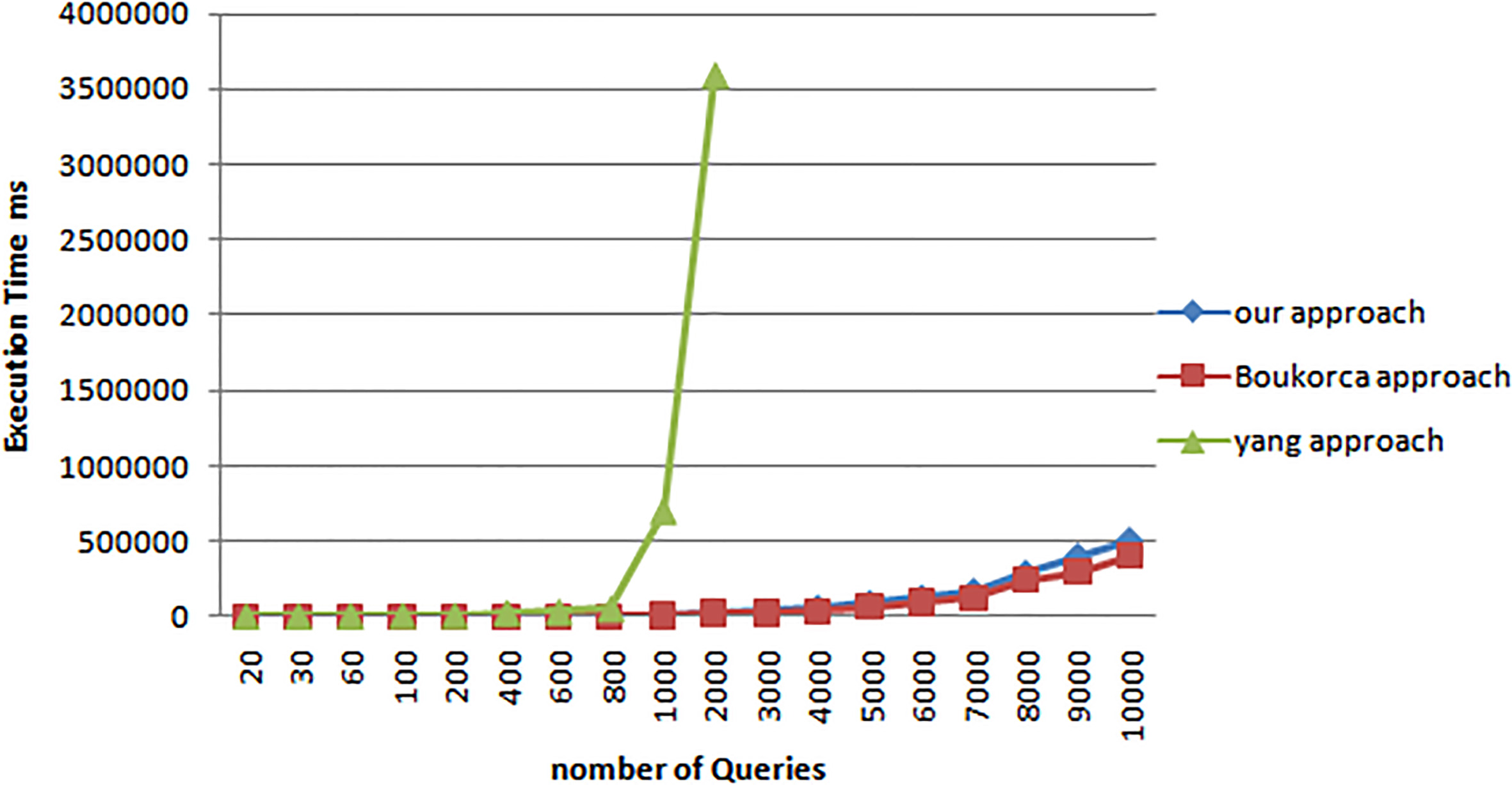
To study the effect of the size of the workload on the performance of our approach, a series of the tests were applied to evaluate the optimization rate for each workload, by estimating the cost of this workload with and without using materialized views (MV) (1-cost
Optimization rate of query processing cost.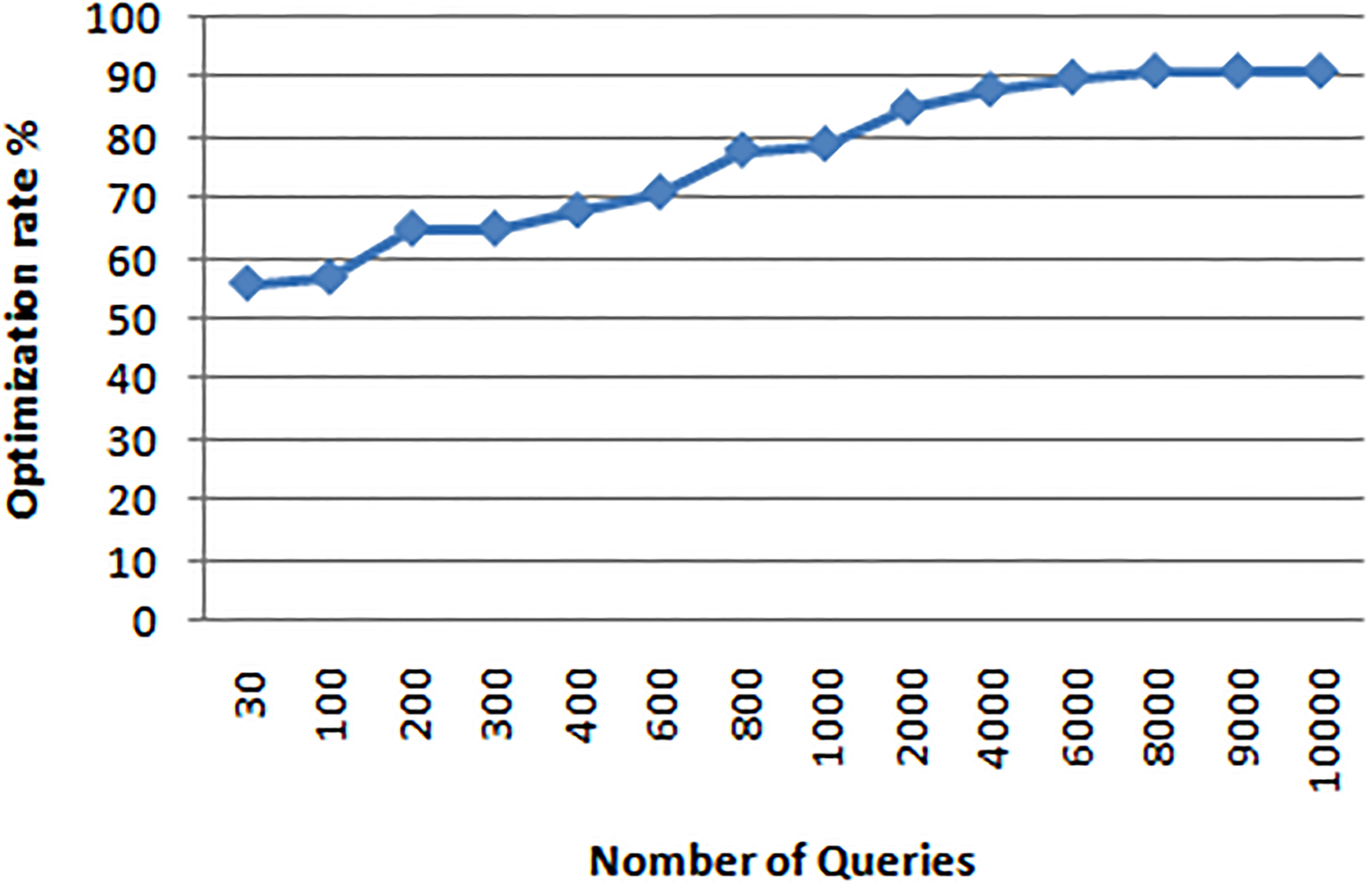
In order to test the impact of our MVPP for VSP with existing approaches of Boukorca et al and Yang et al., we calculate the processing cost of queries with materialized views, by our simulator. The obtained results are described in Fig. 7.
Our approach outperforms Yang et al., approach which does not scale when many queries are used and outperforms the Boukorca et al. approach. This means that our approach selects the best views compared with existing approaches.
Query processing cost with materialized view.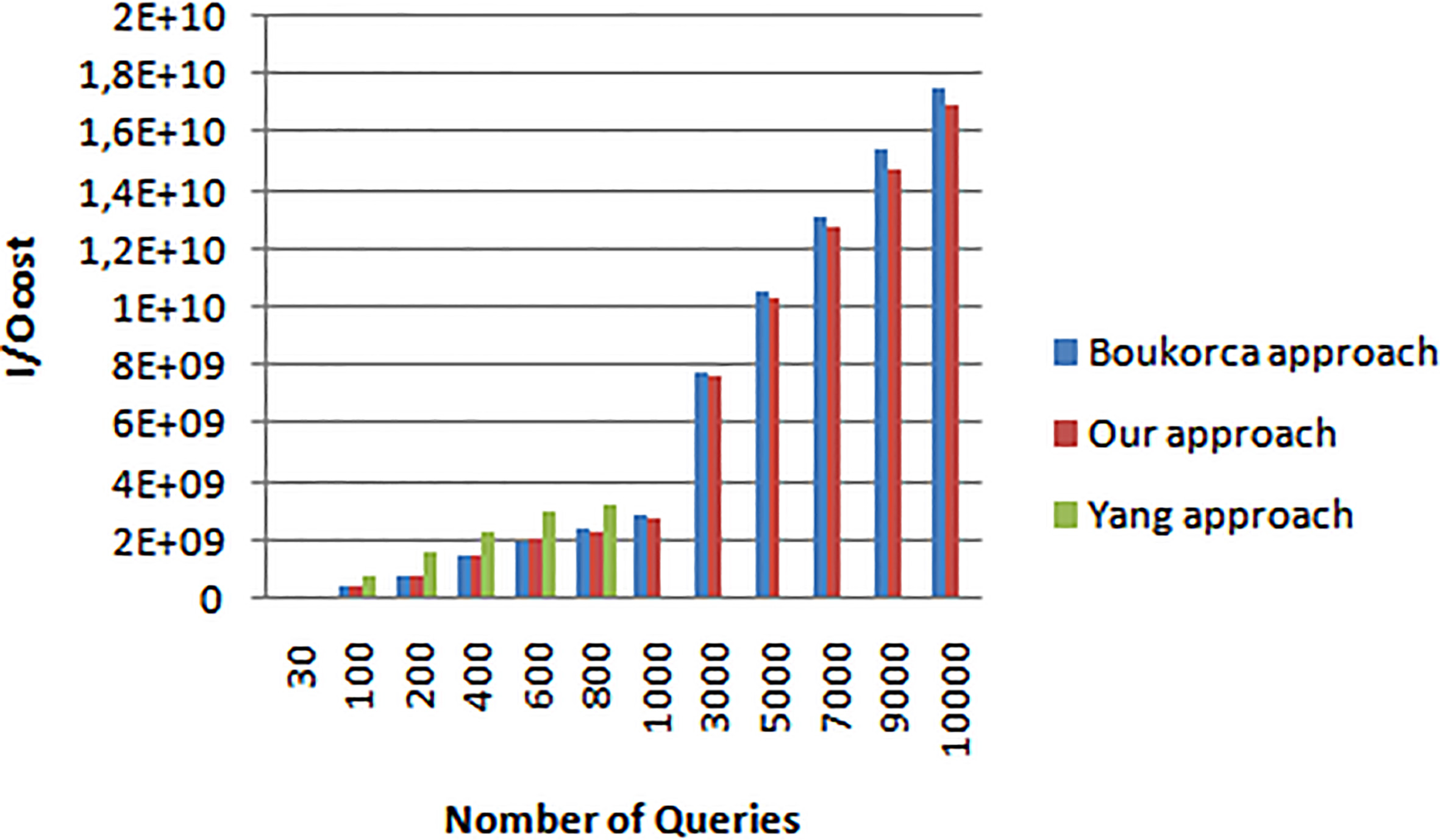
To validate the theoretical results found by our simulator, the obtained materialized views by our approach and other approach are then injected in Oracle 11 g DBMS and the workload of 30 OLAP queries are evaluated by considering these sets of views.
The obtained results are given in Fig. 8, which compares total execution costs with materialized view, and materialization costs, which represent the maintenance costs of the views such as maintenance cost, equal the sum of the creation cost and processing cost of the view. This test confirms that our approach is better than Yang et al., one and there is a little better processing cost with materialized view value compared with the Boukorca et al approach which confirms the effectiveness of our MVPP for selecting best views.
Query processing cost using materialized view (MV) in Oracle.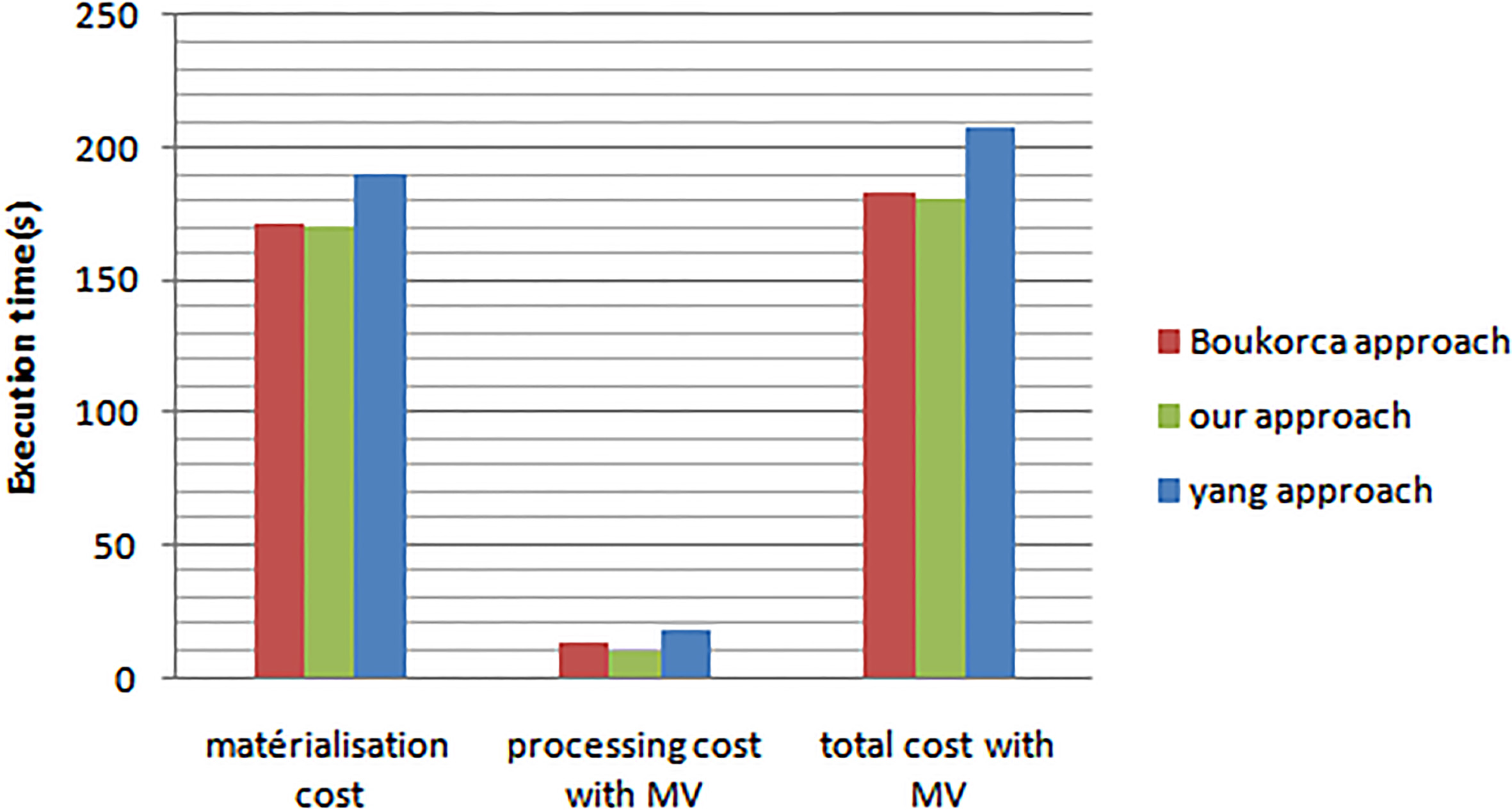
Our experimental results have demonstrated the scalability of our approach by stressing then in terms of the size of queries (10000 queries) and it compared with the most important state of art studies. We evaluated the required time to generate our multi-view processing plan (MVPP) against the approach of Yang et al. [7] and Boukorca et al. [24]. The results showed that our approach is more effective in terms of execution time, because we have benefited from the advantage of the K-means algorithm in data mining applications is its efficiency in clustering large datasets, and our proposition of generating this MVPP without passing by the logical plans of each query, which allows our approach becomes scalable. We also tested the impact of our MVPP for the View Selection Problem (VSP), the results prove that our approach selects the best views compared with existing approaches because we grouped the big queries that are similar in the same group following the most important sub-plans with a single join called score sub-plan. But the disadvantage we have found in our approach is that even with the coupling between two world multi-query optimization and the physical design phase by using materialized view in order to optimize big queries context, remain insufficient to gain effectiveness during the evaluation of these queries over centralized data warehouse. In the face of this situation, the passage to distributed and parallel platforms is one of the scalable solutions adapted to evaluate these big queries, for this we want to improve our approach in order to test our MVPP to designing parallel data warehouse.
Conclusion
We proposed in this paper an approach of modeling big and interacted queries for materialized views through data mining that considers the scalability issue to deal with the Big Queries phenomenon. This approach is based on the divide-conquer principle to model the interaction between queries by using the K-means clustering and operation of refinement in order to generate the global plan MVPP and materialized views are derived from this MVPP. Our approach is compared with the most important state of art studies and the experimental results show the effectiveness and the scalability of our approach even with a large workload of queries.
In our future work, we will consider the impact of the generated MVPP to identify the selection predicates which participate in the horizontal data partitioning of the data warehouse. In addition, our approach is applied in the static context, does not take into account the change of the workload. In our future work, we will implement our approach in a dynamic context using similarity and dissimilarity measures to study the effect of workload updates on the obtained results.
Footnotes
Authors’ Bios