
Abstract
In grid computing, if the system load in each of resources is almost equal, this indicates correct resource usage. This paper presents an agent based load balancing model. Instead of balancing the load in the grid by job migration technique or by moving an entire process to underloaded resources. The proposed agent based load balancing model aims to take advantage of the agent’s characteristics to generate an autonomous system. It also has a distinct advantage over other agent-based load balancing models in terms of resource utilization. The performance evaluation shows that the proposed model can enhance the overall performance of grid computing.
Keywords
Introduction
Grid computing has recently become one of the most vital research themes in the field of computing. The Grid paradigm has acquired popularity as a result of its capability to give facile access to geographically distributed resources functioning through various administrative domains. The grid environment looks as a combination of heterogeneous, dynamic, and shared resources in order to give reliable and faster access to Grid resources [7].
The main aim of load balancing is to enhance the application response time by which load would be distributed according to resources. This is even more vital in computational Grid where the main concern is to equitably submit jobs to resources and to reduce the difference between the overloaded and underloaded resources [7].
Multi-agent systems offer promising features for resource managers. The reactivity, proactivity, scalability, cooperation, robustness, flexibility and autonomy that characterize agents can help in the complex task of managing resources in dynamic and changing environments.
This paper presents a new Agent Based load balancing Model, called ABLBM. A hierarchical architecture with coordination is designed to ensure scalability and efficiency. In addition, a multi-agent approach is applied to improve the adaptability. This study aims to decrease the average response time of jobs submitted to the gridand maximize resource utilization whenever possible. The reminder of the paper is organized as follows: Section 2 briefly reviews some related works; Section 3 defines the proposed agent-based load balancing model and Section 4 describes the proposed load balancing algorithms; experimental results are presented in Section 5; finally, Section 6 summarizes the main contributions of this paper with a summary on future directions.
Literature review
The authors [5] proposed Agent Grid Load balancing model (AGLBM) by analyzing the load of compute nodes and the subsequent migration of virtual machines from overloaded nodes to underloaded nodes. The proposed system involves multiple nodes that interact to implement MapReduce jobs. The multi-agent system consists of a group of agents: node sensor agent, simulation model sensor agent, analysis agent, migration agent and distribution agent. Analysis and distribution agents are defined as reasoning agents. Sensors and migration agent are reactive agents. The sensor agent collects the necessary information on the status of the node. This information contains: node loading, communication line loading. When collecting information, use performance counters. The sensor agent observes the evolution of the state of the simulated model objects located on the node. As information that the sensor agent sends as output information, the frequency of the event, the frequency of receiving and sending messages from the poles, the frequency of the state change. The analysis agent interviews the analysis agents at certain intervals, decides, using the rules, whether balancing is necessary. If this is the case, the distribution agent is communicated.
The distribution agent is the source of “knowledge” about the surrounding environment (neighboring nodes, statistical data on neighboring nodes) for the analysis agent. This knowledge is proposed to clarify the rules according to which the agent decides on the need for balancing. The broker agent controls with all agents and controls the functioning of the nodes, when the node has completed its part of the work. The broker-agent takes some of the work from the other node and mixes it with a free node. This ensures that the entire node is still being processed. The rule-based distribution agent selects the model objects to be transferred and chooses the target network nodes. The distribution agent, when selecting objects for transfer to other nodes, refers to neighboring distribution agents. Then, the distribution agents are synchronized, which makes it possible to determine the main agent. After the execution of the synchronization algorithm, the lead agent completes the simulation process by sending a message corresponding to the simulation system. The agents then request the objects necessary for the system. The migration agent moves the objects to other nodes. The migration agent sends the objects from the simulation model to the distribution agents of the target nodes. Once the migration is complete, the distribution agents are synchronized again and the simulation system is launched. The modelling process is ongoing. In this study, system performance has not been studied, the implemented Hadoop platform is also simple, and the experimental installation of Hadoop may not be optimal and the results may be misleading to some extent.
In the study of [10], a distributed resource allocation protocol model (dRAPM ) is proposed to assign and schedule tasks on a distributed grid. Using the properties of multi-agent systems, the proposed distributed resource allocation protocol (dRAP) is described as follows: An agent in the system is simply a node. Each agent has a vector including the number of CPUs in its cluster and the residual time to complete the execution of its current process. Each agent is assured to be in exactly 1 out of 4 cases during the simulation.
In the first case, an agent has no assigned jobs to it and it is not part of a cluster. In this case, the agent analyzes the queue, it takes into account the CPU
In the second case, an agent has been assigned jobs and it is not part of a cluster.In this case,the agent continues executing the job and updates its information vector. If the job requirements are not totally satisfied, the agent will query its neighbors and attempt to form a cluster such as: CPU
In the third case, an agent is currently part of a cluster and has no assigned jobs.In this case the agent scans the queue, it considers the unassigned jobs and it takes on the job which minimizes the equation:
In the fourth case, an agent has been assigned a job and it is currently part of a cluster. In this case,the agent continues the execution of the job and updates its information vector. When the job is completed, the agent disconnects from the cluster and returns to first case.
A main feature of this algorithm is that nodes ask their neighbors to form clusters. This reduces waiting time and communication costs. One optimization to consider would be to delay the disconnection of the cluster in state 4, which would guide learning or memory in the system where the planner would be able to remember the requirements of the past process. The problem with this algorithm is its decentralized nature, it is neither a centralized control nor a precise synchronization on nodes (agents).
The main contribution of this study [9] is the development of an agent-based model for managing network resources with defined operations so that the user can perform jobs efficiently and effectively and thus significantly improve management by a gLite Grid middleware. The agent-based resource management model (ABRMM) provides a platform based on a collection of agents in a virtual organization. The key aspects of this proposal architecture are: resource tracking, load balancing and agent hierarchy. The agents that make up this platform are defined as the agent user interface (AUI), scheduler agent (SA), resource search agent (RSA) and monitoring agent (MA). AUI collects basic information on the type of work resource requirements or special requests for resources using a web interface to communicate with the user. The SA is responsible for planning the execution of work with appropriate resources. He contacted RSA for a list of available resources. He finds the best resource according to the demands and availability of the machines. RSA gives a list of resources, RSA makes the link between uses and resources. Then, the RSA functionality switches to the WM gLite. The user can choose the resource or allow it to be executed in a transparent manner while respecting the established criteria. The MA is responsible for monitoring the status of resources to provide online information on availability and, at the same time, it controls the tasks performed by each task. The MA multi-agent system interacts through a communication interface, successfully maintaining the discovery of current information services and updating the gLite middleware.
In this paper [4], the authors proposed a new load balancing structure based on the moving agent and a technique for optimizing ant colonies. In the proposed Ant Colony Optimization Model (ACOM), a dispatcher agent is involved in distributing the tasks received to the worker agents according to the right decisions in order to minimize the overall execution time (makespan). The proposed framework is constructed using three layers which are the producer of user tasks, the scheduling load balancing layer and the workers’ layer. This study should be complemented by comparing their results with other methods, minimizing task movements and resulting in additional costs in the migration process.
Another study [6] presented the design and implementation of a priority based fuzzy load balancing model (PBFLBM) in a computing grid. In this grid template, the user sends his jobs to the grid agent, after the grid scheduler uses the priority-based scheduling algorithm to schedule jobs from the grid agent to the available resource. Load balancing is done using the fuzzy logic technique Propose, in which a set of fuzzy rules are produced using the resource and the work parameter. As fuzzy control rules are collected using linguistic variables, perceptual knowledge and inspection are easily integrated into the control mechanism.
Proposed model
Grid model
A Grid computing was modelled as a collection of clusters proposed in a multi-node platform. Each cluster was composed of nodes and belonged to a LAN local domain (Local Area Network). Every cluster was connected to the WAN global network (World Area Network) by a Switch [2].
The proposed load balancing model was based on mapping the Grid architecture into a tree structure. This tree was built by aggregation as follows: First, for each cluster, a two level subtree was created. The leaves of this sub-tree correspond to the cluster nodes, and its root, called cluster manager, represents a virtual node associated with the cluster. Secondly, sub-trees corresponding to all clusters were collected to generate a three level sub-tree whose root is a virtual node designated as a Grid manager. The concluding tree is referred to as C/N, where C is the number of clusters that constitute the Grid and N the number of worker nodes [2].
Agent based load balancing model
This study aims to develop a hierarchical load balancing model based on a multi-agent system, in addition to previous work on agent-based load balancing. There are two key challenges for Grid computing: heterogeneity and scalability. The authors propose a three-layer architecture to address the scalability issue (Fig. 1). Connecting or disconnecting resources (worker nodes or clusters) correspond to simple operations in a tree (adding or removing leaves or sub-trees). The proposed agent based load balancing model aims to take advantage of the agent’s characteristics to create an autonomous system.
Proposed agent based load balancing model in grid.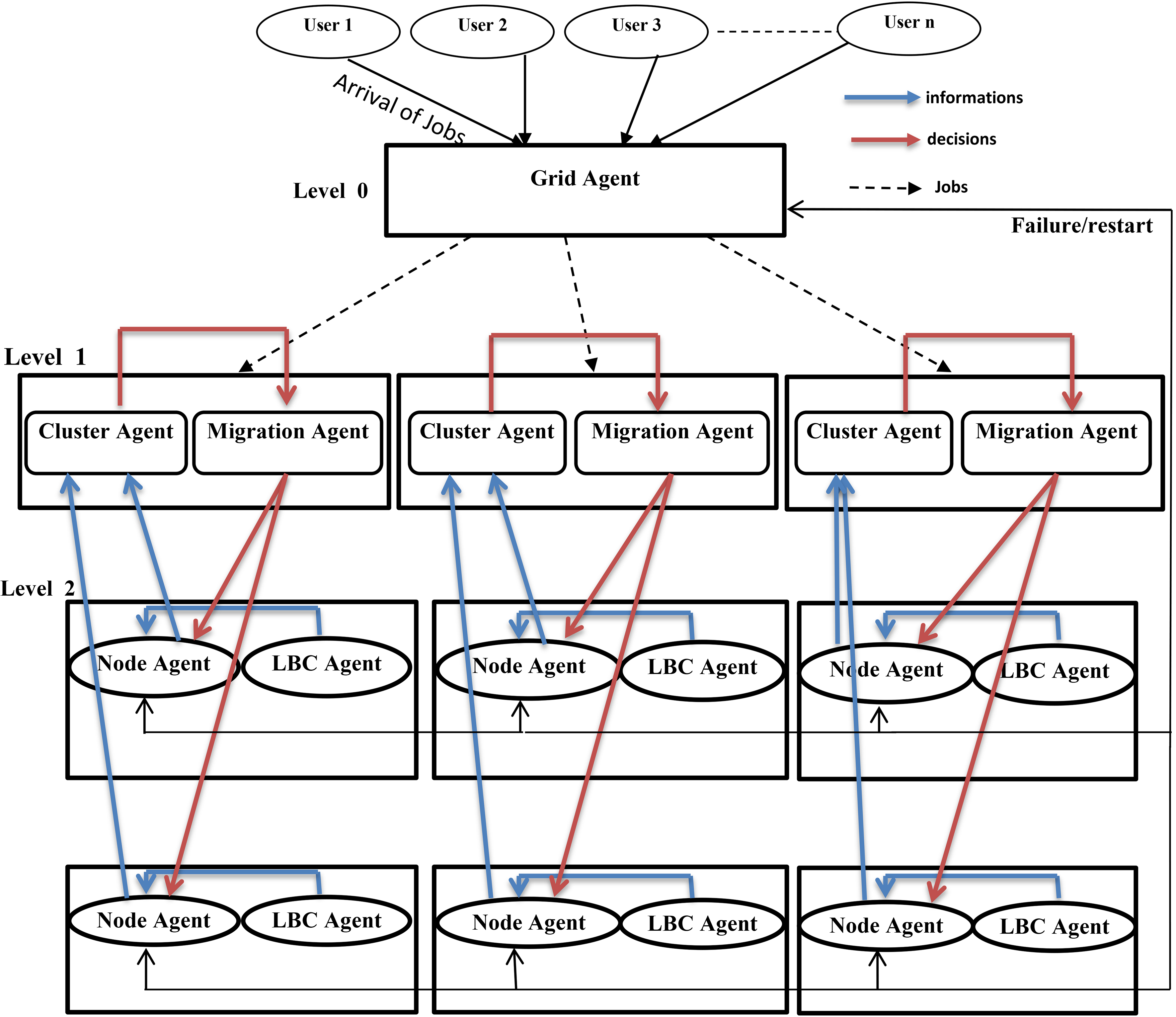
In the proposed model, three levels are identified. The first is Level 0, at this level we find Grid Agent, the Grid users send their jobs to the Grid Agent. The latter is responsible for receiving jobs from Grid users and sending them to Node Agents. When a node fails, Grid Agent stops it and restarts it on a different set of nodes. Also, the Grid Agent starts up all Cluster Agents.
The second level is Level 1. At this level, Cluster Agent is associated with a physical grid cluster; this Agent is responsible for the maintenance of the load information relating to each of its Node Agents. With such information, the Cluster Agent estimates the load of the associated cluster and distributes information to other Cluster Agents. Moreover, Cluster Agents take the decision to start local load balancing and sending these decisions to Migration Agent, also Cluster Agent initiates a global load balancing process. Then, the Cluster Agent starts up its associated Migration Agent and all Node Agents of nodes under its control.
In addition, the Migration Agent is present at level 1. Its role is to start the migration process, by sending the migration decisions to the Node Agent, waiting for an acknowledgment from the receiver node, and ensuring that the migrated jobs are received and successfully resumed at the destination node.
The third level is Level 2. At this level, Node Agents and LBC Agents are present. It is necessary to have one Node Agent on each node. Each Node Agent at this level is responsible for receiving jobs sent by Grid Agent and maintaining its load information. Next, it sends this information to its associated Cluster Agent. Likewise, Node Agent works in cooperation with the Migration Agent to execute the migration process. The AgentNode starts up all its associated LBC Agents.
At Level 2, the LBC Agent is also present. It resides at each node and its role is to collect information about the jobs (number of jobs queued at node, arrival time, waiting time, submission time, start time, processing time and finish time of each job on the local node). It is concerned also with removing the terminated or migrated jobs from the queue of jobs, and calculating a total load of nodes and sending it to its related Node Agent.
According to the proposed model, two levels of load balancing are considered: Intra-cluster Agent based load balancing algorithm and Inter-Clusters Agent based load balancing algorithm.
There are certain specific events that change the load configuration in Grid computing and can be classified as follows: i) any new job is arrived, ii) accomplishment of execution of any job, iii) any new node is arrived, iv) any existing node is removed, v) failure of Machine at any node, vi) the node become overloaded.
When any of these events happen, the local load value is changed. Table 1 summarized the notations used for the proposed algorithms.
Notations used
Notations used
Depending on its current load, each Cluster Agent decides to start a Job Migration operation. In this case, the Cluster Agent tries, in priority, to balance its load among its nodes.
3.3.1.1. Load estimation
The node load at a given time was simply described by the CPU queue length. It indicates the number of processes awaiting execution. The proposed algorithm considers CPU-U (CPU Utilization), Q length (Queue length) and Mem (memory utilization) as load information parameters to measure the load of a node.
These parameters are calculated as follows:
where
where
where
The averaged information of CPU-U, Qlength and Mem are the load parameters used to describe the node load.
Algorithm 1 is LBC Agent deployed in the proposed framework.
Algorithm 2 is Node Agent deployed in the proposed framework.
Activity diagram for AgentLBC Algorithm.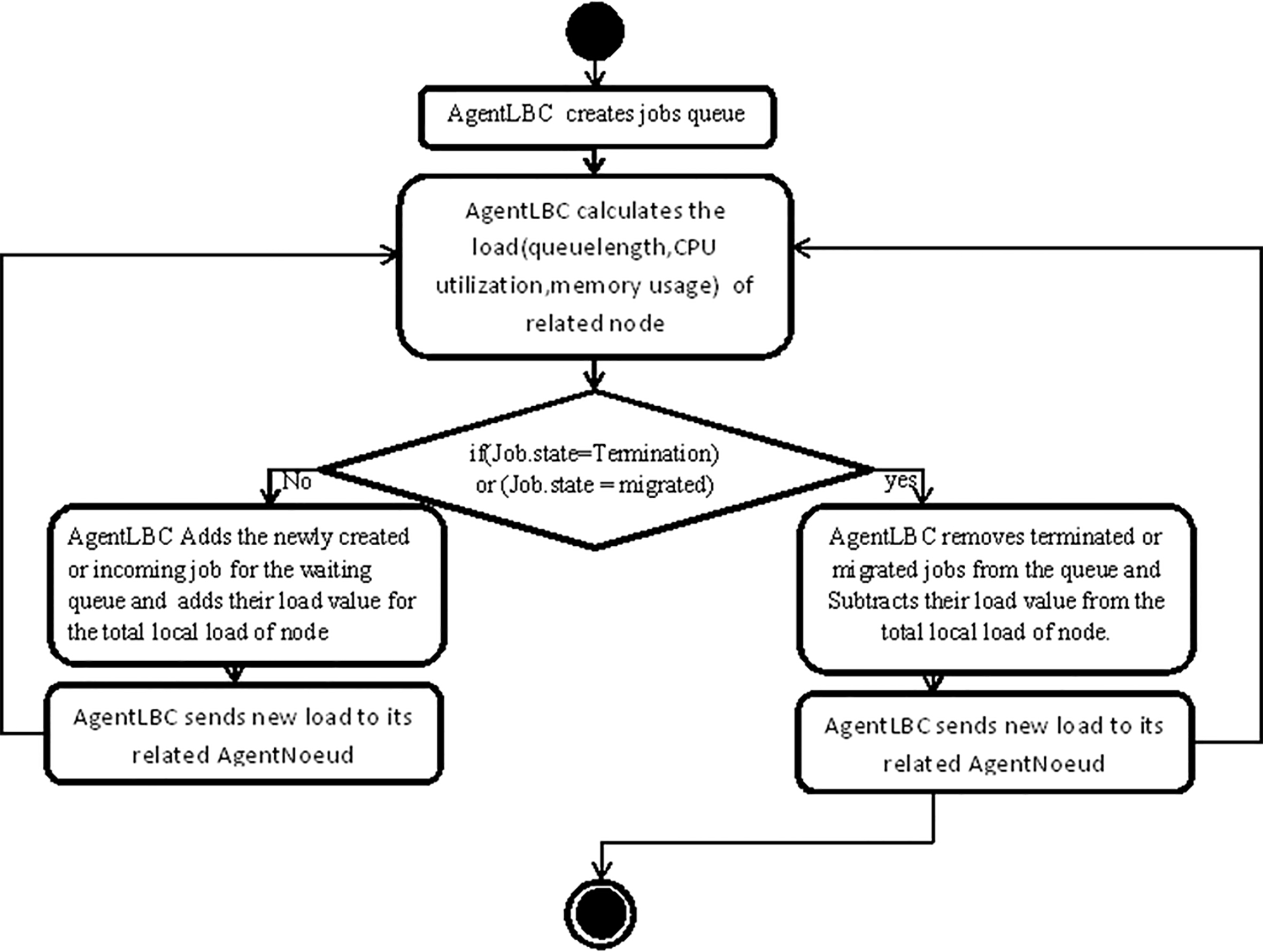
3.3.1.2. Decision making
In the next step, the nodes must be classified according to their load. Three states were used for classification: overloaded, underloaded and balanced. First, Cluster Agent must calculate two threshold values, which are calculated as follows:
Cluster Agent calculates load average of each parameter (CPU-U and Qlength) over all related nodes.
where
where
Activity diagram for AgentCluster algorithm.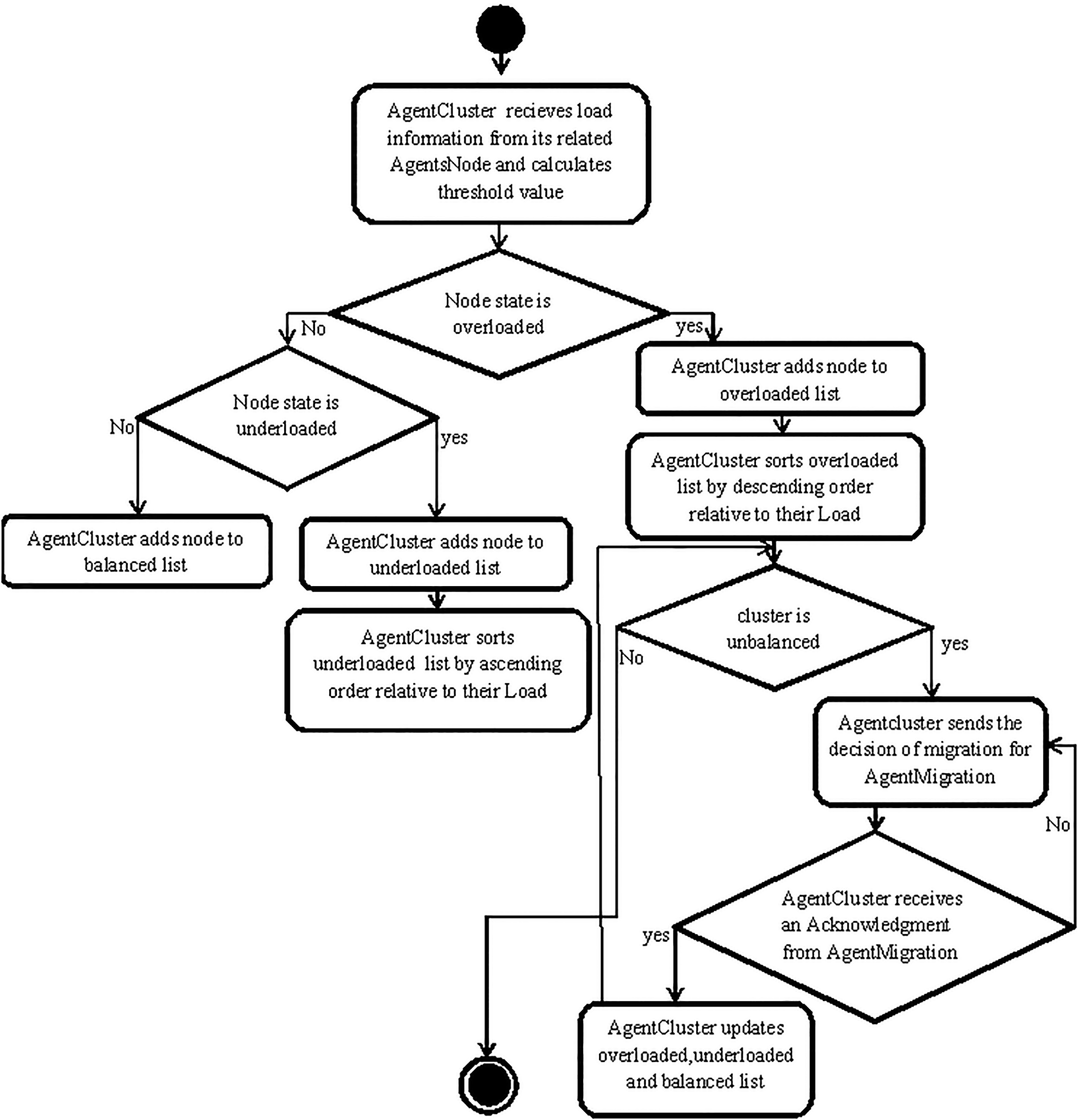
3.3.1.3. Calculation of threshold values
The higher and lower threshold values of Qlength and CPU-U of parameters are calculated by multiplying the average load of (Qlength or CPU-U) and a constant value.
where TH
The next step is to divide the nodes for balanced, overloaded and underloaded nodes using the threshold values.
The node will be added for overloaded list if queue length is high, or CPU utilization is high, or memory usage is greater than 85%, then the node is classified as overloaded node.
The node will be added for underloaded list if queue length is low, or CPU utilization is low.
The node is not into the overloaded list or the underloaded list. The node is in a balanced load state. They are considered to be more loaded than the low state and less loaded than the high state.
Algorithm 3 is Cluster Agent deployed in the proposed framework.
3.3.1.4. Job migration
After classifying the nodes, in the next step Cluster Agent decide to transfer jobs from overloaded to underloaded nodes. It sends this decision for Migration Agent.
Algorithm 4 is Migration Agent deployed in the proposed framework.
Activity diagram for AgentMigration algorithm.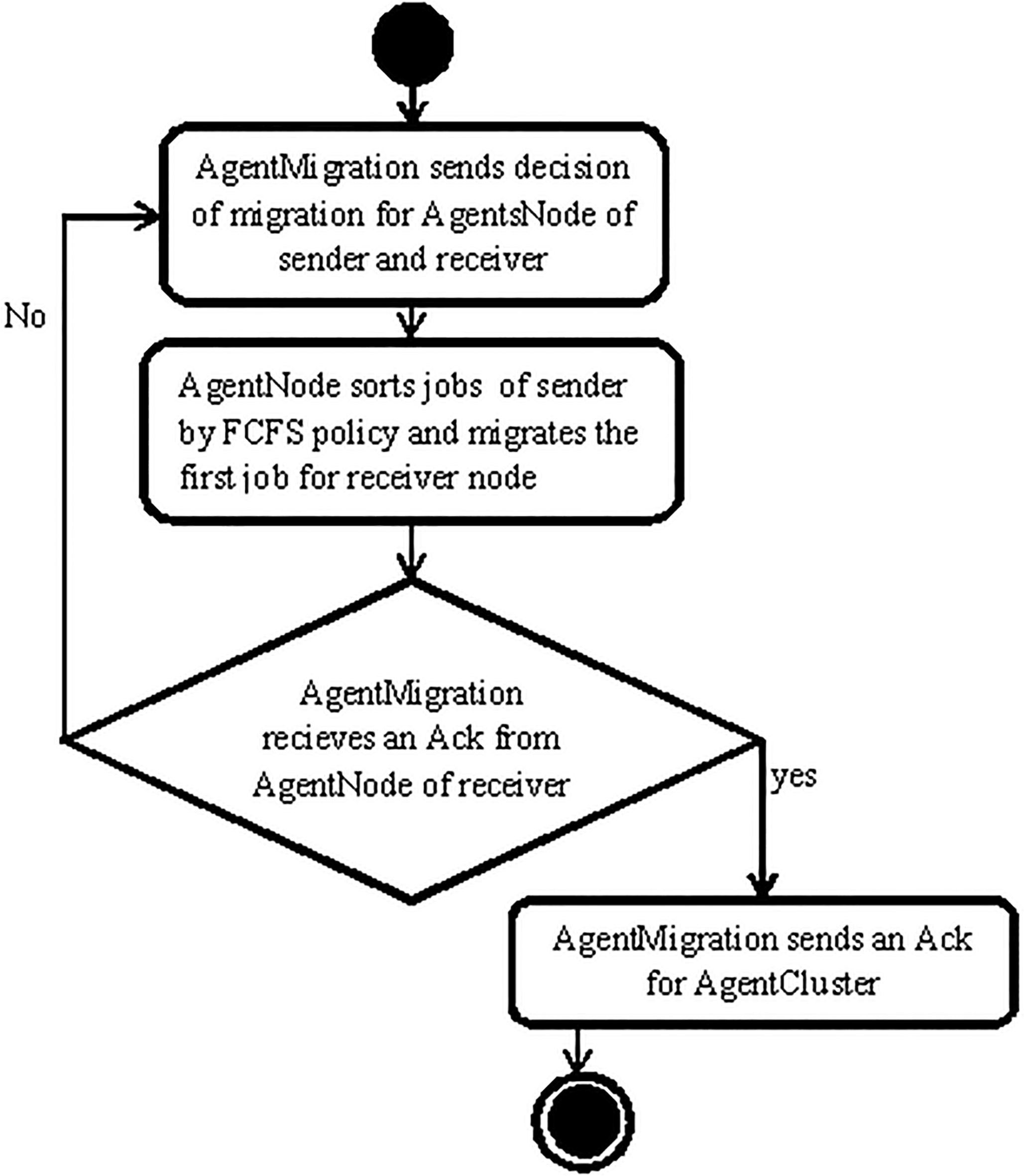
This algorithm applies a global load balancing among all clusters of the Grid. The Inter-cluster load balancing at this level is made if Cluster Agent fails to balance its load among its associated nodes. In this case the Cluster Agents transfers Jobs to under loaded clusters based on the load information received by clusters. the following algorithms are proposed:
Algorithm 5 is Cluster Agent deployed in the proposed framework.
Algorithm 6 is Grid Agent deployed in the proposed framework.
Activity diagram for AgentCluster algorithm.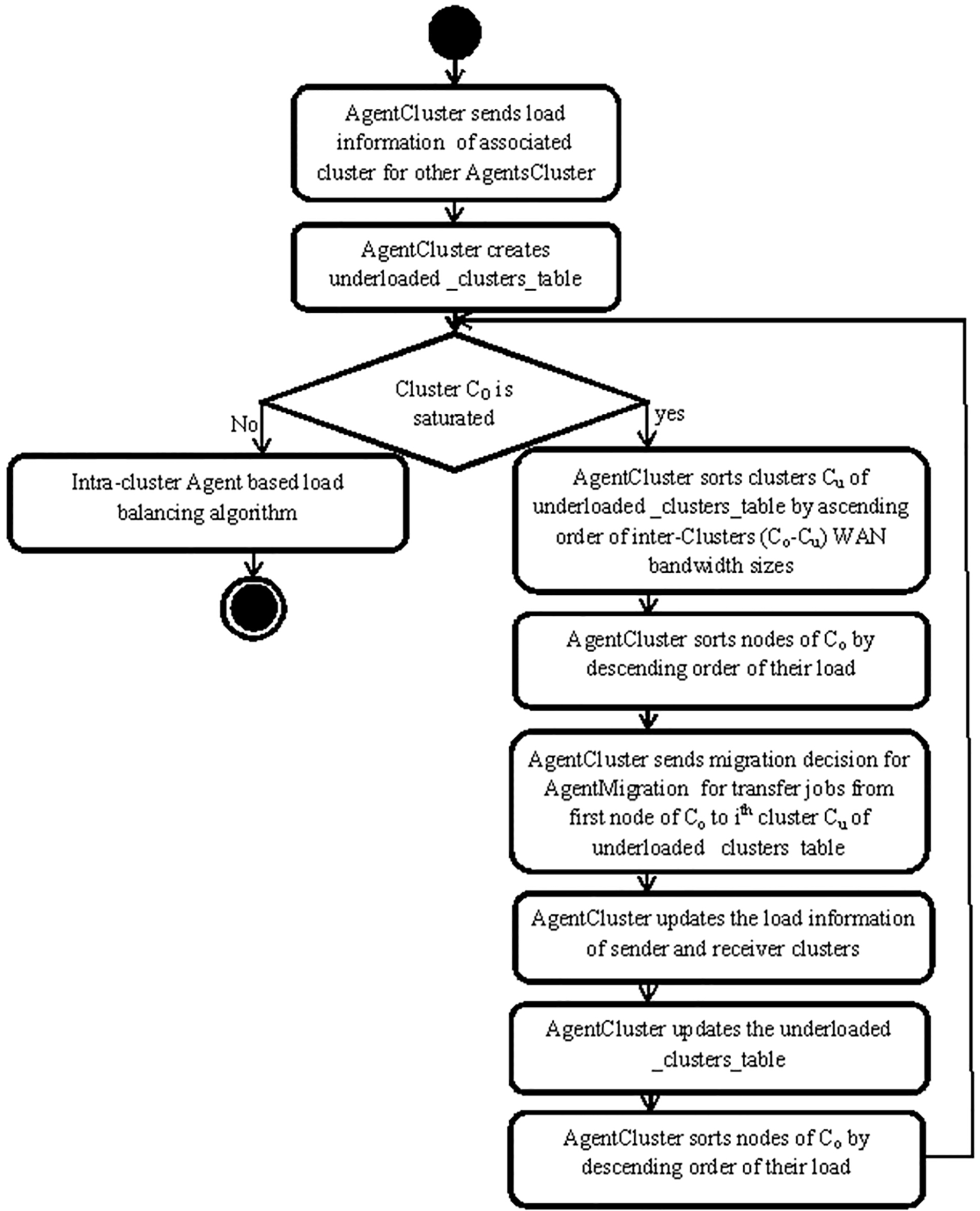
The last algorithm is implemented in Cluster Agent which determines the way a receiver cluster is selected for a job migrated from overloaded cluster. Cluster Agent of Saturated Cluster calculates the minimum communication cost of sending jobs to receiver underloaded clusters based on the information collected in the last exchange interval. Cluster Agent selects the cluster that gives minimum overall cost.
UML Sequence Diagram describes agent interactions in intra cluster load balancing process.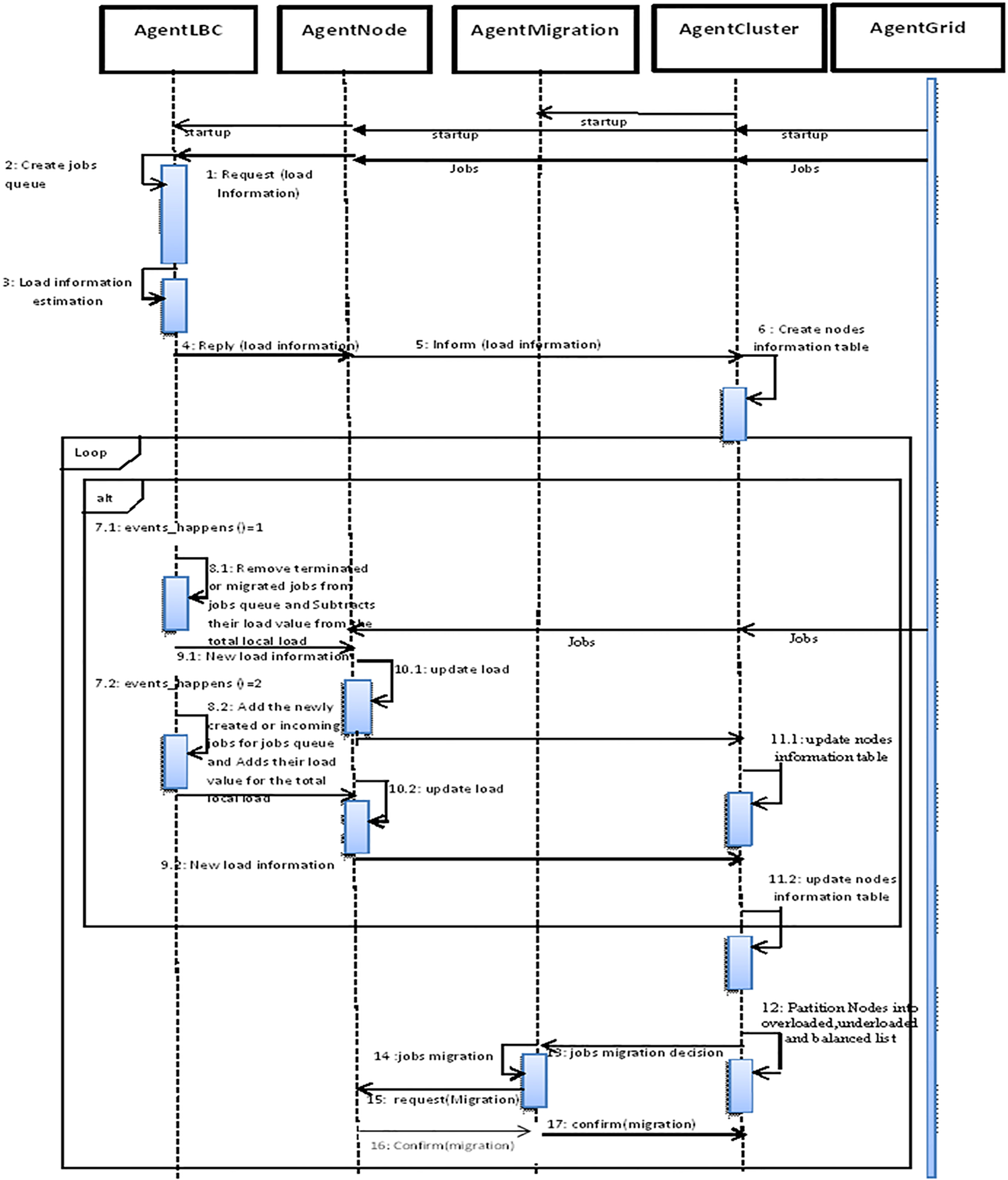
The proposed agent based load balancing algorithm is intended to take advantage of the agent’s characteristic to create a self-adaptive and self-sustaining load balancing system. The proposed system consists of five types of agents, in unbalanced situations, and if the Cluster Agent finds that there is a load imbalance between the nodes under its control, it receives the load information from each Node Agents. On the basis of this information and the estimated equilibrium threshold, it analyses the current load of the cluster. Depending on the result of this analysis, it decides whether to start a local balancing in case of an unbalanced state, or simply inform the other Cluster Agents of its current load. Node Agent sends the updated local load value to Cluster Agent, which updates its load information. The local node load is calculated by the LBC Agent residing at each calculation node. LBC Agent creates the task queue at the local node and updates it if necessary, and sends the Node Agent load information based on the defined events. Migration Agent is responsible for migrating jobs to the selected underloaded node. There is an Migration Agent in each Cluster, who expects an acknowledgement of receipt from the receiving node once it receives the migrated job. The Migration Agent ensures that the work is successfully received and resumed or started at the destination node. The last agent is Grid Agent, it is the role of the distribution of work between clusters, all Cluster Agents are started by this type of agents.
Workload
The complex data set was modelled from the national Grid of the Czech Republic’s MetaCentrum [11], which allowed to carry out very realistic simulations. It also provides information on machine failures and specific work requirements and this information influences the quality of solutions generated by scheduling algorithms. The job description includes (job ID, user, queue, number processors used, etc.).
The cluster description also includes detailed information such as RAM size, CPU speed, CPU architecture, operating system and list of supported properties (allowed queue(s), cluster location, network interface, etc.) In addition, the information machines were under maintenance (failure/restart). Finally, the list of queues containing their time limits and priorities is provided.
The proposed algorithms were implemented in Alea 2 (Job Scheduling Simulator based on GridSim) [3]. Alea 2 is an event-based simulator used to test planning algorithms under various conditions (different types of resources and dynamic task modifications in the environment, etc.). This simulator is based on GridSim Toolkit [8] and represents an extension that includes better tools for scheduling the implementation visualization skill and higher simulation speed.
Experimental results
To evaluate the effectiveness of the proposed algorithms, an experimental environment using Alea 2 as a grid simulator and JADE (Java Agent DEvelopment Framework) for agent implementation was set up. In the proposed infrastructure, management agents can communicate in a grid environment using the Jade agent platform. In addition to Alea 2, a class library was developed that simulates the activities of an agent platform. This library, called ABLB (Agent based load balancing), includes the classes: GridAgent, ClusterAgent, LBCAgent, MigrationAgent and NodeAgent. The simulation is initialized by the GridAgent class which creates instances of resources, jobs and other entities as required by the GridSim standard. GridAgent reads information describing the grid resources and jobs from a data file, reads the jobs from the data_set file and dynamically produces the jobs instances over time. each job (gridlet) attribute such as Gridlet ID, Gridlet length and input file size and output file size. Figure 7 specifies the Grid Resource parameters such as: resource ID, resource’s CPU speed and resource’s memory capacity. Next, GridAgent lists all the available grid resources within the grid environment. When the simulation time is equal to the job submission time, the GridAgent starts the ClusterAgent and dynamically sends the jobs created for the Node Agents over time.
Grid resource characteristics.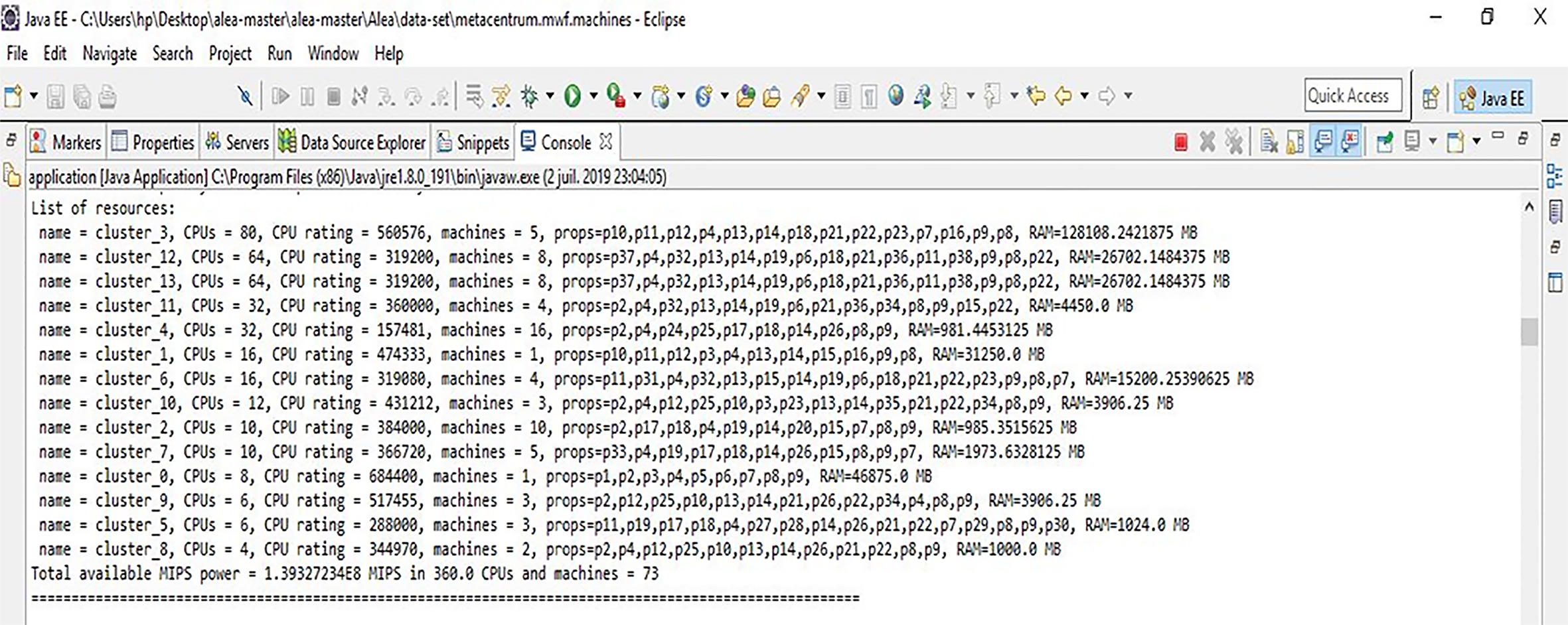
On the basis of its own load and the estimated balance threshold, ClusterAgent analyzes the load state of the cluster. For an imbalance state, ClusterAgent determines the overloaded nodes (sources) and the under loaded ones (receivers), depending on their load information by using the threshold values. Decision making algorithm results are shown in Fig. 8.
Result of decision making algorithm.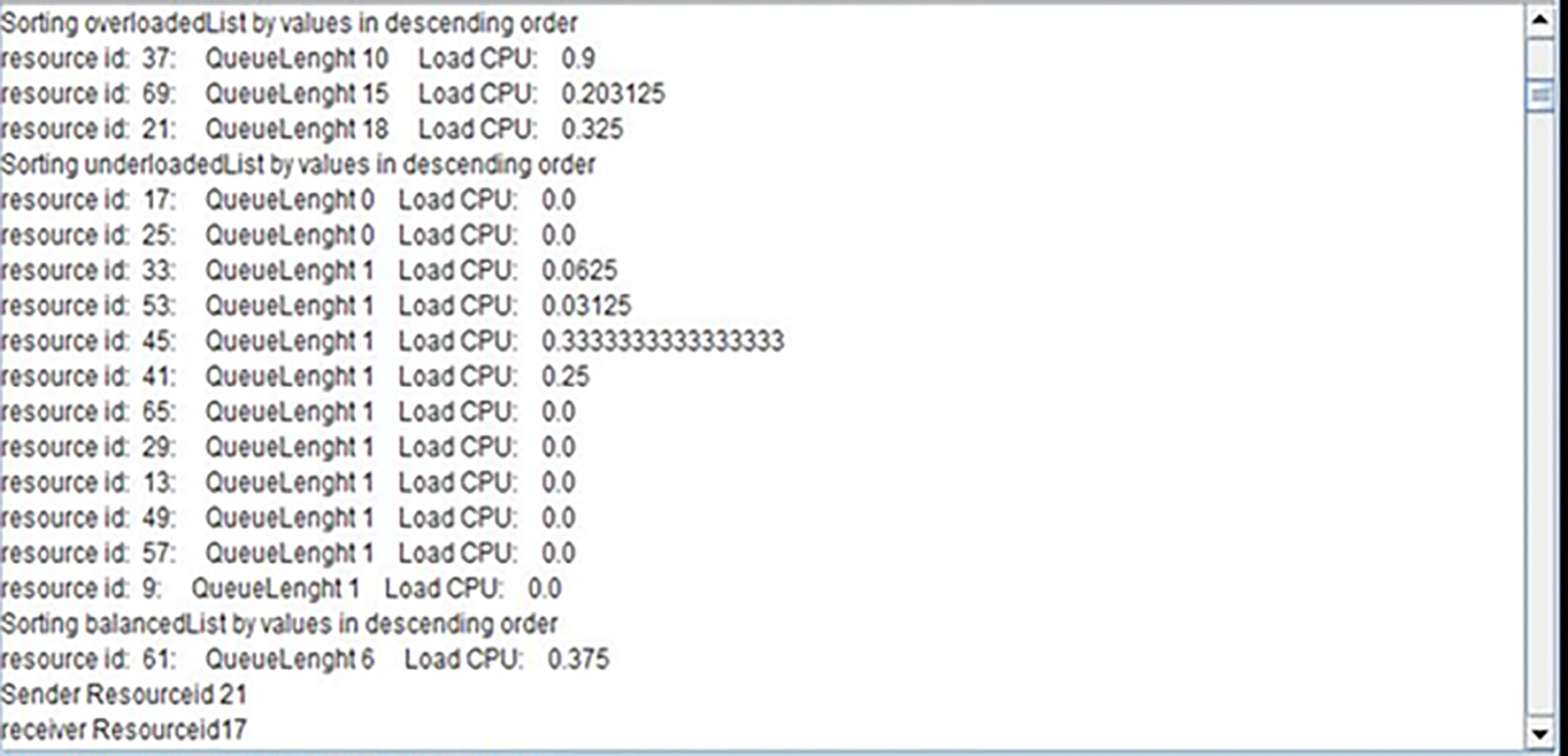
After classifying the nodes, in the next step ClusterAgent decide to migrate jobs from overloaded to under-loaded nodes, the proposed algorithm works in pair of node (sender and receiver), the first pair has the most overloaded node and the must under loaded node, second pair has the second most overloaded node and the second most under-loaded and so on. in the proposed example the pair of node (Resourceid21, Resourceid17), the first submitted job is selected to be migrated.
The important performance factors in estimating the proposed algorithm are: scalability, the number of jobs waiting in queues and maximizing resource utilization. Some experiments were carried out to evaluate the efficiency and performance of the proposed algorithm.
Experimentation 1
In the first experimentation, the focus was on the number of agents that the system can stabilize before it becomes out of control.
Average response time (seconds) according to various Agentscluster numbers.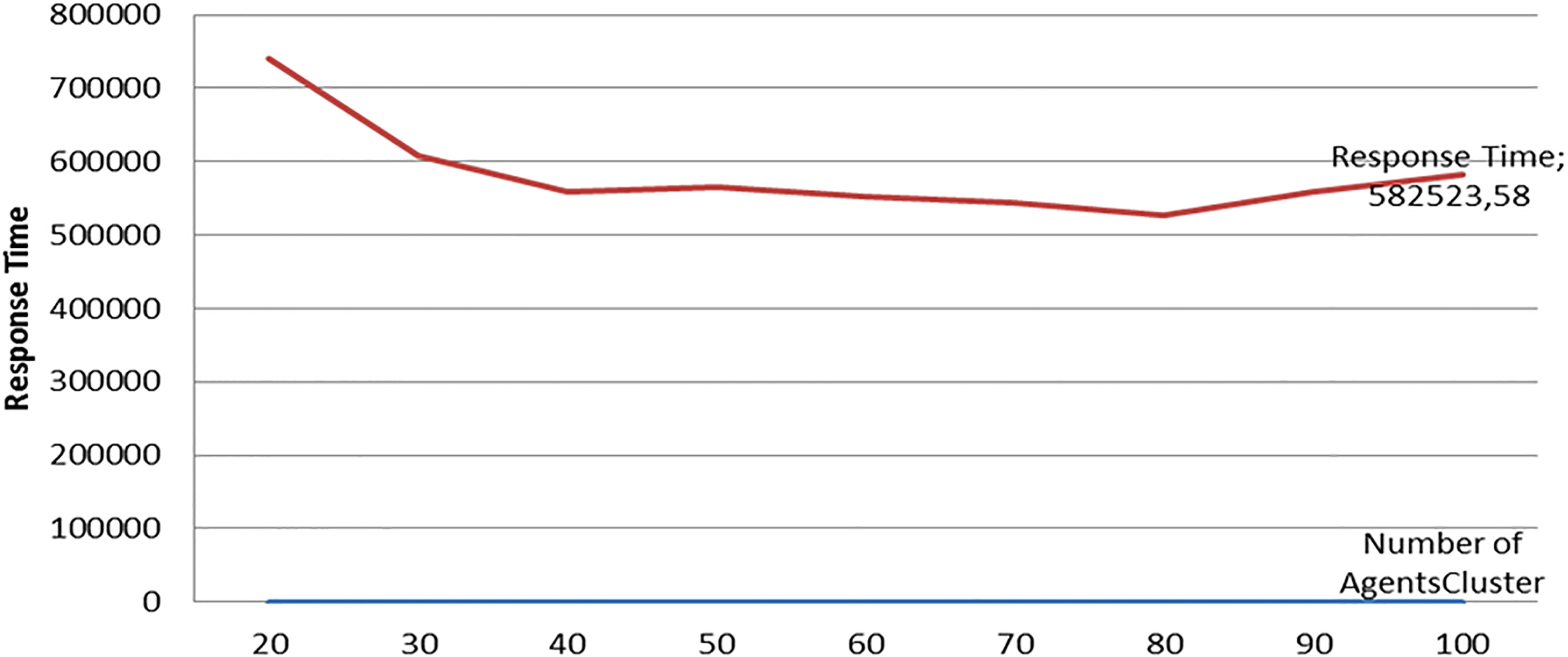
Figure 9 shows that the limit of the proposed algorithm is about 100 Cluster Agents. The simulation takes only a few minutes, but it creates a huge message. This is simply caused by the number of agents participating in the system. This problem increases as new agents are added, but around 1Grid Agent, 100 Cluster Agents, 100 Migration Agents, 462 Node Agents, 462 LBC Agents, the system still works for the most part correctly.
The hierarchical load balancing model solves scalability problems: a larger number of agents in the hierarchy will lead to greater activity without the intervention of a central agent. In this model, the system adapts correctly.
In the second experimentation, the use of resources was the main focus (%). The number of clusters was assumed to be 14, and each cluster was considered to be composed of different numbers of resources. The number of jobs was 3000. Figure 10 shows the use of the cluster with and without ALBA algorithm.
Comparison of cluster utilization (%) with and without Agent Based Load Balancing using 14 clusters.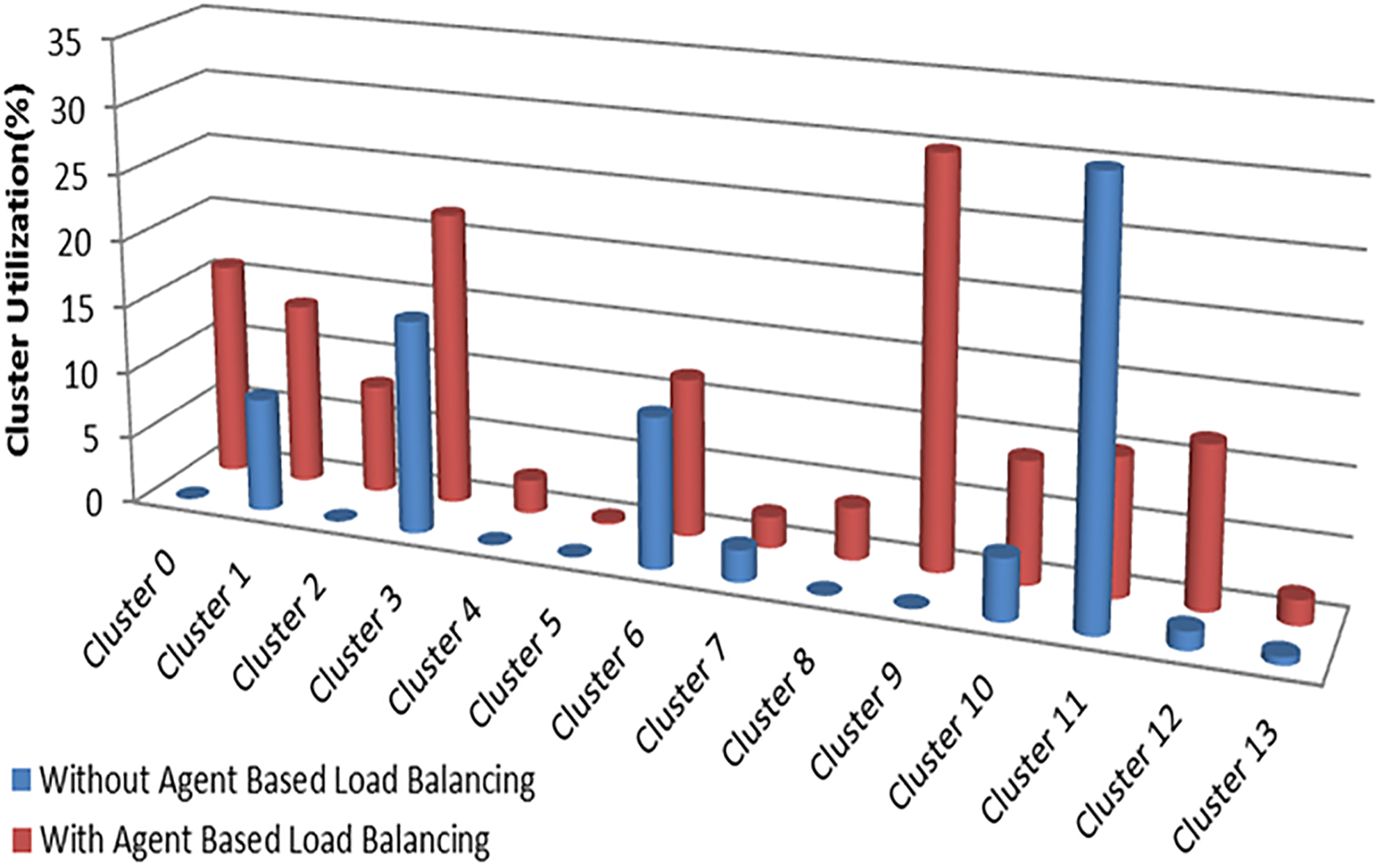
Figure 10 shows that the agent based load balancing algorithm is more effective in maximizing resource utilization.
The ALBA algorithm allows job to be scattered over the most available resources when there was no appropriate resource, unlike other traditional algorithms that try to select the best resource that resembles the work requirements; otherwise, the job will remain in the global queue, indicating an underutilization of those resources.
In this section we will show the differences and similarities between our proposed model and the existing models in [5, 4, 9, 6, 10].
Comparison between the proposed Agent Based Load Balancing model and other models
Comparison between the proposed Agent Based Load Balancing model and other models
In Table 2, we compared some current Agent Based Load Balancing Models for grid computing environments..
Because all existing models which we considered, have been proposed for grid computing environments. Therefore all of them have applied dynamic approach which is suitable for systems like grid computing that have dynamic, unpredictable and various workloads. In addition, most of the proposed models which we considered, have been designed in hierarchical and heterogeneous forms. So, we can say that all of them are not fault tolerant solutions and this would be a main drawback for most of them. Also we observed that all of these existing models in this study are scalable.
After reviewing the existing models comprehensively, it can be stated that different models have considered different metrics for evaluation. Some of the papers have considered a single performance metric such as [9, 4] while some have considered multiple objectives for metrics such as [6, 10]. Those existing models do have limitations that need to be addressed. Thus there is need of an algorithm which can offer maximum resource utilization, maximum throughput, minimum response time, dynamic resource scheduling with scalability and reliability. The proposed model address most above issues, it supports heterogeneity, scalability and dynamics of grids. Moreover, it decreases the average response time and maximizes resource utilization.
There have been a number of efforts at developing Agent based Load Balancing Models for grid computing. It is often difficult to make comparisons between different efforts because each Agent Based Load Balancing Model is usually developed for a particular system environment or particularly greedy application with different suppositions and restrictions.
Load balancing models are generally multi-objective such as enhancing performance and reducing operational cost. Therefore, an optimal trade-off between various contradictory objectives needs to be preserved.
The algorithms proposed under the Alea 2 simulator written in Java were developed to test and estimate the performance of the load balancing model based on the proposed agent. Experimental results show that the proposed model allows a better balance of load and the correct use of resources.
There are many opportunities to improve resource utilization and reduce response time through coordination and cooperation among agents. Therefore, the proposed model supports heterogeneity, scalability and dynamics of grids. In addition, a multi-agent architecture for grid load balancing was suggested, as well as a job migration technique to reduce the difference between overloaded and underloaded nodes. Finally, to estimate node load, the combination of CPU usage, memory usage and queue length was applied.
The proposed model ABLBM has some unique features:
It is hierarchical, which facilitates the circulation of information through the tree and defines the flow of messages in the proposed model. The model also provides fault tolerance through its self-configurability. Nodes leaving the system will be replaced by new nodes, also the tasks will be reallocated to other nodes when a node leaves without finishing its current task. Furthermore, it supports the scalability of grids: insertion or elimination entities (nodes or clusters) are very simple operations in the proposed model (insertion or elimination nodes, subtrees. In addition, the proposed model considers the heterogeneity of resources; thus, it is completely independent of any physical network architecture. The proposed model considers the heterogeneity of resources so that it is completely independent of any physical network architecture. It supports flexibility and expandability: various intelligent agents have been deployed to reduce system complexity by modularization. Moreover, it is easy to modify its components, and add more features and functions to it.
However, the problems of the model implemented, there is no certainty that migrating jobs will resume in the reception node. The sender node does not keep a copy of the job until it is left at its new receiver node. Other solutions must be found to offer more reliability for migrating jobs. Moreover, the time required to complete a migration process is not explicitly calculated.
Thus, based on the promising results of these experiments, the authors aim to compare the results obtained with other agent-based load-balancing algorithms in terms of performance metrics. Therefore, the authors will consider the cost of negotiation between agents. The authors will also use a mobile agent for load balancing and improve and use the proposed model in real grid environments
Footnotes
Authors’ Bios