
Abstract
Extensive use of cloud services has led to the need for service reliability for both the service provider as well as the users. In the Infrastructure as a Service cloud computing model, it is critical to ensure the reliability of resources such as virtual machines (VMs); storage networks etc. The paper proposes a replication-based fault tolerance method to improve the reliability of VM-based services. The proposed approach utilizes a data centre topology-aware method to select physical machines where replicas of VMs may be placed. The selection criteria for VM replica placement favour the physical machines at lower CPU temperature, more available space and at a lower edge length from the physical machine that primarily hosts the VM. By avoiding deteriorating physical machines, this policy increases the probability of successful recovery if the VM or its host physical machine fails. The proposed approach has been evaluated using two metrics, namely recoverability and the total bandwidth consumed in the replication and recovery process. The performance of the approach has been compared with a random replica placement method as well as a state of art algorithm. The simulation results illustrate that the proposed approach provides higher reliability than the other methods.
Introduction
Cloud computing is a paradigm of distributed computing developed for provisioning of dynamic computing services over the internet. It allows users to access, configure and manipulate the resources (such as software and hardware) at a remote location [18]. According to the U.S. National Institute of Standards and Technology (NIST) definition, “Cloud computing is a model for enabling convenient, on-demand network access to a shared pool of configurable computing resources (for example servers, networks, storage, services, and applications) that can be quickly provisioned and released with the least management effort or service provider interaction” [13].
Cloud computing consists of three levels of service models such as (a) Software as a Service (SaaS): software applications are presented by the cloud service provider in the form of services to the consumer or end-users (b) Platform as a Service (PaaS): provision of platforms to develop, run, test and manage applications in the cloud (c) Infrastructure as a Service (IaaS): provision of access to resources as physical machines, storage, networks, servers, virtual machines on the cloud etc. [15].
This work focuses on the Infrastructure as a service model of cloud computing which employs infrastructure in data centres and technology of virtualization to provide users with resources on demand. With virtualization technology, users (also referred to as tenants) are able to rent and access shared resources in IaaS data centres [4]. Physical machines or hosts are provisioned as virtual machines to users for running their applications. Of the numerous virtual machines (VMs) executing in a cloud data centre, it is hard to guarantee that all the VMs constantly perform satisfactorily [9]. In practice, various cloud services are not able to meet their commitment towards reliability assurance successfully due to failures of VMs. In a cloud computing-based environment, it is critical to enhance the reliability of the VM-based services for QoS guarantees to users [5].
Several solutions have been developed to deal with service reliability issues that either forecast and prevent failures or endeavour to provide fault tolerance [17]. Recognizing and eliminating faults that may arise in the system is infeasible for a complicated computing environment such as a cloud computing system where VM failures are unavoidable [10]. Therefore, fault tolerance schemes are used more often to enable the system to serve the request even some of the components are not working properly. It is desired that a fault tolerant system is capable to work despite faults in software or hardware components, failures of power or other varieties of unexpected adversities [7, 20]. Thus, fault tolerance is related to successful operation and hence, system reliability.
Various fault tolerance schemes such as checkpointing and replication have been proposed in literature for the cloud environment. Replication of VMs has been proposed to provide reliability of applications executing on VMs hosted on cloud hosts. Faults and hence, failures of physical machines are inevitable in cloud computing. Each physical machine can store
However, restarting on the replica VM consumes time and network resources since data or information to needs to be acquired from the central storage system/servers. Therefore, VM replication is not a trivial problem since it involves placing the replica at such a node that recovery is possible as well as quick, i.e., does not lead to a high downtime. In many instances, a single VM may fail while its host is still executing. If the replica has been randomly placed, the probability of encountering additional failures increases and more bandwidth is required to transfer the data or information to the replica. In comparison, the appropriate placement of replica of a VM could save a significant amount of time as well as network resources consumption in case of failure.
The paper addresses the problem of fault tolerance in cloud computing by proposing a virtual machine replication scheme. The proposed scheme is a new topology aware VM replica placement method to improve the reliability and availability of cloud based systems. Using this proposed approach, replicas of virtual machines (referred to as primary VMs) are placed on the optimal candidate servers (referred to as backup VMs). The optimality of a candidate for replica placement is determined by calculating its weight which is dependent on its distance from the VM and its current temperature. Distance between the replica and the host VM needs to be kept low for fast recovery. Further, candidates with higher temperatures are not preferred as they are more likely to fail earlier [5]. Weight based selection for replica placement contributes to a fast recovery by reducing the time and bandwidth required to transfer the data or information to the replica in case of failure. Evaluation of the proposed algorithm is performed by counting the percentage of successful recoveries for failing virtual machines. The proposed approach is also compared with a random VM placement approach and a related VM replication method, optimal redundant VM placement method (OPVMP) presented by Zhou et al. [1]. It has been verified that the proposed approach results in a higher percentage of recoveries by traversing lower number of links.
The rest of the paper is organized as follows: Section 2 discusses the related work in the area of fault tolerance in cloud computing. Section 3 discusses the proposed approach and Section 4 presents the performance evaluation of the proposed scheme with the results of simulation. Finally, we conclude our presentation in Section 5.
Literature review
Fault tolerance allows systems to offer the needed services in the presence of component failures, or one or multiple faults. Fault tolerance approaches aid in detecting and handling faults in the system that may occur either due to hardware failure or software faults. Fault tolerance is especially crucial in cloud platform as it provides to users assurance regarding performance, reliability, and availability of the applications executing in cloud. As identified from literature, fault tolerance approaches for cloud based systems are generally reactive in nature and work to reduce the effect of failure after the failure has occurred. The commonly used techniques to achieve reactive fault tolerance are replication, checkpointing based recovery and job resubmission [12]. Checkpointing [1] is used to save the system’s state periodically. In case of a constituent task’s failure, the job is restarted from the last checked pointed state rather than from the beginning and thus, it prevents the loss of useful computation. However, taking checkpoints periodically and restarting a failed service from the last saved checkpoint image(s) is time-consuming and involves high overheads during normal working
Another popular and related technique for fault tolerance is replication [11] which takes advantage of redundant and idle computing resources present in data centres to provide fault tolerance. Replication schemes create multiple copies or replicas of tasks or resources and stores these replicas in a distributed manner. As a result, a task can continue execution in the presence of failures as long as a replica is available.
Replication is one of the most commonly employed fault tolerance techniques in cloud due to the availability of redundant resources in the datacenters. As a result, a number of replication based fault tolerance techniques have been reported in literature for cloud computing. Zhou et al. [1] proposed an optimal redundant virtual machine placement model to improve the reliability of server-based cloud services using a replication-based fault tolerance method. A heuristic algorithm has been proposed for appropriate host server selection as well as optimal placement of VM replicas. An asymmetric virtual machine replication method to improve the reliability and reduce the access latency has been presented by Chen et al. [16]. The proposed approach employs an active primary virtual machine and semi-active slave VM combination. Wu et al. [19] have proposed a two-stage fault tolerance method. In the first stage, the algorithm ranks the manufacturing services according to their importance or priority. Replication policies are adjusted for services according to their ranks in order to achieve a trade-off among fault tolerance and use of resources for fault tolerance. In the second stage, authors use an A*-based heuristic alternative path searching algorithm to find appropriate replacement systems for the complex services in case of failures. An adaptive Replication and Resubmission based model has been presented by Patra et al. [14] for fault tolerance in real-time cloud computing. Using a predictive model, the system detects faults and subsequently decides on fault tolerance method based on the availability of resources. Another replication based method has been put forth by Abdelfattah et al. [3] that tolerates faults by implementing replication and resubmission approaches depending on the reliability requirements. Once a task failure occurs at the node with highest reliability, the task is rescheduled to the node with second highest reliability.
A related fault tolerance approach is of checkpointing whereby a VM’s execution state is saved periodically to stable storage during failure-free execution. Upon failure, a VM retrieves its last saved state and resumes computation from that state instead of restarting from initial state. Checkpointing entails overhead of storage and communication and hence, has not been employed generally for fault tolerance in cloud. In order to perform checkpointing with low overheads, a solution of incremental checkpointing has been suggested by Gill and Buyya [17]. Each checkpoint image contains incrementally pages that have been modified since the last checkpoint. An additional reduction in the consumption of network resource was presented by Zhao et al. [6], who designed a peer-to-peer checkpoint scheme for a cloud data centre with a fat-tree topology. In this approach, the checkpoint images are kept on neighbouring host servers. It is observed that placing the storage server in the same pod in the fat tree eliminates core switches from transfer of checkpoint images. Zhou et al. [1] proposed a checkpoint-based approach to tolerate the failures of both the host server as well as the edge switches. The main motive of this scheme is to ensure cloud service reliability and to minimize network resource consumption. Amoon [8], proposed an adaptive framework that utilizes both replication and checkpointing fault tolerance approaches to develop a fault tolerant framework. Their algorithm dynamically selects the most suitable fault tolerance scheme for each allocated VM.
The present work makes use of the topology of the cloud data centre in determining a suitable host for placing the VM replica. Subsequently, an optimal host is selected based on its temperature and current usage. The aim is to increase the probability of successful recovery of a failed VM.
Proposed approach
The paper proposes a topology aware VM replication scheme for a data centre with fat tree network topology.
Reactive fault tolerance techniques.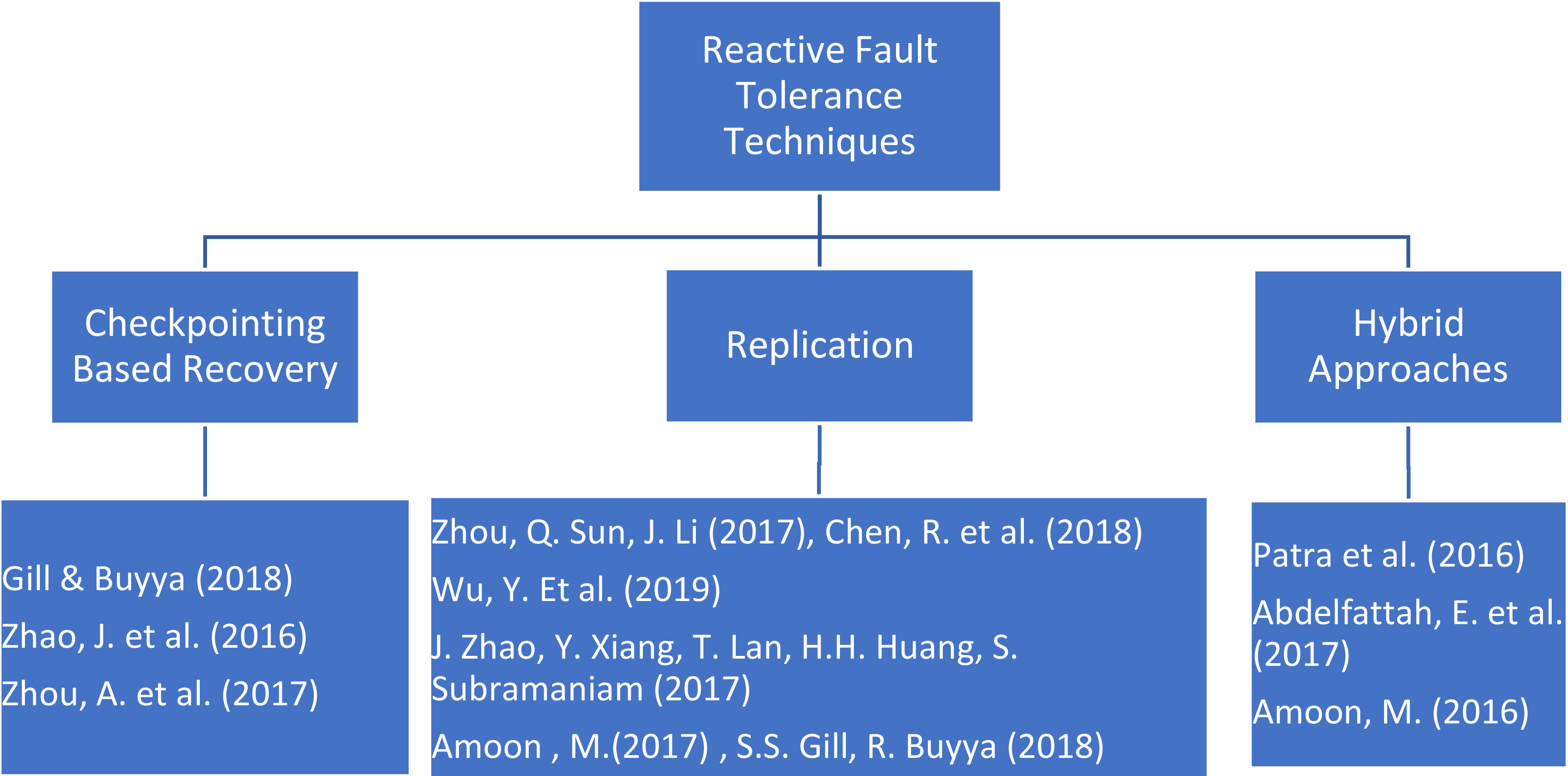
The paper considers an IaaS cloud computing system which employs fat-tree network topology architecture. The fat tree topology consists of three layers of switches as depicted in Fig. 2, where a fat tree topology with four pods is shown. The bottom layer of fat tree topology is edge switch. The link that connects an edge switch with a host server is known as edge link. The host PMs are physically linked to the network using edge switches. All host PMs that share similar edge switch are said to lie in one subnet. The middle layer of the fat tree topology is the aggregation switch. The connection that joins a core switch with an aggregation switch is known as the aggregation link. All host PMs that share similar aggregation switch with each other are said to be in the same pod. The topmost layer containing core switches is the core tier. The link that joins a core, as well as an aggregation switch, is known as core link [2, 5]. The main advantages of using fat tree topology are that all switches are indistinguishable commodity Ethernet switches. Furthermore, this topology has the benefit that it provides multiplicity of paths for communication in case the system encounters blockages of bandwidth resource. A k-port fat tree network, i.e., where every switch has k-number of ports can be constructed by using the values of Table 1.
Specifications of a fat tree
Specifications of a fat tree
Fat-tree topology architecture.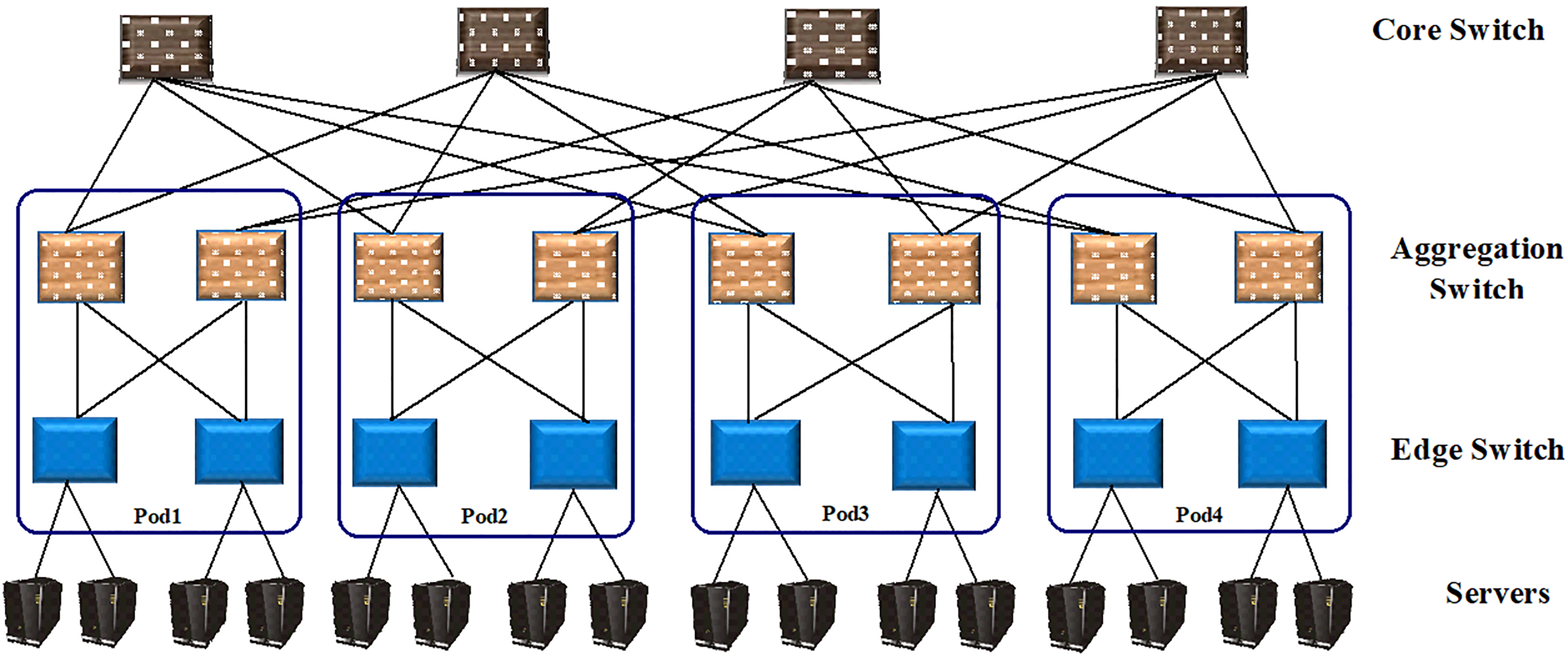
The fat tree topology architecture consists of varied host PMs, where each PM is categorized by the CPU performance, well-defined MIPS (millions of instructions per second), the bandwidth of a network, size of RAM, as well as disk storage. At any certain time, a cloud-based data centre generally serves several concurrent users. The host PM may contain n heterogeneous VMs. Users generally submit their requests for leasing n heterogeneous VMs that are provisioned on the host PMs. The VMs can be categorized by CPU performance’s requirements, network bandwidth, RAM and disk storage. The measurement of each request is quantified in MIPS [5].
The proposed scheme calculates and uses a weight, w for each physical machine (PM) in the data center. A PM is preferred for placement of a replica VM based on its weight. The weight,
A low value of a PM’s weight indicates its appropriateness for hosting a replica of a VM. CPU temperature is selected as a causal parameter since it can be used to find a deteriorating physical machine. Maintaining temperatures of machines below threshold values can improve the energy efficiency of data centres. Monitoring and forecasting of CPU temperature are crucial for avoiding failures of PMs caused as a consequence of overheating. Thus, the machines with lower temperatures are considered more suitable. Further, each PM can host up to a maximum number of VMs dependent on it’s as well as the VMs’ configurations. Therefore, a PM hosting less number of VMs currently is more preferable as a candidate PM. Therefore, lower weight of a given PM
Subsequent to calculation of weights, the proposed scheme places replicas of VMs on each host PM onto the candidate PMs. A PM can host a given number,
Virtual machine replication.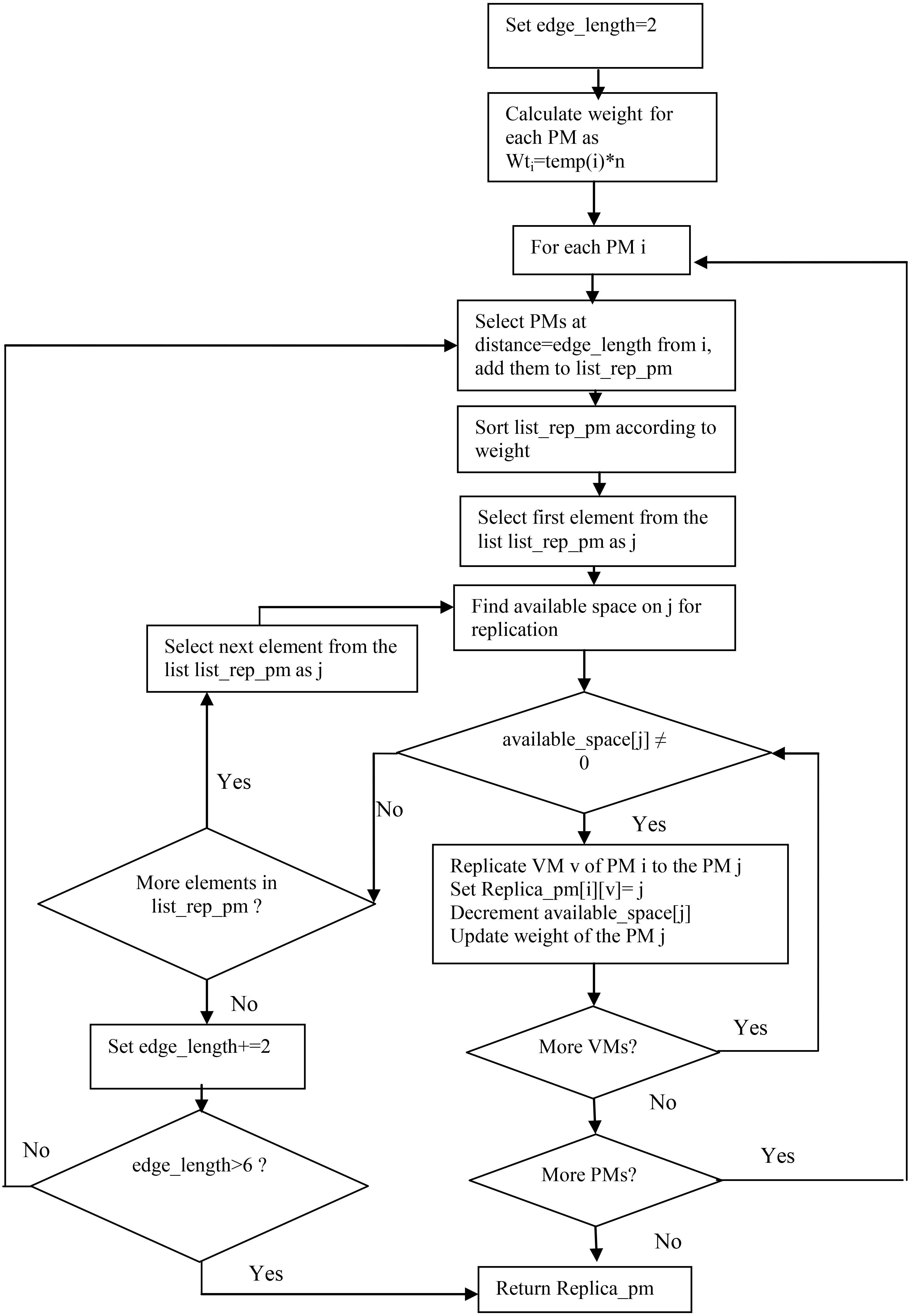
Each PM in a data centre is assumed to host one or more VMs and is referred to as the primary PM for VMs hosted by it. A backup PM is selected from other available PMs to place the replicas of VMs executing on the primary PM. For a given VM, its backup replica does not run till the primary functions normally. In case of failure of the primary, the replica on the backup PM replaces the failed VM. If failure of a VM is related to hardware failure, the replica VM obtains the required data from the central database of the service being executed. However, in case of software related failures of the VM alone, the data can be obtained from its host or primary PM.
Since a fat-tree topology is assumed, the candidate PMs are shortlisted based on their edge length from the primary PM for saving of bandwidth resource in the data centre. Therefore, firstly the PMs within the same subnet are considered. These are the PMs that are connected to the same edge switch as the host PM. If none of these can host the replica, the PMs connected to the same aggregation switch as the primary PM are considered. Only if none are found in the same subnet or pod, other PMs are considered as candidate PMs. The PM with the minimum weight out of all candidate PMs is then will be selected as the backup PM. Therefore, weight is computed for all PMs using Eq. (1) and thereafter, they are sorted in order of increasing weights. The first element from the list is checked for availability of space for an additional VM. If space is available, replica is placed on the candidate PM otherwise the next minimum weight candidate PM is selected from the list. This process continues until either
There is no space available in any candidate PM or Replicas of all VMs have been placed.
The VM replication procedure is presented in detail in Algorithm 1.
A PM may fail independently of another PM in the cloud data centre. The PM failure may occur due to several reasons such that network related failure, software or hardware faults etc. In this paper, we consider both hardware related failures of PMs and software failures of specific VMs. A VM may fail randomly due to any faults in operations being executed on this VM. Failure of a VM will not affect the other VMs executing on the same PM as itself. In this case, recovery of the VM will take place in an independent manner.
However, if a PM fails, all VMs hosted by the PM fail and need to recover. The present work has used the CPU temperature-based model for simulating the deterioration or failures of PMs [5]. A PM may fail if the CPU temperature exceeds the threshold value for maximum temperature. The temperature model is defined below:
Here, the initial sub-equation simulates the procedure of CPU temperature variation during computer boot;
An effective recovery procedure is necessary for a reliable cloud system. When one or more VMs of a host PM fail, the scheduled tasks on the failed VM may pause for a time period and are kept in the waiting queue. The recovery process is required to retrieve the replica of VMs from the backup PMs efficiently. If a failed VM recovers, all tasks in the waiting queue are rescheduled for execution. Otherwise, the scheduled task cannot be finished successfully. In case a PM fails, the recovery procedure is executed for all VMs hosted by it.
The VM recovery procedure is presented in detail in Algorithm 2.
Performance evaluation
In this section, we assess the efficiency of the proposed approach with simulation based experiments. We compare the proposed method with a random VM replication approach in terms of
Total number of successful recoveries possible and The total number of links between a VM and its replica.
A data centre with k-port fat tree network topology has been assumed for all experiments with specifications used for simulation listed as follows and in Table II. Details of number of switches for different values of k are given in Table I. For example, a data centre with 8-port fat tree topology consists of 16 core switches and 8 pods. Each pod consists of 4 aggregation and 4 edge switches. There are 4 host PMs in each subnet. Total number of PMs can be 128 and the maximum number of VMs could be 512. Similarly, a 12-port fat tree consists of 36 core switches and 12 pods. Each pod consists of 6 aggregation and 6 edge switches and each edge switch connects 6 hosts or PMs. Total number of PMs can be 432 and the maximum number of VMs could be 1728.T he simulation experiments have been performed on a system having Intel
System configuration for the proposed method
System configuration for the proposed method
The VM replication approaches are evaluated using the following performance metrics:
Recoverability: This parameter is used to compute the percentage of successful recoveries of virtual machines, and is calculated as follows:
Recoverability vs number of VMs.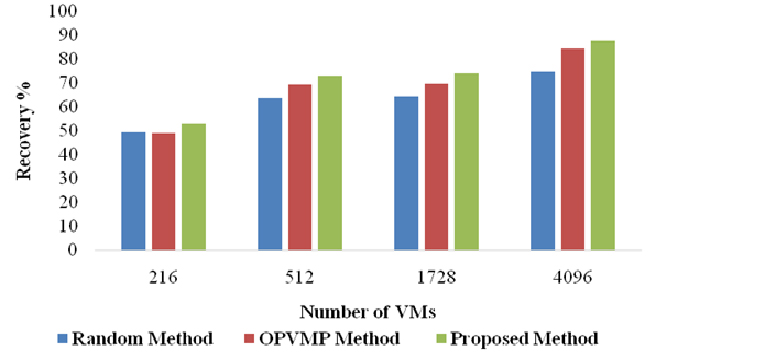
Recoverability for varied number of VMs.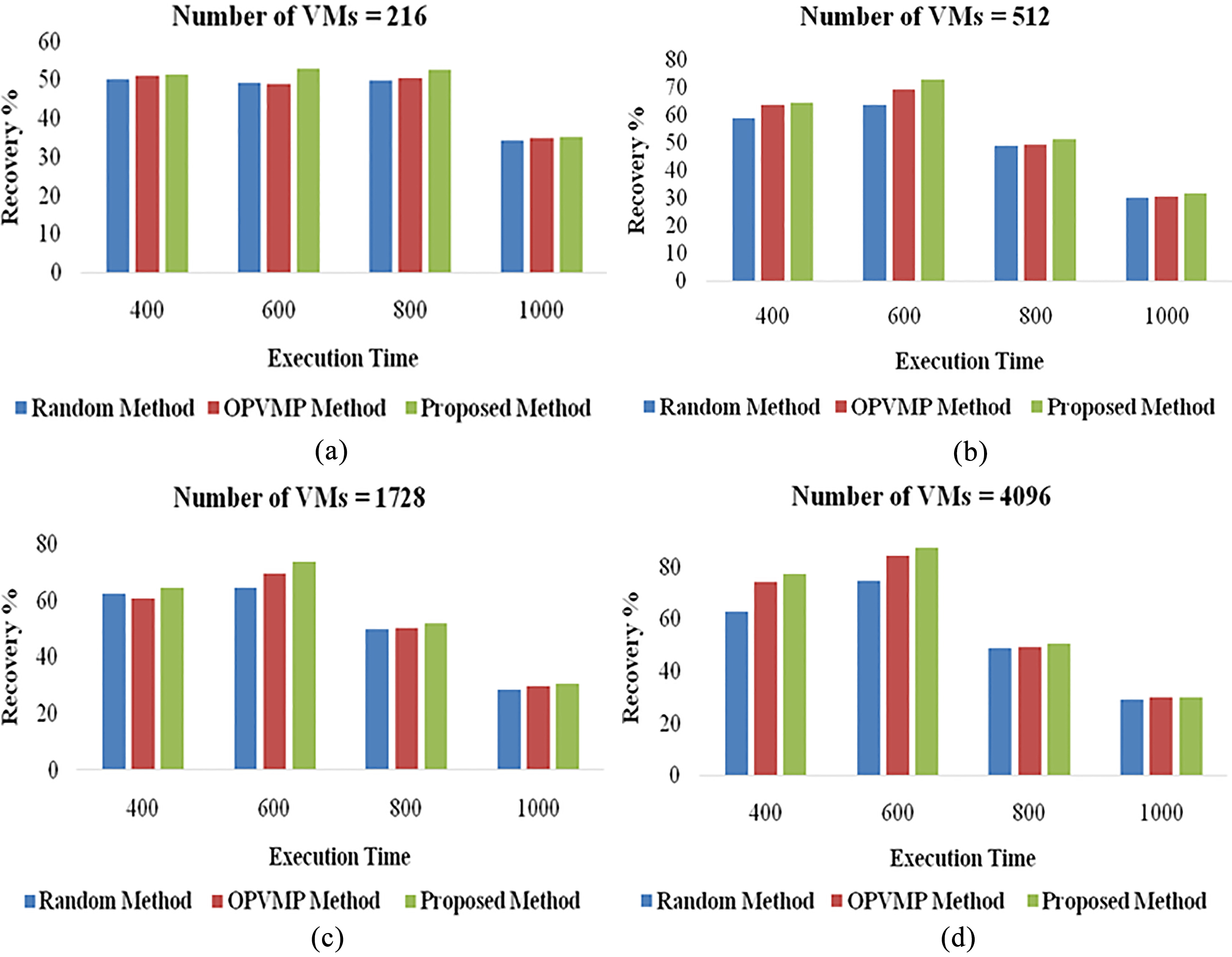
Total Bandwidth (TBW): Used to calculate the amount of bandwidth consumed in VM replication procedure. It indicates the total number of edges or links between a primary PM and a backup PM where the replica of VM is placed and is calculated as follows:
where
The objective of the proposed VM replication scheme is to maximize the recoverability and reduce the total links between VMs and their replicas. While increase in recoverability is an obvious design parameter, reducing the number of links decreases the overhead and latency of recovery.
Measuring recoverability
The first set of experiments measures the percentage of VMs that recovered successfully using the proposed method in a given period of time. The results are compared with the number of successful recoveries using a random replica placement method and a state of art algorithm, Optimal redundant Virtual Machine Placement (OPVMP) presented by Zhou et al. [1]. It can be observed from the results in Fig. 4 that the proposed scheme achieves higher recoverability, of approximately 15% on average, than the random VM placement scheme and around 6% than the OPVMP scheme. Further, as the number of VMs increase, value of recoverability does not degrade and hence, the proposed scheme is scalable in performance.
Subsequently, recoverability is measured by varying the time of simulation for different number of VMs. Figure 5 demonstrates the performance of the considered algorithms. The proposed algorithm results in higher recoverability as compared to the random approach as well as OPVMP. As time increases, there is a dip in performance of all algorithms. However, the proposed algorithm performs better than the other algorithms in all cases.
The next set of experiments evaluated the recoverability under varying rates of VM failures. Failure rate, i.e., how frequently a PM or VM fails in a specified period of time, provides a degree of reliability of the cloud computing system. Figure 6a and b demonstrates system recoverability for failure rate as 0.01, 0.05, 0.1 and 0.5 (denoting low to high rates of failures) for 512 and 1728 VMs, respectively.
Recoverability vs failure rate.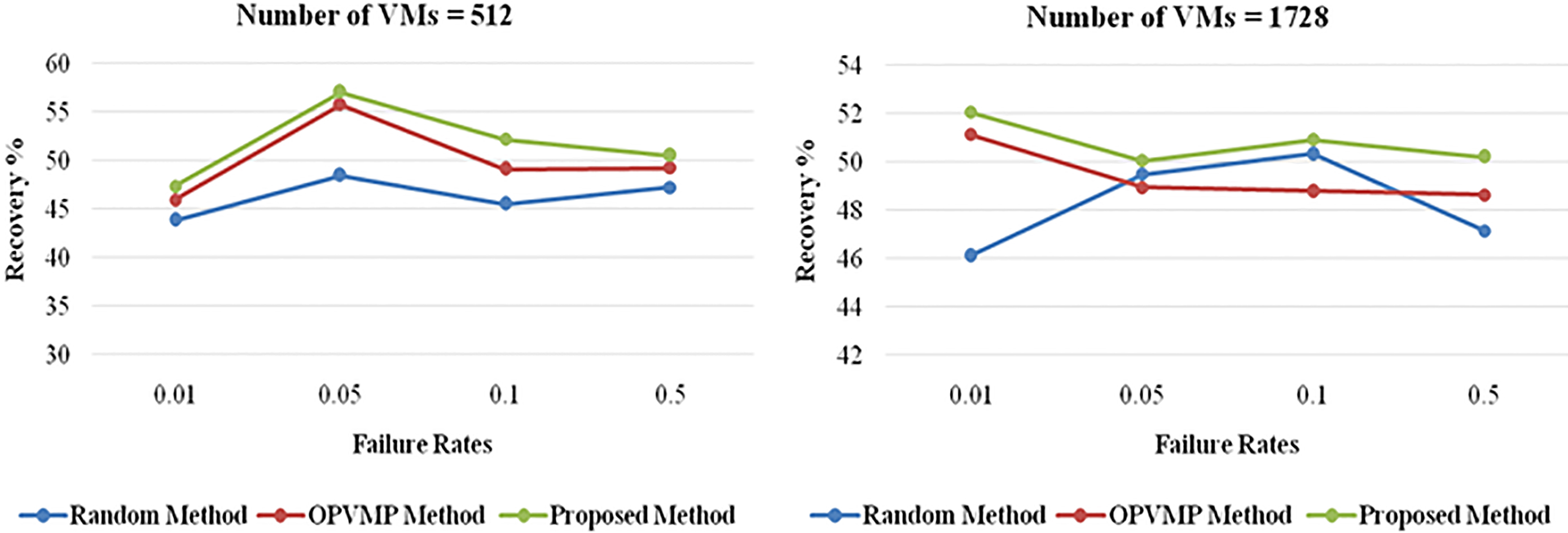
Total bandwidth consumed for replicating varying number of VMs.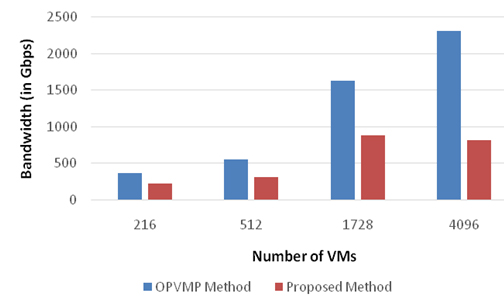
In both cases, proposed approach is able to yield a higher recoverability than the random replica placement approach as well as OPVMP. Moreover, it is observed that even with an increase in failure rate of up to 50 times (i.e. 5000%), recoverability of the system remains comparable to that for lower failure rates.
The next set of experiments is performed to assess the bandwidth consumed to place the replica of VMs on backup PMs. Figure 6 illustrates the bandwidth consumed while placing replicas of 216, 512, 1728 and 4096 VMs in a particular duration, using the proposed and OPVMP algorithms.
Figure 7 illustrates that the proposed approach consumes significantly lower bandwidth to replicate the VMs as compared to the OPVMP algorithm. This implies a saving of resources both during replica placement as well as during recovery.
Subsequently, the time taken to execute the proposed algorithm and the OPVMP algorithm were computed. The results in Fig. 8 indicate the higher time taken by OPVMP as it involves sorting operations in subnets, pods or even the whole network in worst case.
Total execution time.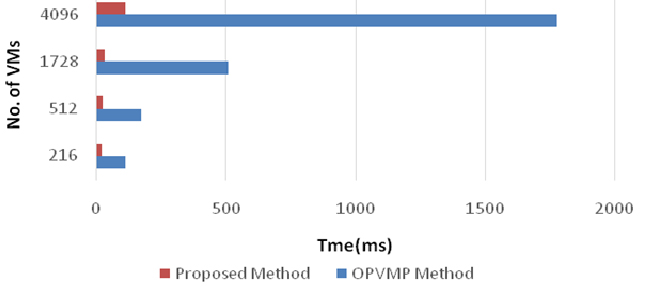
Thus, the simulations’ results demonstrate that the proposed approach offers better recovery percentage, provides scalability and requires traversal of significantly lower number of network connections than a random replication approach as well as a related, contemporary method, OPVMP.
The paper has presented a topology-aware replication-based fault tolerance method to improve reliability of cloud computing systems. The proposed approach employs a CPU temperature-based model to avoid deteriorating physical machines while placing the VM replicas. It also aims to place the replica of a VM on a physical machine closer to its host machine; thereby reducing bandwidth wastage and speeding up recovery of a failed VM. The performance evaluation has employed metrics of recoverability and the total number of links traversed in the replication process. The simulation results have illustrated that the proposed approach is successful at providing better reliability than other related and contemporary replica placement methods.
Footnotes
Authors’ Bios