
Abstract
With the rapid development of data and IT technology, cloud computing is gaining more and more attention, and many users are attracted to this paradigm because of the reduction in cost and the dynamic allocation of resources. Load balancing is one of the main challenges in cloud computing system. It redistributes workloads across computing nodes within cloud to minimize computation time, and to improve the use of resources. This paper proposes an enhanced ‘Active VM load balancing algorithm’ based on fuzzy logic and k-means clustering to reduce the data center transfer cost, the total virtual machine cost, the data center processing time and the response time. The proposed method is realized using Java and CloudAnalyst Simulator. Besides, we have compared the proposed algorithm with other task scheduling approaches such as Round Robin algorithm, Throttled algorithm, Equally Spread Current Execution Load algorithm, Ant Colony Optimization (ACO) and Particle Swarm Optimization (PSO). As a result, the proposed algorithm performs better in terms of service rate and response time.
Introduction
Cloud computing is being widely adopted as one of the most popular paradigms appeared in the last years, in both industrial and academic worlds [51]. The main idea of cloud computing is to provide related services according to users demands through the sharing of hardware resources and software programs [31]. Cloud computing architecture can be divided into three categories, which are Platform-as-a-Service (PaaS), Software-as-a-Service (SaaS) and Infrastructure-as-a-Service (IaaS). These help resources management and end-user to get their requirement application [66]. On the platform as a service level, a software layer is provided to create high level services. This platform helps users to design, develop, evaluate, and host applications on the cloud level [18]. In SaaS, the software application is offered to the end users without any customization [65]. Infrastructure-as-a-Service allows users to use IT resources remotely on a “pay-as-you-go” basis [45]. Cloud computing can be classified into four models such as Public, Private, Hybrid and Community. In the private cloud, the cloud infrastructure can be used solely by an Individual or a Single Organization. It can be handled by the Person/Member of the Organization to which it belongs [57]. Public cloud is an open network that is available on the Internet and managed by a third-party cloud service provider [48]. Hybrid cloud is a combination of two or more distinct models (private, community or public) that remain unique entities [33]. Cloud computing meets numerous challenges at increasing number of users because the demand of resources sharing and usage are increased rapidly. Therefore, load balancing between resources is an important challenge [23]. Load balancing distributes a workload across multiple entities, which can achieve optimal utilization, maximize throughput, minimize response time, and avoid overload [43].
Fuzzy logic, which may be viewed as an extension of classical logical systems, provides an effective conceptual framework for dealing with the problem of knowledge representation in an environment of uncertainty and imprecision [74]. A fuzzy set is a class of objects with a continuum of grades of membership. Such a set is characterized by a membership function which assigns to each object a grade of membership ranging between zero and one [73]. A linguistic variable is a type of variable which uses words to represent its values instead of numbers [20] (e.g. slow, medium and fast). The fuzzy inference is including fuzzification, rule base, and defuzzification. Fuzzification is a process considering crisp numerical inputs and calculations of the degree of membership for each linguistic input term [7]. The rule base contains a set of fuzzy if-then rules which defines the actions of the controller in terms of linguistic variables and membership functions of linguistic terms. Defuzzification is the process of converting the fuzzy output set into a single number [28].
Machine learning algorithms, while being complex in nature, are now being employed for complicated tasks where traditional systems are inefficient [55]. Clustering is an unsupervised learning process, which means that the data objects are clustered into several groups according to the similarities/dissimilarities among them, without prior knowledge [77]. K-means is an unsupervised machine learning algorithm, it is one of the most well-known clustering algorithms and has irreplaceable research value. Its advantages are simple thought, fast convergence speed and easy realization [30]. It groups data samples based on their feature values into
In this research, to enhance ‘Active VM load balancing algorithm’, described in the related work section, we model the imprecise requirements of memory size, processor speed and the number of processors through the use of fuzzy logic, then these parameters are considered to classify the different machines by the use of clustering (k-means algorithm). Moreover, we implement and evaluate a dynamic load balancing algorithm which could efficiently predict the virtual machine that will schedule the next job. The main contributions of this paper are summarized as follows:
The use of the fuzzy logic to represent the weight of the different VMs. The use of the k-means algorithm to cluster the virtual machines. Comparing the proposed algorithm with:
Active VM load balancing algorithm Round Robin algorithm Throttled algorithm Ant colony optimization Honey bees load balancer Particle Swarm Optimization
In this comparison, we consider the following fundamental criteria: response time, overall data center processing time, data center request servicing times, virtual machine cost and data transfer cost. The experimental scenarios demonstrate that the proposed algorithm is very competitive when compared with existing approaches.
The remainder of this paper is divided into five sections. The second section introduces the related work and the third section depicts the proposed approach. In the fourth section, we compare the proposed algorithm against Equally Spread Current Execution Load, Throttled algorithm, Round Robin algorithm, Ant Colony Optimization (ACO) and Particle Swarm Optimization (PSO). The fifth section displays the detailed analysis of the proposed approach. Finally, the sixth section is dedicated to a conclusion and some future works.
This section presents some of the frequently used load balancing algorithms available in the literature. In cloud system, there are many challenging issues that affect the performance of cloud computing and cloud service among multiple nodes, but the workload balancing and service brokering is major challenge in cloud computing [38]. Load balancing is the mechanism of detecting overloaded and underloaded nodes and then balance the load among them [53]. The benefits of load balancing would lead to maximizing the throughput, minimizing the response time, increase in resource utilization, further leading to better user satisfaction as well as increase in the overall performance of the system [24]. Load balancing algorithms are classified as static, dynamic and adaptive. In the static load balancing the cloud require prior knowledge about the system [54]. Static algorithms improve the execution time but they do not consider the current load of the virtual machine during the allocation [26]. Some static methods are min-min, spherical Robin, opportunistic load balancing (OLB) and max-min algorithms. In dynamic technique, the load balancer considers the current state of the system, and the task is allowed to move from the overloaded node to the lightly loaded node [4]. Some dynamic techniques are agent-based load balancing, honey bee behavior inspired load balancing, ant colony optimization and throttled [40]. Adaptive load balancing algorithms are a special class of dynamic algorithms [46]. They have the ability to change the rules based on the current load information.
Various algorithms of load balancing have been proposed in cloud computing to optimize different performance parameters. This section discusses about few important works.
General load balancing algorithms
This subsection presents an overview of realized works in the field of general load balancing techniques. Despite several algorithms are provided in this category, we have focused on new ones.
The Round Robin is one of the best-known and simplest algorithms for sending workloads to servers. All the nodes are aligned in a circular manner to allocate jobs without considering the current state of the virtual machines [61]. The time is divided into several slices, and each node is given a specific time quantum, and in this interval, the node will perform its operations [67]. This algorithm is not suitable for different processing performance [62].
Throttled load balancing algorithm is a dynamic algorithm that deploys completely the tasks on virtual mchines [50]. The load balancer maintains an index table that contains VMs (virtual machines) Id and its status (Available/Busy) [64]. When the data center receives the request (cloudlet), the LB scans the table and returns the Id of the first available virtual machine. If all VMs are busy then the value ‘0’ will be returned. This algorithm does not work perfectly when the virtual machines have different hardware architecture (performance).
Equally Spread Current Execution (ESCE) also called active VM load balancing algorithm, is based on spread spectrum technique. The load balancer spreads the load onto distinctive nodes, and thus, it is known as spread spectrum technique [64]. It is a dynamic load adjusting calculation, which handles the process with priority. It maintains a list of all virtual machines and jobs, then it, equally, distributes the tasks to the corresponding VMs [24]. It initially allocates VMs which are in free state. If all the VMs are allocated, the algorithm selects the VM (virtual machines) with the minimum number of allocations [37]. Table 1 summarizes the objectives, the advantages and the drawbacks of several techniques used in the literature review.
General load balancing algorithms
General load balancing algorithms
This subsection summarizes several works that investigated the Clustering and the fuzzy logic in the field of load balancing. Narender et al. [39] proposed a solution, fuzzy row penalty method, for solving load balancing problem in cloud computing environment. They used fuzzy technique for solving uncertain response time and fuzzy row penalty method for solving both balanced fuzzy load balancing problem and unbalanced fuzzy load balancing problem. This technique increases performance and scalability, minimizes associated overheads, and avoids bottleneck problem. This approach can not predict the load scheduling.
Iranpour et al. [32] proposed a distributed load-balancing and admission-control algorithm based on a fuzzy game-theoretic model for large-scale SaaS clouds. To control the admission of requests, a Self-Adaptive Fuzzy type-2 Controller containing two fuzzy controllers is introduced. The proposed algorithm is scalable, in which the control tasks are divided among application and proxy servers. This algorithm, in comparison with other algorithms, offers average response time and average processing time.
Ragmani et al. [58] proposed a hybrid algorithm based on the Fuzzy logic and ant colony optimization (ACO) concepts to improve the load balancing in the Cloud environment. This algorithm used a fuzzy module to evaluate the pheromone value in order to improve the calculation duration. It uses also the Taguchi concept for selecting the best ACO parameters.
Priya et al. [56] proposed a fuzzy-based Multidimensional Resource Scheduling model, with Fuzzy Square inference that associates cloud user query based on the fuzzy rule, to obtain resource scheduling efficiency in cloud infrastructure. The F-MRSQN method includes three stages to be performed between the users and the servers in cloud environment: obtains incoming requests from the cloud users, online Fuzzy-based Multidimensional Resource Scheduling by resource manager, and perform load optimization using Multidimensional Queuing Network.
Adhikari et al. [2] proposed a load balancing approach, referred as LB-RC (load balancing resource clustering), for finding the optimal set of servers for task assignment to balance the load of the servers in a long-term process. The algorithm is divided into four phases, resource clustering, merging of clusters, resource optimization, and task assignment policy.
A heuristic based load balancing algorithm is developed by authors in [75], where the clustering approach is used. They have applied Baye’s theorem to obtain optimal clusters of physical hosts available for load balancing.
Kapoor et al. [36] proposed an algorithm, Cluster based load balancing, which works in heterogeneous nodes environment, considers resource specific demands of the tasks and reduces scanning overhead by dividing the machines into clusters. Table 2 presents an overview of realized works that use Clustering and fuzzy logic to balance th load over cloud system.
Cluster and fuzzy-based load-balancing algorithms
Cluster and fuzzy-based load-balancing algorithms
In this subsection we present a set of works which have adopted nature inspired load balancing algorithms. Ant Colony Optimization (ACO) is a meta-heuristic approach based on the behavior of real ant while they search for their food [5]. Ants deposit a chemical substance on their path called pheromone. Other ants can smell pheromone and they tend to prefer paths with a higher pheromone concentration [21]. Like the ant find the optimum path to find the foods, communication and data transfer took part in optimum way [64]. With an ACO Algorithm we can build the shortest paths from a combination of several paths [63].
Honey Bees algorithm is derived from a detailed analysis of the behavior that honey bees adopt to find and reap food [41]. It consists of scout bees, forager bees and food source. Scout bees are responsible for searching food source randomly, employed bees share information of food to the onlooker bees, and onlooker bees discover the amount of nectar and compute the probability [23]. Finally, they return to their hive and do waggle dance to inform others about quality/fitness of food source [41]. This algorithm is suitable for independent tasks but it does not work perfectly in the case of dependent ones.
Particle Swarm Optimization (PSO) was first proposed by Eberhart and Kennedy in 1995 [42]. It is inspired by the social behavior of animal and swarm theory. It has several advantages, including quick convergence, high precision and relatively easy implementation [3]. This algorithm initializes randomly a swarm in population [47]. The swarm consists of many particles where each has its position, velocity, and current objective value [17]. Table 3 describes a number of existing nature inspired load balancing algorithms.
Nature inspired load balancing algorithms
Nature inspired load balancing algorithms
Due to the weakness of each of the meta-heuristics mechanisms, they must be combined to achieve a very efficient load balancing in cloud computing [52].
Cho et al. [11] combines ant colony optimization and particle swarm optimization to solve the VM scheduling problem. This algorithm uses historical information to predict the workload of new input requests to adapt to dynamic environments without additional task information and rejects requests that cannot be satisfied before scheduling to reduce the computing time of the scheduling procedure.
Shojafar et al. [60], propose a hybrid approach using the fuzzy theory and Genetic Algorithm (GA) to do optimal load-balancing by considering the execution time and cost. The proposed algorithm allocates the tasks to resources by considering, virtual machine memory, virtual machine processing speed, job lengths, and virtual machine bandwidth.
A hybrid meta-heuristic is proposed in [27] using nature inspired genetic algorithm and particle swarm optimization approaches. The algorithm takes advantages of both the algorithms by avoiding slower convergence rate of GA and local optimum problem in PSO. In Table 4 we describe a number of existing hybrid load balancing algorithms and determine some defects and advantages of them.
Hybrid load balancing algorithms
Hybrid load balancing algorithms
This section introduces the proposed load balancing algorithm. The main objective of this work is to propose a meta-heuristic algorithm adapted to a Cloud environment. The aim is to reduce the response time and to improve the use of resources.
To enhance active virtual machine load balancing algorithm, the proposed approach is structured in two main phases. First, weightings the different nodes, where we apply fuzzy logic to assign weights to the corresponding virtual machines based on its characteristics.
Second, the Clustering phase: This step consists of grouping several virtual machines into clusters using k-means clustering algorithm. This architecture allows to assign tasks to the most favorable virtual machine according to the hardware characteristics such as memory, processor speed, the number of processors, etc. Figure 1 describes the framework used to develop and implement the fuzzy clustering load balancer algorithm.
Weighting virtual machines using fuzzy logic and k-means.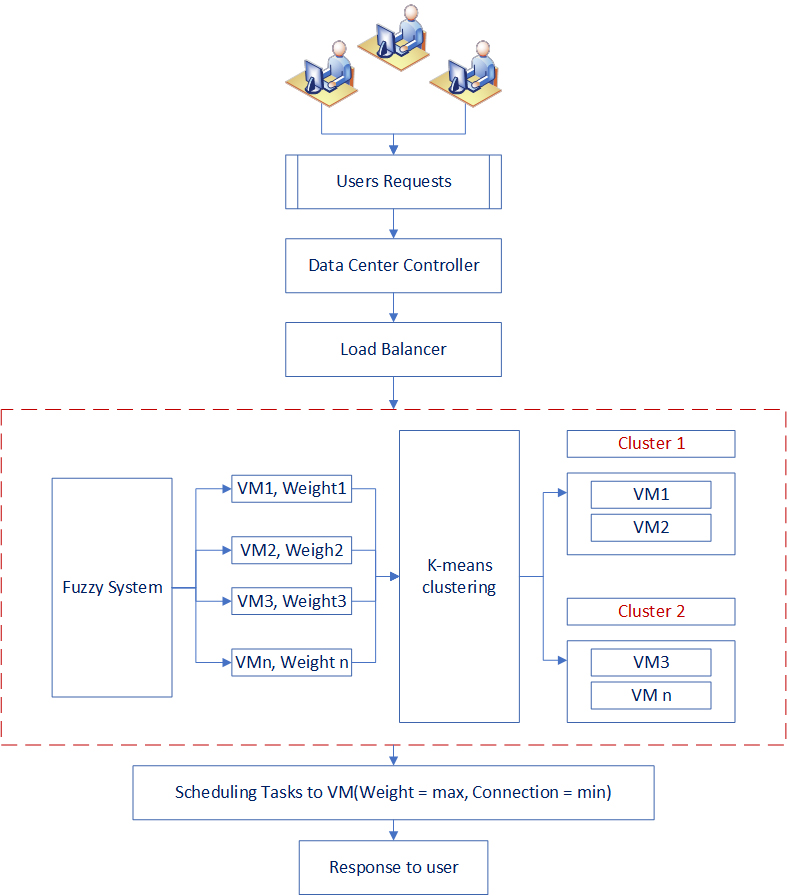
This section gives details on the steps involved in design of the fuzzy logic controller to weighting each virtual machine based on its characteristics: processor speed, number of processors and memory size. The fuzzy controller used in the proposed work includes: Fuzzification, knowledge base, Fuzzy Inference System (FIS) and Defuzzification. The basic structure of a fuzzy controller is shown in Fig. 2.
Fuzzy controller.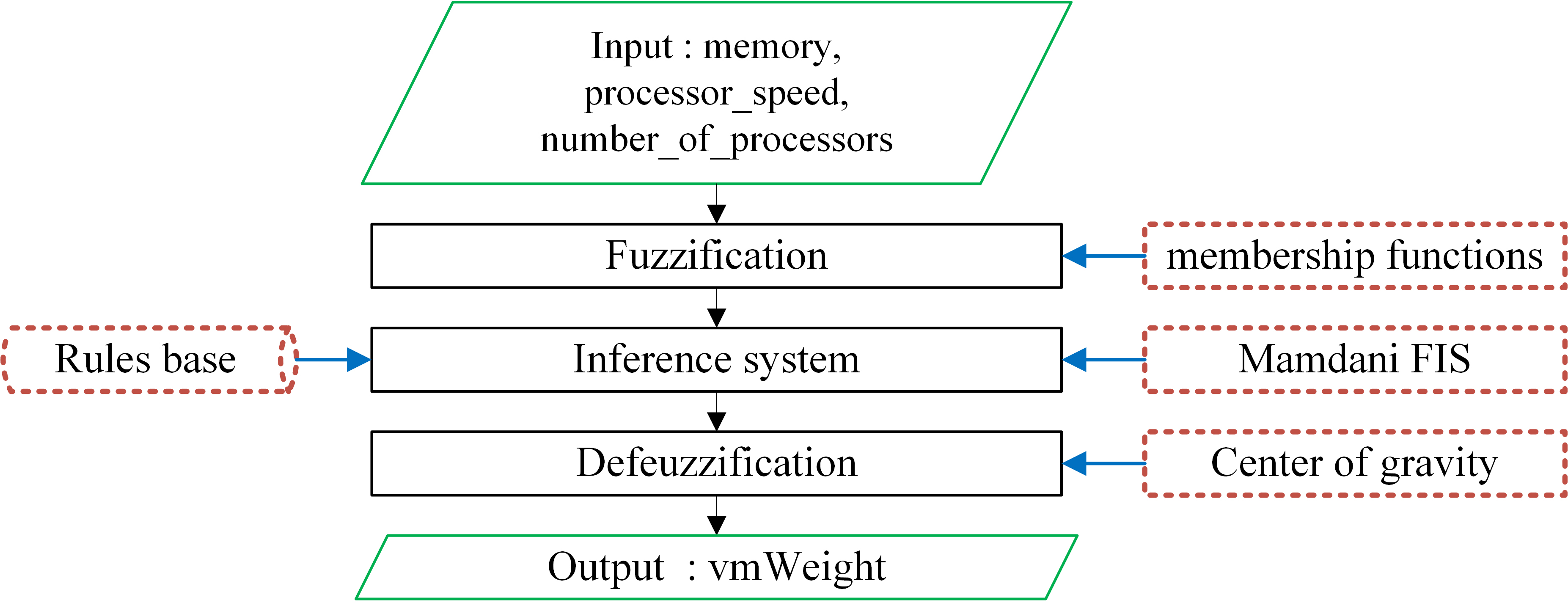
Fuzzification allows to convert crisp values into linguistic terms (linguistic variables), we consider five fuzzy linguistic variables: memory (verySmall, small, medium, large, veryLarge), processor speed (verySlow, slow medium, fast, veryFast) and number of processors (veryLow, low, medium, high, veryHigh). Trapezoidal shapes of membership functions are used in this configuration. Figure 3 shows member membership functions generated by our program.
Membership functions.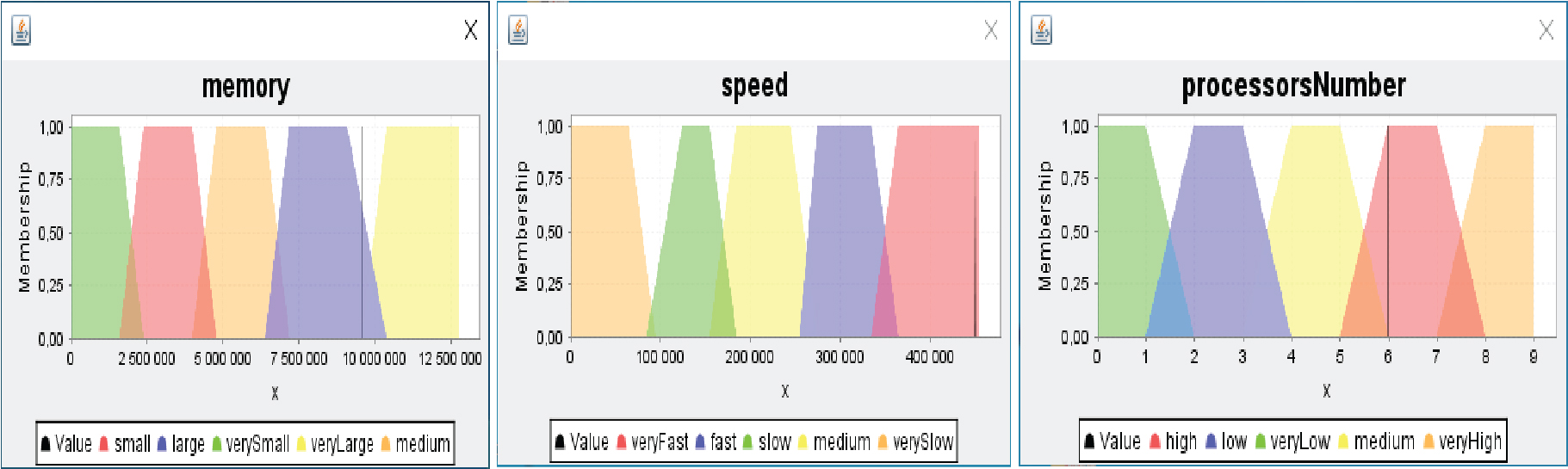
Several rules are needed to describe the relationships between the results desired and the data available. These rules map the fuzzy inputs to fuzzy outputs. Fuzzy rules are expressed as a collection of “IF-THEN” statements. They can be easily implemented using fuzzy conditional statements in fuzzy logic. Some rules of the proposed knowledge base are described in Algorithm 1. The inference engine handles the way in which rules are combined. Mamdani Fuzzy Inference System (FIS) is used in this approach, and it is expressed as [49]:
where
Defuzzification is the process of obtaining crisp number from the fuzzy output. For the defuzzification model, the associated linguistic variables used to describe the performance of each node (VM) are: veryLow, low, medium, high, veryHigh. We adopt the method of the ‘Center of Gravity’ determined according to following equation [71]:
where
Defuzzification using COG.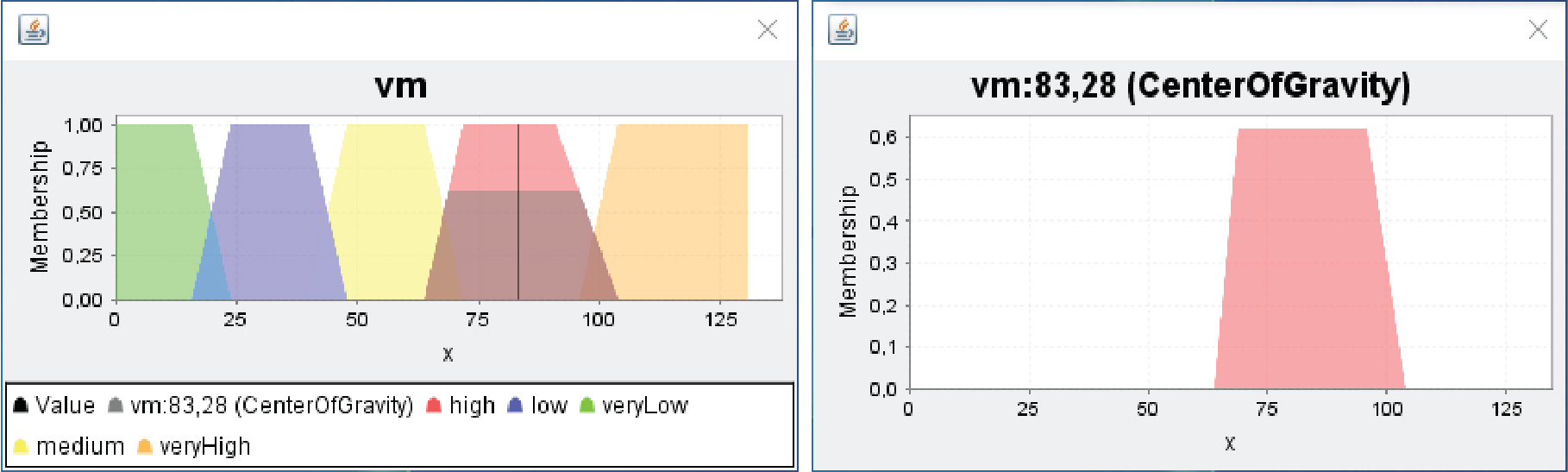
The Implementation of fuzzy controller using java API of the proposed approach is illustrated in Algorithm 1.
[h!] Pseudo-code: Fuzzy controller in FCL languageFUNCTION_BLOCK WEIGHT// Block definition
VAR_INPUT speed: REAL; processorsNumber: REAL; memory: REAL;
VAR_OUTPUT vm: REAL;
FUZZIFY memory // Fuzzify input variable ‘memory’
TERM verySmall:=(0, 1) (1604800, 1) (2404800, 0);
TERM small:= (1604800, 0) (2404800, 1) (4004800,1) (4804800,0);
TERM medium:= (4004800, 0) (4804800, 1) (6404800,1) (7204800,0);
TERM large:= (6404800, 0) (7204800, 1) (9104800, 1) (10404800, 0);
TERM veryLarge:= (9604800, 0) (10404800, 1) (12804800, 1);
END_FUZZIFY
……. //In the same way, we define the other parameters
RULEBLOCK No1
RULE 1:IF (memory IS verySmall) AND (processorsNumber IS veryLow) AND (speed IS verySlow) THEN vm IS veryLow;
…
END_RULEBLOCK
END_FUNCTION_BLOCK
Scheduling of
The proposed algorithm uses clustering approach to divide VMs with similar capacities into groups. K-means clustering approach has been used to divide VMs into clusters. This will reduce the time required to find optimal VM for task migration. The load balancer maintains a list of VMs in each cluster. The proposed approach is dynamic, centralized, heterogeneous and it considers the performance of virtual machines, it also allocates the virtual machines which have least number of allocations and in a way that the workload is kept distributed effectively. The clusters are sorted in descending order according the obtained weight (from the fuzzy processing, described in the previous section) of the correspondent virtual machines. The proposed technique selects a VM which has highest capacity and lowest number of allocations as target VM. Algorithm 3.2 presents a pseudo-code of k-means algorithm used in our program.
[h!] Algorithm k-meansK: the number of clusters A set of k clusters
D: a data set containing n objects Select k points as initial centroids arbitrarily (the centroid positions do not change) each centroid c Estimate the Distance
In this research, we use the Euclidean Distance which is majorly used in k-means for computing the distance among data objects, It is computed as [8]:
where
Virtual machines clustering using k-means.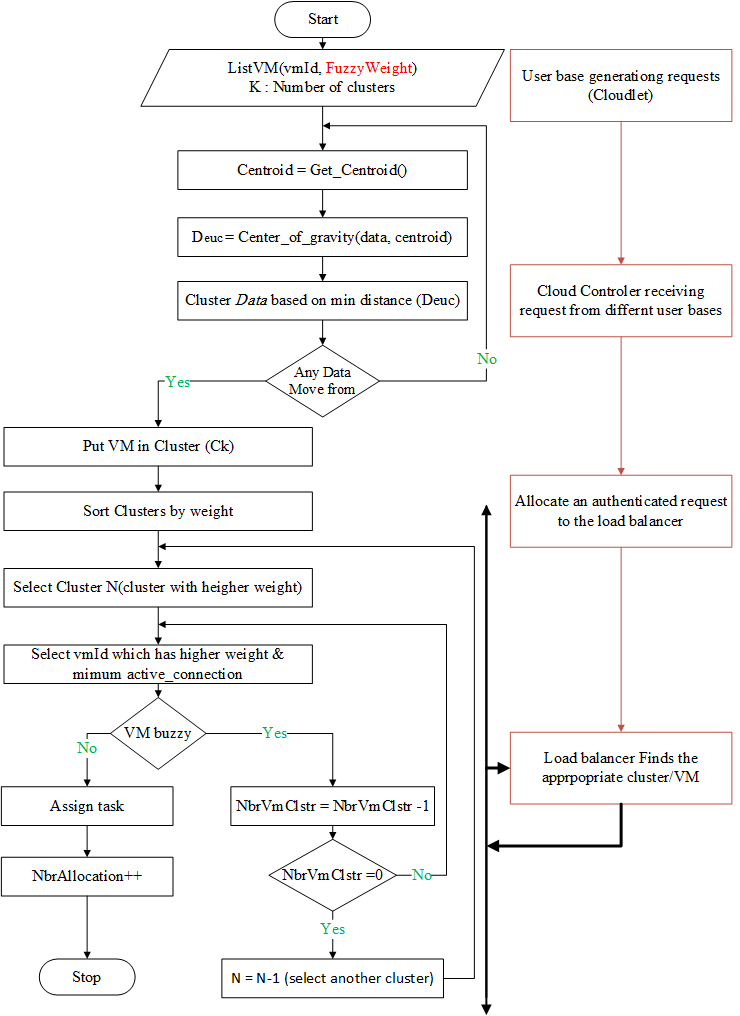
Figure 5 presents a flowchart of the main steps of the method described in Algorithm 2.
The procedure of clustering technique is described in Algorithm 3.
[h!] Algorithm clustering VM R: Request (cloudlet) VmId which will handle the request maintains an index table of VMs initialize VMs status (Available/Busy) available VM is not allocated create a new one Clustering the VMs into K clusters using k-means algorithm Sorting Clusters by weight Job scheduler receives new task each cluster calculate the number of requests currently allocated to the VMs identify the VM whose active task count is least and vmWeight is max Vm is busy Increment the number of busy Vms go to 10 vmID
[h!] Pseudo-code getStoredClusters function public ArrayList<List<Entry<Integer, Double> > > getStoredClusters() throws Exception { //***** Clustering Data using weka library ****************** SimpleKMeans kmeans = new SimpleKMeans(); kmeans.setNumClusters(numberOfClusters); data = Filter.useFilter(data, filter); kmeans.buildClusterer(data); //********* sorting Clusters by Centroid ********************** aListClusters = getSortedClstrCentoid(); /*sorting clusters by weight basis of sorted list of centroids using function getSortedClstrCentoid*/ sortedClusters = getSortedClusters(aListClusters); return sortedClusters;}
Algorithm 3 is described by the flowchart shown in Fig. 6.
Flowchart-clustering virtual machines.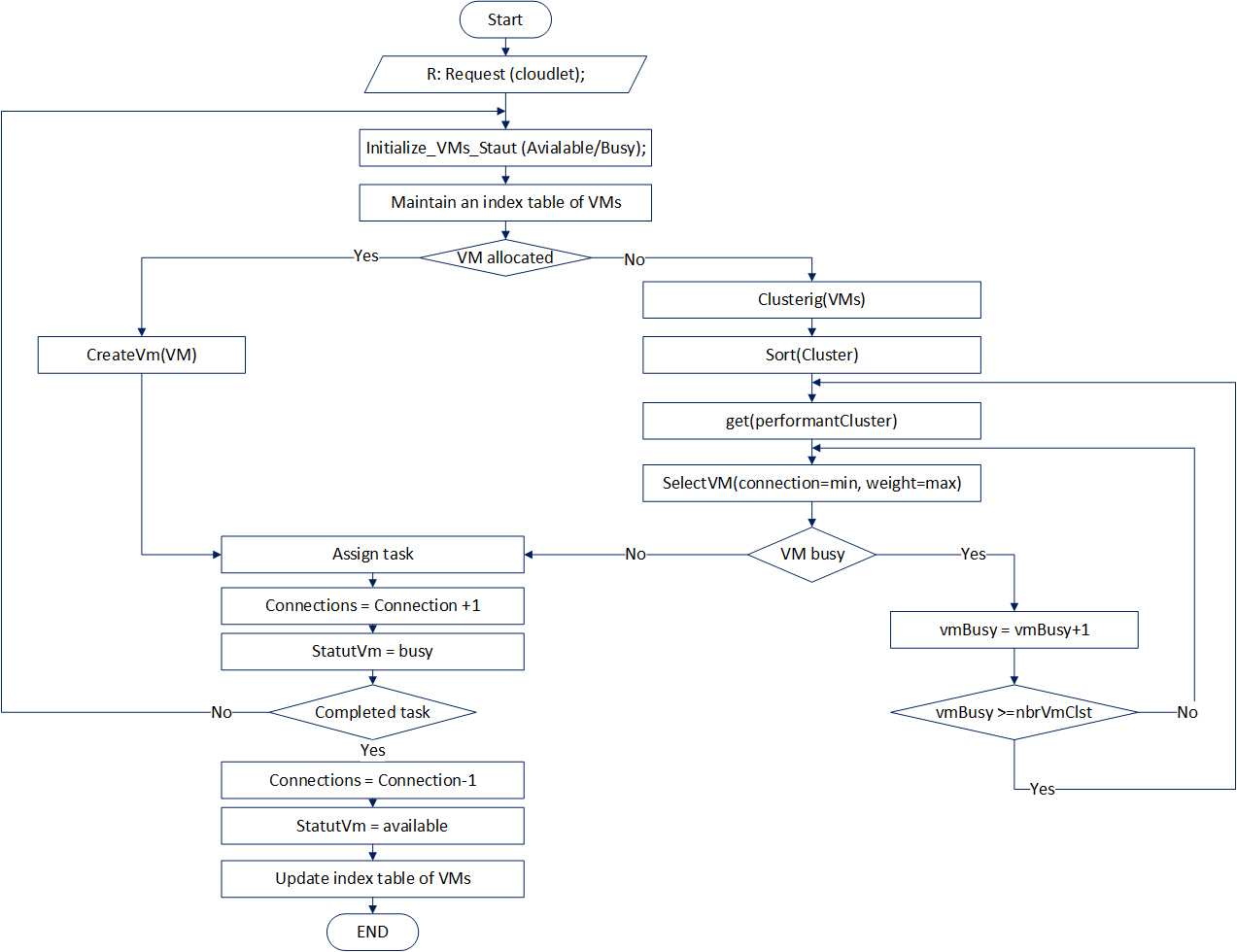
The implementation of virtual machine clusters using java API and Weka Library is shown in Algorithm 5.
An implementation in Java code for the main function getNextAvailbleVM() of the proposed load balancer is shown in Algorithm 6.
[h!] Pseudo-code – load balancerpublic int getNextAvailableVm(){ //If all available vms are not allocated, allocate the new ones if available(vmId) { vmId = allocateNewOnes(); } else { vmId = vmClusteringFuzzyWeights(); } allocatedVm(vmId); return vmId; } //***** Function vmClusteringFuzzyWeights ******************int vmClusteringFuzzyWeights() { //weights used bellow are obtained after execution of fuzzy logic processing getSortedClusters(); /* Start with the most perfomant cluster, if all VMs in this cluster have maxCount or all VMs are busy, go to the next cluster */ if (connectionCount >= maxCount) || (allVmState = basy){ nextCluster(); } else { vmID = getVM(weight = max, commections = min);} return vmId;}
Based on the weights obtained after executing of fuzzy logic, Algorithm 6 classifies the virtual machines in clusters. The clusters are sorted in a descending order according to the obtained weights using the getStoredClusters function described in Algorithm 5. The load balancer selects the most performant cluster and counts the number of allocations of each VM. If all VMs in this cluster have max allocations, the load balancer will select the next cluster. Algorithm 6 assigns tasks to the VMs which belong to the most performant cluster and share the minimum allocation count. If a set of VMs have the same minCount, the load balancer will allocate the one that weighs more. If a cluster is not loaded (
In order to verify the performance of the proposed algorithm, we discuss, in this section, the experiment details of this work and evaluate it by depicting charts. To further demonstrate the effectiveness of the proposed technique, numerical results have been compared with a set of algorithms in the literature addressing the problem of workload in cloud computing environment.
We used fuzzy logic to represent the weights of different virtual machines based on their hardware characteristics. The basic structure of the fuzzy controller consists of four conceptual components: rule base, fuzzification, inference engine, and defuzzification. The task of converting input variables into linguistic term set is in the responsibility of the fuzzifier of this system. The responsibility of converting the fuzzy output of the fuzzy inference engine to a crisp value is in responsibility of defuzzifier, the fuzzy inference engine is also responsible for obtaining fuzzy output using the rules defined and stored in the database. These virtual machines are grouped into a cluster, using the famous non-hierarchical classification algorithm: K-means, according to their performance, ie their weight. The tasks will be assigned to virtual machines having more weight and having a minimum number of connections.
Tools and configuration
For the experiments, we use the following tools to evaluate our algorithm: CloudAnalyst, jFuzzyLogic v3.0, Weka Library 3.8 and JFreeChart Library 1.5.0. The simulation is conducted on Ubuntu 20.04.1 LTS, Linux Platform, Eclipse IDE 2020–06 and Java 1.8.0_201.
Example of interface.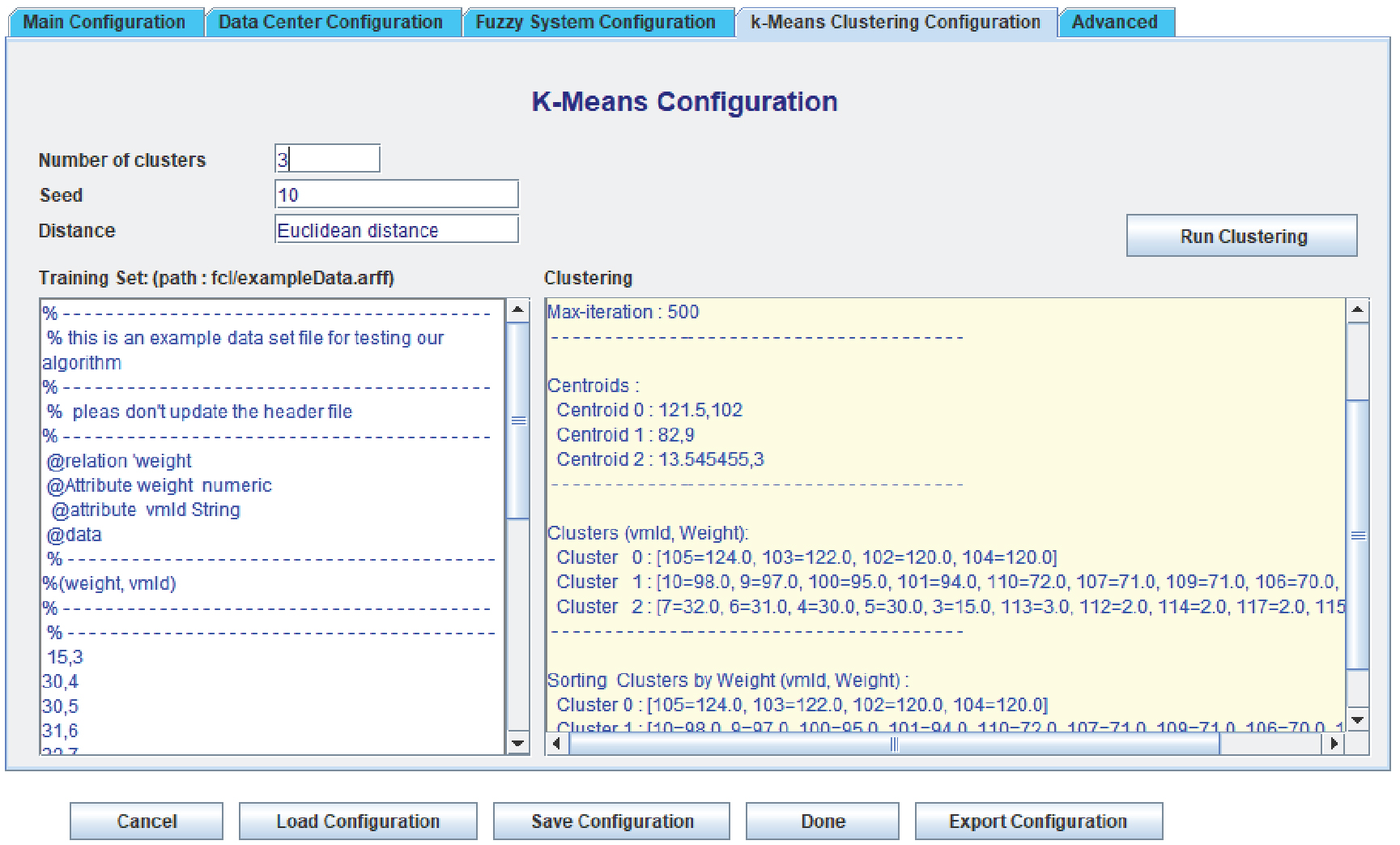
Figure 7 shows an example of an interface generated by our program, it allows to configure the settings of k-means algorithm used in the proposed load balancer. The work is simulated with six regions where data centers are available with region code (0–5). Data centers contain a set of hosts and help in managing the characteristics of virtual machines like RAM, Processing Elements, Central Processing Unit, Bandwidth, Million instructions per seconds (MIPS), Timeshared Scheduling Policy. etc. Table 5 summarizes a sample of five DC configurations which contains the characteritics of the virtual machines such as the speed range, the number of processors and the size of RAM.
Data centers
In the GUI, we configure ‘Advanced Configuration Parameters’ to include the ‘Client Grouping Factor’ with the value 1000, ‘Service Broker Policy’ used is ‘Closest Data Center’, the ‘Enquiry Grouping Factor’ is set to 10, the ‘Executable Instruction Length per Enquiry’ is 500 Byte and ‘Simulation Duration’ is set to 60 days.
In this section, we discuss the simulation result based on the following parameters: ‘Response Time’, ‘Data Center Request Servicing Time’ and ‘Processing Cost’, and their comparison with the existing Load balancing algorithms:
Our algorithm Fuzzy Clustering Load balancer (FCL) Equally Spread Current Execution Load algorithm (ESP) Round Robin algorithm (RRB) Throttled algorithm (THR) Ant Colony Optimization (ANT) Honey Bees load balancer (BEE) Particle Swarm Optimization (PSO)
In Table 6, we compute the overall response time and the DC processing time in a millisecond of the data center. The results are obtained after the execution of the different algorithms: our work, Equally Spread Current Execution Load, Round Robin, Throttled algorithm, Ant Colony Optimization (ANT), Honey Bees load balancer and Particle Swarm Optimization (PSO).
Overall response time
Overall response time
Figures 8 and 9 show the comparison of average response time and data center processing time for the different algorithms.
Overall response time.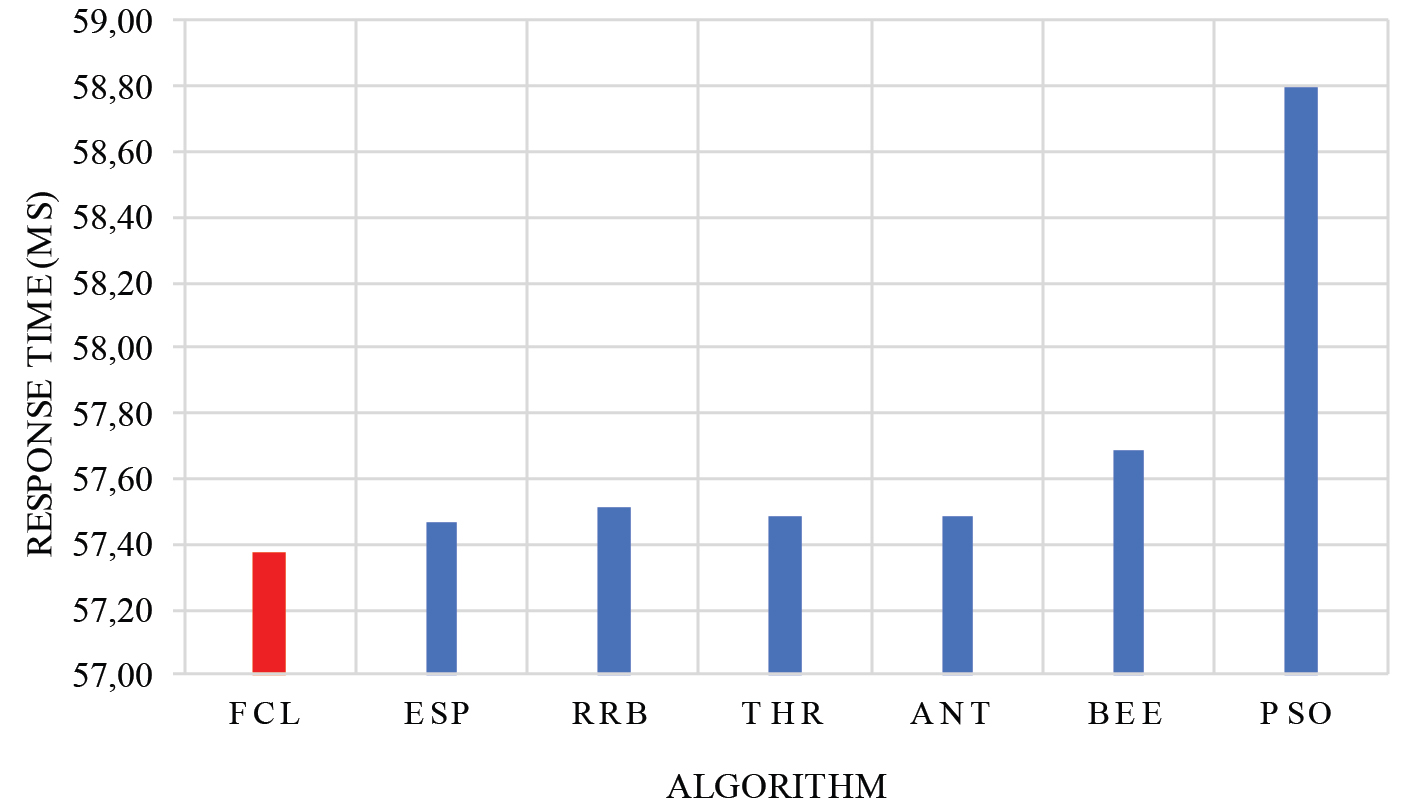
Data center processing time.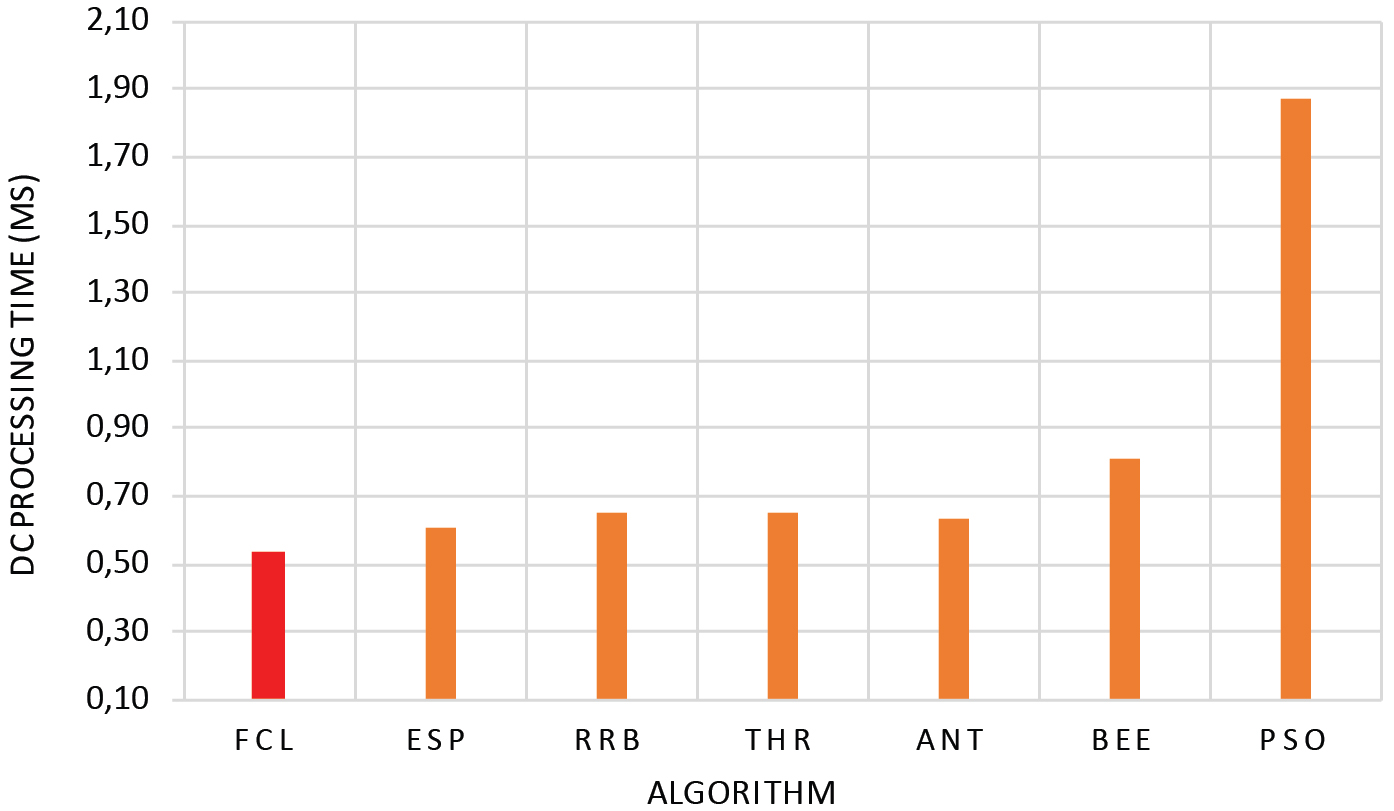
From Figs 8 and 9, it can be seen that compared to other techniques, the proposed algorithm yields better in terms of response time and data center processing time. That is because the FCL avoids under-load and over-load of VMs.
In this section, we conduct an empirical evaluation of the ‘data center request processing time’ for each algorithm. This factor presents the time spent to forward a user’s request to a data center. A summary of the obtained results is presented in Table 7 that includes a sample of nine elements.
The average ‘data center request processing time’ for various algorithms is depicted in the graph obtained as shown in Fig. 10.
DCs request servicing time
DCs request servicing time
Data center request servicing times.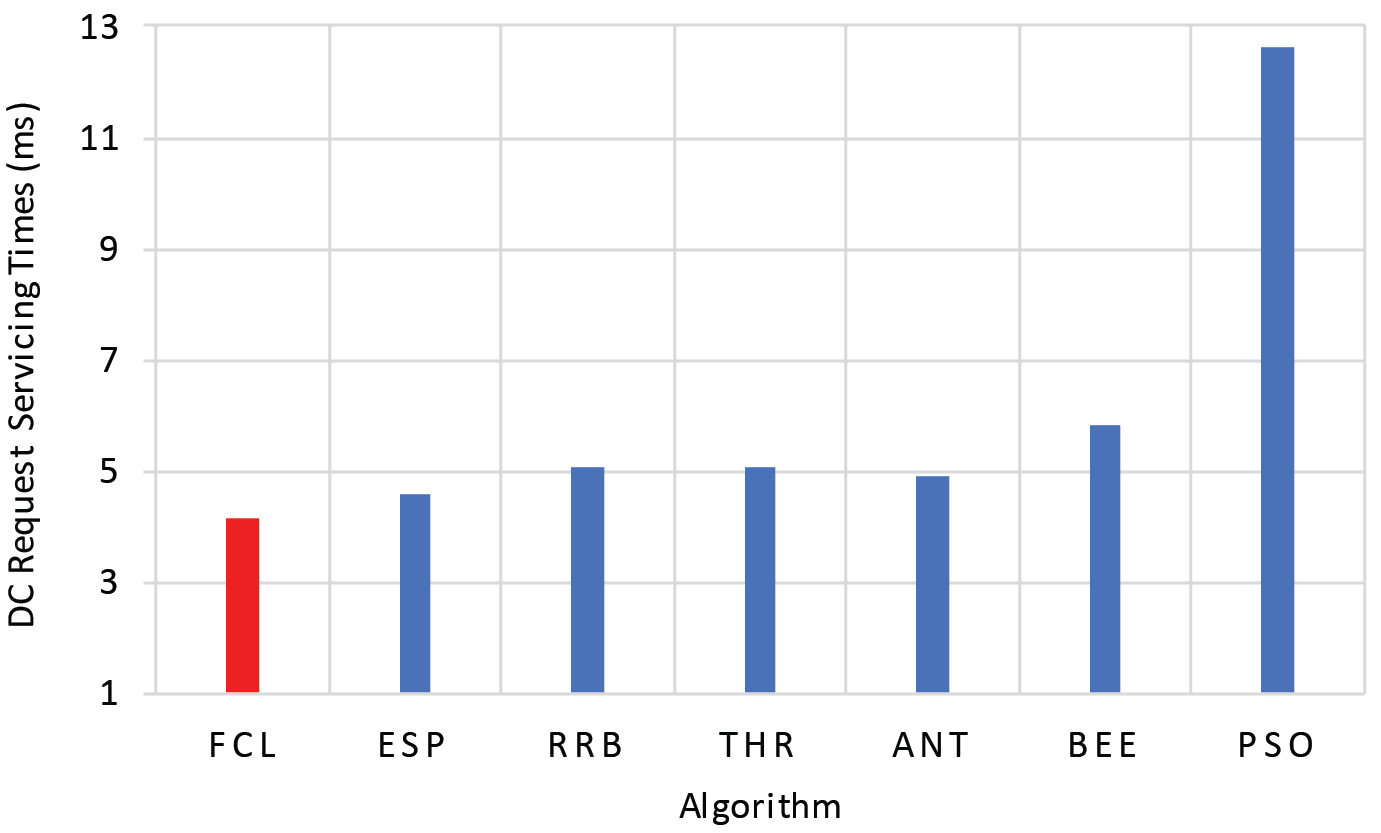
From Fig. 10, we deduce that the ‘Data Center Request Servicing Time (DCRST)’ in the proposed algorithm (FCL) is shorter than it takes in the other load balancer algorithms. Because in this approach, tasks are forwarded to the most performant virtual machines with least number of allocations. Thus, the fuzzy clustering load balancer reduces the data center Request Servicing Time and improves the resources’ use.
Now, we compare the performance evaluation in terms of the ‘processing cost’ that can be obtained by computing the sum of the ‘overall virtual machine cost’ and the ‘total data transfer cost’. Table 8 includes a sample of nine elements.
Overall processing cost
Overall processing cost
Figure 11 shows the comparison between the seven services load balancer algorithms.
Overall processing cost.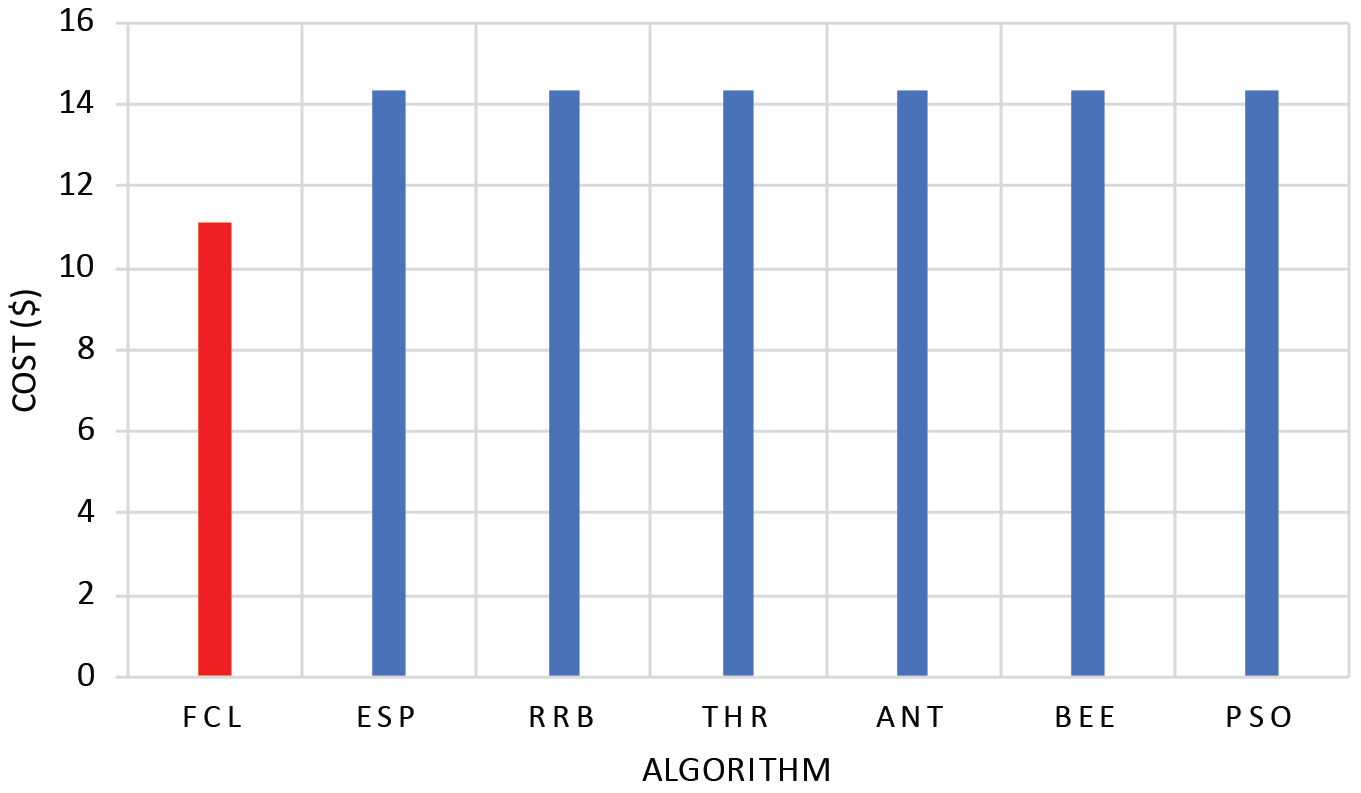
Table 8 illustrates that the ‘processing cost’ depends, in some cases, on the weight of each node. This is because the FCL (our algorithm) assigns tasks to VMs according to their loads, availability and weights i.e., tasks are assigned to the most performant VMs. This can lead to a minimum ‘transfer cost’ and a slightly higher ‘processing cost’ compared to other algorithms.
Though there are several works available in the literature, some of the methods do not consider the characteristics of cloud computing environment yet, it needs to improve the performance in several aspects [16]. Therefore, there are opportunities to improve resource utilization, response time, and cost in the existing system. Active virtual machine load balancing algorithm, also called Equally Spread Current Execution (ESC) is one of the best-known and simplest algorithms for sending workloads to servers. However, this algorithm has a problem that it does not consider the specific characteristics of each virtual machine such as: performance, memory size, speed of processors, etc.
In this paper, we propose to enhance the aforementioned algorithm through the use of fuzzy logic and non-hierarchical clustering technique (k-means), which is an unsupervised learning algorithm.
Comparison of load balancing algorithms
Comparison of load balancing algorithms
The proposed FCL algorithm has been simulated using CloudAnalyst and compared against active VM Load Balancing algorithm (known as ESP), Round Robin algorithm (RRB), Throttled algorithm (THR), Ant Colony Optimization (ANT), Honey Bees load balancer (BEE) and Particle Swarm Optimization (PSO). The comparison between existing works considers different metrics which are: Response Time, Data Center Request Servicing Time and Processing Cost. Experiments demonstrate that the proposed algorithm (FCL) reduces the response time, minimizes the processing cost and improves data center processing time. Moreover, in a few occasions, the FCL costs slightly more than the other approaches at some nodes. This issue is because the virtual machines, in such situation, are used more frequently. In Table 9, we make comparison between the proposed approach and the existing algorithms based on different aspects, such as the main aims of the work, its advantages and the drawbacks of the scheduling algorithms.
The cloud computing is commonly used by users. The technology of load balancing is not exploited to its full potential. The overall performance of cloud environment depends on the results of the techniques used to redistribute workloads among different nods, and to assign tasks to the appropriate VMs. This paper presents an enhanced algorithm based on fuzzy logic and k-means clustering, for optimizing load balancing in modern cloud computing systems. Virtual machines are arranged in a cluster form. This management improves the CPU utilization and redistributes the load efficiently. This work aims to enhance the performance of cloud system using clustering and fuzzy controller. The algorithms are implemented in the CloudAnalyst simulator. As shown in the results of the experiment, the proposed algorithm has obvious performance advantages concerning the overall performance, the throughput and load balancing adeptness.
In future research, we plan to improve the load balancing by considering other parameters such as bandwidth.
Footnotes
Author’s Bios