
Abstract
Data-intensive cloud computing systems are growing year by year due to the increasing volume of data. In this context, data replication technique is frequently used to ensure a Quality of service, e.g., performance. However, most of the existing data replication strategies just reproduce the same number of replicas on some nodes, which is certainly not enough for more accurate results. To solve these problems, we propose a new data Replication and Placement strategy based on popularity of User Requests Group (RPURG). It aims to reduce the tenant response time and maximize benefit for the cloud provider while satisfying the Service Level Agreement (SLA). We demonstrate the validity of our strategy in a performance evaluation study. The result of experimentation shown robustness of RPURG.
Introduction
Cloud computing has become a common solution in both government and industry for storing and processing large-scale data in the last decade. As the Cloud’s base device, data centers are capable of providing nearly infinite computing and storage capacity cost-effectively to meet the needs of users, i.e., tenants. Recently, the advent of huge-scale cloud-based systems has increased competition for vast data storage facilities in cloud services. Furthermore, vast volumes of data are being processed in data centers since more and more cloud based systems continue to be data consuming.
Modern distributed storage structures typically usually use data replication to ensure high data availability, performance and fault tolerance [32]. This improves the user’s queries that can be called from closest locations by requiring the data file to replicate. Creating replicas for data files that have more accessing frequency is very useful. The next question facing them is determining where the latest replicas will be mounted for guarantying consistency. Indeed, if replicas are randomly put in a chosen node, this does not result in improved system performance [35].
In order to cope with the heterogeneity of workload in cloud systems, a number of data replication strategies is being proposed to maintain at the required levels of satisfaction between users and providers [36]. In this context, the provider and its clients conclude utility-related Service Level Agreements (SLAs) to assess costs and fees depending on the output rates achieved. On the other hand, the service provider requires controlling its resource in order to maximize its profit. Utility-based management strategies are widely used to provide load managing and achieve the best trade-off for QoS levels across job levels [27, 28].
In this paper, we propose a new data Replication and Placement strategy based on Popularity of User Requests Group (RPURG) for heterogeneous cloud systems. It aims to minimize replication costs. We based on the frequency of access of latest group of clients requests (popularity group), user budget and quality of service (QoS) defined in the SLA contract. We formulate this as a Knapsack problem and try to solve it in such a way that the system’s flexibility and QoS are maintained at the optimal rates. Dealing with the consistency issue [25], the last updated data are propagated to all replicas, i.e., asynchrony replication [41, 42]. We defer this issue to a future work. Four problems are discussed in the proposed strategy:
Which data are replicated? To classify the data involved, we focused on data popularity. Data popularity is an important parameter that most replication strategies take into account. We consider data popularity of group of user requests. The number of requests for each data is computed by the data request matrix in the registry. When data are replicated? We based on a threshold response time when satisfying the response time objective for tenants depending on the tenant budget. By this way, we avoid penalties paid from the provider to its tenants. Where new replicas are placed? We consider the network bandwidth (NB) locality [28]. The NB between DC is low when the NB between nodes of a same DC is high. We also consider parameters such as the replication cost in each data center and latency for users, i.e., low response time threshold for users with important budget. The replication cost should also be smaller than the budget for the tenant. Consequently, replicas are placed according the replication cost that includes the data transfer cost. In addition, we take into account the load balancing issue [38]. How many replicas are created? The number of replicas to be created/ deleted is periodically determined in a dynamic way. It depends on the provider profit when executing a group of request. This permits an elastic management of replication [26].
The rest of this paper is organized as follows: Section II provides a related work. Section III describes the details of the implemented strategy. Section IV evaluates the performance of the proposed strategy. Section V concludes the paper and gives some possible future work.
Many data replication strategies were proposed in the literature. Most of synthesis replication work [28] classified these strategies in cloud systems into static [34] vs. Dynamic [8] strategies while other work classified them into provider-centric [28] vs. consumer-centric strategies [29, 37]. In static strategies, each generated replica is kept in the same position or removed manually by the user after a long service period. On the other hand, dynamic strategies build and remove replicas according to changes in the cloud setting. RPURG is considered as a dynamic strategy since replicas of each data set are created, placed and maintained dynamically according to the system workload and the tenant budget. Also, we deal with the provider-centric approach that attempts to ensure the provider profit while satisfying tenant’s SLOs. On the other hand, strategies are also defined according to the metric (or group of metrics) they are trying to manage. Some of them consider a policy for cost minimization for the provider while another aims to ensure the Quality of service for tenants. Figure 1 proposes a rough classification of replication strategies.
Taxonomy replication strategies.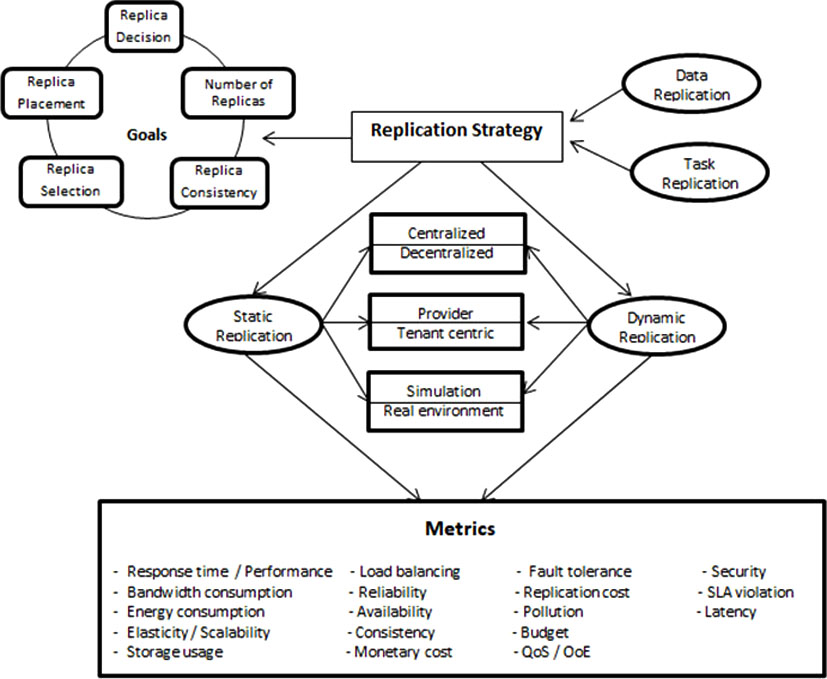
In what follows, we describe some strategies that aim to satisfy different objectives for the tenants. Most of them aim to satisfy a single tenant objective such as availability [8], energy consumption [43], performance [9] and fault tolerance [40]. Only some strategies aim to simultaneously meet several tenant objectives. On the other hand and as noted below, most of these strategies neglect the cost of replication for the provider.
Lin et al. [7] suggested two algorithms for QoS-aware data replication (QADR) in cloud computing systems. To perform data replication, the first algorithm adopts the basic concept of high-QoS first-replication (HQFR). Even so, the data replication expense and the volume of QoS-violated data replicas cannot be reduced by this greedy algorithm. The second algorithm converts the QADR problem in that well-known minimal cost maximum flow (MCMF) issue to meet these two minimum goals. However, the HQFR algorithm has scalable mechanism, but High time complexity.
Wei et al. [8] proposed a cost-effective dynamic replication management (CDRM). This primarily seeks to boost cloud computing efficiency between cost-effective flexibility and attractive load balancing. To catch the link between replica quantity and availability, a novel model is implemented. CDRM uses this pattern to measure and sustain minimum replica number for a guaranteed usability prerequisite. Replica location depends on the likelihood and capability of the data nodes being closed. Price effective maintenance of data replication will redistribute the task between data nodes by modifying the Number Replicas. Even so, CDRM have low reliability and high energy consumption.
Tos et al. [9] suggested the approach of performance and profit-oriented data replication (PERP) that offers SLA guarantees such as accessibility and quality as well as increases the cloud supplier’s economic advantage. PEPR saves replicas in data centers where an average reaction time is greater than the SLO response time limit. PEPR activates replication only if the provider’s reaction time and revenue growth are met. on the other hand, PEPR technique puts replicas at a lower load node, not even in the same sub-regions of the tenants. Replicas are thus not sufficiently similar to the tenants raise the transition time. The response time is also high.
Gill et al. [10] proposed a complex, cost-aware, streamlined data replication approach that determines the minimum number of replicas needed to achieve the functionality required. The knapsack principle has been used to optimize replication costs and to replicate replicas from higher-cost cloud services to lower-cost computer servers without affecting the availability of data. However, this strategy have different disadvantages like low consistency rates, low load balancing and high response time.
The authors in [11] proposed a model to analyze real-world replication work processes. They identify three new techniques to optimize the use of storage space during replica formation, and two new QoS-conscious greedy algorithms for optimizing replica placement [11]. However, the load balancing is not considered.
The proposed strategy in [12] has aimed to decrease the latency of access to the file server and increase the availability of data while optimizing the infrastructure by load balancing. By juggling between these optimization goals, an accurate and enhanced multi-objective integrated replication management (EIMORM) tries to find a trade-off between different objectives. However, the replication cost is neglected.
Mansouri et al. [13] suggested a complex data replication technique for popularity that is displayed on the cloud platform using data access details. In consideration of the 80/20 principle, DPRS replicates only a tiny volume of the data file demanded as much as possible. Effects of free storage room, no request and site centrality, it determines which site the document is copied to. In order to improve the cumulative efficiency by copying the data and accessing the data in parallel, this paper proposes a parallel download strategy. The strategy’s vulnerability neglects the impact of the pattern of file access in the replica judgment.
Dealing with high data longevity, PMCR separates the cloud services into the main tier and replacement tier and categorizes data obtained from data popularity into hot data, warm storage and cold files. PMCR preserves three replicas of the same files in one Copy-set, generated by two databases in the primary tier and one server in the backup tier, to accommodate both correlated and isolated failures. PMCR uses aggregation techniques to minimize computing costs and latency costs for the third replica of hot data and cold data in the recovery tier [14]. However, Response time is neglected.
Sun et al. [15] is based on the principle of making node replicas if they are overwhelmed and stored in other nodes to relieve their workload. It does not sacrifice the access latency if it will decrease the number of overwhelmed nodes, even if it is a decentralized solution. Maintaining replicas based on the state of their loads is one of the key features of DARS. But, it does not take into consideration neither bandwidth nor energy consumption.
Authors in [16] use the file access history. They decide the similarity of the data files while prefetching the most common files. Thus, the next time that a file is required on this web, it will be available locally. In comparison, the replica substitution technique plays a crucial role due to the constraint of storage capacity. The value of useful replicas based on the fuzzy inference method with four input parameters can be calculated by the PDR strategy (i.e. quantity of accesses, replication cost, latest when the copy was visited, and availability of data). In the other hand, they neglect load balance technique.
Casas et al. [17] conceive a cloud computing Structured and File Reuse-Replication Scheduling (BaRRS) algorithm. This algorithm splits the science workflow into several workflows by parallelization for balance use. It deals with the data recycle and multiple replication strategies for transferable data optimization. It takes into account task execution time, task dependence patterns and file size for adaptation of new replication and data reuse strategies. Ultimately, on the basis of budgetary cost and execution time, it chooses the optimum solution and it is difficult to have an optimal solution, which is a complex task.
Centered on file heat and node load, Zhao et al. [18] suggested an enhanced dynamic replica creation strategy. The node load is integrated and, using average heat and average load, the number of replicas is modified. Three new methods for maximizing storage space use during replication development and two new QoS greedy perceptive algorithms for optimizing replication location were proposed by Zeng et al. [11]. A more uniformly distributed replica of the data set can be accomplished by the use of a circular method during the replica creation process. However, Energy and consistency were neglected in this work.
Dai et al. [20] invented a significant approach for optimizing the I/O efficiency of distributed storage systems is the I/O load balancing. The data positioning algorithm greatly influences the degree of I/O load balancing. It is very difficult to develop a data positioning algorithm with the optimal I/O load balancing assurance, as data popularity follows an incredibly biased distribution [39].
Elango et al. [21] used cloud storage with a replication algorithm mix and task scheduling strategy for data replication in the data cloud world by tracking all work processes. In the large database of a node, the data replication can be accomplished by finding the commonly used data patterns. This will be accomplished by the frequent pattern mining algorithm based on Fuzzy FpTree.
In order to formulate the issue of data replica positioning, Cui et al. [22] built a tripartite graph and suggested a data placement technique based on the GA for a scientific workflow to minimize the volume and quantity of data movement in cloud environments. However, the privacy datasets in the science workflow were neglected by this work.
For secure cloud storage, Xue et al. [23] suggested a validated data sharing protocol based on proven data ownership and deletion. The device achieves the beneficial characteristics of promoting all operations. Without downloading the entire data from the old cloud, and verifying the data integrity of the new cloud, the data owner will transfer the outsourced data from one cloud to another. The t does not need to think about the deletion of the deleted data in the original cloud since the deletion proof on the cloud data will be produced by the cloud. Users should then verify that the data were correctly migrated and actually removed from the initial server.
Ma and Yang [24] solve the conventional problem of data replication by exploring an in-memory data cache solution. More specifically, using the stream processing system, the authors suggest a live data replication method for in-memory document stores. Some studies have been performed and the findings published indicate that, relative to Map Reduce-based batch replication, the proposed method is more effective for the replication of continuous in-stream altered data.
Mansouri et al. [2] described mathematical models to explain the five goals, such as cruel gain duration, stack fluctuation, storage consumption, risk of failure and latency, when the efficiency of each knowledge node is taken into consideration. Reproductions for the five goals are put across knowledge hubs. They show an expired replication replacement protocol that takes into consideration their important parameters: document usability, the last date the replication was demanded, the amount of accesses and the replication calculation. The ADRS promotes the transitory placement and the introduction of data-based options such as database transparency to determine the replication of the casualty. They neglected the question of trade off for better property, e.g., the usability and expense of different services.
Comparison between existing replication strategies in the literature
Table 1 above presents a comparison between the replication strategies that exist in the literature compared to the following metrics: (Cost-Network bandwidth-Response time Consistency-Load balancing-Energy).
The
For example Lin et al. [7] took into consideration Cost, Network bandwidth and load balancing but they neglected response time, Energy and consistency.
In the other hand, Elango et al. [21] focused on response time and neglected all other parameters.
Each client, i.e., customer, has a clear concept of SLA restrictions and adaptive negotiation with provider procedures in the cloud system. The availability of resources to clients of the cloud infrastructure environment entails various difficulties and challenges.
The main goal of the structured resource distribution strategy is to follow the constraints of Quality of Service (QoS) and increase the cloud provider’s benefit.
Nowadays, cloud service providers have followed the same traditional methods and auction processes to distribute services. Current strategies are not very successful due to the diversity and diverse characteristics of services. Therefore, the cloud service provider should have an appropriate and personalized resource allocation strategy in which different aspects, such as the defined penalty cost, time and other SLA criteria should be followed by the clients.
The proposed topology for our strategy.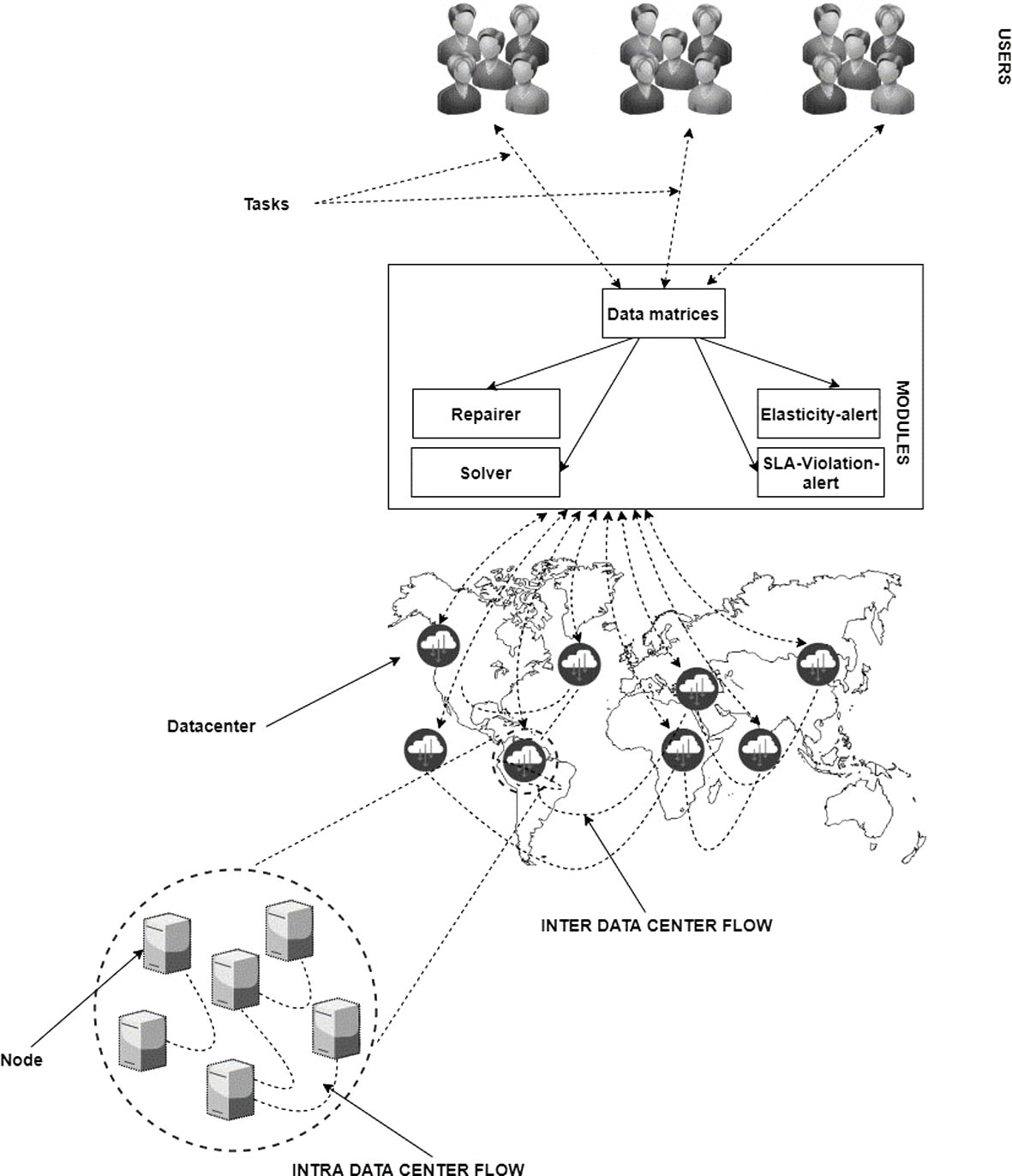
For this reason, we have implemented New Data Replication and Placement based on Popularity of User Requests Group (RPURG) based on the elasticity of replicas following the frequency of access of latest group of clients requests (popularity group), user budget, quality of service for users to generally reduce client response time, reduce cost and maximize benefit for cloud provider without neglecting the conditions of the SLA to be respected or minimize the constraints to be violated between clients and provider.
Figure 2 shows the topology adopted by our strategy RPURG. We distinguish three essential parts in this proposal architecture: (i) the user who sent request and receive response, (ii) datacenters that store all data and information need-it and finally (iii) an important part namely module management (Solver, Elasticity-alert, Repairer, Sla-violation-alert). Each module plays a role in this proposed strategy.
Model system
In our strategy, we use
Let
Each
Each Node for Data center has a file F. We Indicated that
Proposed architecture.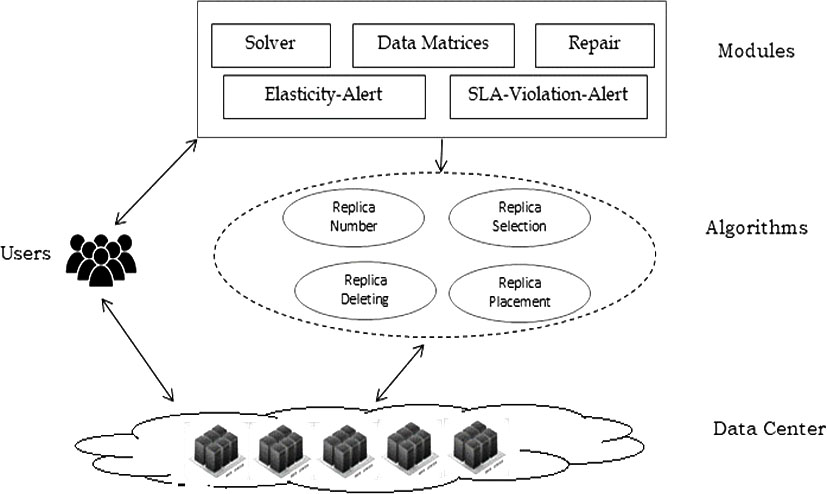
As previously mentioned, our architecture contains several modules: Data Matrices, Solver, Repairer, Elasticity-alert and SLA-Violation-alert described as follows
Data matrices
We identify six matrices:
Matrix of popularity
Matrix of capacity-node
Matrix of size-dataset
Matrix of threshold response time
Matrix of threshold maximum budget
Matrix of bandwidth network
Solver
Since our solution aims to determine the number of necessary replicas such as the objectives of the tenant will be satisfied while ensuring a profit for the cloud provider, we think about this Mathematical statement of the problem:
where:
The system take into consideration consistency so we use the last file modified (time of modification) then we make the update for all the data with the same content and false value.
Elasticity-alert
Resources can be increased or decreased according to the popularity of each data. It means replicate a data
The popularity of each file is calculated by the following simple equation:
where
The SLA violation module use parameters such as response time, budget for each client and minimum response time as a constraint in a cost minimization based algorithm. In cases of very strict violation for important client (very high budget), the Replication mechanism triggers an increase in resources for not have a huge penalty. We take a consideration a bandwidth as parameter to decrease response time.
RPURG strategy
In cloud computing, we have different sites, heterogeneous data centers, which contain various data file, so we find it difficult to select the file to replicate, so our strategy was faced with the challenge of answering the following questions:
KwInInputKwOutOutputKwFunFunctionKwbeginBegin KwendEnd [t!] Replica selection
Budget
Replica selected
slaviolation
slaviolation
Question 1: What data to replicate? For answering to this question we propose two issues first, We replicate the data on which the majority of requests are made, when the popularity of the file is above the replication threshold (
When the SLA-Violation alert is triggered for an interesting client (
[t!] Replica number
all replica selected
Question 2: How many replicas are created? For answering to this question we use the simplex gives us the optimal number of replica that meets the imposed constraints (2). The number of replica must be increased until reaching the replication threshold in the Elasticity module. The process of creating/deleting replicas is described in Algorithm 3.4.
[t!] Replica placement
select
EX
Question 3: Where replicas are created? Among the data centers that have enough storage space we choose those that have a reduced storage cost and a high bandwidth (In most cases we must choose those that provide a compromise between the two previous constraints).
[t!] Replica deleting
Question 4: Which replicas are deleted? The number of the least popular replica (which has a low access frequency) must be decreased until reaching the erasure threshold in the Elasticity module.
Question 5: What is the cost of replication?
We note that for each operation, we calculate a cost then we have a benefit total
In this section, we have defined our simulation tools. Then, we made a comparison of the result according to different criteria: response time, SLA violation, cost penalty, Total cost and
Simulation tools
In order to validate our strategy, we used CloudSim [1, 19], an open platform, flexible and extensible simulation model that facilitates seamless analysis, simulation, and evaluation of current Cloud computing systems and application services according to a distributed topology. The experiment was carried out using the following tools.
Simulation tools
Simulation tools
The work done was compared with the following data replication strategies: PERP [9], DPRS [13], and CDRM [8] in addition to the NO REPLICATION algorithm. The latter were chosen for this comparative study because they presented the best results among the previous works.
Simulation parameters
Simulation parameters
To evaluate this experimentation we used different metrics average response time, SLA violation, Cost penalty and total cost in 10 heterogeneous data centers with different capacity, costs and bandwidths. We also vary the number of client requests by a step of 200 tasks [200, 400, 600, 800, 1000]. Finally, we use other parameters and variant metrics as shown in Table 3.
In first experiments, we measure the Average response time of various strategies. The results obtained are mentioned in (Table 4).
Average time response values
Average time response values
In Fig. 4, we notice a significant decrease in the average response time for the experimented queries with the RPURG compared to CDRM and PEPR strategies. On the other hand, there is an equality compared to the DPRS since it focuses on the response time as a priority in its algorithm.
We measure also the number of constraints violated by provider. The results obtained are mentioned in (Table 5).
Number of SLA violations
Number of SLA violations
Average time response comparison.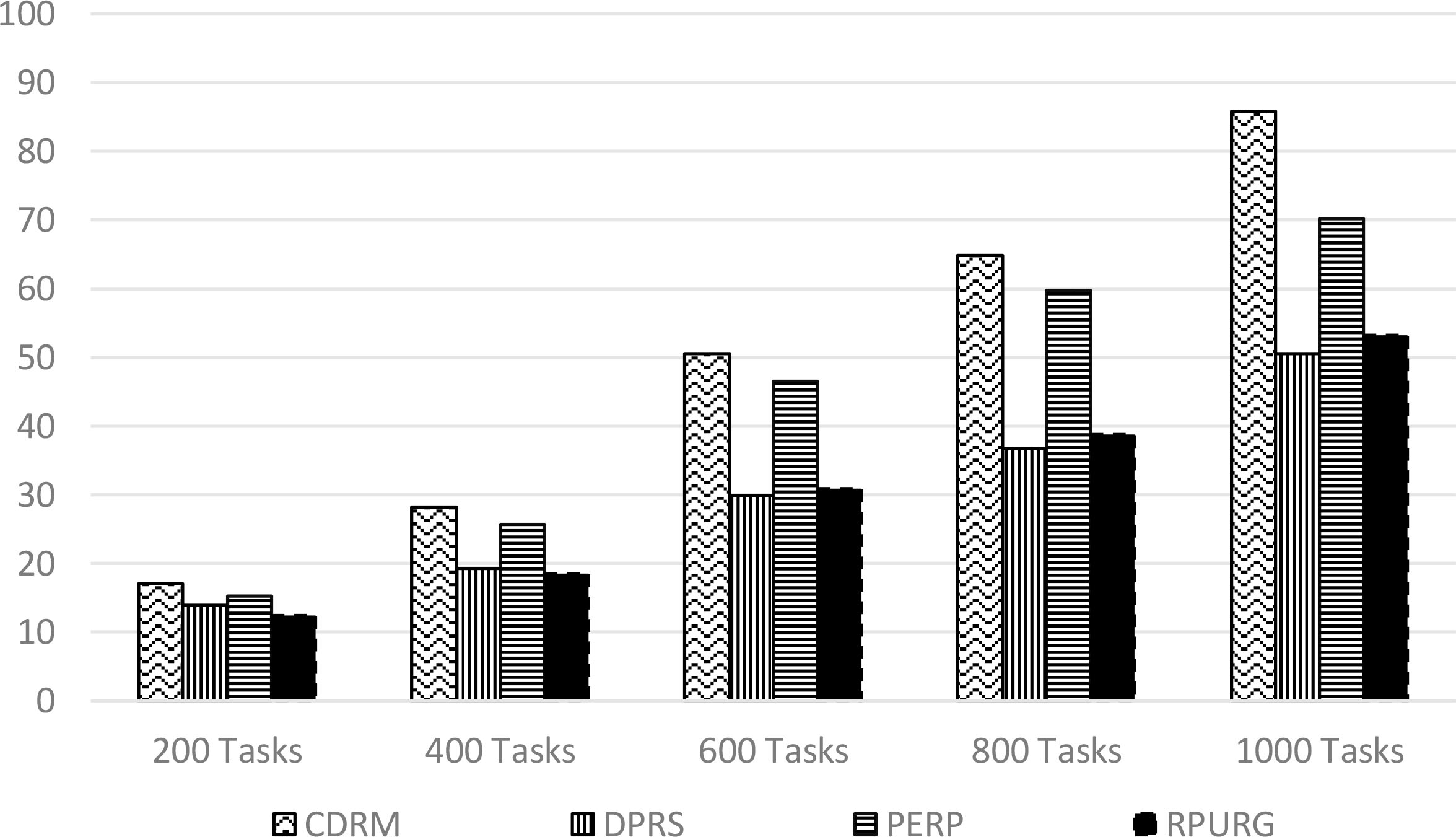
As shown in Fig. 5, The SLA violation time of the experimented queries with the RPURG is substantially reduced compared to CDRM and DPRS strategies. On the other hand PERP takes the lead since it focuses to reduce SLA violation for tenant’s satisfaction.
The provider has penalties to pay for clients suffering losses. Table 6 show the cost penalty for each strategy.
Cost penalty values
Cost penalty values
SLA violation comparison.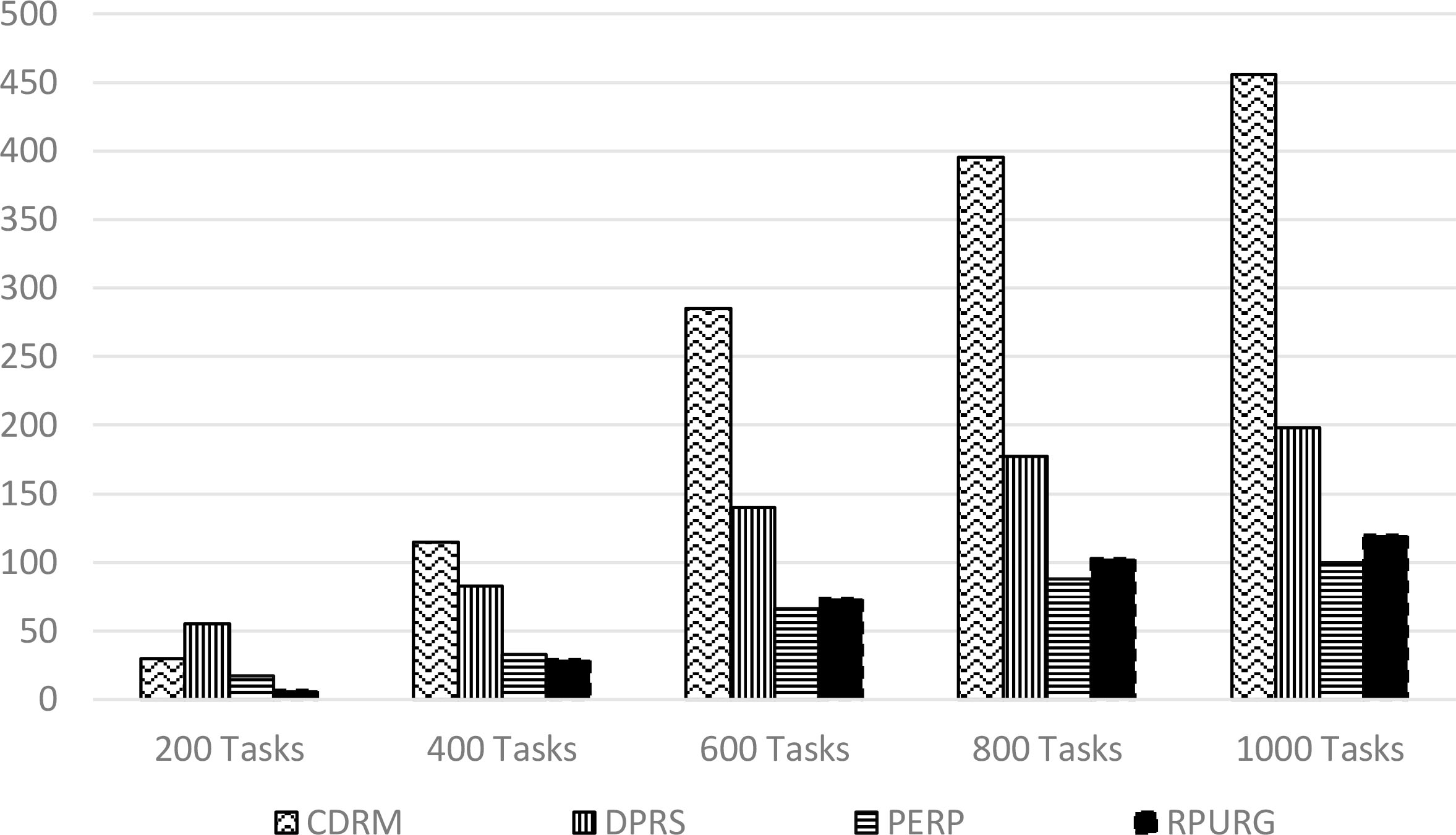
Cost penalty comparison.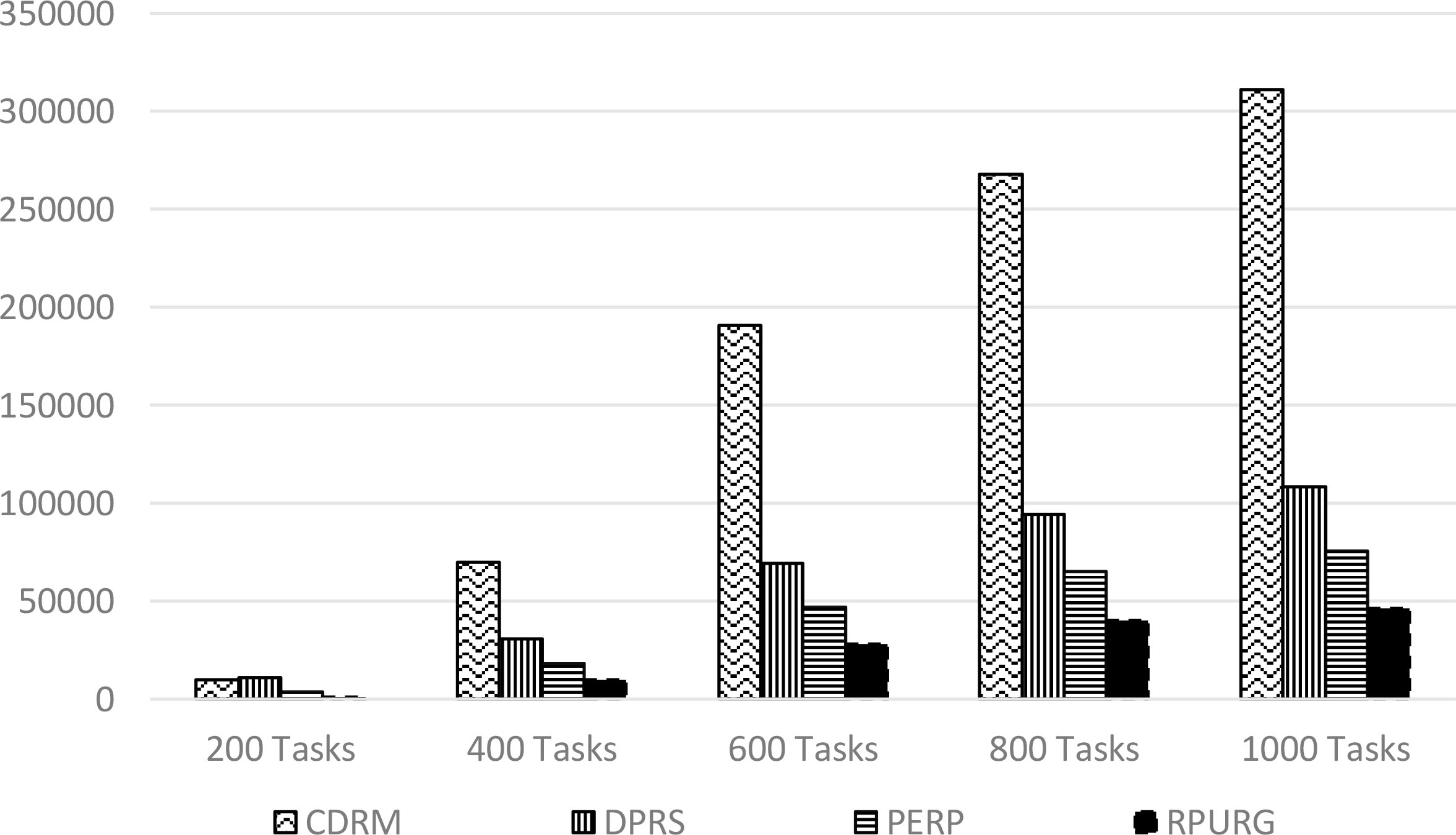
In Fig. 6, our strategy RPURG takes the advantage with minimum Cost Penalty since he minimizes large sums of penalties and only neglects small ones compared to Perp. We note that DPRS and CDRM do not take this metric on consideration.
As shown in Table 7, we resume all costs obtained through Eq. (6) for each strategy by varying the number of tasks.
Total cost values
Total cost values
Figure 7 shows that RPURG find himself the leader compared to PERP, DPRS and CDRM in terms of total cost calculated in Eq. (6) used Cost replication, cost bandwidth consumption and cost erasure.
In order to study and analyze the behavior of our strategy in relation to strategies (No Replication, CDRM, DPRS, and PERP) We have defined a new metric called
We defined this Eq. (7) in order to compare between different strategies with heterogeneous metrics. So, the best strategy is the one which has minimum
Table 8 presents the numerical results obtained by the simulation to measure
Total cost comparison.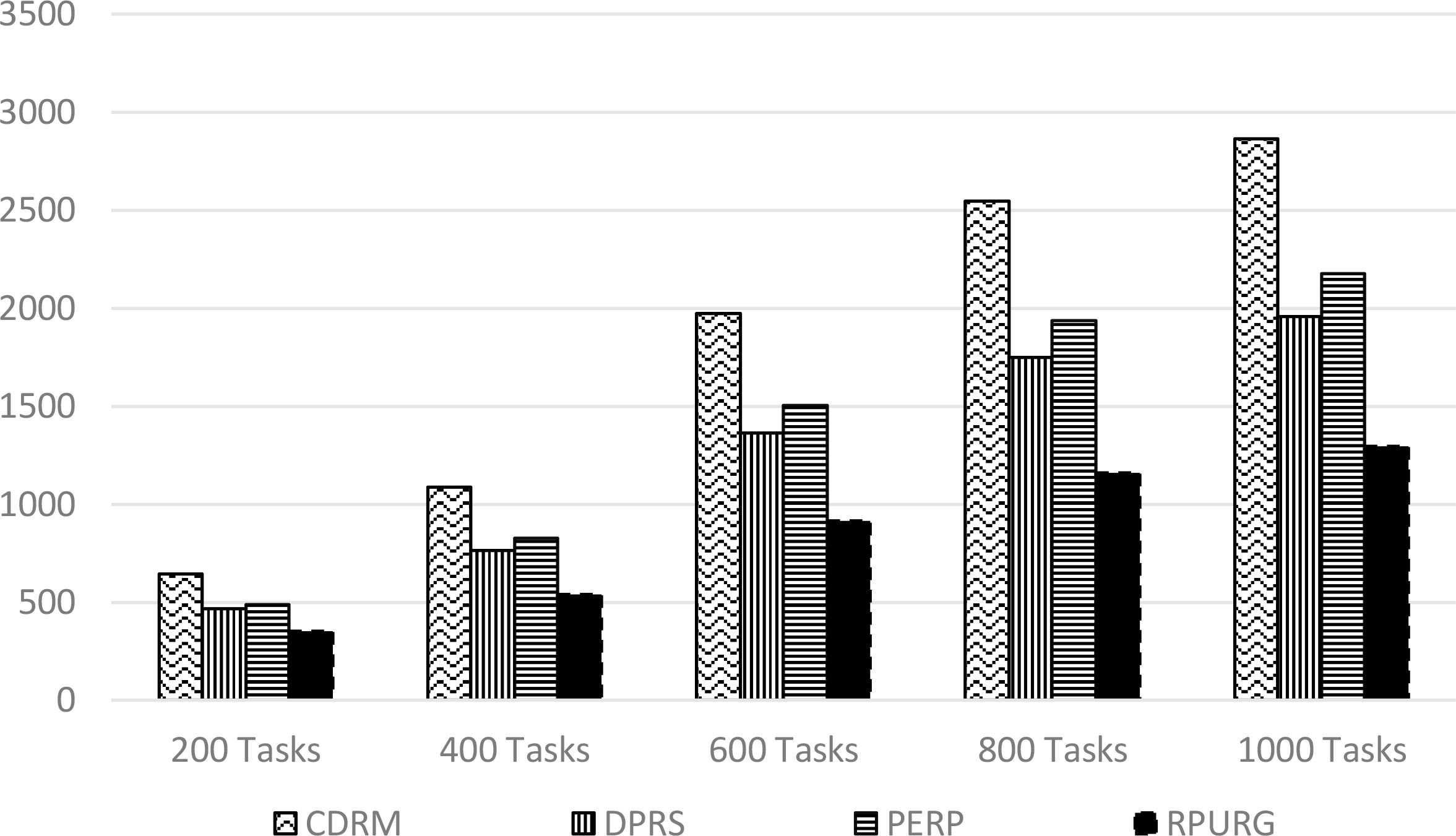
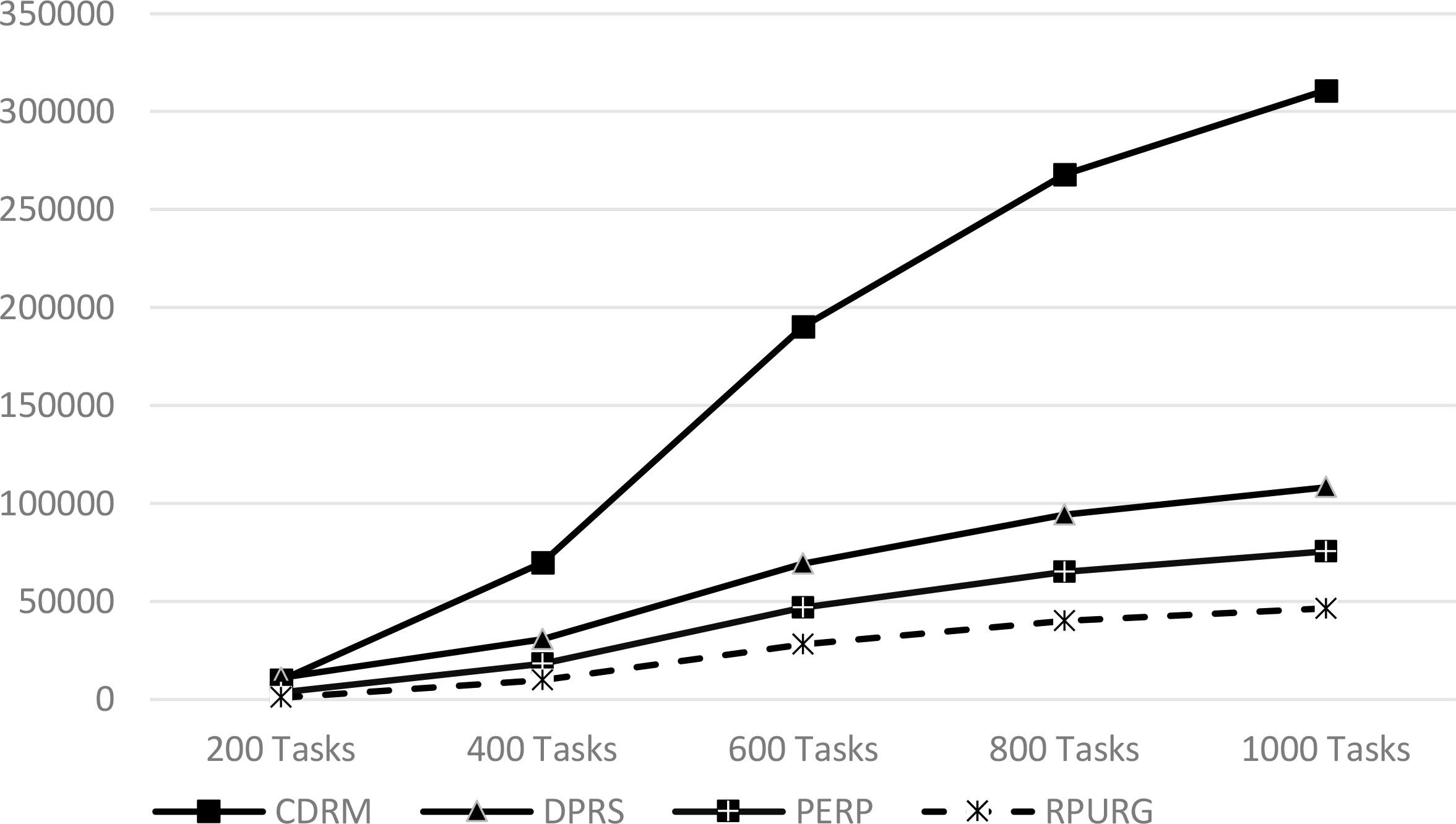
From the results presented in the Tables 7 and 8 and graphs above, we clearly notice that the RPURG has succeeded in guaranteeing the best values
Figure 8 gives the values of the standard
The originality of our paper is that it deals with a double problematic. On the one hand, the problem of cost provider service and on the other hand, the problem of satisfaction of clients. Concerning the assignment problem, we propose to duplicate some replicas if needed. Compared to the works presented in Section 2, our work integrate a Replicas Manager that Creates or Removes Replicas if needed. Moreover, make an exact choice of the placement of the replicas. This decision is based on the assignment algorithm. The works presented in Section 2, do the same thing but do not consider both of them (Cost provider & Satisfaction client) as well as the inconsistency problem is solved in this paper. This makes our work original comparing with the existing works. Our work is related to this dual problem in a large scale environment. Our Strategy neglects the fault tolerance in cloud computing [44].
Conclusion
Nowadays, many data replication strategies have already been proposed in order to improve data availability and performance in cloud systems. Most of research work show that the satisfaction of such objectives relies on number of replica and their placement.
In this paper, we have proposed a new data replication strategy that targets the Quality of Service (QoS) satisfaction in clouds while considering the replication cost. It allows an increased performance and cost containment of cloud services. In order to increase data accessibility and decrease cost caused by replication, we propose to dynamically adjust the replication degree of each data object so that the replication cost is minimized. We based on different protocols and tools like simplex. It takes into consideration a number of parameters such as data popularity when satisfying the performance SLO objective and taking into account the benefit of the provider. Finally, the proposed strategy is validated through experimentation based on CloudSim simulator. The result analysis shows the efficacy of our proposition.
For future work, we try to improve the repair module and to integrate a module that controls failure message when satisfying the fault tolerance objective [40]. We could also based on data mining strategies [30] and machine learning techniques [31] in order to further improve QoS.
Footnotes
Author’s Bios