
Abstract
Cloud computing has emerged as one of the hottest topics in technology and has quickly become a widely used information and communication technology model. Performance is a critical component in the cloud environment concerning constraints like economic, time, and hardware issues. Various characteristics and conditions for providing solutions and designing strategies must be dealt with in different situations to perform better. For example, task scheduling and resource allocation are significant challenges in cloud management. Adopting proper techniques in such conditions leads to performance improvement. This paper surveys existing scheduling algorithms concerning the macro design idea. We classify these algorithms into four main categories: deterministic algorithms, metaheuristic algorithms, learning algorithms, and algorithms based on game theory. Each category is discussed by citing appropriate studies, and the MapReduce review is addressed as an example.
Keywords
Introduction
The advent of the Internet and its popularity have changed communication’s meaning over time. Besides, the need and possibilities of various computations lead to the increased importance of information computing. The concept of cloud computing was introduced in 1960. However, the first use of cloud computing in its modern context occurred in 2006. Many companies such as Amazon, Google, Yahoo, HP, and Intel have been involved in the development of cloud computing [1].
There are many definitions for cloud computing. The National Institute of Standard and Technologies (NIST) [2], defines it as a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources like networks, servers, storage, applications, and services. These resources must be rapidly provisioned and released with minimal management effort or service provider interaction.
In addition to cloud computing, two other well-known computing models emerged. In terms of becoming popular over time, grid computing was first followed by cloud computing and edge computing. Although this paper focuses on cloud computing, there are related significant works studying job scheduling and resource allocation regarding different structures in grid computing and edge computing.
In the cloud environment, there are service consumers and service providers. Consumers submit their work and expect them to be done with the least cost and time, and providers provide the necessary resources to do consumer submitted works. Providers want to make the most profit by the best use of resources and to meet customers’ demands. Thus, the scheduling demand is raising [3].
One of the significant and exciting challenges in the cloud environment is task scheduling. In general, task scheduling is arranging the user requests (tasks) in a particular order so that available resources will be used suitably. Scheduling is the technique of mapping a set of jobs to virtual machines or allocating virtual machines to run on the available resources to fulfill users’ demands [4]. According to the importance of proper scheduling and management of resources, much attention is needed in designing and choosing a suitable scheduling algorithm. Considering the studies that have been done in the field of scheduling in cloud computing, various methods have been proposed. Therefore, it is necessary to be acquainted with different challenges and issues and select the most appropriate option between existing methods based on available resources and requirements of the problem. This paper also provides the necessary background for this selection by reviewing different algorithms regarding the main macro idea on designation.
Various algorithms have been proposed to optimize and schedule job executions in shared environments like the cloud. Among them, deterministic algorithms have received much attention due to their simplicity. However, the complexity of problems and the need for more flexibility have led to the utilization of metaheuristic algorithms. These algorithms can provide a relevant result by creating approximate strategies and exploring the space of scenarios at the right time. Another category includes the learning algorithms, as they can solve a diverse set of problems and challenges in cloud computing. These algorithms receive much attention due to their ability to solve complex problems and find accurate answers using datasets. However, there are crucial challenges in seeking potent hardware compared to other methods. In addition to mentioned categories, game theory provides a new perspective by dealing with conflicts and competitions between objectives in a scheduling problem. Therefore, it has been utilized as a helpful set of algorithms for addressing related problems. Overall, to review scheduling algorithms, we focus on four main categories deterministic algorithms, metaheuristic algorithms, learning algorithms, and algorithms based on game theory. In the following sections, each of these categories is noticed briefly. An ideal and famous example of the cloud utilization is MapReduce while various scheduling algorithms are practically utilized in the MapReduce framework to improve performance.
The rest of this paper is structured as follows. Section 2 outlines the related topics in the cloud environment such as simulators. We present categories of deterministic algorithms, metaheuristic algorithms, and learning algorithms in Section 3, Section 4 and Section 5, respectively. The category of scheduling algorithms based on game theory is explored in Section 6. We review the MapReduce framework regarding scheduling algorithms as an example in Section 7. Finally, Section 8 concludes our work and discusses some future directions.
Background
Problem description
Scheduling is the process of allocating resources to tasks and assigning start and finish times to tasks.
Let us assume several tasks need to be performed while each has resources in the desired range but in chronological order. They should be planned to answer tasks in the shortest possible time. One of the difficulties of such scheduling is the disruption of planned work caused by environmental variations. In addition, challenges in such issues include: Machine task capacity, Machine availability changes, Variations in task required resources, The priority of interrelated tasks, and Preference between independent tasks.
Overall, the issue of scheduling in cloud computing generally consists of two major stages. The first one is the choice of tasks. In this way, the option is about which task is to be selected and start performed. The second one is resource allocation. The scheduler has to decide how many resources on which hardware nodes to allocate to the assigned task.
Resources are one of the most crucial parts of each system, and because of limitations in this part, any system should have proper resource management. Based on work in [5], resource management in the cloud has two critical parts: resource provisioning and resource scheduling.
The process of scheduling is a way to analyze customer required and related Quality of Service (QoS) parameters and decide how to handle them based on available providers’ resources. Regarding works in [3], the first objective of resource scheduling is to identify the appropriate resources for scheduling, the appropriate tasks on time, and the increasing resource utilization effectiveness. The second objective of resource scheduling is to identify the adequate and suitable resource that supports the scheduling of multiple tasks to fulfill numerous QoS requirements such as CPU utilization, availability, reliability, security. In order to increase information, know that security is a set of policies, controls, procedures, and technologies that work together to protect cloud-based systems, data, and infrastructure. The security issue is present in almost all areas of information technology. Due to the connection to the Internet and the existence of user data, this case becomes more sensitive. There are remedies like isolating users’ data and authentication and encrypting stored data [6]. It is good to note that the exploited algorithms must be fast enough to avoid QoS violations. Whereas there are many cryptography methods with various speeds and power, which must be carefully selected in the appropriate method. A good review of cloud computing security is provided in [7].
There are various important goals in scheduling algorithms. As suggested in papers [8, 9, 10], the conceivable scheduling parameters are: Make Span, processing time, quality of service, load balancing, finish time, maximum profit, cost, performance, reliability, and security. Also, there can be many vital parameters in scheduling, such as number of processing nodes, number of storage nodes, bandwidth, service request time, user request, task type, task dependency, physical machines, computing power, computing energy, communication energy. The work in [9] includes the definition and detailed information about these terms.
Energy consumption is a good example of the achievements of improving scheduling algorithms. Energy consumption is becoming important in cloud data centers in recent years. Energy consumption affects the cost of cloud service providers. It also has been considered in green computing because of its impacts on the environment, such as carbon emission [11]. Another impact is reliability, so high energy consumption causes low system reliability [12]. There are lots of works on schedule in compliance with energy consumption [13, 14, 15]. Xing et al. [16] proposed a scheduling algorithm with the goal of energy savings and fairness improvement. Li et al. [17] mainly focus on energy-aware and failure-aware workload scheduling policies. Liang et al. [18] proposed a low-power task scheduling algorithm for heterogeneous cloud computing with the ability to reduce energy consumption by reducing the computational overhead. Another good example is [19].
Here, we illustrate scheduling problem formulation regarding Fig. 1. Let’s assume
In simple form, based on Eq. (1), the scheduling goal is to minimize the consumption time of all tasks.
For example, in a more complicated form, each user requests a specific time for each task based on QoS. Therefore, the best schedule is the one with the lowest violation of QoS as demonstrated in Eq. (2).
Furthermore, to cover QoS violation for user i based on schedule
Scheduling schema.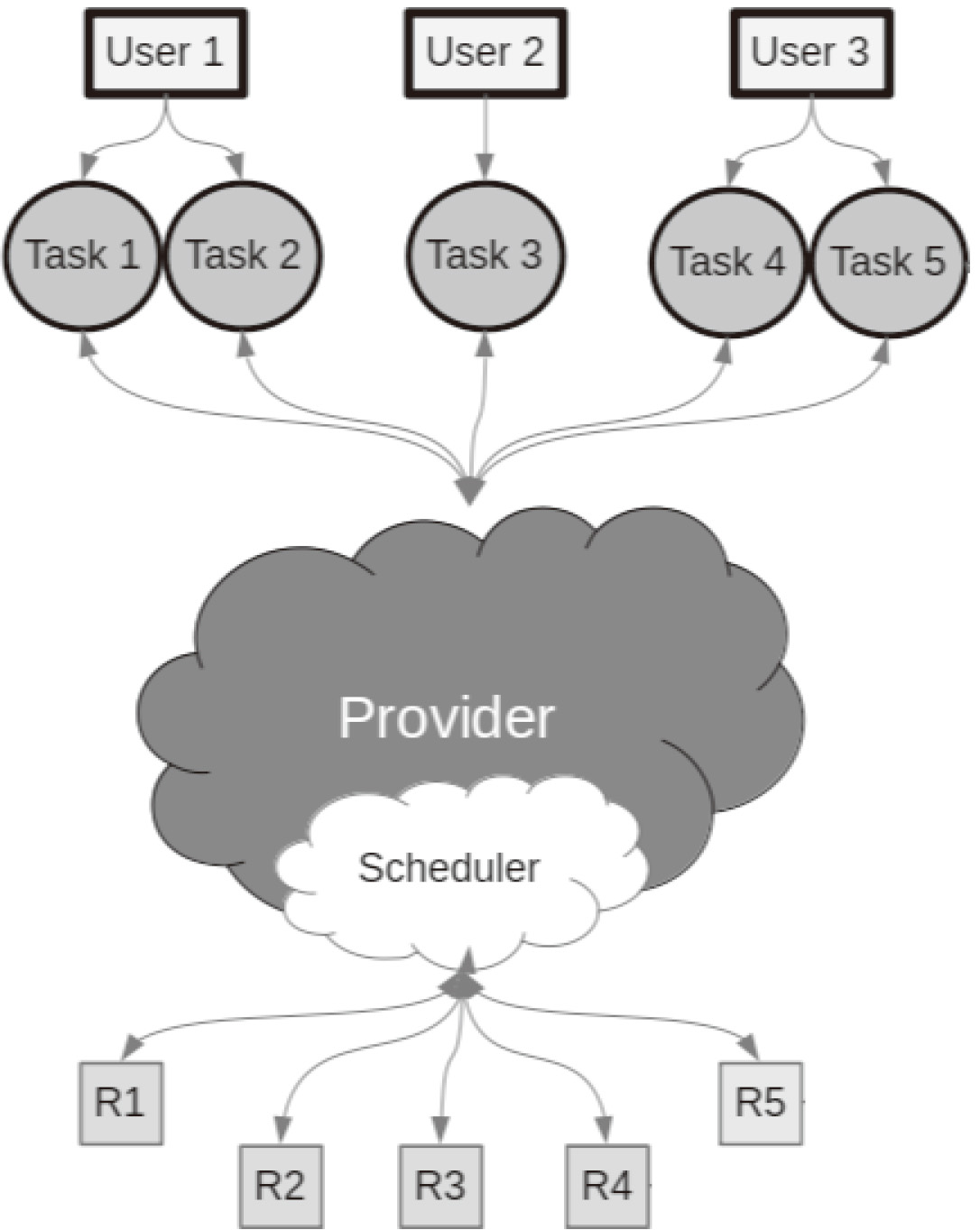
Note that the above formulas can be similarly extended for the other issues that may be raised.
There can be different classifications for various scheduling algorithms. As an example of the first classification, work in [8] categorized scheduling algorithms in cloud computing into two main categories batch mode and online mode.
In batch mode, algorithms receive a set of jobs as a batch, schedule them, and after a fixed time, they receive the next batch. As an example, FCFS and RR are batch algorithms. In online mode, a new task can be received, and it will enter the list of ready tasks and should schedule in its entrance time.
As other works with different criteria to classify scheduling algorithms, we can refer to [20, 21] based on different parameters, [20] based on simulators and adopted tools, [22] based on scheduling objective such as makespan and cost, [4, 22] based on different strategies, [21] based on dynamic and static approaches.
This work considers the macro idea of designing a scheduling algorithm as the main criteria; this classification includes the categories deterministic, metaheuristics, learning, and game theory based algorithms. Let it be noted that the various aims and parameters of scheduling can be achieved in each category. For a better understanding of the content presented in the paper, a list of abbreviations is provided in Table 1.
Abbreviations
The simulator is software to model the environment and test the proposed methods and algorithms. What makes a simulator popular can be originated from the ease of usage, change capability to test various conditions and scenarios, learning to use the tool, and the higher cost of actual hardware and maintenance in real environments. One of the significant challenges in evaluating an algorithm is to select a suitable simulator based on the available capabilities and required features. Works in [23, 24, 25] are discussed the available cloud computing simulators.
CloudSim is the most famous simulator in cloud computing, while many developed simulators are based on CloudSim. Other most-used simulators are WorkflowSim, CloudAnalyst, and GreenCloud [25].
A brief explanation of some well-known simulators is provided in the following. CloudSim is an extensible simulation toolkit that enables modeling and simulation of the cloud environment. This simulator supports VM modeling and can be used to study the migration of VMs for reliability and automatic scaling of applications [26]. GreenCloud simulator is for energy-aware cloud computing data centers. The simulation results are obtained for different architectures [27]. CloudAnalyst is based on simulation frameworks such as SimJava and CloudSim. It has an easy-to-use GUI, a high degree of configurability and flexibility, allows modelers to save simulation experiments input parameters and results that mean repeatability [28]. However, it does not support the pricing model [25]. WorkflowSim is a workflow simulator that can be used for evaluating workflow optimization techniques with better accuracy and wider support [29].
Deterministic algorithms
A significant category of scheduling algorithms is deterministic algorithms. This category includes several items, some of which are selected as examples. In this category, the scheduling decisions are based on several definite criteria while the outcome under the same conditions leads to the same choice. However, this condition may be changed if the algorithm fails to select between two tasks and lead to random selection.
Let it be noted that most algorithms in this category are exploited as an elemental algorithm or as a base testable algorithm for comparing with a proposed novel algorithm. Generally, the simplicity of these methods is one of the crucial factors in their popularity. Mainly, classical scheduling methods have formed this category. Because of their simplicity and efficiency continue to be used, e.g., FIFO scheduling is used in Hadoop. Overall, a lot of research and works belong to this category [30]. In the following, the well-known deterministic scheduling algorithms are pointed out, whereas instances of these algorithms are given in Table 2. Note that the order of the algorithms is near to their simplicity.
Deterministic algorithms
Deterministic algorithms
In this class, algorithms are oblivious to information such as length of tasks, execution time, and QoS.
First Come First Serve (FCFS) or First In First Out (FIFO) is one of the most popular and, at the same time, one of the simplest known scheduling algorithms. This algorithm queues tasks in the order that they arrive in the ready queue. Algorithm 3.1 is FCFS pseudocode. The default scheduler in Hadoop is JobQueueTaskScheduler, which is a FIFO scheduler. However, a more advanced version is implemented by the priority queue that has to be enabled and is not the default scheduler. Therefore, the superiority of the user’s tasks can be considered. However, a famine challenge for users with lower priority can happen. This method can be used in homogeneous environments and has acceptable behavior, but in heterogeneous environments, performance decreases.
: FCFS initial list_of_tasks as empty list [1] Running free resource is available and length (list_of_tasks)
A Round-Robin (RR) method is an arrangement of choosing all elements in a group equally in some rational order. In this method, all tasks are chosen in rotational order. Each task has a unit of time after its neighbor. Works such as [37, 38] have used the RR algorithm or the modified versions for task scheduling in the cloud environment.
Task features aware algorithms
In this class of algorithms, some task related features such as length of tasks, and Minimum Completion Time (MCT) are considered. In the minimum completion time algorithm, tasks are assigned to the virtual resources or virtual machines based on the best predictable completion time in random order. A VM, which is expected to complete a task sooner than the others, will perform it. An improved version of MCT, the Minimum Execution Completion Time (MECT) algorithm, was proposed in [31]. Moreover, inspired by the MCT method, a scheduling algorithm to reach the trade-off between energy savings and delivered performance was proposed in [32]. This scheduling algorithm guarantees to meet the task deadlines and the minimum power consumption.
Longest Approximate Time to End, available in [30], estimates the approximate execution time of each task while there is no exact prediction of execution times. For example, this method may find the average available resources the length of tasks and calculate how long it would take. In this method, the task’s dependence can be considered. In contrast, the return time of a task will be calculated as the sum of the maximum return time of its precedence tasks and its own approximate execution time. However, other policies can be assumed, and calculation is done based on them. The better approximation leads to more hope to reach the promised results in the longest approximate time to end method.
Min-Min assigns the task with the minimum size or completion time to the resource with minimum overall execution time. This method is simple and produces a good output to reduce the average time to complete tasks. Algorithm 3.2 is its pseudocode. Meanwhile, the major challenge of this algorithm is the risk of starvation for some tasks and, at the same time, the reduction of parallelization between tasks. Regarding tasks parallelism, assume three tasks with lengths 2, 2, and 4 and two identical machines. Although the first and second choices will be sizes 2 and 2 running in parallel, the task with size four will be on one node, and the other node will be idle. However, if both tasks with size two are assigned to one node and the task with size four is assigned to other nodes, the parallelism will be higher, and the total execution time will be shorter.
: Min-Min initial list_of_tasks as empty list [1] Running free resource is available and length (list_of_tasks)
An improvement of this method was presented by Patel et al. in [39]. This paper emphasized the need to enhance the makespan of the Min-Min algorithm and proposed an improved version of the algorithm. Max-Min assigns the task with the maximum size or maximum completion time to the resource with minimum overall execution time. Algorithm 3.2 is its pseudocode. This method is as simple as the Min-Min method, and the challenge of reducing the degree of parallelism, which was mentioned earlier, has been addressed. For example, in the previous example, a task of size four is selected and placed on one node, and the other two tasks will be on the other node. This method has its disadvantages. If large tasks are abundant, small tasks remain, and the average completion time has an undesirable increase that would not occur if one of nodes was processing them. On the other hand, starvation for larger tasks has been solved, but this problem will now happen for small tasks.
: Max-Min initial list_of_tasks as empty list [1] Running free resource is available and length (list_of_tasks)
To reduce the wait time and makespan in the cloud environment, an improved scheduling algorithm based on Min-Min and Max-Min is proposed in [40]. The paper [33] provides a comprehensive performance comparison between scheduling algorithms, including FCFS, MCT, Min-Min, and Max-Min. The improved Min-Min [41] is based on adding different rules and combining existing methods. In this algorithm, an attempt has been made to solve the problem of reducing the degree of parallelism. There can be issues for longer tasks in the improved Min-Min algorithm. However, adding a multidimensional priority to solve the problem is very useful. In this regard, prioritization is defined as a weighted average of several measurements. These measurements include the user-defined priority. Moreover, one of the task’s priorities is based on the length, and another priority is related to time, i.e., the longer the waiting time, the higher the priority. Therefore, long tasks can execute after a reasonable time. In the Improved Max-Min method, the average completion time will increase if the number of long tasks is large, while the small tasks could be processed sooner.
The paper [42] proposed a version of this algorithm to assign the longest task to the slowest node and select the slowest nodes in order. As a result, fast nodes match with shorter tasks. Since shorter tasks processing speeds up, fewer problems occur in practice. In this proposed method, statistically and according to the reported results, a better answer has been obtained than the original Max-Min algorithm. The work in [43] utilizes the max-min scheduling heuristic. Their proposed algorithm improves the completion time of requests by using machine learning in clustering requests according to the size and percentage of utilization of virtual machines. Then assigns the largest task to the least utilized virtual machine.
Resource Aware Scheduling method has been introduced for grid computing in [44]. This method is a combination of two methods, Min-Min and Max-Min. In such a way that each time a task is selected, it rotates between the min-min and max-min. If it starts with the odd number of tasks, then start with the Min-Min and if it begins with the even number of tasks, then start with the Max-Min. This heuristic is statistically based on different samples that have been tested and obtained practically.
As the scheduling problem becomes more extensive, the time complexity of the Resource Aware Scheduling method is approximately equal to the time complexities of the Min-Min and Max-Min methods. Let it be noted that reducing the execution time of each task separately does not necessarily cause the reduction of the total execution time. Moreover, there is no obligation on the relationship between throughput and makespan, and the improvement of one does not necessarily affect the other. Earlier, the Min-Min and Max-Min algorithms’ weaknesses have been mentioned, which are problematic in parallelism and average completion time. The Resource Aware Scheduling algorithm has been able to reduce the problem of starvation.
In addition, using the Max-Min algorithm represents the solution to the challenge of weakness in the paralleling execution that has been eliminated. Two components that are often observed in various studies are efforts to optimize the balance of resource allocation between tasks and increase throughput. The second component is more significant when the number of input tasks increases.
Parsa et al. [44] considered this component while Min-Min makes this goal possible. The simulation result of this paper has been achieved based on the grid system. However, the result is still helpful for cloud systems due to its similarities and advantages.
User demand aware algorithms
In some algorithms, other kinds of features are considered. These features are based on users. For example, deadline of each task is based on user asks, awareness of QoS and SLA, and other priorities of users and service providers.
In Deadline Aware, as the name implies, there is an attempt to meet the required time as a deadline in Deadline Aware schedulers, which the user probably chooses. In this regard, a simple example is to select the task that has the earliest deadline. It is also common to ignore a task if it does not meet its deadline or to extend the deadline at an additional cost. Works in [14, 34, 35, 36] has addressed the deadline-aware scheduling.
In priority based algorithms, Based on [48], priority of jobs is crucial in scheduling because some jobs should be serviced earlier than others and cannot stay for a long time in a system. A suitable job scheduling algorithm must consider the priority of jobs. Ghanbari et al. [48] proposed a scheduling algorithm based on multiple criteria decision-making model.
Market oriented algorithms are another important class. It is essential to pay attention to notable factors for users and aspects that are economically significant for job scheduling. Moreover, the available resources are not infinite. Therefore, the resource allocation should be optimized to maximize the provider’s profit. When there is only one resource, the scheduling determines the order of tasks. However, if there are various resources and the possibility of parallelism between tasks, it is necessary to have a suitable resource allocation and task scheduling. Several simple methods have been used to provide a time estimate of task completion by formulating problems. However, such methods lose effectiveness when multiple resources are available and parallel execution is possible. Note that both processing and memory resources are considered when it comes to resources. In a problem formulation, these resources are usually weighed according to the problem conditions and the type of tasks. An example of a scheduling algorithm with a market-oriented heuristic has been presented in [45]. This algorithm aims to give the most revenue to the service providers while resources are limited. Details of this algorithm are as follows: The scheduler first decides whether to accept or reject the input task. It tries to start the scheduling process by prioritizing tasks and determining what resources to allocate to each task in order. It creates a prioritized queue, selects the highest priority, and allocates resources to the next task if it is not possible for each. Assuming that the volume of work received is large, it is not cost-effective in time and processing if each work is wholly rescheduled. Each job may be stopped in the middle of the run and lose resources while another job runs, but the configuration settings do not change. Each job may have physically new resources after retrieving allocated resources, but the configuration mentioned above is retained. If a task is running, it means that it will meet its deadline. Moreover, paper [45] proposed a general linear decay value function to characterize a client’s willingness-to-pay. This amount does not exceed the maximum value defined by the user, but it can be negative.
It is also necessary to get a good and fast estimate of how long a task will execute. This depends on the size of the input and the assigned configuration. The mentioned paper proposed a collaborative filtering-based approach to quickly and accurately predict the execution time of parallel jobs running in a Big Data analytics service platform. Another example is an algorithm that is presented in paper [34]. This algorithm minimizes Monetary Costs for Deadline Constrained Workflows in the cloud environment. At the same time, it can focus on on-demand provisioning, pay-as-you-go model, instance heterogeneity, performance variation, and VM acquisition delay.
On-demand service means serving resources based on user requirements. Cloud computing users define their needs and pay based on their usage. The expected service level will be addressed in the service level agreement (SLA), and the service provider’s schedule must be such that the provided service does not violate SLA.
In a fair scheduling algorithm, all tasks will be given resources as needed if there is no resource constraint. However, if there are resource restrictions, we should try to establish fairness. It is also important what level of services agreement the user has registered in the contract. Some works tried to establish fairness by targeting the quality of services like paper [46]. Two steps should be considered in the scheduling process: prioritizing tasks and then deciding which resources to allocate to each. The first solution that comes to mind is to build a matrix between tasks and resources that determine how long it takes and choose the shortest one each time, thus responding to both scheduling steps. However, this solution does not create enough fairness because longer tasks are practically ignored. An introduction of three well-known fair scheduling heuristics is provided in the following [46].
Max-Min fair sharing: Although the allocated amount may be more than the required one, all tasks are given the same resources. Redistribute the rest and continue this process as long as possible. This method is computationally simple but not entirely fair, especially since some tasks are completed after a while. It remains to be seen how the freed resources will be handled.
Simple fair task order: To complete Max-Min fair sharing, it is stated that the released resources prioritize between tasks and prioritize the task that finishes the earliest. This method also does not have complete fairness.
Another change can be made to improve fairness so that the freed resources are divided between tasks. In the first type, it should be distributed equally among everyone, and in the second type, it should be rescheduled for them, and the allocation of those resources should occur again. For example, the size of tasks should be considered. The second type is fairer, but there is more computational and temporal complexity due to multiple rescheduling.
The heuristic of dynamic optimization is introduced in the paper [47]. In a dynamic optimization algorithm, tasks are divided into two categories based on their nature: tasks that are important to reaching the deadline and more costly tasks. Each type is arranged according to the index of the same category. There is now competition between the two rows as to which row to process first. In this regard, it can be done in turns and rotations, and there is a queue each time. It is examined to select and allocate resources to establish the resource with the fastest processing time for the considered task.
Metaheuristic algorithms
The use of statistics and probabilities in computer science is inevitable. Various algorithms with non-deterministic behaviors have been proposed in the category of metaheuristic algorithms. Much effort has been made to develop and utilize scheduling methods in this category.
The general scheduling problem is a well-known NP-hard problem; therefore, if a method inspects all the cases, it is not cost-effective in terms of time and computational factors. As a result, researchers have used metaheuristic techniques to approach optimal answers. Such methods find a proper solution by trying to examine the state space and seek better answers in a reasonable time [49]. Although it does not guarantee that the best answer will be found due to the wide range of problem situations and limited time, the result is usually perfect.
In deterministic algorithms, there is less flexibility than in metaheuristics in interacting with different environments and problems. Also, deterministic methods are often complex in interaction with extensive data, so they cannot find the answer. At the same time, one of the most significant weaknesses of the metaheuristic algorithms is the lack of guarantee of finding the best solution.
In many metaheuristic algorithms, many agents search the problem space and try to find a better answer. This is called swarm intelligence. These algorithms are divided into three general subcategories regarding the number of search agents. The first subcategory has one agent, and only one agent tries to find the desired answer. The second subcategory is multi-agent, and a set of agents are searching in the problem space. The third subcategory combines different methods that may be multi-agents or single-agent.
One of the most critical challenges in metaheuristic algorithms is getting stuck in local optimums. Special attention has been paid to this challenge in the scheduling context regarding metaheuristic techniques. At the same time, trying to examine more of the state space and find a better possible answer and the algorithm’s speed has been considered. A simple example is given below to explain the local optimum problem further. Let us assume a robot climbs a mountain and tries to reach the highest point. This robot has simple tilt sensors only to perceive its surroundings at very short distances. So, it chooses the highest point near and goes to it, while if the surrounding points are lower, it stays at this point and thinks it has reached the peak. In Fig. 2, two robots, 1 and 2, search for the highest peak. Robot 1 moves to its left to reach point A, which is the main peak, and stops there, in which case it succeeds. Robot 2 stops at point B, but it is clear that it has not reached the main peak while stuck in a lower peak called local optimum.
An example of local optimum.
In the following, a broad range of metaheuristic algorithms is discussed. In addition, Instances of the mentioned algorithms are given in Table 3. Houssein et al. [5] prepared a good review about metaheuristic based algorithms for task scheduling in cloud.
Metaheuristic algorithms
As an simple example Hill climbing is one of the most popular single-agent algorithms. This algorithm is practically similar in appearance to the example in Fig. 2. However, its simple form is a single-agent and changes its position to find a better answer. How fast the hill climbing is, how the location changes, and the local optimization escape method are discussed differently. For example, the algorithm is simulated annealing, which changes the velocity as an exponential function that gradually decreases the speed to initially escaping from local optimums and progressively decreases the speed to allow convergence. A good example for simulated annealing in [64] used a combination of this method and genetic algorithm.
Another popular version of hill climbing is the Tabu Search algorithm [50]. This algorithm keeps a list of visited points to not return to them or other explored places. This method is especially effective if there are several restarts. Let it be noted that this way of searching can be considered by different algorithms. Another improvement that has been proposed in this regard is the use of two parallel processors, one of which is responsible for checking the list of prohibited and one for performing agent moves and other tasks.
Multi-agents, nature-inspired algorithms
The behavior of nature has strangely taken steps towards optimization, and with inspiration from nature, many algorithms have been designed and introduced. Meanwhile, some of these algorithms have been used in scheduling optimization to allocate resources in cloud computing.
The Genetic algorithm (GA) tries to produce the desired output by simulating the behavior of living things. In a GA solution, there are common points that form the framework of the algorithm. In general, this algorithm starts by randomly generating several instances, which is the first generation. Each generation member is valued by a function that indicates the degree of fitness called fitness function. As in the environment, a fast gazelle is more valuable; in other words, it is more compatible with its environment and is more robust in the face of dangers. Its chances of survival are greater than those of a slow-moving gazelle. Genes make up a chromosome and express its characteristics. At the same time, each generation member has a chromosome made up of genes. Just as the production of the next generation is based on the composition of genes of the previous generation, that is, the output of the next generation is produced by combining current genes and a kind of intersection between them. How much each member of the current generation can transmit their traits through the company of their chromosomes to produce the next generation is based on a fitness function. In many cases, some top members are selected to produce the next generation, and in other cases, everyone has a chance. This probability is evaluated based on a function and the degree of fitness for the related problem. Also, in nature, one factor that reveals new traits is changes caused by mutations. In this algorithm, mutations may also occur, causing changes in the chromosome sequence. Note that the production of each generation is a forgetfulness of the previous generation, and to complete this process, various contracts are made. A contract can include implementing a certain number of generations and reaching a produced member with a minimum level of success regarding the output of the evaluation function. Algorithm 4.2 is a pseudocode for simple form of GA.
: GA[1] initial population randomly
As a common method for task scheduling and resource allocation in the cloud environment, each chromosome is one of the scheduling modes and is valued based on the target. Each chromosome has a gene for the number of functions, and each gene is a number from a set of numbers corresponding to the index number that determines each of the available resources. The mutation changes these numbers, using that resource to perform the specified task.
Many researchers focusing on task scheduling has been used GA approach to design scheduling framework. Pang et al. in [59] used GA to expand the search range of solutions due to GA mutation and crossover ability. Saha et al. in [60] introduced an algorithm that uses GA to minimize the waiting time and queue length in their considered system. Cui et al. in [58] proposed a workflow task scheduling algorithm based on GA that consists of a two-dimensional coding method and has a novelty in genetic crossover and mutation operation to increase population diversity. Paper [79] proposed a scheduling algorithm based on the multi-objective genetic algorithm. Its goal is to decrease energy usage and earn the provided access by agencies. This makes an appropriate scheduling mapping as per user real-time needs.
Modified Genetic Algorithm is similar to the general genetic algorithm while the first generation is received spatial attention [61]. For example, eight chromosomes are produced first, and all organs are random in the general genetic method. However, in the modified version, it is suggested that some of these organs be made in different ways to help to achieve a better answer. That is because these methods themselves have pursued the possibility of achieving a better answer. For this reason, one of the primary members assigns tasks sorted in ascending order by size to resources, which are sorted by speed. In another member, tasks are assigned in descending order by size to resources sorted by speed. These two cause these traits to be deliberately introduced to the population and cause the hope of increasing the speed of finding the answer.
In general, each algorithm has advantages and disadvantages, and trying to combine algorithms to obtain benefits of both is common. One of the problems with the genetic algorithm is that it is slow because the combination of chromosomes can destroy the valuable part of the product. The use of greedy algorithms accelerates operations and results in fewer execution cycles. In [62], unlike many genetic algorithms that only pay attention to the completion time of all tasks, the combined algorithm considers the average response time, balance degree, service quality, and cost of work. In this algorithm, everyone has a chance to produce the next generation based on the amount of a fitness function, defined other statistical functions for the intersection, and mutation that decreases over time. At first, a large amount of intersection and mutation makes more space visible, and as it reduces, the rate of convergence and finding a better answer increases. Note that the absence of an intersection event means selecting and transferring the same member directly to the next generation. However, to improve the work, the greedy algorithm is used in such a way that, after applying the intersection and mutation, the following works are done: Total processing time computation for different virtual machines. Sorting virtual machines by computed amounts, finding the task with the shortest execution time, and choosing the task on the slowest machine. If it is the fastest machine, then the job is done, in other words, the worst run time is on the fastest node, and practically nothing can be done. Otherwise, this task will be transferred to the fastest processing node.
These steps continue until the job is done, and then members are replaced. Note, although this operation improves balance and helps to improve output, it also reduces the chance of examining the entire issue space. Of course, this case can be ignored due to time limitations. The quality of services and financial issues have also been considered during the evaluation of chromosomes, which are not difficult to apply. Regardless of the above greedy section, a multi-component evaluation function is needed.
There are applications in the task performance matters while there are dependencies between tasks modeled by a workflow [63]. For example, in a multi-stage MapReduce, the input of a task can be the output of other tasks. In this case, it is common to use a DAG to model task dependencies. In addition to the priorities, the order of dependencies has to be met in such scheduling. Therefore, Workflow Scheduling using GA follows the order of tasks to perform any task in the left genes sooner. As a result, it will face a severe negative score during the evaluation if priorities are not met. The algorithm also needs a resource selection function for each task, a Min-Min algorithm. Note that genes represent each task’s performance on each chromosome, so duplicate numbers should not be.
One of the most popular algorithms for swarm intelligence is particle swarm optimization (PSO). This algorithm is generally several randomly generated particles that start moving in the problem space and are updated to get closer to the optimal solution. PSO algorithm is simply like several hill-climbing agents searching in the problem space with different starting points. One of the most critical and effective superiority of PSO is that a particle considers both its best-found point and the best-found point so far by all other particles whereas, considering both of these points on its motion. Algorithm 4.2 is a pseudocode for simple form of PSO. In the following, three versions of particle swarm optimization are described. However, there are many versions regarding various applications. Pradhan et al. [57] proposed a great overview of PSO based algorithms in cloud computing.
: PSO[1]
Tsai et al. [50] proposed multiple particle swarm optimization for task scheduling in the cloud environment. The evaluation function has several different inputs in this method, e.g., the cost and returns time. As a result, a function is merely a weighted average of the various input values normalized to a specific range when necessary.
Saeedi et al. [51] proposed an improved many-objective particle swarm optimization algorithm for dynamic workflow scheduling in the cloud environment. Its goal is to minimize the makespan, the cost and the maximization of reliability for users and energy consumption for providers. Moreover, paper [52] proposed a bi-criteria priority-based particle swarm optimization to schedule workflow tasks. This method minimizes the execution cost and time with specified deadlines and meets budget constraints.
Particle swarm optimization can be combined with other algorithms to take advantage of other methods. A comprehensive review is presented in paper [54]. For example, paper [53] proposed a scheduling algorithm by combining PSO with GA and ant colony algorithm. As a result, the combination of PSO and GA compensates for the low genetic speed while escaping from local optimums.
Cost and time in data flow computing are crucial while paying attention to only one of these factors can lead to serious challenges for the other factor due to their contradictory behavior. The paper [55] proposed genetic algorithm based on greedy strategy. It is is focused on meeting deadlines and speed of convergence while also considering costs. This paper divides all particles into equal groups, and this division causes a kind of distribution that, according to the paper, is useful in managing massive data. In addition, the size of the group changes, and it is dynamic. This resizing allows the speed of convergence to be controlled. If the groups’ size is small, more space is observed, making it easier to escape from local optimums. In addition, each time, only the position of the worst particle in each group is updated, not all the particles, which leads to the observation of more space and, of course, a reduction in the rate of convergence. Note that each group is seen as a large particle.
Another innovation in paper [55] is considering the importance of numbering indexes in space. For example, when moving from the first position to the second position, numbers between the two have no special meaning. Still, creating a valuation function and calculating the proportion in space makes points between them meaningful. A matrix is calculated, which is the time of execution of each task on each node. A matrix is also calculated, representing the information transfer time between nodes. Normally pointers to pointers are meaningless, but efforts have been made to improve numbers in this paper. This numbering is done according to the importance of the cost and reaching deadlines. It is clear that not reaching the deadline is very undesirable, so first arrange them according to it, and then if several items have the same amount, arrange them based on cost. An adaptive renumbering strategy is proposed to make the index of resources meaningful. It adaptively uses two metrics related to execution time and execution cost, respectively, to sort and renumber resources to make the learning among particles clearer and more reasonable.
It is necessary to note that the paper mentioned can find a potential balance between diversity and convergence, and several groups are coevolved using the master-slave multigroup distributed model.
Another algorithm is antlion. It has been named in works that examine the behavior between antlions and ants [73, 74]. In this method, ants move in the problem space and search for food. At the same time, antlions try to trap ants by creating traps, finding better places for traps, and building bigger traps. In addition to these, a trapped ant tries to escape while the antlion tries to slow it down by throwing pebbles to catch the ant.
Like nature, ants move randomly, which makes the whole space of the problem visible. Movements of ants are in multidimensional space, as each dimension represents one of the considered characteristics. It should be noted that ants are like particles in optimizing particle swarm or chromosomes of the genetic algorithm.
Features of the antlion Algorithm are as follows: Movements are random in all dimensions. The degree of possibility of accidental movement is affected by ant traps. As antlions receive better adaption, their traps become bigger. The term elite is the same as the antlion with the best fitness. Ants can be caught by any of antlions at any stage. For ants to move towards the antlion, the effect of random movements decreases over time. If an ant is fitter than an antlion, it is caught in the middle of a trap by an antlion. In this case, the antlion builds a new trap there. Random movements must be in the problem space and not outside. For this reason, normalization occurs, which affects the minimum and maximum possible value of each dimension. All ants have a chance of success based on the output of a fitness function. In hunting, it is assumed that each ant is only for one antlion. Antlion tries to trap ants and slow down movements of ants. In this regard, a coefficient is applied that is affected by the number of execution rounds to the total execution rounds, which causes it to remain in the optimized points. The final elite is the best match among all antlions.
The cuckoo is a bird in nature that attempts to survive by laying its eggs in other birds’ nests. In the meantime, the attempt is to find nests that can deceive the host bird, and in this case, the bird tries to be in the same areas next time, and in practice, convergent behavior occurs. The research on the use of cuckoos has been investigated by presenting the implementation in such a way that each cuckoo creates a new answer, and tasks are the eggs, and nests are the processors [72]. Each time eggs generation occurs, a new mapping is produced, mapping success is evaluated, and successive implementation cycles eventually lead to an optimal response. Also, the assumption that each nest has the capacity of one cocoa egg solves the problem of interfering with the demand for tasks from the same sources.
Gravitational Search Algorithm (GSA) is constructed based on the law of Gravity, and the notion of mass interactions and its searcher agents are collections of masses [68, 69, 70, 71]. Improved Lévy based whale optimization algorithm is introduced by paper [75] to reduce costs and resource waste and save energy. Moreover, task scheduling based on Cat swarm and Bat behavior [76], based on mean grey wolf optimization [77] and based on self-adaptive fruit fly optimization [78] are among the other nature-inspired methods.
Using fuzzy logic and fuzzy system to improve metaheuristic algorithms
Fuzzy logic and fuzzy systems are suitable for an environment where several factors are not precisely identified or already known. The main advantage of using a fuzzy approach for defining a controller is that there is no need for complex mathematical modeling to develop the controller. Fuzzy logic is about approximations, not exact solutions. The output of a fuzzy system is not an exact number but a number in the range of 0 to 1 as one represents total accuracy. Further, such behavior is observed frequently in the real world [56].
Paper [56] proposed a hybrid task scheduling algorithm based on a fuzzy system and Modified Particle Swarm Optimization technique to enhance load balancing and cloud throughput. The initial population is generated in the PSO part by assigning the smallest tasks to virtual machines with the fastest processor. Moreover, for fitness, the calculation uses the fuzzy system while the length of tasks, CPU speed, RAM size, and the total execution time are the input of the fuzzy system. Another example is the paper [65] that utilizes fuzzy logic to improve its result. In their method, the Gravitational Search Algorithm (GSA) is considered a base algorithm, and fuzzy logic is used to determine the number of masses that affect one another during the implementation of the GSA. As other examples, we can mention [66, 67] that use fuzzy logic to calculate the fitness value in GA and to improve the priority-based Max-Min algorithm, respectively.
Learning algorithms
Recently, there has been increased interest in using artificial intelligence and learning models. Various methods based on learning algorithms have been proposed to help get the job done. In this regard, trying to allocate resources, schedule jobs, and predict workloads are among the popular ones.
There are several strategies in artificial intelligence used to solve problems. The general category is called machine learning (ML). Moreover, reinforcement learning (RL) and deep learning (DL) strategies have received significant attention. In the following, ML, RL, and DL methods are briefly explained with representative algorithms in each category. The mentioned papers of these categories are given in Table 4.
Learning algorithms
Learning algorithms
Machine learning is a subset of methods based on artificial intelligence. Its primary focus is developing computer programs that can access data and use it for their learning. The learning process begins with observations and then uses data to find a pattern in the data and make better decisions. The main goal is to allow the computer to learn automatically without human intervention and to be able to adjust its actions accordingly.
One of the simplest models in machine learning is the Support Vector Machine (SVM). For example, a virtual resource scheduling prediction scheme based on SVM is proposed in [100]. In this scheme, reconstructing the phase space produces SVM inputs for training and predicting. As another example, a workload prediction model based on machine learning is presented in [101]. This algorithm selects idle VMs or VMs with a low workload and turns them off to reduce power consumption.
Reinforcement learning
Reinforcement Learning is among the most popular algorithms in machine learning. In these methods, a learning agent starts to experience different situations and gather information with the help of feedback. As a result, it can act better in future decisions. Usually, there is a linear equation of the weighted average of the current score and the score from the feedback. Reinforcement learning can be learned based on experience without the need for basic computation rules, leading to flexibility in various issues. Here, several examples of algorithms that utilize Reinforcement Learning are provided.
Algorithm 5.2 is a pseudocode of its simple form.
RL can be said to be a promising approach to auto-scale in the cloud, as it is possible to learn clear, dynamic, and consistent resource management policies [85].
: RL[1] initial policy randomly
! (converge on policy)
Attention has been paid to energy consumption, but it should not be forgotten that less energy consumption means fewer resources and reduces execution time. Therefore, a balance must be struck between these two. The proposed model in the paper [80] also tries to minimize energy consumption without violating the contract with the user and exceeding the deadlines. In this regard, an attempt has been made to provide a model to predict energy consumption and know how much energy consumption is to be faced. Therefore, the valuation function is defined based on the absolute value of the difference between the predicted amount and the experienced amount in practice. This difference is called the forecast error, and it should be reduced if possible. The point to be added is that the forecasting cost can be updated in different cases with different parameters and used in algorithms mentioned earlier and need to be estimated.
Paper [81] proposed an energy-aware multi-objective reinforcement learning algorithm that tries to minimize the makespan and energy consumption while meeting the budget constraint for a multi-objective workflow scheduling problem. In addition, works in [82, 83] used a multi-agent reinforcement learning algorithm for job scheduling.
The complexity of scheduling increases if several parameters need to be optimized, especially if these parameters conflict with cost and makespan. The paper [14] investigated a bi-objective scheduling problem for deadline-sensitive tasks in the heterogeneous cloud environment. The scheduling objectives are to minimize energy consumption and makespan. It proposed a scheduling algorithm that uses reinforcement learning behavior. In this scheduling, a flexible decision-making unit learns from the performed operation and improves itself. The presence of this reinforcement learning mode helps to approach the optimal answer in a dynamic environment. It should be noted that automatic learning is suitable for dynamic and complex environments with many uncertainties. Therefore, the introduced method with such flexibility should be able to allocate resources to tasks best. In reinforcement learning, if the action selected for one task is successful, the probability for other actions may decrease, and the probability of this action will increase and vice versa.
Deep learning
Deep Learning is a new subset of machine learning that has increasingly become a popular trend in the last few years. This popular method is easy to use, powerful, and an important element of data science. Deep learning is beneficial to perform tasks with a large amount of data. Another important point is to use experiences of previous cases like the reinforcement learning paradigm. Some deep learning models can also learn from the past and influence their internal information matrix. Also, they can understand sequential behavior when receiving sequences. One-dimensional Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Long Short-Term Memory (LSTM) are suitable models for this kind of input.
As an example, in LSTM based algorithm proposed in paper [94], there is a storage resource that is updated at each step and uses the previous information as an additional input and uses it to generate new output. This leads to detecting various behaviors such as high and low slopes and oscillations while reducing the volume of the stored matrix. Multiple resources, including CPU, bandwidth, RAM, and storage resources, are used as inputs, which means the model regards all of them. As another example of LSTM utilization, work in paper [95] used this model to predict the amount of work that would be requested at any given time. As this paper states, the advantages of this model are the ability to detect patterns that exist at different time intervals, the ability to decide what period is important and influential automatically, and provides a nonlinear behavior that can more easily manage possible noise than something like the regression line.
Q-learning is a model-free reinforcement learning algorithm. This algorithm considers the problem state space as a set of spaces and tries to move and learn between these spaces. This method creates a policy of which path to go in each case. This algorithm is fast, and essential information can be easily applied by writing in the value of each house. Q-learning defines a measure of the success of monitoring, allocating, and controlling a scheduling process. This measure is a linear combination of performance and cost. In the case of rapid changes in inputs, values of the Q-learning table may fluctuate, whereas to compensate, weights are frozen. After receiving the result of several steps, updates will occur. Many deep learning models somehow follow behaviors of machine learning algorithms, such as using reinforcement learning and creating a model called Deep Reinforcement Learning (DRL). For example, Wang et al. [93] proposed a new DRL based algorithm. This was also introduced in a model called deep Q-learning (DQL). As an example, Kaur et al. [92] proposed DQL based algorithm to improve the earliest-finish-time. The paper [86] aims to balance resource consumption and execution time by using deep learning.
Another example of Q-learning for task scheduling as an energy-efficient cloud computing is paper [84]. Paper [87] proposed deep Q-learning task scheduling, and it is aimed at solving the problem of handling directed acyclic graphs (DAG). Another good example is [92].
Zhang et al. [88] proposed a DRL-based scheduling approach to minimize the job completion time, the load imbalance value, and total cost. It is a multi-task deep reinforcement learning approach for scalable parallel task scheduling. Paper [89] used DRL to reduce energy consumption and cost through resource provisioning and task scheduling. Paper [90] used DRL for QoS-aware job scheduling. Paper [91] proposed a job scheduling algorithm based on deep reinforcement learning to minimize the makespan.
Workload prediction can benefit different proposed algorithms in cloud management and scheduling. An accurate forecast helps mitigate energy consumption, meet the required quality of service, predicting energy consumption [98]. As an example, paper [99] proposed a deep learning model for predicting cloud workload. Paper [96] used LSTM for forecasting CPU usage of machines in data centers. Apart from the above, artificial intelligence has various other usages in cloud computing; for example, Gao et al. [97] proposed an algorithm to predict failure by utilizing Bidirectional Long Short-Term Memory as a model with two LSTMs. The mentioned paper aims to predict whether tasks and jobs are failed or completed.
Algorithms based on game theory
Game theory (GT) mainly focuses on the strategic interaction among rational decision-makers and is widely applied in all fields including logic and systems science [102]. Game theory models have been developed to achieve goals such as increasing resource utilization and high quality of service for consumers and allocating resources efficiently and equitably between cloud centers, cloud service providers, and data consumers [103]. There are many good paper examples, [104] proposed algorithm schedule assigns each task on its best virtual machine based on Matching Game theory in the final phase. Each task can choose the appropriate machine in this model, respecting each machine’s maximum number of quotas. As an example, [105] proposed using game theory and optimization methods in optimization problems. It is necessary to determine the strategy, payoff, and players in game theory. In the context of scheduling, each task is assumed to be a player, and each strategy is one of the virtual machines, and each task tries to receive a better total output by choosing the suitable virtual machine. For payoff, it used completion time and waiting time. Another examples are [106, 107, 108]. For an overview, simple game theory based pseudocode is available in Algorithm 6.
: Simple scheduling based on game theory[1]
In game theory, two main classes are Cooperative and non-cooperative, representing games in which players work together to achieve the overall goal and compete to achieve their goals, respectively. For scheduling, Patra et al. [109] have implemented both cases and tried to provide proper real-time task scheduling in cloud computing. According to the output of this work, the cooperative type had a more successful result. [110] proposed a cooperative game model for scheduling cloud computing tasks. Participants can optimize their game strategy based on a series of rational assumptions. A sequential game-based scheduling algorithm is proposed based on the Nash equilibrium solution analysis. Ye et al. [111] is a good example of non-cooperatives.
Nash equilibrium is a concept in game theory that no player gets a better payoff by changing its strategy assuming all other players do not change their strategy [112]. The work in paper [113] used game theory to minimize thermal imbalance and hotspots while it introduced a game strategy to allocate resources in data centers. In this paper, tasks are allocated according to their temperature status and the effect on other nodes. In addition, Nash equilibrium is used to provide a non-cooperative game as a solution. The work in paper [114] used game theory to help cloud providers in the decision-making process while the goal is to increase resource utilization and profit. Paper [115] has been tried to reduce the average response time and energy consumption by using the Stackelberg game. Paper [116] proposed a model based on game theory that the job scheduling is considered as a n-player and non-cooperative game. In this model, each job is a player whose payoff is the amount of makespan. Moreover, achieving the optimal solution in planning with Nash equilibrium is checked. Genetic algorithms have also been used to find different points to reach the Nash equilibrium. Paper [117] introduced Nash Equilibrium-based VM Replacement that is designed such that most data center hosts are either in optimal resource utilization or shut down. Paper [118] introduced the usage of Nash Equilibrium concepts to improve throughput and reduce the overall idle time of the processors. Overall, there are many related works in the context of Nash equilibrium in cloud environments [110, 112, 119, 120, 121].
MapReduce review as an example
Different categories of scheduling in cloud computing were introduced in the previous sections. The following is an exploration of a famous example of using cloud computing. This section examine MapReduce and some proposed ideas and algorithms to improve its performance, especially the scheduling part.
MapReduce is a programming model for processing and generating large data sets. Users specify a map function that processes a key/value pair to create a set of intermediate key/value pairs and a reduce function that merges all intermediate values associated with the same intermediate key [122]. The widespread popularity of big data processing platforms using the MapReduce framework is the growing demand to optimize their performance for various purposes. In particular, enhancing resources and job scheduling are becoming critical since they fundamentally determine whether applications can achieve the performance goals in different use cases. Scheduling plays a vital role in big data, mainly in reducing the execution time and cost of processing [123].
MapReduce has become popular because of its ability to perform parallel tasks, balance data sharing, efficient use of resources, and optimal management. In addition, the ease of use increased its popularity. Due to the high popularity of MapReduce, it has attracted the attention of many researchers, and there is much discussion about its optimization. Many famous companies like Google and Yahoo have been instrumental in developing and improving MapReduce. Many sources on this subject provide helpful information, including papers [30, 124, 125], which are references for a general introduction. A brief introduction to this context is provided in the following.
The design of MapReduce consists of different parts, and there is variety in its implementation, but in general, the main parts are common. As the name implies, there are two critical steps: Map and Reduce. Nodes are also categorized in several ways, such as master and slave nodes or manager and worker nodes or nominal nodes, and data nodes. Nominal nodes are responsible for the overall management of operations and are responsible for dividing tasks and specifying tasks for other nodes. On the other hand, they are responsible for monitoring the performance of others and dealing with the problem of failed nodes. Data nodes are responsible for performing their assigned tasks. The nominal nodes send a message to the worker nodes to monitor, and if they do not receive a response, it means that the node is in trouble, which means that it must think about delegating its tasks to other nodes.
Hadoop
Hadoop is one of the most popular open-source implementations of MapReduce. This implementation provides a software framework for distributed storage and processing of big data.
Hadoop is widely used because it can handle all types of data like structured or unstructured, and supports redundancy, scalability, parallel processing, and distributed architecture [30]. Some Hadoop technology companies are Amazon Web Services, Cloudera, ScienceSoft, Pivotal, Hortonworks, IBM, MapR.
In the MapReduce process, the data is split between different nodes and processed based on a user-defined function. After that, it becomes a set of crucial order and value pairs. This set will be the output of the mapping stage and the next stage’s input. This data is called intermediate data and is used as input to nodes that are supposed to produce the final output and reduce the so-called intermediate data to the last data. In the meantime, it is important to choose which node each of these pairs of orders will be on. This is called shuffling. Various challenges may be raised in this regard, such as maintaining data security at different stages, optimizing processes, selecting appropriate nodes, and dealing with failed or slowed-down nodes.
With the provision of Hadoop infrastructure, the user only needs to prepare the two-step executable functions and try to determine the configurable parameters in the executive system and not deal with the complexities of the work. Another challenge is the issue of the locality. There is a gap between the node that has to process a specific task and its associated data. The shorter the distance, the better the performance because the cost of data transfer time is reduced. The problem is that it is not always possible to place data on the associated node, making it more complicated. Kalia et al. [126] proposed a good overview of Hadoop framework, Hadoop shortcomings and issues, and different coupled algorithms.
Algorithms based on MapReduce
Numerous instances can be seen in various papers and studies that attempt to provide a suitable function for a particular task or algorithm, in other words, to rewrite different algorithms based on MapReduce. An introductory example is the counting of different words in a text. This example, although simple, describes the operation well. In what follows, a brief description of word counting is given. In this case, a counter is designed to create statistics of the repetition of words in a text. Figure 3 is a sample abstract example of word counting that is used for description. As a part of this method, each of the sentences on the left is assigned to one of the processing nodes. Then, each of these nodes arranges a pair for a received word such that the word and one are set as its key and its value, respectively. This indicates one repetition. Keys sort this data, which is called the intermediate data set, and all pairs of sequences with the same initial letter are matched to a node to reduce. This node calculates the total value of pairs with the same key, and now the number of repetitions of each word will be the product of the output aggregation of the reducing nodes. Note that this is a simple expression of word counting and some unpleasant effects are available, such as an imbalance in the allocation of intermediate data to the reduction nodes. Different algorithms can be used for scheduling in MapReduce. For example, Pandey et al. [127] proposed a heuristic method that tries to improve energy consumption. Singh et al. [128] proposed a metaheuristic based method. This paper used ant colony optimization.
An example of MapReduce for word counting.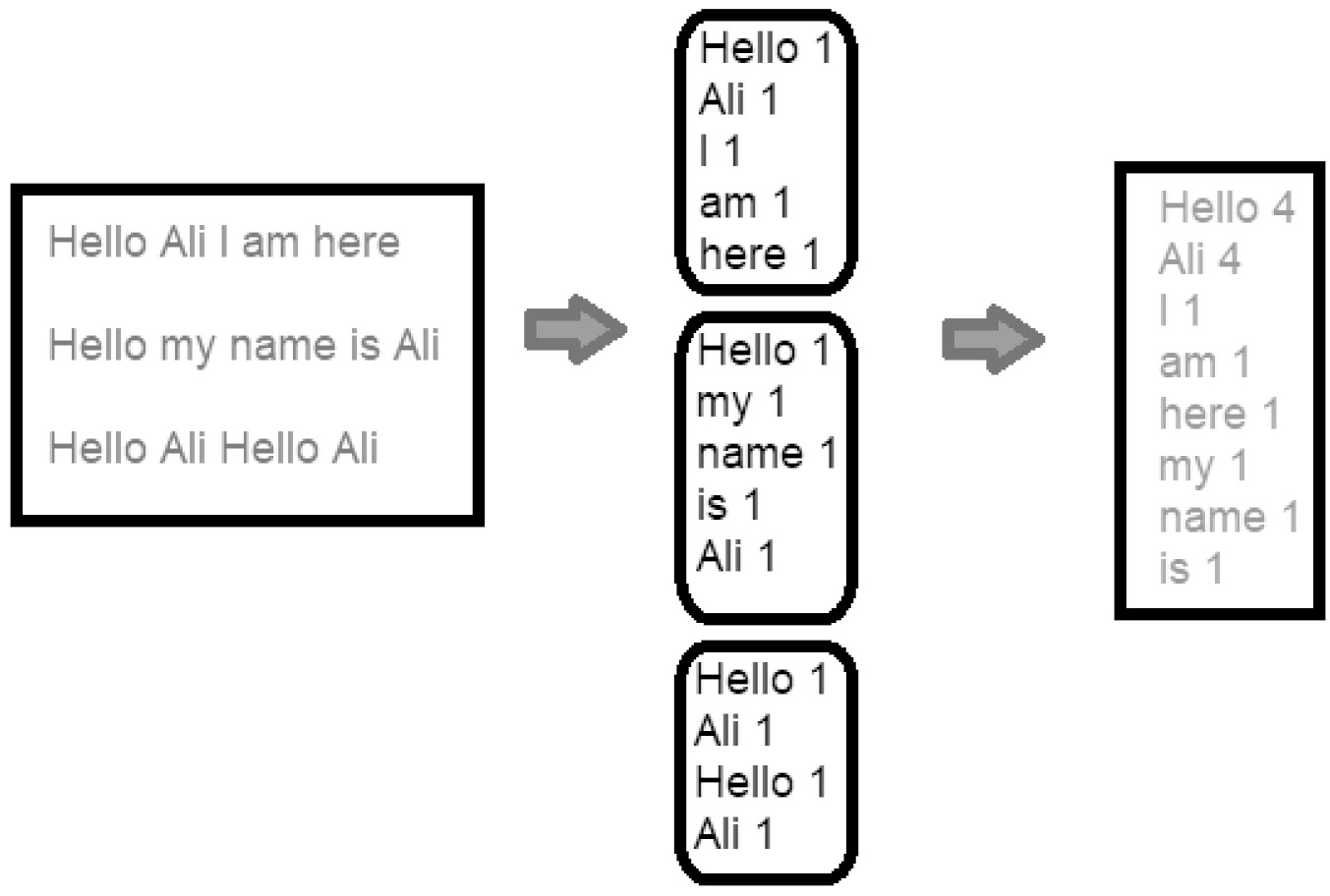
As other examples, It can mention the problem of rewriting the decision tree algorithm with MapReduce [129]. Another simple example is the estimation of the number Pi [125]. The input data are many different points that are randomly generated in a square interval. Determine whether the point belongs to an enclosed circle or has a perpendicular rectangle, and as a result, the middle data keys are the same as the circle and the square.
Intermediate data is an important part of the MapReduce process because it connects the two main parts; Map and Reduce. i.e., the output of the first stage is the input of the next stage. Knowing that different nodes may be disrupted, all intermediate data associated with a disrupted node must be reproduced. Therefore, a repetitive process occurs. By looking at this issue from a statistical point of view and given a large amount of data, this concern will remain even in the face of a small percentage of failure.
A paper by Moise et al. [130] aimed to solve this problem by using a distributed file system. This type of file is ideal for applications with large data volumes and data transactions that are fast and high, which is precisely what happens to intermediate data. The complete reproduction process does not need to occur again using a distributed file system and optimality is brought for node failures. However, an effective data management method is essential while a distributed file system is utilized. BlobSeer is a large-scale distributed storage service that addresses advanced data management requirements resulting from ever-increasing data sizes. This system can address concerns related to the management. The BlobSeer collects large volumes of data with a binary view written separately after each information change, and the previous information is not lost, precisely what demands here. The paper [130] has succeeded in eliminating reproduction overheads in the case of failure, whereas by providing management service facilities, there will be no challenge in the productivity of distributed files. As a result, the system will behave better, and the processing overhead will be less.
In various cases, a sequence of MapReduce invocations is necessary to solve the problem, i.e., the problem is better to be divided into smaller subproblems. This issue does not affect the optimality of the model itself but rather an improved method for solving it. One of its advantages is reducing the overhead of dealing with failure during the process and simplifying the problem. paper [131] proposed Hashdoop, which is a MapReduce framework for network anomaly detection.
In Hashdoop, for example, if the number of packets sent from a source to a destination is too high, unusual behavior is possible. The proposed algorithm of Hashdoop consists of two MapReduce steps. First, the received data is checked in two ways based on origin and destination, and outputs of this step of MapReduce are categories whose key is their common origin or their common goal. In the meantime, it will sort these data chronologically, and in the second step, it will count the repetition of each input and output pair at different times. Abnormal behavior is recognized when a large value indicator is large for a regular set of origin, destination, and time. As a result, the complexity of the problem has been dramatically reduced in Hashdoop.
Moreover, to improve MapReduce performance, one thing that can be done is to delete the somehow wrong data in a related context. Suppose the administrator node notices that nodes have trouble processing part of the data, and failure occurs. In these cases, a part of the input data is probably flawed, and thus, the nominal node itself commands to remove that data from the input data. This will improve performance and deal with multiple failures for such reasons.
Comparison between four categories of scheduling algorithms
Comparison between four categories of scheduling algorithms
Many scheduling algorithms have been proposed for MapReduce taking into account various factors such as user preferences, makespan, deadline, and available resources [123]. For example, consider meeting the deadline one of the desired scheduling factors. Paper [35] consider this criterion. The time required for processing, including mapping and reduction, is calculated, and the purpose of this paper is to serve the maximum number of tasks requested. The order of task checking is based on their deadlines, and if it is estimated that a task cannot complete the process before its deadline, it is ignored and set aside. Such methods tend to prioritize tasks or even eliminate some of them rather than targeting the MapReducing pattern itself.
Scheduling methods are generally divided into two categories; the static type occurs at the beginning of the schedule. The second type is dynamic, in which decisions are made during work upon receiving each task. Scheduling algorithms consider and prioritize only one component: availability of resources, FIFO, and fair scheduling. Section 3 covers the overview of these scheduling algorithms that there is not much distinction between methods for MapReduce and general ones.
Conclusion
Improving performance is one of the most significant concerns in the cloud environment. Meanwhile, the adopted resource allocation and job scheduling significantly affect cloud management performance. This paper explores motivations for demanding better scheduling and investigates various scheduling methods. Therefore, this paper focuses on examining scheduling algorithms in four main categories: deterministic algorithms, metaheuristic algorithms, learning algorithms, and algorithms based on game theory. Deterministic algorithms are simpler but, at the same time, have less flexibility. In the case of complicated problems, attempts have been made to find a near-optimal answer with indefinite methods and with the help of metaheuristic algorithms. Providing suitable methods becomes more and more difficult as the situation becomes increasingly complex. Accordingly, the utilization of learner patterns, especially reinforcement learning and deep learning, has facilitated implementation and high processing power and understanding of time patterns. Game theory is another helpful approach because it can study relations between agents and make better strategies. Moreover, a comparison between the four proposed categories are provided in Table. 5. In the end, in this paper, there is a review of the MapReduce framework as a example of big data processing that required proper scheduling approaches for accepted performance. Due to the increasing importance and popularity of edge computing, reviewing existing papers in this field that aims to improve performance and better scheduling can guide future reviews. The combination of simpler algorithms can also be seen in different algorithms. In this paper, we tried to examine the advantages of each method, the possibility of combining various algorithms, and better achievable results.
Footnotes
Author’s Bios