
Abstract
In this paper, we propose a new cloud reactive fault management technique called Hybrid Redundant Array of Independent resources for cloud computing (H_RAIC). The latter uses a new concept called Redundant Array of Independent resources for cloud computing (CRAIR), which is inspired by a powerful conventional technique called Redundant Arrays of Inexpensive Disks (RAID). H_RAIC takes into consideration the cloud resources state and aims to satisfy both cloud users and cloud provider requirements. Our solution was compared with the replication technique which represents a specific case of CRAIR, and with other CRAIR levels defined in this paper. The results show that our technique is a promising solution, that can be used to meet both user and provider requirements.

Introduction
Nowadays, cloud technology continues to rank among the most important technologies, being increasingly solicited by new fields, due to its power in terms of storage capacity, variation in provided service, etc. This power leads to the migration of an important number of data and services to the cloud environments. The migration requires a huge number of resources, which are mainly Virtual Machines (VM) and Physical Machines (PM). In addition to the huge required quantity of resources, the age of some resources is becoming increasingly older. These factors increase the probability to get a resource failure.
Unfortunately, the prediction of a fault cannot be ensured at 100%, hence the need to use a reactive fault tolerance mechanism that can reestablish the service quickly without losing data after the failure.
Cloud users and providers are considered as the main actors in cloud architecture. Each actor has its requirements that must be satisfied. The requirements can vary from a user to another and from a provider to another. The users’ requirements can be data conservation, service continuity; meanwhile, the users can favor a requirement over another. Meanwhile the optimization of the total space consumed is a common objective between all providers, which can help the provider to minimize the total number of used resources, subsequently, economizes other parameters, like total cost, energy, etc.
To satisfy both users and providers, a powerful fault tolerance management mechanism need to be deployed. The solution must ensure a trade-off between users’ and provider requirements. The trade-off will have to ensure reliable data discovery, fast re-establishment of services in the interest of cloud users, and the total used space saving in the interest of cloud provider.
In this work, we propose a reactive fault tolerance management, called Hybrid Redundant Array of Independent resources for Cloud computing (H_RAIC). The latter allows both cloud users and the cloud provider to define the nature of their resources. Our approach manages the fault tolerance according to the values defined by both the users and the provider, with the aim to ensure a trade-off between the users and provider requirements.
H_RAIC is inspired by RAID [14, 3] technology. The latter is considered as a powerful fault tolerance technique implemented in the most open-source operating systems. It aims to manage the disk faults and can be deployed either as software solutions as or using a dedicated hardware equipment.
In the present work, we are interested in three parameters which are: Total used space, recovery time, and the maximal number of allowed simultaneous faults, bearing in mind that if the latter is not respected, the failed resource cannot recovered.
The contributions of this work are realized through two main stages:
In the first stage, we define a new concept called CRAIR, and then present its different levels in detail. Each level can be considered as an independent fault tolerance management technique, while bearing in mind that all CRAIR levels are inspired by RAID. In the second stage, the H_RAIC approach which is based on the different CRAIR defined levels is introduced. H_RAIC process consists in three steps. The first step consists to divide the resources into multiple sets according to their nature. Then in the second one, each set is divided into subsets of independent resources. In the last step, one of the RAID levels is applied on each subset according to its nature.
In order to show the reliability of the H_RAIC approach, a comparison of the latter with different defined levels, and with the replication technique is done in the evaluation section. The comparison shows that the H_RAIC solution can be considered as a powerful solution, which can satisfy both user and provider.
The remainder of this paper is organized as follows. Section 2 gives a brief illustration of the related work. Section 3 presents the architecture modeling on which H_RAIC can be deployed. Section 4 provides the fundamental concepts allowing a good understanding of the functioning of the H_RAIC solution. Section 5 presents the details of H_RAIC functioning, including the global H_RAIC process and the different CRAIR levels. Section 6 introduces the evaluation phase, by defining measured parameters in the first part and presenting the results in the second part. Section 7 analyses the obtained results. Finally, Section 8 gives the conclusion and the future work.
Literature review
Based on existing fault management techniques used in cloud computing, we can group them in the following taxonomy:
Fault type. Which are crash faults and byzantine faults [7]. A crash fault is due to a failure of one or more system components. Meanwhile, a byzantine faults occurs when ambiguities in the expected output resulting appears.
Detection method. For managing the two types of faults described above, essentially two kinds of techniques can be used: proactive and reactive techniques [6]. In the first one, the technique is in charge to predict and react before the fault appearance, whereas in the second one, the technique reacts after the fault.
Repair method. From fault tolerance repairing method point of view, two main standards of fault tolerance are defined, namely Proactive Fault Tolerance Policy and Reactive Fault Tolerant Policy [19]. The first one envisages avoiding failures, while the second one aims to reduce the effects of occurring faults. Considering the nature of our proposed policy, only some Reactive Fault Tolerant policies will be presented in the remainder of this section.
In [20], the authors have discussed some reactive fault tolerance approaches, among which we mention:
Task Resubmission: this technique is based on task resubmission when a fault is detected. The resubmission processes must be done without interrupting the system workflow.
Check-pointing/Restart: this technique allows restarting the failed cloud component (application, VM or PM) from a saved state called checkpoint. It is considered as an efficient fault tolerance technique for high computation intensive applications hosted in the cloud.
Replication: this technique consists to keep multiple copies of data or object, which will be used when a fault occurs. According to [2], the replication technique is a popular solution with many varieties.
In addition to Checkpoint/Restart, Replication, some other techniques that aim to ensure a reactive fault tolerance management are discussed in [13, 1], for examples, user-defined exception handling, S-Guard, and Rescue Overflow.
k-fault [11, 16] is a specific case of the replication technique in which k additional copy of service is configured, which allows to ensure the service continuity if k servers fail simultaneously.
An adaptation of RAID technique in cloud environment is discussed in [5], where a combination of local and cloud storage in a RAID-like configuration is proposed. The proposed solution (called RAID 4.5) is based on RAID 4, with the addition of a second dedicated parity drive. In [8], another solution inspired by RAID (level 6) is proposed. The solution allows to discover the lost resource after fault, with the aim of optimizing the storage space used.
SaveMe [15] is a cloud storage system that proposes to use a single virtual volume for each user by combining public and private cloud storage. SaveMe supports data encryption, redundancy, and scalable volume management. To achieve the goal of data availability, all data should be redundantly stored to multiple cloud storage services that are independent of each other.
In [6], the authors have proposed a mechanism for a multi-cloud private data backup system, using data deduplication to reduce the overall storage overhead, erasure coding to achieve redundancy at low overhead, and incorporate mechanisms for proof of data possession.
In [12], the authors proposed a cloud-backed storage system, for sharing and storing big data in multiple cloud providers and storage repositories, BFTCloud [18] was proposed by Yilei Zhang et al. The authors have used the dynamic replication technique, in which voluntary nodes are selected based on QoS characteristics and reliability performance. Extensive experiments on various types of Cloud environments show that BFTCloud framework guarantees the robustness of systems in the case where f resources out of a total of 3f
A collaborative approach was proposed in [17], where the authors proposed a fault tolerance management method, which divides the detection/repairing of the faults between both cloud provider and users. In the proposed method, the users are responsible of the detection and repair of the application’s fault, while the cloud provider ensures the VM and Hardware fault detection and repairing.
In [10], the authors modeled and evaluated the reliability of RAID-6 configuration implemented in the cloud infrastructure, the proposed implementations being called cloud-RAID-6. The authors proposed a hybrid analytical modeling method that combines a Markov model and a multi-valued decision diagram model.
FITCH is a fault tolerant solution for cloud computing proposed in [14], which supports the dynamic adaptation of replicated services. FITCH was designed for supporting two replication services: a crash fault-tolerant Web service and a Byzantine fault-tolerant key-value store based on state machine replication. The services are achieved through horizontal (addition/removal of replicas) and vertical (upgrading/downgrading replicas) scalability.
An adaptive framework based on both replication and checkpointing techniques is proposed in [2]. The replication is used for a VM that if it has a large performance impact on the cloud if it fails, where the number of replication is determined according to the application importance. While the checkpointing technique is adaptive, the length of checkpointing interval can be determined according to the failure probability of the VM.
Looking at the proposed techniques, we show that all the proposed techniques doesn’t takes in consideration the age of resource, which represents an important index for predicting the resource stat, then the probability of having a fault. Also the nature of resource is not considered by the proposed works, which means that some resources are more important than the other ones. The two parameters represent important issues in the existing methods, which can be considered as important challenges for the futures works. In our proposed method, both resource stat and nature are introduced.
Overall context and fundamental concepts
In the architecture that we have used in this paper, it is assumed that the cloud resources are hosted on different data centers. Two types of resources are considered: Physical Machine (PM), and Virtual Machines (VM). Each PM can host one or more VM, according to its capacity.
The PM are hosted on different data centers dispatched on geographically separate areas. In addition, the set of resources are heterogeneous, that is, each resource has its owner characteristics. In this work, the considered parameters are CPU speed, write rate on the disk, read rate from the disk, download speed, and upload speed.
The process of our proposed H_RAIC solution consists in staring by selecting the most powerful computing node (PCN) that exists in the cloud. Then, when a crash of such a resource is occurred, all data necessary for recovering the failed resources are transferred to the PCN in the first time, then, in a second time, the reconstruction of the failed resource is done on the same node (PCN), and finally, the reconstructed resource is transferred to its original host on which it was hosted before the crash appearance. The use of PCN allows finishing the operation as soon as possible on one hand, and on the other hand, allows avoiding the load of the set of other PM that host the VM currently functioning.
Before proceeding with the functional description of H_RAIC (Section 5), two main notions need to be explained:
Resource nature
The first classification of resources is called resources nature, which allows to identify the nature of such a resource. In H_RAIC solution, each resource R is coded by a string called R_nature which is composed by a sequence of three substring separated by “_”. R_nature is coded using Eq. (3.1), and it depends on the performance requirements.
In Eq. (3.1), the first substring denoted rt represents the resource type; which can take a VM or PM value. The two following substrings (pp and vn) depend on the value of rt.
The second substring denoted pp allows to define the VM nature, whereas pp is not considered in the case of resources of PM type. pp can take one of the three values in the case of resources of VM type: DATA, SERVICE, and TEST. DATA means that the resource is used for data storage where the user is interested by data more than the service continuity. SERVICE means that the VM is used to offer a service, subsequently, in the case of a crash the resources must be established as soon as possible. The last value denoted TEST indicates that the VM is used just for test, which means that it is not an important resource and its crash will not penalize the user.
The last value denoted vn represents the resource performance in the case of a resource of PM type, or the PM that hosts the VM in the case of a resource of VM type. vn can take values S, B, or M: S for a PM in a perfect state, with very low probability to fail, M for a PM which is in an medium state with a medium likelihood to fail, and B for a PM in bad state with high probability to fail.
For example, the value “VM_Data_S” means that the resource is a virtual machine used for data and hosted on a secure physical machine. All possible values that R_nature can take are: PM_B, PM_M, PM_S, VM_Data_B, VM_Data_M, VM_Data_S, VM_Test_B, VM_Test_M, VM_Test_S, VM_Service_B, VM_Service_M, and VM_Service_S.
Two main recommendations are required by the RAID technology. The first one consists in the use disks of the same size, while the second one consists in the use of independent disks. The two recommendations are inherited by H_RAIC. Hence, all the resources of the same subset are independent and have of same size.
In our formulation, two resources are considered independents if they are not hosted on the same PM, subsequently, all resources of type PM are independent; instead, two resources of type VM are considered as independents if they are not hosted on the same PM.
H_RAIC functioning
H_RAIC is a reactive fault tolerance management solution which is inspired by the RAID technique. In the present work, we are interested in the most used levels that can ensure the fault tolerance management for the architecture that we have defined in Section 3. A hybridization of the different levels is done in the objective to ensure a trade-off between cloud users and cloud provider requirements.
H_RAIC uses four basic levels of RAID and two variants of two basic RAID levels. The different used RAID levels are RAID 0, RAID 1, RAID 5, RAID 6, RAID6 with HS, and RAID5 with HS. HS allows to use a supplementary resource in standby state that can be used in the case of a crash. A RAID with HS allows to accelerate the recovering processes because a blank resource is already present.
For the Terminology used, each level x of CRAIR is inspired from RAID level x., and each level CRAIR x with HS is inspired from RAID x with HS. In what follows, the term CRAIR is the adaptation of the name RAID after its adaptation in our solution H_RAIC.
Global H_RAIC proces
The global process can be considered as a common process between all proposed CRAIR levels defined in this paper. The global process is composed of two main subprocesses, one responsible for fault detection and the other for fault repairing. The first one allows the detection of the fault. This can be ensured by a network tool that can detect the absence of the resource. Meanwhile, the second sub-process, described by Algorithm 1, is triggered after the appearance of the fault.
Algorithm 1 describes the process that allows to repair the failed resource (R_failed), where two cases are possible, VM failure and PM failure. In the first case, the first setup consists to find the subset nature of the failed resource and then recover the failed resource according to the used level of CRAIR in the second setup. In the second case in which all the failed resources are PM, all the VM hosted on the same PM are identified in a first step, and then, all these VM are reconstructed one by one using the same process like the case of VM failure. The resource independence property makes it possible to recover all VM hosted on the failed PM.
Reconstruction scheme
Figure 1 shows the scheme of the reconstruction processes triggered by a resource failure. In the figure, Subset label represents the set of resources that belong to the failed resource subset, and the transfer speed between a resource and the PCN changes from a resource to another looking to the heterogeneity of the cloud environments.
Reconstruction scheme.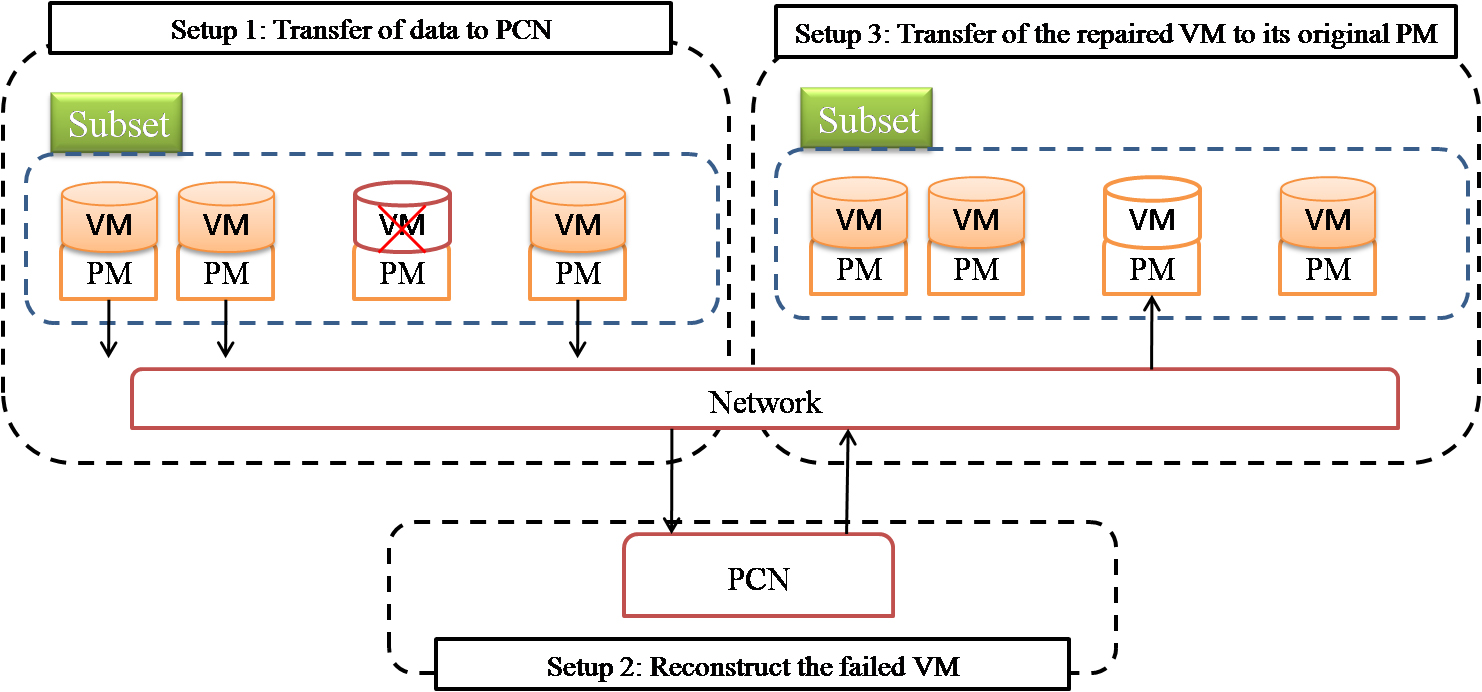
The resources that compose the cloud infrastructure are initially divided into sets of resources of same nature and then each set of resources is divided into subsets, provided that all resources in a subset are independent. Subsequently, each subset contains only the independent resources of the same nature on which the same level of CRAIR will be applied.
RAID application
As is well known, each level of RAID has weaknesses and strengths. Meanwhile, each level of RAID is recommended in some cases and not in others, according to the requirements. H_RAIC takes into account these notions alongside with the requirements of cloud provider and users, in order to find the best suitable CRAIR that will be applied while ensuring the satisfaction of both users and provider.
The value of R_nature is the key that allows to identify which level of CRAIR should be applied. For example, in the case of the sub-set that contains a VM of DATA hosted on a performing PM, we suggest to use CRAIR6. It’s true that CRAIR6 does not allow to ensure the repairing of resources in the case of more than two simultaneous failures like CRAIR. However, it is not worth to spend too much storage space (the case of RAID 1) to ensure a fault resource recovering given the low probability of failure. On the other hand, it is indispensable to be cautious, because the VM is important, and the probability to get a failure is not nil, despite its low value. For these reasons and considering the nature of this resource, we avoid to use the level 0 which doesn’t manage the faults, and the level 1 which consumes a huge space.
The rest of all possible cases are summarized in Table 1. The value of R_nature is exposed in the first column, and the corresponding RAID Level is described in the second column.
Resource nature/CRAIR level correspondence
Resource nature/CRAIR level correspondence
The reconstruction of such a failed resource depends on the used level of CRAIR. In the remainder of this section, the functioning of each CRAIR level will be presented, by defining the way in which RAID is applied. The application pertains to the backup creation, and the recovery of the failed resource.
We assume that we have a cloud composed of a set of PM and VM connected by a network.
Remember that each subset contains only independent resources of the same size. Consequently, Eq. (4.5) is automatically satisfied for the whole set of resources.
where
CRAIR0: In this case, each subset CRAIR1: This level can also be called mirroring level, in CRAIR1, it is assumed that we have a subset that contains p resources
The weak point of CRAIR1 lies in the huge space consumption that is the biggest compared with all other CRAIR levels. However, in the other part, the number of simultaneous faults that can be managed is the greatest, which is equal to p/2 for a subset of size p. In the case of a fault of a resource CRAIR5: Both CRAIR5 and CRAIR6 work in a similar way, with the exception that CRAIR5 uses one parity value, while CRAIR6 uses double parity value. Consequently, CRAIR6 allows to discover data in the case of two simultaneous faults, while CRAIR5 allows to discover data in the case of only one resource failure. CRAIR5 is used in the case of a VM of SERVICE type hosted on a secure machine which has low probability to get a failure, because CRAIR5 is characterized by its faster repair time compared to CRAIR6. Subsequently, the service can be quickly reestablished which ensures the continuity of the service. In CRAIR5, we assume that each subset contains at least three resources, following the original RAID level 5 recommendation. Assuming that a subset SSi contains the set of resources
Instead, Eq. (5) is used to recover data in the case of a resource failure. If
CRAIR6: CRAIR6 allows discovering the failed resources in the case of one or two simultaneous failures. This level of CRAIR is used by H_RAIC in the case of VM of type DATA hosted on a PM in medium state. Its functioning are based on the computation of a parity values. Two formula s are used to ensure the CRAIR6 functioning, the first one allows to compute the party values, while the second one is used to discover data in the case of one or two simultaneous faults, Unfortunately, CRAIR6 doesn’t allow data discovering if more than two faults appear simultaneously. In CRAIR6, we assume that each subset
In both Eqs (6) and (7), For the reconstruction phase, two cases are possible. The first one consists in a single resource fault, while the second one represents the case of two simultaneous faults. In the first case, the reconstruction is done with a simple XOR between all the resources that compose the corresponding subset excluding CRAIR 5HS and CRAIR 6HS: CRAIR 5HS and CRAIR 6HS are considered as particular cases of CRAIR5 and CRAIR6, respectively. In the case of CRAIRx with hot spare (HS) option, a hot spare resource in each subset is prepared, then in the case of a crash, the prepared resource is used and the reconstruction will be quick compared to CRAIRx without HS. The algorithm for creating parity values and recovering failed resources is the same as CRAIR5 and CRAIR6. The advantage of using CRAIR with HS lies in the reduction of the mean time of resource recovery, which increases the increase in the total number of allowed simultaneous faults. Its weak point Lies in the reservation of an useless additional space.
For the evaluation phase, H_RAIC and the different CRAIR levels defined in the presented work are compared between them. The JAVA, SHELL and R languages were used to develop our owner simulator designed to simulate the cloud architecture, and to make our experiments. Then, the different experiments have been done using our simulator on a personal computer equipped with an Intel Core i7 processor and 8 GB of RAM, using Ubuntu 18.04 as an operating system.
In our simulator, the used architecture consists in a cloud, which composed of three elements PCN, PM, VM. PCN represents the most powerful PM, which is dedicated to realize the reconstruction of the failed resource as described in Section 3. Meanwhile, PM represents the physical machines that host the set of VM (physical machines).
In Table 2, the notation of the different used variables and their corresponding signification is presented.
In the evaluation phase, we assume that we have two variables n and m, where, m represents the total number of used PM, and n represents the total number of the deployed VM on the different used PM. Meanwhile, n_m represents the cloud size, which indicates the cloud contains n VM shared between m PM.
In our evaluation, we consider that we have 12 different clouds; each one has its own size. The different used cloud sizes are n_m
For each value in n_m, we generate the corresponding number of PM and VM. Then, for each PM we generate randomly its owner characteristics which are: tPM, sPM, uPM, dPM, wPM, and rPM. Then, we generate n VM, and for each VM, randomly generate its owner characteristics which are: sVM, nVM, and pid_VM. Finally, we will get n VM randomly distributed on m PM, with which, each resource has its own characteristics, which allows us to get a cloud composed of heterogeneous resources.
Variables description
Variables description
The set of generated characteristic and the different values that can be taken by each character are described in Table 3.
Resource characteristics
After generating the cloud, it is possible to apply the H_RAIC process, then measure the different evaluation parameters.
In the evaluation phase, three parameters are considered: total used space, reconstruction time, and the maximum number of allowed simultaneous faults.
The used space depends on the used CRAIR level. The total used space is denoted TUS, where TUS
We assume that we have
Since H_RAIC uses multiple levels of CRAIR, BUS is computed as the sum of a partial BUS denoted
Using all defined PCN, VM, and VM characteristics already fixed in Table 3, it is possible to compute the necessary time to complete all operators. wPCN and sVM allow to compute the amount of time required to write the data on the PCN if necessary. Meanwhile Min_PM_NO, PM_Rf_NIS, and sVM allow to predict the time necessary to transfer the data used in the failed resource reconstruction. Finlay pCPN and sVM allow to predict the time consumed to complete all computations.
Equation (5.2) is a general formula used to compute the time needed to reconstruct the failed resource (Rf).
The reconstruction time is denoted RecT. In the formula, Min_PM_NOS represents the minimum network out speed between all PM that host a Rf which belongs to the subset of failed resources, and PM_Rf_NIS represents the pid_VM of the PM that hosts Rf.
The maximum allowed simultaneous faults that can be managed by H_RAIR depends on the used CRAIR level as shown in Eq. (11).
In the latter, MaxAlloweSF (CRAIR5) is equal to the number of the subset that use CRAIR5, because CRAIR5 allows to recover the failed resource in the case of only one resource fault. Meanwhile CRAIR6 allows to manage the case of two simultaneous faults. Consequently MaxAlloweSF (CRAIR6) equals twice the number of the subset that uses CRAIR6. For CRAIR1, the number of maximum allowed simultaneous faults that can be managed is equal to the sum of
The different results are presented in Figs 2–4. Figure 2 demonstrates the total consumed space by the totality of cloud resources for each used algorithm, while Figs 3 and 4 represent respectively. The reconstruction time and the maximum allowed simultaneous faults according to the resource nature.
All consumed space.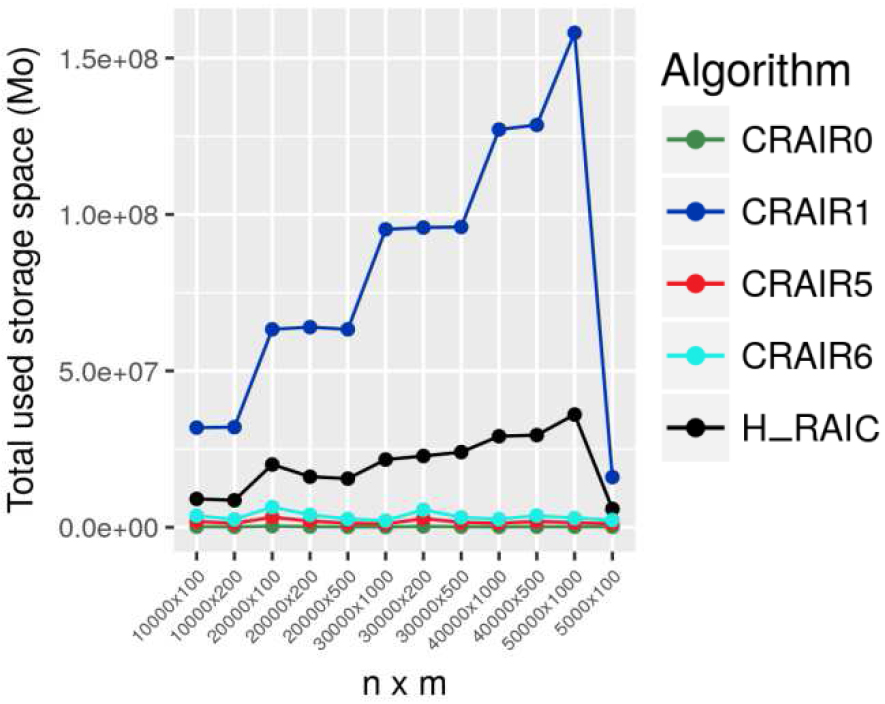
Reconstruction time.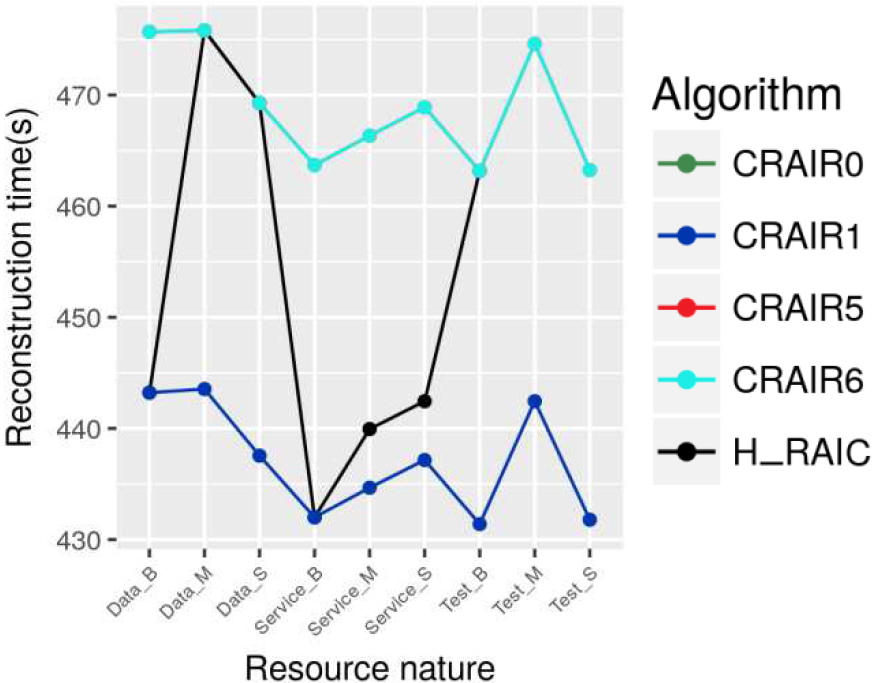
Maximum number of allowed simultaneous faults.
Simultaneous reading of Figs 2–4 allows interpreting the different obtained results, therefore, understanding the interest of H_RAIC in the realization of a trade-off between the total used space, reconstruction time, and the maximum allowed simultaneous faults.
In the case of a VM of type DTAT and a VM of type SERVICE hosted on a bad PM, the reconstruction time obtained using the H_RAIC algorithm is the best compared to all the other used levels. Also, the maximum allowed time for simultaneous faults is the largest as CRAIR level one. Those results are expected, since the probability to get a failure if high and thus the maximum allowed simultaneous fault must be as great as possible and the reconstruction time must be as fast as possible.
For the TEST VM hosted on a bad PM, the probability to get a failure is high, but the rate of use of this kind of VM by the users are usually low, and the data are not important if they are lost. For this reason we show that the results are satisfied, where we save a large space using CRAIR5 in our approach, when we allow to manage the fault because the high probability of fault, but with low value of 71 simultaneous resources fault, and with a high value of reconstruction time.
For the TEST VM hosted on a medium and secure PM, H_RAIC doesn’t manage the fault, which is expected given the nature of the VM and used PM. In this case, the space usage takes the same value as CRAIR0 which is considered as the optimal value compared to other CRAIR levels.
When the SERVICE and DATA VM are hosted on a secure PM, the probability to get a failure of each VM is very low, but given the nature of these VM, it remains important to previous a fault. H_RAIC ensures the fault management of a low number of simultaneous faults, with a higher reconstruction time compared to other levels, but with lower space usage. The reconstruction time obtained for the DATA VM hosted on medium PM is slightly higher than the one obtained for SERVICE VM hosted on a PM of the same nature, which can be explained by the fact that the time for the VM dedicated to service is important. Meanwhile, the use of CRAIR5 and CRAIR6 participates to save the total used space.
In this work, a new concept called CRAIR that contains several levels was defined. Then, H_RAIC approach was proposed. CRAIR is inspired by RAID technique widely used in large number of operating systems, H_RAIC can be as suitable method for a specific cloud, where the set of resources are heterogeneous.
H_RAIC is considered as a hybridization of the different levels of CRAIR. The hybridization is done with the aim to ensure a trade-off between the total used space, reconstruction time, and the maximum allowed simultaneous faults, subsequently allowing a trade-off between the user’s requirement, and the provider requirements.
In the first time, the resources are divided into sets of resources, each one containing the resources of the same nature, and then, in the second time, each set is divided into sub-sets of independent resources. Afterwards, the CRAIR level is applied on the elements of each sub-set and the choice of CRAIR level is made according to the users and provider requirements.
In this paper, the scalability aspect has not been taken into account. Therefore, an important perspective consists in making an evaluation of H_RAIC from the scalability point of view, which allows getting more knowledge about the proposed solution, and consequently to think about future improvements.
More extensions are possible: the proposed H_RAIC is oriented to a cloud environment, even though it can be adapted to any environment based on resource visualization, as well as other distributed systems, like Fog, Grid, IoT, etc.
Another perspective can be introduced, which consists to consider other parameters, like cost and consumed energy. Also, the comparison of our proposed solution with more similar works can be considered.
In the presented work, we have focused on VM, but it is also possible to use containers, which represent an excellent alternative to VM.
Footnotes
Author’s Bio