
Abstract
The appliances that are received at a cloud data centre are a compilation of jobs (task) that might be independent or dependent on one another. These tasks are then allocated to diverse virtual machine (VM) in a scheduled way. For this task allocation, various scheduling policies are deployed with the intention of reducing energy utilization and makespan, and increasing cloud resource exploitation as well. A variety of research and studies were done to attain an optimal solution in a single cloud setting, however the similar schemes might not operate on multi-cloud environments. Here, this paper aims to introduce a secured task scheduling model in multi-cloud environment. The developed approach mainly concerns on optimal allocation of tasks via a hybrid optimization theory. Consequently, the developed optimal task allotment considers the objectives like makespan, execution time, security parameters (risk evaluation), utilization cost, maximal service level agreement (SLA) adherence and power usage effectiveness (PUE). For resolving this issue, a novel hybrid algorithm termed as rock hyraxes updated shark smell with logistic mapping (RHU-SLM) is introduced in this work. At last, the superiority of developed approach is proved on varied measures.
Introduction
Scheduling tasks in cloud is turning out to be a demanding task nowadays, since it is essential to discover a superior task scheduling solution efficiently in multi-cloud surroundings [9, 10]. Multi-cloud entails service compositions as well as several optimal objectives. Generally, user tasks were submitted to data centres for obtaining specific services in a compensated approach, and CSPs have a tendency to charge their services depending upon on computing resource configuration by a SLA [11, 12, 13]. Currently, large-scale multifaceted appliances contain varied types of service elements that demand diverse amalgamations of reliability and security. In addition, on the cloud part, diverse levels of reliability and security are necessitated [14, 15, 1].
As the need of user’s tasks are varied, every task might have additional opportunities to discover a suitable cloud service in a multi-cloud system for avoiding poorer adaptableness among cloud services and tasks, extreme cost waste or compute time, and information leak owing to inadequate service security. Therefore, a multi-cloud system is vital to guarantee the requirements of users [16, 17]. A lower level of cloud source reliability might lead to service failure or interruption and also brings needless losses to users. In a multi-cloud surrounding, a CSP is selected based upon diverse requirements of user’s tasks; therefore, if services fails at a CSP, the services at another providers will maintain related tasks [18].
Moreover, the users could also evade service intermission risks. As a result, it is essential for users to choose service policies depending upon their individual requirements and utilize them to several CSPs [19, 20, 1]. Nevertheless, it is not easy to select a realistic resource scheduling policy for users in diverse multi-cloud surroundings [21, 22], as incomplete cloud resources include diverse functions and capacities. It needs a scheduling method that not only satisfies efficiency to finish task requests, however it needs a scheme to increases the exploitation of VMs with various QoS [23, 24, 1].
The major objective of this research work is
In this research, the 6-tuple multi-objective parameters that include makespan, execution time, utilization cost, and risk probability, maximal SLA adherence and PUEfor scheduling the tasks is defined. For solving this optimization issue, a new hybrid model referred to as RHU-SLM is introduced.
The rest of the paper is organized as: Section 2 reviews this topic. Section 3 narrates an overview on proposed secure task scheduling approach. In addition, Section 4 provides description on considered 6-tuple objectives. Section 5 describes the introduction of novel RHU-SLM algorithm for optimal task scheduling. Sections 6 and 7 discuss the acquired results and conclusion, respectively.
Optimization based methods
In 2021, Qing et al. [1] proposed a new scheduling technique known as MMA for optimizing the total cost and makespan for every tasks subjected to reliability and security constraints. The technique was separated into 2 stages for scheduling tasks. The initial stage was to discover the finest matching candidate sources, so that the tasks would meet up its favoured demands together with reliability, security, and performance in a multi-cloud surrounding. The subsequent one performed numerous rounds of re-allocation for optimizing cost and execution time of tasks iteratively by reducing the variances of approximated completing time.
In 2019, Karnam et al. [3] have proposed an optimization scheme termed as MFGMTS in cloud computing surroundings. The objectives, resource utilization, energy consumption, communication cost and time, execution cost and execution time were evaluated by means of penalty cost function and epsilon-constraint. The regarded constraint minimized the fitness function for providing finest job scheduling.
In 2018, Jena et al. [4] proposed GA-CCRATS for scheduling in multi-cloud computing. The scheme was principally separated into 2 stages, such as shorter task scheduling and GA-oriented resource allotment. The intention was to map the jobs to VMs for minimizing makespan time and to maximize consumer contentment. Finally, thorough experimentations were performed and the simulated outcomes proved the enhancement of developed scheme.
In 2019, Pang et al. [7] developed an EDA-GA oriented approach for scheduling tasks. At first, the sampling and probability schemes of EDA were deployed for producing specified feasible solutions. As the last step, the most favourable scheduling scheme for allotting tasks to VM’s was discovered. This model has benefited stronger searching ability and more rapid convergence speed. The tentative resultants illustrated that the offered method has efficiently enhanced the load balancing ability and minimized the execution time.
Deep learning based method
In 2020, Ismayilov and Haluk [8] analysed a prediction-oriented scheme called “NN-DNSGA-II algorithm” that included NSGA-II with ANN scheme. Further, 5 leading non-prediction oriented dynamic schemes were deployed for resolving the issue in workflow scheduling. The offered work focused on 6 objectives such as, improvement of utilization and consistency diminution of energy, makespan and cost.
Other popular methods
In 2019, Thirumalaiselvan and Venkatachalam [2] developed 3 diverse scheduling schemes like RBS algorithm, high priority scheduling algorithm and ELB algorithm for scheduling tasks in multi-cloud. These diverse schemes were deployed depending upon the task count and VM count in multi-cloud surroundings. If the task count was equivalent to VM count, ELB scheme was deployed. If the task count was superior to VM count, higher prioritization scheduling scheme was deployed. If the task count were smaller than VM count, RBS scheme was deployed. By exploiting these 3 diverse scheduling schemes, the efficiency and makespan of multi-cloud computing was improved.
In 2019, Panda et al. [5] developed multi-cloud network, in which several clouds were mutually integrated for offering joint services in a communal way. In addition, task scheduling was very demanding in multi-cloud than single cloud. Accordingly, the adopted scheme developed 3 “allocation-aware task scheduling algorithms” and the developed model also included “Min-Min and Max-Min algorithm”. At last, the adopted model was computed regarding cloud consumption, throughput, and makespan over the conventional schemes.
In 2020, Lavanya et al. [6] deployed 2 allotment schemes known as TBTS and SLA-LB models. The tasks were scheduled in batches via TBTS and it aided the scheduling of tasks in VM with various configurations. SLA-LB scheduled the tasks on the basis of user necessity, like deadline and resources. Experimental outcomes exposed that the performances of the introduced scheme outperformed the extant schemes concerning makespan, gain cost, penalty and utilization factor.
Research gaps
Table 1 shows reviews on task scheduling in multi-cloud environment. Some limitations of the related works are, increased makespan [2], complexity [4], absence of energy utilization [6], and requirement of multi-objective algorithms [3]. Furthermore, the existing works need an enhanced model for effective task scheduling with good security. Thus, a secured task scheduling approach based on RHU-SLM is introduced. Comparing with the related works, we introduce 6-fold objectives such as makespan, execution time, utilization cost, and risk probability, maximal SLA adherence and PUE.
Review on conventional task scheduling in multi-cloud environment models
Review on conventional task scheduling in multi-cloud environment models
Among the elements of cloud model, the subsequent connections take place: “(a) CU-cloud manager, (b) cloud manager-CSP, (c) CSP-CSP, (d) CSP-cloud manager, and (e) cloud manager-CU”. In addition, the overhead usually take place at the individual part. Moreover, it is believed that the flexibility of cloud makes these overhead insignificant.
Architecture of developed task scheduling model in multi-cloud.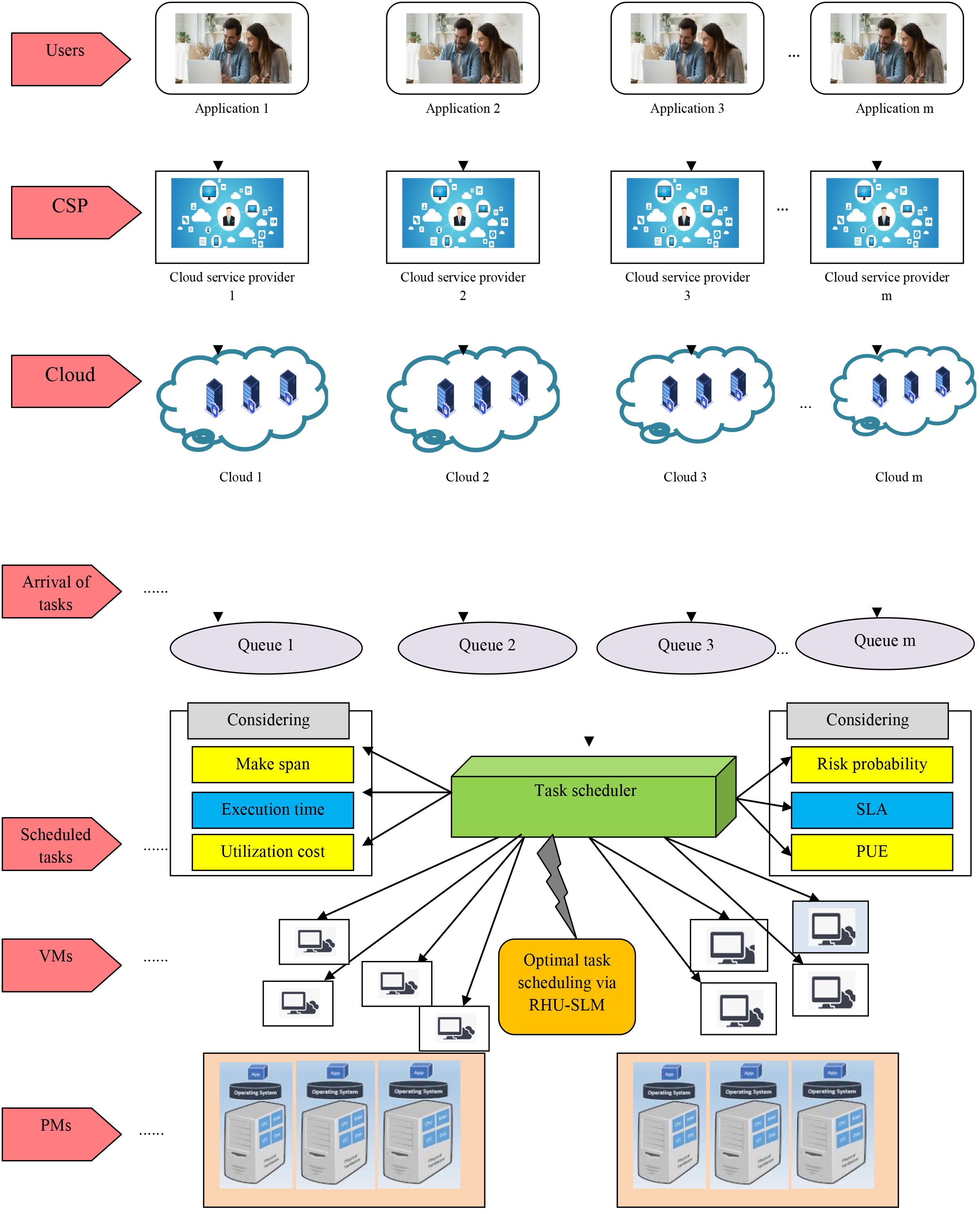
Whenever a job comes to a cloud manager, it allots the tasks in a waiting queue, and then discovers an active VM to hand over the task depending upon the defined 6-tuple objectives. The defined 6-tuple objectives here are execution time, makespan, utilization cost, risk probability, maximal SLA adherence and PUE. The developed scheme concerns on allocating the tasks optimally via an optimization concept. The tasks are simultaneously allotted in the VMs and the scheduling occurs in parallel. In this work, a new hybrid scheme known as RHU-SLM is developed for optimal scheduling. In addition, the deliberation of risk probability is the most important role as the constraint guarantees the security requirements when scheduling the tasks. Depending upon the risk probability (together with another metrics), the VM allotment is done for every task. A multi-cloud task scheduling model is considered in this work as depicted in Fig. 1.
The major elements of multi-cloud task scheduling model are CU, Cloud Manager and CSP:
Cloud Manager: It is a central unit, which deals with the service requests of customers and receives the position of VMs cloud providers. CU: With the aid of cloud manager, the CU can create their requests and is said to be the cloud’s service client. CSP: It is a cloud distributor, and by employing VMs on the physical server, they offer on-demand services. For managing the peak demands, every cloud includes management server to interact with another manager servers to pass consumer requests. Demands of customers are often extended over numerous clouds, and their requests were handled via a distributed manner.
Moreover, the flowchart for the overall working process of this research is shown in Fig. 2.
Flowchart of the overall working process.
Cloud system model
This work considers a group of clouds
where
The mapping is performed for scheduling, matching, and allocating tasks. The mapping function
Reduced makespan Minimal cloud utilization cost of tasks Reduced execution time of VM Reduced security risk probability SLA Adherence, SLA Power efficiency, PUE
The description on defined 6-tuple objectives is portrayed in the forthcoming section.
The overall intention of this work is delineated in Eq. (3),
where the weights
A series of tasks arrives in queues and gets implemented in a VM. The period exhausted by VM for processing a task is its implementation time. The executing time of the tasks have a tendency to vary based on its appliance. When a task is executed in a negligible amount of time, the missing deadline issues are resolved. The arithmetical formulation for
where pr, Me indicates the processor and memory of VM, correspondingly and Ma is set as 1.
Execution time for every tasks
where
The arithmetical formulation for every task
where
where
Makespan is the collective time taken by the resources to finish the execution of every task. Generally, usage of VM is characterized by how the resources in the cloud are utilized [25]. The makespan is inversely proposal to the rate of utilization. A proficient scheduling scheme should schedule the tasks such that the least makespan and highest VM utilization are attained. The numerical formulation for makespan is specified in Eq. (8),
where
For a specified task, the scheduling risk probabilities of tasks
where
The risk probabilities of tasks are the entire risk probability of the task related to the security service. For
Moreover, the risk probability of workflow is the mean probability of every task. The collected task’s average probability is attacked at the time of workflow as in Eq. (11).
“A SLA refers to the official commitment that entitles the service provider to maintain a definite level of quality, availability and responsibility; while providing the intended services.” SLA denoted by
where
where
It is modeled as in Eq. (14) and it is a significant measure deployed for quantifying the power efficiency of data centers. It is represented as the entire energy consumption of a DC for supporting its computing equipment’s
The VM along with tasks are given as input to RHU-SLM for optimal scheduling by taking account of above-said objectives. As 3 PM with 30 sets of VM in each PM is deployed in our work, the input solution is represented as in Fig. 3. In Fig. 3a–c manifests the solution encoding of Cloud 1, 2 and 3.
Solution encoding of (a) Cloud 1, (b) Cloud 2 and (c) Cloud 3.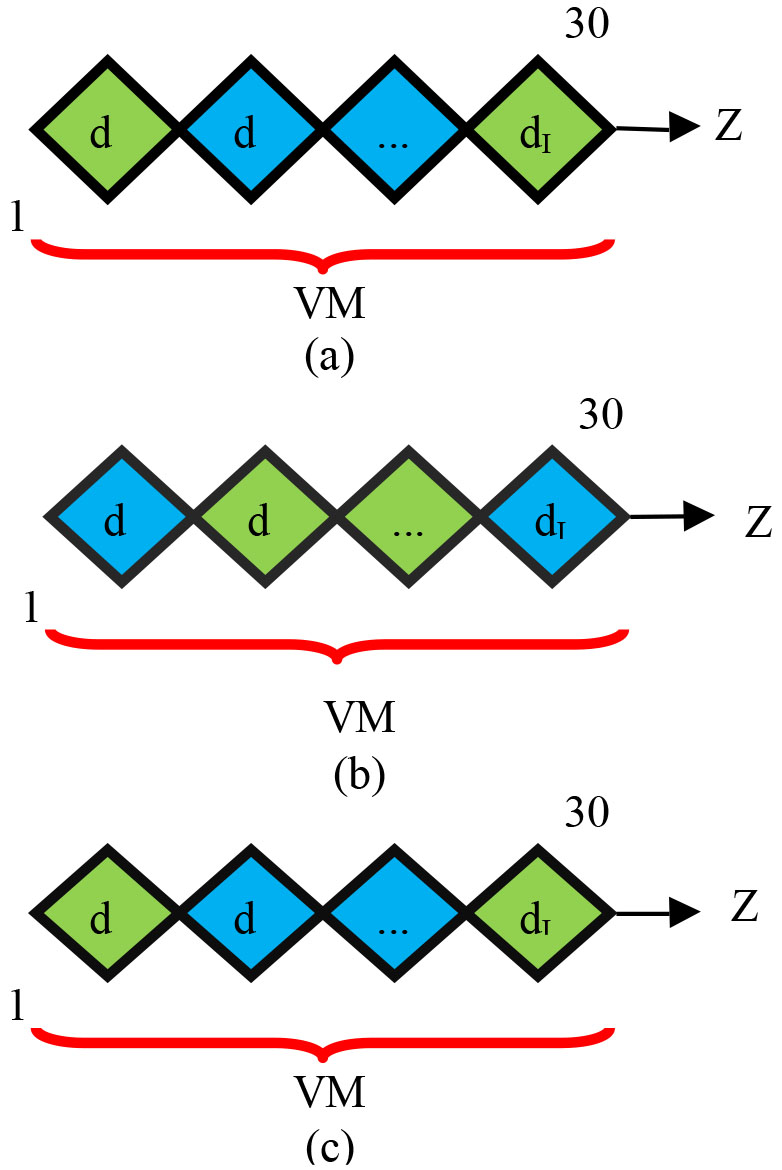
Though the conventional SSO [30] model encompasses a variety of enhancements; it suffers from specific limitations like, local convergence etc. To overcome the disadvantages of traditional SSO, the theory of RHSO [31] is included with it to form a new scheme termed as RHU-SLM. Hybridized optimization schemes are said to be capable for specific search issues [26, 27, 28, 29]. The steps followed in the proposed RHU-SLM are as follows.
RHU-SLM includes 4 fundamental phases namely, “initialization, forward movement, rotational movement, and position update”.
For modelling RHU-SLM, the initial solution population have to be produced arbitrarily within the searching space. Every solution symbolizes a particle of odour that shows a feasible shark position at the starting of searching procedure. The initial solution vector is exposed in Eqs (15) and (16),
where
The associated optimization issue is modelled as in Eq. (16),
where
While blood has been mixed in water, the Shark in each position approaches stronger odour particles with a “velocity
Thus, the velocity in every dimension is computed as in Eq. (18), where
where
The raise in
where
Owing to shark’s forward movement, its novel position is
where
The shark includes rotational movement for finding the strong odour particle. This procedure is termed as local search as shown in Eq. (23),
where
The searching path of shark continues with rotational movement since it moves nearer to strong odour particle. Conventionally, the update occurs based upon shark position, however, as per developed concept, the update occurs based upon proposed RHSO model as shown in Eq. (24),
where circ symbolize circular motion.
The procedure will be continued till
The pseudocode of RHU-SLM approach is given by Algorithm 1.
Simulation environment
The developed multi-cloud task scheduling model was simulated in Python and the simulation was set up with 3 sets of PM and 3 clouds. Every set of PM includes 30 counts of VMs and the data center value is 2. The entire task count to be attained is altered as 100, 150, 175, and 200, correspondingly. Further, the performances of RHU-SLM for optimal scheduling is validated over other models such as TSMGWO [32], WOA [34], RHSO [31], SSO [30], SSA [35], MFO [36], DHOA [37] and RF [33], The analysis was done regarding energy consumption, risk probability, makespan, PUE, resource utilization, execution time, and computation time as well. Here, the assessment was done with varying count of VMs. The evaluation was done using 2 datasets namely, GoCJ dataset and HSCP dataset.
GoCJ dataset: Hussain and Aleem have developed a realistic cloud workload dataset using Google Cluster traces known as the GoCJ dataset. The GoCJ dataset is provided for evaluation purposes in the form of different text files in the Mendeley data repository. Data is arranged in the form of rows consisting of numeric values. The numeric value indicates the size of the cloud job in terms of million instructions (MI). This dataset is composed of five types of jobs with different proportions. Each text le of the GoCJ dataset contains a different number of jobs of different sized cloud workloads.
HCSP dataset: The Heterogeneous Computing Scheduling Problem (HCSP) dataset is developed based on expected computation time consisting of a fixed number of virtual machines and number of tasks by considering four factors: distribution of workload, consistency, heterogeneity of task, and heterogeneity of the resources”.
Convergence analysis
Figure 4 describes the convergence (cost) analysis of adopted RHU-SLM scheme over traditional schemes such as TSMGWO, WOA, RHSO, SSOA, SSA, MFO and DHOA for varied iterations. Here, analysis is done by varying the iterations from 0, 20, 40, 60, 80 and 100 for GoCJ and HSCP datasets. In fact, as per the portrayed 6-tuple objectives, it is essential to attain a least cost function for better performance of the system. This criterion has been well established by the developed RHU-SLM model. On observing the analysis outcomes, the proposed RHU-SLM model has attained minimal cost values for all iterations when compared over the existing schemes. Initially, from iteration 0 to iteration 80, the cost values is found to be higher for proposed as well as compared schemes, however, as the iteration count increases, better (minimal cost) outputs are attained. That is, from iteration 90 to 100, the cost values goes on reducing for both the proposed and compared models, however, the adopted RHU-SLM method exhibits slightest values when evaluated over the existing ones. Predominantly, the presented approach has accomplished a least cost value (almost 0.243) for HSCP dataset with the incorporation of developed optimization concept. Thus, the overall evaluation shows the enhancement of presented model.
Convergence analysis of the proposed and existing approaches for (a) GoCJ dataset and (b) HSCP dataset.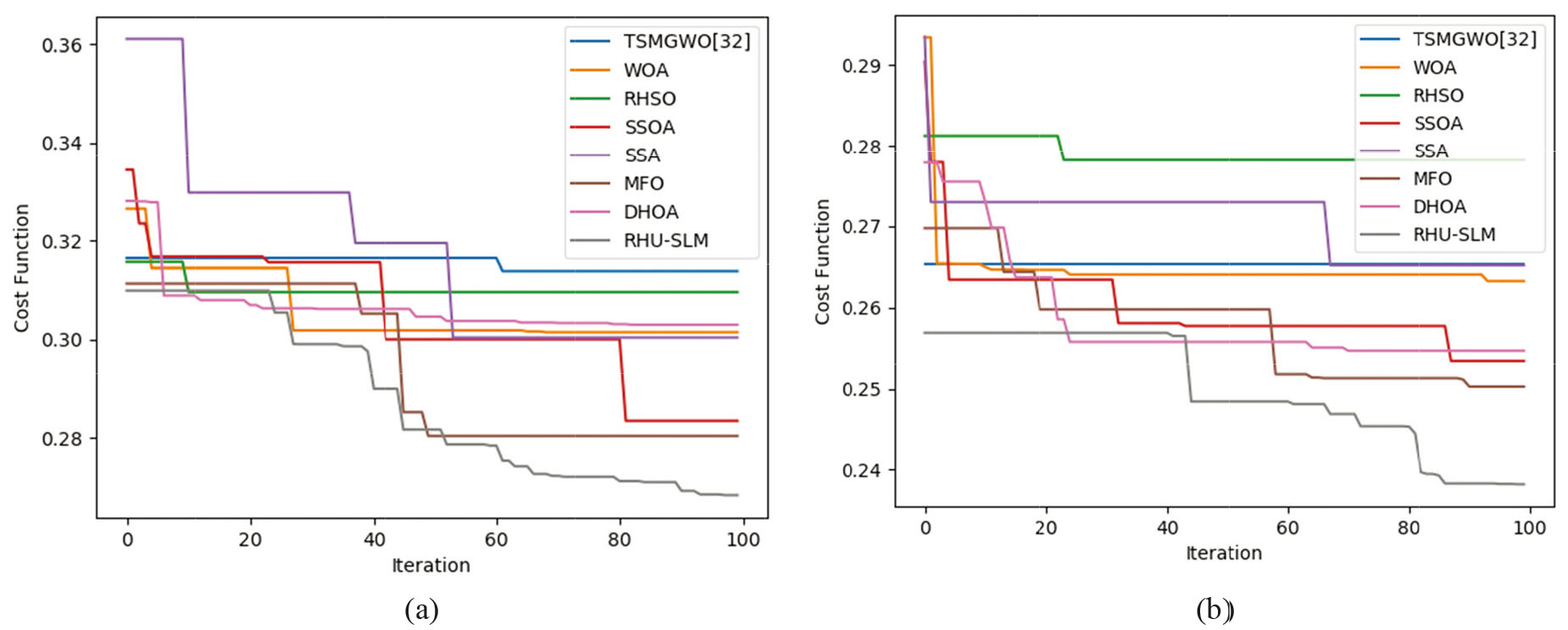
Analysis on power usage effectiveness (PUE) of the proposed and existing approaches for (a) GoCJ dataset and (b) HSCP dataset.
Power usage should be minimal while scheduling the tasks in VMs. Here, this evaluation is performed for varying count of tasks from 100, 150, 175 up to 200 and the resultants are shown for 2 datasets such as GoCJ and HSCP datasets as in Fig. 5a and b, respectively. As per the attained resultants in Fig. 5a, the RHU-SLM is found to exploit minimal power of 2.7 using GoCJ dataset when the task count is 175. At certain count of tasks, the compared schemes like TSMGWO, WOA, RHSO, SSOA, SSA and MFO have accomplished minimal PUE than developed model; however, on considering other criteria, the developed approach has accomplished more optimal outcomes than the compared ones. Thus, the effectiveness of adopted method regarding energy utilization is confirmed.
Analysis on execution time
The execution time gets differed on the basis of defined application. Nevertheless, the VMs should implement the tasks with negligible execution time and improve the reliability of PM. The execution time acquired by the proposed and extant models for both GoCJ and HSCP datasets are exposed in Fig. 6a and b, respectively. The task evaluation is done for varied count of tasks from 100, 150, 175 and 200. On noticing the outcomes, the results accomplished using HSCP dataset is found to be better than the outcomes attained using GoCJ dataset. Figure 6a, the executing time goes on rising with increase in the count of tasks, however, the adopted approach seems to attain minimal executing time than the compared extant approaches. A minimal execution time of 0.120 is achieved for task count of 175 using HSCP dataset. At certain task counts, the extant schemes have accomplished least executing time than RHU-SLM, however, the overall performance of developed model seems to be good, which shows the enhancement of the proposed model for task scheduling.
Analysis on execution time of the proposed and existing approaches for (a) GoCJ dataset and (b) HSCP dataset.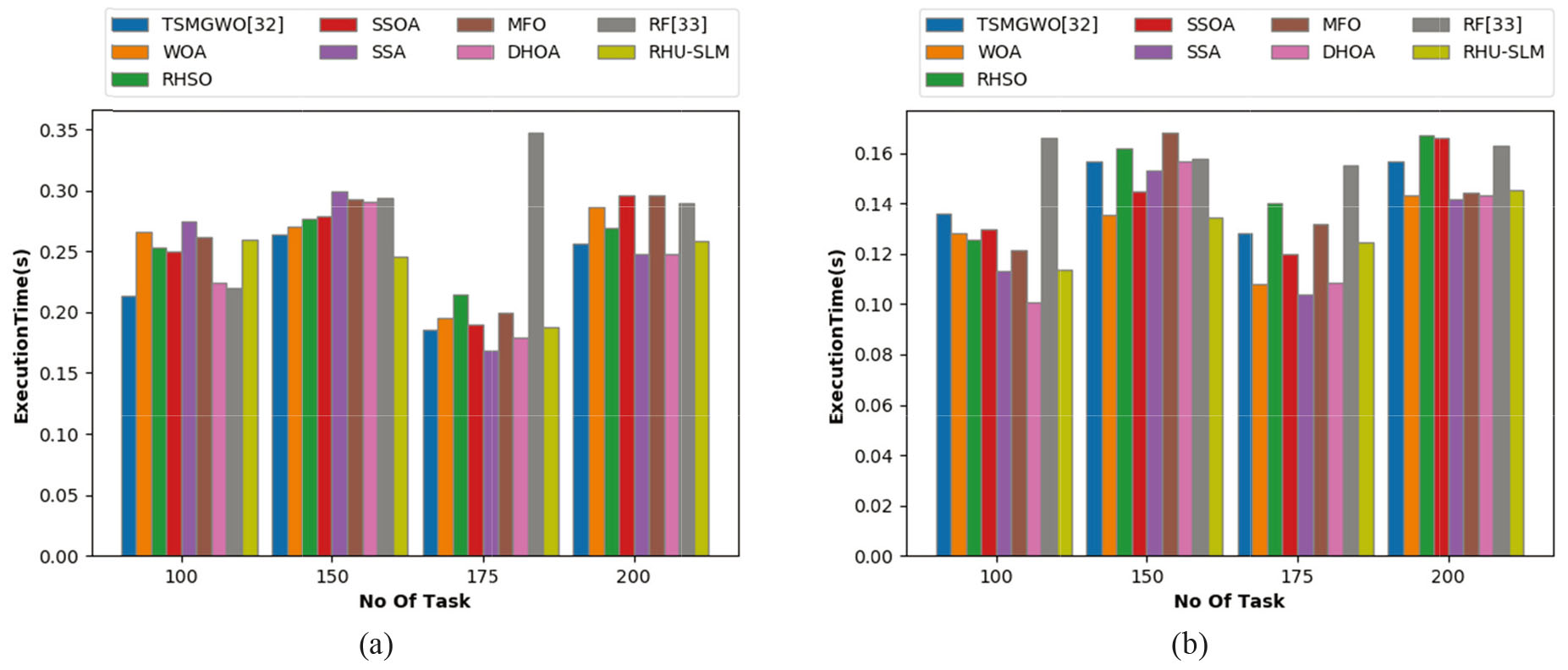
Figure 7a and b shows the analysis on SLA by varying count of tasks from 100, 150, 175 to 200. The results are acquired using GoCJ and HSCP datasets for proposed and conventional models. The SLA should be higher as defined in the objective function in Eq. (3). On observing the graph, it could be scrutinized that the developed scheme obtained high SLA of 0.0036 when the number of tasks is 100 for GoCJ dataset. Likewise, for HSCP dataset, a high SLA is accomplished when the count of tasks is 150 and 175. At certain task counts, the compared schemes have attained higher SLA than that of suggested RHU-SLM model. Nevertheless, the developed model has revealed optimal outcomes for other performances and therefore, this variation can be considered negligible.
Analysis on service level agreement (SLA) the proposed and existing approaches for (a) GoCJ dataset and (b) HSCP dataset.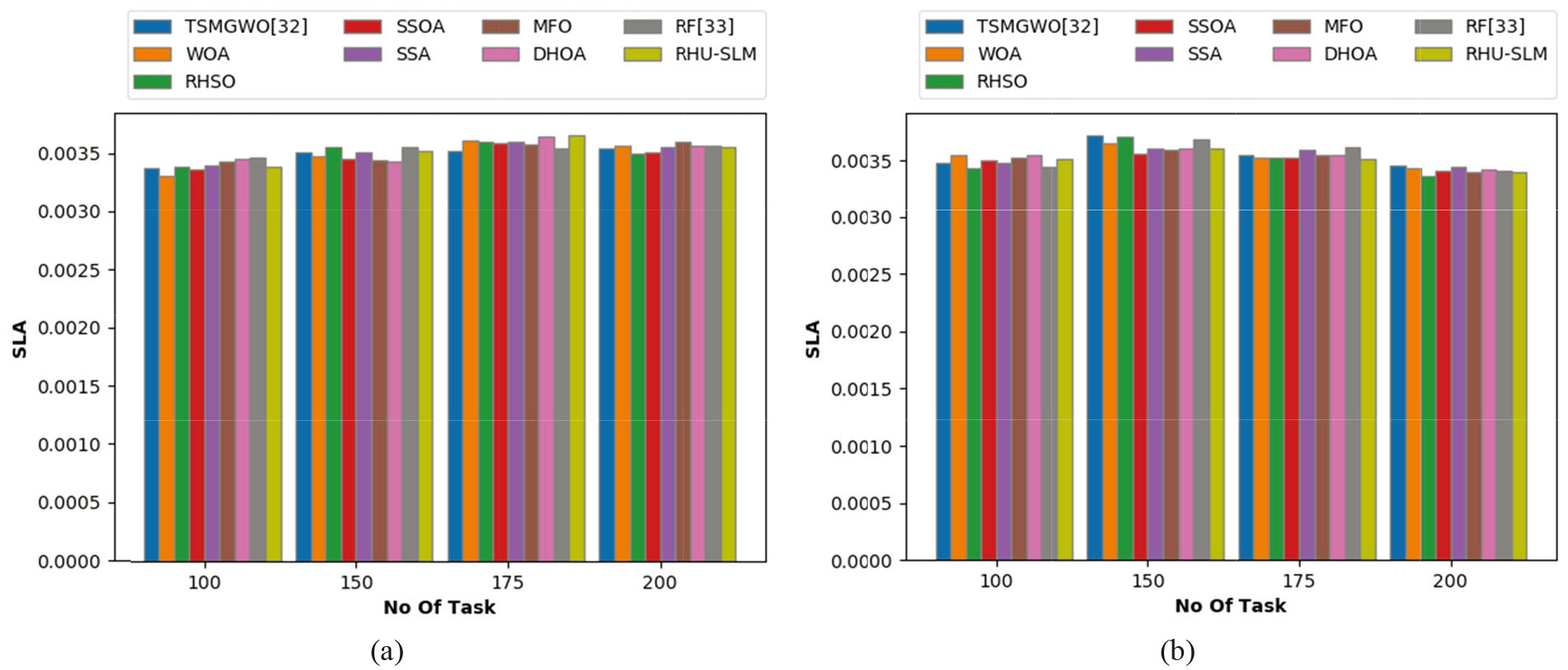
Analysis on makespan of the poposed and existing approaches for (a) GoCJ dataset and (b) HSCP dataset.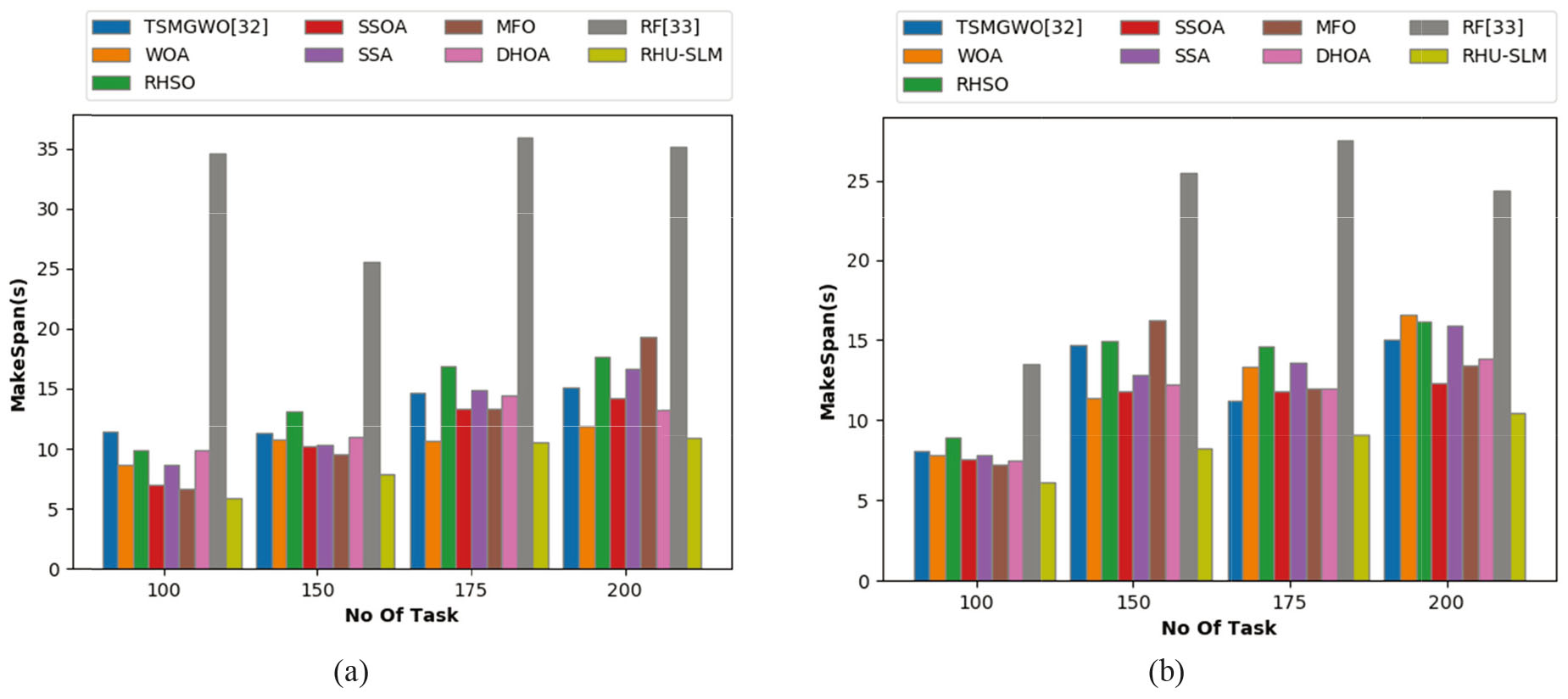
Figure 8a and b shows the makespan of tasks accomplished using GoCJ and HSCP datasets by the proposed and conventional models. The evaluation is done for varying count of tasks from 100, 150, 175 up to 200. On observing the graph, it could be noted that, as the number of tasks goes on increasing, the makespan also gets increased. Thus, a minimal makespan is acquired by developed RHU-SLM model and existing models when the count of tasks is 100. Specifically, a least makespan of 6 is achieved by adopted scheme using HSCP dataset, which is much minimal than the other makespan values attained by proposed scheme. On the other hand, the adopted scheme had achieved a comparatively higher makespan of 12.5 while scheduling 200 counts of tasks. That is, the makespan of adopted model for scheduling 100 counts of tasks is 99.5% better than the makespan of adopted model for scheduling 200 counts of tasks.
Analysis on resource utilization
Generally, lesser resource utilization is obligatory to schedule and execute the tasks. The resource utilization of proposed and the existing algorithms are shown in Fig. 9a and b for GoCJ and HSCP datasets. On observing the graph, the RHU-SLM had utilized the minimal resources whilst scheduling and executing 150 counts of tasks. Comparatively, the resource utilization values attained using HSCP dataset is found to be better than the resource utilization values attained using GoCJ dataset. A much higher resource utilization value of 12500 is attained when the task count is 200. Thus, the assessment established the betterment of proposed work for task scheduling with minimum resource utilization.
Analysis on resource utilization of the poposedand existing approaches for (a) GoCJ dataset and (b) HSCP dataset.
Energy managing is fetching more attention in cloud storage owing to the augmented usage of cloud computing resources with increasing energy costs. Thereby, it becomes necessary to minimize the energy utilization for executing a task that leads to the extension of network life span. Here, this assessment is undergone for varying count of tasks from 100, 150, 175 up to 200. The resultants are accomplished for 2 datasets such as GoCJ and HSCP dataset that are shown in Fig. 10a and b, respectively. As per the attained resultants in Fig. 10a, the RHU-SLM is found to utilize the smallest amount of energy while running the tasks. Particularly, for GoCJ dataset, when the task count is 150, more optimal outcome has been accomplished by the developed approach than the compared ones. In addition it can be noted that the resultants acquired using HSCP dataset is much effectual than the resultants acquired using GoCJ dataset. On observing Fig. 10b, the adopted scheme has achieved minimal values for energy utilization when the count of tasks is 100, 150 and 175. Thus, the efficacy of adopted scheme regarding energy utilization is proved.
Particularly, for GoCJ dataset, when the task count is 150, more optimal outcome has been accomplished by the developed approach than the compared ones. In addition it can be noted that the resultants acquired using HSCP dataset is much effectual than the resultants acquired using GoCJ dataset. On observing Fig. 10b, the adopted scheme has achieved minimal values for energy utilization when the count of tasks is 100, 150 and 175. Thus, the efficacy of adopted scheme regarding energy utilization is proved.
Analysis on risk probability of the proposed and existing techniques for GoCJ dataset
Analysis on risk probability of the proposed and existing techniques for GoCJ dataset
Analysis on energy consumption of the poposed and existing approaches for (a) GoCJ dataset and (b) HSCP dataset.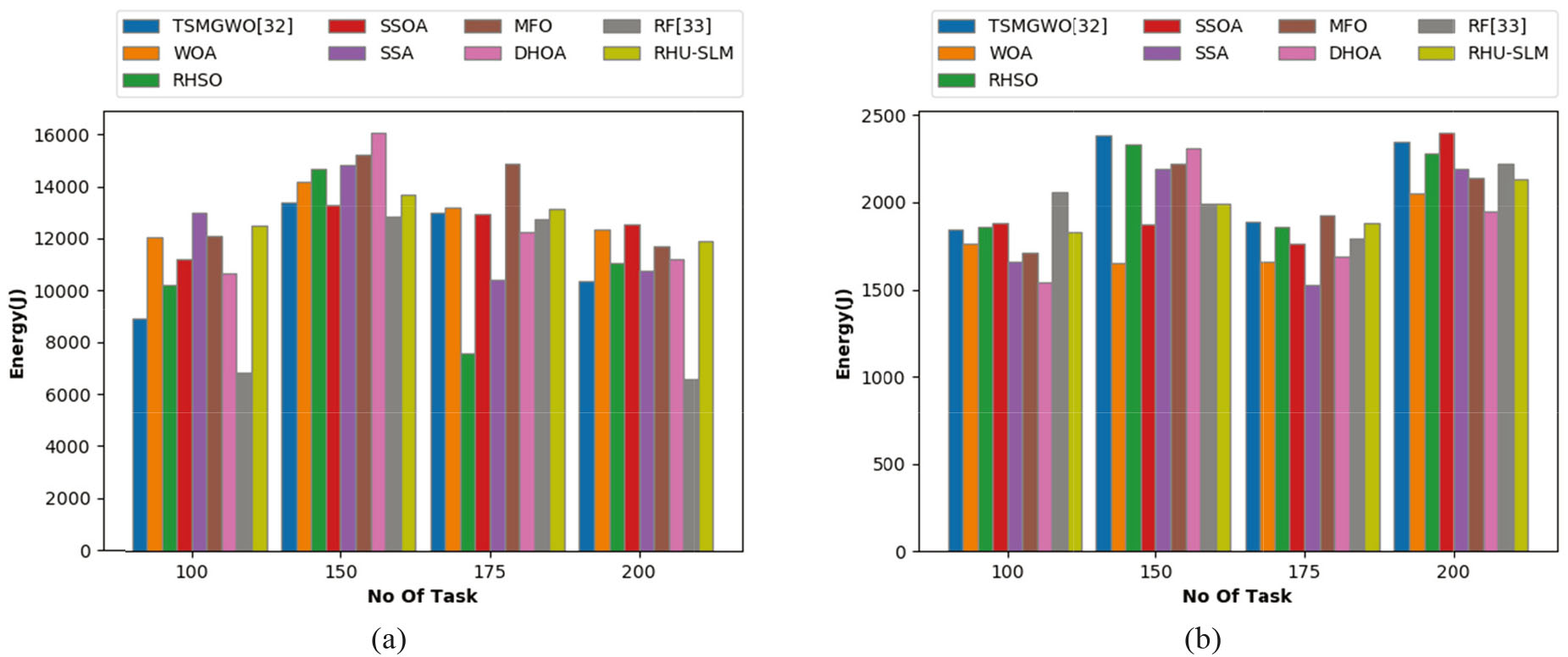
The performance on security regarding risk probability for RHU-SLM over extant schemes is represented in Table 2. From the resultants, it is shown that the RHU-SLM guarantees higher security by incurring lesser risk. On the other hand, the compared schemes like TSMGWO, WOA, RHSO, SSOA, SSA, MFO, DHOA and RF models represent higher risk values that demonstrate the unsecured scenario. The security analysis for proposed and conventional models for both GoCJ and HSCP datasets is tabulated in Tables 2 and 3, correspondingly. In Table 2, the risk probability acquired by the RHU-SLM while scheduling 100 tasks is 20.76, which is the least value when compared to other schemes like TSMGWO, WOA, RHSO, SSOA, SSA, MFO, DHOA and RF. On scrutinizing all other count of tasks, the risk probability of the proposed model seems to be lesser than extant ones. Altogether, the analysis establishes the enhanced security of the proposed algorithm.
Analysis on risk probability of the proposed and existing techniques for HSCP dataset
Analysis on risk probability of the proposed and existing techniques for HSCP dataset
The time deployed by the traditional and adopted methods for optimal task scheduling is portrayed in Tables 4 and 5 for both GoCJ and HSCP datasets. From Table 4, it is known that the time taken by proposed RHU-SLM model at task 100 is 20.74% superior to the time taken by proposed model at task 200. Moreover, it is observed that, as the count of tasks increases from 100 to 200, the time taken also increases for scheduling the tasks.
Analysis on computation time (s) of the proposed and existing techniques for GoCJ dataset
Analysis on computation time (s) of the proposed and existing techniques for GoCJ dataset
Analysis on computation time (s) of the proposed and existing techniques for HSCP dataset
Degree of Imbalance is evaluated for computing the imbalance of jobs among VMs. Therefore, the degree of imbalance should be negligible for ensuring the balanced workload distribution. Here, this assessment is undergone for varying count of tasks from 100, 150, 175 up to 200 and the resultants are accomplished for 2 datasets such as GoCJ and HSCP dataset that are shown in Tables 6 and 7, correspondingly. On analysing the obtained resultants in Table 6, the RHU-SLM is found to attain minimal degree of imbalance than extant schemes. However, at certain cases, the extant scheme poses minimal degree of imbalance than proposed model. Since, the objectives defined in Eq. (3) are attained in an optimal way, this variation can be neglected. Thus, the efficiency of adopted scheme concerning degree of imbalance is proven.
Analysis on degree of imbalance for the proposed and existing techniques for GoCJ dataset
Analysis on degree of imbalance for the proposed and existing techniques for GoCJ dataset
Analysis on degree of imbalance for RHU-SLM and existing techniques for HSCP dataset
The results sections clearly show the effectiveness of the proposed RHU-SLM model. The defined 6-fold objectives play a major role in effective task scheduling. Comparing to the existing method [2], the proposed model produces reduced makespan. The implemented RHU-SLM model is easy when compared to the method in [4]. Furthermore, this research work overcomes the limitation of the works in [6, 3] and also it is a powerful method for task scheduling.
Conclusion
In this paper, a secured task scheduling approach was proposed in multi-cloud environment. The presented work focused on optimal allotment of tasks by integrating the optimization theory. Consequently, the adopted optimal task allocation model considers the objectives such as makespan, execution time, and utilization cost, security along with SLA and PUE parameters. For optimal scheduling, this work deploys a new model that hybridizes the concepts of SSO and RHSO. At last, the superiority of offered scheme was established over the conventional schemes regarding diverse measures. On noticing the outcomes, the results accomplished using HSCP dataset was found to be better than the outcomes attained using GoCJ dataset. The executing time goes on rising with increase in the count of tasks; however, the adopted approach seems to attain minimal executing time than the compared extant approaches. Specifically, a minimal execution time of 0.120 was achieved for task count of 175 using HSCP dataset. In future, the work can be extended to analyse on real cloud environment.
Footnotes
Abbreviations
Author’s Bios