
Abstract
Cloud computing epitomizes an important invention in the field of Information Technology, which presents users with a way of providing on-demand access to a pool of shared computing resources. A major challenge faced by the cloud system is to assign the exact quantity of resources to the users based on the demand, while meeting the Service Level Agreement (SLA). Elasticity is a major aspect that provides the cloud with the capability of adding and removing resources “on the fly” for handling load variations. However, elastic scaling requires suspension of the application tasks forcibly, while performing resource distribution; thereby Quality of Service (QoS) gets affected. In this research, an elastic scaling approach based on optimization is developed which aims at attaining an improved user experience. Here, load prediction is performed based on various factors, like bandwidth, CPU, and memory. Later, horizontal as well as vertical scaling is performed based on the predicted load using the devised leader Harris honey badger algorithm. The devised optimization enabled elastic scaling is evaluated for its effectiveness based on metrics, such as predicted load error, cost, and resource utilization, and is found to have attained values of 0.0193, 153.581, and 0.3217.
Keywords
Introduction
Cloud computing is an evolving computing model that is gaining popularity nowadays. It is a paradigm, which facilitates sharing of computing devices, and resources based on the user demand. Cloud computing provides a way to provide shared resources, such as storage applications, networks, data centres, and servers with less effort. Additionally, cloud computing enables users, as well as organizations for keeping their data in third-party or private data centres/storage locations, which may be present anywhere in the world [9]. The definition of cloud computing as given by the National Institute of Standards and Technology (NIST) is, “A model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction” [10]. The resources on the cloud are provided to the users on a pay-per-use basis. However, allocating these resources correctly along with the satisfaction of user requirements require effective allocation schemes. With the ever-increasing requirements, the process of assigning resources to users has become tedious and challenging [11]. Users can access the information available in the cloud storage over the internet, wherein the resources from various locations can be considered as a centralized resource over the network. If the user requirements are very high, the network will be provided by cloud computing [12]. Cloud computing has the following important aspects, such as Measured service, rapid elasticity, resource pooling, broad network access, and on-demand self-service. Here, the pool of resources is allocated to the users based on the user demand, which requires scaling in and out of the resources. Moreover, the resources must be constantly monitored, to provide transparency of service [13].
The performance of any cloud-oriented system depends upon three aspects, namely efficiency, elasticity, and scalability. The efficiency of the system depends on how accurately the resources are matched according to the user requirements, whereas the scalability of the system depends on the capability of the cloud to enhance the resources available by expanding them to meet the user requirements. Elasticity refers to the ability of the cloud to automatically adapt itself in accordance with the varying demand [14]. The efficiency of the cloud depends on the effective utilization of the resources, wherein resource management is established by using effective resource scalability, allocation, and scheduling methods. The resources are made available as Virtual Machines (VMs) (to the users through the process of virtualization, which enables the utilization of a single PM as multiple virtual resources [15]. The process of delivering the services to the user is highly complex and is carried out by the Cloud Service Provider [16]. In the cloud, the cost of hosting services can be effectively reduced by using elasticity, which can be achieved by using virtualization, which guarantees isolation of operations for various users [17]. Cloud-based systems can adapt to the varying workload through the process of scaling, which denotes the ability of the system to scale according to the load received. Characterization of the load is done by considering the complexity as well as the count of the queries and the speed at which the tasks are received [18].
Elastic scaling is the process of matching the resources available to the demand automatically by the cloud data center. It is done with the target of ensuring that the services are made available to the users adaptively, and constantly devoid of any resource wastage [19]. Moreover, it enables us to meet the Service Level Agreement (SLA) along with efficient resource utilization, thereby reducing the cost of hardware and software is required [20]. Further, dynamic scaling in and out of the system can be achieved, thereby avoiding idle resources and unanticipated spikes in load [21]. For achieving elastic scaling, the load associated with the computing resources has to be predicted [22]. In the cloud, elastic scaling is ensured by using two mechanisms, namely vertical, as well as horizontal scaling. Vertical scaling performs dynamic modification of the physical resources in a VM, thus modifying the resource interfaces through programming languages. It doesn’t require restarting the system, as it is carried out using two processes, namely VM adjustment and VM migration. Horizontal scaling is a coarse-grained technique, which considers VMs as units for performing allocation. Here the number of VMs is enhanced or reduced on a horizontal layer, thereby adjusting the resources available by rebooting applications. This type of scaling cannot adjust when only one resource type is needed, thus it increasing the cost [23]. A major issue faced by the scaling techniques is determining, when scaling in or out has to be performed [24]. Though many studies have been carried out for implementing auto-scaling using VM migration and placement or machine learning, attaining Quality of Service (QoS) is still a major issue [25].
In this paper, an effective technique named, leader Harris honey badger algorithm based scaling is devised for performing elastic scaling. Here, load prediction is performed using the cloud model depending on the bandwidth, memory, and CPU. The predicted load is then compared with the predefined threshold to decide whether elastic scaling has to be performed. If the predicted load is greater than the threshold, then horizontal scaling is performed, otherwise, vertical scaling is performed. The devised leader Harris honey badger algorithm is utilized for carrying out elastic scaling depending on the CPU, memory, and hard disk.
The major contribution of this article is given below. Introduced leader Harris honey badger algorithm for elastic scaling for resource management: A novel leader Harris honey badger algorithm is developed for performing elastic scaling, based on the load predicted. The devised leader Harris honey badger algorithm is created by adapting the leader Harris hawks optimization with respect to the honey badger algorithm, for enhancing the performance of the optimizer. Here, load prediction is performed based on the bandwidth, CPU, and memory.
The remaining part of the paper is divided into the following sections: Section 2 details the prevailing related works, Section 3 describes the system model of the cloud, and the devised method is detailed in Section 4. The results of the developed scheme are provided in Section 5 and the discussion is provided in Section 6. Finally, the conclusion is provided in Section 6.
Literature review
Scaling in the cloud has been studied in detail in several researches and many techniques have been proposed. Here, we consider eight of the prevailing works, and these methods are shortly briefed. In 2019, Toosi et al. [1] introduced an Elastic Service Function Chain (SFC) for performing auto-scaling in the cloud. The Elastic SFC technique is an algorithm, which was developed to perform vertical, as well as horizontal scaling of Virtualized Network Function and dynamically allocating the bandwidth. A Virtualized Network Function migration, as well as dynamic flow scheduling technique, was employed for enabling proficient resource utilization. The Elastic SFC was highly successful for satisfying the latency as well as cost reduction, but this method was not implemented in real-time scenarios, for analyzing the impact of the technique. Liu et al. [2] presented a bottleneck detection algorithm for eliminating the resource bottleneck in the cloud system in 2020. Here, the system load was monitored and iteratively increased by the automatically generated test module. The variation in the metric was analyzed with the help of the bottleneck detection algorithm for determining the bottleneck, and a vertical scaling technique was provided for overcoming the system deficiency. This technique was effective for eliminating the feeble point of the target services; however, it did not consider the integration of horizontal scaling for dealing with large-scale applications. Also, in 2020, Li et al. [3] presented an integer programming algorithm for performing dynamic elastic scaling. This system was realized using two parts, such as load prediction and elastic scaling. Initially, the present trends and the past features of the load were utilized to predict load using the load prediction model. Based on the load, the resources were assigned for satisfying the user demand. Elastic scaling was then carried out using horizontal as well as vertical scaling. Multiple combinations were generated to satisfy the resource needs, and the integer programming algorithm selected the cost-effective scaling from the various combinations. This method was highly effective for minimizing the scaling cost as well as enhancing the utilization of resources; but this scheme did not consider the minimization of dynamic resource cost. Yu et al. [4] created an elastic Network Function Virtualization (NFV), in 2020, for provisioning resources in cloud for Virtualized Network Function. The Elastic NFV was implemented using two modules, namely the Scaling Conflict Handling, and Resource Elastic Provisioning modules. The current resource requirements were captured by using a Dynamic Multi-Resource for provisioning elastic resources. Further the Scaling Conflict Handling module was used to estimate the time for triggering the migration. The Elastic NFV method was highly effective in minimizing the embedding cost and migration time, however this technique failed to consider a hybrid of both vertical and horizontal scaling for enhancing the resource allotment.
In the same year, Brabra et al. [5] devised a Cloud Resource Description Model for managing cloud resources using elasticity. Here, a high-level abstraction set was utilized for describing the cloud resources, while taking into account the behavior of the resources based on elasticity with time using cloud resource requirement State Machine. Moreover, it offered an effortless method of simplifying cloud resources based on elasticity. Further, it considerably minimized the effort and time required for designing the system. However, the technique failed to utilize learning techniques for identifying the autonomic features for handling unanticipated situations. Also, Shahidinejad et al. [6] proposed an auto-elastic colored Petri nets for automatic management of cloud resources. The system behavior was explored by considering the system states as well as the incidents causing state variations. Here, an elastic controller based on colored Petri nets was used for modeling the host, controller as well as arrival transitions. This system was successful in enhancing the QoS of the cloud services, although it failed to utilize the colored Petri nets for scheduling for improving accuracy. In 2021, Sahni and Vidyarthi [7] developed a StreamScale-H auto-scaling algorithm for performing elastic scaling. StreamScale-H was a heterogeneity-aware scaling technique that utilized a hybrid auto-scaling technique for identifying the positions at which scaling was needed. Moreover, it identified the suitable VM sizes based on the heterogeneity of VMs. The technique was highly efficient for offering high QoS with minimal costs, but it was unsuccessful for reducing the overhead. In the same year, Yan et al. [8] developed a HANSEL system for optimizing horizontal scaling using the Kubernetes platform. Here, a Bidirectional Long-term and Short-Term Memory (Bi-LSTM) was employed for estimating the load along with an attention scheme and also reinforcement learning was utilized for realizing elastic scaling. This system was highly efficient for enhancing resource utilization; however, it did not consider cooperation and satisfaction of the distributed management needs and also failed to adapt with varying scenarios.
The main challenges encountered by the prevailing approaches of scaling in cloud are listed below.
A bottleneck detection scheme was proposed in [2] for performing resource allocation by recommending scaling in case of a bottleneck. The major challenge faced by this approach was that it did not consider the integration of horizontal and vertical scaling algorithms to handle large-scale resource allocations. An integration of horizontal and vertical scaling algorithms was considered in [3], where integer programming algorithm was devised for implementing dynamic scaling. This approach did not take into account the prediction of load using various metrics apart from memory and CPU for improving the accuracy. The drawback in [3] was overcome in [6], where the colored Petri net based elastic controller was proposed, which was highly efficient in estimating the resources with the varying workload. However, the technique did not consider the utilization of auto-scaling methods for improving its performance, which remained a key challenge. An efficient auto-scaling technique was proposed in [7], wherein the StreamScale-H was utilized for performing elastic scaling. This technique was unsuccessful in considering the incorporation of the approach with the prevailing open-source Stream Processing Systems for validating it in cloud platforms. Existing techniques of scaling pose a great challenge where they have to adapt to the rapidly varying workload requirement in a very short time. Moreover, the random workloads forbid the utilization of fixed models for scaling. In addition to this, the scaling approaches have to provide flexible resource allocation on the PMs without affecting QoS, which remains a key challenge.
System model of cloud
The advancement in the field of digital technology has led to the explosion of data that is generated daily. This ever-increasing data poses a requirement for development of technology for their storage and processing, which can be realized by using cloud computing. Cloud computing provides users with opportunity of accessing the huge amount of information, data and other computing devices on a pay per use basis. The increasing user demand for resources can be met by the usage of virtualization, wherein the virtual versions of the resources are created by using the limited physical resources. A single PM can be considered to have multiple versions of VMs, and each VM can be utilized for performing individual tasks. The allocation of VMs is a critical process, as improper allocation can result in overloading, or under-loading, thereby affecting the performance of the cloud. Figure 1 depicts the system model of cloud.
System model of cloud.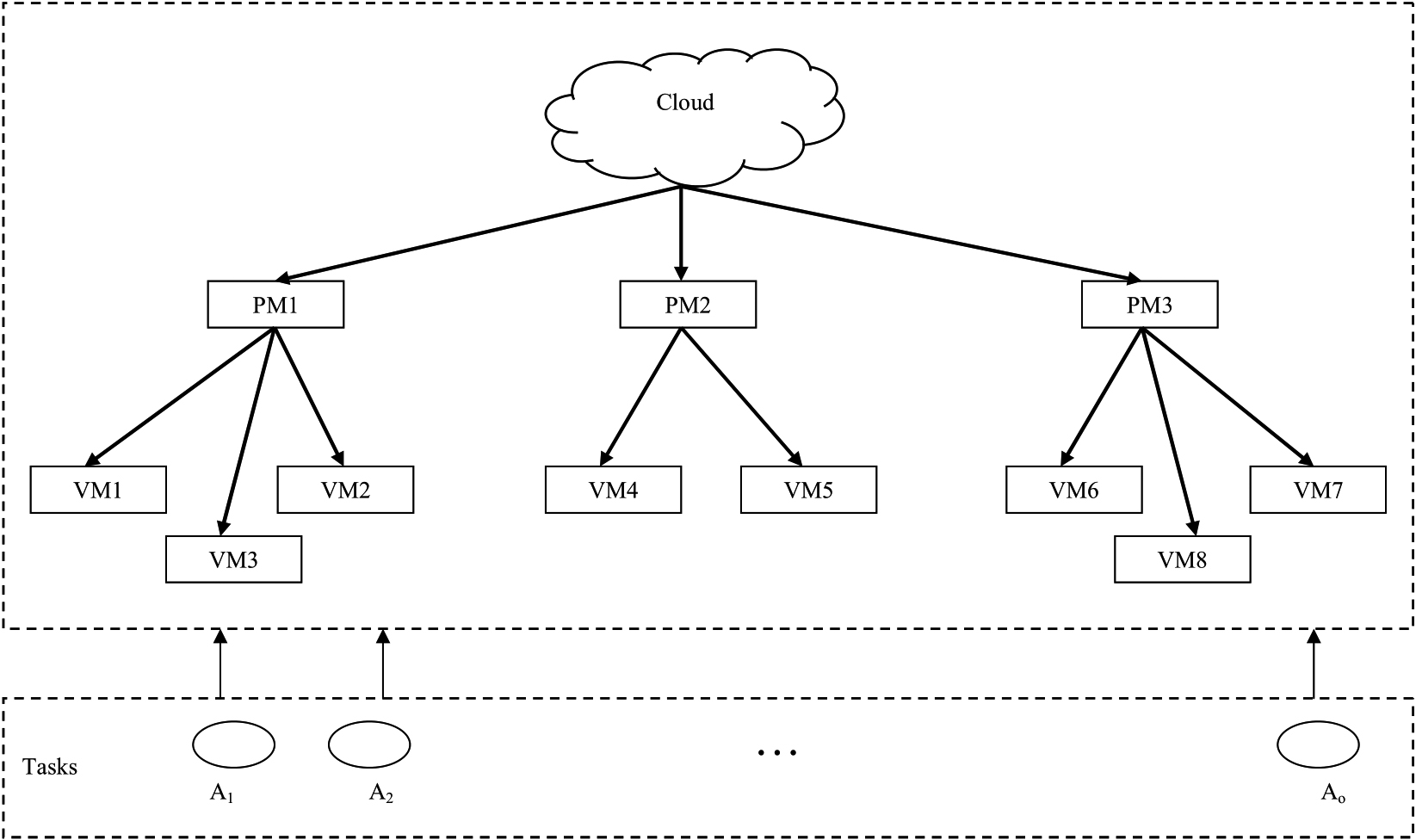
Consider the system model of the cloud computing, assume that there a set of PMs denoted by
Schematic view of the developed leader Harris honey badger algorithm based elastic scaling for resource management.
Scaling is a key process that enables the smooth handling of services provided by the cloud. However, the limited number of PMs make it a challenging task to allocate the resources based on user demand without causing any wastage and affecting the user experience. Additionally, scaling has to be done with a reduced cost. In this paper, a hybrid optimized scaling technique is devised. The developed leader Harris honey badger algorithm based scaling is realized using the following steps. Initially, the tasks are submitted by the user to the cloud. Based on the tasks, the load prediction is carried out on the VM using the cloud considering the bandwidth, CPU, and memory. If the predicted load is high, i.e. if the VM is overloaded, then scaling has to be performed, whereas no scaling is performed during the predicted load is low. The predicted load is compared to the predefined threshold, when the predicted load is greater than the threshold, horizontal scaling is carried out, or else vertical scaling is done. Horizontal scaling is performed by adding nodes to the overloaded system from the underloaded system using the devised leader Harris honey badger algorithm, based on the horizontal cost that depends on CPU, memory, and hard disk. On the other hand, vertical scaling adds CPU, RAM, etc. to the system using the developed leader Harris honey badger algorithm. Here, the leader Harris honey badger algorithm is devised by integrating the leader Harris hawks optimization [26] algorithm with respect to the honey badger algorithm [27]. Figure 2 depicts the schematic view of the developed leader Harris honey badger algorithm based elastic scaling, and the process of the devised elastic scaling is detailed in the upcoming sections.
The process of scaling is carried out using Algorithm 1.
Incoming task
Let us assume the incoming tasks by denoted by,
where
Load prediction [3] is performed by performing transformation of the quantitative data into qualitative concept, wherein a concept leap is made by considering the ideas of overlapping, as well as intimate clouds. Later the prediction model is established by considering the relation between memory, and CPU. Load prediction is performed by considering the historic or past data and the present data. The collected historic data comprises the bandwidth, CPU consumption of the VM, and memory consumption. Let us consider that the data is gathered over a long time period
where
The past dataset is given by,
The present dataset is given by,
At last, the above three datasets are utilized for generating the cloud models, which are combined for predicting load using the inertial weighting technique. In the cloud system, load data is present in the time-series format. This data has to be normalized, and then fitted for converting the quantitative data into qualitative concepts, for performing load prediction. The transformation is based on the principle that low frequency elements contribute less to the qualitative concept than those at high-frequency and is represented by,
where
Here, the load, comprising of CPU and memory consumption is transformed into qualitative concept, which contains several clouds. The qualitative concept, thus generated is coarse as the distance among the neighboring clouds is low. Hence, for selecting the best concept count, and making the concept of individual clouds clear and the distance suitable, concept leap is required. The overlap and similar cloud concept are determined using overlap and similarity, wherein overlap refers to the percentage of small clouds created by the overlapping of abscissa and two neighboring clouds. Similarity can be described as the distance among two neighboring clouds, which is computed by finding the absolute value of the variation in the expected values. Consider the expected curve of the two neighboring clouds be represented by the distribution functions,
As there is no certainty on the location and size of the neighboring clouds, three scenarios can exists where the clouds can intersect at two points, one point or no point. The cloud can be considered to cover the adjacent cloud completely in case of no intersection, and in this case, the overlapping degree
where area indicates the overlap area
The clouds are regarded as overlap or similar clouds, when the overlap degree is higher than the threshold value
This section details the process of elastic scaling using the devised leader Harris honey badger algorithm scheme. The predicted load
Horizontal scaling
When the predicted load
4.3.1.1. Solution encoding
Solution encoding is a way of representing the solution of any problem using a pictorial representation. Here, the solution indicates the underloaded PM, to which the VMs have to be added from the overloaded PM. Figure 3 represents the solution encoding of horizontal scaling.
Solution encoding of horizontal scaling.
4.3.1.2. Fitness function
The optimal solution is calculated considering the fitness function, wherein the minimal fitness function yields the best solution. The horizontal expansion cost is considered as the fitness function, and is given by,
where
where
where
4.3.1.3. Devised leader Harris honey badger algorithm
This section elaborates the developed leader Harris honey badger algorithm for performing horizontal scaling, wherein the developed leader Harris honey badger algorithm is created by adapting the exploration capability of the leader Harris hawks optimization [26] corresponding to the honey phase of the honey badger algorithm [27]. The leader Harris hawks optimization algorithm was developed for enhancing the exploration ability of the Harris hawks optimization. The Harris hawks optimization algorithm is inspired from the supportive conduct and the surprise pounce strategy of the Harris’ hawks while chasing a prey. Multiple hawks wait for the prey and besiege in from various directions cooperatively for surprising it, and attacking the prey at last. The Harris hawks optimization algorithm reveals multiple chase patterns and escaping strategies, however suffers from limited exploration, which is overcome in leader Harris hawks optimization by constraining the adaptive perch probability and using a leader-oriented mutation-selection approach. The leader Harris hawks optimization is highly efficient in minimizing the complexity of the system and avoiding local optima; however, it is computationally expensive. On the other hand, the honey badger algorithm is modeled based on the foraging features of the honey badger, wherein the dynamic way of finding honey by smelling or digging or following a honey guide bird is considered. Two modes, namely digging, as well as honey mode are considered for finding the food. The honey badger employs its ability to smell for determining the food source location, and the prey is captured by digging the site after appropriate selection, in the digging mode. In the honey mode, the badger follows the honey guide bird for identifying the beehive location. The honey badger algorithm offers the advantage of rapid convergence, and it is efficient in determining the problem solutions from a complex search area, but it failed to consider multiple objectives while optimization. By amalgamating the honey badger algorithm and leader Harris hawks optimization, the merits of both the optimization strategies can be obtained in the hybrid scheme, thus improving the effectiveness of the optimizer. The leader Harris honey badger algorithm performs optimization in two phases, namely exploration, as well as exploitation based on the escape energy, which is given by,
where
The algorithmic steps of the developed leader Harris honey badger algorithm are given below;
Step 1) Initialize the position vectors of hawks
Let us consider a population of hawks, whose position vectors are represented by using the following expression,
where
Step 2) Evaluation of fitness
The fitness parameter is already defined using Eq. (11).
Step 3) Exploration phase (
)
The hawks perform exploration of the prey position in this phase, the adaptive perch probability of each hawk is considered for performing exploration,
wherein
where
Now, consider
The honey phase in honey badger algorithm, where the honey guide bird is followed by the badger can be represented by the expression given below,
where,
where
Substituting Eq. (27) in Eq. (25), we get,
Substituting Eq (33) in Eq. (24), we get
where
Step 4) Exploitation phase (
)
The hawks carry out the surprise pounce based on the seven kill tactics for hunting the prey. The prey always attempts to evade the attacks, which leading to different attack schemes from the hawks. Consider the prey has a chance
i) Soft besiege
While
Here,
where
ii) Hard besiege
While
iii) Soft besiege with progressive rapid dives
While
where
Here,
where
iv) Hard besiege with progressive rapid dives
While
Here,
where
Step 5) Leader-based mutation-selection
The mutation position vector of the hawk is computed by considering the best, second best, and the third best position vectors of the hawks, represented by
The position vector for the next iteration can be obtained by the following expression,
Similarly, the prey location is updated as,
Step 6) Re-evaluate fitness
Once the new solution is generated, the fitness of the solution obtained is recomputed. If the generated solution has a lower fitness value than the previous one, it will replace the existing solution.
Step 7) Terminate
The above process is kept repeated till the maximum value of iteration
The best solution corresponds to position vector of the prey
Vertical scaling is performed when the predicted load is less than the threshold value. Here, scaling is carried out by adding CPU, RAM to the existing system, for meeting the user demand. Vertical scaling aims at improving the capacity of the system by upgrading the resources available.
4.3.2.1. Solution encoding
In this section, the solution encoding of vertical scaling is briefed, wherein the solution represents the VMs. Here,
Solution encoding of vertical scaling.
4.3.2.2. Fitness function
The fitness function used to find the optimal solution while performing vertical scaling is briefed here. The fitness function is computed by considering the vertical cost [28], which is given by
where
where
4.3.2.3. Devised leader Harris honey badger algorithm for vertical scaling
Virtual scaling is performed by using the developed leader Harris honey badger algorithm, which is created by adapting the leader Harris hawks optimization algorithm in line with the honey badger algorithm technique. The devised leader Harris honey badger algorithm is already elaborated in the section 4.3.1.3. Here, only the fitness function differs and the fitness function is given by Eq. (53), and the optimal solution corresponds to the one with minimum fitness.
In this section, the experimental outcomes of the developed leader Harris honey badger algorithm (LHHBA) based elastic scaling are examined in order to reveal its effectiveness. The devised LHHBA based elastic scaling is realised by implementing it using Python tool using simulation on a Personal Computer with Windows 10 Operating System, Intel i3 core processor and 8 GB RAM. Moreover, the devised elastic scaling approach is compared with the prevailing approaches based on various metrics, which are also briefed in the sub sections.
Evaluation measures
The evaluation of the devised LHHBA based elastic scaling is carried out using measures, like predicted load error, cost, and resource utilization. These metrics are shortly briefed in the upcoming sections.
Predicted load error
The predicted load error is estimated by determining the difference between the actual load and the predicted load and is represented as,
where
Cost is computed by considering the total cost of scaling the resources during the process of elastic scaling, and is expressed as,
where
where
Resource utilization is determined by using the following expression,
where
In this section, the developed LHHBA based elastic scaling technique is compared to the state-of-art approaches, like Integer Programming Algorithm [3], Bottleneck detection algorithm [2], StreamScale-H auto scaling [7] and Elastic Service Function Chain (SFC) [1], in order to reveal the effectiveness of the devised approach.
Comparative assessment with task size as 100
This section details the assessment of the developed LHHBA based elastic scaling technique when the task size is considered to be 100, by considering various measures, and the same is displayed using Fig. 5. Figure 5a depicts the comparative evaluation of the developed technique based on predicted load error. The prevailing techniques, such as Integer Programming Algorithm, Bottleneck detection algorithm, StreamScale-H auto scaling and Elastic SFC computed values of predicted load error at 0.2732, 0.1263, 0.1238, and 0.0952 for 5 epochs. The devised LHHBA elastic scaling measured a value of low predicted load error at 0.0196. In Fig. 5b, the assessment of the developed LHHBA based elastic scaling is depicted using cost. For 10 epochs, the existing approaches, like Integer Programming Algorithm, Bottleneck detection algorithm, StreamScale-H auto scaling and Elastic SFC and the devised LHHBA based elastic scaling calculated cost of 1128.676, 830.286, 561.854, 489.784, and 253.075. The analysis of the devised LHHBA based elastic scaling is illustrated in Fig. 5c based on resource utilization. The proposed LHHBA based elastic scaling attained a resource utilization of 0.3376, but the state-of-art methods, like Integer Programming Algorithm, Bottleneck detection algorithm, StreamScale-H auto scaling and Elastic SFC attained a higher value of resource utilization at 0.5342, 0.4656, 0.5039, and 0.4467, respectively.
Comparative evaluation with task size 100.
Figure 6 depicts the comparative assessment of the developed LHHBA based elastic scaling when the task size is 200 by considering multiple values of epochs. In Fig. 6a, the analysis of the devised LHHBA based on predicted load error is displayed. For epoch as 10, the prevailing methods, such as Integer Programming Algorithm, Bottleneck detection algorithm, StreamScale-H auto scaling and Elastic SFC obtained values of predicted load error at 0.2817, 0.1251, 0.1262, and 0.0982. The devised technique achieved a low value of prediction error rate at 0.0187. Figure 6b portrays the evaluation of the developed technique based on cost. The proposed LHHBA based elastic scaling achieved a cost of 281.471, which is less than the value of cost at 1282.471, 821.422, 582.168, and 601.154 attained by the prevailing approaches, such as Integer Programming Algorithm, Bottleneck detection algorithm, StreamScale-H auto scaling and Elastic SFC for 15 epochs. The evaluation of the introduced LHHBA based elastic scaling with respect to resource utilization is portrayed in Fig. 6c. The proposed elastic scaling scheme achieved a low resource utilization of 0.3547, whereas the value corresponding to the existing methodologies, like Integer Programming Algorithm, Bottleneck detection algorithm, StreamScale-H auto scaling and Elastic SFC is 0.5374, 0.4639, 0.4418, and 0.4996, for 5 epochs.
Comparative evaluation with task size 200.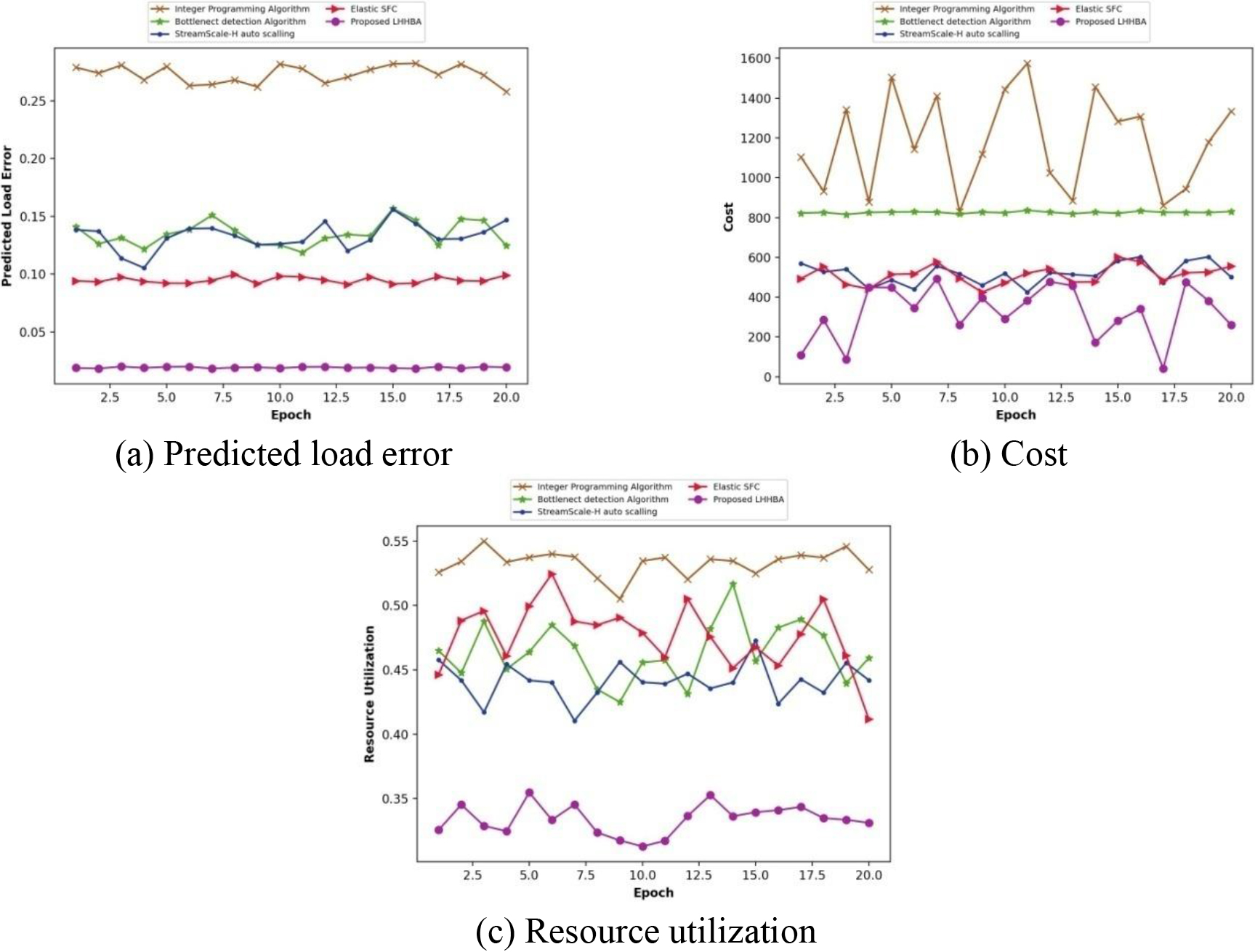
In Fig. 7, the comparative analysis of the developed LHHBA based elastic scaling with task size as 300 by considering various epochs. Figure 7a depicts the analysis based on predicted load error. For 15 epochs, the conventional methods, like Integer Programming Algorithm, Bottleneck detection algorithm, StreamScale-H auto scaling and Elastic SFC and the proposed LHHBA technique attained value of predicted load error at 0.2703, 0.1336, 0.1447, 0.0948, and 0.0191 respectively. The evaluation of the devised LHHBA based elastic scaling based on cost is displayed in Fig. 7b. The cost calculated by the devised approach is 76.887, whereas the conventional techniques, like Integer Programming Algorithm, Bottleneck detection algorithm, StreamScale-H auto scaling and Elastic SFC attained cost of 868.570, 818.045, 486.174, and 555.129, for 5 epochs. In Fig. 7c, the evaluation of the developed LHHBA based elastic scaling is represented using resource utilization. With 10 epochs, the prevailing methods, such as Integer Programming Algorithm, Bottleneck detection algorithm, StreamScale-H auto scaling and Elastic SFC computed resource utilization values of 0.5410, 0.4795, 0.4766, and 0.4520, while the developed LHHBA scaling technique achieved low resource utilization of 0.3431.
Comparative evaluation with task size 300.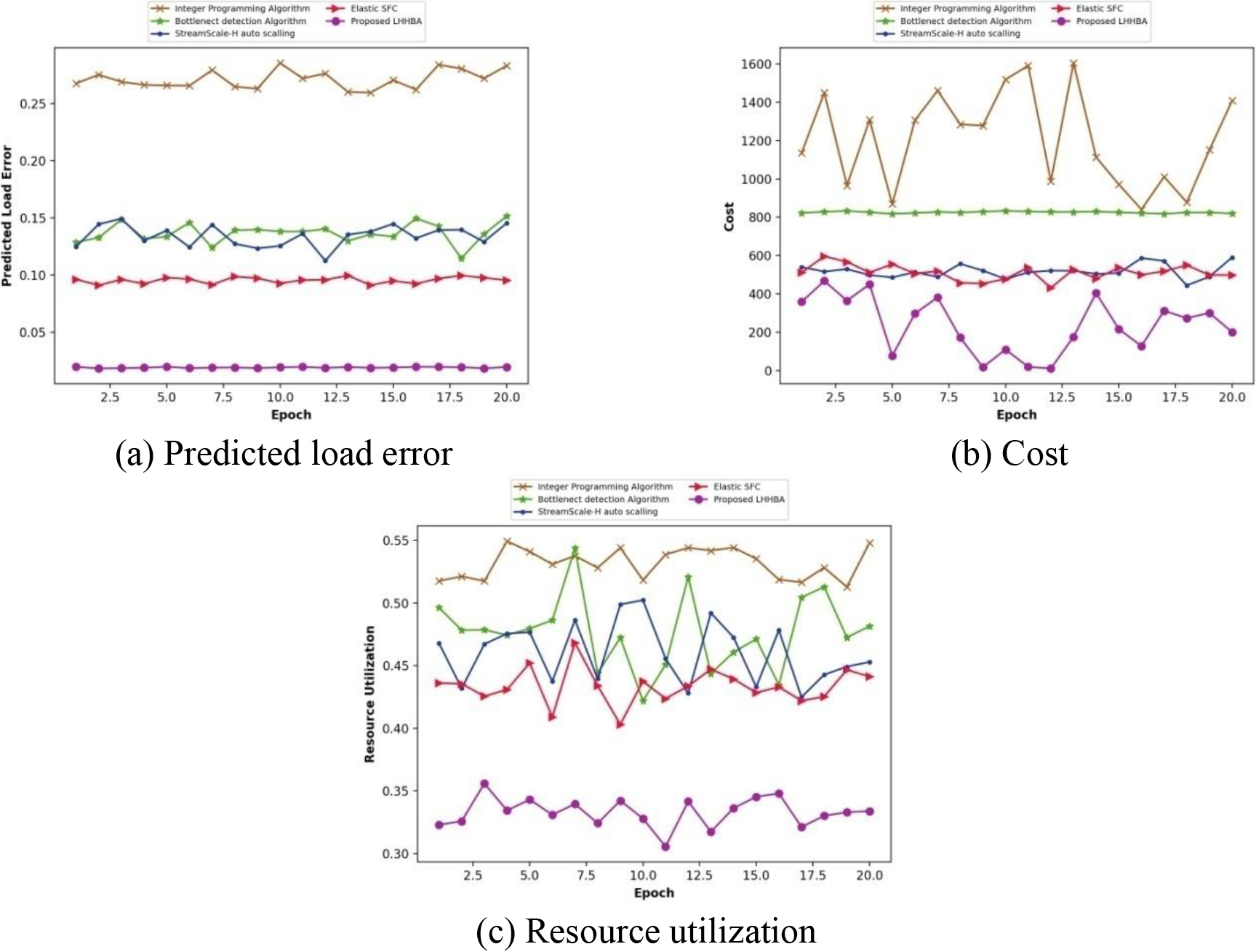
Comparative evaluation with task size 400.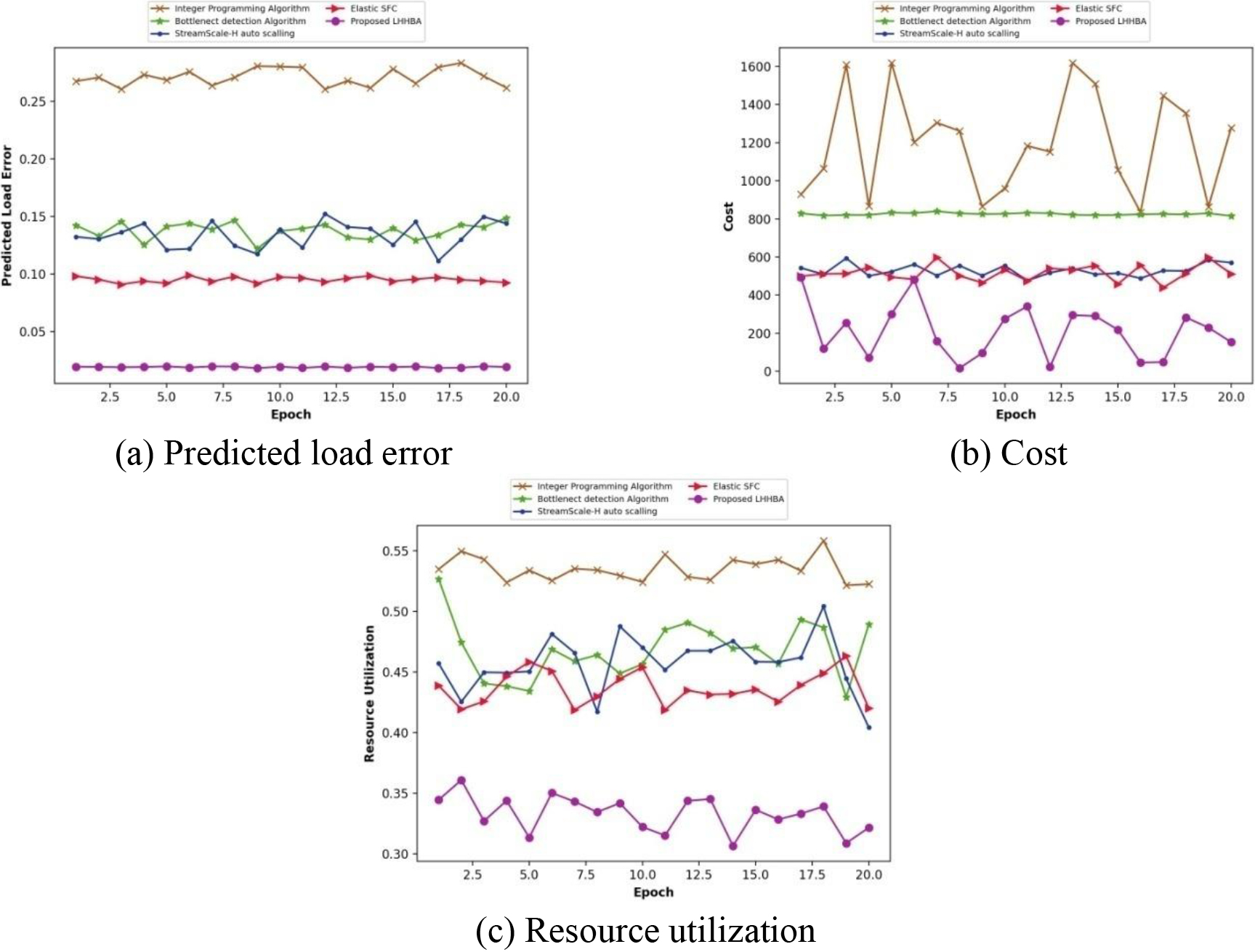
In Fig. 8, the analysis of the devised LHHBA based elastic scaling is displayed by considering task size as 400, by varying the number of epochs. The assessment based on predicted load error is displayed in Fig. 8a. The state-of-art techniques, like Integer Programming Algorithm, Bottleneck detection algorithm, StreamScale-H auto scaling and Elastic SFC and the introduced LHHBA approach computed predicted load error of 0.2781, 0.1399, 0.1255, 0.0938, and 0.0192, for 15 epochs. In Fig. 8b, the cost-based analysis of the developed scheme is shown. At 5 epochs, the devised LHHBA approach measured value of cost at 301.249, which is less than the values of 1617.606, 832.428, 523.216, and 494.079, computed by the existing schemes, like Integer Programming Algorithm, Bottleneck detection algorithm, StreamScale-H auto scaling and Elastic SFC. Figure 8c illustrates the assessment of the developed LHHBA technique using resource utilization. The prevailing methods, such as Integer Programming Algorithm, Bottleneck detection algorithm, StreamScale-H auto scaling and Elastic SFC attained resource utilization of 0.5242, 0.4565, 0.4702, and 0.4540, which is higher than the value 0.3223 calculated by the developed LHHBA based elastic scaling for 10 epochs.
Discussion
The comparative discussion of the introduced LHHBA based elastic scaling is explained in this section. The devised elastic scaling technique is compared with the state-of-art approaches for examining its effectiveness based on measures, such as predicted load error, cost, and resource utilization. Table 1 displays the values attained for the various approaches based on the metrics corresponding to 20 epochs, for task sizes of 100, 200, 300, and 400. It can be observed from the table that the devised LHHBA based elastic scaling attained a minimum value of predicted load error, cost, and resource utilization at 0.0193, 153.581, and 0.3217, thereby proving its effectiveness. The low value of load predicted error is caused by the performing transformation of the past data into qualitative concepts during the prediction process. Further, the utilization of the hybrid optimization process while performing scaling minimized the cost and the elastic scaling process reduced the resource utilization. Also, the proposed LHHBA minimizes the complexity of the system, avoids local optima, and increases the convergence speed. Hence, the proposed method offers the high performance than the existing methods, such as Integer Programming Algorithm [3], Bottleneck detection algorithm [2], StreamScale-H auto scaling [7] and Elastic SFC [1].
Metrics discussion for various task sizes
Metrics discussion for various task sizes
This paper devises an efficient technique of elastic scaling, which provides an effective way of utilizing the multiple resources available in cloud computing without affecting the user experience. Here, the load is initially predicted by utilizing the cloud model considering parameters, like CPU, and memory, the value obtained is checked to find if overloaded. If overloaded, vertical scaling and horizontal scaling are carried out by comparing the predicted load with a threshold value. A new optimization algorithm is developed for performing the process of scaling, based on parameters, such as bandwidth, CPU and memory. The developed leader Harris honey badger algorithm is devised by adapting the exploration ability of the hawks leader Harris hawks optimization algorithm in line with the honey phase of the honey badger algorithm. The devised leader Harris honey badger algorithm based elastic scaling is scaling is evaluated for its effectiveness based on metrics, such as predicted load error, cost, and resource utilization, and is found to have attained values of 0.0193, 153.581, and 0.3217. Further investigation will focus on the utilization of other metrics, like response time, and throughput for improving the effectiveness of the scaling approach.
Footnotes
Author’s Bios