
Abstract
Social platform have disseminated the news in rapid speed and has been considered an important news resource for many people over worldwide because of easy access and less cost benefits when compared with the traditional news organizations. Fake news is the news deliberately written by bad writers that manipulates the original contents and this rapid dissemination of fake news may mislead the people in the society. As a result, it is critical to investigate the veracity of the data leaked via social media platforms. Even so, the reliability of information reported via this platform is still doubtful and remains a significant obstacle. As a result, this study proposes a promising technique for identifying fake information in social media called Adam Adadelta Optimization based Deep Long Short-Term Memory (Deep LSTM). The tokenization operation in this case is carried out with the Bidirectional Encoder Representations from Transformers (BERT) approach. The measurement of the features is reduced with the assistance of Kernel Linear Discriminant Analysis (LDA), and Singular Value Decomposition (SVD) and the top-N attributes are chosen by employing Renyi joint entropy. Furthermore, the LSTM is applied to identify false information in social media, with Adam Adadelta Optimization, which comprises a combo of Adam Optimization and Adadelta Optimization . The Deep LSTM based on Adam Adadelta Optimization achieved maximum accuracy, sensitivity, specificity of 0.936, 0.942, and 0.925.
Keywords
Introduction
The majority of citizens have spent their entire lives by intermingling in online through social media systems in recent times, and much more people look and collect news from social media in place of traditional media. Implicit nature of such social media sites is the driving force behind this massive shift in news consumption. It is generally considered as a time effective process, and cost effective to gather news from social platform when contrasted with the conventional news organizations, such as television, and newspapers. Besides, the benefits of using this social platform are to share, comment, and converse the trending information’s with the readers available on social platform [14]. Because of its inherent properties, social media offers multiple advantages to audience, rapid distribution, and very cheap cost and is easily accessible by everyone at any time. The major reason behind this rapid development of user’s commitment in online news is the adorable characteristics of social platforms, such as fast dissemination, and user-friendly type. Though the social media has gained more attention among people in the world, the quality of the news distributed through such platforms are very low when compared to the conventional news distributed by the news organizations. This is because of the fact that the social media doesn’t have any authority that tend to cause the dissemination of wide spread of fake news. Numerous fake news, which are substandard with highly fake news are rapidly spread through online [28, 15]. Social platform has become a fundamental source of news consumption in recent days. Thus, it plays an effective role for individual person to post or comment news.
Fake has been termed as a own created information that copies the original content of news media but not followed the guidance of any organization, that imbricates with other content disorders like false information or misleading information that is intentionally made to mislead the people. It can minimize or maximize the efficiency of the programs, and campaigns that focused in citizen’s awareness, health, and well-being is the consequences of this false information in social platform [17]. Fake news means false information that spreads rapidly among people that deliberately made to mislead the people, which affect each individual in this society or as a whole society. The major impacts of dissemination of fake news are as follows: For instance, it may disrupt the news ecosystem’s truthfulness stability. The second issue is that false information persuades the majority of citizens to believe false narratives. Finally, fake news may create considerable impacts on real-world events [16, 31, 33, 34]. The recognition of false information has got more attention hence the social media also enable the huge dissemination of false information due to its harmful effects of false news. However, the efficiency of false report detection merely from original news content is usually insubstantial as the pieces of fake information are written to imitate the original news [18].
False information has emerged as one of the key constraints in both industry and academia in recent times, and human fact-checking is an appropriate solution to this issue. Human fact-checking scholars may have extremely lower power effectiveness. Besides, the manual fact-checking is very much expensive and laborious. Hence, in order to cope up with such limitations, Deep Learning and Machine Learning are introduced to computerize this mechanism [35, 36]. For past few years, Internet of Things (IoT) researchers have been trying to develop effective strategies for online false reports detection to find the fake news from original content and different hierarchical classification techniques can be employed for fake news detection [22, 37, 38]. To achieve the task as it needs systems to review the news and evaluate it with the original news to categorize it as fake whereas the identification of fake news is a difficult process. [19, 39, 40]. The Natural Language Processing (NLP) tasks shares similarities to fake news in which the deep learning models are utilized. In [21], to estimate the semantic similarity of question pairs the Siamese Manhattan LSTM (MaLSTM) is used. The text sequence is converted into a fixed length vector representation by the deep neural network which is then employed to determine the similarities of two textual sequences [20].
The most important aim of this experimentation is to expand and establish an efficient approach for fake news identification from social media by presenting Adam Adadelta Optimization (AO) based Deep Long Short-Term Memory (Deep LSTM). The contribution is given as follows: An effective approach is extended for detecting the false information from social media using Adam AO based Deep LSTM. The assortment of top level features is made by employing Renyi joint entropy measure such that it results the data with reduced dimension.
The leftover sections of the study paper are given below: The literature examination of the existing strategies of identifying fake news is examined in Section 2. The Adam AO based Deep LSTM for fake information identification and Section 4 explain the Adam AO training algorithm is depicted in Section 3. The findings and the explanation of the Adam AO based Deep LSTM scheme is presented in Section 5, the research is concluded in Section 6.
Literature review
Various accessible methods of fake news detection in social media are deliberated as follows: For effective prediction of fake short-text tweets, Lu and Li [1] developed a neural network based model named Graph-aware Co-Attention Networks (GCAN). This problem statement was very challenging task when compared with other conventional studies. The developed GCAN model provided early detection of fake news with high accuracy. Moreover, GCAN was not only developed for identifying the false information in social media but also utilized for classification tasks of short-texts in social media, like hate speech detection, sentiment detection, and tweet popularity prediction. However, the method failed to include generalization model to eliminate the event specific features as it improves the overall system performance. Han et al. [2] modeled a propagation based method approach for fake news detection, which uses Graph Neural Network (GNN) to discriminate among the propagation patterns of real and fake news on social platform. It did not depend on any text details but, it offered better results and higher performance. The developed model avoided the process of re-training on the complete data that decreases the training time. The primary drawback of this approach was that it did not handle different graph structure. For false report detection, Kaliyar et al. [3] devised a deep convolutional neural network for fake news detection (FNDNet). Here, Deep Fake extracted various features at each layer. The cross-entropy rate was very low and the developed approach obtained high classification accuracy. However, the method failed to consider the user profiles based features, and context-specific datasets as it detects the fake news article effectively. A deep neural network is commenced by Kaliyar et al. [4] for classification task, where the context of the news article and the presence of echo chambers in the social media platform were considered for the identification of false report. The developed method offered precision without causing over fitting on the training data. However, the model had the inability to conduct text based classification of news articles in real time.
Monti et al. [5] presented an automatic fake news detection model based on geometric deep learning. The developed method incorporated the heterogeneous data associated with the user activity and profile, news disseminating patterns, social network topology, and social content. The major advantage of this detection model was learning capability the task-specific features from the information. The developed model achieved very high accuracy in various setting levels including large-scale real data, but the performance results was not satisfied in false news identification, such as classification of news topic and virality prediction. Zhang et al. [6] presented a concept of double emotion features in which the emotions of publisher and the social emotions were taken into account for false news identification. The developed model was very well compatible with existing fake news detector. The developed model failed to leverage multi-modal information to acquire the emotions even more precise and also failed to utilize enlightened techniques for dual emotion representation. An efficient deep neural network that had concentrated on considering both the existence of echo chambers over social network and the content of news article was designed by Kaliyar et al. [7]. The developed model provided valuable information about user based interaction. However, accurate classification could be enhanced by including the temporal information. Wang et al. [8] end-to-end framework called Event Adversarial Neural Network (EANN). The developed model was basically comprised with three components. The system actually recorded basic information across all activities, and this depiction was also discriminatory on upcoming events that were to come. However, the method failed to handle the complex feature representation.
Proposed adam Adadelta Optimizer (AO) based deep long short term memory (Deep LSTM) for fake news identification
Fake news identification is intentionally made by the bad writer that imitates the real news and dissemination of such fake news across worldwide misleads the people. At first, the input review information is taken from the review database specified in [10, 27] and it is subjected to tokenization phase. The tokenization phase is fulfilled by using the Bidirectional Encoder Representations from Transformers (BERT) process [11]. The features like Term Frequency-Inverse Document Frequency (TF-IDF), sentence level features, like punctuation, elongated words, capitalized words, Emoticons, Numerical words, and SentiWordNet (score), like positive and negative scores are extracted at the feature extraction phase. Once the features are extracted, dimensionality reduction is performed using Kernel Linear Discriminant Analysis (LDA) [24], and Singular Value Decomposition (SVD) [25] individually, and then the top-N features are selected using Renyi joint entropy. Finally, the chosen features are given into the Deep LSTM [9] for false information identification, where the network classifier is trained by means of the Adam Adadelta Optimizer (AO). The Adam AO is derived by the incorporation of Adam optimization [23] and AO, wherein the activation functions are the sigmoid activation function in output layer and the tangential activation function in hidden layer. Figure 1 represents the schematic view of Adam AO based Deep LSTM.
Block diagram of adam Adadelta Optimizer (AO) based deep long short term memory (Deep LSTM).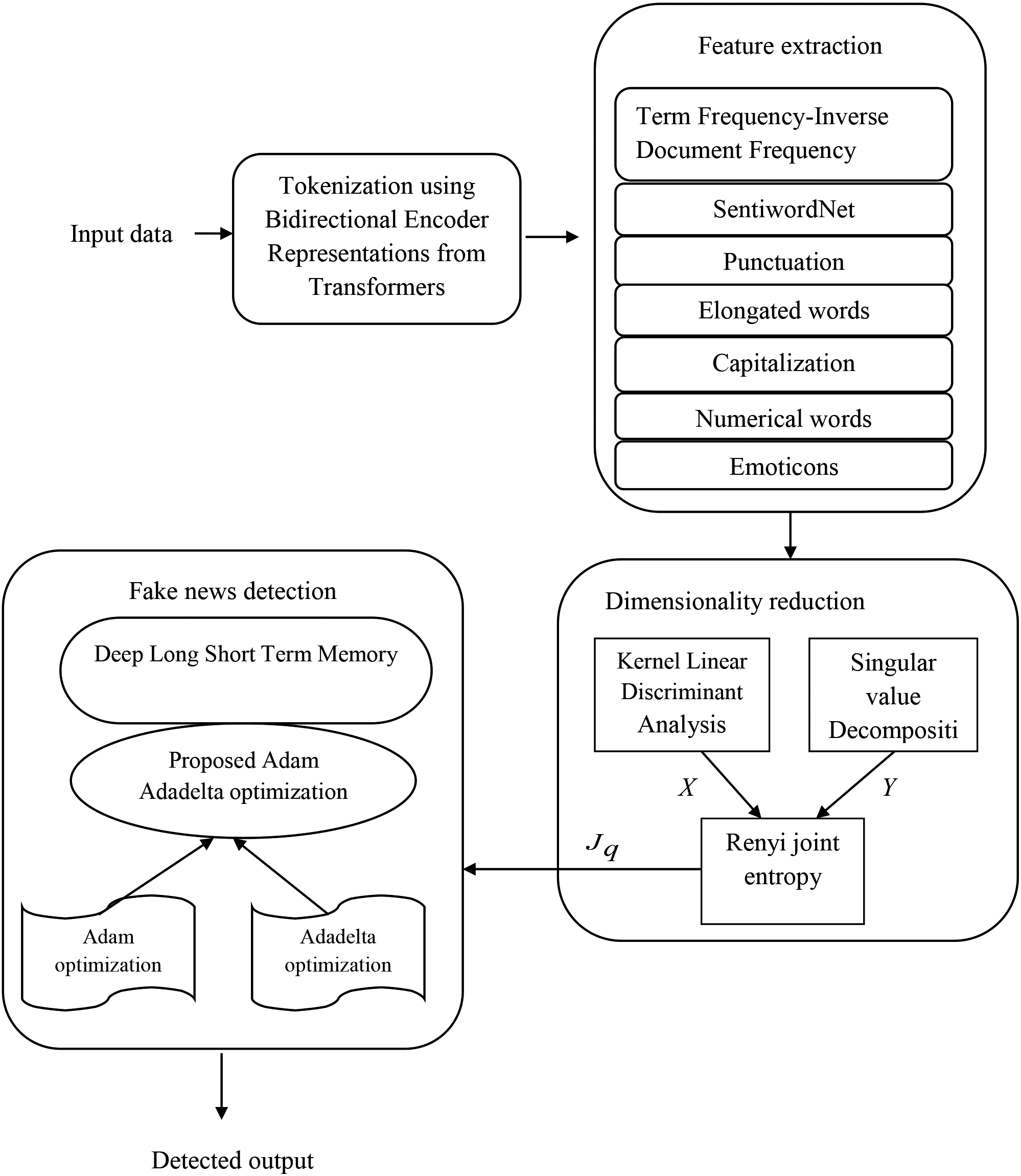
The public reviews on social media platform reveal the emotions, opinions, sentiments, and the expressions of the people all over the world that is very substantial. Hence the review data acquired from the fake news net database specified in [10, 27] is considered as an input data for upcoming process.
where
Tokenization refers to the technique of separating a statement into individual words, and it is important to tokenize content feedback. Before even being fed into the framework, the phrases are separated into minor words which are known as the tokens. Each model showed its respective entailed with its tokenizer, trained on a massive raw data. Here,
Feature extraction
The result of the tokenization procedure is applied to the extraction of feature method. This is the procedure of extracting the appropriate characteristics, which is mainly utilized to train a machine learning classifier. The fundamental aim of feature extraction is to characterize the input text and make it suitable for further processing. The choice of suitable features can enhance the accuracy of the framework and also reducing the price of the training phase. Furthermore, choosing effective attributes can lengthen the system’s training time. As a result, less but more effective features are extracted are described below:
Term frequency-inverse document frequency (TF-IDF)
TF-IDF [13] utilizes the frequency count of every term present in the whole document for the characterization of input text. Such frequencies are employed to determine the value that represents the implication of a term mentioned in the whole manuscript. Alternately, it also represents every term in the document by its corresponding weight. Typically, most of the feature extraction process includes the feature of TF-IDF [22], because the normal term frequency is not a reliable technique to characterize all the terms in a document, specifically when the set of documents has huge number of documents. It is a process of information retrieval in which its value maximizes if the token occurs often in the document and the value minimizes if the token occurs frequently in the corpus, thereby resulting an accurate metric value. TF-IDF provides the score of word frequency that attempts to point up the interesting words. Thus, TF-IDF can be expressed as,
where the entire documents is specified as
The SentiWordNet [12] is employed to extract the scores and numbers of positive, negative, and neutral words in tweets. In addition, the SentiWordNet is also utilized to determine the total score and this score is very significant to categorize the tweets into multiple classes to understand the sentiment value of the tweets. Here, polarity score triple is employed to calculate the semantic orientation of a word and for this, comparison of positivity and negativity value per term is performed. The negative or positive grouping of review texts and it is specified as,
where
Emotions on the social tweets are strengthened utilizing exclamation and question marks. Punctuation they are essential for the grammatical structure of a text. This feature considers the number of questions marks in the tweets and the number of exclamation marks in the tweet message. Therefore, such features are more useful to provide certain information about the sentiment of a tweet message. The punctuation feature is expressed as
Elongated words
These are a type of feature that counts the number of words that are replicated with the characters twice, 3 times, or 4 times all through the file. Eg., happy. The result obtained from this type of feature is expressed as
Capitalization
Capitalized words, also known as capitalization, are a feature that is primarily used to determine the number of words in a document that contain all upper-case characters. The output obtained from this feature is denoted as
Numerical words
It is a characteristic utilized to establish the number values existed in a sentence and the feature extracted is notated as
Emoticons
Emoticons are facial expressions acquired in pictorial representation, and are frequently utilized in social platform to convey their emotions. The emoticons must be substituted with its sentiment polarity and the resultant of this feature is indicated as
Therefore, the output obtained from the method of feature extraction is expressed in the form of,
The extracted feature
Kernel linear discriminant analysis (LDA)
It is a standard tool for categorization problem and it is purely on the basis of conversion of the input space into a latest one. By exploiting kernel functions, LDA [24] is generalized in a case where in the converted space the principal component is nonlinearly associated with the input variables. The Kernel function
Step 1: calculate the matrices
For a given classes
Let
where
where
Step 2: Decompose
Assume Eigen vectors matrix decomposition
where the diagonal matrix of non-zero eigen values is specified as
Step 3: Compute Eigen vector and Eigen values
Since
Step 4: Compute Eigen vectors and normalize them
As the eigen vectors are linear combinations of
All solution of
The coefficients of
Step 5: calculate projections of test points into the Eigen vectors
By knowing the normalized vectors
The result achieved through the process of Kernel LDA is expressed as
SVD [25] is a general method for the study of multivariate information and it can identify and even mine the small signals from noisy data. SVD offers another way to factorize a matrix into singular values and singular vectors. Moreover, SVD is used to determine some of the same type of information as the Eigen decomposition determines.
Let
where
Let the measurement of the extracted feature is
Once the measurement of the features is decreased by means of Kernel LDA and SVD, the top-N characteristics are selected using Renyi joint entropy. The equation for Renyi joint entropy is represented as,
where
The output obtained from the fusion of features using Renyi joint entropy
Structure of Deep Long Short Term Memory (Deep LSTM)
Deep neural systems are a type of recursive feed forward systems, which are mainly utilized for the purpose of extracting and learning the features which are deeply implanted in the information. The result obtained from Deep-LSTM [9] network depends upon the state of such cells and this feature facilitates the system for the function of detection, since instead of last input such method needs the historical context of inputs. The effective principle is based on the memory cells and these cells convey many subunits with various objectives. Figure 2 denotes the structure of Deep LSTM.
Structure of deep long short term memory (Deep LSTM).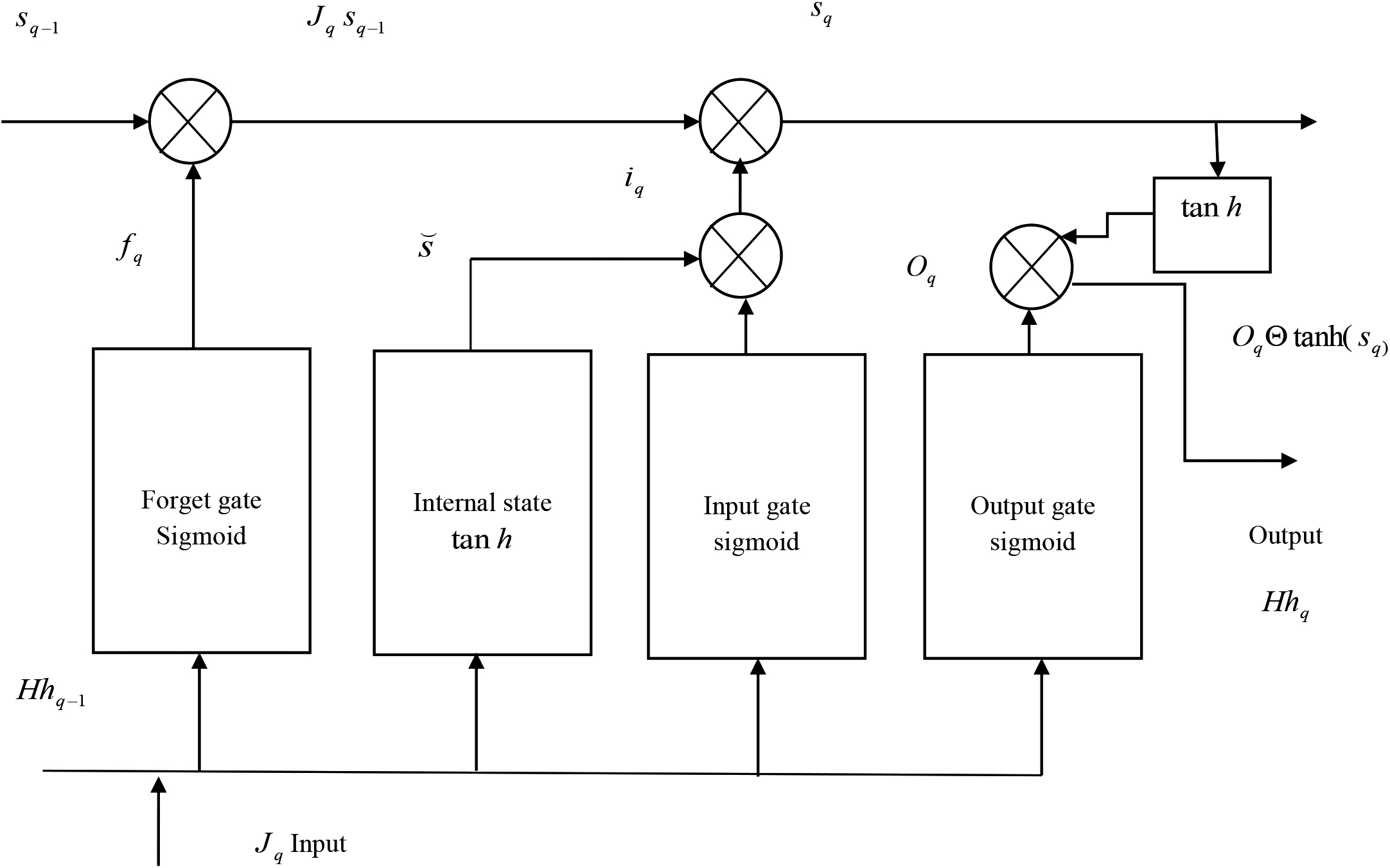
The input node
The input gate
The internal state
The forget state
The output gates perform the process, which is expressed as,
The final result of the memory cell is represented as,
The Adam AO is derived by the combination of Adam Optimization [23], and Adadelta Optimization, which is employed to train the network classifier Deep-LSTM [9] in order to achieve the optimum solution and effectively detect the fake news over social media. Adam only needs first-order gradients with less memory obligated. From the estimation of 1 and 2 moments of the gradients the individual adaptive learning rates for various constraints are formulated by this model. The name Adam is obtained from the estimation of adaptive moment. The benefits of Adam optimization are that the magnitudes of parameters are unchanged and its step sizes are roughly bounded by stepsize hyper-parameter and it does not need any immobile purpose. Moreover, it works well with sparse gradients and it generally executes a pattern of step size annealing. Adadelta optimization is a gradient descent stochastic technique that supports adaptive learning rate per region of space to address two issues. i) Continuous decay of learning rates during training; and ii) the requirement for a physically selected global learning rate. Manual tuning of a learning rate is not needed in this technique, which also would seem to be robust to various architectural model choices, data modalities, noisy gradient details, and hyper parameter estimation.
Step 1: Initialization
To initialize the parameter of the optimization, such as
Step 2: Determine fitness
It is utilized to estimate the false information effectively from the social media platform using the optimal function and it is expressed as,
where
Step 3: Determine the moment vector
Let us initialize the first and second moment vector as
Step 4: Compute bias-corrected moment vector
Let Gg be the gradient of the stochastic objective
The first moment determination is expressed as,
The second moment determination is,
Step 5: Update parameters
In Rider Deep LSTM, the update solution is derived by integrating Rider optimization algorithm with the Adam Optimization [30]. According to the Rider Deep LSTM, the parameter update solution of algorithm is derived by hybridizing Adam optimization [23] with AO [29] and it is derived as,
From Rider Deep LSTM,
Step 6: Termination
The process is repeated until the optimal solution is attained.
Algorithm 1 views the pseudo code of Adam AO with Deep-LSTM classifier.
This segment elucidates the result and discussion of Adam AO based Deep LSTM with the evaluation metrics.
Experimental setup
The execution of the suggested technique is performed in PYTHON. The performance of Adam AO based Deep LSTM is investigated by relating to the accuracy, sensitivity, and specificity. The database utilized in the proposed method are FakeNewsNet database (Dataset #1) [10], and BuzzFeedNews database (Dataset #2) [27].
BuzzFeedNews database: BuzzFeedNews database is a collection of datasets from Facebook posts and it consists of text, videos, photos, and links but for this research work we consider only the text data. Some of the contents are mostly true and some of them are mixture of true and false content.
FakeNewsNet database: FakeNewsNet database is similar to the above said database, which consists of gossips and fake mews about political events and so on.
Table 1 lists the abbreviations used in this paper and their definitions.
List of abbreviations
List of abbreviations
This division calculates the performance of suggested model with the evaluation metric using Dataset #1, and Dataset #2.
Table 2 represents the confusion matrix for Dataset #1.The accuracy of the proposed method with feature size
Confusion matrix for Dataset #1
Confusion matrix for Dataset #1
Table 3 demonstrates the confusion matrix for Dataset #2. For 90% data, the accuracy attained by the suggested scheme for feature size
Confusion Matrix for Dataset #2
The efficiency development of the Adam AO based Deep LSTM is analyzed and compared with the existing methods, such as GNN [2], Deep Unified Attention Model with Latent Relation Representations (DUAL) [32], and Deep Fake [4].
Comparative discussion
Comparative analysis using Dataset #1.
Comparative analysis using Dataset #2.
GNN: Here, a propagation based technique is used for fake news detection, which utilizes GNN to differentiate the propagation patterns of real news and fake news over social networks.
DUAL: Here, a DUAL model is used for detecting fake news. This method integrates two scopes of features for detection and concurrently discovers the hidden representation of these two features.
Deep Fake: Here, the content of the news article and the presence of echo chambers in the social network are considered for fake news detection. A tensor representing social context is formed by integrating the user, news, and community information. The news content is amalgamated with the tensor, and coupled matrix-tensor factorization is engaged for obtaining a representation of both social context and news content.
In Fig. 3, the comparative analysis of suggested scheme by considering the Dataset #1 is shown. The accuracy of the proposed method is 0.924, where the existing GCAN is 0.822, DUAL is 0.839, and Deep Fake is 0.848 for the training data 90%. The sensitivity of the proposed method is 0.939 that results the efficiency improvement of developed scheme with GNN, DUAL, and Deep Fake, is 8.68%, 7.931%, and 6.463% for the training data
In Fig. 4, the comparative analysis of Adam AO based Deep LSTM using Dataset #2 is represented. The accuracy of the proposed method is 0.936 that results the efficiency improvement of extended scheme with GNN is 12.049%, DUAL is 10.646%, and Deep Fake is 9.399% for the training data 90%.The sensitivity of the devised method is 0.942, whereas 0.877 for GCAN, 0.885 for DUAL, and 0.899 for Deep Fake for the training data 90%. If the training data
Table 4 signifies the comparative discussion of Adam AO based Deep LSTM based on the best performance. From the analysis, the Adam AO based Deep LSTM achieved maximum accuracy, sensitivity, specificity of 93.55%, 94.19%, and 92.46% for Dataset #2.
Fake news is purposely spread by the bad writers who manipulate the original content of the news. In this research, an Adam AO based Deep LSTM is devised to identify the fake information in social media by considering the assessment data. Here, tokenization is performed using BERT technique and the features are removed. The measurement of the feature is decreased using Kernel LDA, and SVD, where the fusion of the feature is carried out using Renyi joint entropy. Once the top-N features are selected, the fake news detection is performed by means of Deep LSTM and the training of the network classifier is completed by using Adam AO based Deep LSTM. The Adam AO based Deep LSTM achieved maximum accuracy, sensitivity, specificity of 0.935512, 0.941913, and 0.924554. To improve the accuracy of detection process using other novel optimization algorithm with different classifier and explore in all type of news like image and videos will be the future work.
Footnotes
Author’s Bios