
Abstract
Conventional recommendation techniques utilize various methods to compute the similarity among products and customers in order to identify the customer preferences. However, such conventional similarity computation techniques may produce incomplete information influenced by similarity measures in customers’ preferences, which leads to poor accuracy on recommendation. Hence, this paper introduced the novel and effective recommendation technique, namely Deep Embedded Clustering with matrix factorization (DEC with matrix factorization) for the collaborative recommendation. This approach creates the agglomerative matrix for the recommendation using the review data. The customer series matrix, customer series binary matrix, product series matrix, and product series binary matrix make up the agglomerative matrix. The product grouping is carried out to group the similar products using DEC for retrieving the optimal product. Moreover, the bi-level matching generates the best group customer sequence in which the relevant customers are retrieved using tversky index and angular distance. Also, the final product suggestion is made using matrix factorization, with the goal of recommending to clients the product with the highest rating. Also, according to the experimental results, the developed DEC with the matrix factorization approach produced better results with respect to f-measure values of 0.902, precision values of 0.896, and recall values of 0.908, respectively.
Keywords
Introduction
RS has been introduced along with the web for recommending the products to the users. Initially, the RS relies on content-based technique, demographic-based technique and collaborative filtering-based technique. Nowadays, the RS was constructed based on social information. Results are decided using a collaborative recommendation system based on product similarity. Moreover, the effectiveness of collaborative recommendation can be further improved on the basis of local as well as personal information from internet of things. In addition, the RS utilizes various resource of information for making the users with predictions as well as recommendation of products. Moreover, the RS aims to balance the factors, such as stability, novelty, disparity as well as accuracy [10]. Most of the familiar commercial websites use RS for assisting their customers and their respective products. The RS considers the information regarding the recommended products as well as customers for finding the most appropriate products from the available products [11]. Generally, the RS states that the people suggest the recommendation as input, and then the system aggregates and provides the product regarding the requested recommendation to the recipient. RS suggests the product to the customer for purchasing based on the user preference. Moreover, various techniques have been introduced for RS, like knowledge-based, content-based, collaborative-based and so on. These conventional techniques are not effective all time due to the poor design. In such situations, the hybrid recommender provides a better solution for this issue [12].
One of the well-known methods used in RS is CF. In the CF family of algorithms, there are numerous ways to locate comparable users or things, as well as numerous ways to determine ratings based on the ratings of comparable users. It is a system of recommendations that makes predictions about a user’s future behaviour. However, CF technique has the CCS issue and ICS issue. Here, the CCS issue is produced due to the inexistence of rating records, whereas the ICS issue occurs due to the existence of small number of record rating of new product. The RS utilized the huge amount of information based on the user searching activities in the past and it identifies the item based on the user requirement. Moreover, the collaborative RS did not utilize the content information of products for making recommendation. In addition, the RS relies on the relationship among users as well as products, which are generally encoded in a rating feedback matrix with each element indicating a specific user rating on a particular item [13]. CF is the more appropriate and broadly employed recommender systems in which the CF model aims to systematize the process of ‘word-of-mouth’ in which people suggest products to one another. Moreover, the CF scheme utilized the past information of each user for recommending the products to the neighbourhood people who require similar products. In addition, the CF approach estimates the requirement of new items by investigating the neighbourhood people [14].
CF approaches are often divided into two kinds, including memory-based technique and model-based methodology. Based on how well a product is rated, memory-based techniques are used to determine user preferences. Moreover, the memory-based method uses locality-sensitive hashing, which periodically employs the nearest neighbouring approach. On the other hand, model-based approaches are employed to extract the data, and then the machine learning techniques are utilized to identify the pattern using training data. Some of the familiar model-based techniques involve Bayesian methods [16], clustering methods [17], and latent semantic models [18], like probabilistic latent semantic assessment [15] and Singular Value Decomposition. In [19], RBM-based CF algorithm was developed for recommendation. In [20], the hybrid recommendation algorithm was devised by extending the RBM-based techniques with better performance. In [21], a Deep Convolutional Neural Network was employed to identify the latent factors from music audio. In [22], a revised autoencoder scheme was introduced for CF in order to make recommendation. Moreover, the effectiveness of recommendation can be enhanced by including collaborative filtering based on the decomposition of MF strategy. MF strategy utilizes the user’s and product’s latent features, such that the inner multiplication of user and item latent features are equivalent to the user’s rating on that product [23].
This research aims to design and develop the DEC with matrix factorization for performing the collaborative recommendation. The review data is considered as an input for recommendation process, which contains the product ID and the customer ID. Initially, the agglomerative matrix is generated based on the review data. After the generation of agglomerative matrix, product grouping is done using DEC, which provided the grouped product by combining the similar products. The series of best customers is then generated by doing a bilevel matching between the query and the product group using the Tversky index and angular distance. After that, the relevant customers are retrieved from the sequence of best customers, such that the customer preferred product is retrieved. At last, the final recommendation is done using matrix factorization based on the product with maximum rating, and then it is recommended to the customers.
The major contribution of this research are given by,
The other sections of the research paper are as follows: Section 2 describes the various existing techniques based on recommendation techniques, Section 3 illustrates the developed DEC with matrix factorization model, Section 4 illustrates the results of the experiments, and Section 5 illustrates the conclusion.
There are eight traditional user rating prediction approaches for collaborative recommendation, each with advantages and disadvantages stated. Zhang et al. [1] modelled the DeRec approach for performing the recommendation based on weight loss function. Here, the recommendation was done mainly based on the list of user-item rating. Moreover, this method was attained the optimal accuracy along with minimal computational complexity. However, the memory consumption of this method was high. In order to resolve this, Chen et al. [2] modelled the DDCF method for performing collaborative recommendation. Here, the recommendation system was operated on the basis of user preferences with respect to the dynamic time decay. Moreover, the developed method vigorously utilized the decay functions depending on the behaviour of users. Yet this approach overlooked different datasets. Guo et al. extended .’s degree classification criterion technique for recommendation via collaborative filtering was created in order to make use of different datasets. Here, the sigmoid function was used to determine how closely connected items and pairs of items are to one another. Moreover, this method was employed to resolve the trade-off among accuracy as well as effectiveness of items based on collaborative filtering. However, the developed method did not utilize decision support systems for enhancing the experience of user and productivity of website companies. For increasing the experience and productivity of such companies, Jain et al. [4] modelled the EMUCF algorithm for performing recommendation based on non-linear similarity. Here, the Bhat-sim was used to determine the similarity and the similarities between the users were calculated using the Bhattacharyya coefficient. While the developed method achieved great accuracy, it was challenging to handle the numerous components that grew in size with time. For enhancing the performance with various items, Alhijawi and Kilani [5] designed the Genetic-based recommender system for performing the collaborative recommendation using genetic algorithm. The RS was carried out using two functions in which the first function was employed to utilize the semantic information for estimating the similarity among items, whereas the second function was employed to estimate the similarity among users. Moreover, the developed method has the ability to make more accurate predictions. However, the developed method did not able to handle a small as well as medium sized datasets. In order to resolve the issues of using datasets, Panda et al. [6] devised the Normalization-based collaborative filtering recommender system for performing recommendation. This method had two steps for performing recommendation such that the first step was able to perform the prediction of user ratings, and then the second step was carried out to perform the recommendation. Using a maximum confidence interval, the suggested approach achieved greater accuracy in this case. Yet, it was unable to add new users or goods to the rating matrix. For attaining the effective user rating and product matrix, Chen et al. [7] modelled the Collaborative filtering recommendation algorithm for performing collaborative recommendation with respect to the user correlation as well as evolutionary clustering. Although, the developed method handled the huge volume of data, this method did not include some other effective information of network for further enhancing the performance. For improving the system performance, Li and Han [8] modelled the hybrid collaborative filtering technique for performing the collaborative recommendation. Here, the hybrid collaborating recommendation scheme was attained by integrating collaborative filtering as well as content-based filtering approach. Also, the system that was devised was able to handle vast amounts of information with higher stability. Nevertheless, in order to improve performance, the devised approach was unable to handle the factorization machine.
Proposed DEC with matrix factorization for collaborative recommendation
The main goal of this study is to create a new DEC model with matrix factorization for collaborative recommendation utilising a dataset of Netflix movie recommendations. In order to create the matrix based on customer preferences, the review data is initially given to the agglomerative matrix development phase. The produced matrix is then put through the process of product grouping using DEC [25], where comparable groupings are clustered into one group and dissimilar groups are clustered into one group. Using group-product bilevel matching between the query and item group utilising the Tversky index and angular distance, the best product group from the entire product group is then selected. Following the selection of the best product group, the user query is matched with the best product group according to the Tversky index and angular distance in order to retrieve the customer’s favourite product. Additionally, matrix factorization is used to carry out the final recommendation in order to find the product with the highest rating. Figure 1 shows the schematic illustration of developed DEC with matrix factorization for collaborative recommendation.
Block diagram of proposed method for predicting user ratings based on collaborative recommendation.
The review data from Netflix dataset contains set of customer ID and product ID. Let us consider the customer
where,
The gathered data from the dataset is transformed into the matrix format for making the recommendation scheme as effective. The customer series matrix, the customer series binary matrix, the product series matrix, and the product series binary matrix are all computed during this stage.
Customer series matrix
The review data acquired from the dataset is utilized to generate the customer series matrix
where,
After constructing the customer series matrix
Here, ‘1’ represents the product searched by the customer and ‘0’ indicates the product not searched by the customer.
The review data
where,
Once the product series matrix is formed, then the product series binary matrix
Here, ‘1’ represents the customer searched product, and ‘0’ indicates the customer not searched product.
Deep neural networks are used by DEC to simultaneously learn feature representations and cluster assignments. In order to iteratively optimise a clustering objective, it learns a mapping from the data space to a lower-dimensional feature space. In this work, the product grouping is carried out by the DEC algorithm [25] for finding the best product groups. Here, the input of DEC is
Clustering with KL convergence
By selecting an initial approximation of cluster centroids
where,
Additionally, the computation
where,
To gather together related products into a single group, products are grouped. Let us consider the group attained by the DFC is represented as,
where,
The group-product bilevel matching is carried out using Tversky index and angular distance in order to select the optimal product from the grouped product
Query
The matrix form of number of queries is illustrated as,
where,
The mathematical sequence of number of queries are converted into binary form, and the binary series of query is termed as,
where,
where,
Thus, the group product bilevel matching is obtained by combining the angular distance and Tversky index, and it is mathematically expressed as,
where,
To choose the best group user series in binary format after obtaining the ideal group, the pertinent customer retrieval phase is executed. Binary best group is used to identify the customer ID, and the best product is chosen depending on the consumers. The consumer who is in the best groups searches the product lists here. Thus, the relevant customer retrieval series is indicated as
where,
Binary best group
After that, the binary best group is obtained by transforming the series of best user group into the binary form, and is portrayed as,
where,
After the retrieval of relevant customer, the matching among relevant customer
Moreover, the angular distance among relevant customer
Thus, the group product matching is achieved by adding the angular distance and Tversky index, and it is mathematically expressed as,
where,
where,
The matrix factorization [24] is an effective approach, which has implicit feedback. Here, the user information is not directly provided by the user where it has been collected by analysing the past behaviour of user about the product through the user-item interaction matrix. This technique is more effective to predict the user rating of any product. The user rating matrix is calculated by multiplying the two matrices, such as
where,
From the user preferred items, the items having highest rating will be recommended, which can be denoted as
Based on the highest possible customer rating, the user-preferred product is chosen in the final recommendation process. In this instance, the product that received the highest rating from the consumer is recommended in the final recommendation stage. Algorithm 1 depicts the pseudo-code for the aforementioned procedure.
Results and discussion
The findings and analysis of the developed DEC with matrix factorization technique based on evaluation metrics are described in this part.
Experimental setup
Using a Python tool, Windows 10 OS, and an Intel i3 core CPU, the experimentation of the created DEC matrix factorization approach is performed.
Dataset description
The dataset employed for the developed technique is Netflix-movie recommendation Dataset [9]. The reviews that were used in this case were obtained directly from Netflix. The collection also includes 4 text data files, each of which has more than 20M rows, or more than 4K movies and 400K users. Consequently, the Netflix-movie recommendation dataset currently has 17K movies and 500K
Performance metrics
Performance indicators like F-measure, precision, and recall are used to analyse the effectiveness of the developed DEC with the matrix factorization approach.
(i) F-measure
It is a measurement that determines the recall and precision weighted harmonic means.
where,
(ii) Precision
It is a measure that is calculated by adding the true positive ratio and the false positive ratio together.
where,
(iii) Recall
Recall value refers to the proportion of TPR, and the summation of true positive and FNR.
where,
By altering the amount of queries with different iterations depending on evaluation metrics and using the Netflix-movie recommendation dataset, the performance of the constructed DEC
Performance assessment based on queries
Figure 2 displays the performance evaluation of the created approach using various queries and iterations. The performance evaluation of the developed technique with respect to the f-measure value is shown in Fig. 2a. When the number of the query is 2, the created DEC
Performance assessment of developed technique by adjusting the queries.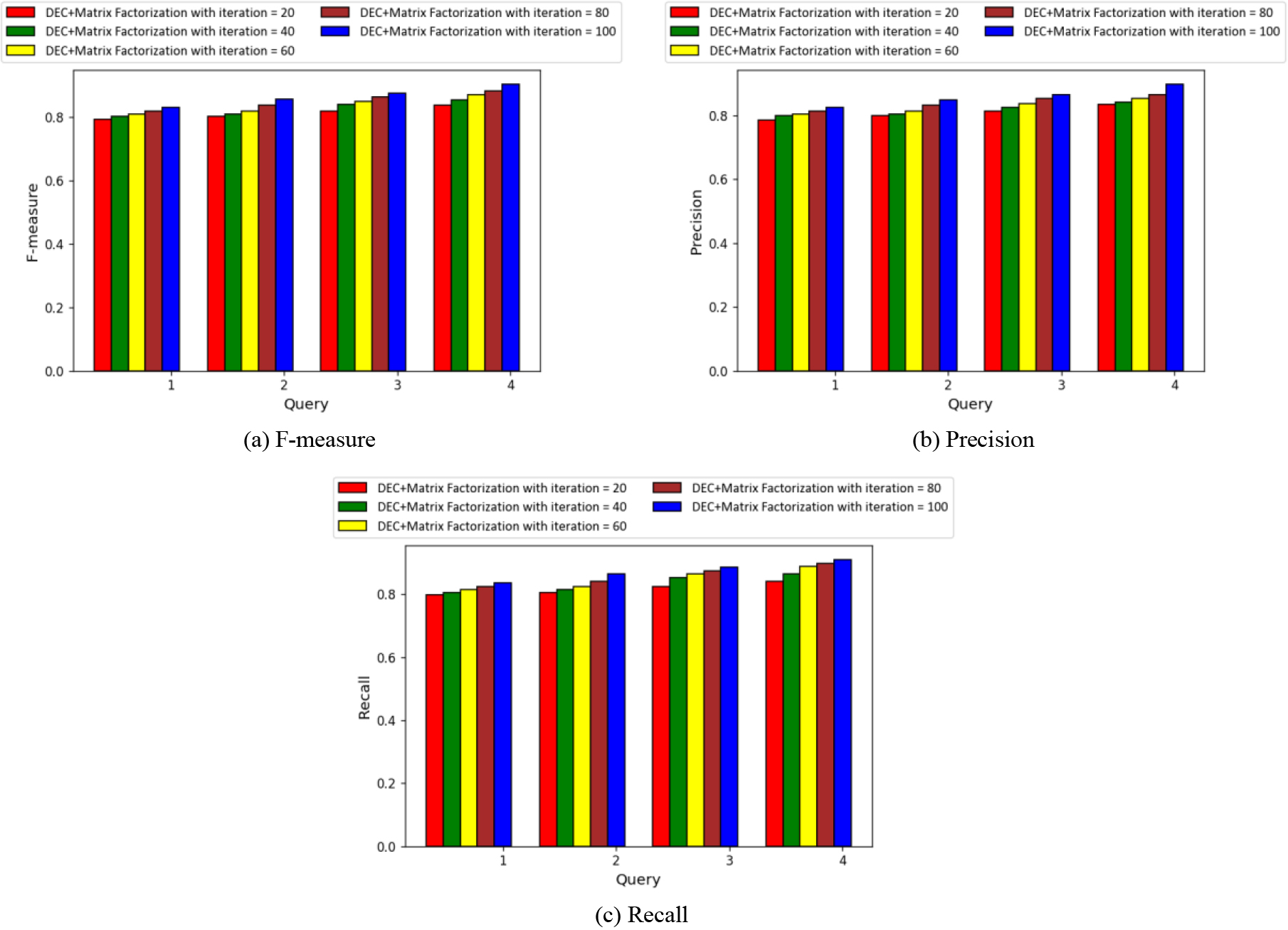
The comparative assessment is done by the inclusion of various existing techniques along with the proposed DEC
Comparative techniques
The effectiveness of developed technique is investigated by comparing the developed DEC
Comparative assessment of developed technique by adjusting the query using cluster size 3.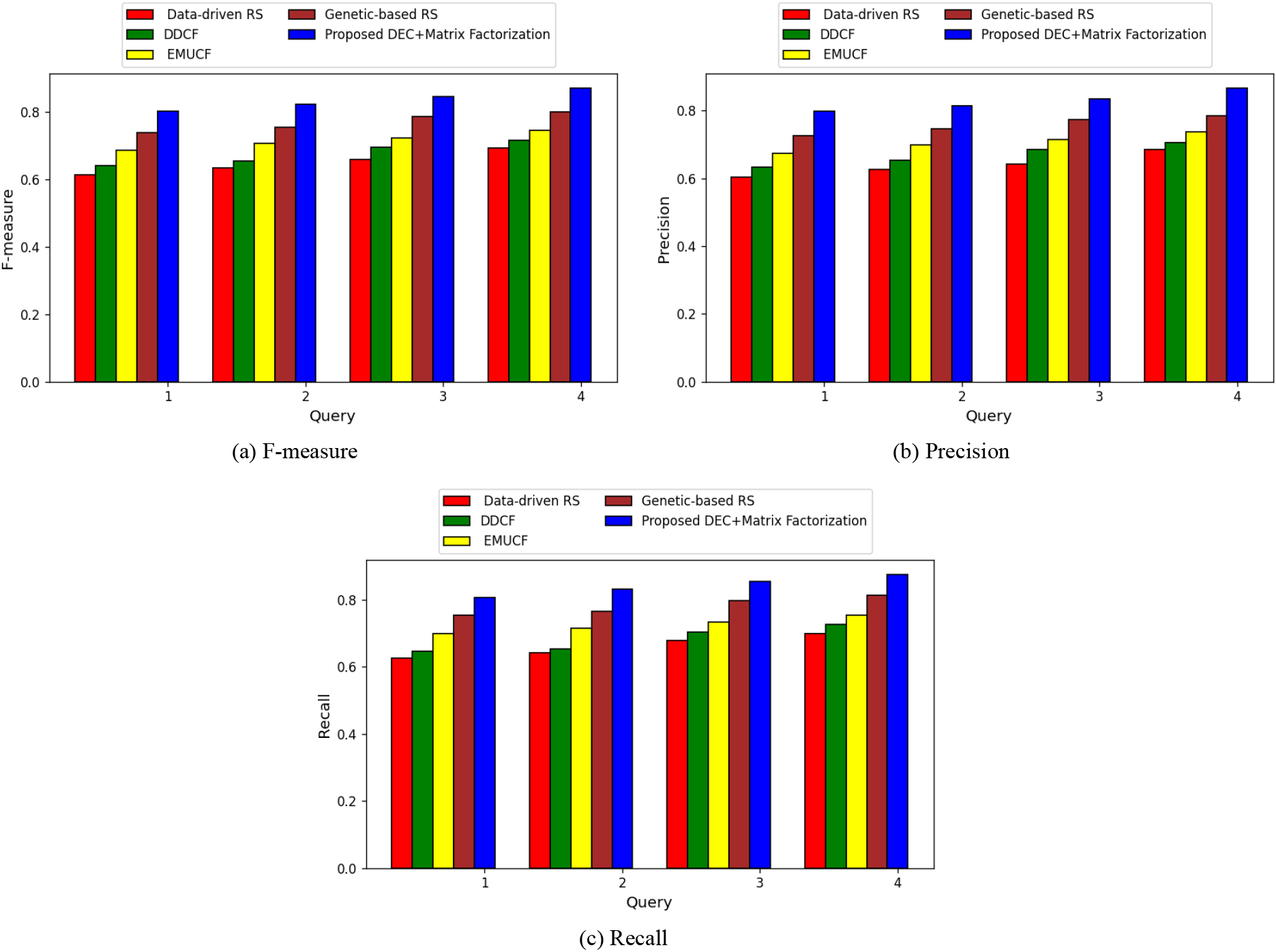
The comparative evaluation of the developed technique with regard to performance criteria utilising cluster size 3 is explained in Fig. 3. The comparative evaluation of created technique based on f-measure value is shown in Fig. 3a. When the number of queries is 1, the newly created method yielded an f-measure value of 0.768, while the corresponding values for the data-driven RS, DDCF, EMUCF, and Genetic-based RS were 0.613, 0.639, 0.686, and 0.739, respectively, for the current methodologies. The comparative evaluation of created technique with respect to precision value is shown in Fig. 3b. The created technique in this case acquired a precision value of 0.814 for the query of 4, while current techniques like data-driven RS, DDCF, EMUCF, and genetic-based RS attained f-measure values of 0.685, 0.704, 0.736, and 0.785 for the same query. The comparison of created approach evaluations based on recall value is shown in Fig. 3c. When there are three queries, the created and existing approaches each achieved recall values of 0.678, 0.704, 0.732, 0.798, and 0.814, respectively.
Comparative assessment using cluster size 4
Figure 4 explains the comparison of developed techniques employing cluster size 4 with regard to performance parameters. Figure 4a shows a comparison of developed techniques based on F-measure value. In this case, the created technique yielded an f-measure value of 0.875 for the number of queries of 3, while the existing techniques, such as data-driven RS, DDCF, EMUCF, and genetic-based RS, yielded f-measure values of 0.679, 0.716, 0.754, and 0.791 for the same number of queries. The comparison of produced approach evaluations based on accuracy value is shown in Fig. 4b. The created method acquired the recall value of 0.847 for the number of question is 2, while the current strategies achieved the recall values of 0.648, 0.665, 0.705, and 0.754. The comparative evaluation of proposed technique based on recall value is demonstrated in Fig. 4c. When there are 4 queries, the created method has a recall value of 0.908, compared to the recall values of 0.725 for the data-driven RS, 0.785 for the DDCF, 0.801 for the EMUCF, and 0.836 for the genetic-based RS attained by the existing methodologies.
Comparative assessment of developed technique by adjusting the query using cluster size 4.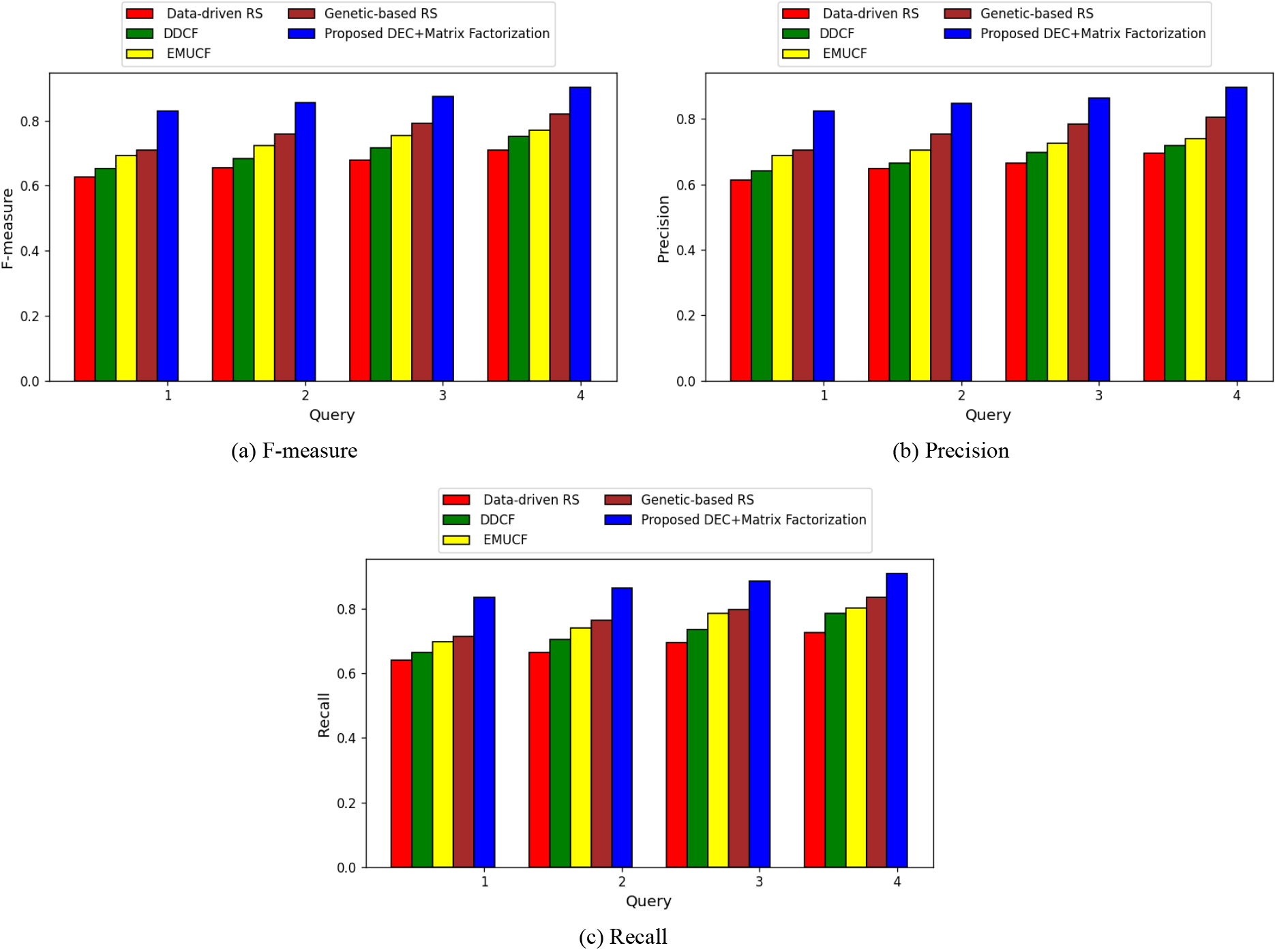
The developed DEC
Comparative discussion
Comparative discussion
This paper presents the developed DEC
Footnotes
Abbreviations
Author’s Bios