
Abstract
During the past few decades, melanoma has grown increasingly prevalent, and timely identification is crucial for lowering the mortality rates linked to this kind of skin cancer. Because of this, having access to an automated, trustworthy system that can identify the existence of melanoma may be very helpful in the field of medical diagnostics. Because of this, we have introduced a revolutionary, five-stage method for detecting skin cancer. The input images are processed utilizing histogram equalization as well as Gaussian filtering techniques during the initial pre-processing stage. An Improved Balanced Iterative Reducing as well as Clustering utilizing Hierarchies (I-BIRCH) is proposed to provide better image segmentation by efficiently allotting the labels to the pixels. From those segmented images, features such as Improved Local Vector Pattern, local ternary pattern, and Grey level co-occurrence matrix as well as the local gradient patterns will be retrieved in the third stage. We proposed an Arithmetic Operated Honey Badger Algorithm (AOHBA) to choose the best features from the retrieved characteristics, which lowered the computational expense as well as training time. In order to demonstrate the effectiveness of our proposed skin cancer detection strategy, the categorization is done using an improved Deep Belief Network (DBN) with respect to those chosen features. The performance assessment findings are then matched with existing methodologies.
Keywords
Introduction
Melanoma, a kind of skin cancer, has gotten more deadly globally in past years. Amongst malignancies, skin cancer is by far the most lethal because it can arise from non-pigmented cells anyplace throughout the body [1, 2, 3, 4, 5]. The epidermis, the topmost covering of the skin, encompasses four kinds of cells: squamous, basal, as well as melanocytes. These basal cells make up the bottommost layer of the epidermis, whereas the squamous cells make up the topmost layer. Melanocytes utilize a pigment designated as melanin to safeguard the deepest layers of the skin. The skin’s melanocytes might alter or grow markings for a multitude of reasons, including infections, allergies, and sun exposure. Skin cancer might appear as any new, larger, altering, blistering, bleeding lumps, patches, or moles. More often than not, excessive sun exposure leads to skin darkening [6, 7, 8, 9, 10, 11]. The triggered effects of DNA mutations have an influence on such skin cells’ proliferation over time when they are subjected to intense UV radiation. Because not all changes to their skin, such as moles, acne, blemishes, as well as other markings, are malignant, it’s indeed tough to identify cancerous cells directly. The 3 varieties of skin cancer are often linked to squamous cells, basal cells, as well as melanocytes,
Melanoma was frequently formed by the melanocytes when they have been categorized inappropriately [12, 13, 14, 15, 16, 17]. Melanomas are also to blame for three-fourths of all estimated skin cancer-linked fatalities every year. Between benign as well as malignant melanoma kinds, the malignant seems to be more threatening. The early recognition of malignant melanoma is therefore crucial. Melanoma is not an exception, since it may harm anyone at any time. Melanoma’s tendency to expand quickly to blood arteries and lymphatic vessels is its main danger [18, 19, 20, 21]. The observation seems frequently favored for skin cancer identification. Realizing that skin cancer might impact so many persons globally, of all ages and levels. Every individual should conduct a self-examination of their complete skin surface monthly once, according to the Skin Cancer Foundation as well as the American Cancer Society [22]. Dermoscopy, also known as dermatoscopy or epiluminescence microscopy, is a common noninvasive screening procedure utilized to assess skin lesions. The preponderance of dermatologists has used this dermoscopy to boost the accuracy of melanoma diagnosis. Furthermore, dermoscopy has an identification accuracy of about 75%. Additionally, even an expert dermatologist could make a mistake during the diagnosing procedure since many distinct forms of skin cancer can have similar initial manifestations. A computerized-oriented diagnosis, as well as an assessment approach, is therefore required [23, 24]. A computerized approach provided to the dermatologist comprises processing stages such as boundary recognition, feature retrieval, as well as categorization with the help of CAD systems. The precise automatic identification of melanoma utilizing a computer-based melanoma identification model remains a tricky job. The deep learning technique may be utilized as a way of enhancing categorization accuracy. Because of this, we have created a deep learning-based skin cancer identification strategy to get an effective and accurate classification. This proposed work has the following contributions
An Improved Balanced Iterative Reducing as well as Clustering utilizing Hierarchies (I-BIRCH) is proposed in this work to provide an effective image segmentation. Along with the conventional local ternary pattern, Grey level co-occurrence matrix as well as the local gradient patterns features, we have proposed Improved Local Vector pattern features to provide better feature extraction. This work develops a unique strategy known as the “Arithmetic Operated Honey Badger Algorithm” (AOHBA), which speeds up computation by choosing the optimal features. We presented an Improved Deep Belief Network to obtain an accurate categorization.
The following format is used to organize the structure of this paper: Section 2 contains a concise overview of late available literature on skin cancer identification. Section 3 offers a synopsis of the proposed work. Section 4 covers the proposed work’s implementation findings; Section 5 offers the work’s conclusion, whereas the next section holds the work’s references.
A comprehensive summary of some recent articles on melanoma diagnosis has been provided below.
In order to autonomously diagnose skin cancer, Saba et al. [25] 2019 suggested a novel strategy centered on deep convolutional neural networks (DCNN). This suggested cascaded design included three key elements: (a) HSV color conversion as well as fast local Laplacian filtration (FlLpF) for contrast amplification; and (b) color CNN and XOR function for retrieval of the lesions’ boundaries, (c) regarding feature fusing, the hamming distance (HD) methodology has been used, and also the Inception V3 architecture was utilized to retrieve the in-depth characteristics. They too have developed a technique for choosing the most discriminating characteristics called entropy-regulated feature selection. This suggested work outperformed the already accomplished works in regard to categorization accuracy.
Balaji et al. [26] presented an optimal neural as well as fuzzy technique for diagnosing skin cancer in 2020. The cancer area was discovered in the presented research using fuzzy c-means segmentation. The neural network got trained to utilize the Firefly optimization’s dominating characteristic. The classifier’s error rate had been reduced as a result of this prominent feature. Its simulation findings indicated that the presented work was superior in regard to assessment criteria such as “accuracy, specificity, as well as sensitivity.”
Thanh et al. [27] established a unique strategy for identifying melanoma skin cancer utilizing autonomous image processing approaches in 2020. This recommended research was performed in three stages: image pre-processing depending on a primary curve, color normalization to separate skin lesions, then ABCD rule-dependent retrieval of features. The authors then demonstrated the relevance of the presented effort in regard to the accuracy of the ISIC database utilizing experimental outcomes.
Murugan et al. [28] used a watershed segmentation strategy for segregating the acquired skin photos in 2019. The characteristics in the format of shape, ABCD constraint, and GLCM were then retrieved from these same segmented images. These characteristics were then categorized using the k Nearest Neighbor, Random Forest, as well as SVM (Support Vector Machine). As a consequence, the scientists discovered that the SVM model outperformed the others in detecting skin cancer.
In 2020, Kumar et al. [29] presented a more effective strategy for earlier diagnosis of the 3 categories of skin cancer. The obtained skin lesion photos were first segmented utilizing fuzzy C-means clustering. The image qualities of the selected image were then strengthened by pre-processing it through the distinct filters. This pre-processed image was then taken to retrieve the RGB color space, Local Binary Pattern (LBP), including GLCM features. An artificial neural network (ANN) was formed utilizing the differential evolution (DE) strategy to distinguish between malignant as well as non-cancerous skin. In regards to excellent accuracy, the simulated consequence demonstrated the efficacy of the suggested DE-ANN work.
In 2019, Sreelatha et al. [30] established the Gradient as well as Feature Adaptive Contour (GFAC) paradigm for earlier-stage melanoma disease identification. This identification was then conducted quickly utilizing noise removal and also the suggested image segmentation methodology. Furthermore, they utilized Multiple Gaussian distributed topologies for effective feature retrieval. The suggested way was evaluated with the PH2 dataset, as well as the findings revealed lesser errors.
In 2020, Thurnhofer-Hemsi and Dominguez [31] developed a deep-learning methodology for skin cancer diagnosis. The authors used a learning algorithm to create hierarchical yet simple classifiers utilizing CNNs. When evaluated utilizing the HAM10000 dataset, the outcomes show that the suggested approach is efficient.
In 2020, Chaturvedi et al. [32] published a computer-aided diagnostic approach for exact multi-class skin (MCS) cancer categorization 2020. This developed system was evaluated utilizing the HAM10000 dataset, as well as the findings showed that it outperformed five pre-trained CNNs.
Current skin cancer identification strategies, whether handmade or deep-learning-based, struggle with two significant issues: (a) excessive computational cost as well as (b) model overfitting. For that reason, we need a novel method to provide better performance in the task of skin cancer identification.
Methodology
Skin cancer is among the worst kinds of cancer. Unfixed deoxyribonucleic acid (DNA) within skin cells creates genetic flaws or abnormalities on the skin that leads to skin cancer. Because skin cancer spreads progressively to other regions of the body, it is more treatable in the early stages, which is why it is best identified early. The rising number of skin cancer occurrences, fatality rate, and high cost of healthcare treatment need early detection of its signs. Given the importance of these concerns, we have created a 5-stage skin cancer identification methodology. The input image is first pre-processed via strategies like Gaussian filtering as well as histogram equalization. Those pre-processed images are subjected to segmentation, where an improved BIRCH is utilized to provide better image segmentation by efficiently assigning the labels to the pixels. The features such as Improved Local Vector Pattern, local ternary pattern, Grey level co-occurrence matrix as well as local gradient patterns were retrieved from those segmented images. For feature selection, we have proposed a hybrid optimization named the Arithmetic Operated Honey Badger Algorithm (AOHBA), which provides an optimal feature selection by merging the functions of both Honey Badger and Arithmetic Optimization Algorithms. In the final classification phase, the images get classified based on those selected optimal features, by the utilization of improved DBN. The architecture diagram of our proposed AOHBA-based skin cancer detection is given the Fig. 1.
Architecture of the proposed AOHBO-based skin cancer detection.
Preprocessing seems to be the first stage necessary to prepare image data for system input and the input image gets denoted as W. The pre-processing decreases network training time as well as speeds up model assessment. In our work, we used two image preprocessing techniques, which are the Gaussian filtering technique, and histogram equalization.
Gaussian filtering
A low pass filter termed a Gaussian filter has been employed to blur certain areas of an image and reduce noise. To receive the intended result, the filter is constructed as an even-sized symmetric kernel and is applied to every pixel inside the Region of Interest. The kernel isn’t really resistant to significant color changes since its central pixels contribute more to the ultimate value than its outermost pixels. An approximate representation of the Gaussian Function is indeed a Gaussian filter [33].
When applying a Gaussian filter to an image, the size of the kernel or matrix that will be utilized to demean the image would be first determined. Since the sizes are often odd numbers, it is possible to estimate the total outcomes on the central pixel. The Kernels also retain the identical count of rows as well as columns since they are symmetric. The Gaussian equation, which computes the integers within the kernel, is just as follows:
Where
A quantitative method to increase the histogram’s dynamic range has been called histogram equalization. The histogram can occasionally have a narrow range of values; equalization increases the histogram’s range. This exact method is used in digital image processing to boost an image’s contrast. In order to maintain the edges in diverse sections of the image, we employed adaptive histogram equalization in our work. This Adaptive Histogram Equalization is different from typical histogram equalization in that the adaptive technique raises local contrast. The image is divided into different blocks, and every section’s histogram equalization gets computed [34]. As a result, AHE generates several histograms, each of which represents a different portion of the image. It improves the local contrast as well as edge outlines in all clearly defined areas of the image. The pre-processed images obtained from this stage are denoted as
Segmentation
Those pre-processed images get segmented in the second stage. An unsupervised data analysis approach called BIRCH (balanced iterative reduction as well as clustering utilizing hierarchies) is being utilized to accomplish the segmentation process in our work. Experiments have demonstrated the algorithm’s linear scalability with respect to the number of objects and the high quality of the data clustering. BIRCH’s capability to dynamically and progressively cluster incoming multi-dimensional metric data points in an effort to provide the best possible clustering for a certain group of resources is one of its advantages.
The capacity of BIRCH to continuously and progressively cluster entering multi-dimensional measurement data points in an effort to achieve the best possible grouping for a specific collection of resources is one of its advantages. BIRCH typically only needs to scan the database once. A collection of N data points that are expressed as real-valued vectors together with the required quantity of clusters K are provided as input for the BIRCH algorithm. There are four steps to its operation, the second of which would be optional.
The data points are utilized in the initial step to create a height-balanced tree information architecture called a clustering feature (CF) tree, which is described as follows:
The clustering characteristic CF of a collection of N d-dimensional information points has been described as the triple
The branching factor B as well as threshold T of a CF tree, and a height-balanced tree having two attributes, are being utilized to organize the clustering characteristics. A non-leaf node may have up to B entries of the type [CF
The average linkage distance among clusters
In our Improved BIRCH, instead of using Eq. (6), we have used the following Eq. (7) to find the Average Linkage distance between clusters.
Where
Those segmented images get symbolized by
Segmented images were subjected to the feature extraction stage. As a specific kind of dimension reduction, feature retrieval in image processing has been the activity of extracting pertinent as well as helpful information from the entire image. The overall content of an image may be utilized to retrieve the characteristics of that image, such as color, location, texture, form, and also the dominating border of an imagery item or area. In this research, we have extracted four diverse features, including the Gray level co-occurrence matrix features, the improved local vector pattern, the local ternary pattern, as well as the local gradient pattern. The detailed process of feature extraction techniques were given below.
Improved local vector pattern
We have proposed an improved Local Vector Pattern to effectively retrieve more specific discriminative data in a particular sub-region. The values between the referred pixel as well as the neighboring pixels having distinct distances from various directions are calculated in this local vector pattern (LVP), which is intended to express the one-dimensional direction & structural data of local texture [36].
A vector’s directional value is usually represented as
The LVP in
Our improved LVP uses the following Eq. (11), instead of using Eq. (10),
Where
By utilizing this improved LVP, more specific discriminative data in a particular sub-region gets retrieved.
The four 8-bit binary pattern LVPs have been merged to create the LVP at the reference pixel
A ternary, or three-valued, code is LTP. In LTP, a lag restriction value of “l” is utilized to compare the neighborhood to the center pixel values [37]. In accordance with Eq. (12), one of all 3 values
Where l stands for the lag limitation value and Tk reflects a single ternary number allocated to the surrounding pixel k. Bkas well as kcp indicates the gray-level intensity levels of the bordering pixels as well as the center pixel, correspondingly. By dividing LBP into two distinct LBPs, this LTP preserves the main benefits of LBP, including computation simplification.
A 3x3 pixel region’s local pattern gets determined utilizing the local gradient stream from one side to another via the center pixel. Two distinct two-bit binary configurations, referred to as the Local Gradient Pattern (LGP) for the pixels, are used to indicate the center pixel of that area. Every pixel’s LGP structure is subsequently retrieved.
A value of “1” or “0” gets supplied to the pixel depending on whether the gradient value of the adjacent pixel goes greater than the threshold level. Assume around i sample spots on a circle having radius b that is centered on a pixel. When determining the pixel values for neighborhood b as well as i, LGP utilizes bilinear interpolation [38].
LGP uses adjacent pixels that are
The gray-level co-occurrence matrix (GLCM) is indeed a matrix that displays several arrangements of the grey levels that can be observed in the image. The distinct areas in the photos could be distinguished due to the textural elements that GLCM derived from the photographs. In GLCM, a co-occurrence matrix gets created by comparing the pixel values of adjacent pixels.
A pixel’s brightness value is related to the count of rows as well as columns. The GLCM approach, which computes second-order statistical texture characteristics by taking into account the linkage among two pixels namely, the reference pixel as well as its surrounding pixel for arithmetic calculations, offers data regarding texture features. In particular, four of these characteristics were extensively used: contrast, entropy, homogeneity, as well as energy.
Contrast is used to show the grey level difference inside this GLCM matrix. It computes the pixel’s as well as its neighbor’s intensity. Entropy is used by the energy characteristic to calculate local homogeneity. It has a value between 0 and 1. The inverse of contrast weight is indeed the homogeneity feature, which computes the not-zero in the GLCM. Its range is between 0 and 1. The entropy characteristic seems to be the quantity of energy [39].
The extracted features from this stage such as LVP (A
Optimal feature selection
From those extracted features, optimal features will be selected in this stage. We select the feature selection is categorized into two ways. Before feature selection, the size is 2637 * 360. After the feature selection, the size is 2637 * 185. When creating a classification model, the procedure of feature selection involves lowering the count of input variables. In order to boost the model’s performance as well as lower the computation expense of modeling, it is desired to limit the count of input variables or features. For feature selection, we have used the hybrid algorithm named Arithmetic Operated Honey Badger Algorithm (AOBHA) which is the mixture of both Arithmetic (AO) and Honey Badger Optimizations (HBA). The extracted feature set
Arithmetic Operated Honey Badger Algorithm (AOBHA)
In this AOBHA, the Honeybadger gets updated with the hybrid updation function, created by combining the functions of HBA [40] and AOA [41].
Honey badger foraging behavior gets imitated by the Honey Badger Algorithm (HBA). Although the HBA algorithm has the benefit of dynamic searchability, it has the disadvantage of becoming stuck in local optima as a result of population diversity loss, particularly when trying to solve a challenging optimization problem. In order to find food supplies, a honey badger generally digs as well as smells, or else it tracks a honeyguide bird. Digging mode has been used to express the initial scenario, and honey mode to depict the second. When in the earlier phase, it makes use of its ability of smell to precisely pinpoint the prey; when found, it moves about the food source to find the ideal place for digging and then grabbing it. In the latter scenario, a honey badger pursues a honeyguide bird’s guidance to approach a beehive. The algebraic procedures of the HBA have been listed below. The population of probable solutions in HBA was illustrated as follows:
Where
where Co represents a constant
Where
A honey badger significantly depends on three factors during the digging phase: the prey’s scent strength I, the proximity between both the badger as well as the prey
Our AOHBA uses AOA, for the solution updation in the honey badger algorithm (HBA). The following equation represents the initialization step of the Arithmetic Optimization Algorithm (AOA).
In the equation above, MOA stands for the Math Optimizer Accelerated function, C_Iter stands for the present iteration, that is between 1 as well as the maximum count of iterations m_Iter and
By combining Eqs (17) and (20), we have developed the following equation
Here r7 is estimated by using a Sinusoidal map
r7 is a random number between 0 and 1.
By merging Eq. (17) from the honey badger algorithm and Eq. (23) from AOA, we have developed the following hybrid function
Where
The selected optimal features were denoted as
Flowchart of proposed AOHBA scheme.
The objective function of our proposed work is error minimization, which is described in the following Eq. (25)
Solution encoding of our proposed work is the optimal features, which were selected by our proposed AOBHA. The proposed AOHBA has attains the minimization error ranges from 1.15 to 1.09 demonstrating its effectiveness. Also, the selected optimal features were given in Fig. 3.
Solution coding of the proposed AOBHA-based skin cancer detection technique.
The selected optimal feature set will be given to the input of our improved DBN classifier. A particular type of generative probabilistic network known as a DBN develops the combined distribution among input information as well as label information via the activity of learning. The top Softmax decoder as well as a multilayered restricted Boltzmann machine (RBM) make up the DBN model’s architectural component [42].
Effectively increasing the count of layers inside the RBM network and other aspects of the DBN model’s architecture can significantly increase categorization accuracy. The accuracy of the categorization effectiveness may be considerably increased by choosing appropriate DBN model operational factors, including the learning rate, the count of successful unsupervised learning, as well as the count of hidden tier neurons.
It is discovered that its RBM layer piled with the DBN system is two layers by bringing up controlled research as well as comparing the classification effectiveness of the model. A unique type of generative human brain is RBM. A solitary RBM consists of a viewable layer as well as a hidden layer of a two-layer neural net. Every layer’s neurons really aren’t interconnected, and the layer does not exhibit the self-feedback phenomena. The neurons in both the viewable layer as well as the concealed layer are completely interconnected.
The neurons there in RBM’s concealed tier possess identical activation likelihood when the feature data of the neurons inside the visible layer is mapped. The features of the layer of neurons that are visible can be precisely stated after numerous pieces of training. Following is an expression of the energy ratio across the visible layer as well as the concealed layer:
where
Consider that the input value of the DBN system is J, as well as the hidden layer’s output value, is H, the weight, as well as bias update formula linking the concealed layer neuron as well as the output layer neuron, is,
where
The RBM connectivity of every layer can only guarantee that its weight attains the optimum representation of the layer’s defining characteristics during the initial pretraining step; it is unable to achieve the optimal projection of the input data for the whole DBN architecture. As per court of error back propagation from top to bottom, this calls for the back propagation (BP) algorithm, along with forward unsupervised categorization outcomes as well as label information, to fine-tune the linkage weight as well as bias among neurons in every layer of the entire DBN framework, layer at a time. The entire categorization procedure significantly reduces the overfitting problem that is prone to manifest itself in a solitary BP neural network, resulting in the parameter choice that results in the smallest squared error of the DBN architecture.
As per the proposed logic of improved DBN, a novel mean square error loss function is used to get better results from each layer. The loss function for training that is most frequently employed is a mean squared error (MSE) [43].
Where
Our improved DBN uses the following MSE loss Eq. (32),
Here weight
Finally, the output layer provides the classification results, whether it is benign or malignant, based on those optimal features. Figure 4 shows the modified DBN’s architectural layout. A Deep Belief Network (DBN) consists of many hidden layers between the input and output layers. The basic operation of a neural network is to take in a set of inputs, process those inputs using increasingly intricate computations, and then output the findings to deal with practical problems like categorization. We are restricted to feed-forward neural networks.
Architecture of improved DBN.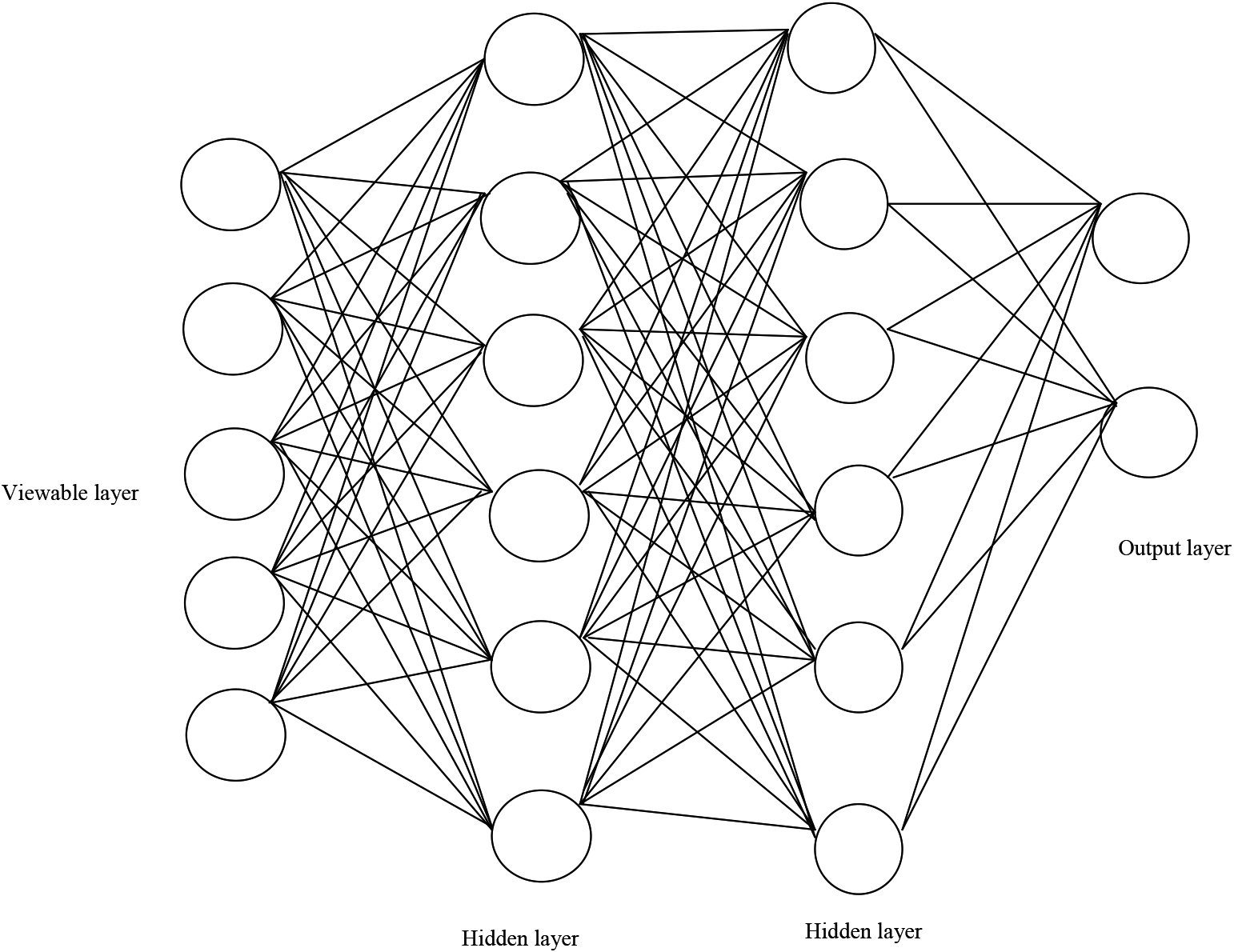
The proposed work was implemented in Python and the dataset used in this work is the Malignant vs. Benign (ISIC) dataset.
Dataset description
Our Arithmetic Operated Honey Badger Algorithm (AOHBA) based skin cancer detection performance matrices were compared with diverse conventional systems such as WOA, SSA, HBA, TOA, and AOA, and the findings were given below.
Image results obtained from the original image, pre-processing, segmentation phases, FCM image, and K-means are given in Figs 5–10 with sample images.
Image results obtained from Sample images.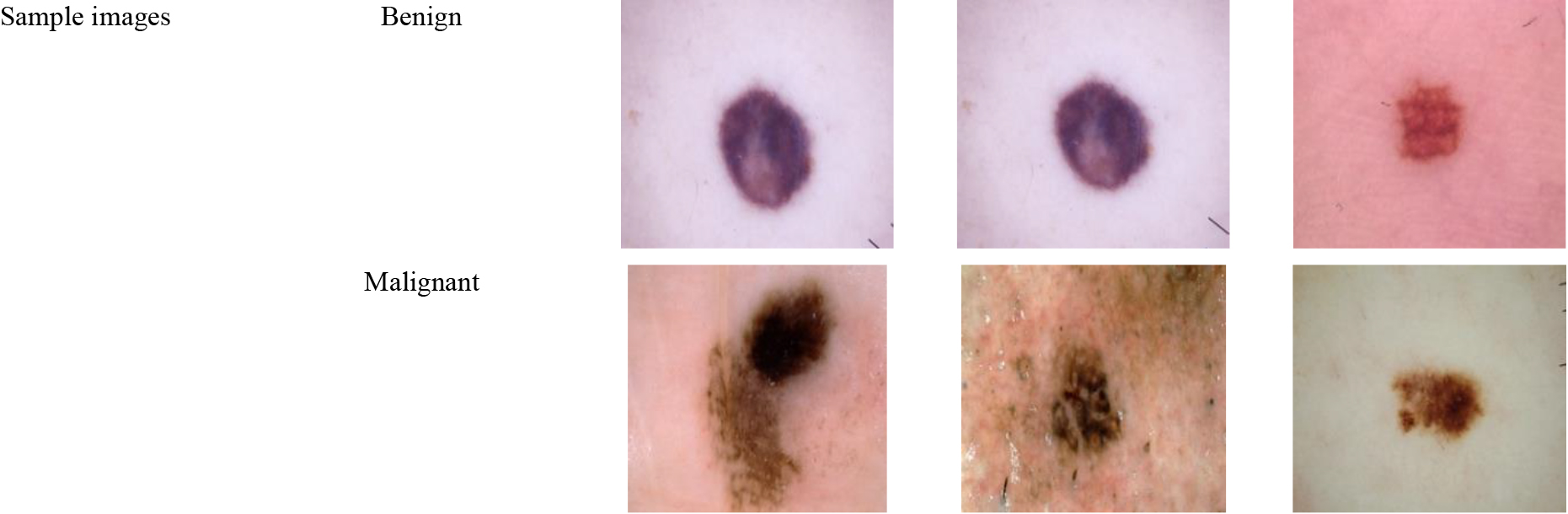
Image results obtained from Pre-processed images.
Image results obtained from Segmented images.
Image results obtained from FCM images.
Image results obtained from K-means images.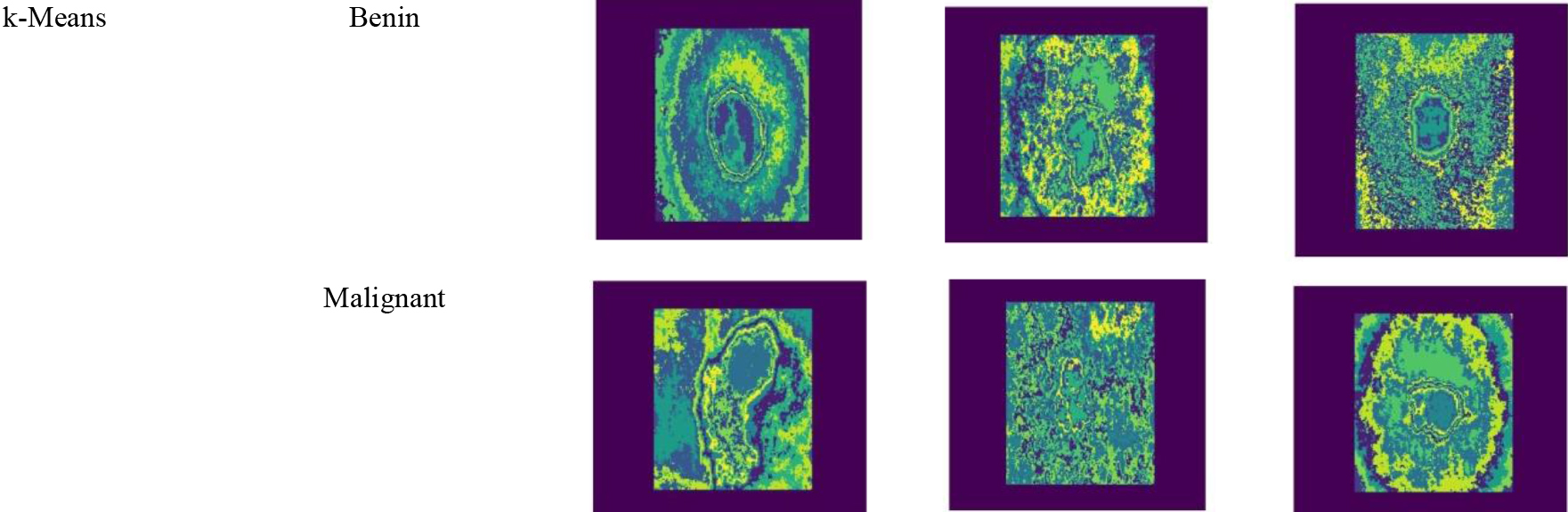
Image results obtained from conventional BRICH images.
To prove the effectiveness of the skin cancer detection strategy, we have evaluated the matrices such as Dice-score and Jacquard coefficient analysis like the proposed BRICH, K-Means, and FCM. The proposed BRICH has attained the values of 0.681, 0.655, and 0.609 in the Dice score values. Jacquard coefficient analysis has achieved 0.80, 0.84, and 0.72 respectively. The comparison of segmentation methods is illustrated in Table 1.
Conventional segmentation methods with Dice score and Jacquard coefficient analysis
Conventional segmentation methods with Dice score and Jacquard coefficient analysis
Our proposed AOHBA’s cost function was assessed for 0–50 iterations, and the outcomes were contrasted with those of the existing algorithms shown in Fig. 11. The cost function values for WOA and SSA are 1.153 and 1.165 for 0–10 iterations, respectively, but the value for our AOHBA technique is 1.133. Our proposed AOHBA method’s cost function value is low and steady after 10 iterations and is equal to 1.1. From the graph, the proposed AOHBA has attains the minimization error ranges from 1.15 to 1.09 demonstrating its effectiveness.
Cost function comparison of proposed AOHBA with conventional algorithms for 0–50 iterations.
Figure 12 compares the outcomes of our proposed AOHBA’s evaluation of performance metrics including accuracy, precision, sensitivity, as well as specificity with those of traditional algorithms for learning percentages of 60 to 90. In comparison to other traditional approaches, our proposed AOHBA achieves rates of 0.88, 0.9, 0.9, and 0.8 at 60 LP, whereas WOA and TOA only achieve accuracy, precision, sensitivity, and specificity values of 0.78, 0.85, 0.72, and 0.79, and 0.88, 0.82, and 0.79, respectively. The fact that our proposed AOHBA technique simultaneously obtains higher measure values for 70, 80, as well as 90 LPs demonstrates the higher performance of our proposed AOHBA approach.
In a similar manner, the outcomes of our proposed AOHBA technique for 60–90 LPs were analyzed for performance metrics such as F measure, MCC, NPV, FNR, as well as FPR, and the comparisons with standard methods are shown in Fig. 13. While our proposed AOHBA meets the rate of 0.9, 0.83 and 0.93 at 70 LP, SSA, and HBA attain the f measure, MCC, as well as NPV measure values of (0.82, 0.61 and 0.7) and (0.82, 0.62 and 0.71), respectively. The reality that our proposed AOHBA-based skin cancer detection methodology receives higher ratings for 80 and 90 LPs, respectively (0.96, 0.96, and 0.97) and (0.97, 0.97, and 0.97), shows that it can function more adequately than other classical methodologies. Our proposed AOHBA also attains a rate of (0.100, 0.050, 0.040, and 0.050) as well as (0.20, 0.15, 0.10, 0.10) for negative matrices like FNR and FPR assessment, that’s less than other standard methodologies.
Performance comparison of ablation study with four scenarios
Comparison of performance matrices including Positive measures.
Comparison of performance matrices for negative and neutral measures.
In this work, an ablation study was carried out to examine the effectiveness of our proposed AOHBA-based skin cancer detection system by eliminating specific processes in order to determine their relative contributions to the system as a whole. Our proposed AOHBA is employed in four scenarios: conventional BIRCH, conventional LVP, conventional DBN, as well as convenient operation without feature extraction. Table 2 lists the performance metrics for each scenario.
In order to determine the efficacy of our improved BIRCH and improved LVP, the proposed method was tested against conventional BIRCH and LVP, which obtained accuracy rates of 0.8100 and 0.8879, respectively, while our proposed obtained a rate of 0.9179, demonstrating that we can obtain better results by using our improved BIRCH and LVP. Similarly, our proposed AOHBA achieves the sensitivity and specificity rates of 0.9406 and 0.8756, whereas the approach without feature extraction only manages to attain rates of 0.8314 and 0.7667. The MCC and NPV values achieved while employing conventional DBN were 0.6452 and 0.7482, however, our proposed AOHBA obtains rates of 0.8189 and 0.8879, which are greater than other scenarios.
The outcomes of the comparisons between our proposed AOBHA’s various performance metrics with several classifiers, including SVM, RF, KNN, CNN, as well as DBN, are seen in Table 3. In contrast to the accuracy rates of 0.7736, 0.8050, and 0.7899 achieved by SVM, KNN, and RF classifiers, our proposed AOBHA-based skin cancer detection method obtains a rate of 0.9179. Our proposed AOBHA also yields rates of 0.9406 & 0.8756 in terms of sensitivity and specificity, whereas CNN and DBN classifiers reach rates of 0.9142, 0.8256 and 0.8559, 0.7984, which are lower than our proposed AOBHA-based skin cancer detection approach.
Performance comparison of our proposed AOBHA with conventional classifiers
Statistical measures of our proposed AOHBA were evaluated in terms of error and are compared with various optimization algorithms such as WOA, TOA, SSA, AOA, and HBA, which are given in Table 4. The STD as well as mean values of the WOA, and TOA were 0.019, 1.133, and 0.0179, 1.117, respectively, which were higher than our proposed AOHBA of 0.014, and 1.113. When AOA and HBA achieve maximum and minimum values of 1.1569, 1.1059, and 1.1507, 1.1072, respectively, our proposed AOHBA achieves rates of 1.1501 and 1.1049, indicating that our proposed AOHBA can give fewer error outputs than the other classical approaches. This evaluation is done as the model relies on the use of an optimization algorithm. Normally, optimization algorithms are stochastic in nature, and thereby evaluation is needed to determine the optimal performance with respect to statistical measures. In this work, the evaluation is carried out with respect to certain case scenarios.
Statistical analysis of proposed and convention
The input photos are pre-processed in the initial pre-processing stage using Gaussian filtering as well as histogram equalization methods. Improved Balanced Iterative Reducing and Clustering Using Hierarchies (I-BIRCH) was created to improve image segmentation by effectively assigning labels to pixels. In the third step, features including Improved Local Vector Pattern, local ternary pattern, Grey level co-occurrence matrix, and local gradient patterns were retrieved from the segmented images. We created an Arithmetic Operated Honey Badger Algorithm (AOHBA) for feature selection, which lowered computational costs and training time by picking the optimal features from the retrieved features. Finally, the photos are categorized utilizing an improved Deep Belief Network (DBN) based on the selected features, and the performance assessment results are compared to traditional techniques to demonstrate the efficacy of our proposed skin cancer detection strategy.
Footnotes
Author’s Bios