This paper provides finite-time performance bounds for the approximate policy iteration (API) algorithm in discounted Markov decision models. This is done for a class of approximation operators called averagers. An averager is a positive linear operator with norm equal to one with an additional continuity property. The class of averagers includes several of the usual interpolation schemes as lineal and multilinear approximations, kernel-based approximators among others. The API algorithm is studied under two settings. In the first one, the transition probability is completely known and the performance bounds are given in terms of the approximation errors and the stopping error of the policy iteration algorithm. In the second setting, the system evolution is given by a difference equation where the distribution of the random disturbance is unknown. Thus, in addition to the errors by the application of the API, in this case the performance bounds also depend on a statistical estimation error. The results are illustrated with numerical approximations for a class of inventory systems.
The approximate dynamic programming (ADP) is a broad family of algorithms aiming to compute approximated solutions in Markov decision processes (MDPs). It has attracted the attention of many researchers not only because it extended the application field of the MDPs theory, but also because the analysis of the approximate algorithms rises up several theoretical challenges that relate different mathematical fields (approximation theory, stochastic algorithms, statistical estimation, neural networks, etc.).
Concerning to the basic aspects, the departure point of the ADP is the general theory on the classical MDPs algorithms – either for the discounted cost criterion or the average cost criterion. Then, the ADP algorithms can be classified in terms of the algorithm in which they are based, thus defining the subfamilies of procedures generically known as approximate value iteration (AVI) algorithm, approximate policy iteration (API) algorithm, and approximate linear programming (ALP) approach. Roughly speaking, the ADP algorithms interleave an approximation step at each stage of the classical algorithms. This simple idea has produced a vast variety of competing approximate algorithms, but the most part of the literature is concentrated on finite space models. See, for instance, the books [4,18] and the survey papers [3,19,20,22] for general discussions and comprehensive accounts on the ADP algorithms.
In particular, the API algorithm have been mainly studied for finite spaces models [3–5,18,20], but there are some few exceptions [2,8,14,15,23,24,29]. The present work deals with the API algorithm for a discounted cost criterion with Borel state and action spaces, but differs from these latter papers in several ways.
To begin, in the present work is used a “perturbation approach” for the analysis of the API algorithm. This is done by considering approximation schemes that define a class of operators called averagers. An averager is a positive linear operator with norm equal to one that satisfies an additional continuity property. The averagers include several of the most used interpolation schemes (e.g., piecewise linear and multilinear approximations, piecewise constant approximations, kernel-based approximations, certain splines approximations) and some variants of the projected equation method.
The key property of an averager is that allows to see the approximation step as a “perturbation” of the original Markov decision model and the approximate algorithm as the exact algorithm in the “perturbed model”. These facts in turn have two important consequences: (i) they allow to establish directly the convergence of API algorithm and to identify the limit functions as the optimal value function on a perturbed model; (ii) they also allow to give finite-time performance bounds in terms of the quality of the approximations given by the averagers for the one-step cost function and the transition law of the original model. Usually the performance bounds are asymptotic and are not tied to the accuracy of the approximation step. It is also worth mentioning that the results in (i) and (ii) are obtained without imposing any other structural condition than the standard continuity and compactness conditions used in the MDP’s literature.
On the other hand, the papers [2,8,14,15,29] follow a free-model approach so their approximations rely on simulation of the controlled processes and prove the convergence either in the mean or with a “high probability” or almost surely under several technical conditions. The papers [2,8] provide a finite-time bounds which holds with a high probability for models with compact state space and finite action space. Moreover, the bounds are not given in term of the accuracy of the approximation schemes and seem to be quite difficult to estimate. The work [23] is of experimental nature since it focus in comparing the performance of several discretization procedures using some test models. The paper [24] focus on the rate of convergence of the API algorithm for a growth model using a piecewise linear interpolation. The papers [14,15] prove the almost sure convergence of the API algorithm assuming that the state and control spaces are compact convex subsets of a Euclidean space and also that the transition law has a density among other technical conditions. The paper [29] presents results for denumerable space models and claims that the results can be extended to general spaces.
The papers [1,17,26] also study the discounted performance criterion for systems with general spaces but using the approximate value iteration algorithm. In general terms, they share one or more features mentioned for the references [2,8,14,15,29].
In the present work the API algorithm is studied following a based-model approach under two settings. In the first one, the one-step cost function and the transition law of the system are completely known. Thus, the performance bounds of the API algorithm are given in terms of the approximation errors of the costs and of the transition law, and the stopping error of the API iteration algorithm. In the second setting, the controlled system evolves according to a difference equation of the form where H is a given function, and are the state and the control variables at time n, respectively, and the disturbance process is an observable sequence of independent and identically distributed random vectors with unknown density ρ. The density ρ is estimated using an historical record of the random disturbances by means of a density estimator , which in turns defines an estimated control model . Then, the API algorithm is applied in the estimated model , yielding a estimated–perturbed model as well as an estimate–approximate policy iteration (EAPI) algorithm. Clearly, the performance of this new algorithm depends on the accuracy of the model for estimating the unknown model , and also on the accuracy of model for approximating . Then, in addition to the errors in the application of the API algorithm, there is an estimation error whose accuracy is determined by the density estimation process.
The problem of finding optimal policies under unknown disturbance distribution is called adaptive control problem, and has been studied in several contexts (see, e.g., [9,10,12,13,16]). Typically, in this case, the adaptive policies are obtained by applying the “principle of estimation and control” (see [10]) which consists in substituting the estimates into optimal stationary controls. That is, before choosing the control , the controller gets an estimate of the density ρ, and combines this with the history of the system to select a control , defining the non-stationary control policy . Thus, since the discounted criterion depends strongly on the decisions selected at the first stages, precisely when the information about the unknown density ρ is deficient, it is not possible to ensure the optimality of such a policy. This fact implies that the optimality of this class of policies is studied in a weaker sense, the so-called asymptotic discounted optimality. In contrast, the estimate–approximate policy iteration introduced in this paper offers an alternative to numerically approximate optimal stationary policies for control systems with unknown disturbance distribution.
Summarising, the present paper provides finite-time bounds for the API algorithm using averagers under the two settings described above and it is organized as follows. Section 2 introduces the Markov decision model and some well-known results on the discounted cost criterion. Next, Section 3 presents the API algorithm and the performance bounds, whereas Section 4 develops the estimate–approximate algorithm. Section 5 illustrates the results by computing an approximate optimal policy for an inventory system. Finally, the Appendix collects the proofs of the main results of the work.
The discounted cost criterion
Notation. Denote by the Borel sigma-algebra of a Borel space X – recall that a Borel space is a Borel subset of a complete and separable metric space. From now on, “measurability” either for sets or functions will always mean “Borel measurability”. Given two Borel spaces X and Y, a stochastic kernel on X given Y is a mapping such that is a probability measure on X for each , and is a measurable function on Y for each . Denote by the space of real-valued bounded measurable functions on X with the supremum norm , and by the subspace of bounded continuous functions. Moreover, denotes the indicator function of the subset A, that is, for and otherwise. To end, (respectively ) is the set of positive (resp. non-negative) integers and (resp. ) denotes the set of real (resp. non-negative real) numbers.
The control model. Consider the standard discrete-time Markov control model given by where the state spaceX and the control spaceA are both Borel spaces; the family consists of non-empty measurable subsets of the control space A, where stands for the admissible control set for the state . The state-control admissible pairs set is assumed to be a Borel subset of the Cartesian product of . The evolution or transition law is a stochastic kernel on X given , and the one-step cost function is a measurable function on .
As usual, the Markov control model is thought of as the model of a discrete-time controlled stochastic processes with values in , where denotes the state of a system at time and the admissible control chosen by the controller at the same time. The controlled process evolves as follows: if at time n the controller observes the state and chooses the control , then the she/he incurs in a cost and the system moves to a new state according to the probability measure , that is,
Control policies. Let for and . The set is the set of admissible histories up to time of the controlled process, whose elements have the form where for , and . An admissible control policy is a sequence of stochastic kernels on A given such that for all , . Denote by Π the set of all admissible control policies.
Let be the class of all measurable selectors f from X to A, that is, the class of measurable functions that satisfy the constraint for each . An admissible control policy is called stationary policy if there exits such that the probability measure is concentrated at for all , ; in this case, the policy is identified with the measurable selector f and the class of all stationary policies with .
Let and the corresponding product σ-algebra. Each policy and initial state define a probability measure on the canonical sample space which determines the evolution of the stochastic controlled process . The expectation operator with respect to such measure is denoted by .
Discounted optimality criterion. Let be a fixed discount factor. The performance of the controlled process under a control policy is measured by means of the discounted cost criterion where is the initial state. The discounted optimal value function is defined by Thus, the discounted optimal control problem consists in finding a policy such that . If such a policy exists it is called optimal policy.
Assumption 2.1 below guarantees that the discounted cost criterion is well-defined for all policies and the existence of an optimal stationary policy as well.
is a continuous function bounded by a constant .
The mapping is compact-valued and continuous.
is weakly continuous in , that is, the mapping is continuous for each .
To ease notation, for each measurable function and selector define In particular, this notation yields Next, for each define the operators and and the dynamic programming operator as for those measurable functions u on X for which the involved integral is well defined.
It is easy to see that , , is a contraction operator from the Banach space into itself if the cost function is bounded.
Similarly, under Assumption 2.1, the dynamic programing operator T is also a contraction operator from the Banach space into itself with modulus α. Thus, the operators , and T have unique fixed points in the spaces and , respectively.
Moreover, by a standard selection theorem (see, e.g., [10,21]), for each function u in there exists a selector such that , that is, The policy defined by the selector f is called u-greedy policy.
Standard dynamic programing arguments yield the following well-known result (see, e.g., [10,11]).
the optimal value functionis the unique fixed-point inof the operator T, that is,
a stationary policyis optimal if and only if;
there exists a stationary policysuch that; hence,is an optimal policy.
The solution given by Proposition 2.3 to the optimal control problem is not feasible from the practical point of view because it requires the optimal value function is known in advance, which is rarely the case. Roughly speaking, the value and policy iteration algorithms seek to circumvent such obstacle by providing first a sequence of functions converging to the optimal value function , and then by approximating the optimal policy with a -greedy policy if the algorithm stops in stage k. The present work focus on the policy iteration (PI) algorithm, which runs as follows:
initial step: choose a policy and put ;
evaluation step: given compute ;
improvement step: compute a policy such that .
The PI algorithm poses several issues. Firstly, in order to the algorithm is well defined, it is needed to guarantee the existence of the policies in the improvement step (iii). Secondly, it is needed to establish whether the sequence converges to the optimal value function ; and thirdly, once the convergence is assured, it remains to bound the performance error incurred when the algorithm is stopped at stage k and the discounted cost is used to approximate . Note that Assumption 2.1 does not guarantee the existence of the policies in the improvement step because the functions , , need not to be continuous nor lower semicontinuous. However, once the policies in step (iii) are ensured to exist, the two latter issues are addressed by standard dynamic programming arguments, so these facts are stated in the next proposition without proof.
Suppose that Assumption2.1holds, and also that there exist policies,, satisfying the condition in the improvement step (iii). Then:
the sequenceconverges decreasingly to;
moreover,
Despite of Proposition 2.4, the PI algorithm is not feasible numerically for systems with large or infinite state space. Specifically, for such systems neither the evaluation step nor the improvement step can be carried out exactly, so each function , , has to be approximated by a function somehow chosen, and then to realize an approximated improvement step with respect to this latter function. The resulting algorithms are generically called approximate policy iteration (API) algorithms.
There are a number of approximating schemes for choosing and computing the functions , , as, for instance, the modified or optimistic policy iteration, the least square policy iteration, the temporal differences method, the projected policy evaluation, and many others. Obviously, the API algorithms also pose the same issues as the exact PI stated above, which are addressed in the next section for a class of approximating operators called averagers.
The approximate policy iteration algorithm with averagers
This section studies the API algorithm for a class of approximation operators called averagers (see Definition 3.1 below). The key fact is that these operators define “perturbed Markov control models” in which the exact policy iteration algorithm coincides with the approximated algorithm in the original model. This allows, for one hand, to show the convergence of the API algorithm and, for the other one, to provide finite-time computable performance bounds (see Theorem 3.6 below).
The plan for this section is the following. Firstly, we introduce the approximation operators we are concerned with; secondly, we define the perturbed models together with the API algorithm. Finally, we give the results concerning the performance error bounds.
Approximation operators. For an operator L from into itself, denotes the image of function in and is thought of as an approximation of function ; thus, such operators are called approximators. In particular, for each and , and are the images of and , respectively.
An operator is said to be an averager if it satisfies the following conditions:
.
L is a linear operator.
L is a positive operator, that is, for each in .
L satisfies the following continuity property,
An averager L is called weakly continuous averager if belongs to for each in . Similarly, the averager L is called strongly continuous averager if belongs to for each in .
Examples of averagers are given by the piecewise constant approximations, linear and multilinear interpolations, kernel-based operators, certain projection schemes and Schoenberg’ splines.
It is easy to prove that an averager L is a monotone operator – that is, whenever – and also that it is non-expansive with respect to the norm , that is,
The next proposition shows the key properties of averagers. In fact, the name of averager comes from properties (a) and (b) in the next proposition.
is a transition probability onX, that is,is a probability measure onXfor each, andis a measurable function for each;
for all.
The proof of this proposition follows standard arguments, so it is omitted.
The perturbed models. Fix an averager L and define the perturbed one-stage costs and transition laws as follows: Note that , , is a transition probability on X since it is the composition of two transition probabilities, namely, and ; in fact, by Proposition 3.2, it holds that
Thus, by Kolmogorov’ extension theorem, for each stationary policy and initial state there exist a probability measure and a Markov chain both defined in the canonical sample space – endowed with the product σ-algebra – such that is the (one-step) transition probability. We shall refer to the family of stochastic processes , , as the perturbed Markov decision processes.
To make easy the notation, instead of writing we shall write whenever there is not possibility of confusion. Then, the (perturbed) discounted cost for a stationary policy is defined as where denotes the expectation operator with respect to the probability measure .
The corresponding optimal value function is defined as . Thus, a stationary policy is called optimal if .
Now for each , define the operators and also the dynamic programming operator for the perturbed model as
From Proposition 3.2, it follows that Thus, the linearity of operator L imply that Using the latter equality it is easily seen that , , is a contraction operator with modulus α from into itself if the function is bounded. This result also follows noting that is the composition of a contraction operator and a non-expansive operator. Then, has a unique fixed-point , that is, By using standard dynamic programming arguments it can be shown that and also that Furthermore, the operator satisfies the following properties.
Suppose that Assumption2.1holds and also that L is a weakly continuous averager. Then:
is a contraction operator frominto itself with modulus α;
for all functioninit holds that
moreover, for eachinthere exists a measurable selectorsuch that
Suppose that Assumption2.1holds and also that L is a weakly continuous averager. Then, the optimal value functionis the unique fixed-point ofinand there existssuch thatMoreover, a stationary policyis optimal if and only if. Hence, policyis optimal.
Approximate policy iteration (API) algorithm.
Initiation step: let be arbitrary and put ;
evaluation step: given compute ;
improvement step: compute a policy such that and go back to step (ii).
Suppose that Assumption2.1holds and also that L is a strongly continuous averager. Then, the sequenceconverges decreasingly to the optimal value functionand
Approximation error bounds. In order to provide performance bounds for the API algorithm introduce the following constants. Let be a subclass of stationary policies that contains the stationary optimal policies for both the original and the approximated model, and the policies generated by the API algorithm as well. Then, define where stands for the total variation norm for finite signed measures, that is, where λ is a finite signed-measure on X. Notice that
Moreover, observe that and measure the approximation accuracy of operator L. The following result provides bounds for the performance of the API algorithm in terms of and .
Suppose that Assumption2.1holds and also that L is a strongly continuous averager. Letand,, be the functions and policies defined by the API algorithm. Then:
;
for all.
An estimate–approximate policy iteration algorithm
In many applications the cost function C and/or the transition law Q are unknown. Then, it is needed to resort to statistical estimation procedures for getting an estimated model, which in turns should be approximated. Next, this estimated–approximated model is used to compute “good” policies for the unknown original model. Clearly, the performance of those policies will depend on the properties of the estimation procedure as well as on the accuracy of the approximation scheme used to compute them. In this section, the above problems are addressed assuming the controlled stochastic system evolves according to the difference equation where is a measurable function, the disturbance variables , , are independent and identically distributed (i.i.d.) random variables with values in the Euclidean space and common density function , which is assumed to be unknown to the controller. It is also assumed that the one-step cost function is given as where is a measurable function.
Thus, the transition law (2) takes the form for all , , and satisfies the equality for each measurable function v on X for which the integral is well defined.
is continuous on for each ;
is a bounded continuous function on for each ;
the mapping is compact-valued and continuous.
It can be easily verified that under Assumption 4.1 the one-step cost in (9) is a bounded continuous function, and also that the transition law in (10) is weakly continuous. Thus, Assumption 4.1 implies Assumption 2.1 for any density function .
Depending on the modelling situation, one can draw on different statistical estimation procedures. Here it is assumed the density is unknown but the disturbance variables , , are observable, so there is a observed sample available for the controller. Then, based on the sample , the controller gets an estimated density of the unknown density . This yields an “estimated” model where for all and .
Next, in order to compute an nearly optimal policy, the model is perturbed using an averager L, as in the previous section, producing a “perturbed model” where
Recall that model satisfies Assumption 2.1 (see Remark 4.2). Thus, all the results in previous sections hold for and whenever, of course, the averager L has the properties asked there.
Now, let and be the discounted costs under policy for models and , respectively, that is, for each , where and denotes the Markov chains induced by the policy in the models and , respectively. Moreover, denote by and the optimal value functions in the models and , respectively. Recall that denotes the optimal value function in the original model .
EAPI algorithm. The estimate–approximate policy iteration (EAPI) algorithm is as follows:
initiation step: let and put ;
evaluation step: given , compute ;
improvement step: compute a policy such that
Notice that the EAPI algorithm is exactly the policy iteration algorithm in model . The hope is that for large enough k the policies have a good performance provided that the model gives a good estimation of the unknown model and, at the same time, the model gives a good approximation of model . To measure the accuracy of these approximations, let where is a subclass of stationary policies that contains the stationary optimal policies for the models , , and , as well as the policies generated by the EAPI algorithm.
The next result establishes the performance bounds for the EAPI algorithm.
Suppose that Assumption2.1holds and also that L is a strongly continuous averager. Then, the following performance bounds hold for each:
;
.
Under mild assumptions, using (9), (10) and (12), the quantities and can be controlled by choosing enough accurate averagers and also bounded by constants that depend on L but not on the random sample ; in fact, this is the case of the inventory system considered in Section 5.
On the other hand, a desirable property of the estimators is consistency. The kernel method provides estimates with such a property under a pretty mild condition. Indeed, let be a measurable function such that . The estimator based on kernel K is where , , is a sequence of positive real numbers and is an independent random sample drawn from the unknown density ρ. The following statements are equivalent (see, e.g., [6, Chapter 3] and [7, Chapter 9]):
and as ;
the estimates , , are strongly consistent, that is,
for each there exist a constant and such that
Additionally, each one of the above properties implies that
Moreover, for a wide class of densities and certain class of kernels, it is known that the rate of convergence in (17) is of order as t goes to ∞ (see [7, Chapter 9, Theorem 9.5]). That is, there exist a positive constant d and such that for all .
For the parametric case, that is, when the unknown density ρ belongs to a parametric family , the maximum likelihood method also provides consistent estimates and asymptotic normality under some regularity conditions (see, e.g., [25, Section 4.2, p. 145]).
In some specific cases, one can directly propose estimates with good properties. To illustrate this fact, suppose that the unknown density belongs to the parametric family where is a measurable function such that is finite and Θ is a subset of . It can be proven that is the maximum likelihood estimate of θ and also that -a.s. for each . The former fact follows from direct computation, while the latter one is consequence of the Borel–Cantelli lemma since for all , where is the distribution function corresponding to the density .
On the other hand, note that so the (strong) consistency of the estimates implies that -a.s. Moreover, some computations show that
Taking into account Remarks 4.4 and 4.5, Theorem 4.3 can be restated as follows. Assume that all conditions in Theorem 4.3 hold and suppose that and where and are positive constants that do not depend on the random sample , and also that as , that is, there exist a constant and such that for some positive constant γ. Then, and where the sequences and are those produced by the EAPI algorithm.
An inventory system
Consider a discrete-time inventory system with a single item and finite capacity . Let be the item inventory level and the quantity ordered at the beginning of period , respectively. Moreover, let be the product demand during period and assume that there is not backlog, that is, the unmet demand in each period is lost. Thus, the inventory system evolves according to the difference equation where for any . The initial inventory level is given and the demand process consists of non-negative i.i.d. random variables, which are also independent of the initial inventory. Let be the common distribution function of the demand process and assume that it admits a density function ρ, that is, for all .
Thus, the state and control spaces are , while is the admissible control set when the inventory level is . Observe that the mapping is continuous and compact-valued. The transition law is where stands for the expectation with respect to the distribution function . Clearly, the transition law satisfies that for all and any measurable function v on X for which the integral is well defined. The one-stage cost function is where p, h, and c are positive constants representing the unit cost for the unmet demand, the unit holding cost for inventory at hand, and the unit production cost, respectively. Then, the one-step cost is
Under these conditions, the above inventory system satisfies Assumption 2.1 (see Remark 4.2).
Consider now the approximation operator L defined by the linear interpolation scheme with N evenly spaced nodes and put . Thus, for each measurable function v on X, the operator L is defined as Clearly, L is a weakly continuous averager, that is, it is an averager that maps into itself (see Definition 3.1).
It can be shown that for each , there exists a base-stock optimal policy (see [28]). Recall that a stationary policy is base-stock if for , and otherwise, where the re-order point S is a non-negative constant. In fact, the re-order point of an optimal base-stock policy satisfies the equation whenever . If the optimal re-order point is . Similar arguments also show that there exist base-stock optimal policies for models , and . Thus, we take and equal to the class of base-stock policies.
Now, in order to bound the quantities and defined in (8), suppose the inventory model satisfies the following additional conditions:
the density ρ is Lipschitz continuous with modulus ;
ρ is bounded by a constant ;
the expected demand is finite.
Under this additional conditions, after some cumbersome computations, it can be verified that
The above bounds combined with Theorem 3.6 yield the performance bounds where is a -greedy policy and M is a bound for the one-step cost (24). Clearly, and can be done arbitrarily small by choosing fine enough grids and carrying out a large enough number of iterations of the algorithm.
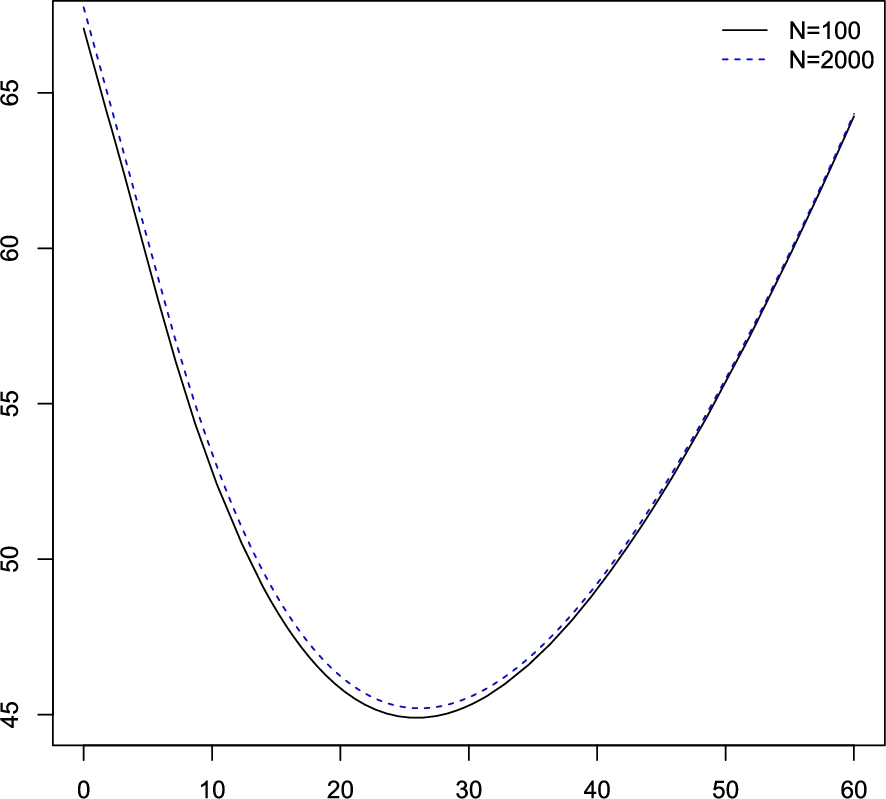
Approximate optimal policies computed by the API algorithm using a linear interpolation scheme with N nodes for an inventory systems with exponentially distributed demand with parameter . The optimal re-order points are and
N
100
500
1000
2000
1.635e−4
2.018e−6
2.761e−7
4.184e−8
6.463971
6.466142
6.466244
6.466270
1.013e−3
1.040e−4
1.525e−5
1.389e−5
10.78305
10.78982
10.7899
10.7900
To illustrate the last statement with numerical results, suppose that the demand has a exponential density , , with , and take , , , . Observe that and also that it is a Lipschitz function with modulus .
Denote by , , the functions produced by the API algorithm with discount factor α when it is used a grid with N nodes and, similarly, the constant stands for the re-order point of the policy computed by the API algorithm with N nodes. The algorithm starts with the policy , , and stops once the quantity falls below the tolerance . Table 1 shows the numerical results for the API algorithm with discount factors and , and a grid with N nodes for .
Approximate policy iteration functions for .
Approximate policy iteration functions for .
Table 1 and Figs 1 and 2 show that the API algorithm converges very fast and that practically identifies the optimal re-order point. In all these cases the API algorithm stops at the fourth iteration. In fact, is virtually the optimal value function and is the optimal re-order point for .
Table 2 below displays bounds for and as well as for the performance errors and . Notice that and are very sensitive to the discount factor α even though the quantities and can be controlled easily. In fact, the bounds and look quite conservative, specially if they are compared with the values given in Table 1. However, recall that (27) and (28) guarantee that and can be done arbitrarily small taking – perhaps unnecessarily – fine enough grids.
Bounds for the performance errors and for an inventory systems with exponentially distributed demand with parameter and discount factor
N
100
500
1000
2000
5000
10,000
2.8
0.56
0.28
0.14
0.056
0.028
0.48
0.096
0.048
0.024
0.0096
0.0048
97
19.4
9.7
4.75
1.93
0.95
194
38.8
19.4
9.5
3.86
1.9
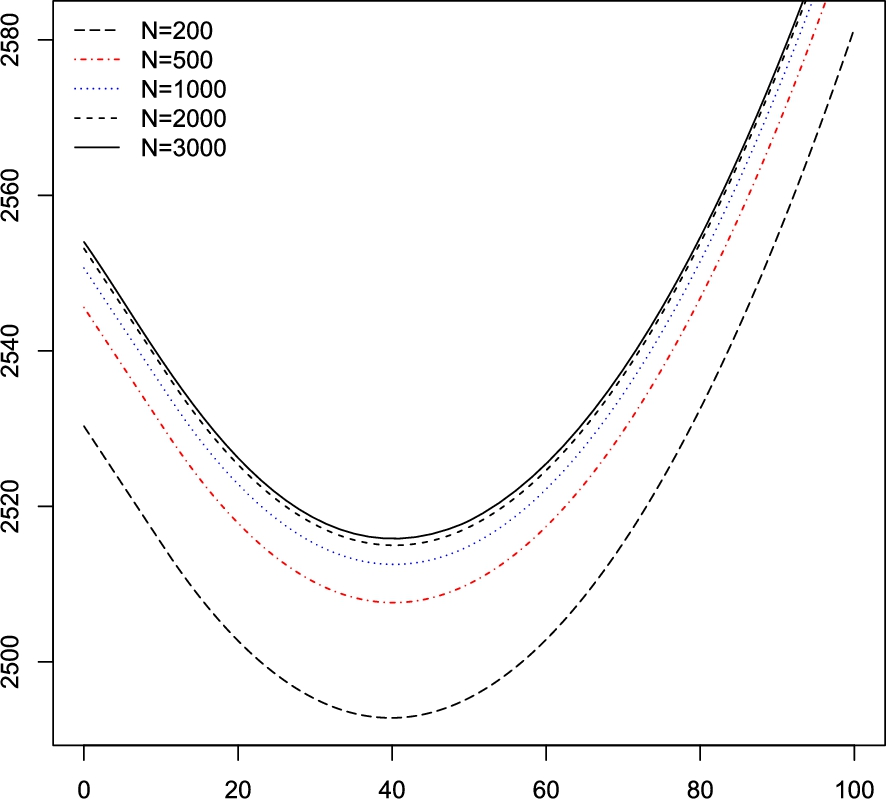
Approximate optimal policies produced by estimation–approximation policy iteration. The optimal re-order point are and
,
,
t
10
20
50
10
20
50
6.064e−7
5.984e−7
7.331e−7
3.526e−5
2.050e−5
3.084e−5
13.9394
11.6970
11.5385
16.5738
16.0126
15.8759
5.32533
5.23075
5.072251
5.783765
5.222557
5.0859
In the following consider the case in which the demand density function belongs to the parametric family of densities where the parameter θ is unknown but lies in some interval with . Thus, the goal is to estimate the unknown parameter θ, and based on the estimate to compute approximated optimal policies. The maximum likelihood estimator of θ is , so the density estimate is
The bounds for quantities and defined in (14) and (15) can be obtained in a similar way as it was done for and but using instead of after noting that density is bounded by and Lipschitz continuous with modulus . Thus, from (25) and (26), so, by Remarks 4.5(b) and 4.6 (see (18)), it holds that and where .
The numerical results shown in Table 3 correspond to the values , , , , and discount factors . The EAPI algorithm was performed with samples simulated from the density (30) for assuming that the true parameter value is and using a grid with evenly spaced nodes.
Footnotes
Acknowledgements
Work supported partially by Consejo Nacional de Ciencia y Tecnologia (CONACyT) under Grant CB2015/254306 and also by Proyectos FEC-2015 de la División de Ciencias Exactasy Naturales, Universidad de Sonora.
The proof of Theorem 4.3 is based on Lemma A.1, Remark A.2 and Lemma A.3 given below.
AlmudevarA., Approximate fixed point iteration with an application to infinite horizon Markov decision processes, SIAM Journal on Control and Optimization46 (2008), 541–561.
2.
AntosA.SzepesvariC. and MunosR., Learning near-optimal policies with Bellman-residual minimization based fitted policy iteration and a single sample path, Machine Learning71 (2008), 89–129.
3.
BersetkasD.P., Approximate policy iteration: A survey and some new methods, Journal of Control Theory and Applications9 (2011), 310–335.
4.
BertsekasD.P. and TsitsiklisJ.N., Neuro-Dynamic Programming, Athena Scientific, Belmont, MA, 1995.
5.
CooperW.L.HendersonS.G. and LewisM.E., Convergence of simulation-based policy iteration, Probability in the Engineering and Informational Sciences17 (2003), 213–234.
6.
DevroyeL. and GyörfiL., Nonparametric Density Estimation: The L1 View, Wiley, New York, 1985.
7.
DevroyeL. and LugosiG., Combinatorial Methods in Density Estimation, Springer, New York, 2001.
8.
FarahmandA.GhavamzadehM.SzepesvariC. and MannorS., Regularized policy iteration, in: Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 2008, pp. 441–448.
9.
GordienkoE.I. and Minjárez-SosaJ.A., Adaptive control for discrete-time Markov processes with unbounded costs: Discounted criterion, Kybernetika34 (1998), 217–234.
10.
Hernández-LermaO., Adaptive Markov Control Processes, Springer, New York, 1989.
11.
Hernández-LermaO. and LasserreJ.B., Discrete-Time Markov Control Processes: Basic Optimality Criteria, Springer, New York, 1996.
12.
HilgertN. and Minjárez-SosaJ.A., Adaptive policies for time-varying stochastic systems under discounted criterion, Math. Methods Oper. Res.54 (2001), 491–505.
13.
HilgertN. and Minjárez-SosaJ.A., Adaptive control of stochastic systems with unknown disturbance distribution: Discounted criteria, Math. Methods Oper. Res.63 (2006), 443–460.
14.
MaJ. and PowellW.B., A convergent recursive least squares approximate policy iteration algorithm for multi-dimensional Markov decision process with continuous state and action spaces, in: IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning, New York, 2009, pp. 66–73.
15.
MaJ. and PowellW.B., Convergence Analysis of Kernel-based On-policy Approximate Policy Iteration Algorithms for Markov Decision Processes with Continuous Multidimensional States and Actions, Department of Operations Research and Financial Engineering, Princeton University, 2010.
16.
Minjárez-SosaJ.A., Approximation and estimation in Markov control processes under a discounted criterion, Kybernetika40 (2004), 681–690.
17.
MunosR., Performance bounds in -norm for approximate value iteration, SIAM Journal on Control and Optimization47 (2007), 2303–2347.
18.
PowellW.B., Approximate Dynamic Programming: Solving the Curse of Dimensionality, Wiley, 2007.
19.
PowellW.B., Perspectives of approximate dynamic programming, Ann. Oper. Res. (2012), 1–38. doi:10.1007/s10479-012-1077-6.
20.
PowellW.B. and MaJ., A review of stochastic algorithms with continuous value function approximation and some new approximate policy iteration algorithms for multidimensional continuous applications, Journal of Control Theory and Applications9 (2011), 336–352.
RustJ., Numerical dynamic programming in economics, in: Handbook of Computational EconomicsAmmanH.M.KendrickD.A. and RustJ., eds, Vol. 1, Elsevier, 1996, pp. 619–728.
23.
RustJ., A comparison of policy iteration methods for solving continuous-state, infinite-horizon Markovian decision problems using random, quasi-random, and deterministic discretization, available at SSRN: http://ssrn.com/abstract=37768 or https://dx-doi-org.web.bisu.edu.cn/10.2139/ssrn.37768.
24.
SantosM.S. and RustJ., Convergence properties of policy iteration, SIAM Journal on Control and Optimization42 (2004), 2094–2115.
25.
SerflingR.J., Approximation Theorems of Mathematical Statistics, Wiley, 2002.
26.
StachurskiJ., Continuous state dynamic programming via nonexpansive approximation, Computational Economics31 (2008), 141–160.
27.
Vega-AmayaO. and López-BorbónJ., A performance bound for discounted approximate dynamic programming using averagers, Reporte Interno, Departamento de Matemáticas, Universidad de Sonora, 2013.
28.
Vega-AmayaO. and Montes-de-OcaR., Application of average dynamic programming to inventory systems, Math. Methods Oper. Res.47 (1998), 451–471.
29.
XuX.HuD. and LuX., Kernel-based least squares policy iteration for reinforcement learning, IEEE Transactions on Neural Networks18 (2007), 973–992.