
Abstract
In most sub Saharan African countries,the mechanism for pricing auto-insurance policies is tariff based. This means that the key factor that influences price changes is usually based on regulation and legislative dynamics. Additionally, where ratemaking is risk based, analysis has in most cases focused on internal historical data or claims history, particularly in the sub Saharran Africa. These policy regimes have led to unfair price distortions among policyholders and have increased risk of portfolios for most insurance companies. In this study we consider geographical location risk that influence auto-insurance claim process for an insurance company. The study develops a Markov-modulated tree-based gradient boosting (MMGB) model for pricing auto-insurance premiums. The Markov-modulated tree-based gradient boosting model is a Tweedie general linear model (GLM) based pricing algorithm with a compound Poisson-Gamma distribution whose rate varies according to accident risk in a Markovian process. Thus, the study extends the existing premium pricing framework by integrating a geographical location risk factor into the main pricing framework. The study applies the model to a motor insurance data set from Ghana. The results show that the proposed method is superior to other competing models because it generates relatively fair premium predictions for the non-life auto-insurance companies, helping to mitigate more the insured risk for the firm and the industry.
Introduction
The operational process of non-life Insurance assumes different risks profiles for the insured influenced by instabilities within the business environment. Predicting the financial obligation for claims in non-life insurance is quite complicated and usually depends on the structure of insurers liabilities. The question has always been how much premium to allocate to a policyholder to ensure fairness on the part of the insured and to avoid bankruptcy on the part of the insurer. The most critical task in insurance pricing is how to accurately predict the risk of claim and the expected coverage for the insured should the event occurs. The task of modeling claims has been a major challenge because of data structure which is usually highly skewed with many zeroes as well as high claim severity. Traditional modelling technique such as generalized linear modeling (GLM) technique as proposed by Nelder and Wedderburn [28] has been the major tool used for loss cost modelling (McCullagh and Nelder [24]). To cite few examples Haberman and Renshaw [19] and Mihaela [27] analyzed claims severity and frequency using the GLM technique. Smyth and Jorgensen (2002) also published a paper that used Tweedie GLM as an alternative approach in modelling claim frequency and severity. This modelling framework assumes that claims arrival has a Poisson distribution and claim severity follows a gamma distribution such that the total claim structure could be modelled with Tweedie compound Poisson. Even though Tweedie GLM is often used, it has a major drawback. One major drawback is that link between the variate and covariates which is usually constrained to a linear form is rare in practice. For instance, in auto-insurance, risk of claim is not necessary inversely related with age (McCartt et al. [25] and Anstey et al. [2]). To correct this draw back various procedures have been proposed. Wood [35] for instance proposed Generalized Additive Models (GAM) to overcome some of the deficiencies of the GLM such as the linear link to a more general form. However, with GAM the structure of the model must be specified. The main and interaction effects have to be specified by the researcher. This often result in specification bias which likely affects the predictive power.
To overcome the deficiencies of GAM, Yang, Qian and Zou [36] proposed a gradient tree-boosting algorithm for fitting compound Poisson models nonparametrically. Despite its strong predictive power, its outcome depends on the data generating process and the associated variables. The result of the literature reviewed showed a wide range of models that consider historical risk as the only basis for price differentiation among policy holders. However, the difference with this study is that we present a process of integrating location risk in the pricing framework. We utilized the concept of Markov chain and tree-based gradient boosting mechanism to derive the model instead of a single model that characterize most claim cost modelling by most researchers. This study seeks to improve on the work of Yang et al. [36] by obtaining an auxiliary variate x i closely related to and has a positive correlation with the study variable, claims y i .
The fast-paced changes in business environment and technological advancement require that we have an all-inclusive dynamic risk treatment, especially in non-life insurance. As cited in Djuric [8], Cramer [5] said that the goal of risk theory is to provide a mathematical analysis of the fluctuations in the insurance business and to suggest various means of protection against their adverse effects. This motive is what this study seeks to achieve. The rest of the paper is organised as follows, Section 2 presents methods and materials of the study, Section 3 also presents analysis and results of the two datasets employed and Section 4 presents the conclusion and recommendations of the study.
Methods and materials
Gradient boosting and predictive modelling
To keep the paper self-contained, we briefly explain the principles of gradient boosting, which is a statistical learning framework for predictive modelling. Gradient boosting is a nonparametric prediction framework that combines base(weak) learners into a strong predictive function in an iterative fashion. The idea originated from Breiman (1998) with further significant improvement by Friedman [15,16], Hastie, Friedman and Tibshiran [20] and Yang, Quian and Zou [36]. We briefly explain the general procedures for gradient boosting. Let x = (x
1, x
2, …, x
p
)
T
, be p-dimensional predictor variables and y a one dimensional outcome variable. The goal in predictive modeling is to determine the optimal function that maps x to y. This is done by minimizing the expected value of a loss function 𝜑(⋅, ⋅) over the function class
A forward stagewise algorithm is adopted to approximate the minimizer in Eq. (1), which then builds up the components of 𝛽[m] h (x; 𝜉
m
), (m = 1, 2, …, M) sequentially through a gradient descent-like procedure. At each iteration m (m = 1, 2, …), suppose the current estimate for
The negative gradient vector
This section briefly introduces compound Poisson distribution and the Tweedie model as a basis for our model formulation and analysis. Let N be a Poisson random variable denoted by Pois (𝜆) and let Y denote independent and identically distributed gamma random variables denoted by Gamma (𝛼, 𝜔) with mean 𝛼𝜔 and variance 𝛼𝜔2. Define a random variable Z by
Yang et al. [36] integrated the Tweedie model into the tree-based gradient boosting algorithm by Friedman to model insurance claim size.
In Non-Life insurance, the risk premium represents the expected cost of all claims declared by policyholders during the insured period. The calculation of the premium is based on statistical models that seeks to incorporate all available information about the accepted risk, thereby aiming at a more accurate assessment of tariffs attributed to each. The basis for calculating the risk premium is the statistical modeling of frequency and cost of claims that depends on the characteristics defined in the insurance contract. The risk premium is the mathematical expectation of the annual cost of claims declared by policyholders and it is obtained by multiplying the two components; the estimated frequency E (N) and expected cost of claims E (Y ): the risk premium for the ith policyholder is
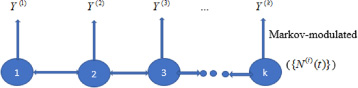
The conceptual framework of the study.
The study assumes that risk of accident varies from one state to another and from time to time. Factors such as vehicle density, road network, traffic regulation etc. may vary from one state to another and hence risk propensity may vary likewise. More specifically, suppose Y j is a non-negative random variable corresponding to the amount of the jth claim. Also let assume that the random variables Y j are equally defined as a function of the Markovian process M. This means that beside historical risk, claim arrival process at time t depends on the behaviour of the process M at time t. The behavior of this process is captured as location risk of a policy.
The study consider a portfolio of policies of the form
Given that the occurrence of an accident at time t is a stochastic sequence, we characterize and discretize our risk model into ten (10) states based on the ten geographical states in Ghana (j = 1,2, …,10). Given the initial probabilities x
0 of the event E in state j at period t. We compute the transition matrix M for period t via Bayes theorem. Let P (E) denote the long run proportion of times the event E occurs upon repeated sampling during time t. In otherwords how likely it is that a vehicle operating within state j or between states will experience event E. Furthermore denote P (E
t1) the risk of occurence of an accident in state one at time t and P (E
t2) the occurence of an event at time t in state two etc. In the context of our study and mathematical tractability, we define E
t1 E
t2 as the event that a vehicle operates between two states. This means that P (E
t1 E
t2) represent the risk involved when operating between two states. Given that E
t1 and E
t2 are independent, P (E
t1 E
t2) = P (E
t1)P (E
t2). Thus the probability distribution of accident risk can be expressed as a transition matrix as
We obtained data from two sources; An auto-insurance data was obtained from a major insurance company in Ghana. The data spans from 2013 to 2016. The data contains claim history and other characteristics of policyholders. In line with the study objectives, an auxiliary data was obtained from National Road Safety Commission on the number of road traffic accidents that spans from 2001 to 2015. The National Road Safety Commission is a state agency responsible for safety education and accident statistics in Ghana. The data include road traffic information for all the ten geographical regions of Ghana.
Analysis and results
The paper considers two sets of data an accident data and insurance data as described in Section 2.5.
Summary of accident data
We use the crash data to derive the location risk. The probability distribution of the accident risk, the transition matrix and the stationary distribution is shown in Table 1, Table 2 and Table 3, respectively. Table 1 is the probability distribution of accident risk accross the ten regions of Ghana as per the data, Table 2 represents the transition matrix derived from Section 2.4 and Table 3 derived from Eq. (17).
Accident matix for the ten geographical zones
Accident matix for the ten geographical zones
Source: Authors computation (2018).
A 10-dimensional discrete time Markov chain defined by the ten
Long run distribution of accident risk
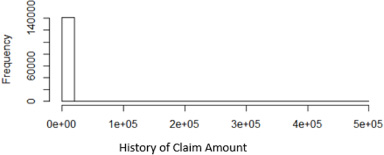
Distribution of claims (2013–2016).
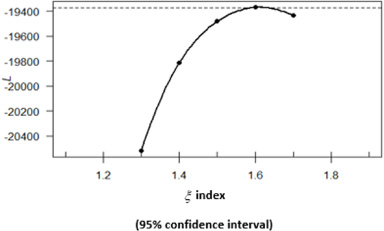
Estimating the optimal index parameter (𝜉).
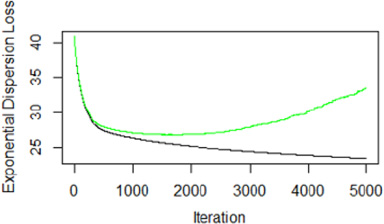
A plot of CV error showing the optimal iteration number.
Thus, Table 3 shows the long run distribution of accidents risk across the ten regions of Ghana. This means that in the long run accidents risk within Greater Accra region is about 19.64%, Ashanti 19.43%, Brong Ahafo 9.78%, Central region 10.69%, Eastern region 14.69%, Northern region 4.53%, Upper East region 3.23%, Upper West 2.02%, Volta region 7.25% and Western region is 8.73%. For mathematical tractability the study sought to reclassify the ten states into three based on risk similarities consistent with Occams razor. The result of the classification is described: Thus Greater Accra and Ashanti regions were classified as considerable risk zone, Brong Ahafo, Central region, Eastern region, Western region and Volta region classified as medium risk zones, while Northern region, Upper west and Upper east were classified as low risk zone. This classification is Markov-driven over a period of time, depending on the behaviour or the changing dynamics of the risk matrix in Table 1.
The insurance data consists of policy and claim information for each vehicle. The data contains one hundred and forty thousand, nine hundred and sixty-one (140,961) vehicle records out of which contains five thousand, four hundred and fifty (5450) claims records for four (4) years, from 2013 to 2016. Table 4 summarizes the variables of the data set.
Insurance policy variables
Insurance policy variables

A schematic overview of the TD boost model.
Figure 2 also shows the distribution of total claim amount recorded from 2013 to 2016. The figure suggests high skewness. This is expected as claims rarely occurs and when it occurs, the severity of it when it occurs has been the bane of the non-life insurance industry.
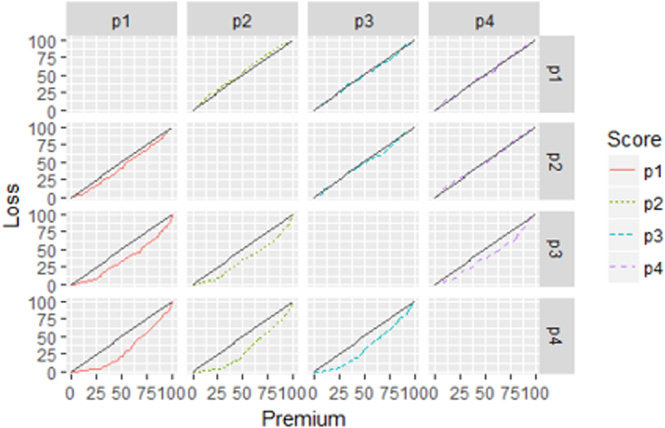
Plot of ordered Lorenz curve.
From Table 5, there were approximately 140,961 insured customers of which about 5450 (3.9%) filed for claims. About 85% of the claims in the study period occurred in Greater Accra region and the lowest claims frequency resulting occurred in Upper West region. The total claim size recorded for the study period was Ghana cedis (GHS) 43,364,372 while the premium income accrued from claimants is GHS 7,630,261 representing about 17.6% of aggregate claims. This means that less than a quarter of claims was accounted for by the premium income for the period. In terms of regional distribution of total claims, Greater Accra region recorded the highest of the aggregate claims (85%) but contributed about 83% of the premium income. Ashanti region recorded the second highest (about 8%), while Upper West recorded the lowest (0.09%). These are not surprising since nearly 75.4% of the total insured are in the Greater Accra region, and less than 0.3% of same are in the upper west region. In terms third party and comprehensive segregation, the data showed that a claim of approximately GHS 5,284,407 was recorded for third party representing 12.06% of total claims and approximately GHS 38,516,284 for comprehensive representing 87.94% of total claims. No claims were recorded for third party fire and theft. This means that majority (about 88%) of total claims was made on comprehensive policies.
Regional distribution of claims (2013–2016)
As discussed in Section 2, the study considered the distribution of accident risk across the ten regions of Ghana. To the best of our knowledge no such information has been considered in insurance pricing in the both developing and the developed economies. The author reckon that several factors influence insurance outcomes. Some of the factors include regulation and legislative changes, claim trends, vehicle density, interest rate and investment. Legislative and regulation, inflation, interest rate and investment could be regarded as fixed. However, claim trends, vehicle congestion and for that matter accidents risk in different geographical zones could vary from one region to the other as well as from time to time. More so, factors such as, roadway design, roadway maintenance have been shown to contribute significantly to road accidents which vary from one region to another. For this reason, these phenomena are characterized and incorporated into the pricing framework. The study used Markov theory to categorize the claims data set based on accident risk derived for each region.
Two indicator variables ℓ 1 and ℓ 2 were adopted to integrate the three levels of geographical location risk into the risk premium prediction function in Eq. (15). In Table 4, the claim amount and claim frequency represent the outcome variables. The rest of the variables represent and were considered as the historical risk factors for non-life insurance claims.
The study estimates the predictor function of the model using the method discussed in Section 2. Consistent with statistical model framework, 70% of the data was randomly selected to be used in building the model, while 30% is used for out-of-sample validation of the model. As discussed in Sections 2.1 and 2.2, the first choice in building a Tweedie gradient boosting model involves selection of the appropriate loss function which we specify as Tweedie. With Tweedie loss function, the method requires specification of the index parameter (𝜉;1 < 𝜉 < 2), the shrinkage (𝜁;0 < 𝜁 < 1), the optimal number of trees and the interaction depth (L).
The optimal index parameter was obtained using profile likelihood estimation method Yang et al. [36]. As shown in Fig. 3, the optimal 𝜉 obtained was 1.61 at 5% level of significance.
We also adopt a selection procedure to obtain the optimal M. To illustrate the selection procedure, we first grew many trees with M = 5000 and plot the error rate associated each tree size. This is done using a five-fold cross validation.This means that the data was randomly divided into five (5) samples not necessary equal size. Each of the five (5) sample is fitted separately to the model. Out of which the optimal number of trees is obtained. As shown in Fig. 4 the curve colored green represents the error rate at various levels of iterations. As the tree grows from point zero (0) onwards the error rate reduces suggesting an improvement of error reduction rate. As the model moves beyond 2000 iterations, the curve turn upwards suggest diminishing returns of model accuracy. The point where the improvement in error rate reaches its maximum is the optimal tree number which from Fig. 4 is given as M = 1788. We further examined the optimal interaction size (L). It is worth noting that a model with a one-way interaction effects is simply an additive model. The study evaluated 20, 10, 5, 4, 3 and 2 way interaction effects using the training data set. The result showed that the ten (10) way interaction effects gives relatively better results (L = 10). Our shrinkage parameter was also set at 0.05 (Friedman [15]). Based on the specifications; M = 1788, shrinkage parameter (𝜍 = 0.05) and 𝜉 = 1.67, we estimate the predictor function in Eq. (12) considering (15) and using the procedure described in Section 2.1. A schematic overview of the algorithm by Yang et al. [36] is shown in Fig. 5. The resulting model summary is shown in Appendix Tables 6 and 7.
Tables 6 and 7 present the variables considered with their relative importance. In an attempt to assess how important each variable is to the model as in regression trees we calculate the total amount of reduction in the Residual Sum of Squares (RSS) attributable to splits caused by the predictor and averaged over the number of trees. In classification trees, we do the same thing using average reduction in the Gini index. The location effect as specified by the model Eq. (15) was significant. Thus, while state 1 contribute about 0.08%, state 2, contribute about 0.6%. This is significant considering the nature of business of the non-life insurance business and the severity of claims when it occurs.
Model evaluation
The study compares the Markov-modulated Gradient Boosting model which has integrated location risk with other conventional models. We considered a TDboost without location risk, (TDBOOST), Tweedie Generalized Linear Model (TGLM), Gradient boosting approach by Guelman [17]. To examine the performance of these competing models, after fitting each on the training data, we predict the risk premium
Mathematically, suppose B (X) is the base premium, we define the relative premium as
A low relativity is interpreted as the policy that is highly profitable and a suitable candidate to retain. This means that if the score Z (X) is the desirable approximation of the expected loss. Then, if the relativity is small, then we expect a small loss relative to the premium. If the relativity is large we expect a large loss relative to the premium (Werner and Modlin [33], Frees et al. [12]). In addition, under relativity ordering a large covariance between losses and the proportion of premiums retained implies a high Gini index. A large negative covariance between premiums and relativities implies a high Gini index. The ordered premium and loss distribution is given respectively as
The two distributions (19) and (20) are based on the same sorting criteria. The Ordered Lorenz curve is the graph of
From (18) the prediction for R (X) from each model is successively specified as the base premium and use the predictions from the remaining models as the competing premium to compute the Gini indices. Using minimax strategy to select the best performing model, the study selected the model that provides the smallest of the maximal indices over the competing models.
Table 8 presents the Gini indices with their standard errors in Table 9. We find that the maximal Gini index is 1.38 when using MMGB as the base premium, 12.07, when using TDboost as base premium, 28.406 is when using GLM as base premium and 36.296 when using GBM as the base. MMGB is the smallest. Therefore, MMGB has the smallest maximum Gini index of 1.380, hence it is the least vulnerable to alternative scores.
Several statistical techniques have been proposed to price premiums such as modelling the frequency and severity of claims and computing the product of its expectations (Haberman and Renshaw [19], Mihaela [27] etc.). There is constantly the need to improve on ways in which policy premiums are priced. In many actuarial risk models, consideration is mostly placed on internal historical claims data that are obtained within the insurance firm or industry. Thus, external data is rarely used. With unobservable phenomenon, researchers usually employ hidden Markov chains to make extrapolations (Guillou et al. [18], McNeil and Lindskog [26]). However, it is important to note that besides historical claims data in Auto insurance external observable phenomenon such as policy operational risk as a factor contribute significantly to loss cost. Practical tools for studying such phenomenon in a more flexible way has been a challenge. Results from our gini index suggested that the MMGB model defined risk relatively better the cases where such risk considerations are discounted. for some predictors could pose a challenge. More so as oppose to other non-linear statistical learning methods such as neural networks and support vector machines, Gradient boosting provides interpretable results via the relative influence of the input variables and their partial dependence plots (Guelman [17]). By considering location risk of a policy, the flexible Markov Modulated Tree-Based Gradient Boosting method which is designed to integrate location risk factor into insurance pricing framework was to be more efficient. Based on the sample data used in this analysis, the level of accuracy in predictions was shown to be higher for MMGB relative to other models. This is not surprising since GLMs are relatively simple linear models and are thus constrained by the class of functions they can approximate. In short, Markov-modulated gradient boosting framework is a viable alternative method for building insurance loss cost models such as Guelman [17], Yang et al. [36], Friedman [15,16] within the statistical learning framework.
Conclusion
We have presented a probabilistic Markov-modulated tree-based Gradient Boosting (MMGB) model that considers location risk in pricing auto-insurance premiums. We have shown that by integration of location risk or introducing geographical location risk as covariates, the insurance policies are better differentiated in terms of risk and priced efficiently. This could assist non-life insurance companies in underwriting and claims management for sustainability. We have shown that the MMGB model performs relatively better than, the cases where location risk is not considered.
Recommendations
In view of the above conclusions, to ensure sustainability and fairness in pricing, a model-based MMGB approach is recommended for risk premium pricing in Ghana and other sub-saharran countries where accident risk is diverse across geographical locations. This is because the model is flexible and fairly captures the distribution of the data structure and account for location risk for any given policy.
It is also recommended based on the findings that; the non-life insurance companies use the risk-based model as an additional tool to ascertain the level of risk for its clients.
Footnotes
Summary of model variables with their relative importance
Matrix of standard errors
| MMGB(P1) | TDBOOST(P2) | GLM(P3) | GBM(P4) | |
| MMGB | 0.000 | 3.062 | 3.555 | 3.107 |
| TDBOOST | 3.045 | 0.000 | 3.570 | 3.140 |
| GLM | 3.246 | 3.266 | 0.000 | 3.412 |
| GBM | 2.273 | 2.304 | 2.869 | 0.000 |