
Abstract
We study paycheck optimization, which examines how to allocate income in order to achieve several competing financial goals. For paycheck optimization, a quantitative methodology is missing, due to a lack of a suitable problem formulation. To deal with this issue, we formulate the problem as a utility maximization problem. The proposed formulation is able to (i) unify different financial goals; (ii) incorporate user preferences regarding the goals; (iii) handle stochastic interest rates. The proposed formulation also facilitates an end-to-end reinforcement learning solution, which is implemented on a variety of problem settings.
Introduction
We propose a reinforcement learning solution to paycheck optimization. Specifically, one aims to allocate monthly income in order to achieve goals like paying out loans, purchasing a mortgage, saving for retirement, etc. Indeed, such a problem is common in everyday life and similar services are provided by various companies. In this work, we hope to provide a rigorous framework for such problems with a reinforcement learning solution.
Finding a suitable problem formulation for paycheck optimization is especially challenging. First, the goals of paycheck optimization are often multivariate and quite heterogeneous. Therefore, it is cumbersome to unify such goals and optimize them simultaneously. Second, incorporating the preferences of users becomes especially complicated for paycheck optimization. For instance, some goals like paying out credit card debt can be more urgent to the user than saving money or purchasing a mortgage, while the amounts vary greatly. It is unclear how to incorporate such information into decision-making methods. Third, the interest rates of financial goals (e.g. inflation rate, savings rates, etc.) evolve stochastically over time. This makes learning an optimal paycheck allocation strategy even more challenging. Finally, without a proper formulation, the powerful decision-making tools in machine learning and control are not applicable to this problem.
To the best of our knowledge, a quantitative solution for paycheck optimization is missing. Existing results on paycheck optimization are mainly analytical without an implementable methodology [1,8,11]. One can also consider paycheck optimization as a non-traditional robo advising problems with different targets. However, existing literature is mainly for portfolio optimization [5–7] or other single financial goals [4]: such methods are not applicable to paycheck optimization with the multiple heterogeneous goals studied in this work. Some existing paycheck optimization solutions rely on a simple waterfall method. Specifically, the user needs to prioritize different goals in an absolute order to finish the goals one by one. In other words, all incomes will be allocated to a specific goal and only when one is met will the next one be considered. As a result, the method is incapable of targeting multiple goals simultaneously and thus is generally sub-optimal. An example where the waterfall method performs poorly is given in Appendix.
Separately, there exists a huge amount of literature on reinforcement learning for decision-making in various scenarios. Such methods provide flexible solutions for many different decision-making problems, but are not directly applicable to paycheck optimization.
In this work, we propose a utility maximization framework for paycheck optimization and a data-driven policy gradient method. First of all, we formulate the paycheck optimization as a utility maximization problem to unify various financial goals and incorporate user preferences. In detail, we leverage piecewise-linear utility functions. Whenever a goal is active (i.e. it is still beneficial to allocate income to this goal) the corresponding utility function is negative, while it becomes zero otherwise. This design has two advantages: on one hand, it encourages a policy to finish the goals; on the other hand, it is possible to express the user-specific preference for each goal via the slope of the utility function - the steeper the slope, the more beneficial it is to allocate income to the corresponding goal.
The decision-making target is to maximize the sum of the utility functions of each goal across time. With the proposed utility maximization framework, we conduct policy gradient to solve for an optimal paycheck allocation strategy. Specifically, with the collected data, we implement policy learning using gradients estimated from the data. As a result, we learn a paycheck optimization policy in a data-driven and model-free manner, without specifying any stochastic model. This provides a flexible solution to paycheck optimization.
Problem formulation
Paycheck optimization studies the problem of income allocation over different financial goals. Examples of financial goals include paying out credit card debt, paying out student loans, saving for a home down payment, saving emergency funds, or saving for retirement using for example 401Ks or IRAs. At time t, we use S t to denote a user’s income, and 𝜋 t to denote the fraction of S t assigned to different financial goals. By optimizing the income allocation 𝜋 t , we aim to complete all the financial goals.
In paycheck optimization, the financial goals are heterogeneous. For instance, savings goals like retirement and emergency funds are different from debt goals like student loan and credit card debt. Indeed, the former depend on interest rates that increase the value of the wealth assigned to them, i.e. they contribute to finishing them. On the other hand, the latter’s interest rates increase the value of the debt itself, delaying their completion. Goals also differ based on their maturity. Short-term goals, like credit card debt, have much higher interest rates and thus, should be treated more urgently with respect to longer-term goals. In practice, it is unclear how to unify such heterogeneous traits and optimize these goals simultaneously.
While the main objective of paycheck optimization is finishing all financial goals, it is also important to consider the users’ preferences. Instead of completing the goals as fast as possible, different users may have different priorities for each goal. For example, some users could prefer saving for purchasing a house more than saving for retirement. On the other hand, some might prioritize retirement, given that such investments may have higher interest rates that would allow them to finish all other goals more quickly. Additionally, an agent may choose to pay down high interest debt first, or they may prioritize the confidence boost that comes from zeroing out debt and choose to pay out small debts first. As a result, how to quantify the preference of users and incorporate them into paycheck optimization is also an open question.
Paycheck optimization as utility maximization
In this section, we formulate paycheck optimization as a utility maximization problem. For each financial goal, we define (i) a state variable, (ii) its dynamics and, (iii) a utility function.
State variable
To devise a utility maximization objective, we first define the state variable for this problem. Let I be the set of financial goals with cumulative totals that we aim to achieve. Then,
Dynamics
Critically, the specific dynamics of X
t
are different for each financial goal. We use S
t
and
For financial goals involving savings like home down payment and emergency funds, we define
Finally, for retirements savings, the structure is considerably different due to the presence of tax-advantaged savings accounts which are commonly used for retirement, i.e., 401K and IRA. If goal i is the retirement savings, denoted as RS, then
For each goal we wish to define a corresponding utility function
Let us now note the following about the defined utility functions. First, both are continuous with finite derivative, which allows for gradient-based methods to solve the corresponding maximization problem (3) below. Second, they return negative values when x > 0, but stay at zero when x ≤ 0. Moreover, as stated above, the value of p, q for different financial goals model the user’s preference with respect to each goal. Specifically, p, q are non-negative weights which can be chosen to incentivize completion of goals: the larger the value of p, the more incentive to complete the first (or only) segment of the goal; the larger the value of q, the greater the incentive to complete the second segment.
For the single phase goals, e.g.
In addition to the goals with state variables, we also want to assign utilities to the 401K and IRA goals, since making regular contributions to these accounts could be a user desired goal in addition to their contribution to the retirement savings goal. Since there are no cumulative totals to meet, the utility for the 401K and IRA will be assessed based on the contribution at each time t.
401K is a two-phase goal, where the first phase consists of contributions up to a minimum level, while the second one comprises contributions up to the maximum allowed level. Hence, for 401K the utility will be given by

Different utility functions.
Eventually, with utilities defined for every and each goal, we can define the paycheck optimization target as maximizing the expected total utility:
Note that, while the proposed framework provides the ability to assign a different preference (weights) to every goal, it is always feasible to fix some of them to simplify the problem. This is vital from a practical perspective, since it might be difficult for users to order the importance of all financial goals. For instance, we might assume that the user have the same preference for all debt goals and thus fix p i for student loans and credit card debt as one value. In practice, this can simplify the communication with users when trying to come up with p i ’s and q i ’s.
We aim to solve (3) by deep deterministic policy gradient [10]. Specifically, we parametrize the policy as a deep neural network of X
t
:
Our procedure is as follows:

Where Step 1 is initialization for each training epoch, Step 4(b) follows (4), and Steps 5,6 are where we optimize our neural network. Optimization can be done with any standard algorithm, for example gradient descent or ADAM [9].
In this section, we implement the proposed method for paycheck optimization. We aim to show that our method is readily available for paycheck optimization for users with different preferences. In the following, we first describe the experiment protocol and then provide results.
Protocol
To implement the proposed method, we consider three types of users with different preferences for each of the financial goals:
the home buyer, whose priority is purchasing a home as quickly as possible; the saver/retirement planner, whose priority is maximizing retirement savings and saving for emergency; the debtor, who prefers to pay off debt first.
For each category, we construct a representative user, with preference weights selected reflecting the user type (see Table 1). For each of the users, we set the same input data (see Table 2). With this experiment, we demonstrate that the proposed paycheck optimization framework is able to effectively address the preferences of users, while finishing each financial goal in an efficient manner.
Preference weights for different users
Preference weights for different users
Inputs for each user
For each representative user, we report the contribution to each goal over time under the learned policy in Fig. 2. We note that each goal is successfully completed under the learned paycheck allocation policy. Also, the result is consistent with the user preference. Specifically, home buyer does buy a mortgage earlier than others; the savings of saver grows faster; debtor pays off the debts in the fastest manner.

Contribution to each goal over time under the learned policy with constant rates for three different representative users: home buyer in blue, saver in orange, and debtor in green.
From the experiments above, we can explain the learned policy by preference weights. Specifically, the policy function prefers to finish the financial goals with higher preference weights by allocating more income to such goals. One can further examine the effects of each state variable on the learned policy by using Shapley values. Some examples in portfolio optimization include Babaei et al. [2]; Colini-Baldeschi et al. [3]. However, it is nontrivial to extend such analysis from portfolio optimization to multiple financial goals in our setting. We thus defer that to future work.
Extension to stochastic rates
In the previous analysis, we fixed the rates
We maximize the value function ((5)) following the deep deterministic policy gradient in Section 4 while using data of rates. We use
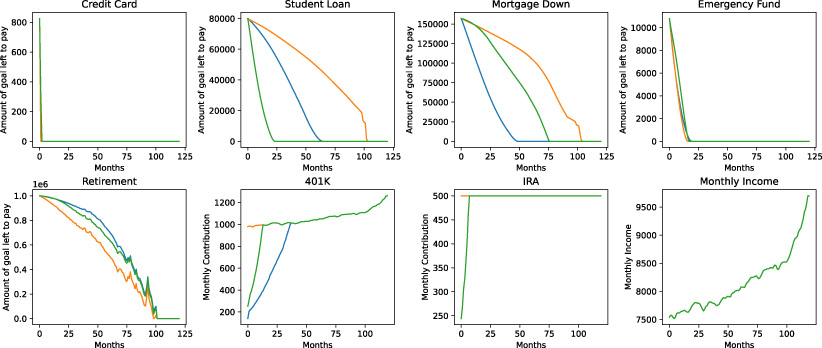
Contribution to each goal over time under the learned policy with stochastic rates for three different representative users: home buyer in blue, saver in orange, and debtor in green. Note that the monthly income suffers a sharp increase after month 100, since it is directly affected by inflation (which has hiked over the last couple of years).
In this section, we conduct experiments for the case with stochastic rates. Under the same setup as the experiments in Section 5, we treat rates
Conclusion
We propose a framework for paycheck optimization with an end-to-end reinforcement learning solution. By formalizing the problem into a piecewise linear utility maximization problem, our method is able to handle heterogeneous financial goals, the preferences of users, and also the stochastic rates. We empirically demonstrate the applicability of the proposed method.
Footnotes
Example of waterfall failure
Consider an individual with disposable income of $1000 a month and two financial goals, each of which involve paying off debt:
Goal 1 is to pay off $1000 with no interest rate, and with priority p
1 = 1000. Goal 2 is to pay off $
Recall that the waterfall method consists in paying off the goals in order of priority. Accordingly, the strategy would be as follows. First, we would pay off Goal 1, since p
1 > p
2. Hence,
On the other hand, let us consider a strategy where we recognize the threat of future compounding interest. The user would optimally split her paycheck evenly among the two goals. Therefore,