
Abstract
In the radio frequency identification technology system, there are too many time slots which are caused by tag collision, and the communication complexity is high. On the basis of the anti-collision algorithm of the binary tree and the quadtree query tree, the methods of locking the collision bit and predicting the child node are used, a new lock-bit hybrid querytree (novel lock-bit hybrid query tree, NLHQT) algorithm is proposed. In the algorithm, the collision bit information is extracted through the lock instruction, and the extracted collision bit information is predicted. While reducing the collision time slot, the reader generates a new query prefix through prediction, thereby avoiding the generation of idle child nodes. Compared with the improved hybrid query tree (IHQT) anti-collision algorithm and the regression lock adaptive multi-tree search (RLAMS), the algorithm in this paper is more effective in reducing the total number of time slots and communication complexity, and the efficiency of identifying tags can be effectively improved.
Keywords
Introduction
The Internet of Things (IoT) is a new type of network technology and industrial model, user application terminals are extended to the interactive communication between people and things, and things and things. IoT is the extension and expansion of the Internet, telecommunication networks, and radio and television networks (Ning, 2012). As a data collection technology to realize the Internet perception layer, radio frequency identification (RFID) technology has been widely used in manufacturing, logistics management, indoor positioning and other fields (Gaukler, 2011). Among them, passive ultra-high frequency (UHF) has received widespread attention due to its long communication distance, fast recognition speed, large storage capacity, and low cost (Lehto, 2009). However, if multiple tags are respond to the reader at the same time, a multi-tag collision problem will inevitably occur. At this time, an efficient anti-collision mechanism is needed to track and identify a large number of tags (Jia et al., 2012).
The tag anti-collision is essential to solve the multiple access in the wireless communication system. The RFID anti-collision algorithm based on time division multiple access (TDMA) is widely used because of its simple principle and no need to modify the hardware part (Zhai et al., 2015). Commonly used tag anti-collision algorithms can be divided into probabilistic algorithms and deterministic algorithms (E-Batouty et al., 2013). The algorithm based on ALOHA is a traditional probabilistic algorithm (Chen, 2009; Barletta et al., 2015), which has a low recognition throughput rate, and when the number of tags is unknown, it cannot guarantee that all tags are recognized, which is easy to cause tag starvation (Yang et al., 2012). The deterministic algorithm is a tree-based algorithm (He & Wang, 2013). The classic tree algorithm includes binary search (BS) algorithm and query tree (QT) algorithm (Myung et al., 2006). Based on this, a hybrid query tree (HQT) algorithm is proposed (Kim et al., 2013). RFID anti-collision algorithm is combined with the classic adaptive multi-tree search (AMS) (Wang et al., 2010; Li et al., 2017), a RFID anti-collision algorithm of regressive lock-adaptive multi-tree search (RLAMS) is proposed. After searching the fork tree of the tree, the collision bits in the tag are extracted to form a new sequence, which can reduce the generation of a large number of collision time slots, but it has not improved the reduction of idle time slots. The hybrid query tree (IHQT) is improved in RFID anti-collision algorithm Shi et al. (2017). A novel RFID anti- collision Q-value algorithm is proposed (Chen, 2019), which changes the Q-rounding of the original Q-value algorithm to 2Q rounding, so that the adjusted frame length is closer to the theoretical optimal value, thereby the convergence is effectively reduced. Slot utilization of time is improved. Branch prediction is added before the reader queries the collision tag, and idle nodes are determined by prediction and removed, which can achieve thorough the purpose of eliminating idle time slots, but the algorithm fails to effectively reduce idle time slots, and the amount of data transmission is still relatively large.
An anti-collision algorithm based on the query tree algorithm is proposed (Zhao et al., 2021), which aims to reduce the energy consumption of the system and improve the communication efficiency. The method divides the tags into two groups and segments the ID, so that the two groups of tags respond to the query commands respectively. In prefix and suffix, according to the status code in the query command, only part of the ID sequence of the query segment is transmitted. The algorithm significantly reduces the transmission of bit information that is useless for the identification process, eliminates idle time slots, and improves system throughput. For the conflict of RFID identification caused by environmental factors such as noise, multiple tags, and multiple readers in the Internet of Things itself, an improved anti-collision algorithm is proposed (Chen, 2022). A grouping algorithm based on power control is proposed to achieve the goal of improving the performance of the anti-collision algorithm and saving energy (Wu et al., 2020); the use of power control related technologies enables the readers in the system to use different transmit powers to communicate with tags of different distances. Each time it communicates with the reader, only a part of the designated area is selected for communication, so as to realize the function of communication between the reader and tags of different distances. In the Dynamic Frame Slotted Aloha (DFSA) algorithm, the frame length limitation leads to low throughput of label identification, and an algorithm is proposed based on Logistic-DFSA (Logistic-DFSA) (Liu & Zhang, 2020). The sequence is generated by the logical mapping, the spread spectrum technology is combined with the DFSA algorithm to realize the parallel identification of multiple tags in a time slot. Then, the influence of the frame length, the length of the spread spectrum code and the number of tags on the system throughput in the identification process are analyzed.
The traditional probabilistic algorithm has a low recognition throughput rate, and when the number of labels is unknown, it cannot guarantee that all labels are recognized, which is easy to cause label starvation. The algorithm also fails to be effective. When the idle time slot is reduced, the amount of data transmission is still relatively large. A new lock-bit hybrid query tree (novel lock-bit hybrid query tree, NLHQT) algorithm is proposed in this paper. The algorithm adds a lock bit instruction, and only locks and extracts the collision bit, thereby forming a new tag sequence, adding prediction instructions to the newly generated sequence, and eliminating idle nodes through prediction. IHQT adds more additional query and collision time slots, and the number of reader queries in the face of binary tree and quad tree conditions is more than other algorithms. On the basis of IHQT algorithm, NLHQT algorithm not only eliminates idle time slots, and also rely on the locking instruction to greatly reduce the collision time, so that the algorithm in this paper can reduce the number of queries of the reader when it is compared with other algorithms. Especially when continuous collisions occur in tags, the algorithm in this paper can quickly and effectively identify tags, thereby effectively improving search efficiency and data transfer volume between reader and tag.
Novel lock-bit hybrid query tree (NLHQT) approach
NLHQT algorithm prediction description
NLHQT algorithm collision instruction description
When the reader is initialized, the stack is empty. At this time, all tags will respond. If the reader only reads one tag, it will successfully identify the tag and the query will end. If a collision occurs, the tag’s collision bit will be locked. According to the Manchester coding principle, the collision position of the collision tag is X in the tag sequence which is detected by the reader, and the same information bit, that is, the non-collision position, is the original information number. By extracting the information of the collision position where X is located, the collision position is locked, so that the locked bit forms a new tag sequence. The addition of the lock bit instruction can make the tag no longer transmit non-collision bit information in the subsequent identification process, thereby greatly reducing the transmission of redundant information. If the two collided tags are 01011000 and 11010100, the tag sequence detected by the reader is XX01XX00 in the Manchester encoding principle, and the collision position information is D7, D6, D3, D2, the collision position is extracted in the subsequent identification process, only the four collision information needs to be transmitted, reducing the amount of information transmission by 50%.
NLHQT algorithm prediction instruction description
After querying the prefix m1, m2, …, m p , the reader adds n-bit binary 1 (n = 1 corresponds to the binary tree algorithm, n = 2 corresponds to the quadtree algorithm, and n = 2 L corresponds to the 2 L fork tree algorithm). When the reader generates a new binary sequence m1, m2 … , m p , 11 … 1 (n 1), the new label after the lock bit receives the prediction instruction of the reader, the prefix K1, K2, …, K p are compared with m1, m2, …, m p , if the two match, the tag converts the n-digit binary number after the ID prefix K1, K2, …, K p into the corresponding decimal number a, and the predicted response sequence is responded to the reader with a length of 2n, the a bit in the sequence is 1 (from left to right, 0 ∼ 2n - 1 bit), and the remaining 2n - 1 bits are all 0. After receiving all tag responses, the reader judges the child node at the corresponding position, it is marked as 0 in the sequence as an idle node, thereby generating a query prefix that avoids idle nodes.
Although the search layer can be shortened by increasing the fork tree, thereby reducing the collision time slot, because the algorithm has reduced the collision time slot through the lock instruction, and in the actual operation process, only the binary tree, the quad tree and the octree are easier achieve. If the octree search is used, although the efficiency is slightly improved, it will dramatically increase the complexity of prefix optimization, which in turn affects the universality of the algorithm. Therefore, the algorithm in the article adopts n = 1 and n = 2 to improve the binary tree and quad tree algorithms respectively and discusses and verifies in these two cases.
The following is an example of analyzing the design ideas of predictive instructions for the situations when n = 1 and n = 2:
The collision tag sequences A, B, C, D are 0010, 0100, 1001, and 0110 respectively.
When n = 1, the first query has no m1 prefix, and only contains a binary number 1, that is, the query prefix is 1. Labels A, B, C, and D convert the binary number of the 0th digit to the corresponding decimal number. That is, the decimal number corresponding to the position of label A is 0, label B is 0, label C is 1, label D is 0, and the remaining bits are 0. That is, tags A, B, and D respond to the predicted response 10, tag C responds to 01, and the binary tree query has two child nodes 0 and 1, so the child node corresponding to the 0th bit of tags A, B, and D is 0, and the C tag child node corresponding to bit 0 is 1. Then a new query instruction is generated to complete the prediction of the first position of the label. Then the C label is successfully identified, and the A, B, and D labels continue to query by analogy.
When n = 2, the situation is similar to when n = 1. The first query prefix does not contain m1 and m2, and only contains two binary digits 11, that is, the query prefix is 11. Labels A, B, C, and D convert the binary numbers of the 0th and 1st digits into corresponding decimal numbers. That is, the decimal number corresponding to label A is 0, label B and label D are 1, and label C is 2. At the same time, each tag responds to a predicted response sequence of length 4, in which the decimal number converted by the tag corresponds to the position 1, and the remaining bits are 0. That is, tag A responds with a predicted response of 1000, tag B and tag D respond with 0100, tag C responds with 0010, and the quadtree query has four sub-nodes 00, 01, 10, and 11, so the 0th and 1st bits in tag A correspond to the child node is 00, the child node corresponding to bit 0 and bit 1 in label B and label D is 01, and the child node corresponding to bit 0 and bit 1 in label C is 10. Then a new query instruction is generated to complete the prediction of the first two digits of the tag. Then the A label and the C label are successfully identified, and the label B and the label D continue to query by analogy.
NLHQT algorithm analysis
If there are 4 tags in the query range of the reader, the tag code is 8 bits, and the tag IDs are tag A (01000010), tag B (01101110), tag C (01101101), tag D (11001110). When n = 1,The identification process of the NLHQT algorithm is in Table 1. At this time, because the lock instruction reduces unnecessary idle time slots, the reader can determine the idle child nodes of the identification tag every time it sends 1 when making predictions. The comparison between the NLHQT algorithm when n = 1 and the IHQT algorithm when n = 1 is shown in Fig. 1. It can be seen from Fig. 1 that the algorithm in this paper not only does not generate idle time slots in the process of tag identification, but it can also effectively reduce the generation of collision time slots and improve the identification efficiency.
NLHQT algorithm recognition process with n = 1
NLHQT algorithm recognition process with n = 1
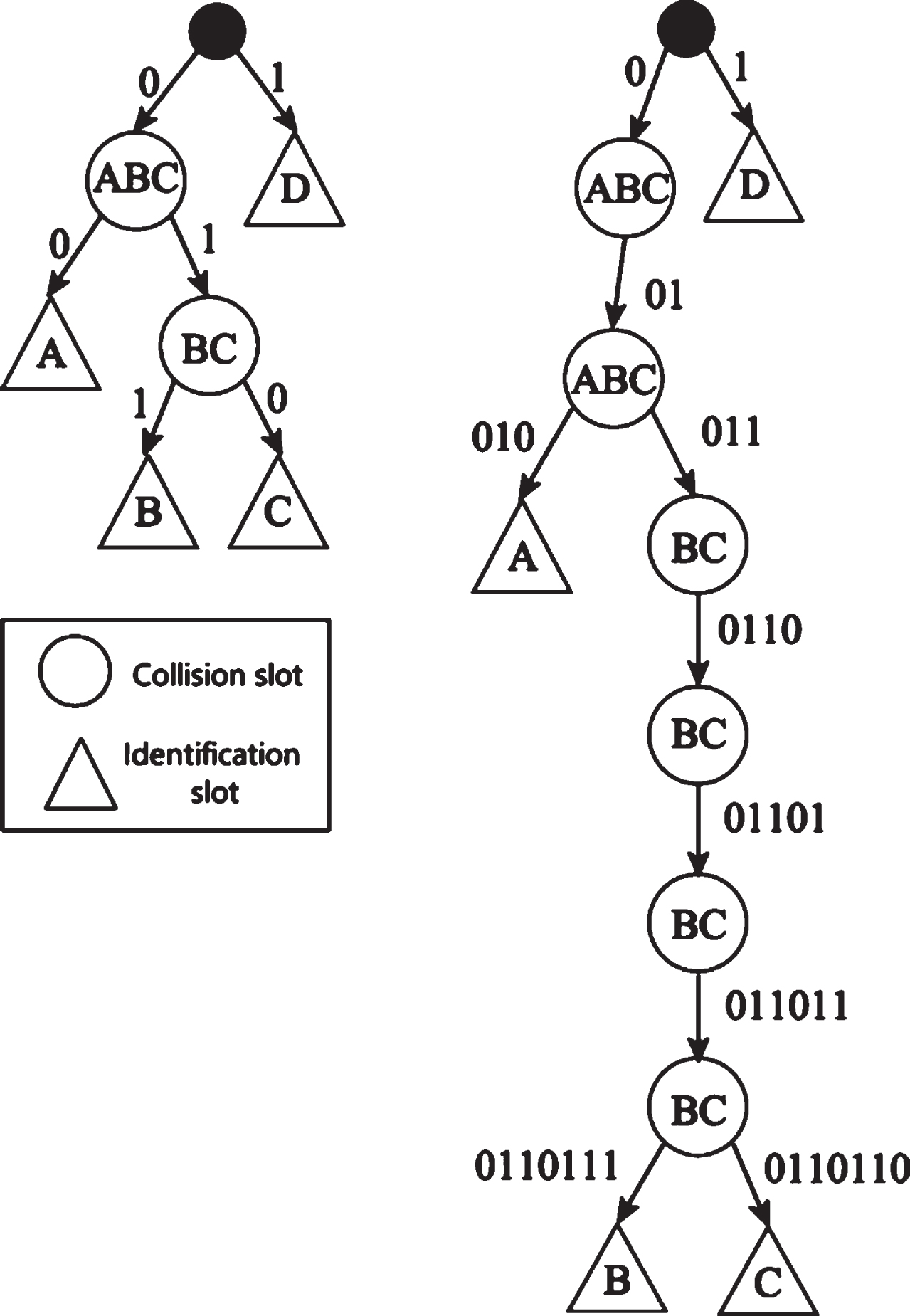
Algorithm flow with n = 1 NLHQT and n = 1 IHQT.
The NLHQT algorithm when n = 2 is shown in Table 2. Similar to n = 1, the existence of the lock instruction makes the reader only need to send “11” each time, the existence of idle child nodes are accurately determined. The comparison between the NLHQT algorithm when n = 2 and the IHQT algorithm when n = 2 is shown in Fig. 2. Through comparison, it can be seen that when tags generate continuous collisions, the NLHQT algorithm can greatly reduce the generation of collision time slots without generating idle time slots, which significantly improves the identification efficiency of IHQT.
NLHQT algorithm recognition process with n = 2
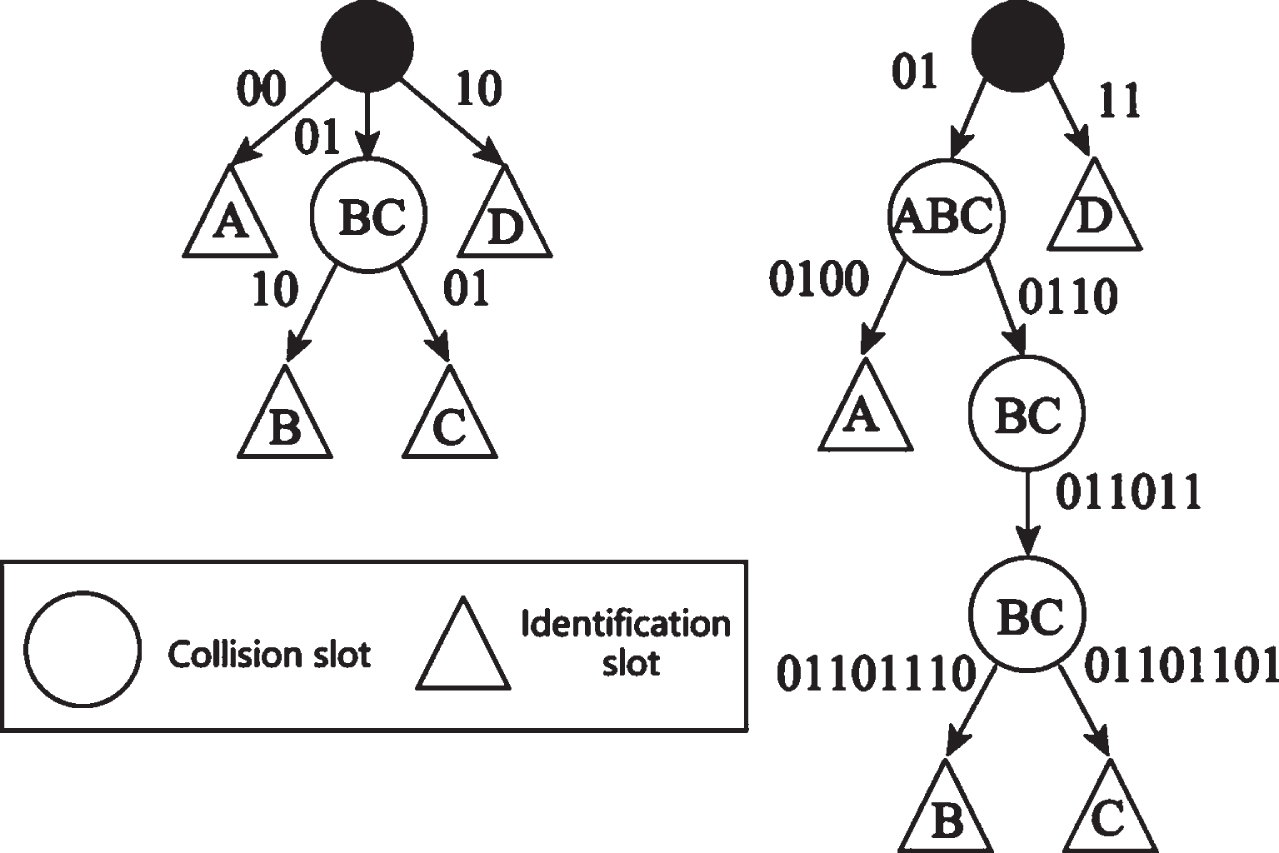
Algorithm flow with n = 2 NLHQT and n = 2 IHQT.
NLHQT algorithm instructions
(1) Request(UID, 1) lock position command, the reader judges the exact position of the tag collision, and sets the bit position of the collision to “1”, the bit position of the non-collision is “0”, and after the tag receives this instruction, its own tag is compared with the information of the reader and extract the position where the corresponding bit of the reader is “1”, a new tag sequence is formed.
(2) Request(s,m,n), where s is the updated query prefix, m is the highest bit of the tag to be identified and compared with the reader query prefix (that is, the highest bit of the detected collision), and n is the next highest bit of the tag to be identified and compared with the reader query prefix (that is, the next highest bit when collision is detected, there is no item when n = 1), from high bit to low bit, 0 ∼ p from left to right (tag code is p bit).
NLHQT algorithm steps
The NLHQT algorithm identification steps are as follows:
The reader initializes the stack to be empty, the reader sends a Request (11111111) search command, and the reader responds with all tags within the recognition range.
The reader makes a judgment on the state of the time slot based on the response of the tag. If only one tag responds, the reader successfully recognizes the tag and jumps directly to “End". If multiple tags respond at the same time, a collision time slot appears and jumps to “Send query command”.
According to the Manchester coding principle, the bit position of the collision tag is judged, and the collision position is set to “1” and the non-collision position is set to “0". The reader sends the lock instruction Request(UID,1) and locks the collision bit with “1”, a new tag sequence is formed, and the sequence is sent to the reader.
The reader executes the prediction instruction Prognosis(1) (when n = 1) or Prognosis(11) (when n = 2).
The tag uses predictive instructions to convert the 0th bit of the tag (when n = 1) or the 0th and 1st bit (when n = 2) of the tag into the corresponding decimal number a, and return a response with length of 2-bit (when n = 1) or 4-bit (when n = 2) to the reader, the total a bit of the response is “1” and the remaining bits are “0".
After receiving all tag responses, the reader judges the child nodes at the corresponding position which is marked in the sequence as useful nodes, and the rest as idle child nodes, and the useful child nodes are formed into the query prefix s which is required by the query command. Tags are identified by query prefix.
Judge whether the tag collides, if it collides, go to “send query command”; if it does not collide, it will be successfully identified.
Judge whether the stack is empty, if it is empty, all the recognition is successful; if it is not empty, the stack will pop up the query prefix and return “send query command”.
Figure 3 is the algorithm flowchart.
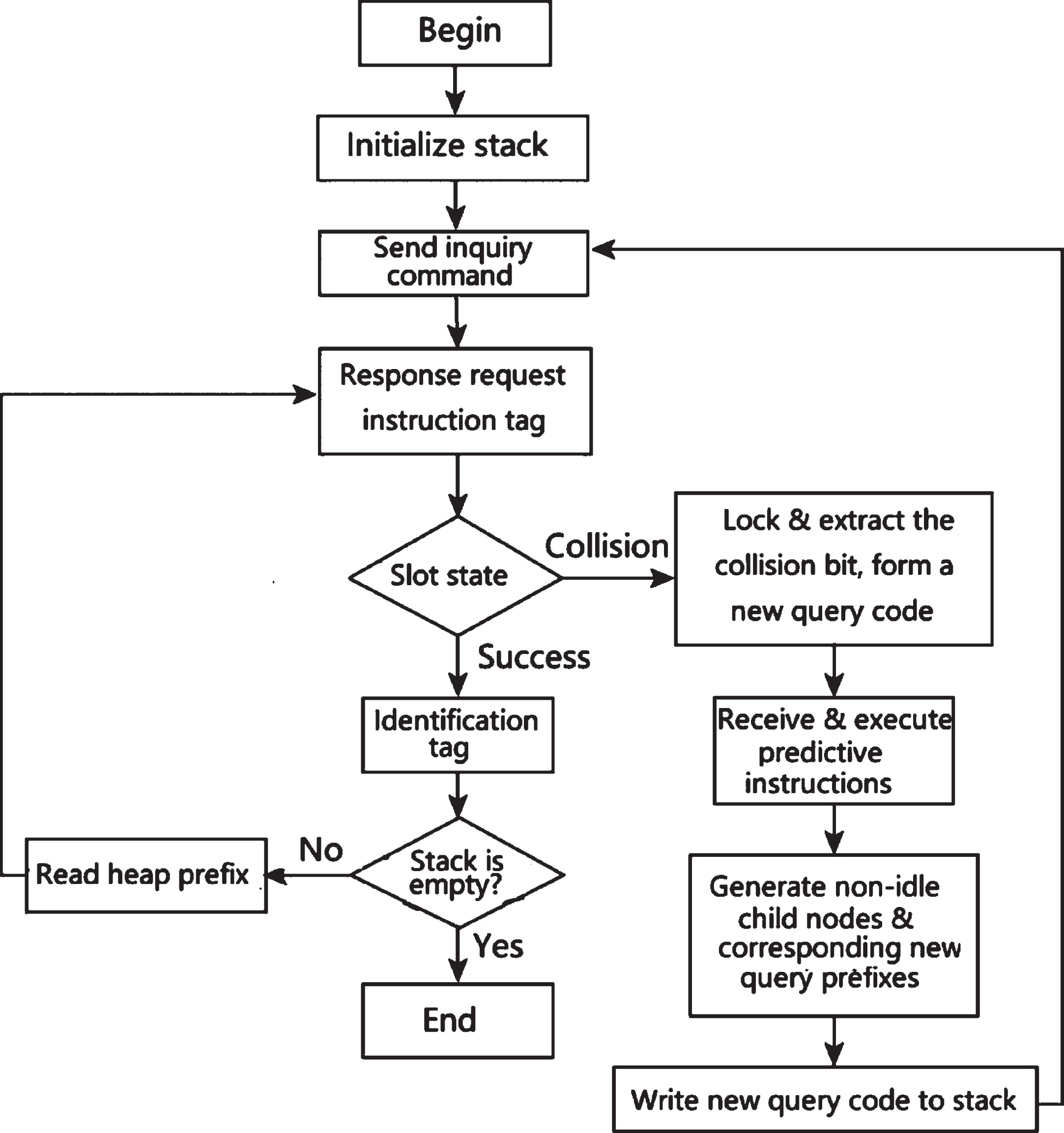
Algorithm flowchart.
Total number of time slots
In this paper, Manchester coding principle is used to lock the collision bit information, the amount of data transmission information can be reduced during the transmission process. Suppose that the tag UID information is a binary number with a length of X bits, the number of tags within the reading range of the reader is M when the x bits collide. Therefore, in the most ideal situation, M labels produce [lb M] collisions on each bit, x = [lb M] ([] is the largest integer less than or equal to this number). In the most unsatisfactory case, N tags collide at different positions, that is, x = M.
When n = 1, the total number of time slots T is Equation (1):
When n = 2, the total number of time slots T is Equation (2):
Throughput rate refers to the average rate of successfully delivering data through a certain node or a certain communication channel in a unit time, and the formula (3) can be obtained:
NLHQT algorithm complexity consists of reader communication complexity and tag communication complexity. It represents the total number of transmission bits which are required for the tag to be successfully identified. It is expressed as formula (4):
Wherein, C (x) indicates successful identification algorithm NLHQT communication complexity when x labels, L represents the number of the first communication query bits, L i denotes the number of communication bits for each query (does not comprise the first query). The bit lock instruction reduces the tag communication complexity of the new algorithm, effectively reducing L i , and the reader communication complexity of the NLHQT algorithm and the IHQT algorithm are about the same, so the NLHQT algorithm has a lower communication complexity.
The reader query times of the classic polytree algorithm is the sum of the number of successful slots, the number of collision slots, and the number of idle slots. Although the branch prediction is added by the algorithm in this paper, it will increase the number of reader queries, the branch prediction eliminates all free time slots and eliminates the reader’s query for free time slots, so the overhead of the reader is reduced to a certain extent.
In the NLHQT algorithm, the reader needs to query once for the successful time slot and twice for the collision time slot. The first query obtains the collision time slot information, and the second query obtains the position of the idle child node in the collision time slot. Assuming that the number of collision time slots, the number of idle time slots and the number of successful time slots are T1, T2, and T3, respectively, the reader query times t of the NLHQT algorithm are Equations (5):
This paper uses Matlab to build a platform simulation for the RFID anti-collision algorithm. The ideal lossless channel is selected, the total number of time slots and collisions, the number of time slots, throughput rate, communication complexity and reader overhead are counted for the classic query tree QT algorithm, hybrid query tree HQT algorithm, the improved adaptive back-locking RLAMS algorithm (based on the adaptive multi-tree AMS algorithm), IHQT algorithm and NLHQT algorithm. Taking into account the actual operation and the universality of the algorithm, too many fork trees of the query tree algorithm will increase the algorithm complexity and the degree of implementation, and increase the workload of the algorithm operation process. Since the improvement of the algorithm in the article has greatly reduced the collision time slot when n = 1 and n = 2, this article only needs to consider the situation corresponding to the binary tree and quad tree query, that is, n = 1 and n = 2. In both cases, not only the algorithm complexity and degree of implementation are low, but also the query speed is fast and the collision time slot is reduced. In order to ensure a fair comparison between the algorithms, it is assumed that the tags in the system are evenly distributed, eliminating the influence of control bytes and check redundancy, referring to the ISO18000-6 standard, randomly generating tags with an ID length of 96 bits, and the information transmission rate is 40 kb/s, the maximum number of tag simulations is 1,000, and the simulation results are averaged at 20 times.
Figure 4 shows the comparison of the total number of time slots for the QT algorithm, HQT algorithm, RLAMS algorithm, IHQT algorithm and NLHQT algorithm when n = 1 and n = 2 respectively. By counting the total number of time slots, it can be analyzed that when the number of identification tags is the same, the total number of time slots of the NLHQT algorithm when n = 1 is smaller than the QT algorithm, HQT algorithm, RLAMS algorithm, and the IHQT algorithm when n = 1, even it is smaller than the IHQT algorithm when n = 2, and the total number of time slots of the NLHQT algorithm when n = 2 is further reduced than that of the NLHQT algorithm when n = 1. Combined with the analysis in Figure 4, considering that both the HQT algorithm and the RLAMS algorithm are improvements in the combination of the quadtree query algorithm, the performance of the two algorithms has been significantly optimized when they are compared to the classic query tree QT algorithm, which is a fair demonstration of the algorithm performance in the article. The following discussion mainly focuses on the IHQT algorithm and the NLHQT algorithm under the quadtree condition, that is, when n = 2. Figure 5 shows the comparison of the number of collision slots when n = 2 for QT algorithm, HQT algorithm, RLAMS algorithm, IHQT algorithm, and NLHQT algorithm. Through the extraction of the collision bit time slot, it can be seen from Fig. 5 that due to the existence of the lock instruction, the collision time slot of the algorithm in this paper is better than that of the QT algorithm, the RLAMS algorithm and the IHQT algorithm when n = 2. The time slot is significantly reduced. With the increase in the number of tags, although the total number of time slots in the NLHQT algorithm gradually increases, because the prediction instructions avoid the generation of idle time slots, and the lock instructions reduce the generation of collision time slots, the NLHQT algorithm is better than the other four algorithms, the performance has obvious advantages, which can effectively reduce the total number of time slots and collision time slots.
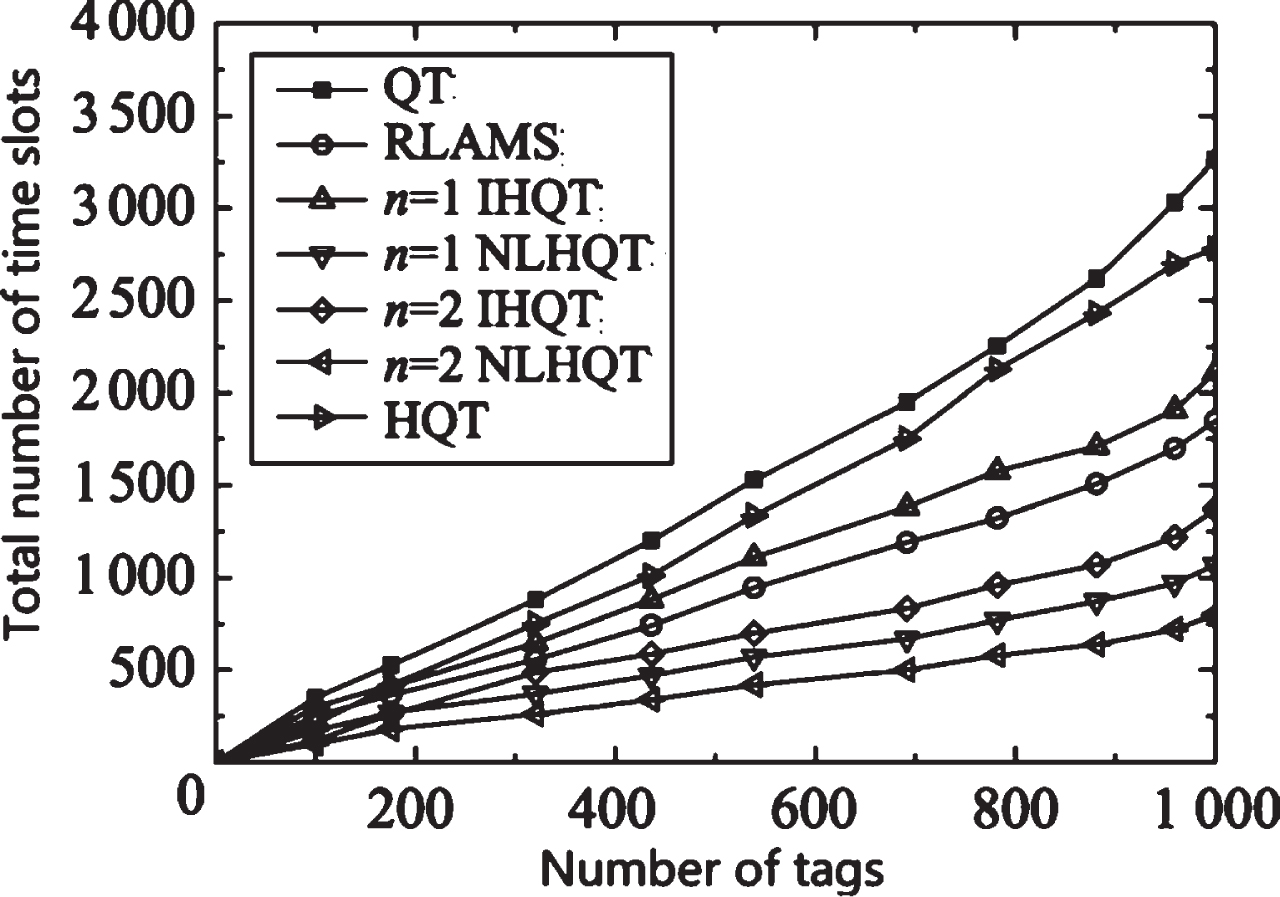
Comparison of total number of slots.
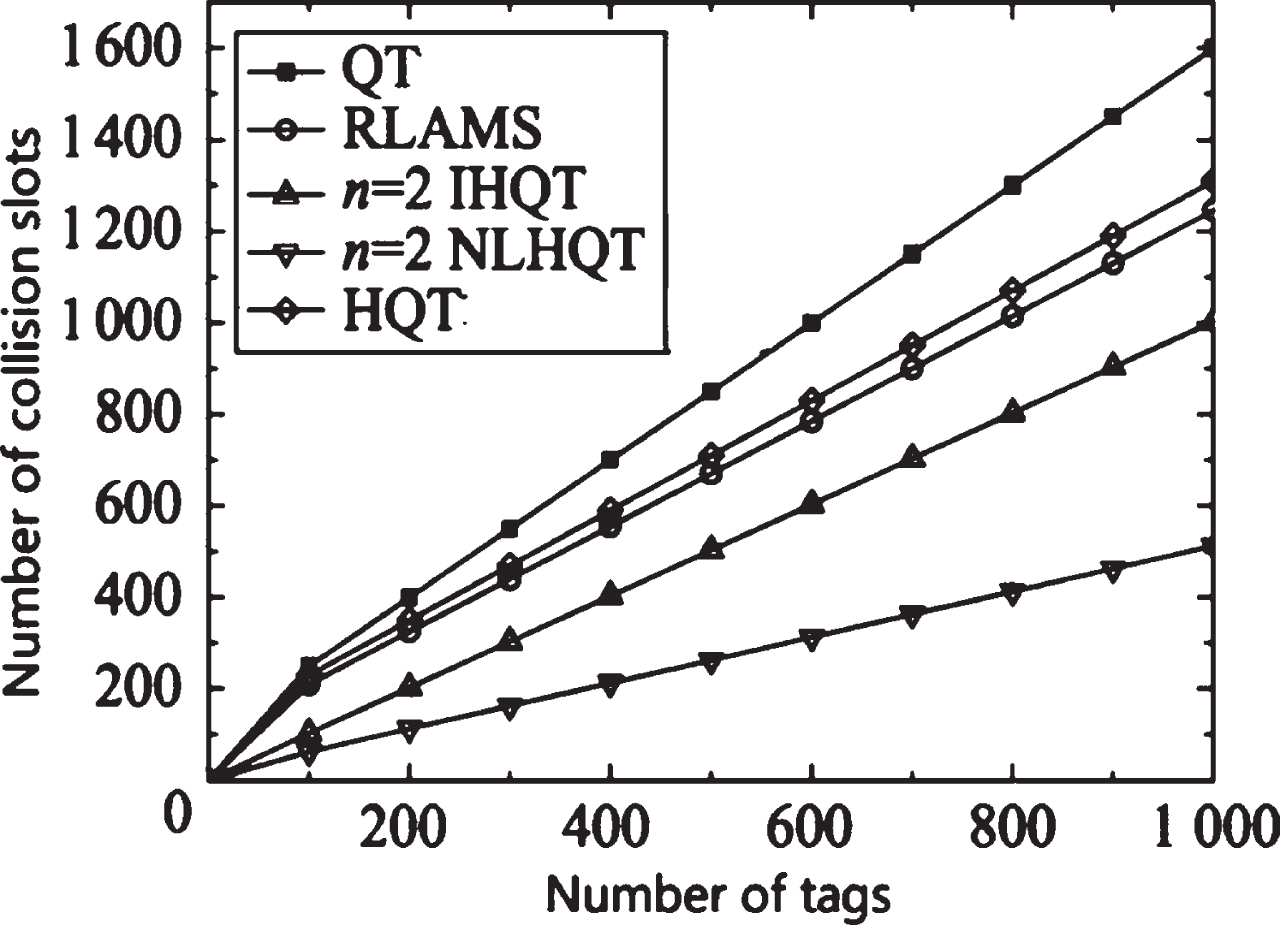
Comparison of the number of collision slots.
Table 3 shows the performance comparison of QT algorithm, HQT algorithm, RLAMS algorithm, IHQT algorithm and NLHQT algorithm when n = 1 and n = 2 respectively. It can be seen from the table that the algorithm in this paper can not only effectively eliminate idle time slots by adding predictive instructions for additional queries, but also greatly improve the query efficiency and query rate of readers by effectively reducing collision time slots. It can be seen from the statistics of the recognition time that the algorithm in this paper can greatly reduce the recognition time of the algorithm and effectively improve the anti-collision performance. Therefore, the algorithm in this paper has better overall performance than other algorithms.
Algorithm performance comparison
Figure 6 shows the comparison of throughput rates of QT algorithm, HQT algorithm, RLAMS algorithm, IHQT algorithm and NLHQT algorithm when n = 2. Based on the total number of time slots, the collision bit x and the total number of time slots T are calculated according to formula (4), the throughput rate is obtained. From the figure, it can be seen that the throughput rate of the algorithm in this paper is about 0.85, which is significantly higher than other throughput rates of the three algorithms, these further verify that the algorithm in this paper can effectively reduce the total time slot T while reducing the collision bit x through the lock instruction. Therefore, the NLHQT algorithm has higher search efficiency and speed.
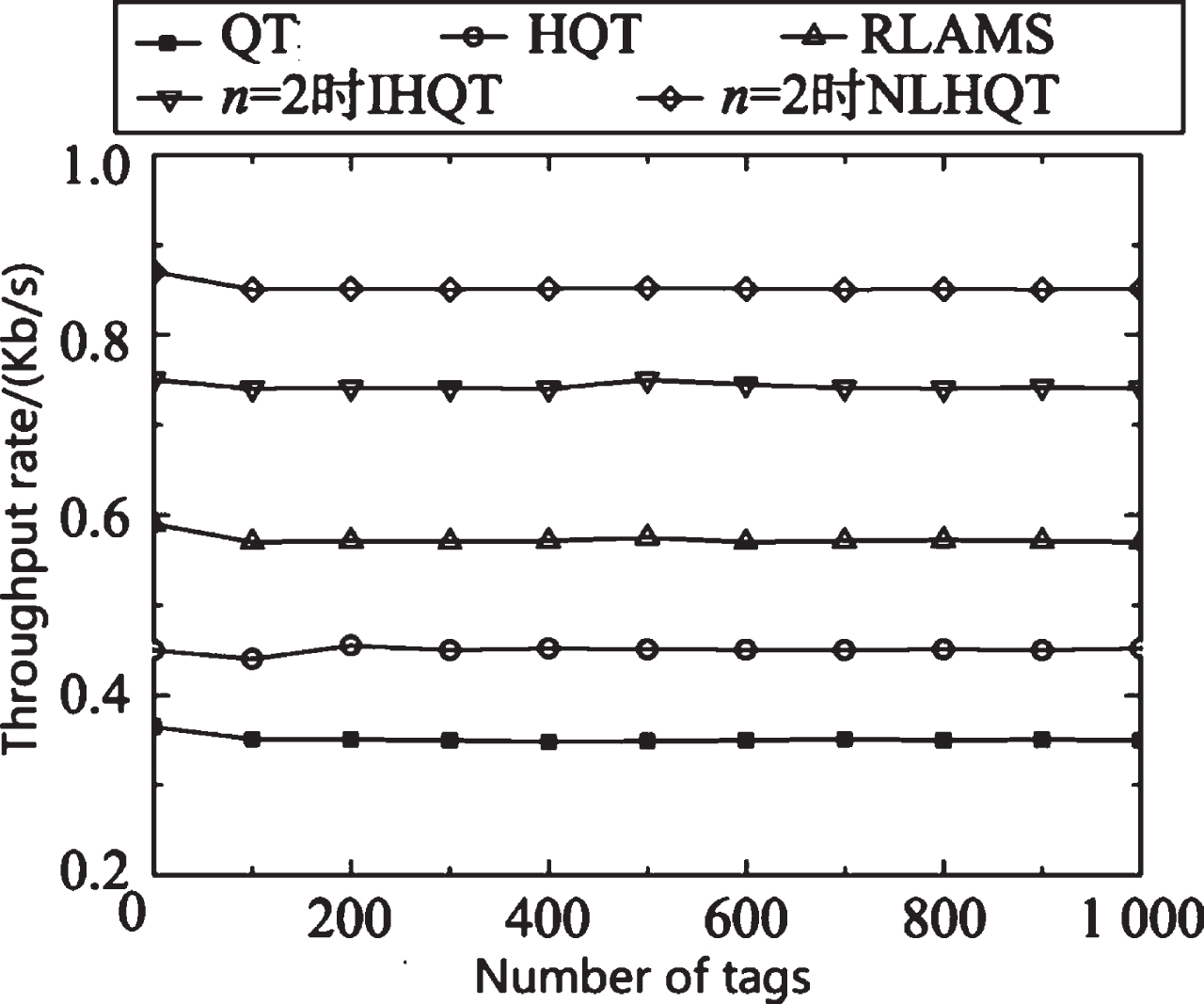
Comparison of throughput rates.
Figures 7–9 are the statistics comparisons of tag communication complexity, reader communication complexity and total communication complexity under the condition of n = 1 and n = 2 with QT algorithm, HQT algorithm, RLAMS algorithm, IHQT algorithm and NLHQT algorithm. It can be seen from Fig. 7 that the NLHQT bit lock instruction greatly reduces the number of communication bits that the tag is queried. Through statistical average analysis, it is found that the algorithm in this paper greatly simplifies the complexity of tag communication. It can be seen from Fig. 8 that the reader communication complexity of NLHQT and IHQT are roughly the same. Due to the branch prediction for idle slots, the reader communication complexity is significantly reduced when it is compared to other algorithms. Therefore, it can be seen from Fig. 9 that the total communication complexity of the algorithm in this paper is significantly lower than the other three algorithms, which shows that the locking of the collision bit and the branch prediction for the idle slot can effectively reduce the communication complexity between the reader and the tag. Although the communication complexity of the NLHQT algorithm has increased with the increase in the number of tags, compared with the other four algorithms, the growth rate is obviously slower.
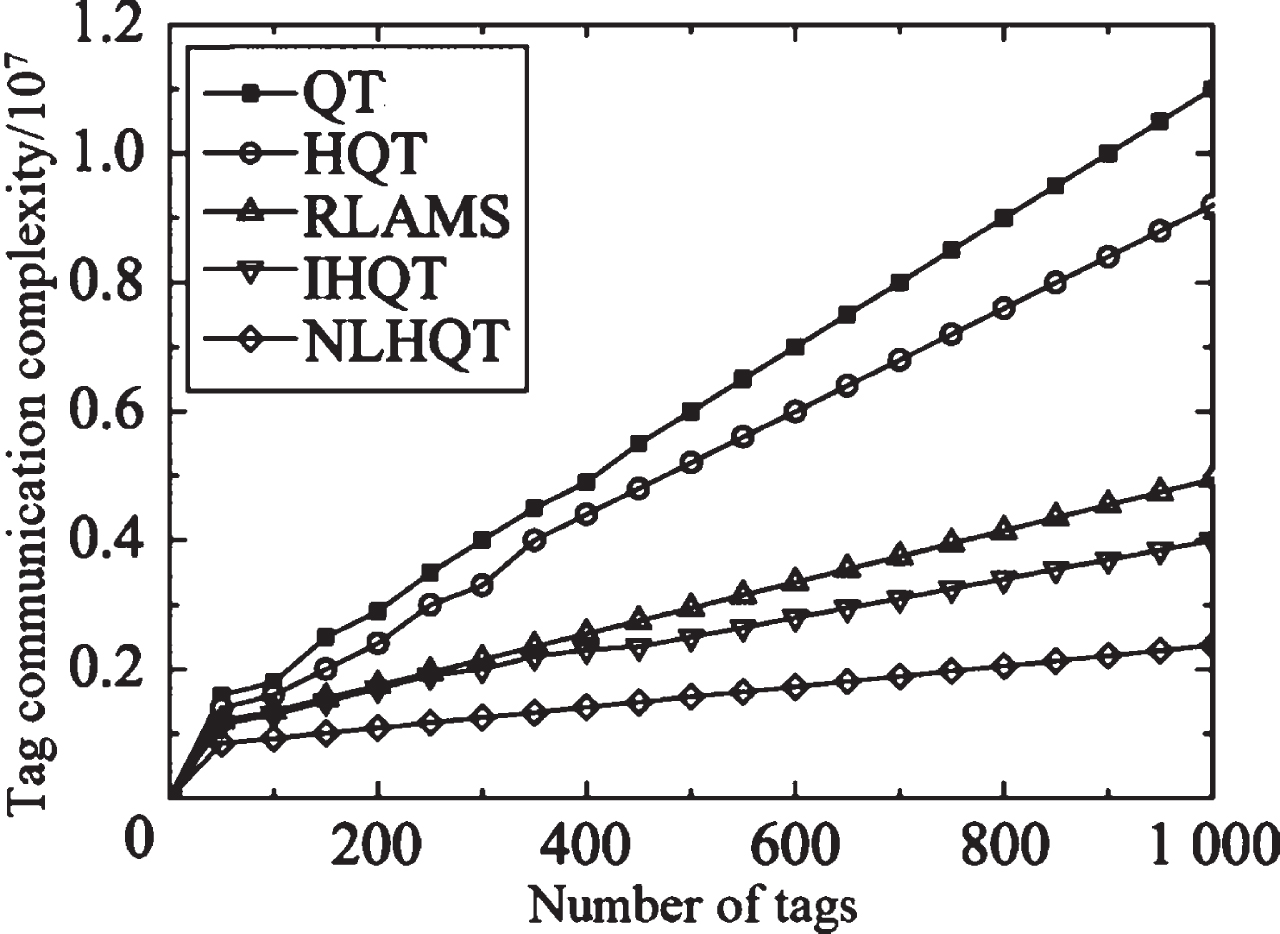
Comparison of tag communication complexity.
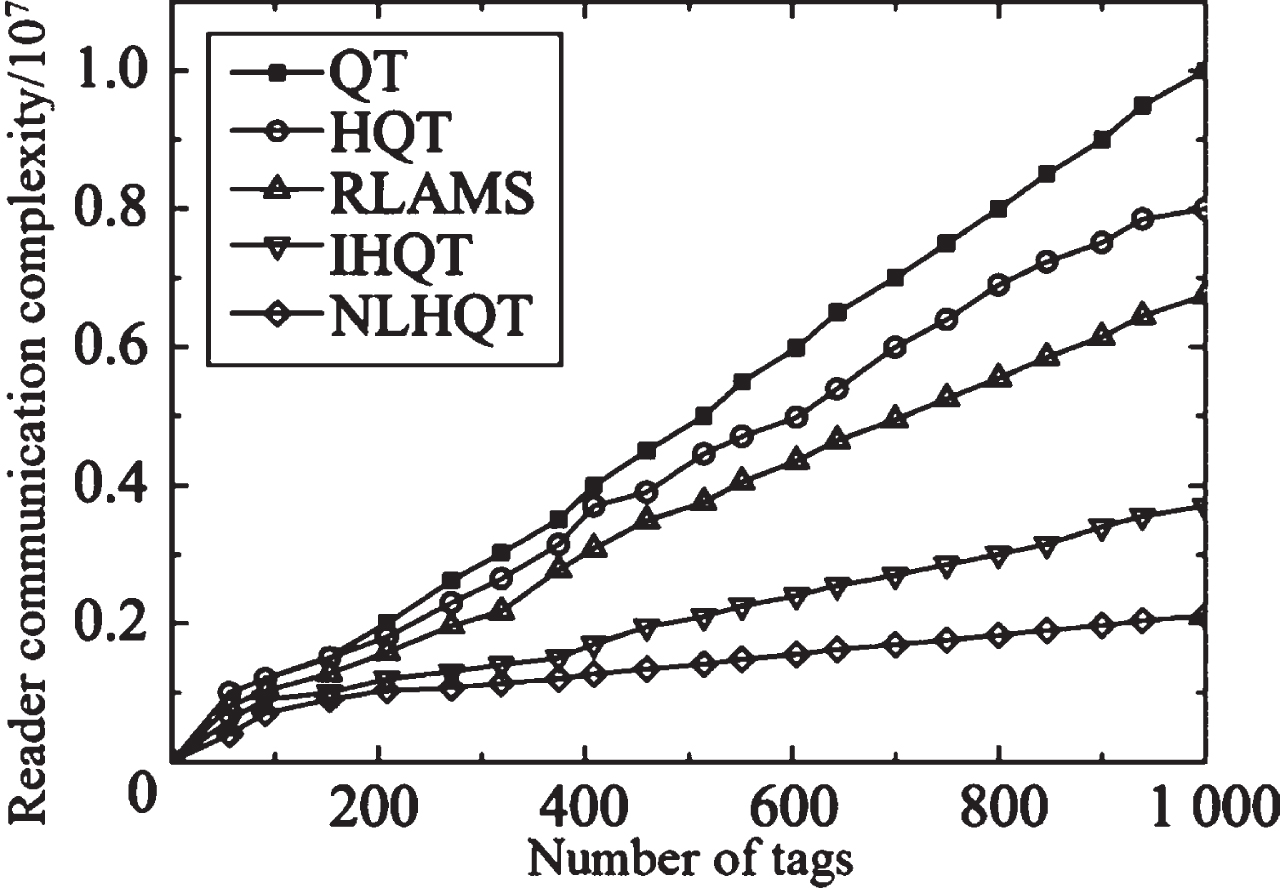
Comparison of reader communication complexity.
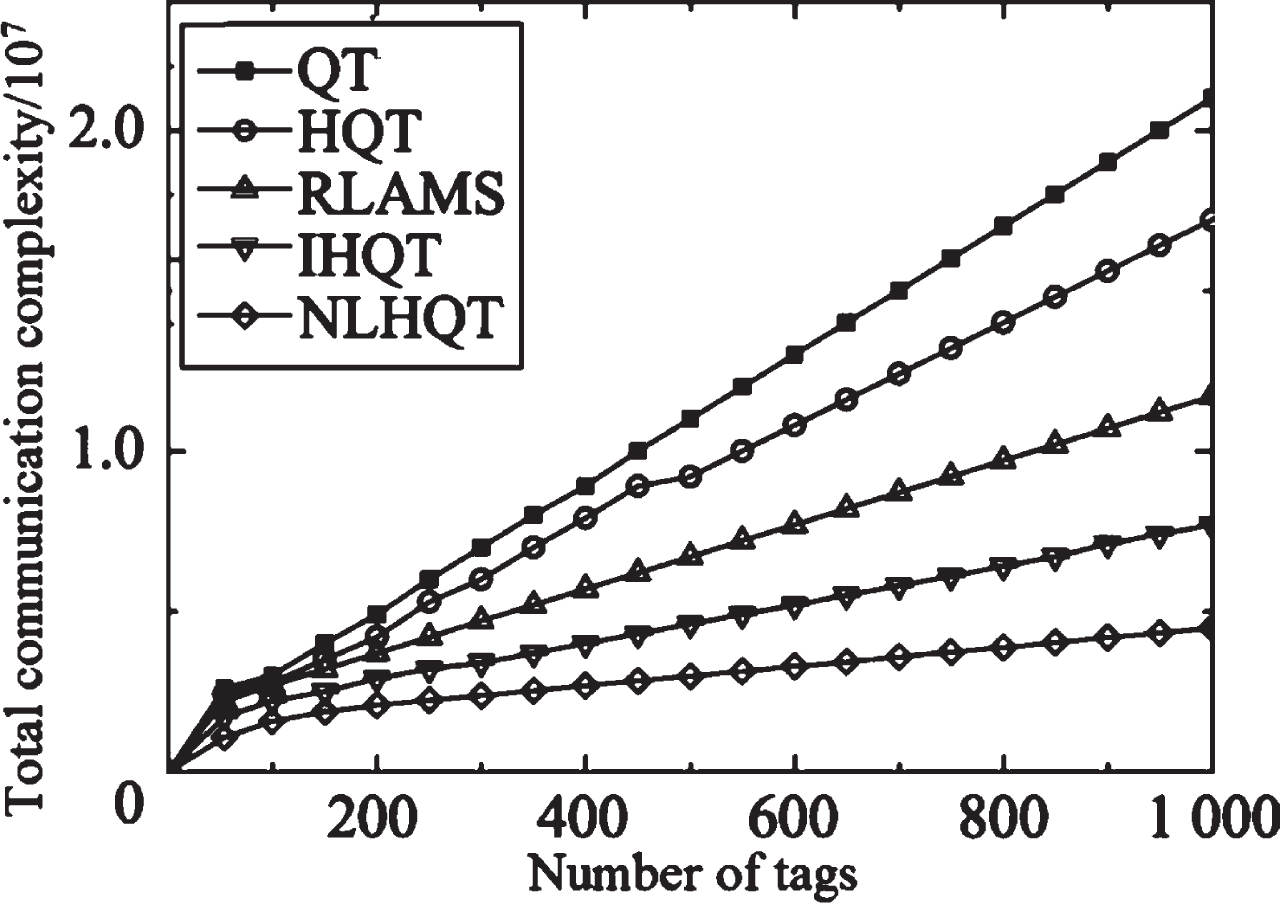
Comparison of total reader communication complexity.
Combining n = 1 and n = 2, Fig. 10 shows the change curve of the number of reader queries of the QT algorithm, HQT algorithm, RLAMS algorithm, IHQT algorithm, and NLHQT algorithm as the number of reader tags increases. It can be seen from Fig. 10 that the NLHQT algorithm has fewer queries than the readers of other algorithms. This is because although the IHQT algorithm adds additional query and collision time slots. In the face of binary tree and quad tree conditions, the reader query times are more than other algorithms, but the NLHQT algorithm not only eliminates idle time slots on the basis of IHQT algorithm, but also greatly reduces collision time slots by relying on lock instructions. The algorithm in this paper can reduce the number of reader queries when it is compared with other algorithms.
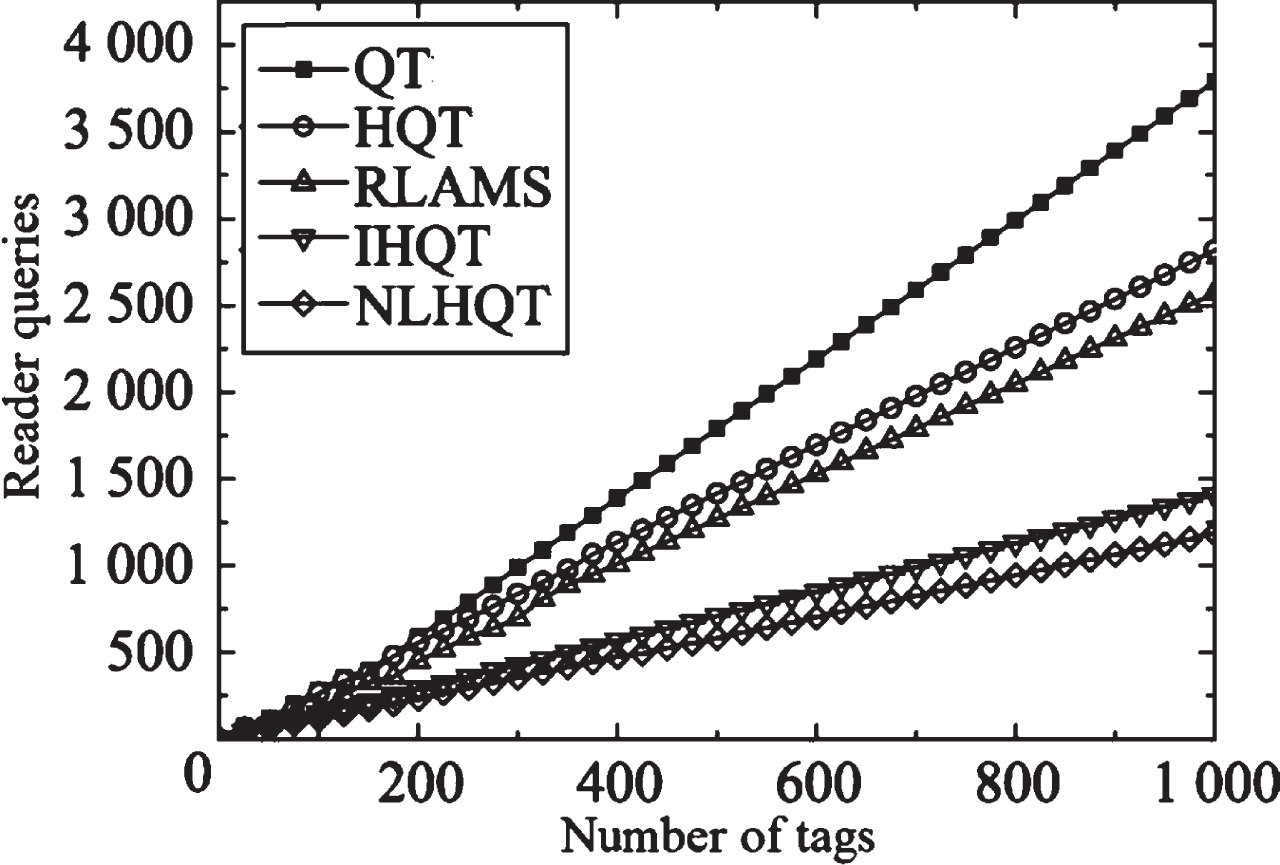
Reader overhead comparison.
In this paper, a new lock-bit hybrid query tree algorithm is proposed, and the algorithm’s lock-bit strategy and the basic idea of eliminating idle time slots are explained. The algorithm’s identification process is described in detail, and the performance of the algorithm is guaranteed while reducing the complexity of the algorithm, this article sets the parameters of n = 1 and n = 2 for performance analysis of the NLHQT algorithm, that is, optimization on the basis of binary trees and quad trees, which further makes the algorithm easier to implement. Matlab simulation software is used to analyze and compare the performance characteristics of several algorithms in the total number of time slots, number of collision time slots, throughput rate and communication complexity, it can be seen that the algorithm in this paper can effectively reduce the generation of collision time slots and eliminate idle slots. It can reduce communication complexity and increase throughput rate, so as to achieve the purpose of improving recognition efficiency, and the overall performance is improved. In addition, the algorithm in this paper is suitable for query algorithms in the case of binary tree and quadtree at the same time, with a wide range of available, low algorithm complexity, and easy implementation.
A binary sorting tree is a useful compromise. Arrays are more convenient to search, and you can use subscripts directly, but it is more troublesome to delete or insert certain elements. In contrast to linked lists, deleting and inserting elements is fast, but searching very slow. A binary sorted tree has both the benefits of a linked list and the benefits of an array. It is more useful for processing large batches of dynamic data. Disadvantages of binary search trees are that sequential storage may waste space (in the case of incomplete binary trees), but it is more efficient to read a specified node O(0). Chained storage wastes less space when the binary tree is relatively large, but the efficiency of reading a specified node is low O(nlogn). When the algorithm in this paper uses a binary sorting tree, it may also face this defect.
Footnotes
Acknowledgments
This work was sponsored by Scientific Research Project (NO. 20C1085) of Hunan Provincial Education Department, China