
Abstract
Data aggregation often occurs due to data collection methods or confidentiality laws imposed by government and institutional organisations. This kind of practice is carried out to ensure that an individual’s privacy is protected but it results in selective information being distributed. In this case, the availability of only aggregate data makes it difficult to draw conclusions about the association between categorical variables. This issue lies at the heart of Ecological Inference (EI) and is of growing concern for data analysts, especially for those dealing with the aggregate analysis of a single, or multiple, 2
As an alternative to ecological inference, one may consider the Aggregate Association Index (AAI). This index gives the analyst an indication of the likely association structure between two categorical variables of a single 2
Keywords
Introduction
The 2
When dealing with the analysis of aggregated categorical data, the utilisation of such data can be traced back to Fisher’s comments in 1935, see [3, page 48], where he stated:
“Let us blot out the contents of the table, leaving only the marginal frequencies. If it be admitted that these marginal frequencies by themselves supply no information on the point at issue, namely, as to the proportionality of the frequencies in the body of the table we may recognize that we are concerned only with the relative probabilities of occurrence of the different ways in which the table can be filled in, subject to these marginal frequencies.”
These comments suggest that the marginal frequencies are not important for inferring the unknown cell values of a 2
The popularity and dissemination of many methods and computational platforms for the analysis of aggregated categorical data increased significantly after King [13] introduced his suite of EI techniques in 1997. King et al. [14] introduced new EI methodologies including the use of Markov Chain Monte Carlo methods to extend King’s 1997 ecological inference approaches. Steel et al. [15] introduced the homogeneous model designed to overcome many of the assumptions underlying the previous EI techniques developed.
More recently, Greiner and Quinn [16] proposed a method to analyse the association between the variables of a general R
In terms of software, EI and EzI were developed by King [21, 22] to perform a range of EI techniques described in his 1997 book and include diagnostics and graphical outputs. In the R programming language, one can also refer to the package eco by Imai et al. [23] for the EI of multiple 2
Despite the growing number of solutions to, and discussions of issues concerned with, EI the proposed techniques require imposing untestable assumptions on the unknown individual-level data. To overcome this problem Beh [25] proposed an alternative strategy by developing the Aggregate Association Index (AAI). The AAI in an index that is bounded by
Therefore, this paper will provide an extension of the AAI for the analysis of multiple, or stratified, 2
1893 New Zealand voting data
The data
Prior to 1893, women were not granted the right to cast a formal vote at national elections or referendum anywhere around the world. As a result, “suffragettes” were organised to fight for equal voting rights. The word “suffragette” was first used in a British newspaper article in 1906 to describe women seeking the right to vote through organised protest (
In February 1918, the British government introduced an Act giving women their right to vote if their age was at least 30 years and either possessed property or rented for at least
The data used in this paper is reproduced from
In the 1893 election, the first national election where men and women were given equal rights to vote, 90,290 women visited polling booths across New Zealand to exercise their right. This figure represents 82.5% of the number of women who registered to vote at the election; a significant turnout at the start of women suffrage movement. A closer examination of the 1893 New Zealand data reveals that there were four metropolitan electorates (the cities of Auckland, Wellington, Christchurch and Dunedin) where the number of votes recorded was more than the number of names listed on the role of registered voters. There were three electorates (Westland, Bruce and Awarua) where only one candidate stood for election and so there was no contest and the four Mauri electorates did not record the number of voters. Therefore, of the original 66 electorates throughout New Zealand, data were only available from 55 electorates, which will be the focus of our discussion and analysis. The voter turnout of the male and female voters in the 55 electorates of the 1893 election are summarised in the 2
1893 New Zealand voter turnout summary by gender
1893 New Zealand voter turnout summary by gender
Fortunately for analysts studying aggregate data, the number of men and women who did, and did not, turnout to vote was recorded for each electorate. Therefore, Table 1 can be modified to yield 55 stratified 2
Notation for the cell, and marginal, frequencies, of the
For each of the 55 New Zealand electorates that we are studying, a 2
For the New Zealand voting data, the row variable consists of the gender categories Female (
For the
When the cell frequencies of each of the 2
From their review, Klein and Linton [29] showed that the ExactC test, Nass test (Nass [35]) and Xu test (Xu [37]) exhibited equally reliable performance in the simulation study undertaken. Furthermore, Klein and Linton [29] found that the ExactC test and Nass test perform equally well. However, the ExactC implies complexity when stratum sample size and the number of strata are large. For simplicity, the ExactC test shall not be considered further in this study due to the large sample size and large number of the electorates in 1893. Therefore, we consider here the Nass and Xu tests of homogeneity of the
The analysis of stratified 2
2 tables when cell values are unknown
Ecological Inference (EI)
While Section 3 considered the case where the cell frequencies at the electorate level are known, consider now the case where this information is assumed unknown. In general, ecological inference allows for the analyst to draw individual-level (at the joint cell frequency/proportion level) conclusions given only the aggregate, or marginal, information [13, 14, 38, 39, 11]. Obviously, a wide range of different numbers could be substituted for the cell values without contradicting its row and column marginals. This logic is referred to in the literature as the method of bounds – see [40] for more details. Furthermore, there are potentials of drawing incorrect conclusions (i.e. paradoxes) at an individual level when using only the aggregate-level data. These paradoxes are well-known to data analysts when working with unknown-cell-value contingency tables and can be summarised as ecological fallacy, Yule-Simpson’s paradox and aggregation bias.
The first issue when drawing individual-level conclusions given only the aggregate-level data is “ecological fallacy”[41, 38]. This states that the result of a particular study at an aggregate level (e.g. election year) does not necessarily imply the same result at an individual level (e.g. voters from different electorates – Table 2). Individual-level information is often lost in the process of aggregation, and thus, all EI methods make assumptions about the data to compensate for the loss of information [11].
The second issue is “Yule-Simpson’s paradox” [42, 43]. This is a situation in which individual-level conclusions derived from different groups may be reversed when the groups are combined. For the 1893 NZ election, it means that the association between the variables at the electorates may be opposite to that at the year level. The Yule-Simpson’s paradox can be minimised when causal relations are brought into consideration [44]. For a more comprehensive history and understanding of the Yule-Simpson’s paradox, one can refer to [45, 46].
Graphical illustration of the AAI concept for the 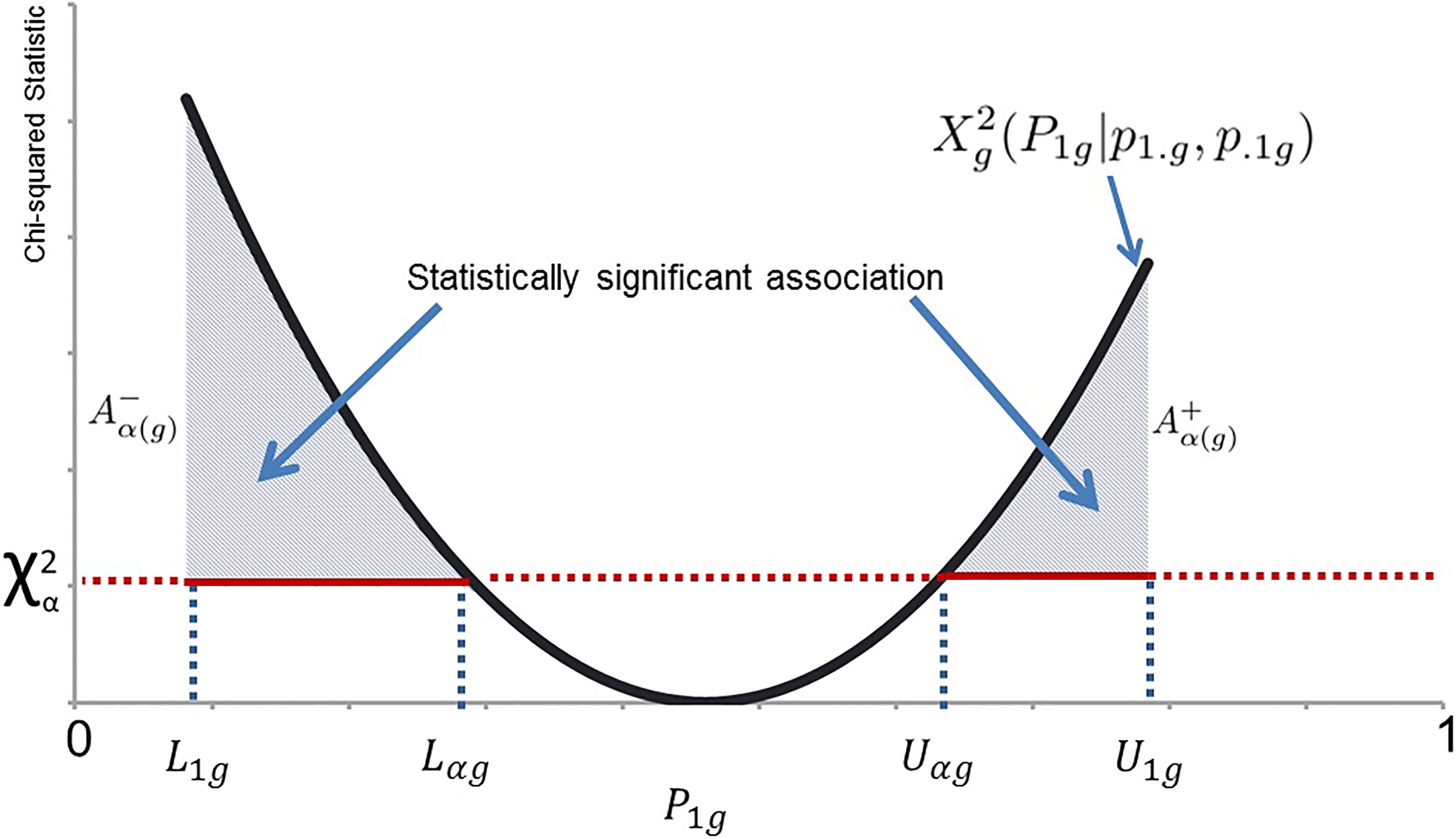
The third issue is the “aggregation bias”. Specifically, aggregation bias refers to the discrepancies between the expected values of estimators using the aggregate-level data and estimators using the indivi-dual-level data [11]. For multiple contingency tables, this occurs when the conclusions at the aggregate level does not accurately reflect the underlying association between the variables at the individual level. In King’s book [13, Chapter 9.2], he stated that this paradox is one of many main difficulties in providing accurate results in ecological inference and proposed several approaches to detect, assess and avoid aggregation bias.
To date, the ecological inference problem is still among the more widely encountered statistical problems in social sciences and other sectors such as epidemiology, geography, sociology, economics, and history research [39, 14]. To overcome the difficulty in ensuring the integrity of the untestable assumptions in EI, and the paradoxes given only marginal information, Beh [25, 26] proposed an alternative approach named as Aggregate Association Index (AAI). The AAI and its extension are the main focus of this study and shall be discussed further in Sections 4.2, 5 and 6.
Analysing the association between two or more categorical variables typically requires answering at least one of the following three questions:
Is there sufficient evidence in the sample to infer that a statistically significant association exists between the categorical variables? What is the best measure to quantify the direction of the association between the variables? What appropriate techniques can be used to visualise the association between the variables?
For the 1893 New Zealand election data, the first question can be answered by performing a Pearson chi-squared test of independence between Gender and Turnout. For the
and the statistical significance of the statistics can be assessed by comparing
A simple, yet popular, means of answering the second question is to assess the direction and magnitude of the association between the variables using Pearson’s product moment correlation. This correlation, defined for the
takes on a value ranging from
To answer the third question, correspondence analysis (CA) can be performed to provide a visual depiction of the association between the two or more categorical variables. Very little attention has been paid to the case of performing a correspondence analysis on a 2
While these strategies are commonly used to study the association between categorical variables when the cell frequencies of Table 2 are known, they are not appropriate for the analysis of aggregate data. Although, when only the marginal information of a single 2
Consider the definition of
The quadratic function of Fig. 1 is a graphical depiction of Eq. (4.2) with respect to
When only marginal information is known, the value of
Homogeneity test results – Nass test and Xu tests
Since
Given the aggregate data, one may therefore conclude that there exists a statistically significant association between Gender and Turnout at the
By taking into account the above properties of
where
For a given level of significance,
The index
is referred to as the aggregate positive association index (AAI
is referred to as the aggregate negative association index (AAI
The discussions of the AAI made by Beh [25, 26] were confined to the analysis of aggregate data for a single 2
AAI curves from the 55 electorates in the 1893 New Zealand election.
While not the focus of this paper, the large AAI may be a result of either the large sample size or the configuration of the marginal information (or a combination of both). For more information on this issue, the interested reader is directed to Beh et al. [49] who introduced two strategies that help assess and minimise the impact of an increasing sample size of a 2
The overall AAI curve
While Fig. 2 shows that, for each electorate of the 1893 New Zealand election, we can gain an understanding of voting behaviour between the genders from only the aggregate data, it is also of interest to determine the characteristics of the AAI and AAI curve for that year. By doing so provides some insight into variations from one election period to another based on limited information through the aggregate data. Such further insights will be left for further discussion, but a preliminary study of this issue has been undertaken by Beh et al. [27]. For example, since the AAI of each electorate in the 1893 New Zealand data is at least 99.0 this suggests that the (overall) AAI for year 1893 will exceed 99.0. To examine how an overall AAI may be determined for the 55 electorates, consider Pearson’s chi-squared defined for the
Before we derive an expression for the overall AAI for the 1893 election, consider first that the equation of a general functional form of a parabola at a point
where
By comparing Eq. (10) with Eq. (11), the leading coefficient of the AAI curve for the
and the focus’s coordinates are
The curvature coefficient of the AAI curve at the vertex point can also be defined as
The key features of the AAI’s quadratic function, just like all quadratic functions, are the bounds of
In terms of the simultaneous depiction of the AAI curves given in Fig. 2, we shall now turn our attention to finding the “best” overall AAI curve for the 1893 election. Section 5.2 describes how this overall AAI curve can be found.
Since there are 55 electorates in the 1893 New Zealand election, there are also 55 vertex points and 55 focus points. Therefore, the mean vertex point is
where
Note that, when calculating these mean quantities, we give equal weight to each of the
where
Therefore, when only the aggregate data is available at the electorate level, the overall AAI curve for the 1893 New Zealand election can be defined by the chi-squared statistic
where
Since an AAI curve, depicted by Eq. (4.2), is bounded by Eq. (5), the overall AAI curve defined by Eq. (19) also requires restriction on its bounds. The overall bounds can be defined in terms of the marginal information by
Overall AAI curve (dashed line) for the 1893 New Zealand election.
See, for example, Hudson, Moore et al. [11].
When testing the association between the dichotomous variables at the
Therefore, by utilising Eq. (19), we can also determine the AAI for the 1893 election, across all electorates, at the level of significance
where
and
respectively.
Therefore, given only the marginal information that is available in the stratified data of the 1893 New Zealand election, the overall AAI curve for the 1893 election can be determined from Eq. (19) and is
where 0.260
Four clusters of the AAI curves in the 1893 New Zealand election by mclust [1–4: cluster number].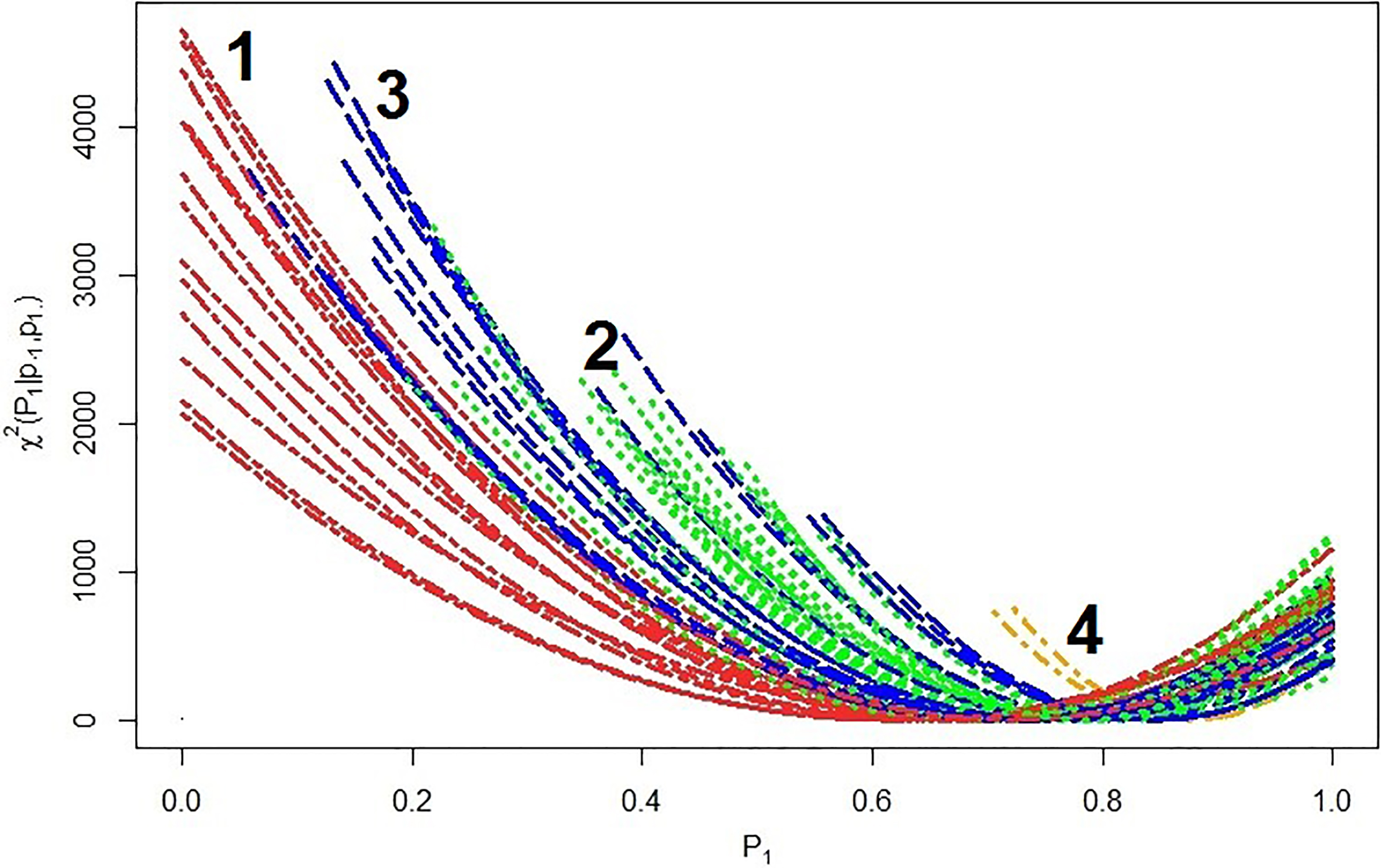
The AAI curve of Eq. (25) is given by the quadratic relationship between the chi-squared statistic and
Bounds, vertex, and curvature
When only the aggregate data is available for analysis, the analyst may not just be interested in determining the AAI for specific electorates. Instead, there may also be interest in determining clusters of electorates that exhibit homogeneous, or heterogeneous, voting behaviors. There are a number of methodologies that may be considered for clustering electorates. These include, but are not limited to, hierarchical clustering [52, 53], centroid-based clustering [53, 54] and model-based clustering [53]. However, despite the popularity of many of these techniques, Fraley and Raftery [55] have pointed out some fundamental issues that are not dealt with using traditional cluster analysis procedures. These issues include, but are not restricted to, objectively identifying how many clusters should be considered, which of the variety of clustering approaches should be used and when, and how outliers are to be dealt with. To remedy these, and other interrelated issues, Fraley and Raftery [55] have proposed a clustering technique based on selecting the best Bayesian model using the Bayesian information criteria (BIC) [56]. The framework of their approach lies with the Gaussian mixture model and the wide selection of models that stem from the eigen-decomposition of the covariance matrix,
For the 1893 election, the values of
Model-based Clustering using mclust
In order to study the features of the electorate-specific AAI curves, we shall be using the software package
Fitted cluster-specific AAI curves (solid lines) and fitted election-specific AAI curve (dashed line) for the 1893 New Zealand election [1–4: cluster number].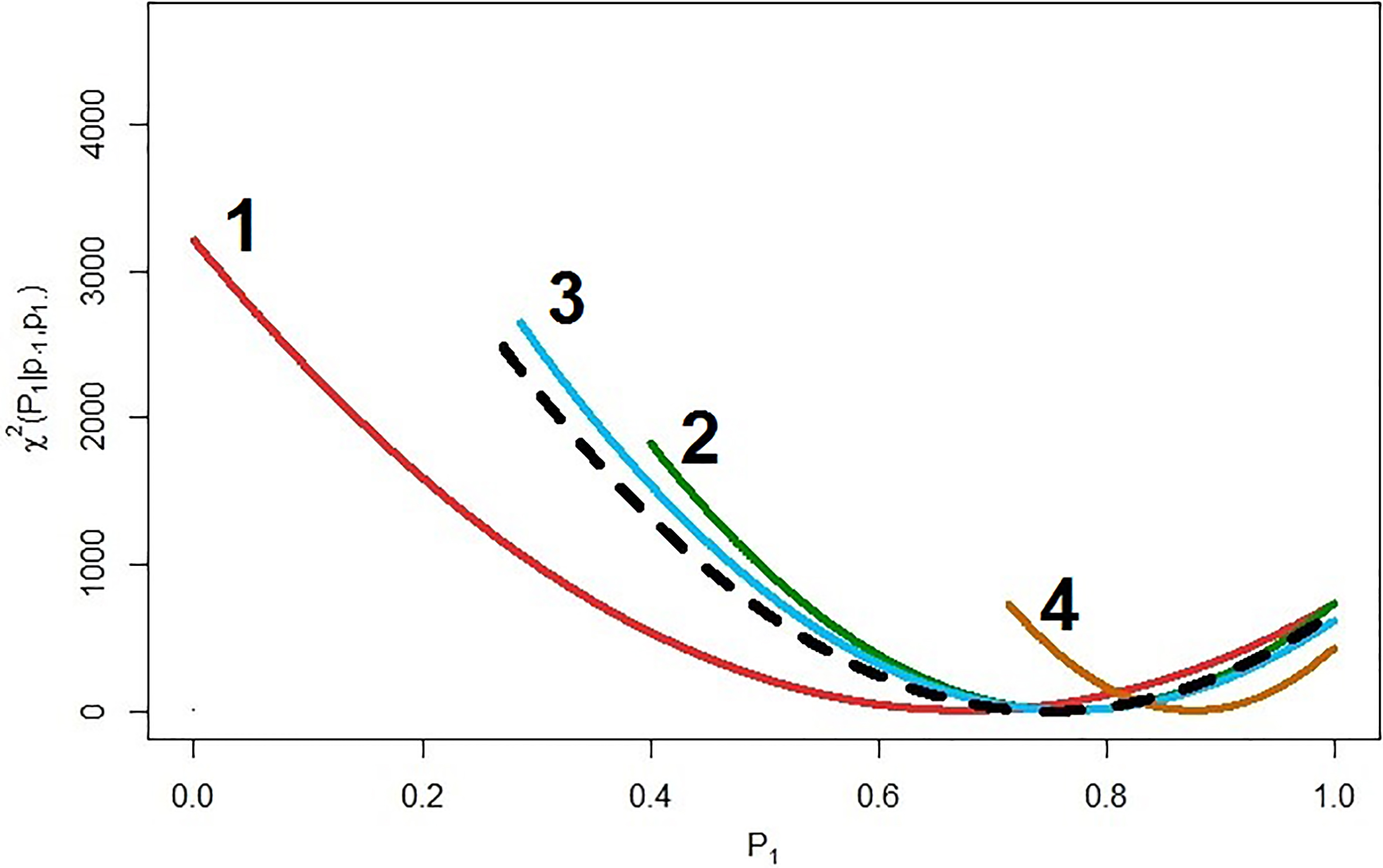
AAI, AAI+ and AAI- for the fitted electorate-specific curves and election-specific curve in the 1893 New Zealand election
When clustering the characteristics of the AAI curve outlined in Section 6.1 for the electorates of the 1893 New Zealand election,
Since
Now that the overall AAI curves for each of the four clusters has been determined and graphically depicted in Fig. 5, we can now find the AAI of each cluster as well as their AAI+ and AAI- quantities. Table 4 provides a summary of these values for the four cluster-specific AAI curves and one election-specific AAI curve. It is immediately clear from this table that, given only the marginal information, there is evidence of a strong association between the voters’ gender and whether they turned out to vote in the 1893 New Zealand election. In fact, this association is far more likely to be negative than positive suggesting that registered male voters were more likely to turnout and vote than female registered voters.
The strength of the positive and negative association is not the same for each of the identified clusters. For example, Clusters 1 and 3 are far more likely to exihibit a negative association structure between the two variables than Clusters 2 and 4. While Clusters 1 and 3 are nearly 10 times more likely to have a negative association than a positive association, Cluster 2 is only 4 times more likely to have such an association structure while a negative association in Cluster 4 is only about 3 times more likely than a positive one.
To provide a better understanding of the electorates’ voting behaviour in terms of geographical distribution when only analysing the aggregate data, the electoral district boundaries were approximated by using the region information in
New Zealand map with 1893-election electorates clustered by mclust [1–4: cluster number].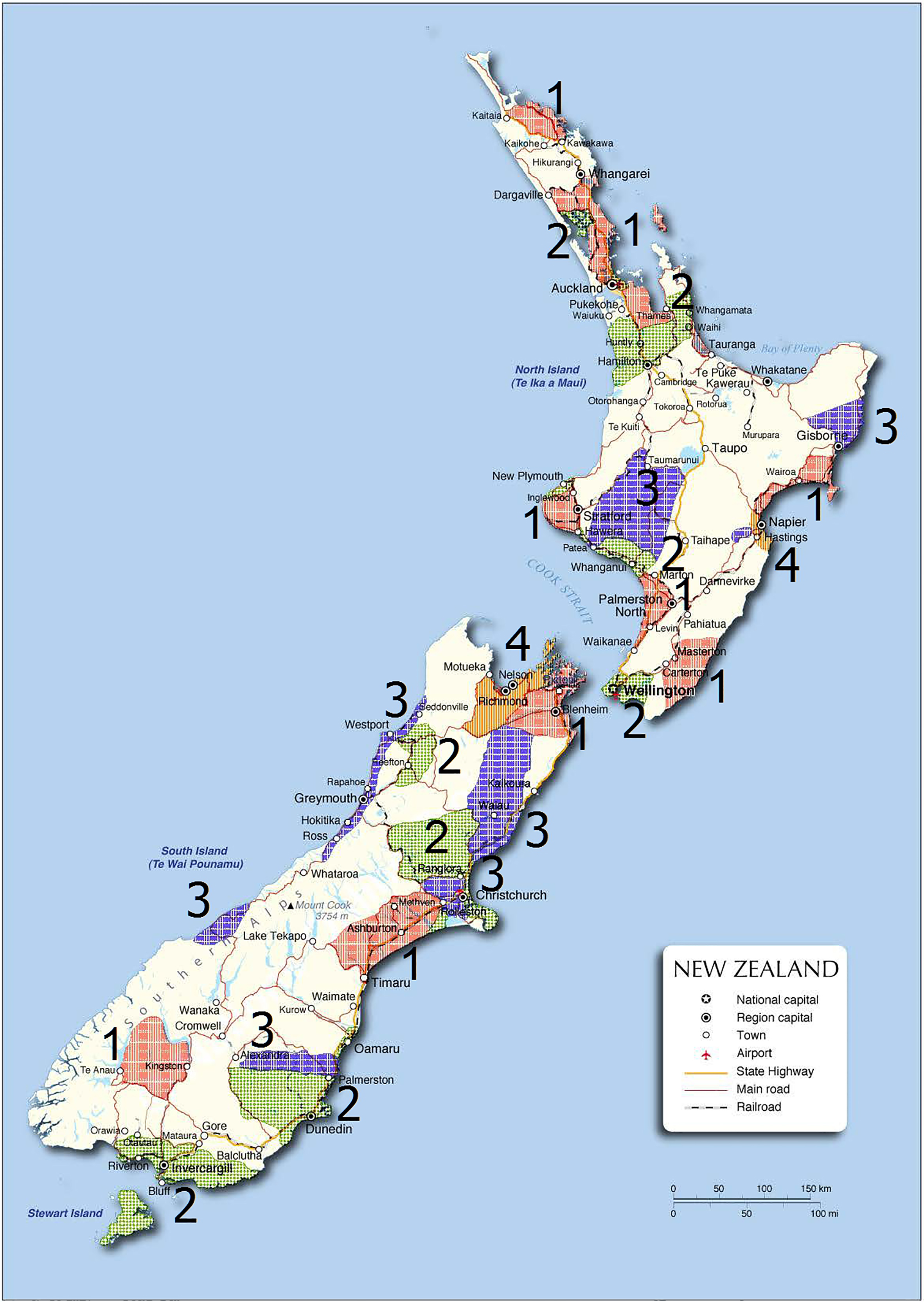
As seen from Fig. 6, the red region (cluster 1), the green region (cluster 2) and the blue region (cluster 3) are geographically close to each other, especially the green and blue region (reflected by the clustering result in Fig. 4) while the two outliers are near Richmond and Napier (cluster 4).
To help understand the source of variation of the electorates among the four clusters, we have undertaken further preliminary studies of the aggregate data. These studies suggest that the population size did not provide any source of homogeneity, or heterogeneity, of the electorates in terms of association. Nor is it apparent that geographical characteristics (e.g. North Island vs South Island, or Rural vs Urban) defined the variation in the voting behaviour between the electorates. However, we have identified that potential sources of clustering may indeed be related to the given aggregate data. The supplementary material provided indicates that the number of voter turnout divided by the number of those that did not turn out
One may also be interested in understanding what effect the two “outlying” electorates that make up cluster 4 – in the Richmond and Napier regions – have on the membership of clusters 1 to 3. If these electorates are removed from the study,
By focusing on the analysis of the aggregate data for a single 2
This paper has shown that, given only the aggregate data of the 1893 New Zealand voting behavior data at the electorate level, there is a statistically significant association between the gender of a registered voter and whether they turned out to vote. Homogeneous voting behaviours amongst the electorates can be identified and visually depicted by clustering via the
Alternative applications of the AAI can be made in a variety of research areas. The extension studied in this paper can be carried out in areas of study including, but not limited to, marketing research, social and medical sciences; these disciplines have commonly used a variety of ecological inference techniques to study their data. Further methodological advances to the AAI and the clustering issues outlined in this paper will also prove beneficial for the practical analysis of aggregated data. For example, the connection between the AAI with other well-known association indices - such as the odds ratio, independence ratio, Pearson’s ratio, the standardised and adjusted residuals (see, for example, [34, 48]) show that the AAI is flexible for a variety of commonly used measures of association the analyst wishes to use; see, also, Beh, Tran and Hudson [59] and Lombardo and Beh [60] for discussions related to such developments. Adapting this work for stratified data will enhance the utility of the AAI in this case.
Further advances to the AAI can be made by generalising Beh’s index [26], his related work, and this paper’s outcomes to the analysis of a single, and stratified
Footnotes
Supplementary data
The supplementary files are available to download from https://dx-doi-org.web.bisu.edu.cn/10.3233/SJI-170387.