
Abstract
Information on the structure of agriculture is necessary to understand the risks for, among others, food security and the environment. The FAO advises all countries to carry out an agricultural census every 10 years to get a full picture. The European Union (EU) collects data on farm structure for the common agricultural policy (CAP) and other policies, but at more frequent intervals.
This paper presents the technical and methodological aspects of the newly modified system for the European agricultural censuses. Under the new set-up, EU countries can reduce the burden on respondents while increasing the availability of statistics for the census 2020. A set of 184 core variables is collected as a census for all farms above common physical thresholds in all countries with the target of covering 98% of each country’s agriculture. For sub-samples of farms, the core variables will be supplemented with variables grouped in three modules. The system allows countries to use multiple sources and methods to obtain data subject to meeting pre-defined quality requirements. The efforts of the European Statistical System (ESS) to allow countries who do not meet the census’s 98% coverage requirements to conduct a sample data collection on the smallest farms and further ways of reducing costs and burden are discussed.
Keywords
Introduction
Eurostat, the EU’s statistical office, publishes EU-wide agricultural statistics on the structure of farms and other operators in the agricultural sector, agricultural production, production factors, and agri-monetary data. Economic accounts for agriculture provide an overall view of the agricultural sector. The main aim is to support decision-making and policy design, implementation, monitoring and evaluation in fields relating to agriculture, such as the EU’s common agricultural policy (CAP), sustainable development, and environmental and food-related policies. Challenges in this area of statistics, such as changes in world agriculture driven by globalisation and social change, changes in the CAP and other EU policies, and technological progress and new data sources, have made it necessary to modernise EU agricultural statistics in order to keep providing high-quality, comparable and flexible data [1]. The primary objectives of this ongoing modernisation are to i) meet new and emerging data needs better, more flexibly and faster, ii) improve the comparability and coherence of EU agricultural statistics, and iii) reduce the costs and burdens which data collections place on producers and providers.
The first step was to modify the system for the agricultural census. A new regulation on farm-level structural statistics, Regulation (EU) 2018/1091 on integrated farm statistics (IFS), provides the legal basis for the agricultural census to be conducted in 2020 and two sample data collections to be held in 2023 and 2026 [2]. These data collections, which cover the widest range of farms, will update information on the state, trends and impacts of the EU agricultural population. They are thus an essential backbone for other agricultural statistics and also fulfil international requirements and guidelines such as those of the FAO, the Intergovernmental Panel on Climate Change (IPCC) and the United Nations Global Strategy to improve Agricultural and Rural Statistics; for example, the standards, concepts and definitions used in IFS were designed in accordance with FAO recommendations for better international comparability.
Methodology
European statistics are produced by Eurostat in cooperation with the EU member states. The national statistical authorities collect, verify and analyse national data and send them to Eurostat. Eurostat’s role is to consolidate these data and ensure they are comparable, using harmonised methodology. As an example, on the structure of agricultural holdings, Eurostat prepares the EU regulations that set common definitions of agricultural holdings, common lists and descriptions of variables, common reference periods, and minimum coverage and precision requirements to be ensured by all EU member states. Eurostat also continuously updates a comprehensive EU handbook providing further details on the classifications and descriptions of all variables and on various methodological aspects. This work is carried out in close cooperation with experts from the member states.
The countries are free to choose data sources and modes of data collection provided that the information allows to produce statistics that meet the above-mentioned common requirements.
The partnership between Eurostat and the national statistical authorities to develop, produce and disseminate European statistics is called the European Statistical System (ESS). In addition to the EU member states, the ESS partnership includes the European Economic Area (EEA) and the European Free Trade Association (EFTA) countries.
National statistical authorities, usually the national statistical institutes (NSIs), collect the data for the 2020 agricultural census. Data collections are based on a modular approach comprising:
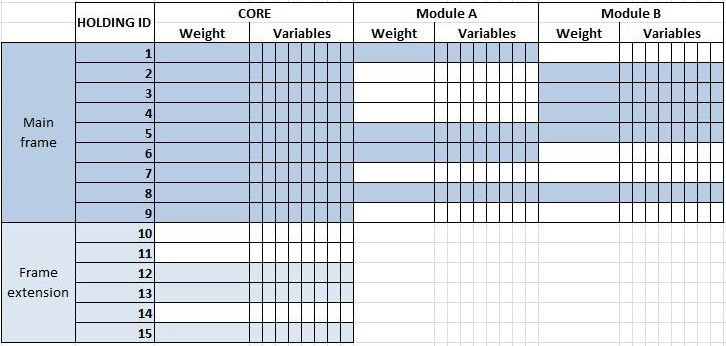
core structural information on the most important aspects: land, livestock and the farmer, collected from farms exceeding common physical thresholds. The thresholds were established based on analyses of 2010 census data. The aim is to cover 98% of each EU member state’s utilised agricultural area (UAA) (without kitchen gardens) and livestock units (LSUs), i.e. economically active farms. IFS does not aim to achieve 100% coverage because UAA and LSU follow power law distributions, with a small number of very large farms accounting for the majorities of utilised area and livestock and many very small farms contributing only little to the totals. Collecting data on the remaining 2% would therefore require a disproportionate effort of contacting many very small farms, or rather households, which are more likely to be unstable, difficult to identify or absent in administrative sources, without contributing significantly to the overall picture. The missing parts are not estimated, and the published statistics describe the population defined as covering at least 98% of UAA and LSU. For countries where farms above the physical thresholds concerned do not provide the 98% coverage required, further data are collected from a sample of farms below the thresholds. This extends the frame to include small farms (farms in the frame extension, see Fig. 1); and
Linking the IFS core and module data collections and frame extension. modules with additional information on certain themes which is to be linked to the core (see Fig. 1), collected at a lower level of precision and/or frequency from a sample of farms above certain physical thresholds for each module, excluding the small farms in the frame extension.
Under IFS, the cost and burden of data collection will be reduced by comparison with the previous regulations, Regulation (EC) No 1166/2008 on farm structure surveys (FSS) [3] and Regulation (EU) No 1337/2011 on permanent crops [4]. This will be done in a number of ways, which are labelled with
Thresholds and frame extension
The previous regulation on farm structure statistics required all member states to cover holdings above certain physical thresholds. In a few cases, these thresholds were too high to achieve sufficient coverage of UAA and LSUs, and some EU countries collected data from almost all their farms. IFS sets lower physical thresholds, but if the requirement of achieving 98% UAA and LSU coverage is fulfilled, EU countries can apply to raise the physical thresholds, so as to reduce the number of holdings from which data are collected. So the IFS thresholds are flexible and can even be raised above the ones set in the previous regulation if the 98% coverage requirement is met (
Under IFS, if countries cannot achieve the required 98% coverage when applying the thresholds, they should extend the frame to include a sample of small farms that fall below these thresholds (see Fig. 1); this sample should collect only core variables (not all variables, as was the case under the previous FSS regulation) (
In addition, each individual small farm can be unstable, but small farms in their entirety change relatively little over time. Large farms are the drivers of agricultural evolution and they account for the largest share of variables’ totals. Their behaviour thus determines overall agricultural evolution. In contrast, small farms’ importance lies mainly in the social dimensions of agriculture and rural areas. This change will be beneficial to EU countries with many small farms, such as Bulgaria and Romania. It represents a departure from the previous system, under which all farms were included in the populations covered by the former censuses and sample data collections.
Under IFS, modules are generally collected on holdings above given physical thresholds (main frame, see Fig. 1). However, the relevant population is further reduced for particular modules (
Source agnosticism
EU national authorities can use a variety of methods and sources to collect data, provided that they meet the necessary quality requirements. These methods and sources are:
S1: statistical surveys: census (a) or sample (b), S2: administrative data sources, and S3: other methods and innovative approaches.
For the census year, the IFS regulation allows samples to a greater extent than the previous regulation. While most variables were collected by census in 2010, the IFS regulation states that a sample-based approach can be used for all modules’ variables in 2020 (
Administrative sources (S2) based on EU regulations and where a certain control is implemented can be used without any justification. The previous regulation explicitly mentioned fewer such administrative sources and required prior information on the methods and the quality of the data from additional administrative sources. IFS explicitly mentions more administrative sources, thereby reducing the number of cases in which prior information on their use and quality is required (
Other methods and innovative approaches (S3) refer to modelling, expert estimates, remote sensing, and so on. Some of the variables in the ‘Animal housing and manure management’ module can be estimated using models. For example, the annual average number of animals in each category can be estimated using models based either on the number of animals raised, divided by the number of livestock raising cycles per year, or on a combination of the number of places and the number of empty days. To give another example, the quantity of manure produced by a given category of livestock can be estimated on the basis of the number of animals under certain types of management.
Eurostat also allows novel data sources such as Big Data if NSIs can make use of them. At the moment, there is still room to increase the use of and improve the quality of administrative sources in the ESS. NSIs and Eurostat are currently focusing more on these sources than on Big Data because they are more structured and less complex, their representativeness and coverage are often better known, they have a manageable volume, and their types of errors are typical so that classical statistical methods can be used to process the data and measure quality aspects.
Such methods reduce the administrative burden on national authorities and the costs they incur, but also the effort that farmers have to make to recall and estimate this information (
Under IFS, in order to allow member states to flexibly choose the source and reduce the burden of data collection further, information on the ‘Machinery and equipment’ (in 2023), ‘Orchard’ (in 2023) and ‘Vineyard’ (in 2026) modules may be based on the year directly preceding or following the reference year, as long as it reflects the situation in the reference year (
While the increased use of S2 and S3 reduces the overall burden, it poses challenges with respect to assessment of data quality. Data quality is affected by both sampling and non-sampling errors. Only data collections based on samples are affected by sampling errors. In this case, the theory for probability samples allows for the sampling design to control for this type of error, and the IFS regulation sets precision targets for certain variables collected on a sampling basis. However, it is impossible to control for non-sampling errors or to target them in advance, because they happen in a non-controlled manner for every statistical process. They cancel each other out or add to or multiply each other, depending on the specific data collection and the specific context. No sound theory is available to predict them. This is more problematic in cases S1a, S2 and S3, where non-sampling errors have a big impact on overall data quality. After the data collections are carried out, multiple indicators can be calculated for each source of non-sampling errors associated with the different steps in a statistical process, while a unique synthetic indicator, such as the mean square error, is not computable. Thus, synthetic quality indicators cannot be set in a regulation such as IFS. However, national authorities are required to describe in quality reports a set of indicators that are both quantitative and qualitative. Quality assessment for multisource data is under continuous development in ESSnet projects. These are networks of several ESS organisations which aim to provide results that will be beneficial to the whole ESS, such as the ESSnet on Quality of Multisource Statistics.
The move towards source agnosticism improves subsidiarity, enabling EU member states to choose the most cost-effective sources for themselves according to their national conditions and needs. It also increases flexibility, thanks to greater openness to future data sources such as precision farming data.
Reduced number of variable breakdowns
The 2010 agricultural census covered a total of 273 variables, collected from all EU farms.
In the 2020 census, the core will comprise 184 variables and will be supplemented by 30 variables in the module ‘Labour force and other gainful activities’, 15 in the module ‘Rural development’, and 70 in the module ‘Animal housing and manure management’, totalling 299 [5]. These are maximum numbers, as member states may transmit fewer variables if particular items do not exist or are not significant in the country concerned.
The above information refers to the absolute numbers of variables in 2020. Burden reduction should be assessed throughout 2020–2026, as the data for the modules will be collected less frequently in the new decade (
In addition, the core and module system makes it possible that fewer farms will have to provide data on all variables in a census or sample year. This reduces the burden on individual farms (
Furthermore, the same list of variables and definitions, as well as common quality standards and data transmission deadlines, will be used in all EU member states, increasing interoperability and reusability so as to reduce the costs and burdens of data collection (
Enhanced data visualisation through geo-referencing
While the IFS regulation allows costs and burdens to be reduced, it enhances the potential for geographical data analysis. The regulation requires information on the geographical location of each farm, namely the code of the cell where each farm is located, using the 1 km INSPIRE statistical units grid for pan-European usage according to Commission Regulation (EU) No 1089/2010 [6]. INSPIRE is based on the infrastructure for spatial information established and operated by the EU member states. It enables environmental spatial information to be shared among public sector organisations and assists in policy-making across boundaries.
Geo-referencing of statistical information at the farm level means that each holding included in a dataset is assigned a high-accuracy geo-reference code. The 1 km grid should be used as a geo-referencing framework. When studying socioeconomic and environmental phenomena such as flooding, a system of grids with equal-size grid cells has many advantages: it allows for easy comparisons, ensures stability over time and allows for hierarchical aggregation, depending on the specific purpose.
INSPIRE provides recommendations on how to assign stable identifiers (codes) to statistical units (agricultural holdings). Having holdings assigned to detailed geographic areas (1 km grid cells) enriches data analysis and allows tabulations to be produced for additional geographic entities that are more detailed than the Nomenclature of territorial units for statistics and cross-border tabulations when quality is good enough, thereby meeting relevant policy needs. For example, data can describe geographic entities such as river basin districts and Natura 2000 core breeding and resting sites for rare and threatened species. The European Commission uses hydrological definitions of basins and sub-basins to assess water balance by the basins of main rivers and tributaries in the EU. IFS data is crucial in making estimates like this. Tabular data are treated for confidentiality and suppressed or aggregated to the upper nested grid level according to the INSPIRE Data Specification on Statistical Units following Directive 2007/2/EC [7]. This occurs when tabular data are unreliable, based on the values of estimated sampling errors, or when the 1 km grid contains 10 or fewer agricultural holdings or is too small for the average farm size in the grid. The upper nested grid cells of 5 km, 10 km or even larger are used as required. Reliable data can be displayed using maps for enhanced data visualisation.
Results
The new IFS regulation entered into force only in August 2018. It is thus still too early to quantify exactly how much the new system will reduce the burden and costs which data collections entail.
Before developing and adopting the IFS regulation, the Commission conducted a formal impact assessment. On the basis of model scenarios, it estimated that the IFS regulation would bring net monetary savings of around 10% of current total costs (almost €320 million reported in the last agricultural census, conducted in 2010). The following had already been taken into account: external factors (such as the decreasing number of farms in the EU and the technological and other progress expected), adaptation costs (such as redesigning data collection systems and improving coherence and harmonisation), and increased data collection costs (owing to some new variables and earlier deadlines). The expected sizeable drop in the number of farms from which data is to be collected (from 12 million in 2010 to 8.4 million in 2020), owing to the new thresholds and the frame extension, was identified as the main source of these savings. However, the impact assessment could not take account of factors such as the smaller number of variable breakdowns and the effects of greater source agnosticism, beyond general estimates, as these had not yet been finalised at the time [8]. This means that while the 2020–2026 round of census and sample data collections can be expected to cost less and impose fewer burdens than the 2010–2016 round, no exact numbers will be available until later on in this decade.
Discussion and conclusion
Organising the collections of data under the IFS regulation is a challenge for all ESS participants. After the 2020 agricultural census, which – given the innovations and efforts outlined in this paper – is expected to account for most adaptation costs, the costs and burden are almost certain to shrink further. Moreover, the system will likely be able to adapt more easily and thus at a lower cost to changing and emerging needs.
Agricultural, rural and related policies account for significant expenditure under the EU budget, coming to around €60 billion per year, which is about 40% of the total EU budget. They create jobs and promote sustainable growth in the EU, and their impact on the environment, food security and rural communities is considerable. Developing, implementing and monitoring these policies requires an evidence basis of high-quality, up-to-date official statistics. The cost of the 2010 agricultural census totalled about €320 million across the EU and its member states. Official statistics are thus a comparatively cheap public service and an investment that generally pays for itself, but high costs and heavy burdens can nevertheless jeopardise their production and acceptance at a time of tightening public finances. This paper presents the ESS’s way of tackling this challenge.