
Abstract
World economic aggregates are compiled infrequently and released after considerable lags. There are, however, many potentially relevant series released in a timely manner and at a higher frequency that could provide significant information about the evolution of global aggregates. The challenge is then to extract the relevant information from this multitude of indicators and combine it to track the real-time evolution of the target variables. We develop a methodology based on dynamic factor models adapted for variables with heterogeneous frequencies, ragged ends and missing data. We apply this methodology to nowcast global trade in goods in goods and services. In addition to monitoring these variables in real time, this method can also be used to obtain short-term forecasts based on the most up-to-date values of the underlying indicators.
Introduction
On a global scale, there is a constant stream of economic information released by official and private sources. National statistical authorities publish national accounts, balance of payments, government finances, monetary statistics, data from the banking sector and many other socio-economic indicators. International actors also compile and publish diverse statistical series. To this, one can add the data produced by commercial statistical providers, with products such as public opinion or business polls. Lately, there has been an important addition to this list: private actors that collect statistical information as part of their activities and that bundle them as standalone products, including stock exchanges, financial institutions, port operators, retailers, and social media companies.
Each of these series provide a piece of information relevant for overall economy activity or for specific sectors. This could present an opportunity for official statistics, allowing the release of more timely information. Although this means that we can keep track of the state of the economy in real time, it also introduces the challenge of sorting out the information that is relevant from that which is not. This problematic is exacerbated by some statistical complications: missing data, measurement errors, undercoverage, low signal-to-noise ratio, heterogeneous frequencies, different starting and ending dates, asynchronous update schedule, large revisions, and others.
Assessing the real-time evaluation of macroeconomic variables based on a series of timely, high-frequency indicators (a process that has come to be called “nowcasting”) is not new. The classical literature on coincident and leading indicators, such as those described in [1, 2], is well established and it has been applied in many areas. Bridge models, linking high frequency variables to a target variable of lower frequency, are standard tools in statistical analysis (see [3, 4, 5] for recent applications to forecasting economic activity). Progress in this area accelerated with the development of more sophisticated techniques of data selection and processing, particularly the application of dynamic factor models, as in [6, 7, 8, 9].
The simplicity of the dynamic factor model and its good empirical performance explain its positive reception as a tool to nowcast or forecast economic variables. This solution was later extended and applied to many contexts. For example, [10] modified the model to allow indicators of mixed frequencies and [11] developed this further by taken into consideration variable reporting lags and the availability of early or “flash” estimates. [12] implemented some modifications to improve the forecasting performance of the model. [13, 14] constructed a similar model to incorporate very high frequency indicators and a dynamic factor model that does not require the use of approximations. [15] applied the basic methodology but extended the application to simultaneously track economic growth in 32 economies by using country-specific and global indicators. The impact of data revisions and data releases is decomposed in [16, 17], as part of a structured framework to study the real-time flow of information and its impact on the nowcasting of a target variable. This methodology was later used by the Federal Reserve Bank of New York, as described in [18].
However, dynamic factor models are not the only methodology used to tackle this problem. For example, the mixed-frequency model (MIDAS) proposed in [19, 20] allows to incorporate data sampled at different frequencies in a flexible way, with many applications and further developments, as shown in [21, 22, 23]. This paper will not explore this approach since, as it will be explained later, recent developments in dynamic factor models also allow to efficiently incorporate variables of mixed frequencies, in addition to overcoming other statistical complications of empirical data. In addition, as highlighted in [17], these are partial models that do not allow to form joint expectations on the entire set of information, and they therefore do not allow to study the complete impact of new information on the nowcasts.
The main objective of this paper is the development of a nowcasting methodology for world trade in goods and services. The standard dynamic factor model will be adapted to accommodate the characteristics of these target variables, and it will incorporate the information available in an extensive list of indicators.
The rest of the paper is organized as follows. The next section will introduce the concept of nowcasting as specifically applied to global trade in goods and services. After that, Section 3 will describe the dynamic factor model and the data transformations required. Section 4 will then present the application of this methodology to the variables of interest. A final section will conclude and introduce some possible areas of future work.
Nowcasting global trade
Assessing the evolution of world trade is crucial for a comprehensive evaluation and forecasting of the economy. Many countries rely on international trade as an important component of their economy and export demand shocks or episodes of price volatility can bring about severe periods of instability. It is therefore essential to identify shifting trends and sudden changes of direction in these variables as soon as possible. International trade is also a variable that can affect the entire national economy, creating imbalances or influencing the effectiveness of policy. National authorities are therefore interested to closely monitor this variable.
However, most of the existing applied literature on nowcasting targets the evolution of global economic activity only, frequentlly measured by GDP. Only a handful of recent articles have applied this approach to other economic series, including international trade. [24] developed a dynamic factor model for world trade relying on a set of monthly indicators. [25] used an augmented bridge model based on theoretical-level relationships to jointly assess world trade and economic activity. Finally, [26] constructed two leading indicators for global trade: one relying on the traditional methodology of the Conference Board cited above, and another based on dynamic factor models with single-frequency indicators.
Figures on world trade are reliably published by international actors. However, they are only available after a considerable lag and with a low frequency (annual or quarterly). Some providers release variables with a higher frequency (monthly), but at the cost of lower coverage, higher variability or frequent revisions. At the same time, there are many variables that can potentially provide information on international trade. The challenge of any nowcasting exercise is to extract the relevant information from a heterogeneous set of variables and organize it into a coherent statistical model.
Two approaches could be followed to estimate international trade. One is to target total figures of global trade directly. The other is to monitor trade variables for the main trading countries or the most important sectors, and then aggregate them into an overall estimate of trade. We prefer the former approach because trade is influenced by global developments that cross national and regional boundaries: globalization and the internationalization of production, growing importance of global value chains, emergence of large multinationals and their reliance on intra-firm industrial processes spread all over the world, generalized influence of exchange rate dynamics, rise of protectionism, cycles of commodity prices, extended effect of new technologies on production, etc. All this may lead to the existence of business cycles that are specific to global trade, but different from those at the country level. In fact, [27] find evidence that this approach leads to improved forecasts in comparison to the indirect (“bottom-up”) approach. The indirect approach would also be computationally difficult to implement since it would require the selection and estimation of individual models for many countries; this practical factor also motivated the choice of the direct approach.
In this paper we will adapt existing nowcasting solutions to the specific characteristics of trade and the indicators that can potentially be used to track them in a reliable and timely manner. However, it must be noted that this is not a macroeconometric model that selects explanatory variables based on their causal linkages with international trade or by following a structural model of the world economy.
The nowcasting model
The goal of the exercise is nowcasting a target variable observed with low frequency (quarterly or annual) or after a considerable lag based on a set of indicators that are available more frequently or with a shorter publication lag. However these indicators are not necessarily available as a rectangular, balanced dataset. Instead, they are affected by several statistical challenges: mixed frequencies, different start and end dates (i.e., ragged ends), asynchronous timing of data publication, and missing data. The methodology employed to calculate the nowcast should take into account these features of the data. This paper takes the dynamic factor models described in [10, 11] as starting point, and extends them to incorporate additional types of variables relevant for nowcasting world trade. The methodology presented by these authors is also extended to include other types of variables, namely annual indicators and monthly variables available only as year-on-year growth rates. Both variables require adapting the structure of the model to accommodate a larger number of lags.
Dynamic factor models introduce the assumption that the observed indicators can be divided into two components: one attributed to one or a few (unobserved) factors, and another that is specific or idiosyncratic to each variable. The factor model serves to establish a mapping between the common factors and the indicators. It is a dynamic model where the factors are assumed to change through time according to an autoregressive process. This model can be summarized through a state-space representation, in which the mapping between indicators and factors becomes the measurement equation, and the dynamics of the unobserved factors become the transition equation. The likelihood of this model can then be calculated via the Kalman filter and the maximum likelihood estimators (MLE) obtained via standard optimization techniques.
Mixed frequencies
The approach to overcome this issue is to express all variables in terms of the highest frequency available in the dataset (in this case, monthly). This requires transforming the variables, through approximations if necessary, so that they are all expressed in terms of monthly growth rates.
Annual variables
Let
Note that the
The annual growth rate of the target variable can therefore be approximated by
Rearranging the elements above and letting
represent the monthly growth rates, we obtain the following approximation of the annual growth rate of a variable in terms of its (unobservable) monthly growth rates.
Let
Quarterly variables are observed only once every three months and the rest of the series is treated as missing.
Monthly time series expressed as monthly growth rates can be incorporated directly into the model. We will denote them in this paper simply as
However, some sources publish their data not as changes with respect to the previous month, but relative to the same month of the previous year. This requires a special transformation before they are incorporated into the model. Let
The mixed-frequency database that will be used to estimate the model may be affected by the presence of missing data from three sources. First, the series may have some missing information directly from the source with no official imputation available. Second, some variables are only observed once per year or quarter. Once transformed into functions of monthly growth rates, they will be available only when a data point is published and the rest of the series will be treated as missing. And third, because each series has its own starting and ending dates. Although it could be possible to restrict the database to the time window where all the variables are available, this would mean discarding valuable information that could be used to estimate the model. Moreover, one of the benefits of the nowcasting methodology is that it uses the most recent information available to estimate the target variable, even if this means that only some of the variables are available in the most recent months.
To overcome the problem of estimating the model with missing data, we follow [10] and substitute all variables by random normal observations independent of the model parameters. The authors show that this only adds a constant to the likelihood and does not impact the estimation of the parameters. Let
where
With this conformable database, we will structure the model as a dynamic factor model in state-space representation. We therefore assume that the target variables and the indicators in the model share one common (time-varying) factor
Annual target variable
To build the state-space model, assume that we have one annual target variable (
Following the transformations described in the previous section, we obtain the following measurement equation of the model.
This can be written more compactly as
with
The factor loading matrix is given by
and
Notice that available forecasts of the target variable can be integrated into the model. They are treated as the true value of the variable plus a random forecast error
The transition equations of the model consist of the following terms.
with the error vector
By adding the required terms, we can write this equation more compactly.
where
with
The size of each matrix
The measurement Eq. (6) and the transition Eq. (7) form the state-space representation of the dynamic factor model. The Kalman filter can then be used to evaluate the likelihood function and calculate the MLE. The prediction equations are initialized at a vector of zeros and the identity as the covariance matrix. Once we obtain the MLE, we can use the updating equations of the Kalman filter to estimate the monthly values of the target variable. This will be the main output of the model. It is also possible to calculate the contribution of each indicator to the nowcast of the target variable; see [11] for details.
In this case, the structure of the model remains the same than the description given above. The measurement and transition equations are still given by Eqs (6) and (7), respectively, and only the underlying matrices need to be adapted. As before, assume that we wish to nowcast the target variable
Using the same nomenclature as before, the matrices of the model are now given by the expressions below. The rest of the process remains identical.
Empirical analysis
The dynamic factor model described in the previous section will be applied to international trade, with the objective of estimating the current-year figures based on the most recent observations of selected indicators. We will follow three main steps in this process.
The first step consists in building a database of indicators that could potentially contribute to nowcast the target variable. In order to be eligible, the indicators have to meet several conditions. They have to be linked to the target variable on theoretical, structural or empirical grounds, so that we start the process with the hypothesis that they can potentially contribute to the nowcasting exercise. They should also be timely available since this method relies on indicators that are published quickly and reliably; any indicator published simultaneously or after the target has no value for nowcasting. Similarly, they should have a frequency at least as high as the target indicator because, for example, annual variables would likely add little value when nowcasting quarterly variables. The time series of the indicators would ideally be long enough, so that the model can have enough information to distinguish between the common factor and the idiosyncratic component. Finally, we should expect the indicators to be regularly available in the future.
There are five types of indicators that could be considered:
Sub-components of the target variable that are released more opportunely. For example, if the target variable is the total exports of goods, we could use the exports of some countries or the exports of a particular product published by industry-specific sources. These variables are part of the target variable and they could also be correlated with trends in other sub-components (for example, other countries or other products), therefore containing important information about the aggregate.3 Variables that are linked to the target variable through structural economic models. For instance, if our target is total imports of services, we could include determinants of the demand for these imports from different macroeconomic models. Other variables that could carry information about the target variable. For instance, if we are studying the trade of goods, an important indicator would be the movement of vessels through the global network of ports and the amount of cargo they transport. These variables are case-specific and allow for the exploration of innovative sources. “Soft” or opinion indicators from surveys or expert assessments. These could be, for example, business or confidence indicators, purchasing managers’ index, new orders estimates, and others. These variables are usually collected from surveys and their signal-to-noise ratio could be low. However, they have the advantage that they are available opportunely, frequently with a very short lag after the end of the period they cover. They are therefore the only information available for the most recent period and the first indication of shocks or trend changes that could affect the target variable. Forecasts of the target variable from other sources. What is the interest of including other forecasts in the model? And why nowcast at all if there are already other forecasts available? There are at least three reasons. First, when we believe that the forecasts provide some information about the target variable, but that they are biased or have high volatility and we believe the nowcast methodology can lead to an improvement. Second, when those forecasts were produced only with low frequency variables and do not incorporate the information provided by higher-frequency variables. And third, when those forecasts are out of date and do not incorporate the most recent data.
These variables can be annual, quarterly or monthly. As described in Section 3, variables enter the model in specific ways and should be transformed accordingly. Annual variables are included as year-on-year growth rates, quarterly variables as quarter-on-quarter growth rates, and monthly variables as either month-or-month growth rates or percent changes with respect to the same month of the previous year. Since this requires making intra-year comparisons, all indicators should be seasonally adjusted. Official seasonally adjusted series from the source are preferred; if they are not available, they will be adjusted by applying the X-13-ARIMA-SEATS methodology [29].4 All data are standardized (to a mean of zero and a variance of one) before the estimation.
Once the full database of indicators is compiled, the second step is the selection of the variables that will be included in the nowcasting model. Since the calculation of the MLE for the model is computationally intensive, and given the expected proliferation of indicators, standard stepwise selection techniques are generally not feasible. We therefore carry out an ad hoc variable selection by following this sequence.
Define a set of initial indicators from the full list available, that a priori could be the most significant. Set the number of lags of the transition Eq. (7) to Discard the variables that are not significant or that have a low contribution in explaining the variability of the target variable.5
Choose the number of lags to be included in the model. A grid search across all combinations of lags is not feasible in this case. We will therefore impose that the number of lags of the transition equations for the factor and the first error term ( Apply a forward model selection process to the rest of the indicators that were not included initially, proceeding by blocks of variables. The lag structure remains unchanged. Only those indicators that are significant are retained. This will lead to the final model.
Two criteria were used to compare models. First, the percentage of variability of the target variable explained by the model calculated over the full sample. Second, the mean absolute error of the forecasts for the last 20% of the sample (the testing sample) at the last data update before the actual values were published, with the parameteres estimated using the first 80% of the observations (the training sample).6 Because missing data is replaced with random draws from a normal distribution, we cannot use likelihood-based model selection criteria. Although this procedure does not affect the calculation of the MLE, it does have an impact on the level of the likelihood and its derived statistics.
This is a computationally-intensive process that, however, does not need to be repeated every time a series is updated. Once the final model is selected, the estimated parameters will remain fixed and they will be used to update the nowcast whenever new data becomes available. The entire variable selection procedure will only be repeated infrequently but regularly to adapt to changes in the underlying trends and correlations among the variables, or whenever new, potentially significant indicators become available.
The rest of this section will summarize the results of the nowcasting exercise for some series of international trade. A full description of the variable selection process and the analysis of the results will not be presented here due to space restrictions, but they are available from the author upon request. The estimations were calculated with data available as of October 2019.
Global trade in goods
The target variable is the world value of exports of goods, as reported in [30].7 This is an annual time series published by the United Nations Conference on Trade and Development (UNCTAD) and the World Trade Organization (WTO). For its compilation, data from national sources, United Nations Statistical Division’s Comtrade database and different secondary datasets disseminated by international and regional organizations are aligned and complemented with each other. This series is updated twice per year: in April, when the figures for the previous year are published, and in September, when these figures are revised. For this exercise, we evaluate the model against the April release.
List of indicators, global exports of goods
List of indicators, global exports of goods
Sources: OECD
There are other series for the global value of exports at a quarterly or even monthly frequencies (produced by UNCTAD, WTO or the International Monetary Fund (IMF), for example), but they only include the subset of countries that publish infra-annual trade data. Although this may cover a large share of world exports, it is still not equivalent to the global figure. For this reason, we selected the annual series as the target variable of this exercise. However, in case of interest, the model for quarterly target variables described in Section 3 can be directly applied to the quarterly series.
Table 1 lists the complete list of variables considered for the nowcasting exercise and their sources. It includes monthly series for the largest exporting countries in the world according to UNCTAD data in [30]. For structural variables that could drive world exports, we include industrial/manufacturing production and retail trade indices as indicators of the global demand for exported goods. In terms of country coverage, we consider the economies with the largest manufacturing sector and the largest final consumption in the world, respectively, according to national accounts data from the United Nations Statistics Division in [31]. Whenever possible, we also include available aggregates, such as the OECD or the European Union, since these groups include some of the largest economies. The list also includes two unique indicators from Eurostat that, although published with a considerable lag, could provide important information on exports: non-domestic manufacturing turnover and new manufacturing orders.
Lag order selection, global exports of goods
Notes:
Contribution to nowcast estimation, global exports of goods
Notes: IPI
We also consider additional indicators that could contribute to explaining the evolution of the global value of exports. First, a quarterly and a monthly series for the export volume, since both have different coverage and publications lags. In addition to the volume, export values are also determined by prices. We use UNCTAD’s free-market commodity prices and WTO’s manufacturing export prices to incorporate this factor. The maritime transport of cargo can also be used to track the amount of goods traded internationally, potentially a good indicator of global exports. For this, the model includes the freight traffic of waterways in China, as well as cargo vessel arrivals and the container throughput in Hong Kong. Additionally, we consider the total volume of ships crossing the Suez Canal and the number of ships transiting through the Panama Canal. The Baltic Dry Index and Harpex Shipping Index could also provide information on international trade. They measure worldwide international shipping rates for dry bulk and containers freight, respectively. Since the supply of cargo ships is highly inelastic, changes in prices should reflect a corresponding change in demand for shipping, therefore serving as proxy measures of export volumes. Finally, in terms of “soft” indicators, we consider a series of business confidence indices, consumer confidence indices and purchasing managers’ indices for the largest economies.
Seventeen indicators were selected for the initial estimation, those that we believe could show a higher correlation to global export values. These are marked in the fifth column of Table 1. By applying the model selection criteria described above, we selected a core model, indicated in the sixth column of this table. This model was estimated at different lag combinations and the results are presented in Table 2, including the results for the two selection criteria described above. We transform both statistics as ratios relative to the best model (the one with the maximum
After this step, the forward selection model process was applied to the rest of the indicators, maintaining the same selection criteria. This was implemented by blocks, where the indicators of one type were tested and selected, before moving to the next type of variables. The final list of indicators is marked in the last column of Table 1, a total of 26 variables. It can be seen that this does not expand considerably beyond the core model, with the exception that country-disaggregated series are generally preferred to the aggregates, since they provide additional information and they are available sooner.
Annual growth rates, global exports of goods. Note: The line represents the estimated annual growth rate of the past 12 months with respect the 12 months before that (i.e., it is a rolling cumulative growth rate over the last 12 months). The points represent the actual values for the growth rate. The model anchors the estimates to the actual figures, so they coincide whenever the growth rate is observed.
The method described above takes information from the 26 indicators to estimate the monthly values of the unobserved common factor. Each indicator has a different weight in the estimation of the factor. Moreover, the weights change through time, as the co-movements between the indicators and the factor evolve. The formula for the calculation of these weights can be found in [11]. Table 3 shows the contribution of each variable over the two last years. The first column corresponds to the target variable, world exports of goods, while the rest of the table shows the selected indicators. There are several points to highlight in this table. First, the model is built in such a way that the estimates are anchored to the actual data. Consequently, whenever the target variable is observed (December 2018 in the table), it takes all the weight and the other indicators do not contribute to estimate the factor. Second, whenever a variable is missing, its contribution to the estimation is zero. We can see that the weights are evenly distributed between the country-level export variables, with a smaller contribution from the structural variables and most of the other indicators (with the exception of the monthly index of export volume and container throughput in Hong Kong port, which take a relatively higher weight). The soft indicators, as expected, only have a small effect on the estimation. However, in the most recent periods, when not all variables are available, the weight of those indicators that are observed increases. Starting in October 2019, no additional data is observed and the weight of all variables becomes zero. The estimates for the rest of the sample are obtained solely from the dynamics specified in the model.
By applying the estimated factor loadings, the factor can then be used to calculate monthly estimates of the target variable (and any of the input indicators, if desired). The results are shown in Fig. 1. The line represents the estimated annual growth rate of global exports of goods over the past 12 months, with respect to the 12 months before that. The points show the actual growth rate of global exports of goods. As explained above, it can be seen that the estimate and the actual figures coincide when the latter are observed. With this figure we can study the monthly movements of global exports. For example, one can see that the worst period of the global financial crisis took place, according to this model, in October 2009, when the annual growth rate reached
The model has a dynamic structure and this allows us to calculate forecasts for the unobserved factor (and, consequently, for the target variable) even when there is no new information available. The final model has a forecasting performance, measured by the MAE calculated at the last point before the release of the final figures, of 0.02. In other words, the forecasts generated by this model had an average error of 2 percentage points. This is a positive result, given the high variability of the annual target series.
Real-time growth rate forecasts, global exports of goods. Note: The solid lines represent year-end growth rate forecasts produced by the nowcast model estimated with the data available at each month. The dashed lines are the actual growth rates, published in April of the following year.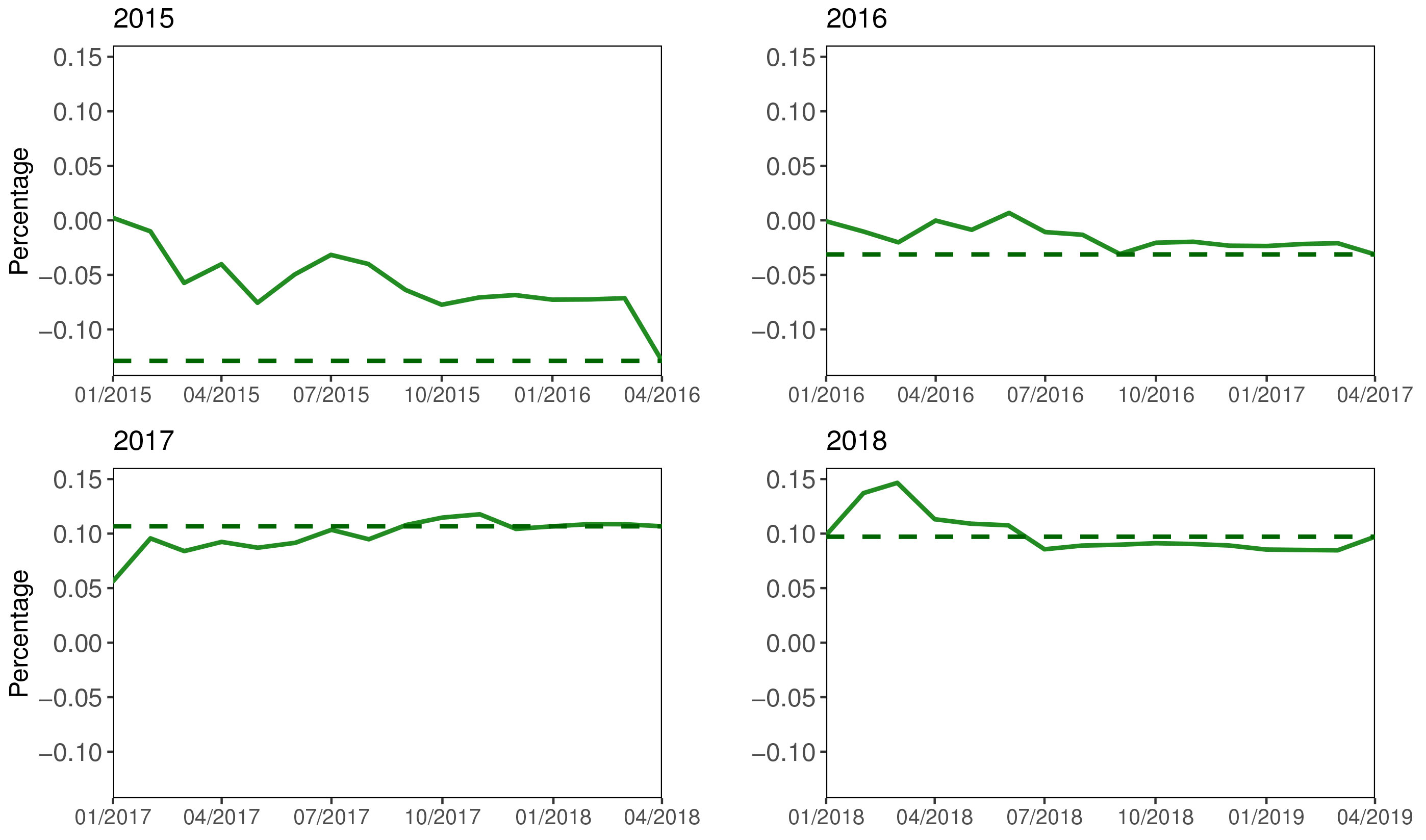
To visualize the real-time performance of the forecasts, we simulate the availability of the 26 indicators at every month since 2015.8 We then use each data vintage to estimate the model and produce a year-end forecast. The first forecast is calculated for January of the respective year, and then every month until March of the following year, the last month before the actual figure is released. This means that for the growth rate of 2015, for instance, we have monthly nowcasts from January 2015 until March 2016 and the actual figure is published in April 2016. The four panels of Fig. 2 show the results for the last four years. Given the lag structure of the model described above, a few months after the last observations, the model has no new information and the properties of the autorregresive model will dominate the dynamics. Because of this, we expect the forecasting performance to quickly deteriorate as the forecasting period is extended. Indeed, the first forecasts of each year is relatively poor. However, as new information becomes available, they rapidly improve.
Services accounted for 23.4% of total international trade of goods and services in 2018.9 This share, however, has followed an increasing trend. Services are therefore an important and growing portion of international transactions. Because of their diversity and intangibility, trade in services is generally more difficult to measure than merchandise trade. However, the statistical framework for trade in services is well established and its coverage has been constantly improving as more countries implement it. Internationally-traded services can be classified according to four categories: goods-related services (3.8%), transport (17.2%), travel (23.7%) and other services (55.3%), where the numbers in parentheses refer to the share of each category in total trade in services in 2018. The group “other services” comprises a wide variety of services: construction, insurance and pension services, financial services, charges for the use of intellectual property, telecommunications and information services, other business services, personal and recreational services, and government services. Consequently, the indicators that will provide information for the nowcasting model should reflect this wide variety of economic areas.
The target variable is therefore the global value of trade in services, as reported in [30]. This is an annual time series calculated in collaboration between UNCTAD, WTO and the International Trade Center (ITC). It is compiled from data from the IMF, Eurostat, the OECD, the United Nations and other national and international sources. It is published every April, when the figures for the preceding year, based on published official data for most countries, are released. The database also includes a quarterly series for services, but its coverage is more limited and subject to large revisions, so it will not be pursued here.
List of indicators, global exports of services
List of indicators, global exports of services
Sources: FRED
The list of indicators that were considered is presented in Table 4. First, the model will include existing series of exports of services atfor the main service exporters. Although most countries only publish quarterly data as part of their balance of payments statistics, some of them also release monthly series. After this, a long list of indicators aim to capture the different types of services.
International merchandise trade and trade in services are complementary. First, because internationally traded goods need to be transported from sellers to buyers (transport is one of the types of international trade in services). Additionally, goods transported may also be subject to international insurance. Indirectly, trade in goods could also create opportunities for financial services, telecommunications, information services and other business activities. Different categories of services could then be correlated to trade volumes, trade values or both. For example, while transport will be mostly dependent of volumes, insurance costs will vary with the value of the merchandise. For this reason, we cover indicators for both volume and value of merchandise trade. For volumes, we include a monthly index of world export volumes, cargo traffic through the Panama and Suez canals, port statistics from China and Hong Kong, and the Baltic Dry and Harpex Shipping indices. For values, we consider the value of exports of goods for the largest world exporters. Travel services are one of the main categories of international services and they can be directly measured through tourism statistics. The nowcast will test international tourism statistics for the largest destinations in the world, according to [32]. The growth rate of world tourism is also included. Since infra-annual statistics for China are not available, we add two series measuring tourist arrivals in North-East and South-East Asia. Goods-related services refer to manufacturing services and maintenance and repair. Even if they only represent a small share of total trade in services, they could be complementary to other service categories (finance and insurance, other business services, etc.) To account for this, we incorporate industrial production indices for the OECD, United States and Japan. Lag order selection, global exports of services Notes:
Annual growth rates, global exports of services. Note: The line represents the estimated annual growth rate of the past 12 months with respect the 12 months before that (i.e., it is a rolling cumulative growth rate over the last 12 months). This is the main output of the nowcast model. The points represent the actual values for the growth rate. The model anchors the estimates to the actual figures, so they coincide whenever the growth rate is observed.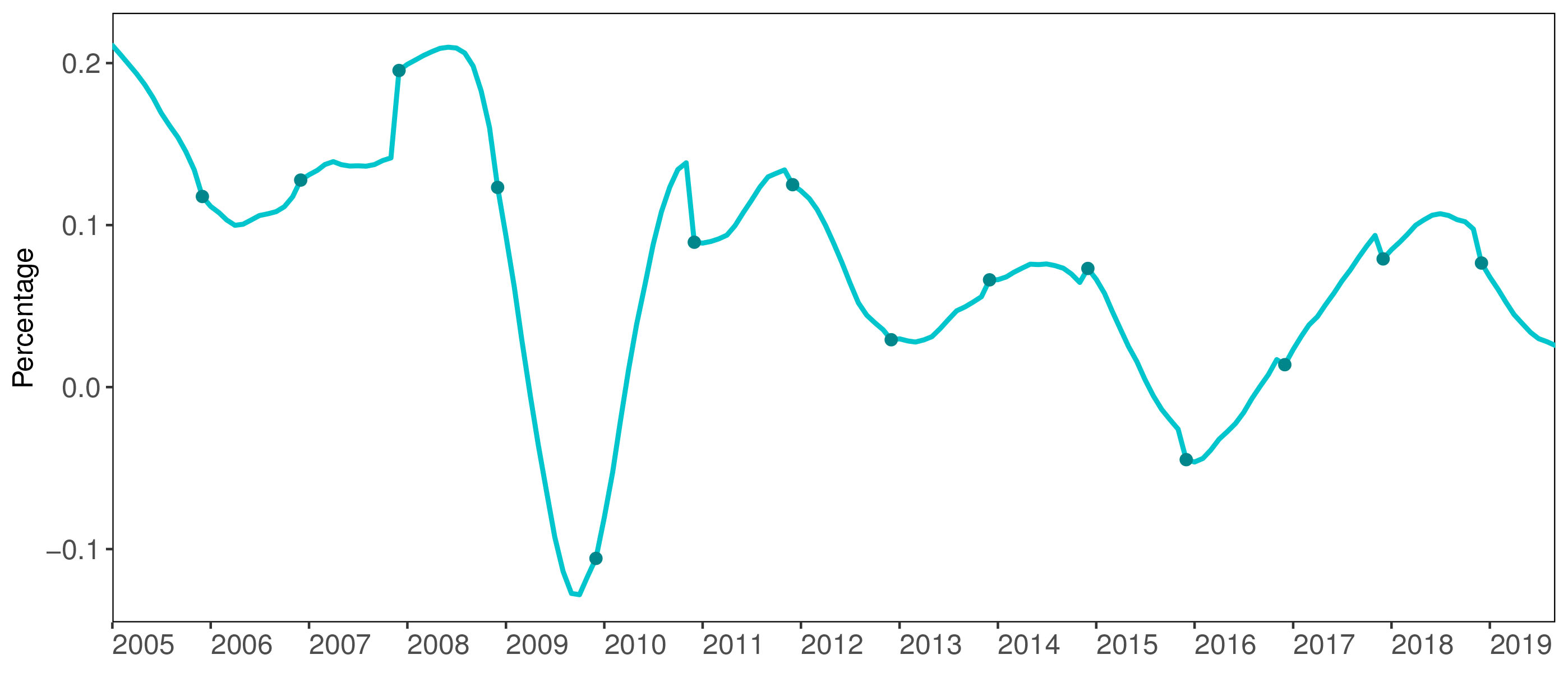
Real-time growth rate forecasts, global exports of services. Note: The solid lines represent year-end growth rate forecasts produced by the nowcast model estimated with the data available at each month. The dashed lines are the actual growth rates, published in April of the following year.
Capital movements around the world also generate demand for international services, in the form of financial, insurance and other types of business activities. However, not all financial flows require the same amount of added services. Foreign direct investment (FDI) is, in principle, more service-intensive because it needs to be supported by a wider range of financial and legal services. We therefore cover this area by including FDI indicators. We consider global FDI flows, as well as inward FDI to the OECD and two of the largest emerging markets: China and India.
In addition, there are other variables that could provide relevant information to estimate trade in services. One of them is the performance of the tertiary sector in the largest exporters. However, service-specific production indices are still not common and we could only cover the United Kingdom, Japan, France and Brazil, plus the retail trade index for the United States. We also include price information (the average unit value of global exports and the commodity price index) that could directly or indirectly affect the level of traded services.
Finally, we include survey-based information that could provide timely information on the target variable. Service-specific surveys are not as common as manufacturing or overall economic activity surveys, so we will only include a business confidence index for the services sector of the European Union; non-manufacturing purchasing managers’ indices for the United States, China and Japan; and general consumer confidence indices for the OECD and China.
An initial list of 19 indicators was proposed, but this was further reduced to a core model of 12 variables after the first estimation. The initial and core models are identified in columns (5) and (6) of Table 4, respectively. The next step was the selection of the lag structure of the dynamic model, which was obtained by testing several combinations of lags terms and choosing the best performer. The results, presented in Table 5, point to a model with
A forward model selection procedure, parallel to the one described above, suggests a final model consisting of the 22 variables marked in column (7) of Table 4. The monthly estimate for the world trade in services is shown in Fig. 3. We can see that this estimate does not have such a good performance as for global merchandise trade. This is evident, for example, in the large jumps registered at the end of 2007 or 2010, caused by sudden revisions of the estimate when the final figures were published. However, the model’s performance improves considerably later in the sample. Indeed, the model is chosen so that it minimizes the forecast error over the 20% final section of the sample and the corrections in the most recent years are much smaller. In total, the model can explain 86.2% of the variability of the annual target variable.
To evaluate the forecasting accuracy of the model, we calculate a final forecast at the last data release before the final figures are published and we measure the absolute error. When we average the errors over the final 20% of the sample, to obtain a forecasting MAE of 0.0125. Figure 4 presents charts of the real-time forecasts generated by the model over the last four years. These figures show that the model correctly identifies trend changes and other dynamics of the series. For example, the model suggested a downward turn for 2015. Although it settled at a forecast of about
This paper presented a methodology to track the real-time evolution of global trade aggregates. This tool can be used to produce estimates of the target variables based on the most up-to-date information available. It could therefore be used to identify, in a timely manner, any changes that would require adapting economy policy in affected sectors or countries.
This model relies on dynamic factor models adapted to take into account common characteristics of this type of data: heterogeneous frequencies, missing data and ragged ends. Moreover, the solution described in Section 3 was developed in a general manner and can be adapted to a variety of target variables and underlying indicators. Additional requirements (such as infra-monthly series and data available only after known transformations) could be introduced to the model in a straightforward manner.
The results are promising. The mean absolute forecasting errors are small and the estimated factor can explain a high proportion of the variability of the target variables. The charts presented in Section 4 show that the nowcasts quickly incorporate the information provided by the underlying indicators and correctly identify changing trends and turning points. However, it must be noted that the dynamic structure of the model considers only short lags, so these models should only be used to monitor the real-time evolution of the variables and to produce short-term forecasts for periods when some of the underlying indicators are already available.
There are several ways to improve this process. First, the co-movements between the variables are constantly changing and previously tested variables may lose or gain significance when monitoring the target variables. There are also new series becoming available or receiving more widespread diffusion. The variable selection process will therefore have to be repeated frequently. Second, it could be interesting to compare the nowcasting performance when the target variable is annual or quarterly. For this exercise, we deliberately chose annual target variables since our objective is to track official data with global coverage. However, there are other series available at a quarterly frequency that, at a cost of a reduced coverage, provide more timely information on the global aggregates. Third, a potentially interesting exercise would be comparing direct nowcasts of the target series with indirect nowcasts obtained by estimating the components of the series separately (for example, the value of merchandise exports by world regions, or the value of service exports by category). Finally, as a robustness check and a potential source of improvement, we can also attempt to replicate the process with alternative methodologies, such as the EM implementation employed by [17].
Footnotes
The size of some submatrices in the measurement and transition equations may need to be adjusted in certain cases. For example, if the number of lags corresponding to the quarterly variables (
Annual variables and monthly indicators expressed as year-on-year growth rates could also be considered in the model, but this would require expanding the matrices considerably. Although we will not do so here, they could be incorporated simply by including the relevant rows and columns in the matrices.
It could seem atypical to use disaggregates of the target variable as inputs to the nowcast. However, as mentioned in Section 2, this is a statistical exercise where variables are chosen because of the timely information they provide about the target variable, and not based on any causal or structural relationship. In addition, as mentioned in [![]() ], the evidence shows that adding information on disaggregates to a forecasting model of an aggregate can indeed improve forecast accuracy.
], the evidence shows that adding information on disaggregates to a forecasting model of an aggregate can indeed improve forecast accuracy.
Seasonal adjustment was calculated with the R package seasonal version 1.6.1, using the default options.
Note, however, that “soft” indicators could show low significance since they normally add little information once the “hard” indicators are published. Their principal advantage is that they are available in a timely manner. They should therefore remain in the model even if their contribution seems minimal.
For the second criteria, the mean absolute error of the forecasts was also calculated at previous data vintages, without significant changes to the results. These robustness checks are available from the author on request.
We use data on world exports and not imports. At the global level, up to measurement errors and reporting issues, both are equivalent.
This is only a pseudo-real-time analysis since the actual data availability at each month is unknown. Even if we know the date of each data release, according the publication schedule of each indicator, most of the times historic data is also revised at each release and we do not have the details for each of these backward revisions.
Acknowledgments
The author would like to thank all members of the Development Statistics and Information Branch of UNCTAD for their useful discussion and suggestions during the preparation of this paper. Also, to the organizers and participants of the UNCTAD Research Seminar and the CCS-UN Technical Workshop on Nowcasting in International Organizations for the comments received.