
Abstract
Household financial distress is a complicated problem. Several social problems have been identified as potential risk factors. Conversely, financial distress has also been identified as a risk factor for some of those social problems. Graphical models can be used to better understand the co-dependencies between these problems. In this approach, problem variables are network nodes and the relations between them are represented by weighted edges. Linked administrative data on social service usage by
Introduction
Household poverty and debts are complex problems. For both types of financial distress, researchers have identified numerous risk and protective factors, which range from the individual level to various layers of the broader social context [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]. This context includes societal, political and macro-economical influences [15, 16, 17]. Yet, according to some authors, this research has not led to a comprehensive theoretical understanding of the causes of financial distress [18, 19]. One possible explanation these authors offer for this absence, is that a comprehensive framework requires the combined effort of several scientific disciplines (e.g. psychology, sociology, economics). This is certainly indicative of one aspect of the complexity surrounding financial distress. Another aspect of this complexity is the difficulty in establishing the direction of the relationship between financial distress and certain suspected risk factors [20], because some of the known risk factors are also among the many potential consequences of financial distress. These include the impact of financial distress on physical health [21, 22, 11, 23], mental health [24, 25, 26, 27, 28], workplace performance [29], and cognitive functioning [30, 31, 32, 33, 34]. For instance, mental health problems may be found to increase the risk of financial distress, but the connection could also be the other way around (i.e. financial distress increases the risk of mental health problems), or there could be a reciprocal relationship between them [35, 36, 37].
Because of such reciprocal effects, it may not be helpful to regard financial distress only as an outcome that is to be explained by a set of known risk and protective factors. Rather, in order to better understand financial distress, we argue that it should be considered as one element within a broader network of interrelated variables. Thus, to better understand financial distress, we should seek to understand this broader network. Psychological networks are used for similar reasons [38, 39].
The structure of this network of variables can then reveal (1) which nodes (problem variables) occupy a central position, so that any change in these nodes is likely to reverberate through the entire network, and (2) which edges (relationships) play a key part in conducting such cascades, so that reducing these dependencies is likely to reduce the overall sensitivity of the network to the impact of adverse changes [39, 40].
Thus, the network-of-variables approach can potentially provide both theoretical insight to social scientists as well as valuable directions for intervention targets to policy makers and social care professionals. In this paper, we propose to describe financial distress within a broader network of variables by analysing a dataset of municipal household register data with statistical graphical models. We will explore how a network structure can be derived from data on financial distress and other problems; and whether the resulting network can be meaningfully interpreted with respect to social policy.
In this context, a graphical model describes a set of variables (nodes) and their undirected conditional relationships (edges). To illustrate this idea, Fig. 1 gives a reduced version of our larger result – discussed in Section 4 – as an example. This small graph shows the relations between household debt, financial support (FinSup), general youth care (GCyth), school absenteeism (Abs) and NEET (Not in Education, Employment or Training). The width of the edges signifies the relative strength of the undirected conditional relationships [41, 42, 43, 44].
The graph shows that educational problems in households (absenteeism, NEET) are not directly connected to debt, but that there are indirect connections through general youth care and financial support. Although this limited graph is given here only for illustration, the potentially interesting role of municipal youth care and its relations is apparent, since educational problems appear to be linked to financial distress mainly through general youth care. This suggests targets for study and intervention. We will further explore such relations in what follows.
Graph of the variables (a) financial distress, financial support (FinSUp) and debt; educational problems, absenteeism (Abs) and Not in employment, education or training (NEET); and receiving general youth care (GCyth).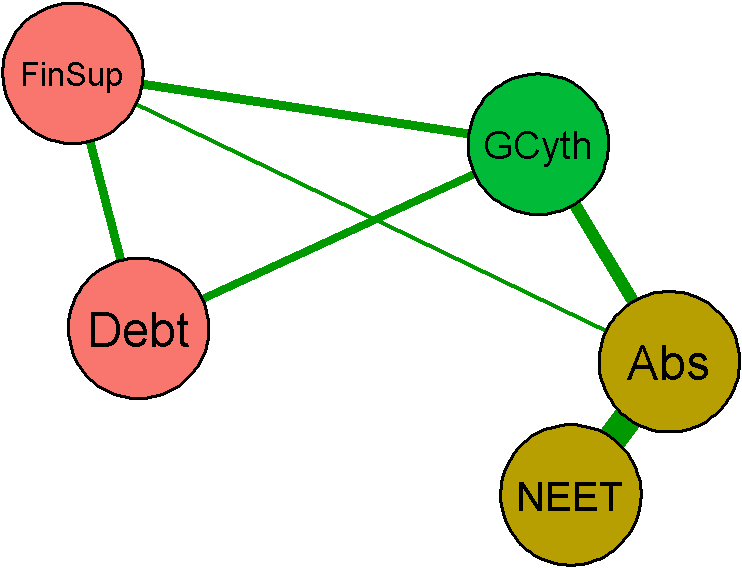
Section 2 describes the specific graphical model that is to be estimated (a pairwise Markov random field with binary variables), the eLasso method of neighbourhood selection to estimate the model, as well as a number of ways to evaluate the resulting graph. The data set is introduced in Section 3 and the graph that was estimated from these data is presented and discussed in Section 4. Finally, Section 5 provides a discussion and conclusion.
Model definition
The core principle of graphical modelling is the representation of variables as nodes and relationships between variables as edges in a graph. Modelling a variable of interest, such as financial distress, within a larger “network”, or graph, of variables is an idea with a long history, encompassing at least two traditions. First, that of directed models, due originally to Wright in 1921 [45], which developed into modern-day “structural equation models” (SEM [46]; and their modern variations [47]), and “structural causal models” [48]. The advantage of these approaches is that, if the directions of the “arrows” in the model are known in advance, estimation yields causal quantities of interest [48]. Their disadvantage is that they require deep a priori knowledge of the underlying causal process as an identification strategy [49].
A second tradition, perhaps less employed within the social sciences, is that of undirected graphical models, due originally to Gibbs in 1902 [50] and Ising in 1925 [51], and applied as “Markov random fields” in a variety of fields including statistical physics, protein function prediction, image analysis, and spatial statistics [42, 52]. These models have the disadvantage that their parameters are not interpretable as causal parameters of interest. Their advantage, however, is that causal “flow” between variables can still be represented without a priori determinations of the directions of causality between the variables [42]. For this reason, they have enjoyed a recent revival within psychological studies as a flexible way of studying constellations of variables on which less information regarding their precise causal interactions is available [53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63]. For the same reasons, we adopt Markov random fields as a convenient framework to study financial distress and its interactions with other variables.
Markov random fields may be parametrised in various ways, depending on the type of variables (discrete or continuous) and whether higher-order interactions are thought to be important. In this work, we will concentrate on a model for binary (dichotomous) variables, in which only pairwise interactions are modeled – that is, a “binary pairwise Markov random field”. Note that this model can also be seen as a loglinear model [64, 65] for the cross-classification of all variables with interactions up to order two; we prefer to use the term Markov random field, to emphasise that the model is part of a family of undirected graphical models that can also be applied to data sets with continuous variables [66]. The nodes in the model are random variables that are either in state
The node tendencies
Note that there are no self-interacting nodes in this model, which means that the edge weights on the diagonal of the matrix are all 0. Edges have no directions, making
Let configuration
Since the edge weights
The denominator – also known as the “partition function” – in Eq. (1) contains a summation over all
The final part of Eq. (2) is of course a familiar expression. It shows that for every node, the conditional probability (i.e. conditional on all other nodes) to turn “on” is simply a logistic probability (“sigmoid”) function, in which the independent variables are the direct neighbours of the node. A difference between the MRF and a series of logistic regression models is that in the MRF the coefficients
Given a fully observed dataset
where
Both challenges can be addressed by leveraging the logistic form of the model shown in Eq. (2). Instead of directly optimizing Eq. (3) and computing
Here we follow the proposals of Ravikumar et al. [74] and van Borkulo et al. [53] for the estimation of binary pairwise MRFs:
For each node
where Using the method described by Friedman et al. [76], for each of the
Here, the number of neighbours selected is For each node, the model with the lowest eBIC score is selected. When different logistic regression models estimate the same parameter An edge
The above procedure implemented as the eLasso method in R package IsingFit [53]. An excellent overview of alternative procedures can be found in Koller & Friedman [42]) and Murphy [52].
There is no straightforward way to evaluate a pairwise MRF with binary variables. Theoretically, a
Edge-weight accuracy and centrality stability
We use bootstrapping as implemented in R package bootnet[57] to construct confidence intervals around edge weight estimates
In addition to the values of the edge weights, the overall structure of the graph is of interest when interpreting MRFs. Therefore the sample stability of the estimated structure should be evaluated, for example by looking at sampling fluctuations in the estimated node centrality (see Section 2.4 for a discussion of centrality). However, because bootstrapping does not give accurate confidence intervals for centrality measures, Epskamp et al. [57] proposed a different approach. The idea behind this approach is that structural features (the centrality indices) that are present in the full sample, should also be found in smaller sub-samples of the data. Out of
According to Epskamp et al. [79], CS-coefficient
In contrast to univariate logistic regression models, effect estimates in the MRF are not unique for each node, as they are shared between node pairs. Because of this, the predictive ability of the MRF may be expected to suffer in comparison to logistic regression models. We will compare the predictive performance of the MRF to logistic regression models to get an informal sense of how large the difference is. Additionaly, Haslbeck and Fried [60] suggest that node predictability may inform intervention strategies: nodes with high predictability can potentially be influenced by targeting neighbouring nodes. Predictions by the MRF can be obtained from the conditional probability models given in Eq. (2), which can be cross-tabulated in held-out “test” data with the observed values of that node, yielding standard classification metrics, such as the true positive rate (TRP, also known as “recall” or “sensitivity”), the precision, and the F1-score. The performance of the graph will be compared with a series of univariate logistic regression models, one model for each variable while using all other variables as independent variables. Since the regression coefficients of the univariate models are not averaged to determine edge weights between node pairs, these models can be expected to outperform the graph on classification metrics. It is of interest to see how much predictive performance the graphical model “loses” in comparison to the univariate models. Since our main aim is to compare predictive performance between models, we will use a predicted probability of
Model interpretation
Node centrality measures
Centrality is an expression of the relative importance of nodes, and can capture useful features of the estimated structure for further study. For example, if the public services in our own data can be interpreted as proxies for underlying problems, then more central problems may be more likely to impact other areas, making them interesting targets for intervention and further study.
There are several ways to measure centrality. Three of the most regularly used centrality indices in psychological networks are strength, closeness, and betweenness. Strength is the absolute value of edge weights connecting the node. Closeness is the average shortest path distance (inverted absolute edge weight) from one node to every other node in the graph. High closeness indicates a relatively low average distance between that node and any other node. Betweenness measures how often a node is on the shortest path (again using inverted absolute edge weight for distance) between each pair of nodes. The betweenness
where
In the context of financial hardship and related social problems, strength centrality indicates how strongly a problem interacts with its neighbours, relative to other problems in the graph. High strength centrality can be due to a few strong connections, or a high number of connections, or both. Closeness and betweenness are less easily interpreted in this context, as these measures not only involve the direct connections of each node, but also take into account edges between nodes without direct connections to the node in question. In a geographical setting, the nature of these concepts is clear. But the exact meaning of closeness and betweenness in a graph that represents relations between problems rather than physical distances between locations requires careful interpretation [63]. Specifically, problems that are indirectly connected do not necessarily have an increased risk to co-occur, even if one of the nodes has high closeness or if the connection runs through a high betweenness node. For instance, in Fig. 1 Absenteeism and Debts are not connected by an edge. In our data, households where absenteeism occurs do have an increased risk of debts and vice versa. Yet, the graph would also be consistent with two subgroups that use some of the same social services (financial support and general youth care) and either have an increased risk of debts, but not of absenteeism, or the other way around, but never both.
So, while high closeness or betweenness nodes can certainly be used to identify potential intervention targets, the actual impact that nodes have through indirect connections cannot be determined from the graph alone. Despite this caveat, closeness and betweenness do help to identify nodes that play an important role in multi-problem situations, which is relevant to theoretical understanding of financial distress and to the development of intervention strategies both. A social service (and the underlying problem) with high closeness indicates that the problem may increase the overall risk of having other problems (and vice versa), both directly and indirectly. High betweenness signals the possibility that problems without direct connections are more likely to co-occur if intermediary problems are present, or that these problems are important elements in multi-problem situations.
A key strength of graphical models is that their interpretation can be facilitated using graph visualizations such as that presented in Fig. 1. However, the layout of such graphs is somewhat arbitrary and can sometimes give a misleading picture of the network structure. A more formal way to identify which nodes can be regarded as groups is through a community finding algorithm, such as the “walktrap” algorithm of Pons & Latapy [80, 81]; see also Yang et al. [82] for an overview of other such algorithms).
Walktrap performs short random walks through a graph. Each step from node to node is probabilistically determined by (absolute) edge weights. Short walks tend to become “trapped” in groups of strongly connected nodes. After many random walks, clusters or communities of nodes can then be identified by comparing how often nodes were visited together during the same walk. The significance of communities is that they identify groups of problems (social services) that have heightened risks of coinciding, which can provide valuable insights for formulating social policy strategies. Like closeness and betweenness, this algorithm treats edge weights as distances. As with those centrality measures, conclusions should be drawn with the some caution.
Data
Data collection and preparation
Register data on public services over the years
Public services in Utrecht are used by a minority of households. As a consequence, binary variables on public service usage can be expected to be imbalanced. Public service usage is higher among lower social-economic status (SES) households. The imbalance will, therefore, be less extreme in a sample that contains many low SES households. Since these households are the primary target of social policies, focusing on this group makes contextual sense as well. Because no direct information on household SES was available, we used neighbourhood level information on social housing to select neighbourhoods with the lowest overall SES. Social housing in the Netherlands is provided by subsidised non-profit housing corporations that offer affordable housing to households based on a means test. Access to social housing typically has a waiting time of several years. Consequently, social housing is strongly related to socio-economic status (SES). Oversampling those who qualify for social housing somewhat remedies the class imbalances in public service usage. This oversampling means that the intercepts
Variables and descriptives
The data set contains information on all households (
Proportions of (semi-)public service use. High refers to High social housing (
), Other to Other neighbourhoods (
)
Proportions of (semi-)public service use. High refers to High social housing (
Proportion of households receiving social services, high social housing neighbourhoods (light) and all other neighbourhoods (dark) compared.
Based on the original data sources, the variables are grouped a priori into five types (areas of social policy):
Disability support services provide persons with physical disabilities, including geriatric problems, with assistive technologies (e.g. wheelchairs, home modifications), specialised semi-public transport (subsidised share taxis) and light housekeeping assistance; Education services are interventions that deal with school absenteeism and NEETs (persons Not in Education, Employment or Training); Finance services provide financial support (unemployment benefits) and debt relief programmes; Social care services assist adults who require aid in independent living due to, for example, light intellectual disabilities and chronic mental disorders; Youth care services aid youths, young adults up to
For each of the 17 (semi-)public services, the proportion of
Not all variables measured can be equated with specific underlying problems. Both general care forms (GCyth and GCsoc) in particular cover a very broad range of problems a household might encounter. General care can also be responsible for involving more specialised social services, so to some extent the graph will depict the infrastructural design of social services. However, with these reservations in mind, it is reasonable to assume that the social service variables are indicators of underlying problems and that any edges between them reflect actual connections between these problems, which we will estimate and interpret in the following section.
In advance, we expected social services for similar problems to form recognisable sub-graphs (communities) within the graph according to the grouping of nodes in Table 1. Furthermore, based on the literature on financial hardship, we expected high centrality scores for debt and financial support. High centrality scores are also expected for both general care forms, since these services are designed to be gateway services to more specialised forms of support. In this section, we first describe visual aspects of the graph. In Section 4.1 we provide a qualitative interpretation of the graph. More formal evaluations of the graph follow in Sections 4.2 (Centrality) and 4.3 (Classification performance).
Figure 3 shows the graph that was estimated by using the eLasso method described in Section 2 on the sample of
Graph of social service provision according to administrative registers. Pairwise binary Markov random field estimated by eLasso. Green edges are positive, red edges (PubTr-FinSup; PubTr-GCyth; HKbasic-FinSup; HKbasic-Debt; GCsoc-YthSpec; GCsoc-Abs) negative; edge width is proportional to edge weight. Nodes are coloured by communities identified with Walktrap. Blue: “Disability support”; Purple: “Light social support”; Red: “Social and Financial support”; Bright green: “Youth care”; Olive green: “Education”. The online version of this article is in colour. All colour labels are explicitly described to make the greyscale version of the graph understandable.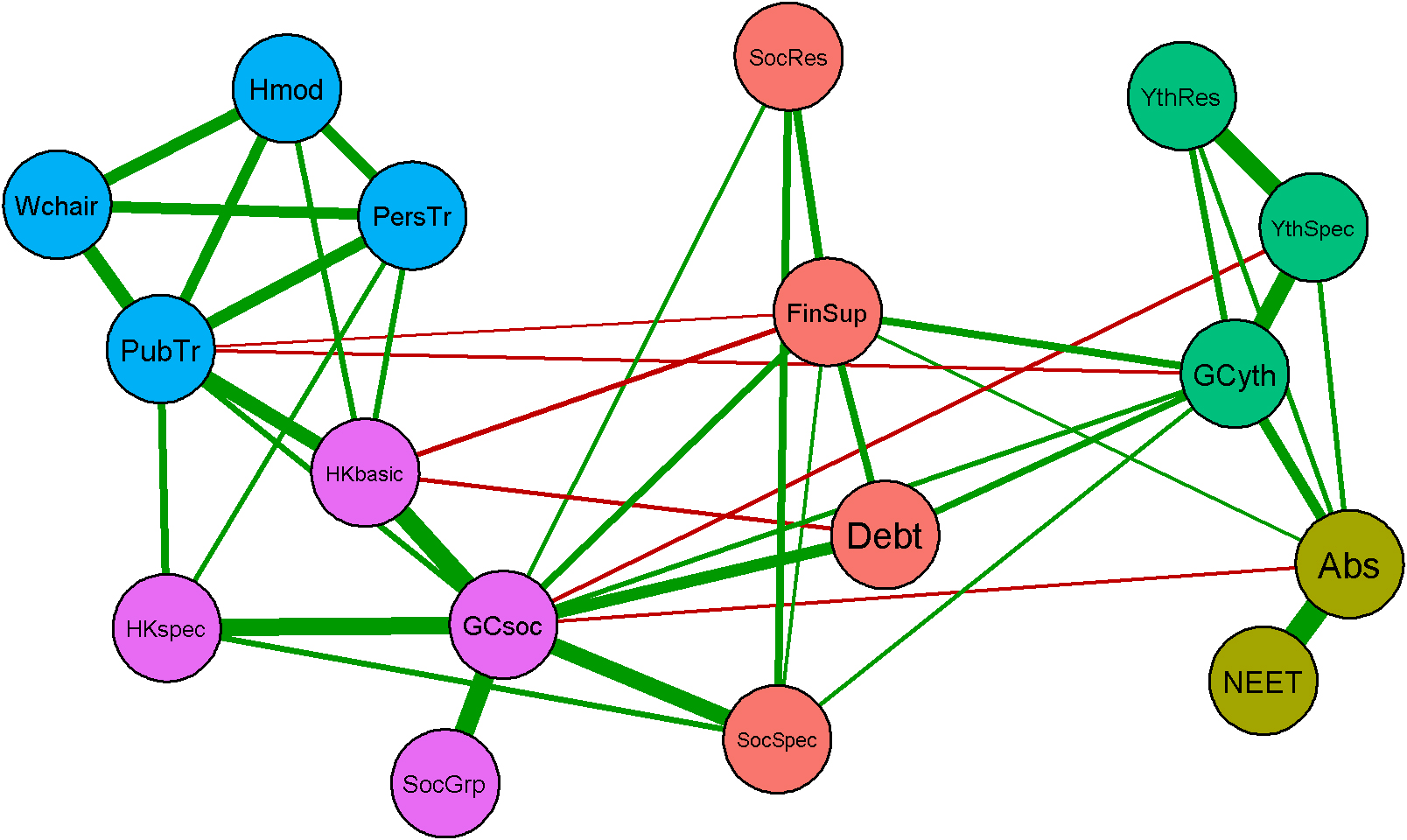
Just as there are five groups in the a priori grouping of services in Table 1, there are five groups according to the community-finding algorithm. However, the composition of the groups is somewhat different. The disability support group (blue nodes in Fig. 3) now consists of wheelchairs (Wchair), home modifications (Hmod), personal transport (PersTr) and public transport (PubTr). Basic housekeeping (HKbasic) was grouped with these disability support nodes according to Table 1, but here it is grouped with the three lightest forms of social care, general social care (GCsoc), housekeeping special (HKspec) and group social care (SocGrp) instead. We shall refer to these nodes collectively as “light social support” (purple nodes). The heaviest forms of social care, specialised (SocSpec) and residential social care (SocRes) are now grouped with the finance services debt relief (Debt) and financial support (FinSup) in a group we call “Social and financial support” (red nodes). The youth care group (bright green) with general (GCyth), specialised (YthSpec) and residential youth care (YthRes) is the same as in Table 1 and so is the group of education nodes (olive green) with absenteeism (Abs) and NEET.
The graph shown in Fig. 3 illustrates which social services most commonly coincide in households, controlling for which other services are provided. Taken together, these co-occurrences form groups that can be related to different types of households. There appear to be two “super-groups”: There are relatively strong connections between all youth-related services (the education and youth care groups) on one side and on the other side there are relatively strong connections between light social care and disability support. The only direct positive link between these super-groups is the (weak) edge that connects both forms of general care (GCyth and GCsoc). In between these larger clusters is the group of social and financial support nodes.
The (blue) disability support nodes (Wchair, Hmod, PersTr, and PubTr) are all strongly connected to each other. None of these nodes have positive links to the group of social and financial support nodes (red nodes), nor to any of the youth-related nodes (bright green and olive green). So, conditional on intermediary nodes, households that receive disability support (except subsidised mass transport, discussed below) are neither more, nor less likely to experience problems in these areas than households without disability support. According to international studies, people with disabilities are among the risk groups for financial hardships. The graph suggests that this may not be the case in the Netherlands, or that financial problems and physical disabilities are independent conditional on other problems. The four disability support nodes all represent services that aim to alleviate financial burdens caused by disabilities, so perhaps this is one of the reasons why debts are not connected directly to disability support in the Netherlands.
The only positive edges that connect the disability support group to other nodes, are links to the social care group. The strongest of these links is the edge between subsidised public transport (PubTr) and basic housekeeping (HKbasic). These services are both associated with geriatric problems. This explains why both nodes have negative connections to debts, financial support (FinSup) and general youth care (GCyth). Elderly persons are over the retirement age and hence they cannot receive unemployment benefits (i.e FinSup). Furthermore, elderly are the least likely adult age group to have problem debts. They are also unlikely to have any children (including young adults under
The light social support group (purple) consists of four nodes: Basic housekeeping (HKbasic), special housekeeping (HKspec), general social care (GCsoc) and group social care (SocGrP). General social care is linked by strong edges to each of the other nodes in this group, while these other nodes are not directly connected to each other. Furthermore – with the exception of the edge between special housekeeping (HKspec) and specialised social care (SocSpec) – general social care is responsible for all positive edges that connect light social support (purple) to social and financial support (red) and general youth care (GCyth). General social care is negatively linked to specialised youth care (YthSpec) and absenteeism counselling (Abs). These latter two services are both associated with households that include minors or young adults living at home. As a rule, general care to such households with (adult) children will always be provided by youth care professionals (i.e. GCyth) rather than social care (GCsoc) professionals. The positive link between both types of general care is possibly caused by independent young adult households, who received youth care which was transferred to social care teams after these young adults reached the legal age limit (i.e.
All three youth care nodes (bright green) are directly connected to each other. They are also all connected to absenteeism counselling (Abs), so there is an obvious link between educational problems and youth social and mental health problems in the graph. General youth care (GCyth) additionally has four weak to moderately strong links to nodes of other groups, including to three out of the four nodes in the social and financial support group (red). Residential youth care (YthRes) concerns the most severe youth problems, that often involve child protection interventions. Many households receive specialised youth care (YthSpec) before, during or after residential care is provided. This explains why specialised youth care is strongly connected to both other youth care nodes, while the edge between general and residential youth care is relatively weak.
The education nodes (olive green) absenteeism (Abs) and NEET appear to be closely related to the youth care group (bright green). This makes sense, since both groups are associated with children or young adults. Despite this strong connection to youth care, the education nodes probably form a separate group because they are connected by the strongest edge in the graph. This connection is so strong because many NEETs have also been registered for absenteeism counselling. Surprisingly, NEET is not directly connected to either financial support (FinSup) or debts. In our sample, households with NEETs are in fact more likely to receive financial support or debt relief services, but these nodes appear to be independent, conditional on absenteeism and, in the case of debts, also on general youth care (GCyth) or financial support (FinSup). The positive edge between absenteeism and financial support can represent both unemployed young adults with a history of absenteeism (who may also be NEETs), as well as households with unemployed parents whose children receive absenteeism counselling (many of whom are not NEETs). According to the graph, NEETs who receive no unemployment benefits (FinSup) or general youth care (GCyth) are not more (or less) likely than average to have problem debts.
Bootstrapped confidence intervals of edge weights between each node pair (grey area) around bootstrapped edge weight means (grey) with original sample edge weights in red. Names not shown for legibility; estimated edge weights can be found in the weighed adjacency matrix in the Supplementary materials.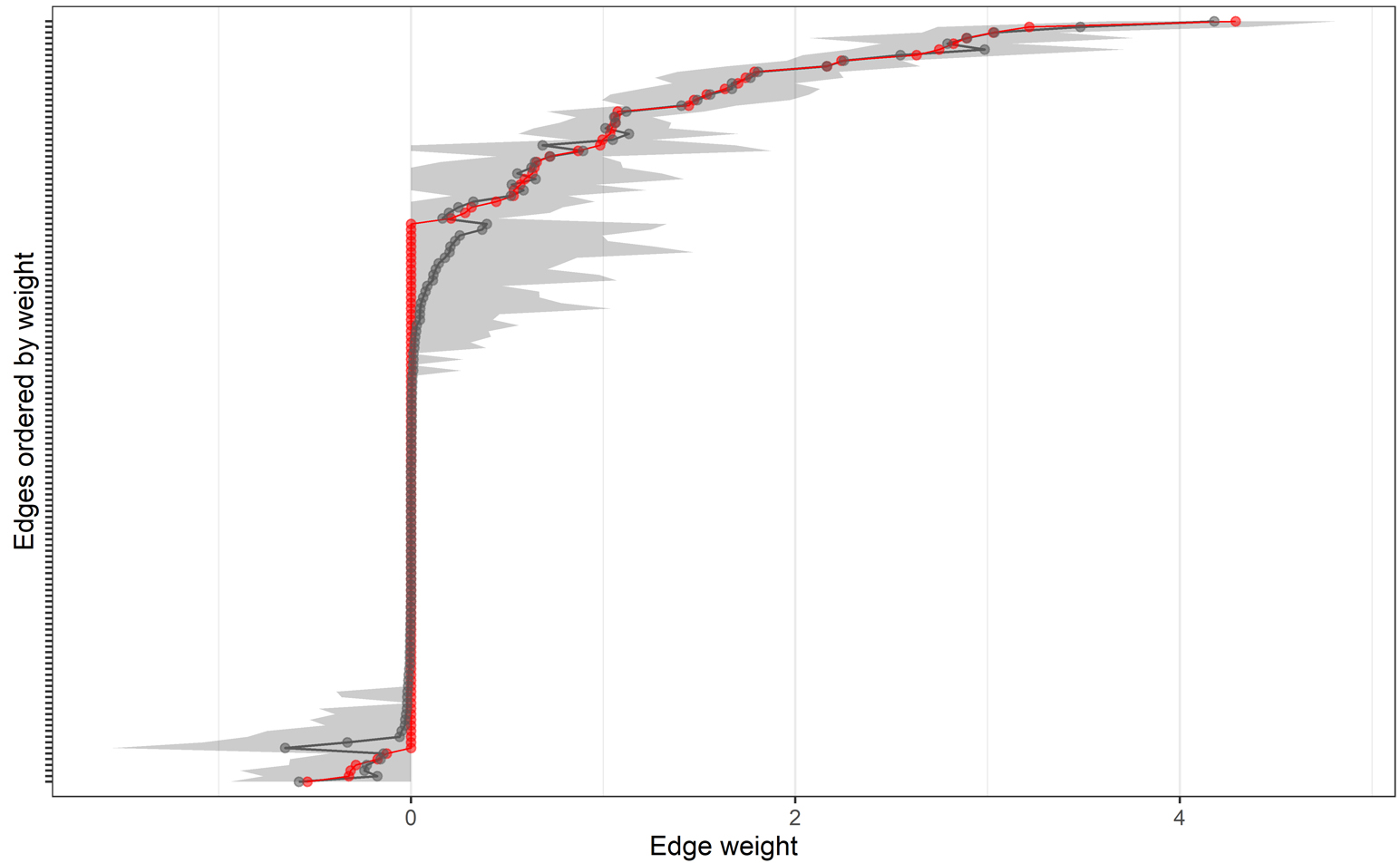
The social and financial support group (red) consists of four nodes that represent unemployment (FinSup), debts and severe social problems (SocRes and SocSpec). Financial support is connected to each of the other nodes in the group and it is the only node in the graph with connections to nodes in all five groups, although the edge with public transport (PubTr) in the disability support group is negative. All four social and financial support nodes are connected to general social care (GCsoc) and three of them are also linked to general youth care (GCyth). The social and financial support group is unlike other groups in the graph, which all broadly correspond to recognisable types of households and associated problems, for example: Physical disabilities, elderly with geriatric problems, adults in need of light support for independent living, and households with children or young adults facing youth-related problems. The social and financial support group, in contrast, is linked both to (adult-oriented) support for independent living and to youth related problems. The strongest of these links are the edges that connect financial support (FinSup) and debts to both forms of general care (GCsoc and GCyth).
The bootstrapped confidence intervals for all
Figure 5 shows the standardized strength centrality scores of all nodes. General social care (GCsoc), public transport (PubTr), basic housekeeping (HKbasic) and general youth care (GCyht) highest strength scores. All of these nodes have in common that they are strongly connected to nodes within their own group and have relatively strong connections to nodes of other groups as well. If the public services in our data can be interpreted as proxies for underlying problems, then these centrality scores may provide clues to which problems are most likely to negatively impact other areas and may therefore be of interest to social policy makers who seek to improve prevention or social support efforts.
The high rankings of both general care (GCsoc and GCyth) forms reflect the role these services play in managing the involvement of specialised care, as well as the fact that households dealing with social and mental health issues are more likely to experience financial distress. Public transport (PubTr) and basic housekeeping (HKbasic) are connected to geriatric problems, but not necessarily to severe physical disabilities. The high strength scores of these nodes are caused by connections to services that are associated with physical disabilities. Hypothetically, this connection may be caused by the worsening of geriatric problems over time. Public transport and basic housekeeping could be early indicators of future requests for additional disability support; information like this may be of use to social policy makers, for example with regard to prognosticating future demand for social services.
Centrality indices: Strength, closeness and betweenness.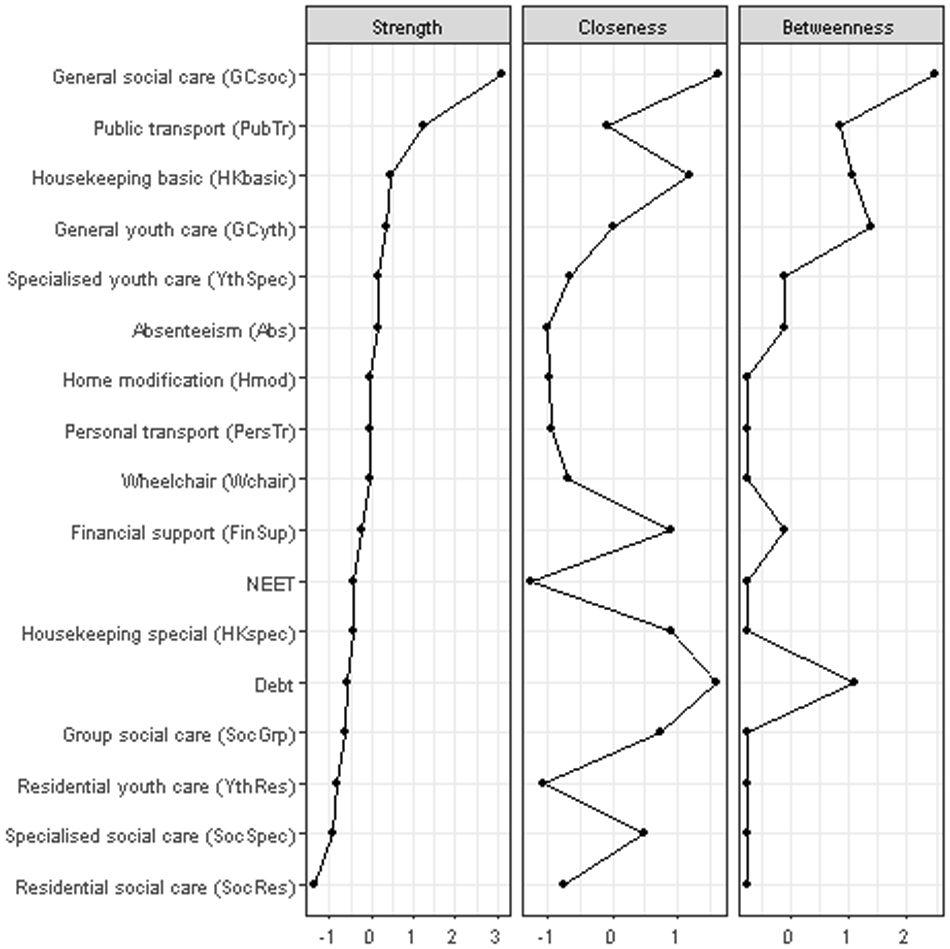
Correlation of strength centrality indices from smaller bootstrapped samples with the original sample strength index. The lower limit of the CI (shaded area) reaches 0.7 for bootstrapped samples of 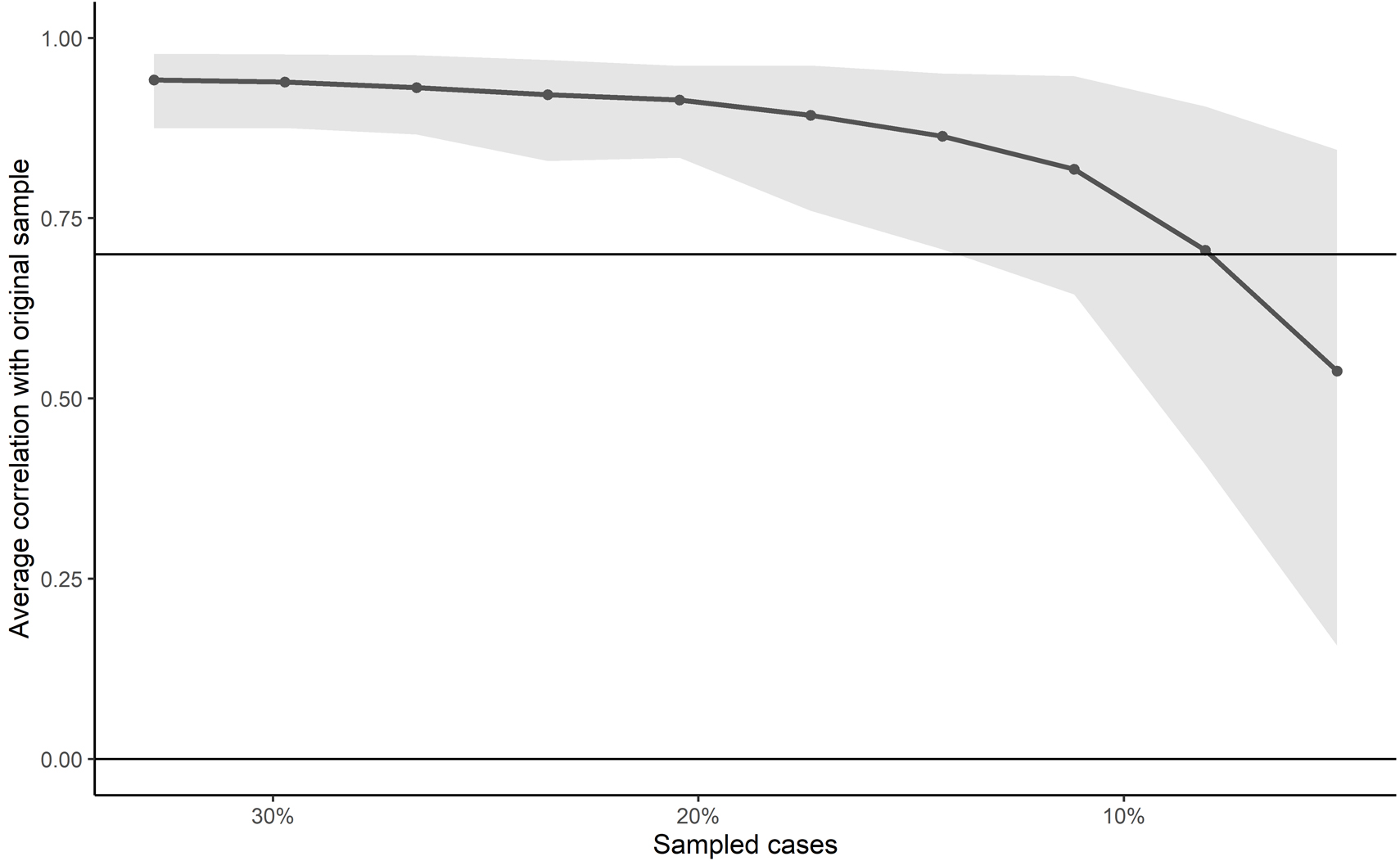
The centrality indices for closeness and betweenness are also shown in Fig. 5. The scores for the debts node are the most strikingly different from the strength centrality score. This relatively weakly connected node has the highest closeness score and the third highest betweenness score. While there is no established way to interpret these indices, this does reinforce the qualitative observation that debts and financial support (FinSup) have a special position in the graph, as these link the youth-related nodes to nodes that involve social care. Another interesting observation on closeness and betweenness is that while absenteeism (Abs) has a relatively high strength centrality score, the closeness and betweenness scores are much lower. Since the high strength of absenteeism largely results from the strong link with NEET, closeness and betweenness seem to better reflect the position of absenteeism than strength centrality, or at least they provide a more nuanced picture than strength centrality by itself.
The stability of the strength centrality index was tested over
The graph can be used to predict node states if the states of neighbouring nodes are given. As discussed in Section 2.1, the conditional probability function for a single node is logistic. However, even when this fact is used in MRF estimation, the estimates from the MRF are not necessarily equal to those from logistic regression, due to the model restriction that edge weights (regression coefficients) should be equal for both nodes in each pair. Therefore, a difference in performance between the MRF logistic models and separately fitted logistic regression models is likely.
The graphical model was used to predict node outcomes on the test data. A univariate logistic regression model was fitted for each node, using all other nodes as predictor variables. The univariate logistic regression models were then used to predict node outcomes for comparison against the graphical model. The classification performance as measured by True positive rate (TPR/Sensitivity/Recall), Precision and F1-scores [84, 85] is shown in Table 2.
Classification metrics of the graph and univariate logistic regression models (LR) compared: TRP (True positive rate), Prec (Precison) and F1 (F1 score)
Classification metrics of the graph and univariate logistic regression models (LR) compared: TRP (True positive rate), Prec (Precison) and F1 (F1 score)
As is to be expected with variables that have severe class imbalances (see Table 1), in absolute terms the graphical model struggles to correctly classify cases across all nodes. The mean scores reflect the poor overall performance of the model with TRP
The aim of this article was to demonstrate how undirected models can be valuable to social policy by applying them to linked administrative data. The resulting graph provides an intuitively understandable overview of how 17 municipal social services at household level are related. The graph is readily interpreted, yet contains a large amount of information. This ability to present complexity in a way that makes it easy to interpret can by itself be regarded as a valuable result.
The high degree of centrality stability in our model indicates that the structural features of the graph can reliably be found in random subsets of the data. The estimated structure, therefore, cannot be attributed to mere random noise. General patterns of node interrelation correspond to prior knowledge and expectations. The groups that were discovered with a community-finding algorithm roughly match the a priori grouping. The few nodes that were found by the walktrap algorithm to be in different groups – basic housekeeping and specialised and residential social care – were all strongly connected to their expected groups. Overall, these results increase our confidence that the remaining findings also represent real-world phenomena.
Several of our findings from the graph result from the organization of social care in Netherlands. For example, “general social care” is a service that is administratively intended to play a central role in the further referral and provision of other social care, and this node is indeed found to have the highest centrality in the graph. While it could be said that such findings could have been predicted in advance based on the administrative organization of social services, administrative realities do not always match the reality on the ground.
Furthermore, several of our findings are potentially useful from a substantive point of view. Most striking is the high betweenness of financial hardship variables (central red nodes in Fig. 3). We conclude that these variables may play a pivotal role in conducting the “flow” between, on the one hand, disability-related and light social care problems such as a need for special housekeeping, and, on the other hand, youth care and educational problems. The estimated graph predicts that intervening on financial hardship problems makes these two groups of variables almost independent. In other words, vulnerability to financial problems is a common denominator for households with either of these different types of problems. We also note that, on a smaller scale, absenteeism plays a similar role in connecting NEET to the broader network.
Our work also has a number of limitations that warrant further study.
First, we have used observational, cross-sectional data to infer something of the (unknown) causal connections between variables. To some extent this drawback was mitigated by using undirected models, which do not attempt to infer causal direction. However, some caveats do remain with this approach. Temporal psychological networks have been used to predict key psycho-pathological transition events in patients with a history of depression, by applying the concept of critical slowing down before phase transitions that is used in research on climate and ecosystems, and recently also in medical and psychological research [62, 86]. Introducing time based on registration data into a graphical model will provide many new challenges. The added complexities that come with time and registration data were the reason not to include time in this study. In future work, we hope to leverage the fact that our full data set also contains longitudinal information.
Second, although administrative registers in the Netherlands have as an advantage that they contain all residents in the municipality at hand, a disadvantage is that the variables observed are simply those resulting from the administrative process, and were not necessarily intended for social research. In general this may result in problems of measurement error and validity [87, 88, 89].
Specifically, in our analysis the ideal measurements would have been those of social problems, but we have observed social services. While these two are very closely related, they are not identical, and we were only able to take account of these differences in the interpretation of our results through substantial knowledge of the basic administrative processes behind the generation of these registers. We caution others interested in applying our approach to administrative registers that involvement of a party intimately familiar with these processes is crucial.
A third limitation of our approach is that we were unable to obtain interpretable results using larger
Fourth, classification performance by the graphical model, as well as logistic regression, was rather poor in an absolute sense. Classification will always be a challenge for any model due to the class imbalances present in all variables. Because our aim was to interpret the graph, rather than optimize prediction, no specific actions were taken to optimize the model for predictive purposes as is common in machine learning approaches. This means that model performance in the predictive sense could likely be improved. Exceptional model mining [90] might prove useful to identify subgroups with less class imbalance for which group-specific graphical models with atypical features can be estimated. Ultimately, in some cases it may simply be enough if the model can accurately identify cases with an increased risk of specific problems. For example, a municipality could include a question to screen for financial problems while offering certain other social services. This requires very little effort and it can be done unobtrusively, so there is no risk or cost associated with false positives.
Fifth, we did not examine individual differences in graph structure. The households in the sample consist of many different subgroups that are likely to have different needs of social services. For example, households without any children or young adults will not encounter youth care or educational support services; certain services are primarily requested by elderly citizens; and young single males and single parents are among households with the highest risk of problem debts. Group comparison is not a straightforward matter with the graphical model we used, however. For one, the number of observations in each group influences the size of regularisation parameter
Sixth, we did not compare graphs obtained with different parameters or different methods of model selection. Instead we only used the eLasso method with hyper-parameter
In conclusion, household poverty and debt, while complex social problems, can be better understood within a “network” of interrelated variables. We accomplished this by applying Markov random fields to linked administrative data, an approach that we believe can bring fruitful further insights for social policy and intervention. We hope other researchers will find the approach presented here equally useful when applied to other social problems.
Footnotes
Acknowledgments
We thank the municipality of Utrecht for creating the necessary conditions to study their data in compliance with Dutch General Data Protection Regulation.
Supplementary data
The supplementary files are available to download from https://dx-doi-org.web.bisu.edu.cn/10.3233/SJI-230028.