
Abstract
Knowledge representation systems based on the well-founded semantics can offer the degree of scalability required for semantic web applications and make use of expressive semantic features such as Hilog, frame-based reasoning, and defeasibility theories. Such features can be compiled into Prolog tabling engines that have good support for indexing and memory management. However, due both to the power of the semantic features and to the declarative style typical of knowledge representation rules, the resources needed for query evaluation can be unpredictable. In such a situation, users need to understand the overall structure of a computation and examine problematic portions of it. This problem, of profiling a computation, differs from debugging and justification which address why a given answer was or wasn’t derived, and so profiling requires different techniques. In this paper we present a trace-based analysis technique called forest logging which has been used to profile large, heavily tabled computations. In forest logging, critical aspects of a tabled computation are logged; afterwards the log is loaded and analyzed. As implemented in XSB, forest logging slows down execution of practical programs by a constant factor that is often small; and logs containing tens or hundreds of millions of facts can be loaded and analyzed in minutes.
Introduction
Much of the literature on knowledge representation and reasoning (KRR) has been concerned with the use of expressive reasoning components such as ASP and
The use of these features can lead to concise representation of knowledge, but also to unpredictability in the time and space a computation requires, even when such a computation terminates. This unpredictability especially emerges when a knowledge base is produced by a team of knowledge engineers working in a loosely coordinated manner to create rules that may depend on one another. In such situations, the question arises whether the size of a resource intensive computation is due to the sophistication of the reasoning it requires; to redundant or unoptimized rules; or to rules that are simply incorrect. The following example illustrates a case that arose during a KRR effort for the Silk project.
Over the course of several months, portions of the Cyc reasoner2
These questions were Advanced Placement exam questions published by the College Board Association (http://apcentral.collegeboard.com/).
Silk and Ergo are implemented using XSB [19], so that their operational semantics ultimately is based on tabled logic programming. In fact, because of the use of frames, defeasibility and Hilog, user predicates in Flora-2 and its extensions are tabled unless they are explicitly declared otherwise – a default that is the exact opposite of tabling in Prolog. To investigate the time and space required for queries like those of Example 1, a knowledge engineer who understood the operational semantics of Silk would use information about the tables to help determine why a computation was costly. For instance, she might want to examine which tabled subgoals were queried most often; how the answers were distributed among the tables; how the queries depended on one another; and how those dependencies affected the overall search. These questions indicate a need to model a tabled evaluation as a structure that can be examined in itself. Accordingly, we denote the problem of exploring large tabled computations as the Profiling Problem. Note that profiling addresses the nature of a computation as a whole in order to determine why a computation may not terminate, or why it is costly if it does terminate. Profiling may thus be used on correctly executing programs, and does not address the question of why given solutions are returned or omitted. For this reason, profiling differs from previously reported approaches based on procedural or declarative debugging or on justification (e.g., [9,16]).
This paper presents forest logging, an approach to the profiling problem based on a trace-based analysis of SLG forests, an operational semantics for tabling. As its name implies, operational aspects of a computation are written to a log that is later loaded and analyzed. Specifically,
We present the design of the logs, and formalize their properties; in particular we show how logs preserve dependency information, and specify the conditions under which the logs can construct a homomorphic image of an SLG forest. We present analysis predicates to display operational information about a tabled computation in an efficient manner, and describe how these routines can be customized in order to represent dependency and other information at different levels of abstraction. We demonstrate by benchmark tests that the overhead of logging is a constant factor. We demonstrate the scalability of log analysis which can load and analyze logs of hundreds of millions of facts.
Section 2 informally reviews SLG and presents the format of forest logs. Some basic properties are shown in Section 3, while Section 4 discusses the analysis routines and describes the implementation of forest logging along with performance results. Related work is covered in Section 6.

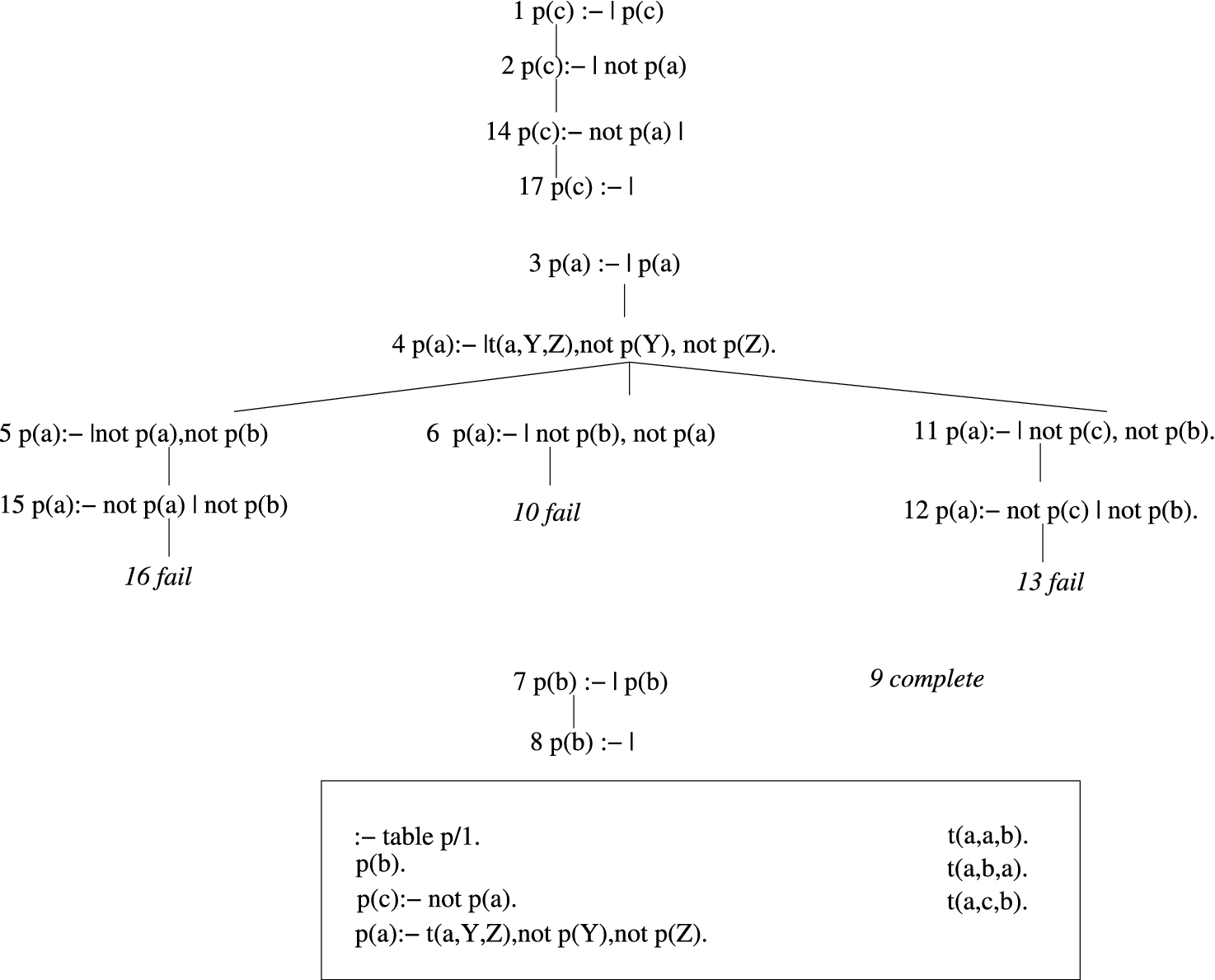
A Definite Program and SLG Forest for Evaluation of the Query reach(1,Y).
All forest logging features discussed in this paper are available in the latest release of XSB (version 3.5). In addition, these features form the basis of the forest logging library in the publically available version of Flora-2 (version 0.99.3), as well as in the commercial Silk and Ergo systems.
SLG resolution (Linear resolution with Selection function for General logic programs) [4] was formulated in [18], to model a tabled evaluation as a sequence of forests of SLG trees. Before discussing the logs themselves, we review those aspects of the forest of trees model for SLG that are necessary to understand forest logging and its applications. As SLG and its extensions have been presented in the literature, our review is largely an informal overview; for full coverage with formal definitions see the references contained in [19]. All code examples are in Prolog syntax.
A review of SLG by examples
For simplicity, we restrict the discussion of SLG to finitely terminating evaluations (which correspond to forests with a finite set of finite trees), and always assume a left-to-right literal selection strategy.
Definite programs
We begin with an example of SLG evaluation of a query to a definite program.
Figure 1 shows a simple program along with an SLG forest for the query reach(1,Y) to the right-recursive tabled predicate reach/2. An SLG forest consists of an SLG tree associated with each tabled subgoal S (where variant subgoals are considered to be identical); each such tree has root
Given an SLG tree
We slightly abuse terminology since it is the predicate symbol of the atom within the literal that is tabled. We further abuse terminology by sometimes using selected literal to refer to the underlying atom on which the literal is based, when it is clear to do so.
The evaluation keeps track of each tabled subgoal S’ that it encounters by creating a tree for S’ via the
This explanation implicitly assumes call variance: that a new tree is created for S’ if there is not already a tree for (a variant of) S’.
When it is determined that a (perhaps singleton) set
As seen from Example 2.1, a tabled evaluation evaluates mutually dependent sets of subgoals, marking them as completed when it is no longer possible to derive answers for these subgoals. In this way, a tabled evaluation can be viewed as a series of fixed point computations for sets of interdependent subgoals. Because of these considerations, much of the operational state of a SLG forest
Let
The Subgoal Dependency Graph of
Since
Understanding the changing dependencies of an evaluation is critical to a number of operational aspects. For instance, a local evaluation restricts operations so that there is always a unique maximal independent SCC. Note that an SCC
Normal programs
Arguably, the main difference between SLG resolution and other tabling methods is the use of
A Normal Program
Figure 2 shows a program with negation,
In situations such as this, where all resolution has been performed for nodes in an SCC, an evaluation may have to apply a
At this stage the SCC {p(a),p(c)} is completely evaluated meaning that there are no more operations applicable for goal literals (as opposed to delay literals). Since p(a) is completely evaluated with no answers, conditional or otherwise, the evaluation determines it to be failed as part of a
There is one additional SLG operation that was not used in either Example 2.1 or 2.2. The
Failure nodes are only created by the
Forest logging allows one to run a tabled query and to produce a log, from which a number of properties of the SLG forest can be inferred. The design of the log attempts to balance several goals: the log should be as informative as possible, but also easy to use and should not overly slow down computations. The log (or trace) consists of Prolog-readable facts (or events) that may be loaded and analyzed, leading to the need to support quick load times and scalable analysis routines.7
For presentation purposes we consider only tabling with call variance, and local evaluation. However the forest logging features described here are also implemented for call subsumption and for other scheduling strategies.
A call to a tabled subgoal. When a literal L is selected in a node N, where N is in the tree for new if cmp if incmp if
If the selected literal L is negative and
The logging of new answers does not correspond to an SLG operation but is useful for analysis.
New Answer. When a new answer
Note that na/3 can be seen as a specialization of na/4 that reduces the memory footprint of the loaded log. A similar specialization is described below for simplification.
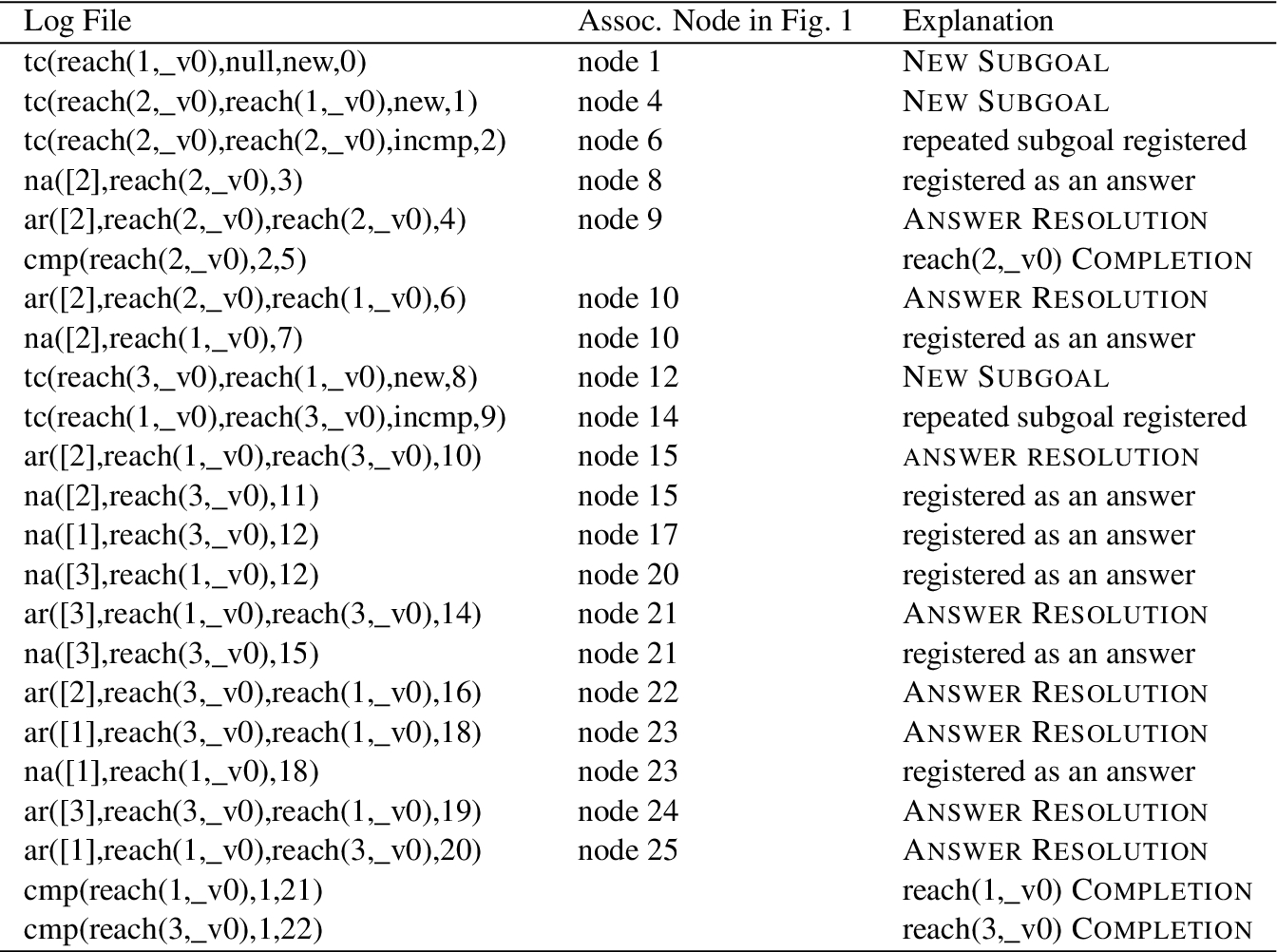
A Log File Corresponding to the SLG Forest in Fig. 1.
If a literal
If a literal
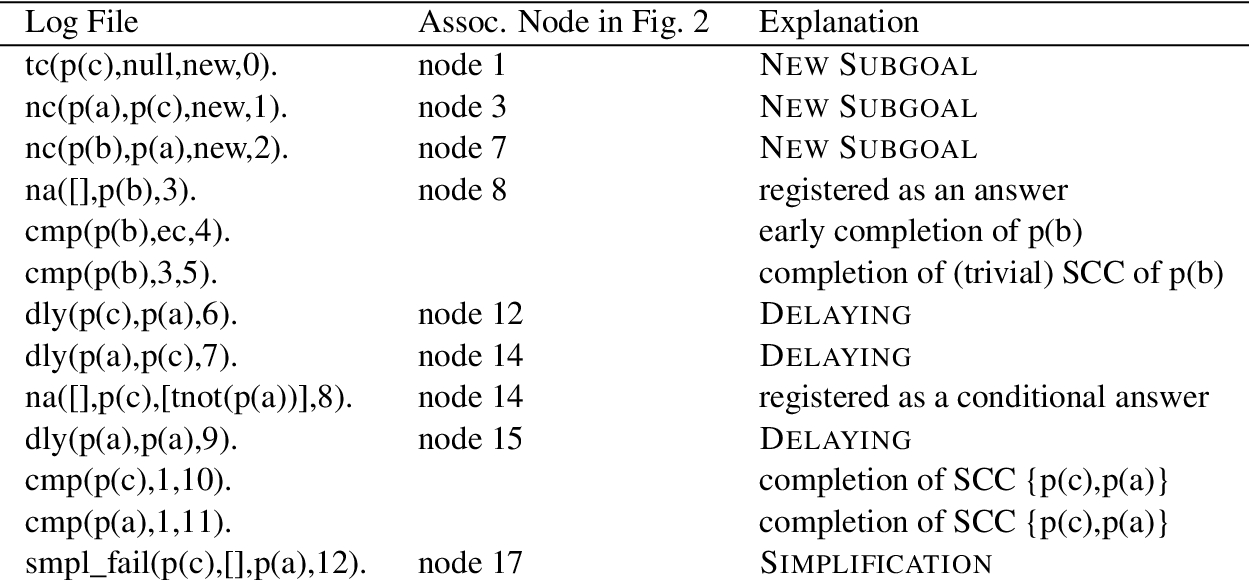
A Log File Corresponding to the SLG Forest in Fig. 2.
The forest for reach(1,Y) in Example 2.1 has the log file as shown in Fig. 3.9
As mentioned above, no fact is logged for an answer A to a subgoal S unless A is newly added for S. For instance, no fact is logged for the creation of the answer reach(1,2) in node 19, since the same atom was added as an answer by node 10 (and logged).
Forest logs capture several important aspects of tabled computations. We begin by showing how they capture the subgoal dependency graph of a given forest (Definition 2.1) a property that is heavily used in Section 4. Next, Section 3.2 clarifies the extent to which a forest log can be used to reproduce an SLG forest, by discussing conditions under which a homomorphic image of an SLG forest can be constructed from a log.
Capturing dependency information
Let A subgoal S is incomplete in V is the underlying set of nodes in E.
Since the log dependency graph is parameterized by a log’s counter, the log can be used to construct the SDG (Definition 2.1) at various stages in the evaluation. This is formalized by Theorem 3.1 which states that the SDG for any forest of an evaluation can be reconstructed from the log dependency graph. This theorem directly underlies the analysis routines of Section 4; and because it holds for any forest, the theorem also underlies analysis of partial computations – e.g., computations that were interrupted because they were suspected to be non-terminating (cf. the discussion of the Terminyzer tool [15] in Section 6).
To be able to reconstruct the SDG of a given forest
Within XSB this is done within the
Let
Proofs are provided in the appendix of this paper.
Because SLG forests capture the operational aspects of tabling, the ability to fully reconstruct a forest would mean that a wide variety of operational properties could be obtained by analyzing a log. However, because forest logs do not keep track of
More precisely, forest logging may lose information about the direct edges between nodes within an SLG tree
Let For any node If the selected literal of n is tabled, then If n is the immediate child of the root of If n is an answer or failure node whose nearest ancestor either has a selected tabled literal or is in Otherwise, If there is an edge between nodes
Let
Note that since the root of any SLG tree has a selected tabled literal, any node whose selected literal is non-tabled has an ancestor that is tabled; because the ancestor relation is a tree, the closest such node is unique, so that

Homomorphic Image of the SLG Forest of Fig. 1.
The homomorphism of Definition 3.2 is partially illustrated by its effect on the forest of Fig. 1 as shown in Fig. 5. It can be seen that for an SLG tree
In order to reconstruct an SLG tree in Let Both The leftmost literals The leftmost tabled literal
Two rules are distinguishable if their bodies are empty or distinguishable.
Let P be a program,
Assuming a fixed maximal size for terms in
Although
While dependency information among subgoals as discussed in Section 3.1 is critical to understanding an evaluation, other aspects are important as well. For example, applications in knowledge representation and business rule development may require analysis of dependencies or of answers that arise from application of a particular rule r for a predicate
Of course the tree edges that represent rules can be explicitly represented by rewriting a program. For instance, each rule
Note that as more predicates are tabled, the number of rules that are distinguishable increases. Thus, Theorem 3.2 implies that forest logging can often support rule level analysis for heavily tabled computations, such as those that occur in Flora-2.12
The current set of forest log analysis routines does not perform rule level analysis and do not explicitly construct homomorphic images.
We now turn to a series of examples illustrating the uses of forest logging as it is implemented in the current version of XSB (version 3.5). Before doing so, we note that XSB’s implementation differs slightly from the description of the previous sections. XSB uses a so-called completed table optimization, where resolving answers from completed tables is nearly identical to resolving program clauses. Because of this, for reasons of efficiency in the current implementation answers returned from completed tables are not logged. In addition, the current version of forest logging does not log ansc/3 facts, (which are rarely needed). However XSB’s implementation of forest logging does record practical events that are not modeled by SLG or its extensions including exceptions thrown during an evaluation, and table abolishes.
Using the log to analyze dependencies
Continuing Example 1.1, we consider execution of a particular biology query that took more space and time than expected. This query took about 30 seconds of CPU time and created about 600,000 tables with about 300,000 answers total. Overall about 8.7 million tabled subgoals were called. The query required about 300 megabytes of table space, while XSB’s combined trail and choice point stack region had allocated over 1 gigabyte of space.13
All times reported in this paper were from a 64-bit machine with 3 Intel dual-core 3.47 GHz CPUs and 188 megabytes of RAM running under Fedora Linux. The default 64-bit, single-threaded SVN repository version of XSB was used for all tests.
After loading the log, the top-level analysis query, forest_log_overview/0, gave the results in Fig. 6 (the execution time for forest_log_overview was 22.1 seconds – cf. Fig. 1).

Output of Forest Log Overview for the Program and Query in Example 1.1.
The forest log overview first shows the total number of completed and non-completed subgoals and SCCs, along with a count of how many of the completed subgoals were early-completed (Section 2.1). Information about non-completed subgoals is useful for analyzing computations that do not terminate. The overview also distinguishes between positive and negative calls to tabled subgoals, and for each such class further distinguishes subgoals that were new, completed, or incomplete. Recall that calls to completed tabled subgoals essentially treat the answers in the table as facts, so that such calls are efficient. Making a call to an incomplete subgoals on the other hand means that the calling and called subgoals are mutually recursive;14
This statement is true not only in local evaluation but also in another common scheduling strategy called batched evaluation.
The overview also provides the distributions of tabled subgoals across SCCs formed by the SDGs of the various forests in the evaluation. While most of the SCCs were small, one was very large with nearly 150,000 mutually dependent subgoals. Clearly the large SCC should be examined. The first step is to obtain the index of its SCC (a unique integer that denotes the SCC). The query get_scc_size(Index,Size), Size > 1000. indicated that the index of the large SCC was 39. The query analyze_an_scc(39) then provided the information in Fig. 7.15
For the purpose of space, the lists of predicates and edges in the SCC have been abbreviated.

Output of SCC Analysis for the Program and Query in Example 1.1.
Within the SCC analysis, information about a given tabled subgoal S is abstracted: only the functor and arity of S is presented. For SCC 39 in the running example, abstraction is necessary, as directly reporting 150,000 subgoals or 4,000,000+ edges would not provide a human with useful information. However, it could be the case that seeing the tabled subgoals themselves would be useful for a smaller SCC. Even for a large SCC, it can be useful for different levels of abstraction to provide mode or type information. For this reason, forest log analysis predicates support calls such as analyze_an_scc(39,abstract_modes(_,_)) which applies the predicate abstract_modes/2 in the breakdowns of subgoals and edges. abstract_modes(In,Out) simply goes through each argument of the term In and unifies the corresponding argument of the term Out with
v if the argument is a variable; g if the argument is ground; and m (for mixed) otherwise.
The resulting output is shown in Fig. 8. Examination of this output indicates that the SCC consists of a large number of fully ground calls to several predicates: rewriting code to make fewer but less instantiated calls to these predicates will often optimize a computation in such cases.

Output of SCC Analysis for the Program and Query in Example 1.1.
Of course, abstract_modes/2 is simply an example: term abstraction predicates are easy to write, and any such predicate may be passed into the last argument of analyze_an_scc/3.16
Due to its use of Hilog, Flora-2 terms are all instances of the generic predicates apply/[1,…,n]. Accordingly, abstraction was used to break out predicate-level information in the output of Section 4.1, while a special version of abstract_modes/2 was used here.
Many programs that use negation are stratified in such a way that they do not require the use of
As indicated previously, the forest log overview includes a total count of As a use case, logging was made of execution of a Flora-2 program that tested out a new defeasibility theory (cf. [20]). The forest log overview indicated that the top-level query was undefined: The analysis predicate three_valued_scc(List) produces a list of all SCC indices in which
A user of XSB may invoke forest logging so that the log is created as described in Section 2. Alternately, a user may invoke partial logging. This option omits facts produced by the
Regardless of the level that is enabled, logging is performed by conditional code in large virtual machine instructions of XSB’s engine, the SLG-WAM, such as
All facts are written canonically17
In Prolog, canonical syntax does not allow operator declarations so that with the exception of list symbols, all function symbols are prefixed and their arguments fully parenthesized. In addition all numbers are written in base 10.
Analysis routines are written in standard Prolog with one exception. Counting the number of (abstracted) edges in an SCC makes use of the code fragment
tc(T1,T2,incmp,_Ctr),
check_variant(cmp(T1,S,_),1),
check_variant(cmp(T2,S,_),1)
Table 1 shows performance results for logging and analysis of various sets of examples:
Cyc Series. Cyc 1 is the working biology example used throughout this paper; Cyc 3 is a similar, but larger, biology example, Both systems are based on the translation of the Cyc inference engine into Flora-2 and then into XSB.
Pref-kb Series. Pref-kb contains a small set of tabled Prolog rules about personal preferences that demonstrate reasoning about existential information in a manner similar to description logics, and make use of default and explicit negation. Queries to these rules were run over sets of 3.7 million and 14.8 million base facts.18
Details of this series, including the code used to generate the datasets, are available at
Reach N Series. This series tests logging of an open query to the right-recursive reach/2 predicate in Fig. 1 over fully connected graphs with 2000–12000 nodes. Since these queries measure reachability from all nodes in the graphs the cost of an open query scales quadratically with respect to the number of nodes in the graph. Although the tabling behavior of a simple transitive closure query such as reach/2 is well understood, this series is included to test the scalability of logging and of its analysis.
Timings for Loading and Analyzing Logs
In part because of XSB’s library predicates for loading canonical dynamic facts, XSB’s load time is efficient for the various types of logs, loading approximately 100,000 facts per second for the Cyc series, over 150,000 facts per second for the Pref-kb series, and nearly 200,000 facts per second for the reach N series. After being loaded, the Cyc examples took about 500 bytes per fact, the Pref-kb examples about 300 bytes per fact, and the reach N facts about 200 bytes per fact. Much of this space is due to the heavy indexing of log facts. The reason that the Cyc logs take the longest to load and the most space to represent is due to the fact that the subgoals and answers for this benchmark were generated by Flora-2 compilation. For instance, the Hilog transformation used by Flora-2 transforms n-ary predicates and function symbols to
Analysis time
Once the log has been loaded, the indexing makes analysis fast enough to be interactive: for the Cyc biology example the top level analysis took around 22 seconds, and analyzing SCC 39 took about 20 seconds when the built-in predicate-arity abstraction was used, and about 60 seconds for the parameterizable version that used abstract_modes/2. Although computing the forest log overview requires several table scans in addition to indexed retrievals, timings for both the Pref-kb and the reach N series show a sublinear growth of analysis time with respect to log size.
Logging overhead
The overhead of query evaluation was also measured, i.e., the time it took to execute a query when forest logging was turned on, compared to no logging. At a general level it is easy to see that forest logging imposes an overhead on an evaluation that is a constant factor. Within XSB’s virtual machine, the SLG-WAM, calls to functions that write log facts are placed directly in tabling instructions and never cause any path through an instruction to be re-executed. The cost of logging a given fact is bounded by a factor that is constant for each terminating evaluation
Full details would require a lengthy exposition of low-level details of the implementation of forest logging with XSB’s virtual machine.
Of course, even an overhead that is a constant factor can have practical importance. For the Cyc series, the overhead of logging increased the time for Cyc 1 by 72% and for Cyc 3 by 132% which was considered acceptable by knowledge engineers. Similarly, the Pref-kb series, which uses a heavily tabled Prolog program, has an average logging overhead of about 225%. On the other hand, for the reach N series the overhead of forest logging on query execution was naturally high (about 2 orders of magnitude), as reach N performed very little
The reach N series was included to benchmark scalability, but partial logging as described in the next section can greatly reduce the logging overhead and log space of the reach N series, if needed.
For some large examples, partial logging (mentioned at the beginning of this section) can reduce the logging overhead, the time required to load a log, and the space the loaded log requires. An example of this is as follows.
In analyzing the log for a query to Pref-kb, it became apparent that much of the resources the query required were due to large SCCs composed almost entirely of goals to equals/2, the predicate used for equality of non-identical terms. By examining the program, a rule for equals/2 was translated from a right-recursive form to a left-recursive form. Simplifying somewhat, this meant translating a rule of the form: equals(X,Z):-basePredicate(X,Y),equals(Y,Z) equals(X,Z):-equals(Y,Z),basePredicate(X,Y)
After performing the above translation, the query time for the transformed series, Pref-kb-lr was reduced by 300–400%, and the maximum memory required for query evaluation was reduced by about 700–800%. However, while the translation optimized the query itself, when logging was turned on the left-recursive query slowed down substantially, even compared to the time required by the right-recursive form when using logging.
Inspection of the log for the query to left-recursive Pref-kb showed that a large number of answers were produced for the top-level query and its tabled subqueries. Since partial logging removes most information about answer derivations it can substantially reduce the logging time and log size for queries with a large number of answers. Table 2 shows that partial logging reduces the size of the log for left-recursive Pref-kb by many orders of magnitude. On the other hand, evaluation of the query to right-recursive Pref-kb produces a large number of subgoals and relatively few answers, so that partial logging is not more efficient than full logging in this case.21
Although the left-recursive and the right-recursive forms of Pref-kb are semantically equivalent, the left-recursive form makes fewer queries than the right-recursive form but its queries are not as instantiated. The left-recursive form thus has a larger search space than the right-recursive form, but it creates far fewer queries for its search and for that reason is more efficient under XSB’s tabling implementation.
Comparing Full and Partial Logs for Pref-kb: Times are in Seconds and Space is in Bytes
Trace-based analysis has been widely used to analyze the behavior of concurrent systems, security vulnerabilities, suitability for optimization strategies and other program properties. Within logic programming, it has been used to support debugging of Prolog [5], Mercury [6], and evaluations that make use constraint-based reasoning [7,14]; the trace analyzer for Mercury was extended to support synchronous program monitoring [11]. More recently, a well-known use of trace-based analysis is the Ciao pre-processor, which infers call and success conditions for a variety of domains based on execution of queries (see [10] for further details).
Based on XSB’s forest logging, a system for analyzing non-termination of Flora-2, Silk and Ergo programs, called Terminyzer has been developed [15]. In addition to the logging mechanisms described so far, Terminyzer relies on special routines that translate compiled Flora-2 code back from a Prolog syntax to a more readable Flora-2 syntax. Displays for Terminyzer are shown in the IDEs of both Silk and Ergo and have been used for debugging by knowledge engineers [1]. The analysis presented in Section 4 predates the termination analysis of [15], and is complementary to it. For instance, the analyses in Section 4.1 considered a program and query that terminated, but was inefficient due to unexpected dependencies among subgoals; while the negation analysis of Section 4.3 helped indicate why a 2-valued model was not obtained.
Discussion
The design of a forest log attempts to balance the amount of information logged against the time it takes to load and analyze a log. The propositions of Section 3 show that a forest log suffices to analyze dependency information and, under certain conditions, has the information available to construct a homomorphic image of an SLG forest. The analysis predicates of Section 4 show how the representation is used to provide meaningful information to users about tabled programs with and without negation. The benchmarks of Section 5 further demonstrate practicality of this approach and its scalability to logs consisting of hundreds of millions of facts. As a result forest logging is now fully integrated into XSB and Flora-2, and underlies tools in the commercial Silk and Ergo IDEs.
More generally, trace-based analysis provides an alternative to static analysis for a number of program or query properties. Unlike static analysis, trace-based analysis requires realistic data along with a representative set of queries. On the other hand, for programs that include Hilog, defeasibility, equational reasoning and other features of Flora-2, Ergo and Silk, static analysis techniques may not exist, may not be implemented, or may not be powerful enough for practical use. As a result, trace-based analysis is a viable technique to determine properties of large tabled computations.
An interesting direction for future work involves having a separate process (or thread) monitor the forest log as the information is produced (cf. [11]). Depending on the application, a monitor may need to retain only a small portion of the log and so would reduce the sometimes significant load and analysis times for a full log. An even more intriguing extension would be to have the monitor communicate back to the execution engine to adapt tabling definitions to ensure termination or to improve efficiency.
Footnotes
Acknowledgements
This work was partially supported by Project Halo and FCT Project ERRO PTDC/ EIACCO/121823/2010. The author thanks Fabrizio Riguzzi for making available the server on which the timings were run, and is grateful to F. Bry, M. Bruynooghe, E. Jahier and an anonymous reviewer for their comments, which have substantially improved the paper.