
Abstract
During the nineties of the last century, historians and computer scientists created together a research agenda around the life cycle of historical information. It comprised the tasks of creation, design, enrichment, editing, retrieval, analysis and presentation of historical information with help of information technology. They also identified a number of problems and challenges in this field, some of them closely related to semantics and meaning. In this survey paper we study the joint work of historians and computer scientists in the use of Semantic Web methods and technologies in historical research. We analyse to what extent these contributions help in solving the open problems in the agenda of historians, and we describe open challenges and possible lines of research pushing further a still young, but promising, historical Semantic Web.
Introduction
Historians have a long tradition in using computers for their research [15]. The field of historical research is currently undergoing major changes in its methodology, largely due to the advent and availability of high-quality digital data sources. More recently, the Web has shaken the paradigm of research data publication, particularly since the inception of the Semantic Web [13] and the Linked Data principles [46]. This paper looks forward on how Semantic Web technology has been applied to historical data, and how these technologies can facilitate, boost and improve research by historians. This survey revisits the open problems in historical data and historical research, and analyses current contributions, namely papers, projects, online resources and tools, that apply semantic technologies to solve such problems. We study how successful these solutions have been and propose some challenges for the future.
Historical research is an interesting domain for the Semantic Web. Historical data are extremely context dependent, and always open to a variety of possible interpretations. Availability on the Web of historical research data, which concerns the study and understanding of our past, is growing. The Semantic Web is an evolution of the existing Web (based on the paradigm of the document) into a Semantic Web (based on the paradigm of structured data and meaning). It is not a separate Web but an extension of the current one, in which information is given well-defined meaning, better enabling computers and people to work in cooperation. This survey studies the crossroads of the Semantic Web and history as research domains.
We consider surveying the state of the art in Semantic Web and history a fundamental task for both fields. First, it is necessary as a knowledge organisation task, in order to articulate research and discern contributions. Second, it fosters development of semantic technology and history, both individually and as a unique field, and helps on building research agendas. Other attempts on gathering research efforts on Semantic Web and history exist, but most of them study specific history subfields [25,94,97] or analyse concrete task-oriented tools [33,39] and methodologies [46,53,54]. Moreover, none of them consist in surveys or literature reviews. To the best of our knowledge, this is the first survey reviewing contributions on history and the Semantic Web as generic fields of research.
The elaboration of the study in this paper is not free of obstacles. The first of them is the large amount of research contributions to survey, which had to be filtered to fit strictly the Semantic Web goals and the historical research goals in order to be feasible. By historical research we mean strictly research performed by historians, and talk about history as a research domain. Thus, we exclude other fields of the humanities in which historical research is also performed, such as art history or history of literature. Nevertheless, in the end the number of contributions amount to more than a hundred. Secondly, and even though the corpus of available literature is large, we also encountered difficulties on accessing some of the sources. To solve this, we combined the contributions with the knowledge of domain experts, conducting eight interviews with pioneers in this area. Third, structuring and articulating all this work is an arduous task that requires a lot of schemas, tables and discussions. Finally, the clash of the vocabularies used by two different research communities, usually pointing at similar issues, is problematic. To bridge different jargon we devote some space to cover existing classifications of historical data, especially discussing terms like structure, and we map historical data problems in terms of Semantic Web solutions.
The paper delivers four contributions. First, it describes a classification of historical data depending on several factors, merging existing distinctions by historians with structural approaches from computer science. Second, it articulates the research conducted in the emerging field of historical Semantic Web in terms of several tasks, and depicts the current landscape on advances in representing historical data with semantic technology. Third, we map the open problems of historical data with the solutions provided by the surveyed research. Finally, we show some open challenges for the future, considering first the not (or only partially) solved problems, and secondly Semantic Web facilities still to be explored in historical research.
While we concentrate on historical research, similar solutions emerge also in other humanities fields at the turn to e-humanities or Digital Humanities [14,92]. As historical research overlaps with literary studies, ancient language studies, archaeology, art history and other humanities fields, these areas of encounter are also predestined candidates for the travel of generic methods developed from a semantic technology perspective for historical research to other humanities fields [68].
The survey is organized as follows. In Section 2 we introduce some background on historical research and the Semantic Web. In Section 3 we study the ecosystem of historical data. We describe the life cycle of historical information, propose a classification for historical sources, and show open problems of historical data. In Section 4 we articulate contributions that apply semantic technologies to historical research. In Section 5 we answer the question on how the contributions presented in Section 4 solve the open problems we describe in Section 3. In Section 6 we show the challenges that are still left to solve. Finally, in Section 7 we discuss our findings and establish some conclusions.
Background
Historical research
The field of historical research concerns the study and the understanding of the past. The field is currently undergoing major changes in its methodology, largely due to the advent of computers and the Web [15].
Computer science has inspired historians from the start. History and computing or Humanities computing were labels used before the inception of the Web [67]. Many pioneers in computer aided historical analysis have a background both in history and in informatics, and reflected early on about the usefulness of computational and digital techniques for historical research [15]. Ever since the advent of computing, historians have been using it in their research or teachings in one way or the other. The first revolution in the 1960s allowed researchers to harness the potential of computational techniques in order to analyze more data than had ever been possible before, enabling verification and comparisons of their research data but also giving more precision to their findings [3]. However this was a marginal group within the historical research: in general, the usage of computers by humanists could be described as occasional [35]. The emphasis was more on providing historians with the tools to do what they have always done, but now in a more effective and efficient way. Concretely,
databases and document management systems facilitated the transition from historical documents to historical knowledge through text analysis;
statistical methods were used predominantly for testing hypotheses, although with time were more valued as a descriptive or exploratory tool than as an inductive method;
image management aided historians to digitize, enrich, retrieve images and visualize data [15].
Although computing tools are currently embedded in the daily life of most researchers, the use of these tools did not revolutionized all sciences equally. Accordingly, history failed to acknowledge many of the tools computing had come up with [15]. Instead of improving the quality of the work of historians and assisting them in their processes, software developed for historians often requires attending several summer schools [16]. Currently there are still many challenges and information problems in historical research. These difficulties mainly range from textual, linkage, structuring, interpretation, to visualization problems [15].
Despite these challenges, computing in history and in the broader sense the humanities, also brought some significant contributions in certain fields like linguistics (corpus annotations, text mining, historical thesauri etc.), archaeology (impossible without geographic information systems (GIS) nowadays), and other fields using sources that have been digitized for historical (comparative) research and converted to databases [15]. The use of electronic tools and media is incredibly valuable and important for opening up various sources for research which would otherwise remain unused. Open access to research data has always been an issue, especially in the humanities. However, over the past years various efforts have been made in opening up these black boxes and making them available for researchers. These different sources contain rich information from various fields, which are often digital in nature in the form of databases, text corpora or images. These sources, in practice isolated databases, often contain a lot of semantics, but their data models were asynchronously designed, making them difficult to compare. So, while more and more sources are being digitized, more attention has to be given to the development of computational methods to process and analyze all these different types of information [45].
A key issue for historians and other humanities researchers when dealing with historical data for comparative research concerns the lack of consistency and comparability across time and space, due to changing meanings, various interpretations of the same historical situations or processes, changing classifications, etc.
Though not all research dreams materialized in the way initially envisioned [60], the inception of the Web allowed historians to aim for world-wide, large scale collaborations, especially in the area of economic and social history. This kind of web based cooperation allows to collect, distribute, annotate and analyze historical information all around the globe [30].
Changes in historical research are closely connected to the emergence of new scientific methods, and this co-evolution holds for decades and centuries. Statistics has influenced many fields including history, and paved the ground for quantitative studies [61]. However, these kind of historical studies became more and more the domain of sociologists, economists and demographers than scientists educated as historians [89]. Late important changes are consequences of recent technological trends connected to the emergence of the Web [76] and the inception of Semantic Web technologies [4].
The Semantic Web
The advent of the Semantic Web poses new perspectives, challenges and research opportunities for historical research. Envisioned in 2001 by Berners-Lee, Hendler and Lassila [13], the Semantic Web was conceived as an evolution of the existing Web (based on the paradigm of the document) into a Semantic Web (based on the paradigm of structured data and meaning). By that time, most of the contents of the Web were designed for humans to read, but not for computer programs to process meaningfully. Although computer programs could parse the source code of Web pages to extract layout information and text, computers had no mechanism to process the semantics. In other words, the Semantic Web is not a separate Web but an extension of the current one, in which information is given well-defined meaning, better enabling computers and people to work in cooperation [13].
More practically, the Semantic Web can be defined as the collaborative movement and the set of standards that pursue the realization of this vision. The World Wide Web Consortium [12] (W3C) is the leading international standards body, and the Resource Description Framework [121] (RDF) is the basic layer in which the Semantic Web is built on. RDF is a set of W3C specifications designed as a metadata data model. It is used as a conceptual description method: entities of the world are represented with nodes (e.g. Dante Alighieri or The Divine Comedy), while the relationships between these nodes are represented through edges that connect them (e.g. Dante Alighieri wrote The Divine Comedy). These statements about nodes and edges are expressed as triples. A triple consists of a subject, a predicate, and an object, and describes a fact in a very similar way as natural language sentences do (e.g. subject: Dante Alighieri; predicate: wrote; object: The Divine Comedy). Subjects and predicates must be URIs (Uniform Resource Identifiers, the strings of characters used to identify and name a web resource like a web page), while objects can be either URIs or literals (like integer numbers or strings) [46]. RDF can be considered a knowledge representation paradigm where facts and the vocabularies used to describe them have the form of a graph. This setting makes RDF very suitable for data publishing and querying on the Web, especially when (a) the dataset does not follow a static schema; and (b) there is an interest of linking the dataset to other datasets.
Efforts on standardization have produced ontologies and vocabularies to describe multiple domains. An ontology is an explicit specification of a conceptualization [43] and contains the classes, properties and individuals that characterize a given domain, such as history. In the Semantic Web, the design of ontologies is done using the Web Ontology Language [124] (OWL). OWL consists of several language variants built upon different modalities of Description Logics [8] (DL), a family of formal knowledge representation languages. Such languages allow reasoning, that is, to extract or deduce consequences and new knowledge from the original.
A large number of RDF datasets have been published and interlinked on the Web, using these ontologies and vocabularies and following the Linked Data principles [11]. In the middle of the document-Web and the data-Web, formats and vocabularies for rich structured document markup (such as RDFa [122] or schema.org [91]) are enabling software agents to crawl semantics from web pages, bridging the gap between the Web for humans and the Web for machines. These efforts have evolved the Web into a global data space [46] where data can be queried e.g. using the SPARQL query language (SPARQL Protocol and RDF Query Language) [120]. Although the transition from the document-Web to the database-Web exists in the form of these standards and technologies, the simple idea of the Semantic Web remains largely unrealized [98].
Historical data
Since the introduction of computers in the field, historical research has produced high-quality digital resources [15]. Historical datasets encompass texts, images, statistical tables and objects that contain information about events, people and processes throughout history. Converted or born-digital, historical datasets are now analyzed at big scale and published on the Web. Their temporal perspective makes them valuable resources and interesting objects of study.
In this section we describe the ecosystem where historical information lives. First we introduce the life cycle of historical information, which is the framework we use to study how historical data is created, enriched, edited, retrieved, analysed, and presented. Then we propose a classification of historical data depending on several factors. Finally, we revisit the traditional open problems of historical data. Some of these problems have found solutions in current Semantic Web developments we present in Section 4.
The life cycle
The main object of study in historical research is historical information, and the multiple ways to create, design, enrich, edit, retrieve, analyse and present historical information with help of information technology. It is important to distinguish historical information from raw data in historical sources. These data are selected, edited, described, reorganized and published in some form, before they become part of the historian’s body of scientific knowledge. We use the life cycle of historical information proposed by Boonstra et al. [15] to study the workflow of historical information in historical research.
Historical objects go through distinct phases in historical research. In each phase, these objects are transformed in order to produce an outcome meeting specific historical requirements. The phases can be laid out as the workflow of a historical information life cycle (see Fig. 1). The phases, although sequentially presented, do not always have to be passed through in rigorous order; some can be skipped if necessary. The phases are also quite comparable with the practice in other fields of science.

The life cycle of historical information (Boonstra et al. [15]). The phases in the life cycle are: (1) creation; (2) enrichment; (3) editing; (4) retrieval; (5) analysis; and (6) presentation.
The life cycle of historical information consists of six phases:
In the middle of the historical information life cycle, three aspects are identified which are central to history and computing, but also in the humanities in general:
Durability ensures the long term deployment of the produced historical information.
Usability refers to the ease of efficiency, effectiveness and user satisfaction.
Modeling denotes to more general modeling of research processes and historical information systems.
The continuous usage of computing in different areas of historical research has produced digital historical data with different formats, perspectives and goals. To be used in the Semantic Web, these historical data have to be represented semantically, using the current standards (see Section 2.2). In this section we propose a classification of historical data in order to bridge the gap between the data representation tradition in historical research, and the standard modelling paradigms of the Semantic Web [4,46].
Primary and secondary sources
Historical sources can be characterized and divided in many ways. A basic distinction used by historians is between primary and secondary sources.
Primary sources are original materials created at the time under study [10]. They present information in its original form, neither interpreted, condensed nor evaluated by other writers, and describe original thinking and data [56]. Examples of primary sources are scientific journal articles reporting experimental research results, persons with direct knowledge of a situation, government documents, legal documents (e.g. the Constitution of Canada), original manuscripts, diaries (e.g. the Diary of Anne Frank) and creative work. Primary sources can be distinguished into administrative sources and narrative sources, like biographies or chronicles. Administrative sources contain records of some administration (census, birth, marriage and death rolls, administrative accounts of taxes and expenses, resolutions minutes of administrative bodies, deeds, contracts, etc.). Typically, historians want to extract the facts in order to gather statistical data. Narrative sources are full text documents containing a description of the past, made by an author being an eyewitness: think of diaries, chronicles, newspaper articles, diplomatic reports, political pamphlets, etc. Historians may be interested in both, factual information and the author’s vision and the bias.
Secondary sources are materials that have been written by historians or their predecessors about the past [128]. They describe, interpret, analyze and evaluate the primary sources. Usually, secondary sources gather modified, selected, or rearranged information of primary sources for a specific purpose or audience [56]. Examples of secondary sources are bibliographies, encyclopedias, review articles and literature reviews, or works of criticism and interpretation.
Since historical data have not been produced under the controlled conditions of an experiment, historical research always has something of the work of a detective, and certain details (read: annoying inconsistencies) cannot be destroyed or manipulated. These details may contain relevant information. On the other hand, to be able to extract statistical information and come up with more general statements, some formalization, relating information and harmonizing expressions of what is later used as variables is needed. Harmonization, the process of making data-sources uniformly accessible without altering its original form, is closely related to issues of standardization and formalization [69].
Intended further processing
Some historians [15] propose to structure historical data depending on their required further machine processing. They distinguish between textual data, quantitative data and visual data. Textual data comprises the whole set of unstructured historical sources, such as letters, memoranda or biographies, all in a form of free text. Quantitative data can be seen as historical sources aiming at a quantitative analysis, like church registers, census tables and municipality micro-data. Finally, visual data gathers all kinds of historical evidence not encoded by text or numbers, such as photographs, video footage and sound records.
Source oriented vs. goal oriented
Researchers make the distinction between source oriented and goal oriented historical data [15]. When dealing with historical data it is important to decide in an early stage whether the data should be modeled according to a source or goal oriented approach. The source oriented approach aims to postpone enforcing any standards or classifications, resemble the underlying source data as close as possible (schema free representation) and hence allow room for multiple interpretations of the data. Another approach is the goal or model oriented approach. Historical data is often plagued with inconsistencies, changing structures and classifications, redundant or erroneous data and so forth. The goal oriented perspective therefore advocates the use of more sound data models to start with. This means restructuring the data according to certain views or goals which are mainly dependent on expert knowledge. Accordingly, this perspective commits to a certain data model in an early stage.
Level of structure
At the end of the creation phase (see Section 3.1) one may expect to have a historical dataset suitable for further processes. However, the nature of the steps to be taken thereafter may strongly depend on the way the resulting dataset is structured. Indeed, attaching Semantic Web technologies to these historical sources (e.g. to extract RDF triples from them, or enrich them semantically) is strongly dependent on their level of structure. We propose the historical data classification shown in Fig. 2. We distinguish three levels of inner structure in historical datasets: structured, semi-structured and unstructured. Each level of structure can be divided into several types of structure.
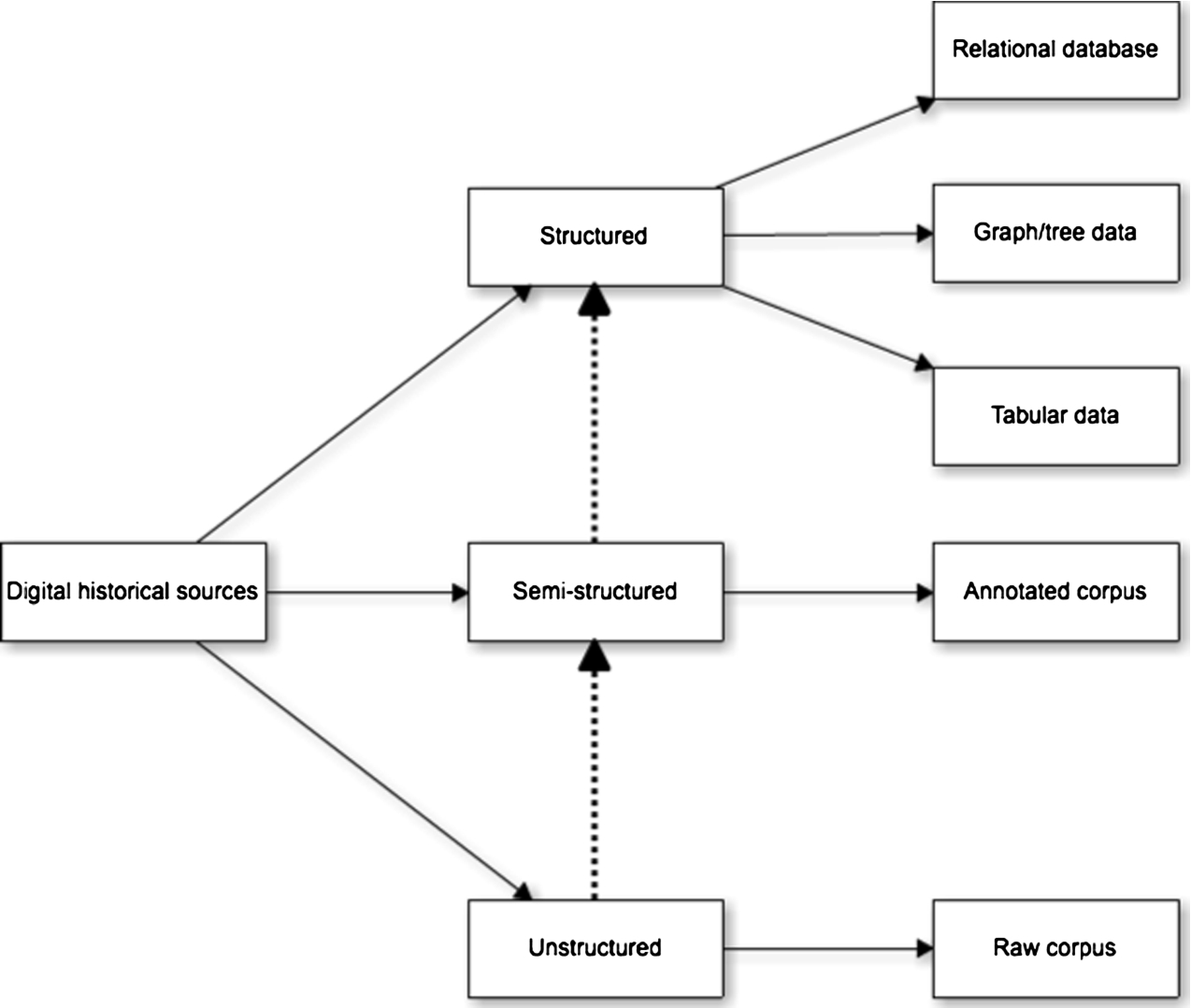
Classification of historical data according to their level of structure. Dotted arrows indicate the direction of usual transformations in workflows that identify historical entities (and their relations), from unstructured to structured representations.
Relational databases. Relational databases have their own languages (SQL) and systems (MySQL, Microsoft SQL Server, PostgreSQL, Microsoft Access, Oracle, etc.) to represent and store historical data. They all follow the relational model [26]. Some issues, especially when trying to integrate data from different databases and modelled with different conceptual schemas, appear often in historical datasets encoded this way.
Graph/tree representations. Relying on graph theory, graph databases offer mechanisms for storage and retrieval of data with less constrained consistency models than traditional relational databases. They provide variable performance and scalability, but high flexibility and complexity support. AllegroGraph, IBM DB2, OpenLink Virtuoso and OWLIM are typical examples. To exchange historical data in graph form, RDF (see Section 2.2) is used. Graph/tree data is found in historical samples that come in formats such as XML (trees), RDF (graphs) or JSON (JavaScript Object Notation). Although they are conceived for modeling data in very disparate models (a tree, a graph and nested dictionaries, respectively) and purposes (e.g. JSON is mainly used for data interchange between web applications and services), these formats also follow some assumptions to put structure on historical data.
Tabular representations. Some historical datasets are encoded in tabular form. Tables consist of an ordered set of rows and columns, the latter typically identified with a name. The intersection of a row and a column is a cell. Depending on the specific encoding (Comma-separated values (CSV), Microsoft Excel spreadsheets, etc.) tables can offer variable features. Tables are used to store all kinds of historical data, especially meso, macro and microdata about individuals, registries, or historical population censuses.
The use of the terms structured and unstructured in computer science to describe datasets is very different from the use of those notions in history, where administrative sources are often labeled as structured and the textual secondary sources as unstructured. Also narrative sources have internal structures, which can be made explicit. From the 19th century onwards historians have made scholarly source editions, which contain structured and annotated information. Nowadays the printed source editions are replaced and supplemented by databases and XML-based digital editions. So, structured or unstructured are relative notions: administrative sources usually have an obvious structured layout, while narrative sources have a latent, at first sight hidden structure, which is made explicit as soon as they appear in a scholarly source edition. So, both administrative and narrative sources can appear in the form of structured or unstructured data in computer science jargon.
Although structure really matters for deciding what specific computing technique or semantic model has to be applied to the sources, being those sources administrative or narrative, deliberate or inadvertent, does not really matter if their inner structure is clearly identified. Their belonging to one type of another may have an influence at some point, but in general the procedure to extract RDF triples from the sources strongly relies on the type of source we have regarding their structure. The goal is a faithful representation of the source in Semantic Web formats: a source-close representation allowing to model data as-is, meeting the same requirements of faithfulness than critical source editions (which is the standard for historians). It is critical for semantic representations to consider context and source structure as critical editions do, because they may be relevant for interpretation of the data. A digitized, semantically-enabled historical source should ideally preserve context and structure and support goal-oriented extraction of data, in order to construct historical facts in the framework of a certain research. By means of dataset interlinking and appropriate design and usage of ontologies and vocabularies, context and source structure should be able to be preserved using semantic technologies. To this end, ontologies can be contextualized to conciliate a party’s subjective view of a domain [17].
Open problems
The classification proposed in Section 3.2.4 is not strict and admits hybrid examples. For instance, annotated digital text sources can be provided both as XML files or stored in a relational database (e.g. for statistical analysis). Some authors classify sources that combine primary and secondary sources like these as tertiary sources [129].
Although many advances have been made in different fields and computers are seen as valuable assets, a high percentage of historians are unfamiliar with or remain unconvinced that semantic technologies may become a new methodological asset [3,106]. The reason is that the weapon of choice of historians was and remains mostly the database, particularly in relational form [3]. This not only enabled historians to retain some of the integrity of the original data sources, but also paved way for rapid advances on issues such as classifications and record linkage. Therefore, historians typically do research using their own datasets, resulting in the creation of a vast amount of scattered data and specific technological challenges. In this section we revisit the traditional open problems of historical research derived from this tradition. In Section 5, after presenting the state of the art in the application of semantic technologies to historical research in Section 4, we point to the specific open problems described here that are eventually solved with such technologies.
Historical data problems can be divided into four main categories: information problems of historical sources, information problems of relationship between sources, information problems in historical analysis, and information problems of the presentation of sources [15].
Historical sources
The first set of open problems in historical research happens in phase 1 of the historical data life cycle (see Section 3.1). This is when the historical data are created.
Manually encoded or OCR-scanned, the creation of the dataset reveals the first barriers. Some characters, words or entire phrases in the original material may be lost or impossible to read or recognise by the human or the computer. Moreover, different techniques may extract historical entities differently. An example would be: what is the word that is written on this thirteenth-century manuscript?
The next question usually is: what does it mean? Background knowledge is provided by libraries in the offline world. But the computer aiding tools also need to have means to help the historian, using the Web as channel and semantics as meaning.
Related to background knowledge is the provenance of the data. Even if the source is clearly identified and its meaning deciphered, the historian needs to know more. To which issue does it relate? Why was it put there? Why was the text written? Who was the author? Who was supposed to read the manuscript? Why has it survived?
Another main issue relates to the structuring problem of historical data [131]. How can historical objects be encoded in a database? Researchers have to decide on what is an adequate data model for their datasets. As historians often have no clear research question when starting an investigation, it is neither possible nor desirable to model the data according to certain requirements in advance. Moreover, different sources have been produced throughout different periods in history with different views and motives. Historical census data is a good example, having varying structures and changing levels of detail which hinders comparative social history research both in past and present efforts [131].
The main discussion regarding this involves whether to use a source or a goal oriented data model for historical data (see Section 3.2.3). Researchers in favor of the source oriented approach claim that a commitment to a certain data model suitable for analysis should be postponed to the final stages of a project, in order to maintain flexibility and build on the data in a non destructive manner. This is especially the case when the database is supposed to be shared with other researchers or used in the future [65].
Relationships between sources
As historical researchers deal with various isolated sources, they face the problem of how to integrate these dissimilar sources for their purposes. This typically happens in phase 2 (enrichment) of the life cycle of historical information (see Section 3.1). An example would be: is this Lars Erikson, from this register, the same man as the Lars Eriksson from this other register?
Quite often several sources are used in historical research, which makes
linking different sources another key problem. Micro data of the same person
contained in different censuses, parish registers, marriage or death
certificates are a good example. Obvious linkage problems are how to
disambiguate between persons with the same name, how to manage changing
names (e.g. in case of marriage of a woman) and how to standardize spelling
variations in the names. In databases, several issues affect data
comparability. Schema mismatch occurs when two different
databases cannot be compared because of semantic differences in the concepts
of their defining schemas. For instance, two XML files conformant to
different DTD schemas may define and structure differently the same
historical entity. Additionally, value mismatch occurs when
the allowed values for columns or variables in two databases are different.
It may also happen across datasets despite being schema or
vocabulary-compatible. For instance, an attribute may encode the variable
social class with categories
Other problems relate to how to link historical data with their spatial and temporal context. For example, some historical facts may need to be linked with occupational titles that evolve over time [48] or with countries with changing geographical boundaries (compare for example the contemporary geographic position of countries in Europe with the situation in 1930 and in 1900; or the fact that the city of Rotterdam suffered nine major changes in its composition between 1886 and 1941 [133]). As historical research often deals with changes in time and space, historians require tools which enable them to deal with these aspects. Accordingly several techniques have been developed for historical research, but the applicability of these has yet to be determined [15].
Historical analysis
Historical analysis is a fundamental part of the life cycle (see phase 5 in Section 3.1). It usually implies data transformations that aid historians in guiding their research. It also builds the bridge between their hypotheses and historical evidence.
The first issue in analysis is the massive treatment of historical data processed in previous stages to satisfy historical requirements, or to support a specific historical interpretation. An example would be: from this huge amount of digital records, is it possible to discern patterns that add to our knowledge of history? Various statistical techniques are borrowed from the social sciences to this end, like multilevel regression, and other techniques have been specifically developed for historical research, such as event history analysis. However, addressing historical data analysis in a broad sense remains essentially unsolved.
In historical research the meaning of data cannot exist without interpretations [15]. Due to drifting concepts in history, different interpretations could exist with regards to certain data [137]. However as interpretation of data is a subjective matter, this information should be added in a non destructive way, preserving the original source data.
Presentation
Presentation is the final phase of the historical information life cycle (see Section 3.1). Its goal is to use visualizations to aid the study and comprehension of historical data. An example problem of such phase would be: how do you put time-varying historical information on a historical map?
Presentation of historical data must be adequate. Different types of presentations are suitable at different stages of a research project. Presentation may take different shapes, varying from digitized documents, poorly and well modelled databases, or visualizations and representations on Geographic Information Systems (GIS). Currently there is a great need for tools and methods to present changes over time and space.
Findings
In this section we review the current state of the art in the application of semantic technologies to historical research, describing relevant contributions towards a historical Semantic Web.
Reviewed papers. The ✓ and ∘ signs
indicate a strong and a medium relationship, respectively, between the
contributions (rows) and the tasks
(columns)
Reviewed papers. The ✓ and ∘ signs indicate a strong and a medium relationship, respectively, between the contributions (rows) and the tasks (columns)
Reviewed projects. The ✓ and ∘ signs indicate a strong and a medium relationship, respectively, between the contributions (rows) and the tasks (columns)
Online resources. The ✓ and ∘ signs indicate a strong and a medium relationship, respectively, between the contributions (rows) and the tasks (columns)
Tools, ontologies, and lexical resources. The ✓ and ∘ signs indicate a strong and a medium relationship, respectively, between the contributions (rows) and the tasks (columns)
Under this category we study research that has been conducted to model historical knowledge or historical facts using standard Semantic Web representations (see Section 2.2). We group contributions to a semantically enabled historical web by the following emphasis of research: historical ontologies, and linking historical data.
Historical ontologies
Data models are necessary for giving structure to any historical data, since they are the abstract models that document and organise data properly for communication. Ontologies encode such models in the Semantic Web [13] (see Section 2.2), and attention has been given to the need of historical ontologies [54]. In historical research, ontologies are the providers of metadata and background knowledge in phases 2 (enrichment) and 3 (editing) of the historical information life cycle (see Section 3.1). Semantic Wikis [86,96] are a great resource for historians to collaboratively build such ontologies.
We find a first category of such models in the form of (typically XML-encoded) taxonomies for historical research. A taxonomy is a collection of controlled vocabulary terms organized into a hierarchical structure, in general with less expressivity than an ontology. The first important example of such knowledge organization is the CLIO system, a databank oriented system for historians [113] appeared in 1980. CLIO included a tag/content representation for historical data that could be structured in complex hierarchies, supporting the recoding of material with doubtful semantics. CLIO remained as the system for organizing historical knowledge until the inception of the Web.
More recently, the Semantic Web for Family History [118] exposes a set of genealogy markup languages based on XML to semantically tag genealogical information on sources containing that kind of historical data. In the context of the Text Encoding Initiative [111] (TEI) there is an important discussion about building the bridge between XML (taxonomies) and OWL (ontologies) in historical data. SIG: Ontologies [101] contains a full log on contributions on how to use ontologies with TEI formats; namely, how TEI-XML encoded documents can refer to historical concepts and properties that have been previously formalized in an external OWL ontology.
The Historical Event Markup and Linking Project [47,88] (HEML) was probably the first project with the goal of creating a Semantic Web of history. Started in 2001, it explored the use of W3C markup technologies to encode and visualize historical events on the Web. Although in the beginning XML was the selected language to provide tagging and markup for describing historical events, the project later experimented with RDF to model and visualize them [87]. This transition was also happening in the whole historical ontologies community, as researchers better understood RDF and its differences with XML.
The modelling and representation of events, often defined as persons doing an activity in a certain place and time, has received a lot of attention in the development of historical ontologies, and most practical results show that the concept of the event is at the core of historical knowledge modelling. Van Hage et al. [134] design the Simple Event Model [95] (SEM), intended to model events in the domains of history, cultural heritage, multimedia and geography. Similarly, the Event Ontology [116], inspired in the musical domain, models the representation of events as combinations of persons, places, moments in time, and factors. Finally, LODE: An ontology for Linking Open Descriptions of Events [64] is especially intended for the publication of historical events as Linked Data. Interestingly, these ontologies have a great overlap in their conceptual modelling of events even coming from different domains. On the other hand, some studies point out specific modelling needs for different historical domains, stressing that historical ontologies should reflect how a particular time frame influences the definitions of concepts [54].
Another big focus in historical ontologies is given to geographical modelling. Owens et al. [83] describe a geographically-integrated history, and stress the importance of dynamics and semantics in Geographic Information Systems (GIS). They set an agenda for historical GIS systems that includes important semantic modelling tasks involving ontologies and geography for historical analysis. Moot et al. [74] depict the interesting crossroad between text analysis, historical semantics and geography in a work that structures geographical knowledge from a historical corpus of itineraries. Vocabularies for historical place names are under discussion [85]. Although not intended for historical research, the GeoNames ontology [117] is the reference for geographical modelling in the Semantic Web.
Since entities like places, persons or events change their over history and time, there is work raising the importance of a change-aware modelling in ontologies [36,68,70]. In historical research and the Semantic Web this is especially true for geographical names, places and regions [52], but also for demographical, social and economical indicators, such as occupations [48].
Linking historical data
By understanding the use and advantages of semantic technologies, practitioners and researchers of historical data can not only connect their own data sources but moreover, also disseminate their data into the Semantic Web and integrate it with other data sources which were previously not possible or cumbersome. The approaches reviewed in this section match the historical data problem of the relationships between sources (see Section 3.3.2). In most cases, the use of semantic technologies solves it.
If one side of knowledge modelling stresses the importance of ontologies and formalization of the semantics of historical domains, the other side pursues the usage of such ontologies to interlink related historical data on the Web. Some researchers in history have centered their interest in how semantics can help relating and linking historical sources and entities: historical, semantic networks are a computer-based method for working with historical data. Objects (e.g., people, places, events) can be entered into a database and connected to each other relationally. Both qualitative and quantitative research could profit from such an approach [58]. Linking historical datasets appropriately is an old and very well known problem in historical research [15]. The landscape on current projects linking historical data (typically extracted from unstructured sources) shows a tendency on publishing more and more historical Linked Data in RDF.
There is a wide variety of project types looking for that structure, though not doing so solely (or explicitly) in RDF. For instance, the Circulation of Knowledge and Learned Practices in the 17th-century Dutch Republic [24] (CKCC project) studies the epistolary network for circulation of knowledge in Europe in the 17th century, extracting all entities and links from the correspondence of scientific scholars of that time. The LINKing System for historical family reconstruction (LINKS) project [63] reconstructs the links between individuals of historical families across several registries. The CCed [20] project follows a similar approach with clerical careers from the Church of England Database. While these projects mine the historical sources for important historical personalities and their relationships, other approaches, such the SAILS [90] project, dive into more concrete historical events and links various World War I naval registries together. The common goal in these initiatives is to produce a semantic network of historical data containing objects like people, places and events connected to each other, which clearly matches the intended purpose of historical ontologies (see Section 4.1.1), but also the general mission of the Semantic Web [13] and Linked Data [46].
Many other projects expose their domain specific historical datasets using RDF. These datasets facilitate their linkage to others using existing ontologies (see Section 4.1.1), achieving shared goals with the old task of historical record linkage. For instance, the Agora project [1] aims at formally describing museum collections and linking their objects with historical context using the SEM [95] (Simple Event Model). Historical events are found elsewhere in historical data. The FDR Pearl Harbor project links events, persons, dates, and correspondence found on government letters and memoranda on the surroundings of the Pearl Harbor attack on 1941 between the US and Japanese governments. All these entities are represented in RDF to model a graph of historical knowledge about that particular event. From a more socio-historical point of view, the Verrijkt Koninkrijk [25] project links RDF concepts found on a structured version of De Jong’s studies on pillarization of the Dutch society after the World War II. More focused on media, the Poli Media project [84] mines the minutes of the general state debates to link historical entities to the archives of historical newspapers, radio bulletins and television programs. The goal is to create a unified historical search environment, facilitating a cross-media analysis [59].
Some general purpose tools facilitate the creation of historical Linked Data. The Fawcett toolkit [33] and the Armadillo project [5] are good examples. The latter exports RDF from any unstructured historical source, producing an RDF graph of historical knowledge that encodes the historical entities and their relationships expressed in that source. Other tools like Open Refine [82] or TabLinker [108] are tailored to produce such Linked Data from structured sources like tables (see Section 3.2).
Text processing and mining
In text processing and mining we revise work that deals with processing unstructured text. Textual resources play an important role in history research. We especially survey work on automatically extracting historical entities (such events or persons) via Natural Language Processing (NLP) techniques. The purpose of NLP is to enable computers to derive meaning from human, natural, or unstructured language input (see Section 3.2).
Structuring historical information from textual resources for further analysis is the bottom line of many research projects. The interesting differences come usually from the various source materials these projects mine. The general public-aimed Agora project [1] enriches museum collections with historical knowledge in order to help users place museum objects in their historical contexts. To this end, Agora employs information extraction techniques from statistical natural language processing to extract named entities (actors, locations, times, event names) from textual resources such as Wikipedia and collection catalogues which are used to populate SEM [95] (see Section 4.1.1) instances. From the object descriptions, also relevant historical entities are extracted which can be linked to the events. To formalize this workflow, Segers et al. [94] present a prototype extraction pipeline for extracting events and their properties from text using off-the-shelf natural language processing tools such as named entity recognition and pattern-based approaches. The main problem they encounter is that the notion of events is still ill-defined in NLP research, and as such tools are not yet readily available.
Textual encoding of the media have also been the source to extract historical knowledge in several projects. The Bridge project [18] aims at bringing more cohesion into Dutch television archives by finding relevant links between the official archives maintained at the Netherlands Institute for Sound and Vision and other information sources such as program guides and broadcasting organizations websites. It is thus focused on improving access to television archives for media professionals. In order to do so, relevant entities are extracted from archives by using statistical NLP techniques. Furthermore, they will detect interesting events in television archives by detecting redundant stories, utilising the structure of the archive to identify links between different entities [19]. The Poli Media project [84] mines the text of minutes of the general state debates to extract and link historical entities from the archives of historical newspapers, radio bulletins and television programs.
The Historical Timeline Mining and Extraction (HiTiME) project [50] is aimed at detecting and structuring biographical events. To this end they analyze biographies of persons from the Dutch union history to create timelines that tell the life story of these persons, and social networks of the persons they interacted with. Van de Camp and Van den Bosch [130] describe an approach to build networks of historical persons by mining biographies for person names and relationships between persons. They use standard named entity recognition tools and utilise the inherent structure of biographies (the topic of the biography is a particular person, and any persons mentioned in this biography should have something to do with this person) to detect interpersonal relations.
Many ehumanities and ehistory projects are exploring document summary techniques or document enrichment techniques from NLP to aid search in their archives. One of these techniques is topic modelling, which can be used to add topic indicators to a document, which may help cluster search results or create more fine grained indexes of archive records. Wittek and Ravenek [139] explore the state of the art in topic modelling techniques to index 19,000 letters of correspondences between 16th and 17th century Dutch scientists.
Other high-level text analysis methods, such as frequency-based corpus analysis to compare e.g. work from different authors or investigation of other stylometry characteristics, are also popular in the ehumanities domain [115]. These methods are not domain-dependent and fit more easily into the ehumanities researcher search-based toolbox.
The spectrum of tools to extract knowledge from unstructured historical data is wide. Important contributions are essentially domain-independent [7], thus not particularly focused on historical text processing. Gangemi [39] presents a recent and complete comparison of generic knowledge extraction tools for the Semantic Web, which will aid historical researchers working in the phases 2 (enrichment) and 3 (editing) of the historical information life cycle (see Section 3.1).
Search and retrieval
In search and retrieval we include systems that exploit semantic formalisms as a new way of indexing, querying and accessing historical data, instead of relying on the traditional text-based or keyword-based algorithms. This task matches the phase 4 (retrieval) of the life cycle of historical information (see Section 3.1).
It is not a coincidence that a high number of contributions that aim at extraction of structured entities from historical data also point at some desired system able to improve search and retrieval of such entities. Indeed, by means of constructing a semantic graph of historical knowledge, search and retrieval of that knowledge, as well as indexing systems that give exact pointers to the source in which particular historical entities are mentioned, can be easily built and improved. The Agora [1] (museum collections), BRIDGE [18] (historical TV metadata), CHOoral [23] (historical audio metadata), Historical Timeline Mining and Extraction (HiTiME) [50] (biographical events), Verrijkt Koninkrijk [25] (Dutch post-war social clusters concepts) and FDR Pearl Harbor [34] (historical events around Pearl Harbor attack on 1941) projects are all good examples of this tendency. Once the knowledge is successfully extracted from the historical sources and formalized appropriately, entities structured this way can be used for a graph-based search and retrieval, for instance through SPARQL queries (see Section 2.2), although most systems use specific access methods [53]. Other projects, like the H-BOT [44] project, use a natural language interface instead of a query system for retrieval of such historical structured knowledge.
Indexing of historical contents is another way of improving search and retrieval of historical data. Indexing and historical data storage systems have a long tradition in historical research [15]. CLIO [113] is a traditional example of such a system, nowadays indexing is performed by XML annotation-oriented approaches, such as described by Robertson [88]. These initiatives should consider the emerging RDFa, microformats and microdata technologies (see Section 2.2) to study the ways they fit in the vast domain of historical text annotation systems.
Semantic interoperability
In this section we analyze to what extent contributions consider the problem of data integration and use the Semantic Web to deal with it. The specific problems encountered are data model mismatching, schema incompatibilities and disparate source formats. Semantic interoperability has much to do with data integration, namely, how to commonly query and uniformly represent data that come from multiple sources (i.e. fitting several, probably non-compatible data models).
Semantic heterogeneity of historical sources is especially present on social history projects. The North Atlantic population project [78] (publication of microdata of several Atlantic countries) has this problem of data harmonization, in which heterogeneity of sources requires an intense work on resolving data model inconsistency between datasets.
The source material for the Historical Sample of the Netherlands [49] (HSN) database consists mainly of the certificates of birth, marriage and death, and of the population registers. From those sources the life courses of about 78.000 people born in the Netherlands during the period 1812–1922 have been reconstructed. Stored in a database and downloadable as files, this information forms a unique tool for research in Dutch history and in the fields of sociology and demography. As in the case of the HSN this type of sources is usually stored in archives, and, for the majority from a more remote past, not yet machine readable and not easy to analyse with NLP techniques. There is one major pitfall in linking this kind of data: extracting data about persons, events, institutions, locations is one thing, but linking to their different instantiations (for instance different name spellings, or persons with the same name) and keeping good documentation is the real challenge [65].
The CEDAR project [21], located in the crossroads of the Semantic Web, statistical analysis and social history, exposes the Dutch historical census data in the Semantic Web. Censuses are a great source of non-biased socio-historical information, but they present complex problems in both internal (i.e. between the time series) and external (i.e. other datasets) interlinking [71].
The work developed by Sieber et al. [100] provides a deep analysis of how semantic heterogeneity can be addressed exclusively with semantic technologies, and describes how to achieve success in environments with very disparate data models. In the history-related domain of geographic information systems (GIS), already discussed in Section 4.1.1, Manso and Wachowicz [66] provide an extensive review on current issues in interoperability.
Classification systems
Multiple publications in classification systems [31,42,72,103] are especially aimed at solving interoperability problems in historical data. Classification systems provide a standard mechanism to compare such data, but their specific implementation and effectiveness depends on the orientation towards source or goals of the historical data (see Section 3.2.3) created in phase 1 of the historical data life cycle (see Section 3.1).
When dealing with vast amounts of historical data, classification systems are a necessity in order to organize and make sense of the data. The main goal of a classification system is therefore to put things into meaningful groups [9]. This entails an allocation of classes which are created according to certain relations or similarities. The main issue with historical classification systems is that they are not consistent over time, making comparative historical studies problematic. Historical census data is a typical example of this problem [21,69]. Census data is the only historical data on population characteristics which are not strongly distorted and yields an extremely valuable source of information for researchers [89].
However, major changes in the classification and coding of the different censuses, have hindered comparative historical research in both past and present efforts [131]. Researchers are forced to create their own classifications systems in order to answer their research question; however, this process often results in disparate systems, which are not comparable, contain a lot of expert knowledge, different interpretations of the data and could not be easily (re)used by other researchers. The fact that many of the modelling techniques are destructive in nature (we cannot go back to the source) makes it even more cumbersome to comprehend these sources. In order to deal with the changing classifications and vast differences at both national and international level, we need to connect the gaps between the datasets and conform to certain standard classification systems.
Currently several significant efforts have been made in this direction. The Integrated Public Use Microdata Series (IPUMS) project [55] for example faces the problem of bridging 8 different occupational classification systems and a total of 3200 different categories, containing the richest source of quantitative information on the American population. The North Atlantic Population Project [78] (NAPP) project provides a machine-readable database of nine censuses from several countries. The main focus of the NAPP project is to harmonize these data sets and link individuals across different censuses for longitudinal and comparative analysis. Their linking strategy involves the use of variables which do not change over time. In this process records are only checked if there is an exact match for some variables, such as race and state of birth. Other variables like age and name variables are permitted to have some variations. Another significant historical classification system is the Historical International Standard Classification of Occupations [48] (HISCO). As occupations are one of the most problematic variables in historical research, HISCO aims to overcome the problem of changing occupational terminologies over time and space. It encodes historical occupations gathered from different historical sources coming from different time periods, countries and languages, and classifies tens of thousands of occupational titles, linking these to short descriptions and images.
Transversal approaches
Finally, there are few but key contributions we have classified as being transversal, because they cover a wide spectrum of the list of overlapping tasks between the Semantic Web and historical research. They also influence almost every phase in the historical information life cycle (see Section 3.1).
The CLIO system [113], a databank oriented system for historians, is the first of such contributions. CLIO was, for decades, the system for creating, enriching, organizing and retrieving historical knowledge from historical data in the pre-Web era. Although not using Semantic Web technologies (see Section 2.2), it had a strong emphasis on semantics as key for structuring historical knowledge.
In the Linked Data universe, the Agora project [1] is one of such transversal contributions. It generates historical RDF of events extracted using NLP techniques from unstructured texts, uses it for enhanced search and retrieval, improves semantic heterogeneity and gives context by linking to other datasets. Similarly, the Verrijkt Koninkrijk [25] and Multilingual Access to Large Spoken Archives (NSF-ITR/MALACH) [79] projects perform these tasks in their particular domains (see Section 4.1.2). The FDR Pearl Harbor project [34] also contributes on this line, but additionally opening the very promising field of historical knowledge inference through the formalization and usage of historical OWL ontologies. All these are good examples on how historical data get much richer when their semantics are explicitly expressed and they are interlinked through standard vocabularies and ontologies.
Regarding tools, the Armadillo architecture of Semantic Web Services [5] and the Fawcett toolkit [33] contain the generic plot behind all these contributions, and cover the whole pipeline of semantic historical data management. The latter extracts RDF event-oriented triples from unstructured texts, and additionally allows historians to install a full semantic toolbox with widgets to experiment with their data. Open Refine [82], in combination with its RDF-export plugin, allows the extraction, transformation, modelling and publishing of historical Linked Data when the sources come in tabular format.
Additionally, the theoretical study by Boonstra et al. [15] envisages possibilities on how the Semantic Web can enhance research by historians. It constitutes, besides, a major work on the evolution of historical computing, ehistory and historical information science, and gives a deep intuition on how computer science can help to solve ancient problems in historical research.
Solving historical problems
Mapping between the open
problems of historical data (see Section 3.3) and the surveyed contributions in historical Semantic
Web (see Section 4). The sign ✓ indicates
that the problem is directly addressed in the Semantic Web task. The
sign ∘ indicates that the problem is indirectly or partially addressed
in the Semantic Web task
Mapping between the open problems of historical data (see Section 3.3) and the surveyed contributions in historical Semantic Web (see Section 4). The sign ✓ indicates that the problem is directly addressed in the Semantic Web task. The sign ∘ indicates that the problem is indirectly or partially addressed in the Semantic Web task
The first interesting result is that some of the problems identified in historical sources (Section 3.3.1) are mostly solved by the approaches we review in historical ontologies (Section 4.1.1). Concretely, our perception is that the structuring of historical data and the development of historical data models have been a success due to the creation of standard vocabularies and ontologies. These ontologies aid historians to describe, at least, the baseline historical entities and relations in historical domains: events are combinations of persons, places and moments in time when something historically relevant happened. The large number of projects exposing historical Linked Data on the Web using these ontologies (see Section 4.1.2) prove their usefulness and success. There is space, though, for improvement. Although it is commonly agreed that current historical ontologies model the core semantics of historical research, authors also agree that they are still scarce and need further development [54,83].
As part of the problems in historical sources, provision of background historical knowledge has been successful only partially. The infrastructure (Linked Data cloud, SPARQL endpoints on historical data) is set up and running. But the amount of historical data available is still too low to give good support to any historian creating historical datasets in the beginning of the life cycle (see Section 3.1). Consequently, little background knowledge can help today these historians in solving e.g. errors or inconsistencies at that phase. Similarly, the generic infrastructure for provenance publishing and retrieval in the Semantic Web is very mature and extensively used in other domains [123], but scarce or non existing in the historical domain although being identified as a very important requirement (see Section 3.3.1). The provision of such provenance on historical datasets needs to be guaranteed in projects using semantic technologies to publish historical data.
Solutions to the problem of relationships between sources are probably the greatest achievement of the application of semantic technologies to historical research. The large number of projects linking historical data we survey in Section 4.1.2 proves that the Semantic Web delivers working solutions to the problem of connecting isolated historical data sources. The usage of developed ontologies and vocabularies has been key to this end. Additionally, the existence of classification systems (Section 4.4.1) helps on data comparability in the Semantic Web. Because we see that the body of historical knowledge in the Semantic Web is still small, we expect the problem of finding related links between historical entities and datasets to grow in the future, although the Semantic Web has generic solutions for this [99].
The problems in historical analysis and presentation of sources (see Sections 3.3.3 and 3.3.4) are only partially addressed in approaches we have classified as transversal. These works cover a wide spectrum of the life cycle of (semantic) historical data, including analysis and presentation (phases 5 and 6, Section 3.1). Consequently, they deal with some analyses and visualizations. However, there is a lack of contributions tackling directly the problem, or considering explicitly historical research requirements with respect to analysis and visualization. The transversal tools are hence very generic, and they could be inappropriate for some historians. Therefore, it is very important to distinguish what analysis requirements are specific to historical research, and which ones are domain-independent. Our hypothesis is that these problems overlap only partially with the goals of the Semantic Web (i.e. representing and linking meaning on the Web). However, historians could benefit from analysis and visualization tools for historical semantic data, not as specific as project-oriented, but not as generic as domain-independent.
In Table 5 all open problems have Semantic Web tasks providing solutions, but not all tasks are mapped to some historical open problem. Concretely, the tasks of text processing and mining (Section 4.2) and search and retrieval (Section 4.3) do not seem to solve any of the identified problems. Why do we find contributions on these areas? First, although not being identified by historians as primary problems, they constitute secondary problems that need to be solved when representing and linking semantic historical data. These problems are not exclusively historical, but they needed to be reimplemented in the Semantic Web realm (e.g. natural language processing for extracting historical RDF triples, SPARQL to query historical semantic data on the Web). Secondly, the goals these tasks aim at were quite well solved in historical research before the inception of semantic technologies (e.g. manual input of historical data, SQL queries in historical relational databases), and thus historians did not consider them into the primary problem space.
The use of semantic technologies has contributed significantly to solving the open problems of historical data (see Section 5). However, there is a lot of room for improvement. The open problems are being addressed as shown, but they are far from being solved until they get additional attention. The scarce amount of historical data on the Semantic Web is a good example. Other problems, some more specific, some more generic, could be also tackled with semantic solutions. In this section we explore some aspects of the Semantic Web that have not been used yet or could be furtherly exploited in historical research.
Semantics of time, change, language, uncertainty and interpretation
Classifications and ontologies in history do exist, but not for all areas, not in Semantic Web languages and not always agreed upon. Although several historical ontologies have been developed (see Section 4.1.1), these models are insufficient for the vast amount and variety of historical data that still has to be published in the Semantic Web, especially when key issues for historians like interpretations or evidences need to be modelled and conveniently linked. Historical ontologies and vocabularies have been a reality in recent approaches. Ontologies describing classes and properties of some historical concern, such as concepts around the Pearl Harbor attack in 1941 [53], are an exciting modelling exercise for researchers but also a necessary step for better structuring historical information in the Web. Ontologies and vocabularies offer a way of controlling the predicates, classes, properties and terms that the community uses as a standard for describing factual and terminological knowledge about history. Designing good ontologies for historical domains is also an area with plenty of challenges: how can ontologies comprise the many conceptions of history depending on the temporal dimension of events described [54]? Moreover, how can differences in meaning and relations between concepts be traced, as time and historical realities change these concepts [137]? To what extent these meaning differences relate to the complexity of the language (e.g. Latin, Middle languages) and uncertainty (e.g. fuzzy dates and locations)? These questions, which comprise semantic technologies, knowledge acquisition and knowledge modelling techniques, are not yet completely understood and are a significant challenge in semantic historical research. On the other side, over the centuries, dictionaries, thesaurus, classification systems have been developed. How to mount those specifically grown ordering principles to the Web in a way that makes them explorable and linkable to other ontologies is one interesting challenge which requires a close collaboration between historians, knowing and designing those specific tools, and computer scientists, often relying on much broader and generic ontologies.
Reasoning
From the point of view of Linked Data, ontologies and vocabularies are designed in order to control the terms in which datasets may express data, as well as the data model in which these data are represented. However, in a more Semantic Web perspective, one may expect these ontologies and vocabularies to facilitate new knowledge discovery; that is, to make explicit some implicit fact that was not trivial to deduce for the human eye, especially in big knowledge bases.
Reasoning is one of the key mechanisms of the Semantic Web still to be used in historical research. The absence of specific methods and tools for automatic historical inference, so that new, implicit historical knowledge can be derived, is another issue. We claim that reasoning could be fundamental for historical analysis 3.3.3 and tasks in the phase 5 (analysis) of the historical information life cycle (see Section 3.1).
Historical ontologies can be used to facilitate historical knowledge discovery using reasoners. Assuming that a particular domain is completely formalized as historical ontologies, then it is possible to run a reasoner on these ontologies to produce derived, implicit rules and facts that were not present in the original model as explicit knowledge (i.e. specifically encoded in the ontology), but that were there as underlying knowledge. For instance, if an ontology describes, on the one hand, the fact that a letter was sent from one government to another, and on the other hand, the fact that governments have a person responsible of sending and receiving letters, then it may be possible for the reasoner to infer what concrete persons sent and received what letters. As the knowledge base grows, implicit knowledge is not evident anymore and reasoners can facilitate an enormous work and produce high-value pieces of historical knowledge.
Since historians have different interpretations and no clear research question when starting an investigation, abductive reasoning (i.e. given the conclusions and a rule, try to select possible premises that support the conclusion) may be more convenient than deductive reasoning (i.e. deduce true conclusions given a premise and a rule) in historical research [22,51]. These would revert the order of some phases of the life cycle of historical information (see Section 3.1), generating a more bottom-up, data-based generation of hypotheses supporting evidence. The impact of abductive reasoning in historical research and its relationship with the life cycle needs further study and clarification.
The introduction of any kind of reasoning in the life cycle needs to be done with the goal of supporting, not replacing, the task of the historian, who must keep control of the implementation of the different phases.
Linking more historical data
We show in Section 4.1.2 that great efforts are being devoted to publish historical Linked Data. However, the amount of structured historical knowledge available on the Web is still insufficient to aid tasks that need high amounts and different kinds of historical background knowledge. While many different data and information sources exist, they are not always interlinked. This isolation of historical data sources hampers that they can be found, but it also inhibits how they can be further processed and connected.
One of the big claims of linked data is that, by linking datasets, relations established between nodes of these datasets highly enrich the information contained in them. That way, browsing datasets is not an isolated task anymore: by allowing users (and machines) to explore entities through their predicate links, data get new meanings, uncountable contexts and useful perspectives for historians.
For example, consider a scenario with three different SPARQL endpoints exposing RDF triples of a census with occupational data, a historical register of labour strikes, and a generic classification system for occupations (in the context of one particular country, for instance). Suppose that: the occupational census of the data exposes triples with countings on occupations (for example, how many men and women worked in a particular occupation in a concrete city), the historical register of labour strikes contains countings on how many people participated in labour strikes (number of women and men, per occupation and city), and the generic classification system harmonizes names of the occupations between both previous datasets (for example, gives a common number for representing occupation names that may vary between census occupations and labour strike occupations). Then, it is clear that several SPARQL queries can be constructed to give very meaningful and interesting linked data to the historian. For instance, such a query may return, given a city and an occupation code, which ratio of men and women followed a particular well-known labour strike. Another SPARQL query may return an ordered list of historical labour strikes by relevance, according to several indicators (strike successfulness ratio, total number of workers on strike, density of people on strike depending on the location, etc.). It is obvious that the possibilities increase if we think of more related historical sources to link, like datasets describing historical weather or historical geographical names and areas.
Flexibility of data models
It is considered to be a bad practice in historical research not doing the historical data modelling at phase 1 of the historical information life cycle (see Section 3.1). The choice of a particular data model to represent historical data is a critical issue for most historical computing projects. The election of some appropriate data model may seem a good design decision at some stage of the project. However, new requirements, research directions or stakeholder priorities may convert that data model into an obstacle more than an aid. Flexibility of data with respect to the data model used to represent historical domains is desired to avoid restructuring entire databases. Comparison in historical research requires flexibility of the models to be able to match them to one another. At the end, that enforces historians to make their data selection and processing dependent of a certain data model that can not be easily replaced or altered if needed. This happens usually in environments with changeable and creep requirements [57].
Applying semantic technologies and Linked Data principles to historical data may have a major advantage regarding historical data models, providing flexibility at the historical data modelling phase. Two different approaches regarding historical data modelling have been followed traditionally in historical computing: the source-oriented representation, and the model-oriented (also known as goal-oriented) representation (see Section 3.2.3). Do semantic technologies allow a flexible representation of historical data? Can the Semantic Web found a new standard on a source-and-goal, hybrid approach? RDF databases (see Section 2.2) can store the middleware representation of further views on the data [69]. These views can be modelled as close to any particular historical interpretation as needed. This way, the decision of what data model suits better the historical source can be postponed until the very end of the life cycle (see Section 3.1), or adopted as early as necessary.
Moreover, additional questions arise when considering the traditional perspectives on data modelling: the conceptual, logical and physical data models. These perspectives help in detaching data management technology, like relational databases or RDF triplestores, from conceptual schemas (i.e. the semantics of a domain). While conceptual data models are currently shared on the Web as e.g. historical ontologies (see Section 4.1.1), the flexibility of the whole modelling stack towards semantic changes needs to be better understood.
Non-destructive data transformations
The non-flexibility of data models (see Section 6.4) is related to the non-flexibility of historical data transformations. Historical data are modified in the life cycle of historical information (see Section 3.1). But if update, enrichment, analytic and interpretative operations are not controlled, these transformations lead to different historical data representations which can hardly be related to each other any more, nor in terms of provenance nor in terms of relatedness.
Another issue is supporting data transformations under two constraints: (a) without modifying source data (so the originals stay intact); and (b) with tracking of changes. Consequently, destructive updates are a major concern when selecting, aggregating and modifying historical data. On the one hand, modifications to specific encodings (CSV, spreadsheets, XML) do not support non-destructive updates, and version control systems are necessary to retrieve previous states. On the other hand, relational databases can be inefficient when querying all recorded transformations, edits and manipulations.
Non-destructive updates are well supported by current Semantic Web technology
like SPARQL (see Section 2.2). SPARQL
Discussion and conclusions
In this paper we present a general overview of semantic technologies applied to historical research. We describe a general approach to historical research and the Semantic Web, and motivate why the combination of the two is an interesting field of research. We introduce core elements of historical research, such as the life cycle of historical information, several classifications for historical data, and the open problems shared by historians and computer scientists. Then, we overview contributions to the young historical Semantic Web in form of papers, projects and tools, articulating the work into several tasks and trends within these tasks. We provide a mapping to see to what extent the work on these tasks is helping to solve the open problems of historical data and historical research. Finally, we dig out a list of interesting open challenges for the future, like working out the semantics of critical aspects for historians, such as interpretation and time, and encouraging reasoning in the historical Semantic Web.
It is interesting to observe the sparsity in Tables 1, 2, 3 and 4. There is a significant difference in the number of empty spaces (i.e. specificity of the contributions) between Tables 1 and 4 (papers and tools, ontologies), and Tables 2 and 3 (projects and online resources). While the former set has essentially lots of holes, the latter has lots of complete lines. The reason for this is probably the specificity researchers think research papers and useful tools need. Usually written by computer scientists, papers and tools need to be grounded and tackle a very concrete problem to be worth written or implemented. On the other hand, projects (Table 2) are written in a very generic way covering all tasks, with probably intensive participation of historians and clear aims to solve the whole pipeline. In practice, though, these goals are materialized in very concrete research contributions. This leads us to think that Semantic Web solutions need very specific requirements in order to be correctly deployed in history. They need to be applied to historical data in a complex, layered and properly adapted pipeline. Good practices and standards, and their relationship with the life cycle of historical information, are still needed for the field to continue evolving.
We show how the Semantic Web and history communities understand the need for representing inner semantics implicitly contained in historical sources, and how these semantics can be conveniently identified, formalized and linked. With the appropriate pipelines, algorithms can extract entities from digital historical sources and transform these occurrences into RDF triples, according to some historical ontology or vocabulary. These entities can be linked between them and with other historical Linked Data, contributing to an open, world wide, online persistent graph of historical knowledge: an historical Semantic Web. The work presented in this survey contributes in one phase or another in this graph-building pipeline. We leave to the reader if this historical Semantic Web building pipeline is, in fact, the Semantic Web version of the life cycle of historical information.
The challenge of the realisation of a historical Semantic Web meeting as many requirements as possible may bring new facilities for a number of stakeholders. On the one hand, humanities researchers, also outside history, will be able to integrate the historical Semantic Web to their own information life cycle. They will be able to search, retrieve and compare historical knowledge and use it for the construction of their narratives, still the final outcome of historical research. On the other hand, practitioners will be able to search new data sources to develop history-aware applications for public institutions, private companies and citizens.
Footnotes
Acknowledgements
The work on which this paper is based has been supported by the Computational
Humanities Programme of the Royal Netherlands Academy of Arts and Sciences, under
the auspices of the CEDAR project (see
This work has been supported by the Dutch national programmes COMMIT.
The authors want to thank all contributing colleagues, especially the interviewees Onno Boonstra, Peter Doorn, Jan Kok, Henk Laloli and Dirk Roorda.