
Abstract
Crowdsourcing techniques provide effective means for solving a variety of ontology engineering problems. Yet, they are mainly used as external support to ontology engineering, without being closely integrated into the work of ontology engineers. In this paper we investigate how to closely integrate crowdsourcing into ontology engineering practices. Firstly, we show that a set of basic crowdsourcing tasks are used recurrently to solve a range of ontology engineering problems. Secondly, we present the uComp Protégé plugin that facilitates the integration of such typical crowdsourcing tasks into ontology engineering from within the Protégé ontology editor. An evaluation of the plugin in a typical ontology engineering scenario where ontologies are built from automatically learned semantic structures, shows that its use reduces the working times for the ontology engineers 11 times, lowers the overall task costs by 40% to 83% depending on the crowdsourcing settings used and leads to data quality comparable with that of tasks performed by ontology engineers. Evaluations on a large anatomy ontology confirm that crowdsourcing is a scalable and effective method: good quality results (accuracy of 89% and 99%) are obtained while achieving cost reductions of 75% from the ontology engineer costs and providing comparable overall task duration.
Introduction
The advent of the Web has significantly changed the context of systems that rely on formally specified knowledge (e.g., ontologies). These systems became distributed, cater for many users with different levels of expertise and integrate knowledge sources of varying quality [11]. As a consequence, an important change was required in the knowledge acquisition methods that enable these systems by gradually extending knowledge creation processes to include groups of users with diverse levels of expertise and training [11]. This change started by opening up knowledge creation tools to wider groups of contributors. Indeed, WebProtégé [30] is an extension of the Protégé ontology editor that allows the ontology engineering process to be performed by a larger, distributed group of contributors. Similarly, in the area of natural language processing, GATE Teamware extends the GATE linguistic annotation toolkit with distributed knowledge creation capabilities [1]. While these extensions support the collaborative and distributed work of knowledge experts (ontology engineers and linguists), recent approaches have tried further broadening this process by allowing large populations of non-experts to create knowledge through the use of crowdsourcing techniques such as games or mechanised labour platforms. Crowdsourcing methods provide effective means to solve a variety of knowledge acquisition tasks [24] by outsourcing these to “an undefined, generally large group of people in the form of an open call” [12].
A crucial knowledge acquisition process in the area of the Semantic Web is ontology engineering. Ontology engineering is the process spanning the creation and maintenance of ontologies during their entire life-cycle. Similarly to other knowledge creation tasks, ontology engineering is traditionally performed by ontology experts and therefore it tends to be a complex, costly and, above all, time-consuming process.
Let’s consider the task of ontology creation. To reduce its complexity, ontology construction is often bootstrapped by re-using existing ontologies or automatically derived ones. Ontology learning methods, for example, automatically extract ontologies from (a combination of) unstructured and structured resources. Although the automatically extracted ontologies already provide a good basis for building the ontology, they typically contain questionable or wrong ontological elements and require a phase of verification and redesign (especially pruning) by the ontology engineer. The ontology verification phase involves, among others, checking that the ontology concepts are relevant to the domain of interest and that the extracted subsumption relations are correct. As detailed in Section 2, crowdsourcing has been used effectively to solve a range of such ontology verification tasks and therefore it could be employed to support the ontology engineer in performing such tasks.
Unfortunately, crowdsourcing techniques require high upfront investments (understanding the techniques, creating appropriate tasks) and therefore, despite their proven usefulness, these techniques remain outside the reach of most ontology engineers. Therefore, in this paper we investigate how to more closely embed crowdsourcing into ontology engineering in line with the current trends of open and extended knowledge acquisition processes. In the area of Natural Language Processing (NLP), where the use of crowdsourcing is highly popular [22], there already exists an effort towards supporting easy integration of crowdsourcing methods into linguists’ work: the GATE Crowdsourcing Plugin is a component of the popular GATE NLP platform that allows inserting crowdsourcing tasks into larger NLP workflows, from within GATE’s user interface [2]. In the Semantic Web area, recent approaches, such as ZenCrowd [8] and CrowdMap [25], involve large groups of non-experts to solve specific knowledge acquisition tasks such as entity linking or ontology matching, respectively. There has been however no work in including crowdsourcing to support a broad range of ontology engineering tasks, although Noy and colleagues [19] introduce a vision for tool support to facilitate the integration of crowdsourcing into ontology engineering after experimentally proving that crowd-workers are a viable alternative for verifying subclass-superclass relations.
To achieve our goal we seek answers to the following research questions:
Overview of approaches addressing problems in various stages of the Semantic Web life-cycle [27], their genres and the type of crowdsourcing tasks that they employ
Overview of approaches addressing problems in various stages of the Semantic Web life-cycle [27], their genres and the type of crowdsourcing tasks that they employ
Our findings show that in a scenario where automatically extracted ontologies are verified and pruned, the use of the plugin significantly reduces the time spent by the ontology engineer (11 times) and leads to important cost reductions (40% to 83% depending on the crowdsourcing settings used) without a loss of quality with respect to a manual process. Experimental evaluations on a large and domain specific ontology has lead to comparable task durations and significant cost reductions (of 75%) while obtaining good quality results that are in line with results obtained by other studies [9,19].
Crowdsourcing methods are usually classified in three major genres depending on the motivation of the human contributors (i.e., payment vs. fun vs. altruism).
Mechanised labour (MLab) is a type of paid-for crowdsourcing, where contributors choose to carry out small tasks (or micro-tasks) and are paid a small amount of money in return. Popular crowdsourcing marketplaces include Amazon’s Mechanical Turk (MTurk) and CrowdFlower (CF). MTurk allows requesters to post their micro-tasks in the form of Human Intelligence Tasks (or HITs) to a large population of micro-workers (often referred to as turkers). Games with a purpose (GWAPs) enable human contributors to carry out computation tasks as a side effect of playing online games [32]. An example from the area of computational biology is the Phylo game (phylo.cs.mcgill.ca) that disguises the problem of multiple sequence alignment as a puzzle like game thus intentionally decoupling the scientific problem from the game itself [13]. The challenges in using GWAPs in scientific context are in designing appealing games and attracting a critical mass of players. Finally, in altruistic crowdsourcing a task is carried out by a large number of volunteer contributors, such as in the case of the Galaxy Zoo (www.galaxyzoo.org) project where over 250 K volunteers willing to help with scientific research classified Hubble Space Telescope galaxy images (150 M galaxy classifications).
Crowdsourcing methods have been used to support several knowledge acquisition and, more specifically, ontology engineering tasks. To provide an overview of these methods we will group them along the three major stages of the Semantic Web Life-cycle as identified by Siorpaes in [27] and sum them up in Table 1.
The OntoPronto game [27] aims to support the creation and extension of Semantic Web vocabularies. Players are presented with a Wikipedia page of an entity and they have to (1) judge whether this entity denotes a concept or an instance; and then (2) relate it to the most specific concept of the PROTON ontology, therefore extending PROTON with new classes and instances. Climate Quiz [26] is a Facebook game where players evaluate whether two concepts are related (e.g. environmental activism, activism), and which label is the most appropriate to describe their relation. The possible relation set contains both generic (is a sub-category of, is identical to, is the opposite of) and domain-specific (opposes, supports, threatens, influences, works on/with) relations. Two further relations, other and is not related to were added for cases not covered by the previous eight relations. The game’s interface allows players to switch the position of the two concepts or to skip ambiguous pairs. Guess What?! [18] goes beyond eliciting or verifying relations between concepts to creating complex concept definitions. The game explores instance data available as linked open data. Given a seed concept (e.g., banana), the game engine collects relevant instances from DBpedia, Freebase and OpenCyc and extracts the main features of the concept (e.g., fruit, yellowish) which are then verified through the collective process of game playing. The tasks performed by players are: Players (1) assign a class name to a complex class description (e.g., assign
Eckert and colleagues [9] relied on MTurk micro-workers to build a concept hierarchy in the philosophy domain. Crowdsourcing complemented the output of an automatic hierarchy learning method in: a) judging the relatedness of concept pairs (on a 5-points scale between unrelated and related) and b) specifying the level of generality between two terms (more/less specific than). Noy and colleagues [19] focused on verifying the correctness of taxonomic relations as a critical task while building ontologies.

Main stages when using the uComp plugin.
Based on the analysis above, we distill a set of recurrent basic crowdsourcing task types used to solve a variety of ontology engineering problems, as follows.
Crowd-workers judge whether two terms (typically representing ontology concepts) are related. In some cases they are presented with pairs of terms [9] while in others they might need to choose a most related term from a set of given terms [28]. This type of crowdsourcing task is suitable both in ontology creation [9] and in ontology alignment scenarios [28].
Presented with a pair of terms (typically representing ontology concepts) and a relation between these terms, crowd-workers judge whether the suggested relation holds. Frequently verified relations include generic ontology relations such as equivalence [5,25] and subsumption [19,25], which are relevant both in ontology evaluation [19] and ontology alignment scenarios [25].
In these tasks, crowd-workers are presented with two terms (typically corresponding to ontology concepts) and choose an appropriate relation from a set of given relations. Most efforts focus on the specification of generic ontology relations such as equivalence [25,26,28], subsumption [9,25–28], disjointness [26] or instanceOf [26,27]. The verification of domain-specific named relations such as performed by Climate Quiz [26] is less frequent.
For this task, the crowdworkers confirm whether a given term is relevant for a domain of discourse. This task is mostly needed to support scenarios where ontologies are extracted using automatic methods, for example, through ontology learning.
The core crowdsourcing tasks above have been used by several approaches and across diverse stages of ontology engineering, thus being of interest in a wide range of ontology engineering scenarios. As such, they guided the development of our plugin, which currently supports tasks T2, T4, and partially T3.
The uComp Protégé plugin
In order to support ontology engineers to easily and flexibly integrate crowdsourcing tasks within their work, we implemented a plugin in Protégé, one of the most widely used ontology editors. The typical workflow of using the plugin involves the following main stages (as also depicted in Fig. 1).
An ontology engineer using Protégé can invoke the functionalities of the plugin from within the ontology editor at any time within his current work. The plugin allows specifying some well defined ontology engineering tasks, such as those discussed in Section 2.1 above. The view of the plugin that is appropriate for the task at hand is added to the editor’s user interface via the Window → Views menu. The ontology engineer then specifies the part of the ontology to verify (e.g., a specific class or all classes in the ontology), provides additional information and options in the plugin view and then starts the crowdsourcing deployment process. Crowdsourced tasks can be canceled (or paused) anytime during the crowdsourcing process. We further detail the plugin’s functionality in Section 3.1. The plugin uses the uComp API1
The process of crowdsourcing happens through the uComp platform, a hybrid-genre crowdsourcing platform which facilitates various knowledge acquisition tasks by flexibly allocating the received tasks to GWAPs and/or mechanised labour platforms alike (in particular, CrowdFlower) [24] depending on user settings. In Section 3.2 we present the crowdsourcing tasks created by the uComp platform (developed in the uComp project,
The uComp platform collects crowd-work harvested by individual genres (GWAPs and micro-task crowdsourcing). Mechanisms for evaluating the quality of each contribution are in place, which aim to filter out potential spammers.
When all crowdsourcing tasks of a job have been completed, the platform combines the results and provides them to the plugin. If the task was crowdsourced to different genres, then the results provided by different platforms must be merged. Subsequently, the individual judgements can be aggregated using appropriate aggregation mechanisms (e.g., majority voting, weighted majority voting, average, collection).
As soon as available, the plugin presents the results to the ontology engineer and saves them in the ontology. All data collected by the plugin is stored in the ontology in
The plugin provides a set of views for crowdsourcing the following tasks:
Verification of Domain Relevance (T4).
Verification of Relation Correctness – Subsumption (T2).
Verification of Relation Correctness – InstanceOf (T2) – the verification of instanceOf relations between an individual and a class.
Specification of Relation Type (T3) is a Protégé view component that collects suggestions for labeling unlabeled relations by assigning to them a relation type from a set of relation types specified by the ontology engineer.
Verification of Domain and Range where crowd-workers validate whether a property’s domain and range axioms are correct.
The following subsections contain detailed descriptions of all plugin functionalities.

The interface of the uComp Class Validation view used to create a Verification of Domain Relevance (T4) task.
contains elements such as the concept selected by the user for validation. This part of the view is diverse among different plugin functionalities.
such as the domain of the ontology, i.e., the field of knowledge which the ontology covers, is present in all views of the plugin. If entered once, the domain will be stored in the ontology (as
For every task, the plugin contains a predefined task description (typically including examples) which is presented to the crowd-worker. If the ontology engineer wants to extend this task description, (s)he can provide more guidelines in the additional information field. This functionality is present in all the views of the plugin.
allows performing a task (e.g., domain relevance validation) not only for the current class, but for a larger part of or even the entire ontology. If the Validate subtree option is selected, the plugin crowdsources the specified task for the current concept and all its subconcepts recursively. To apply the functionality to the entire ontology, the plugin is invoked from the uppermost class, i.e., (Thing). For example, in Fig. 2, the class “energy” has 3 subconcepts, which adds up to 4 units being verified if recursive control is activated.
is a button that computes and displays expected cost of HC verification before actually starting the job. The button is only available in the user interface if CrowdFlower has been selected as crowdsourcing method (and not the GWAP).
to start the crowdsourcing process.

Screenshot showing the interface for subClassOf relation validation, including the display of results.

Screenshot showing the interface for individual validation, currently waiting for results from the uComp API.

The interface of relation type suggestion, the user selects candidates from all existing properties.
Upon receiving the request from the Protégé plugin, the uComp API selects the appropriate crowdsourcing genre and creates the relevant crowd-jobs. Currently the platform can crowdsource tasks either to GWAPs such as Climate Quiz [26] or to CrowdFlower, with a hybrid-genre strategy currently being developed. In this paper, we test the plugin by crowdsourcing only through CrowdFlower.
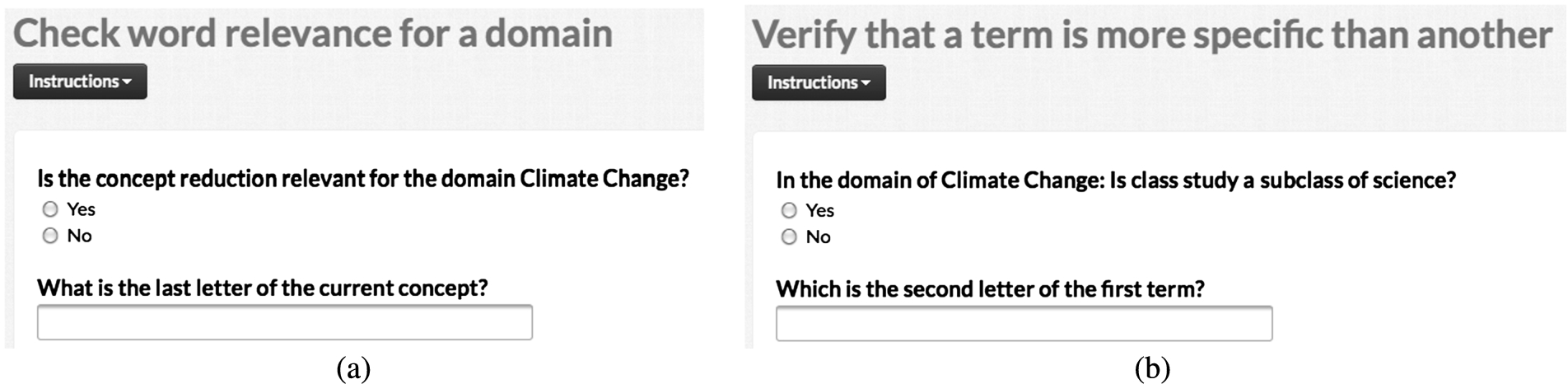
Generated CrowdFlower job interface for (a) the Verification of Domain Relevance (T4) and (b) the Verification of Subsumption (T2) tasks.
Generated CrowdFlower job interface for the Verification of InstanceOf (T2) task.
Figure 6 depicts the crowdsourcing interfaces created automatically by the uComp platform for the verification of domain relevance (part a) and the validation of subsumption relations (part b) while Fig. 7 shows the interface of instance verification tasks. Figure 8 displays the automatically generated crowdsourcing interface for the relation specification task.

Generated CrowdFlower job interface for the Specification of Relation Type (T3) task.
The uComp platform requires only the task data from the Protégé plugin and it provides relevant instructions as well as gold units to all tasks. Additionally, each crowdsourcing interface is extended with straightforward verification questions (i.e., typing some letters of the input terms). It has been shown experimentally (e.g., [14,16]), that extending task interfaces with explicitly verifiable questions forces workers to process the content of the task and also signals that their answers are being scrutinized. This seemingly simple technique had a significant positive effect on the quality of the collected data, as reported in [14,16].
To ensure a good quality output, by default all created jobs are assigned to Level 3 CrowdFlower contributors which are the contributors delivering, on average, the highest quality work. Also, for the moment we assume that the (labels of the) verified ontologies will be in English and therefore we restrict contributors to the main English speaking countries: Australia, United Kingdom and United States. In each created job we present 5 units per task and for each unit we collect 5 individual judgements. A price per task of $0.05 was specified for all jobs. A task is complete when all requested judgments have been collected.
The plugin is available from Protégé’s central registry as the uComp Crowdsourcing Validation plugin. The plugin has been tested with Protégé versions 4.2 and 4.3, as well as the recent version 5.0 (beta). A local configuration file contains the uComp-API key2
Request a key from the uComp team, see
We performed two main groups of experimental evaluations of the uComp Plugin. Table 2 displays an overview of the various experiments performed including their focus and the various experimental settings, described in what follows.
Overview of evaluation tasks performed, including used datasets and settings. U,P,J = Unit, Price ($), Judgements
Overview of evaluation tasks performed, including used datasets and settings. U,P,J = Unit, Price ($), Judgements
The first set of evaluations focuses on assessing the
We evaluate the Plugin in the context of an ontology learning scenario as described in the introduction because i) bootstrapping ontology engineering by extracting an initial ontology automatically is a feasible and frequent ontology engineering approach and ii) automatically generated ontologies present errors that are best solved through human intervention. After the verification step with the uComp plugin, the resulting ontologies are used as part of a media monitoring tool3
To estimate the cost, time and quality aspects when working on large, real-life ontologies we perform a set of
Plugin evaluations were performed over four different ontology engineering tasks in order to 1) test different functionalities of the plugin; and 2) to obtain evaluation results over a range of tasks. These tasks are:
In the scalability evaluations, we focus on evaluating two functionalities of the plugin, namely the domain relevance check and checking the correctness of subsumption relations.
Overview of the ontologies used in the feasibility and scalability evaluations
Overview of the ontologies used in the feasibility and scalability evaluations
The goal of the evaluation is to assess the improvements that the uComp Plugin could enable in an ontology engineering scenario in terms of typical project completion aspects such as time, cost and quality of output. The usability of the plugin is an additional criteria that should be evaluated. Concretely, the evaluation goals can be summarised into the following questions:
How does the use of the plugin affect the time needed to perform ontology engineering tasks? We distinguish the total task time ( Are there cost benefits associated with the use of the plugin? We compute costs related to payments for the involved work-force, that is payments to ontology experts ( What are the implications on the quality of the resulting output when using the Plugin? Several studies have shown that the quality of various knowledge acquisition tasks performed by crowd-workers is, in general, similar to (or even better than) the quality of tasks performed by ontology engineers [19,23,29]. While the quality of the obtained data is not the core focus of our evaluation, we expect to obtain similar results to previous studies. Is the plugin usable? As any end-user tool, the plugin should be easy to understand and use by the average ontology engineer already familiar with the Protégé environment.
Evaluation data
Feasibility track
The input to most evaluation tasks are ontologies generated by the ontology learning algorithm described in [35] (primarily) from textual sources. In the feasibility track, we evaluate the plugin over four ontologies covering four diverse domains (climate change, finance, tennis and wine). All four domains are more or less general knowledge domains, but some (climate change, tennis) require domain familiarity or interest.
The ontologies tested as part of this evaluation experiments are of small to medium size (see Table 3). The Climate Change ontology has 101 classes and 81 relations (out of which 43 are taxonomic relations, and 24 unnamed relations) while the Finance ontology has 77 classes and 50 relations (20 of which are taxonomic relations). The Tennis ontology was used for the relation suggestion task only, it contains 24 unnamed relations. The ontologies were used as generated by the ontology learning process.
The ontologies used in the evaluation process, the instructions given to the manual evaluators, and the results, are found online.4
Task duration in minutes per ontology, evaluation task and setting
For the scalability evaluation we chose the Human ontology which represents the human anatomy part of the NCI thesaurus and was made available as part of the Anatomy track of the Ontology Matching Initiative.6
Unlike in the previous experiments, this is an approved ontology (not a learned ontology) and therefore we can assume it as correct. This allows measuring the quality of the crowd work even without having a baseline created by domain experts. Our strategy is that of modifying the Human ontology by adding incorrect data to it and assess how effective the crowd is in filtering out the incorrect cases. Accordingly, we have performed the following changes to the ontology.
For experiments focusing on measuring the domain relevance of ontology concepts, the Human ontology already provides 3304 concepts. We have extended the ontology with 1000 additional classes with labels extracted using ontology learning techniques from corpora related to the domains of climate change and tennis. These 1000 labels have been manually verified to exclude labels that might refer to the human body. These 1000 classes have been added as random leaf classes to the ontology resulting in a total of 4304 concept labels to be verified for domain relevance. More precisely, for the 500 terms each from the domains of climate change and tennis, the insertion algorithm randomly selects a concept from the original ontology and then inserts a new sub-concept which has the term as concept label. This strategy guarantees that non-relevant concepts are evenly distributed in the ontology.
For experiments involving the verification of the correctness of subsumption relations, human.owl provides 3761 correct subsumption relations. To introduce incorrect relations, we identified 800 pairs of leaf concepts and swapped their places in the ontology, therefore creating 1600 incorrect subsumption relations. Again, concepts to be swapped are randomly selected, and marked with an rdfs:comment tag to easily find incorrect concepts in subsequent analysis.
Regarding the evaluators, four were experienced Protégé users, the other four work in the Semantic Web area but have limited knowledge of Protégé and were shortly trained in Protégé. None of the ontology engineers involved had any strong expertise in a particular domain.
Average costs (in $) for the ontology engineer (
), crowd-workers (
) and the entire task (
) across ontologies and settings
Average costs (in $) for the ontology engineer (
The crowdsourcing job settings are displayed in Table 2. For the feasibility evaluations we grouped 5 units/task, paid $0.05 per task, requested 5 judgement per unit and crowdsourced our jobs to Level 3 workers from English speaking countries, in particular, UK, USA and Australia. Level 3 workers are workers that consistently provide the highest quality work on CrowdFlower. For the scalability evaluations, the job settings were maintained similar to the feasibility level evaluations, with two notable changes. Firstly, we requested only 3 judgements per unit (as opposed to 5 originally) as this setting is more feasible for large-scale tasks where every extra judgement introduces important increases in job costs and duration. We paid $0.03 for each domain relevance verification task (i.e., 5 units) and $0.05 for a task of verifying subsumption relations to cater for the varying difficulty levels of these two tasks. Secondly, we have selected the “Units Should be Completed in the Order they were Uploaded” option offered by CrowdFlower which is recommended for large scale projects. When enabled, this option crowdsources the data in batches of 1000 units at a time. Besides this job setting changes, the pricing model of CrowdFlower has changed from May 2014, when the feasibility experiments were run, by adding to the actual worker costs 20% transaction fees.
In practice, considering benefits, overhead and vacation, the actual costs for a productive hour are likely to be higher than $26. Nevertheless, we decided to keep $26 in order to be able to compare our findings to similar studies.
Ontology engineer cost savings are high and range from 92.4% to 86.15%, averaged at 89.9%. For the entire task, cost savings are moderate (19.7%–60.5%, Avg = 39%), with S_Crowd reducing S_Manual costs with 40%. Note, however, that task level cost savings will ultimately depend on the cost that ontology engineers decide to pay to crowd-workers. For example, choosing a cheaper task setting than currently (i.e., 3 judgements, with $0.01 per task vs. the current 5 judgements and $0.05 per task) will lead to average cost savings of 83.3% for the total task (S_CrowdCheap in Table 5). From the plugin’s perspective, the major goal is reducing ontology engineering costs, as crowdsourcing costs will depend on the constraints of the ontology engineer and are hard to generalise.
Fleiss’ Kappa values of inter-rater agreement per setting and when combining the data of the two settings
Results of the InstanceOf Verification (T2) task
Table 6 presents inter-rater agreement per task and per setting, with the number of raters per task given in parentheses. According to the interpretation of Landis and Koch [15] the inter-rater agreement among manual expert evaluators (S_ Manual) is moderate. Agreement among the four groups of CrowdFlower workers is substantial (S_Crowd). The combined agreement (manual expert and crowdworkers) is always higher than for manual evaluators alone. A detailed inspection of results reveals that judgement is difficult on some questions, for example relevance of given concepts for the climate change domain often depends on the point of view and granularity of the domain model. But in general, crowdworkers have a higher inter-rater agreement, which often corresponds with the majority opinion of manual experts, thereby raising Fleiss’ kappa (S_ManualCrowd). Also, the agreement between the crowd and experts is higher than among experts, possibly because crowdsourcing data is the majority view derived from 5 judgements as compared to a single expert judgement.
Results and Analysis As the task’s difficulty was low, the crowd and the domain experts answered 100% of units correctly, so the interesting point is the comparison of time and cost between crowd workers and domain experts. Domain experts needed on average 45.6 minutes to complete this task, while the crowdsourcing tasks took on average about 120 minutes. This still translates in important cost savings with the crowdsourced experiments costing only $6.31 as opposed to $19.76 corresponding to experts’ pay.
Results and Analysis. Similarly to the feasibility study on concept relevance and subsumption relations, we applied Fleiss’ Kappa for a comparative evaluation of inter-rater agreement regarding relation name suggestion. Apart from retrieving judgements from crowd workers, five domain experts assess relation labels for the 24 relations each in the domains of climate change and tennis. Table 8 provides Fleiss’ Kappa results of inter-rater agreement for the two domains, with the number of raters per task given in parentheses. S_Manual refers to the ratings of the five domain experts, S_ManualCrowd adds the result from the crowd to these five judgements.
Fleiss’ Kappa values for Specification of Relation Type (T3)
The agreement in the domain of climate change is moderate, in the domain of tennis it is fair, according to Landis and Koch [15]. The lower agreement values compared to those reported in Table 6 can be explained by the higher complexity of this task as it requires users to select a relation label from nine candidates. To complicate matters further, in some cases multiple relations labels are suitable candidates. The addition of crowd worker judgements to the judgements of domain experts influences the Fleiss’ Kappa values only slightly, which suggests that the quality of crowd worker results is comparable to domain experts’ quality.
Results of the large scale evaluation
While the experiments above confirm the cost savings made possible by the plugin as well as the plugin’s usability, it is important to also investigate the scalability of the proposed approach and its applicability when working with large and domain-specific ontologies. Table 9 lists the results of the large scale experiments for both tasks of Domain and Subsumption Verification on the Human ontology.
Although the manual and crowd performed verification process would take the same amount of time in hours, for larger projects it is important to translate these hours into working days: indeed, while the crowd is available continuously, the availability of domain experts is determined by working hour schedules. Therefore, when translating working hours into working days, we define a crowd working day as having 24 hours, while an ontology engineer working day has 8 hours. It can be easily seen, that in practice, an ontology engineer would spend more than two days on this task (this is a best case assumption that does not take into account fatigue and breaks) while crowdsourcing could return results within one day.
In term of costs, for the domain verification task we spent a total of $130, where $104 are actual worker costs and $26 are CF transaction fees (TF). Using the $26 hourly wage as for our feasibility experiments, the estimated cost for manually performing this task is $ 511. Therefore, crowdsourcing costs are a quarter of the ontology engineering costs (25%).
The quality of the results was very high. CrowdFlower statistics show an inter-worker agreement of 98%. Indeed, crowd workers rated 4260 of 4304 concepts correctly, which corresponds to a remarkably high accuracy of 99%. There were only 7 false positives, i.e. non-relevant terms from the domains of climate change and sports which were rated as relevant to human anatomy. For example the term “Forehand” (a type of shot in tennis) was wrongly judged as part of the human body. The number of false negatives was higher (37) and included some ambiguous terms in human anatomy such as “Pyramid” or “Curved Tube”.
In terms of costs we paid a total of $194 for the crowdsourcing task (out of which $39 were transaction fees). An ontology engineer employed for 39,20 hours would have costed $1019. Therefore, the total cost of crowdsourcing accounts to only 19% of the amount to be paid to the ontology engineer.
As some classes in the Human ontology have multiple super-classes, after swapping 1600 classes, the resulting ontology contains 2008 correct, and 1753 incorrect, subClass relations. CF workers judged 1812 relations as correct, 1949 as incorrect, so there was a substantial number of false negative ratings. Overall the accuracy of CF workers is 0.895 because 3367 of 3751 worker judgements were correct according to the ground truth provided by the Human ontology.
A detailed analysis reveals that the results contain 1713 true positives and 99 false positives, whereas the number of true negatives is 1654, leaving 295 false negatives. Regarding the false positives, many of the judgements intuitively make sense, e.g., that “Penis Erectile Tissue” is a subclass of “Reproductive System”, or that “Upper Lobe Of The Right Lung” is a subclass of “Organ”, none of which is stated by the Human ontology. Therefore, crowd judgements could help to identify questionable modelling assumptions made by domain experts which might need to be revised. Most wrong judgements concern false negatives, many of which are hard to assess from the concept labels. Examples include “Egg” subclass of “Germ Cell”, “Anatomic Sites” subclass of “Other Anatomic Concept”, and many similar types of relations.
Conclusions and future work
In this paper we investigated the idea of closely embedding crowdsourcing techniques into ontology engineering. Through an analysis of previous work using crowdsourcing for ontology engineering, we concluded that a set of basic crowdsourcing tasks are repeatedly employed to achieve a range of ontology engineering processes across various stages of the ontology life-cycle. We then presented a novel tool, a Protégé plugin, that allows ontology engineers to use these basic crowdsourcing tasks from within their ontology engineering working context in Protégé.
Our evaluation focused on assessing the concept of the crowdsourcing plugin. Although we plan to make use of the uComp platform, this particular evaluation forwarded all tasks directly to CrowdFlower and therefore is not influenced by the particularities of the uComp framework. As a first evaluation of the plugin, we focused on small-scale ontologies. An evaluation of the plugin in an ontology engineering scenario where automatically learned ontologies in two different domains are assessed for domain relevance and subsumption correctness, revealed that the use of the plugin reduced overall project costs, lowered the time spent by the ontology engineer (without extending the time of the overall tasks to over 4 hours) and returned good quality data that was in high agreement with ontology engineers. Finally, our evaluators provided positive feedback about the usability of the plugin.
A set of scalability evaluations aimed (1) to asses how well the proposed concept would scale to large ontologies and (2) to investigate whether crowd-workers can replace domain experts in specialized domains. The cost reductions were significant, with the crowdsourcing payments accounting to only a quarter or less of the estimated ontology engineering costs. Timings are comparable among the two approaches, however, we believe that a self-managed batching of the tasks would have lead to faster completion of tasks as opposed to using the built-in CrowdFlower batch based processing. The obtained quality depends on task difficulty, and ranges from very high (99% accuracy) for a simpler task to an acceptable 89% accuracy for the more difficult task of judging subsumption correctness. As such, our results are in-line with earlier studies that obtained similar quality results from crowds in specialized domains such as philosophy [9] and bio-medicine [19].
Limitations
The results that can be obtained with the uComp Protégé plugin might vary greatly between different tasks (depending on their type and the difficulty of the domain) but also depending on the timing when the tasks are crowdsourced and the response of the available work-force. Therefore, integrating such techniques in projects where strict deadlines must be met is a challenging task.
Additionally, our tool will benefit those ontology development projects which mostly involve the tasks we support and need to perform them extensively. For example, an ontology development project focusing on an ontology with a rich hierarchy and many inheritance levels, will benefit more from the tasks of subsumption verification than projects which develop large, but flat ontologies. Since ontology development processes greatly differ among themselves, there are currently no systematic studies about the relative importance of each task in ontology development projects, on average. As a result, we cannot estimate the usefulness of the plugin for ontology development projects in general either.
Since the plugin focuses on crowdsourcing, we must consider the following two issues of legal and ethical nature, which have so far not received sufficient attention. Firstly, no clear guidelines exist for how to properly acknowledge crowd contributions especially if their work would lead to some scientific results. Some volunteer projects (e.g., FoldIt, Phylo) already include contributors in the authors list [7,13]. The second issue is contributor privacy and well-being. Paid-for marketplaces (e.g., MTurk) go some way towards addressing worker privacy, although these are far from sufficient and certainly fall short with respect to protecting workers from exploitation, e.g. having basic payment protection [10]. The use of mechanised labour (MTurk in particular) raises a number of workers’ rights issues: low wages (below $2 per hour), lack of protection, and legal implications of using MTurk for longer term projects. We recommend at the least conducting a pilot task to see how long jobs take to complete, and ensuring that average pay exceeds the local minimum wage.
Future work
We consider our work as a first step towards the wide adoption of crowdsourcing by the ontology engineering community, and therefore, we see ample opportunities for future work.
Since the use of crowdsourcing has matured enough, it is a good time to move on from isolated approaches towards a methodology of where and how crowdsourcing can efficiently support ontology engineers. Such methodological guidelines should inform tools such as our own plugin, while our plugin could offer a means to build and test these guidelines. Future work will also reveal the best use cases for the plugin – identifying those cases when it can be used to collect generic knowledge as opposed to application areas where it should be used to support the work of a distributed group of domain experts.
Although our first evaluation of an anatomy-specific ontology lead to good results, some highly specialized domains will benefit much more from the possibility of engaging a community of domain experts. The question therefore is whether the current plugin concept could be adapted for expert-sourcing. We already received a request for using the tool in this way by an ontology engineer who needed to collect domain knowledge from domain experts but was hampered in her task by the lack of convenient interfaces for knowledge acquisition from experts. The presented plugin can already be used as an interface between ontology engineers and domain experts, by simply activating the Internal Channel mode of CrowdFlower: with this setting, the created CrowdFlower tasks can be shared through a URL with the chosen expert group as opposed to being presented to the crowd (which corresponds to the External Channel). Therefore, the use of the tool for expert-sourcing is already possible with its current connection to CrowdFlower, but extensions that would connect Protégé to other domain specific tools are not included and will constitute the subject of our future work.
In terms of the plugin development, we plan further extending its functionality (1) to support additional crowdsourcing tasks; (2) to allow greater control over job settings as well as (3) to permit monitoring of the results as they become available from within Protégé. Based on feedback from our research colleagues, we will prioritize supporting ontology localization with the plugin by crowdsourcing the translation of ontology labels into desired languages.
We plan to evaluate the plugin in other ontology engineering scenarios as well (e.g., ontology matching) and to conduct larger scale usability studies.
Recent advances in crowdsourcing include moving away from solving very simple tasks towards enabling experts drawn from the crowd to solve more complex tasks by creating micro-organizations and managing these organizations themselves [21]. While encouraging results have been reported on solving creative tasks such as animation creation or course curricula design, the applicability of this new approach for knowledge creation tasks is still unclear. In fact, Chilton explored different crowdsourcing approaches for the task of creating a taxonomy to describe a collection of text snippets (i.e., questions from Quora), and concluded the necessity of breaking down this task into manageable units of work [6]. An interesting future work question therefore refers to reconciling these two contradicting conclusions and exploring what is the maximum complexity of knowledge acquisition tasks that can be crowdsourced. Such fundamental investigations could result in redesigning our plugin to move on towards crowdsourcing more complex knowledge acquisition tasks than currently.
Footnotes
Acknowledgements
The work presented in this paper was developed within the uComp project, which receives the funding support of EPSRC EP/K017896/1, FWF 1097-N23, and ANR-12-CHRI-0003-03, in the framework of the CHIST-ERA ERA-NET. Dr. Sabou’s work was additionally supported by the Christian Doppler Forschungsgesellschaft, the Federal Ministry of Economy, Family and Youth, and the National Foundation for Research, Technology and Development – Austria.