
Abstract
In this paper we examine the use of crowdsourcing as a means to detect Linked Data quality problems that are difficult to uncover automatically. We base our approach on the analysis of the most common errors encountered in the DBpedia dataset, and a classification of these errors according to the extent to which they are likely to be amenable to crowdsourcing. We then propose and study different crowdsourcing approaches to identify these Linked Data quality issues, employing DBpedia as our use case: (i) a contest targeting the Linked Data expert community, and (ii) paid microtasks published on Amazon Mechanical Turk. We secondly focus on adapting the Find-Fix-Verify crowdsourcing pattern to exploit the strengths of experts and lay workers. By testing two distinct Find-Verify workflows (lay users only and experts verified by lay users) we reveal how to best combine different crowds’ complementary aptitudes in Linked Data quality issue detection. Empirical results show that a combination of the two styles of crowdsourcing is likely to achieve more effective results than each of them used in isolation, and that human computation is a promising and affordable way to enhance the quality of DBpedia.
Introduction
Many would consider Linked Data (LD) to be one of the most important technological trends in data management of the last decade [20]. However, seamless consumption of LD in applications is still very limited given the varying quality of the data published in the Linking Open Data (LOD) Cloud [22,59]. Data quality is commonly conceived as “fitness for use” [24] for a certain application or use case. In particular, data quality issues in LOD are the result of a combination of data- and process-related factors. The datasets being released into the LOD Cloud are – apart from any factual flaws that they may contain – very diverse in terms of formats, structure, and vocabulary. This heterogeneity and the fact that some kinds of data tend to be more challenging to lift to RDF than others make it hard to avoid errors, especially when the translation happens automatically. Simple issues like syntax errors or duplicates can be easily identified and repaired in a fully automatic fashion [13,18,19,32,37,38]. However, certain data quality issues in LD are more challenging to detect. Current approaches to tackle these problems still require expert human intervention, e.g., for specifying rules [18] or test cases [27], or fail due to the context-specific nature of quality assessment, which does not lend itself well to general workflows and rules that could be executed by a computer program. In this paper, we explore an alternative data curation strategy, which is based on crowdsourcing.
Crowdsourcing [23] refers to the process of solving a problem formulated as a task by reaching out to a large network of (often previously unknown) people. One of the most popular forms of crowdsourcing are ‘microtasks’ (or ‘microwork’), which consists in dividing a task into several smaller subtasks that can be independently solved. Depending on the tackled problem, the level of task granularity can vary (microtasks – whose results need to be aggregated – vs. macrotasks – which require filtering to identify the most valuable contributions) as can the incentive structure (e.g., payments per unit of useful work vs. prizes for top participants in a contest).
Another major design decision in the crowdsourcing workflow is the selection of the crowd. While many (micro)tasks can be performed by untrained workers, others might require more skilled human participants, especially in specialized fields of expertise, such as LD. Of course, expert intervention usually comes at a higher price either in monetary rewards or in the form of effort to recruit participants in another setting, such as volunteer work. Microtask crowdsourcing platforms such as Amazon Mechanical Turk (MTurk),1
In a previous work of ours [58] we investigated common quality problems encountered in the DBpedia dataset [6]. We analyzed the detected quality issues and classified them according to the extent to which they could be amenable to crowdsourcing. Based on these results, in this work we study the assessment via crowdsourcing of three specific LD quality issues in DBpedia: incorrect object, incorrect datatype or language tag, and incorrect link. In the following, we explain the research questions investigated in this work and present our proposed approach.
The first research question explored is hence
Secondly, given the option of different crowds, we formulate
To answer these questions, we first launched a contest that acquired 58 experts knowledgeable in LD to find and classify erroneous RDF triples from DBpedia (Section 4.1). They inspected 33,404 triples in total. These triples were then submitted as paid microtasks on the MTurk platform to be examined by laymen or ‘workers’ in a similar way (Section 4.2). Each approach (contest and paid microtasks) made several assumptions about the audiences they address (the ‘crowd’) and their skills. This is reflected in the design of the crowdsourcing tasks and the related incentive mechanisms. The results of both crowds were then compared to a manually created gold standard. The comparison of experts and workers, as discussed in Section 5, indicates that (i) untrained workers are in fact able to spot certain quality issues with satisfactory precision; (ii) experts perform well detecting two but not the third type of quality issues given, and lastly (iii) the two approaches reveal complementary strengths.
Given these insights,
Accordingly, the results of both Find stages (expert and workers) – in the form of sets of triples identified as incorrect, marked with the respective errors – were fed into a subsequent Verify step, carried out by MTurk workers (Section 4.3). The task consisted solely of the rating of a formerly indicated quality issue for a triple as correctly or wrongly assigned. This Verify step was, in fact, able to improve the precision of both Find stages substantially. In particular, the experts’ Find stage results could be improved to precision levels of around 0.9 in the Verify stage for two quality issues which showed to score much lower for an expert-only Find approach. The worker-worker Find-Verify strategy yielded also better results than the Find-only worker approach, and for one quality issue type even reached slightly better precision than the expert-worker model. All in all, our empirical results show that (i) a Find-Verify combination of experts and lay users is likely to produce the best results, but that (ii) they are not superior to expert-only evaluation in all cases. We demonstrated also that (iii) worker-worker Find-Verify approaches are a viable alternative for detection of the studied LD quality issues if experts are not available and that they certainly outperform Find-only lay user workflows.
Note that in this work we did not implement a Fix step from the Find-Fix-Verify pattern, as correcting the greatest part of the found errors via crowdsourcing is not the most cost-efficient method of addressing these issues. Thus, we argue in Section 4, a majority of errors can and should be addressed already at the level of individual wrappers leveraging datasets to LD.
To understand the strengths and limitations of crowdsourcing in the studied scenario, we further executed the semi-automatic RDFUnit framework [27] and a simple automatic baseline and compared their outcomes to the results of our crowdsourcing experiments. We showed that while these (semi-)automatic approaches may be amenable to identifying ontological inconsistencies in RDF data (thus potentially decreasing the amount of cases necessary to be browsed in the Find stage), a substantial part of quality issues can only be addressed via human intervention.
Contributions
This paper is an extension to previous work of ours [2], in which we presented the results of combining LD experts and lay users from MTurk when detecting quality issues in DBpedia. The novel contributions of our current work are summarized as follows:
Definition of the problem of classifying RDF triples into quality issues. Formalization of the proposed approach: The adaptation of the Find-Fix-Verify pattern is formalized for the problem of detecting quality issues in RDF triples. Introduction of a new crowdsourcing workflow that solely relies on microtask crowdsourcing to detect LD quality issues. Analysis of the properties of our approaches to generate microtasks for triple-based quality assessment. Empirical evaluation of the proposed workflows. Inclusion of a new empirical study by executing the state-of-the-art solution RDFUnit [27], a test-based approach to detect LD quality issues either manually or (semi-)automatically.
Structure of the paper
In Section 2, we discuss the type of LD quality issues that are studied in this work. Section 3 briefly introduces the crowdsourcing methods and related concepts that are used throughout the paper. Our approach is presented in Section 4, and is empirically evaluated in Section 5. In Section 6 we summarize the findings of our experimental study and provide answers to the formulated research questions. Related work is discussed in Section 7. Conclusions and future work are presented in Section 8.
Data quality is commonly conceived as “fitness for use” [24] for a certain application or use case. The Web of Data spans a network of data sources of varying quality. There are a large number of high-quality datasets, for instance, in the life-science domain, which are the result of decades of thorough curation and have been recently made available as Linked Data.2
For example,
Our analysis of LD quality issues focuses on DBpedia due to the diversity of the vast domain and scope of the dataset. In our previous work [59], we surveyed existing literature and identified a total of 18 data quality dimensions (criteria) applicable to LD quality assessment. We classified these dimensions into four groups: (i) intrinsic, those that are independent of the user’s context; (ii) contextual, those that highly depend on the context of the task at hand, (iii) representational, those that capture aspects related to the design of the data, and (iv) accessibility, those that involve aspects related to the access, authenticity and retrieval of data to obtain either the entire or some portion of the data (or from another source) for a particular use case. In our previous experiment [58], we identified the quality dimensions applicable to DBpedia and found that four dimensions are particularly prevalent: Accuracy, Relevancy, Representational-Consistency and Interlinking. To provide a comprehensive analysis of DBpedia quality, we further divided these four quality dimensions into 7 categories and 17 sub-categories [58].
For the purpose of this paper, from these sub-categories we chose the following three triple-level quality issues belonging to two dimensions: (i) Incorrect/incomplete object belonging to the Accuracy dimension; (ii) Incorrect datatype or language tag belonging to the Accuracy dimension; and (iii) Incorrect link belonging to the Interlinking dimension. While (i) and (ii) belong to the intrinsic group, (iii) is part of the accessibility group. These categories of quality problems were specifically chosen because, according to our previous study [58], these were highly frequent occurring problems in DBpedia (version 3.9). In particular, out of the 521 distinct resources that were evaluated, there were a total of 2,928 distinct incorrect triples identified. Of these 2,928 triples, (i) a total of 550 triples had an incorrect object, (ii) 363 triples had an incorrect datatype and (iii) 596 triples had incorrect external links. The selected quality issues are described with examples below.3
The prefix
Incorrect object values Consider the following RDF triple:
Incorrect datatype or language tag This category refers to triples with an incorrect datatype or language tag for a typed literal in the object position. For example, consider the RDF triple:
Incorrect link This category refers to RDF triples whose association between the subject and the object is incorrect. This occurs when objects do not show any related content pertaining to the subject of the triple. Erroneous interlinks can associate resources within a dataset or between several data sources. This category of quality issues also includes faulty links to external Web sites or other external data sources such as Wikipedia, Freebase, GeoSpecies, among others.
Given the diversity of situations in which the selected quality issues can be instantiated (broad range of object values and datatypes) and their semantic character, assessing them automatically is challenging. Current automatic approaches apply different mechanisms to detect various types of errors in LD datasets, for example: inconsistencies with ontological definitions [27,53], assigning missing classes to RDF resources [38], or abnormal numerical values [13,32]. Also semi-automatic solutions [27] have been proposed that rely on domain experts to specify customized rules that are tested against the dataset. Further details about these approaches and other relevant works are presented in Section 7. Although these approaches are able to reliably identify certain issues in LD, there are still a considerable amount of errors that are missed, in particular those related to semantic correctness of facts. We therefore theorize that human-based appraisal can constitute an effective solution to detect the selected quality flaws in many instances. In particular, these three quality issues require different cognitive skills in terms of evaluation, i.e., from examining the values of different attributes to identifying whether the links between two resources is appropriate. In this way, we can study whether it is feasible to evaluate these types of quality issues via crowdsourcing mechanisms where lay users can detect erroneous triples without having knowledge about the underlying RDF structure. This allows us for identifying which types of skills are most cost-effective to be employed with regards to utilizing crowdsourcing.
The term crowdsourcing was first proposed by Howe [23] and consists of a problem-solving mechanism in which a task is performed by an “an undefined (and generally large) network of people in the form of an open call”. Nowadays, many different forms of crowdsourcing have emerged, e.g., microtask, contest, macrotask, crowdfunding, among others. Each form of crowdsourcing is designed to target particular types of problems and reaching out to different crowds. Crowdsourcing tasks can be executed in a single iteration, where tasks are submitted to the crowd and the outcome is directly considered the solution of the given problem. However, in order to produce reliable results from crowds, the Find-Fix-Verify pattern has been proposed [4], in which tasks are carried out in successive verification stages. In the following we briefly describe the two crowdsourcing methods studied in this work – contest-based and microtask crowdsourcing – as well as the Find-Fix-Verify pattern.
Types of crowdsourcing employed in this work
Contest-based crowdsourcing
A contest reaches out to a crowd to solve a given problem and rewards the best ideas. In a crowdsourcing setting, contests exploit competition and intellectual challenge as main drivers for participation. The idea, originating from open innovation, has been employed in many domains, from creative industries to sciences, for tasks of varying complexity (from designing logos to building sophisticated algorithms) [31,50]. In particular, contests as means to successfully involve experts in advancing science have a long-standing tradition in research, e.g., the Darpa challenges5
We applied this contest-based model in the ‘DBpedia Evaluation Campaign’7
This form of crowdsourcing is applied to problems which can be broken down into smaller units of work (called ‘microtasks’) [23]. Microtask crowdsourcing works best for tasks that rely primarily on basic human abilities, such as audio and visual cognition or natural language understanding, and less on acquired skills (such as subject-matter knowledge).
To be more efficient than traditional outsourcing (or even in-house resources), microtasks need to be highly parallelized. This means that the actual work is executed by a high number of contributors in a decentralized fashion.8
More complex workflows, though theoretically feasible, require additional functionality to handle task dependencies.
In our work, we used microtask crowdsourcing as a fast and cost-efficient way to examine the three types of DBpedia errors described in Section 2. We provided specific instructions to workers about how to perform each microtask according to the type of studied quality issues. We reached out to the crowd of the microtask marketplace Amazon Mechanical Turk (MTurk). In the following we present a summary of the relevant MTurk terminology:9
Requester: User that submits tasks to the platform (MTurk).
Human Intelligence Task (HIT): Work unit in MTurk and refers to a single microtask. A HIT is a self-contained task submitted by a requester.
Worker: Human contributor who solves HITs.
Assignments: Number of different workers to be assigned to solve each HIT. This allows for collecting multiple answers for each question. A worker can solve a HIT only once.
Question: A HIT can be composed of several questions. In the remainder of this paper, we refer to task granularity as the number of questions contained within a HIT.
Payment: Monetary reward granted to a worker for completing a HIT successfully. Payments are defined by the requester, taking into consideration the complexity of the HIT, mainly defined as the time that workers have to spend to solve the task.
Qualification type or worker qualification: Requesters may specify parameters to prohibit certain workers to solve tasks. MTurk provides a fixed set of qualification types, including “Approval Rate” defined as the percentage of tasks solved by a worker successfully. Requesters can also create customized qualification types.
The Find-Fix-Verify pattern [4] consists in dividing a complex human task into a series of simpler tasks that are carried out in a three-stage process. Each stage in the Find-Fix-Verify pattern corresponds to a verification step over the outcome produced in the immediate previous stage. The first stage of this crowdsourcing pattern, Find, asks the crowd to identify portions of data that require attention depending on the task to be solved. In the second stage, Fix, the crowd corrects the elements belonging to the outcome of the previous stage. Lastly, the Verify stage corresponds to a final quality control iteration.
The Find-Fix-Verify pattern has proven to produce reliable results since each stage exploits independent agreement to filter out potential low-quality answers from the crowd [4]. In addition, this approach is efficient in terms of the number of questions asked to the paid microtask crowd, therefore the costs remain competitive with other crowdsourcing alternatives.
In scenarios in which crowdsourcing is applied to validate results of machine computation tasks, question filtering relies on specific thresholds or historical information about the likelihood that human input will significantly improve the results generated algorithmically. Find-Fix-Verify addresses tasks that initially can be very complex (or very large), like in our case the discovery and classification of various types of errors in DBpedia. The Find-Fix-Very pattern is highly flexible, since each stage can employ different crowds, as they require different skills and expertise [4].
Our approach: Crowdsourcing Linked Data quality assessment
Our work on human-driven Linked Data quality assessment focuses on applying crowdsourcing techniques to annotate RDF triples with their corresponding quality issue. Given a set of quality issues
(Mapping RDF Triples to Quality Issues).
Given a set
Comparison between the proposed crowdsourcing mechanisms to perform LD quality assessment
Comparison between the proposed crowdsourcing mechanisms to perform LD quality assessment
In order to provide an efficient crowdsourcing solution to the problem presented in Definition 1, we applied a variation of the crowdsourcing pattern Find-Fix-Verify [4]. As discussed in Section 3, this crowdsourcing pattern allows for increasing the overall quality of the results while maintaining competitive monetary costs when applying other crowdsourcing approaches. Our adaptation of the Find-Fix-Verify pattern consists in executing only the Find and Verify stages. The Fix stage originally proposed in the Find-Fix-Verify pattern is out of the scope of this paper, since the main goal of this work is identifying quality issues. Furthermore, our adaptation of the Find-Fix-Verify pattern is tailored to assess the quality of LD datasets that are (semi-)automatically created from other sources. Such is the case of DBpedia [30], a dataset created by extracting knowledge from Wikipedia via declarative wrappers or mappings. The DBpedia wrappers are the result of a crowdsourced community effort of contributors to the DBpedia project. When datasets are extracted via wrappers or mappings, it is highly probable that the quality issues detected for a certain triple might also occur in the set of triples that were generated with the same wrapper. Therefore, a more efficient solution to implement the Fix stage could consist of adjusting the wrappers that caused the issue in the first place, instead of crowdsourcing the correction of each triple which increases the overall monetary cost.
We devise a two-fold approach to crowdsource triple-based quality assessment of (semi-)automatically extracted LD datasets. Our approach relies on the Find and Verify stages of the Find-Fix-Verify crowdsourcing pattern. In the Find stage, the crowd is requested to detect LD quality issues in a set of RDF triples, and annotate them with the corresponding issue(s) if applicable. We define the Find stage as follows:
Given a set
The outcome of this stage – triples judged as ‘incorrect’ – is then assessed in the Verify stage, in which the crowd confirms/denies the presence of quality issues in each RDF triple processed in the previous stage. We define the Verify stage as follows:
(Verify Stage).
Given a set
In the implementation of the Find and Verify stages in our approach, we explore two different crowdsourcing workflows combining different types of crowds. The first workflow combines experts and lay users. This workflow leverages the expertise of LD experts in the Find stage, carried out as a contest, to find and classify erroneous triples according to a pre-defined quality taxonomy; workers from a microtask platform then assess the outcome of the contest in Verify stage. The second workflow entirely relies on microtask crowdsourcing to perform both the Find and the Verify stages. As discussed in Section 3, these crowdsourcing approaches exhibit different characteristics in terms of the types of tasks they can be applied to, the way the results are consolidated and exploited, and the audiences they target. Therefore, in this work we study the impact on involving different types of crowds to detect quality issues in RDF triples: LD experts in the contest and workers in the microtasks. Table 1 presents a summary of the two approaches as they have been used in this work for LD quality assessment purposes.
Figure 1 depicts the steps carried out in each of the stages of the two crowdsourcing workflows studied in this work. In the following sections, we provide more details about the implementation of the variants of the Find and Verify stages.

Studied workflows to crowdsource LD quality assessment. The first workflow combines LD experts reached via a contest with laymen from microtask crowdsourcing. The second workflow solely relies on microtask crowdsourcing.
In this implementation of the Find stage, we reached out to an expert crowd of researchers and LD enthusiasts via a contest. The tasks in the contest consisted of identifying and classifying specific types of LD quality problems in DBpedia triples. To collect the contributions from this crowd, in previous work [58], we developed a Web-based tool called TripleCheckMate10
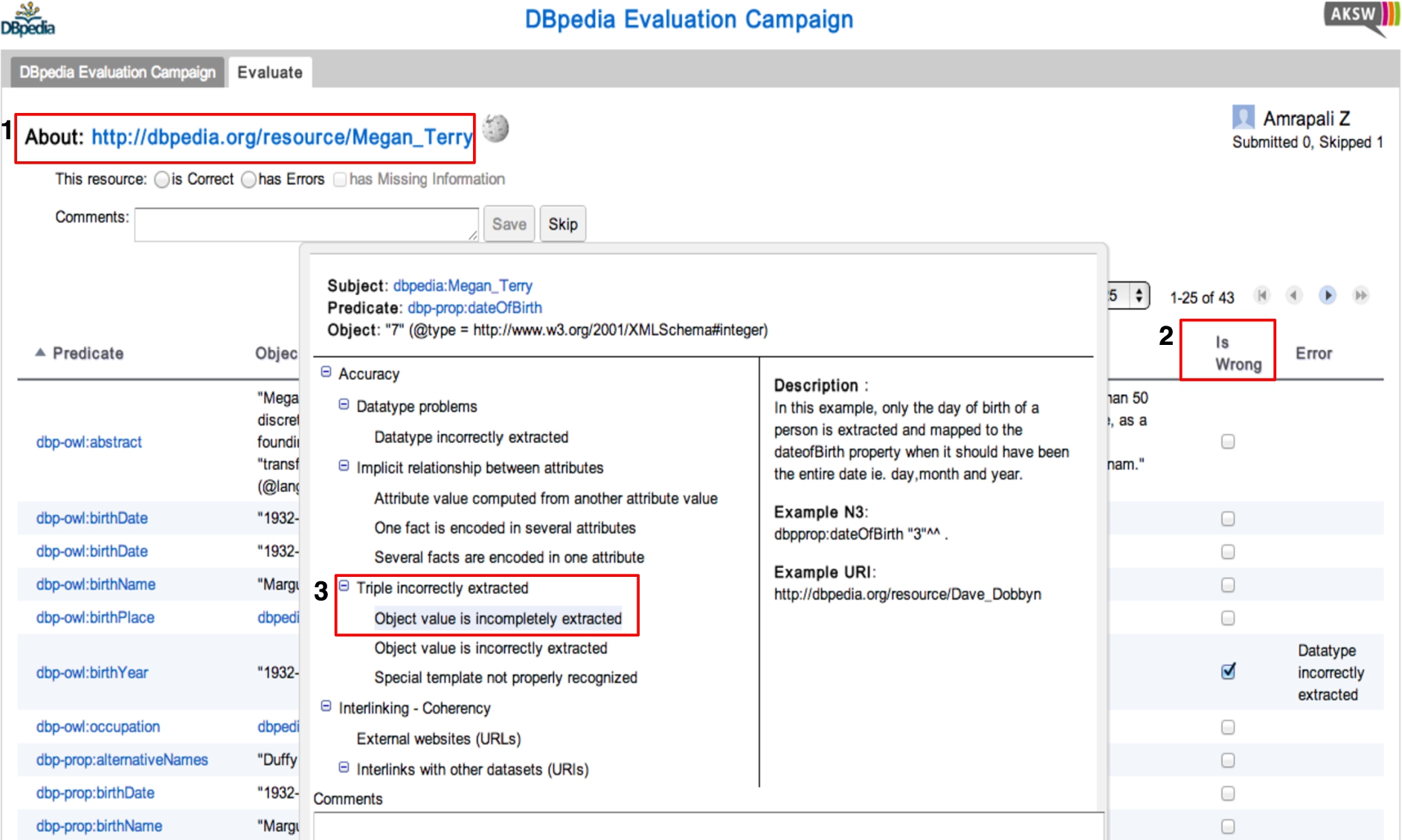
Interface of the TripleCheckMate crowdsourcing data quality assessment tool. (1) Displays the RDF resource that is currently being assessed; (2) Users can specify that a triple is erroneous by checking the box ‘Is Wrong’; (3) Users select the quality issues present in the triple from a pre-defined taxonomy, which contains a hierarchy of quality issues including detailed descriptions and examples for each issue.
The Find stage starts when a user signs into the TripleCheckMate tool to participate in the contest, as shown in Fig. 2. As a basic means to avoid spam, each user first has to login with a Google account through OAuth2. Then the user is presented with three options to choose a resource from the dataset: (i) ‘Any’, for random selection; (ii) ‘Per Class’, where a resource belonging to a particular class may be chosen; and (iii) ‘Manual’, where the user may provide a URI of a resource. Once a resource is selected following one of these alternatives, the user is presented with a table in which each row corresponds to an RDF triple of that resource. The next step is the actual quality assessment at triple level. In our implementation, the user is provided with the link to the corresponding Wikipedia page of the given resource in order to offer further information for the evaluation. If the user detects a triple containing a problem, she checks the box ‘Is Wrong’. Moreover, the user assigns specific quality problems (according to the classification devised in [58]) to erroneous triples, as depicted in Fig. 2. The user can assess as many triples from a resource as desired, or select another resource to evaluate.
The TripleCheckMate tool only records the triples that are identified as ‘incorrect’. This is consistent with the definition of the Find stage from the original Find-Fix-Verify pattern, where the crowd exclusively detects the problematic elements while the remaining data is not taken into consideration. In addition, this tool measures inter-rater agreement for RDF resources that are checked multiple times. Inter-rater agreement allows for (i) analyzing the performance of the users (as compared with each other), (ii) detecting unwanted behavior (as users are not ‘rewarded’ unless their assessments are ‘consensual’) and (iii) ensuring the quality of the assessment (i.e. when there is an agreement and several workers detect the same quality issue). The outcome of this contest corresponds to a set of triples
This Find stage applies microtasks that are solved by lay users from a crowdsourcing platform. In this variant of the Find stage we aimed at implementing a similar workflow for the crowd workers as the one provided to the LD experts. However, given that crowd workers are not necessarily knowledgeable about RDF or complex taxonomies of LD issues [44], we restricted the scope of LD quality assessment to the issues presented in Section 2. In addition, following the guidelines presented by Sarasua et al. [44], each microtask was augmented with human-readable information that could be dereferenced from RDF triples. Formally, in our approach, a microtask is defined as follows.
(Microtask for LD Quality Assessment).
A microtask m is a set of 3-tuples
Following the MTurk terminology (cf. Section 3), each 3-tuple (

Microtask Generator for Find Stage
The execution of this stage, as depicted in Fig. 1, starts by generating the microtasks from
The generated microtasks are then submitted to the crowdsourcing platform. When a worker accepts a microtask or HIT, she is presented with a table that contains triples associated to an RDF resource, as shown in Fig. 3. For each triple, the worker determines whether the triple is ‘incorrect’ with respect to the fixed set of quality issues

Interface of a microtask generated in the Find stage. (1) Displays the RDF resource that is currently assessed and also a link to the Wikipedia page of the resource; (2) Users select the corresponding quality issues present in the triple; (3) Displays contextual information: In our implementation, we extracted values from the infobox of the Wikipedia article associated with the resource – not all the properties of DBpedia resources are available in the infobox, in this case the microtask interface displays ‘Not specified’ in the Wikipedia column.
An important aspect when generating microtasks from RDF data (or machine-readable data in general) is developing useful human-understandable interfaces (Algorithm 1, line 9) for the target non-expert crowds. In microtasks, effective user interfaces reduce ambiguity as well as the probability to retrieve erroneous answers from the crowd due to a misinterpretation of the task. Therefore, before starting to resolve one of our tasks, the crowd workers were instructed with details and examples about each quality issue. After reading the instructions, workers proceed to resolve the given task. Figure 3 depicts the interface of a microtask generated for the Find stage in our approach. To display each RDF triple, we retrieved the values of the
Datatype and language tag errors do not occur simultaneously in an RDF triple and both are associated with literals in the object position. To simplify the instructions, datatypes and language tags are introduced as a single issue to workers, therefore our interfaces display “datatype” even for language tags.
Depending on the human-readable data available in the dataset, line 9 from Algorithm 1 could be implemented differently in order to provide contextual information. For constructing our microtasks, we implemented a simple wrapper which extracts data encoded in the infobox of the Wikipedia article version from which DBpedia triples were generated (depicted in the first column of Fig. 3). To do so, we crawled the Wikipedia page for the version specified via the property
The implemented wrapper could introduce certain errors in the values while parsing the Wikipedia articles’ infoboxes.
Certain predicates in DBpedia triples cannot be found in Wikipedia infoboxes, in particular predicates of RDF/S or OWL, e.g.,
Further microtask design criteria related to quality control is presented in the experimental settings (cf. Section 5.2.2). We used different mechanisms to discourage low-effort behavior which leads to random answers and to identify accurate answers.
The outcome of this stage corresponds to a set of triples

Microtask Generator for Verify Stage
In this stage, we applied microtask crowdsourcing in order to verify quality issues in RDF triples identified as problematic during the Find stage (see Fig. 1). To ensure that in this stage a proper validation is performed on each triple, the microtasks are simplified with respect to the ones from the Find stage such that: (i) each microtask focuses on a specific quality issue, and (ii) the number of triples per microtask is reduced.
The generation of microtasks in this stage is presented in Algorithm 2. This algorithm groups triples in
For instance, a low agreement value might suggest that the triple has no quality issues and hence it should not be crowdsourced. On the other hand, a high agreement value could be an indicator that the triple is indeed incorrect and no further verification is needed. Setting appropriate thresholds for agreement in
Based on the classification of LD quality issues explained in Section 2, Algorithm 2 creates three different interfaces for the microtasks. Each microtask contains the description of the procedure to be carried out to complete the task successfully. We provided workers examples of incorrect and correct triples along with four options (as shown in Fig. 1): (i) ‘Correct’; (ii) ‘Incorrect’; (iii) ‘I cannot tell/I don’t know’; (iv) ‘Data doesn’t make sense’. The third option was meant to allow users to specify when they could not provide a reliable answer. The fourth option referred to those cases in which the presented data was truly unintelligible. Furthermore, workers were not aware that the presented triples were previously identified as ‘incorrect’ in the Find stage and the questions were designed such that workers could not foresee the right answer. We describe the particularities of the microtask interfaces generated for the Verify stage in the following.
Incorrect object values In this type of task, we asked workers to evaluate whether the value of a given RDF triple is semantically correct or not. Human-readable information is displayed by dereferencing URIs of the subject and predicate of triples. In particular, we retrieved values of

Incorrect object value: The crowd must compare the DBpedia and Wikipedia values and decide whether the DBpedia entry is correct or not for a given subject and predicate.

Incorrect link: The crowd must decide whether the content of a link (indicated as “External page” in the user interface) is related to the subject. When assessing links between RDF resources, the preview of the “External page” displays the resource’s page (most of the datasets linked from DBpedia – Wikidata, YAGO – support Linked Data browsers).
In the task presented in Fig. 4(a), workers must decide whether the place of birth of
In case that DBpedia correctly extracted
An example of a DBpedia triple whose value is correct is depicted in Fig. 4(b). In this case, the worker must analyze the date of birth of
Incorrect datatypes or language tags This type of microtask consists of detecting those DBpedia triples whose object datatype or language tags were not correctly assigned. The generation of the interfaces for these tasks was very straightforward, by dereferencing the URIs of the subject and predicate of each triple and displaying the values of
In the description of the task, we introduced the concept of datatype of a value and provided two simple examples to the crowd. The first example illustrates when the language tag (
Incorrect links In this type of microtask, we asked the workers to verify whether the object of an RDF triple is associated with the subject. Incorrect subject-object associations may be due to several reasons: erroneous links referenced from Wikipedia articles, wrong associations between RDF resources (e.g., via the
Examples of this type of task are depicted in Fig. 5. In the first example (see Fig. 5(a)), workers must decide whether the content in the given external Web page is related to
Given that the contest settings are handled through the TripleCheckMate tool, in this section we expose the properties of the proposed microtask crowdsourcing approaches. First, we demonstrate that the algorithms for microtask generation in the Find and Verify stages are efficient in terms of time.
The time complexity of the microtask generators is
The algorithm of the Find stage iterates over all the triples associated with each distinct triple subject in
One important aspect when applying paid microtask crowdsourcing is the number of generated tasks, since this directly impacts the scalability of the approach in terms of the time required to solve all the tasks and the overall monetary cost. The following proposition states the complexity of Algorithms 1 and 2 in terms of the number of crowdsourced microtasks.
The number of microtasks generated in each stage is linear with respect to the number of triples assessed.
Comparison between microtask generators for the Find and Verify stages in our approach.
In the Find stage, a microtask is generated when the number of triples within task exceeds the threshold α. Since in this stage each microtask groups triples by subjects, then the number of microtasks per subject is given by
When analyzing the number of microtasks generated in each stage, the Verify stage in theory produces more tasks than the Find stage. This is a consequence of simplifying the difficulty of the microtasks in the Verify stage, where workers have to assess only one type of quality issue at the time. However, in practice, the number of microtasks generated in the Verify stage is not necessarily larger. For instance, in our experiments with LD experts and crowd workers, we observed that large portions of the triples are not annotated with quality issues in the Find stage. Since Algorithm 2 prunes triples with no quality issues (consistently with the definition of the Find-Fix-Verify pattern), the subset of triples crowdsourced in the Verify stage is considerably smaller than the original set, hence the number of microtasks to verify is reduced.
A summary of our microtask crowdsourcing approach implemented for the Find and Verify stages is presented in Table 2.
We empirically analyzed the performance of the two crowdsourcing workflows described in Section 4. The first workflow combines LD experts in the Find stage with microtask (lay) workers from MTurk in the Verify stage. The second workflow consists of executing both Find and Verify stages with microtask workers. It is important to highlight that, in the experiments of the Verify stage, workers did not know that the data provided to them was previously classified as problematic. The main goal of our experiments is studying the applicability of crowdsourcing as a solution to the problem of detecting quality issues in LD datasets. Specifically, we formulated the following research questions:
Is it feasible to detect the studied LD quality issues via crowdsourcing mechanisms?
In a crowdsourcing approach, can we employ unskilled lay users to identify the studied LD quality issues and to what extent is expert validation needed and desirable?
How can we design better crowdsourcing workflows (in terms of accuracy) using lay users or experts for detecting LD quality issues, beyond one-step solutions for pointing out quality flaws?
In addition, we executed (semi-)automatic approaches to detect quality issues which allowed us to understand the strengths and limitations of applying crowdsourcing in this scenario. We used the semi-automatic RDFUnit tool [27] for assessing ‘object value’ and ‘datatype’ issues, and implemented a simple automatic baseline for detecting incorrect ‘links’.
Experimental settings
Dataset and implementation
In our experiments, the assessed triples were extracted from the DBpedia dataset (version 3.9).17
The task in our experiments is to detect whether RDF triples are incorrect. Based on this, we define:
True Positive (
False Positive (
True Negative (
False Negative (
To measure the performance of the studied crowdsourcing approaches (contest and microtasks), we report on:
Inter-rater agreement computed with the Fleiss’ kappa [14] metric to measure the consensus degree between raters (experts or MTurk workers).
Precision to measure the proportions of positive results of each crowd, computed as
Sensitivity to measure the true positive rate, computed as
Specificity to measure the true negative ratio, computed as
The inter-rater agreement of the experts is reported by TripleCheckMate for the overall results of the contest in the Find stage. Therefore, we also report on the inter-rater agreement of the overall results for microtask workers in the Find stage. Inter-rater agreement is computed per quality issue for the Verify stages.
Precision values were computed for all stages of the studied workflows with respect to the gold standard explained below. In our Find stages, the crowd – expert or layman – was not enquired for annotating triples as ‘correct’ (in conformance with the definition of the Find-Fix-Verify pattern [4]); i.e., the outcome of our Find stages does not contain true or false negatives. Therefore, sensitivity and specificity values were computed only for the Verify stages.
Gold standard
Two of the authors of this paper (MA, AZ) generated a gold standard for two samples of the crowdsourced triples. To generate the gold standard, each author independently evaluated the triples. After an individual assessment, the raters compared their results and resolved conflicts via mutual agreement. The first sample evaluated contains 1,073 triples that corresponds to the set of triples obtained from the contest in the experts’ Find stage and submitted to MTurk. The inter-rater agreement between the authors for this first sample was 0.4523 for object values, 0.5554 for datatypes/language tags, and 0.5666 for interlinks. For the second sample, we analyzed a subset of 1,073 triples that have been identified in the Find stage by the crowd as ‘incorrect’. This subset has the same distribution of triples per quality issues as the one assessed in the first sample: 509 triples for object values, 341 for datatypes/language tags, and 223 for interlinks. We measured the inter-rater agreement for this second sample and was 0.6363 for object values, 0.8285 for datatypes, and 0.7074 for interlinks. The inter-rater agreement values were calculated using the Cohen’s kappa measure [9], designed for measuring agreement among two annotators. Disagreement arose in the object of triples where number values are rounded up to the next integer number. For example, the course length of the
The tools used in our experiments and the results are available online, including the outcome of the contest,19
Contest settings: Find stage
The contest was open from November to December in 2012, and was configured as follows.
Microtask settings: Verify stage
The microtasks for this experiment were submitted to MTurk in May 2013 using the following settings.
Overall results in each type of crowdsourcing approach in the expert-worker crowdsourcing workflow: Combining LD experts (Find stage) and microtask workers (Verify stage)
Overall results in each type of crowdsourcing approach in the expert-worker crowdsourcing workflow: Combining LD experts (Find stage) and microtask workers (Verify stage)
Inter-rater agreement and metrics (computed against the gold standard) achieved in the expert-worker crowdsourcing workflow: Combining LD experts (Find stage) and microtask workers (Verify stage)
The contest was open for a predefined period of time of three weeks. During this time, 58 LD experts analyzed 521 distinct DBpedia resources and we determined that the experts browsed around 33,404 triples. They detected a total of 1,512 triples as erroneous and classified them using the given taxonomy. After obtaining the results from the experts, we filtered out duplicates and triples whose objects were broken links. In total, we submitted 1,073 triples to the crowd. A total of 80 distinct workers assessed all the RDF triples in four days. The average time per microtask spent by the crowd was 94.55 sec. for incorrect objects, 71.69 sec. for incorrect datatypes or language tags, and 116.11 sec. for incorrect links. We then computed the effective hourly rate per type of task: 1.52 US$ for incorrect values, 2.01 US$ for incorrect datatypes or language tags, and 1.24 US$ for incorrect links. A summary of these observations is shown in Table 3.
We compared the common 1,073 triples assessed in each crowdsourcing approach against our gold standard and measured inter-rater agreement as well as precision, sensitivity, and specificity values for each task (see Table 4). For the contest-based approach, the tool allowed two participants to evaluate a single resource. In total, there were 268 inter-evaluations for which TripleCheckMate calculated triple-based inter-agreement (adjusting the observed agreement with agreement by chance) to be 0.38. For the microtasks, for each type of task we measured the inter-rater agreement values among a maximum of five workers using Fleiss’ kappa measure. While the inter-rater agreement between workers for the link task was high (0.7396), the ones for object and datatype tasks were moderate to low with 0.5348 and 0.4960, respectively. Table 4 reports on the precision achieved by the LD experts and crowd in each stage. In the following we present further details on the results for each type of task.
Results: Incorrect object values
As reported in Table 4, our crowdsourcing experiments reached a precision of 0.8977 for MTurk workers (majority voting) and 0.7151 for LD experts. Most of the incorrect values that are extracted from Wikipedia occur with predicates related to dates, for example:
In DBpedia, the property
Wikipedia page version from which this data was extracted:
Furthermore, crowd workers obtained higher values of sensitivity than specificity (0.8899 vs. 0.7482 in majority voting) in both microtask settings. This suggests that workers perform better when detecting incorrect values (true positives) than correct values (true negatives) in RDF triples.

Results for the “Incorrect datatype/language tag” task in the first crowdsourcing workflow (combining experts and crowd workers).
As shown in Table 4, both crowdsourcing mechanisms achieved high values of precision: 0.8270 precision for experts on finding this type of quality issue, while the crowd achieved 0.9116 precision on verifying these triples. However, a closer inspection to the results revealed that the crowd generated a large number of false negatives, obtaining low sensitivity values (0.4802 with majority voting). In particular, the first answers submitted by the crowd were slightly better in terms of sensitivity than the results obtained with majority voting. A detailed study of these cases showed that 28 triples that were classified correctly in the first answer from the crowd, later were misclassified, and most of these triples refer to a language tag. The low performance of the MTurk workers in terms of sensitivity is not surprising, since this particular task requires certain technical knowledge about datatypes and their specification in RDF.
In order to understand the previous results, we analyzed the performance of experts and workers at a more fine-grained level. We calculated the frequency of occurrences of datatypes and language tags in the assessed triples (see Fig. 6(a)) and reported on precision, sensitivity, and specificity achieved by the crowdsourcing methods per datatype or language tag. Figure 6(b) depicts these results. The most notorious result in this task is the assessment performance for the datatype “number”. The experts effectively identified triples where the datatype was incorrectly assigned as “number”,23
This error is very frequent when extracting dates from Wikipedia as some resources only contain partial data, e.g., only the year is available and not the whole date.
While looking at the language-tagged strings in “English” (in RDF
Table 4 displays the precision for each studied quality assessment mechanism. The extremely low precision of 0.1525 of the contest’s participants was unexpected. We inspected in detail the 189 misclassifications of the experts:
The 95 Freebase links24
There were 77 triples whose objects were Wikimedia uploads (composed mostly by images hosted for Wikipedia); 74 of these triples were also classified incorrectly. Within the 74 misclassified triples, the images of 21 triples directly depict the triple subject. In 30 triples, the subjects correspond to geographical entities, and the images correctly depicted either maps (12 triples), landscapes (12 triples), or their corresponding coat of arms (6 triples). In another 13 triples, the images depicted examples of abstract concepts.25
For instance,
{kind=link}
For instance,
As of January 2016.
20 links (to blogs, Web pages, etc.) referenced from the Wikipedia article of the subject were also misclassified, regardless of the language of the content in the Web page. Furthermore, 16 out of these 20 links are still present in the corresponding Wikipedia articles.28 Only 3 links has slightly changed over time but they were correctly extracted from the Wikipedia articles.
On the other hand, MTurk workers achieved high values in both settings, in particular when applying majority voting: 0.7674 for precision, 0.9705 for sensitivity, and 0.9450 for specificity, as shown in Table 4. The links that were not properly classified by the crowd correspond to Web pages whose content is in a different language than English or, despite they are referenced from the Wikipedia article of the subject, their association with the subject is not straightforward. Examples of these cases are the following subjects and links: the resource
Microtask settings: Find and Verify stages
The microtasks crowdsourced in the Find stage were submitted to MTurk in February 2014 and configured as follows.
Overall results in the worker-worker crowdsourcing workflow: Employing microtask workers in both stages Find and Verify
Overall results in the worker-worker crowdsourcing workflow: Employing microtask workers in both stages Find and Verify
All triples identified as erroneous by at least two workers in the Find stage were candidates for crowdsourcing in the Verify stage. The microtasks generated in the subsequent stage were crowdsourced in February 2014 with the exact same configurations used in the Verify stage from the first workflow (cf. Section 5.2.2).
In order to replicate the approach followed in the contest, we crowdsourced in the Find stage all the triples associated with resources that were explored by the LD experts. In total, we submitted to the crowd 33,404 RDF triples and the crowd processed 30,658 triples in 14 days. The microtasks from the Find stage were resolved by 187 distinct workers in 83.29 secs. on average at an hourly rate of 2.59 US$. In total, 26,835 triples were identified as erroneous, and classified into the three quality issues studied in this work. Then, we selected random samples from triples identified as erroneous in the Find stage from the crowd using majority voting. For sampling, we used the same distribution obtained from the first experiment, i.e., each sample contains the exact same number of triples that were crowdsourced in the Verify stage in the first workflow. This allowed us to compare the outcome of the Verify stage from both workflows. We crowdsourced then 509 triples for the task of incorrect values, 341 for incorrect datatype or language tag, and 223 for incorrect links. All triples crowdsourced in the Verify Stage were assessed by 141 distinct workers in seven days. On average, workers spent 95.59 sec. on resolving a microtask for detecting incorrect values, 53.05 sec. on a microtask for incorrect datatypes or language tags, and 131.48 sec. on a microtask for assessing incorrect links. The effective hourly rates in each type of task were: 1.51 US$ for assessing object values, 2.71 US$ for assessing datatypes or language tags, and 1.10 US$ for assessing links. For the incorrect object and incorrect datatype or language tag tasks, all submitted microtasks were finished in the first two days. Regarding the incorrect link tasks, 86% of the microtasks were resolved within four days (consistently with the behavior observed in the first experiment), and the remaining 14% of these tasks were completed after seven days of the beginning of the experiment. A summary of these results and further details are presented in Table 5.
Similar to the first experiment, we measured the inter-rater agreement achieved by the crowd in both stages using the Fleiss’ kappa metric. In the Find stage the inter-rater agreement of workers was 0.2695, while in the Verify stage, the crowd achieved substantial agreement for all the types of tasks: 0.6300 for object values, 0.7957 for data types or language tags, and 0.7156 for links. In comparison to the first workflow, the crowd in the Verify stage achieved higher agreement. This suggests that triples identified as erroneous in the Find stage were easier to interpret or process by the crowd. Table 6 reports the precision achieved by the crowd in each stage as well as sensitivity and specificity values for the Verify stage. It is important to notice that in this workflow we crowdsourced all the triples that could have been explored by the LD experts in the contest. In this way, we evaluate the performance of lay user and experts under similar conditions. During the Find stage, the crowd achieved low values of precision for the three types of tasks, which suggests that this stage is still very challenging for lay users. In the following we present further details on the results for each type of task.
Inter-rater agreement and metrics (computed against the gold standard) achieved in the worker-worker crowdsourcing workflow: Employing microtask workers in both stages Find and Verify
Inter-rater agreement and metrics (computed against the gold standard) achieved in the worker-worker crowdsourcing workflow: Employing microtask workers in both stages Find and Verify
In the Find stage, the crowd achieved a precision of 0.3713 for identifying ‘incorrect values’, as reported in Table 6. In the following we present relevant observations derived from this evaluation:
46 false positives were generated for triples with predicates corresponding to
22 triples identified as ‘incorrect’ by the crowd encode metadata about the DBpedia extraction framework via predicates like
DBpedia triples whose predicates are defined as “Reserved for DBpedia” should not be modified, since they encode special metadata generated during the extraction process.
In 24 false positives, the human-readable information (label) extracted for triple predicates were not entirely comprehensible, e.g.,
14 triples encoding geographical coordinates via the predicates
Prefixes

Results for the “Incorrect datatype/language tag” task in the worker-worker crowdsourcing workflow (crowd workers in both stages).
The crowd in the Verify stage achieved similar precision for both settings ‘first answer’ and ‘majority voting’, with values of 0.4980 and 0.5072, respectively. The crowd generated a large number of false positives (170 in total), therefore, the values of specificity achieved in both settings were not high. Moreover, for the setting ‘majority voting’, the value of sensitivity was 0.9615. Errors from the first iteration were reduced in the Verify stage, especially in triples with predicates
In this type of task, from the analyzed sample of triples we observed that the crowd in the Find stage focused on assessing triples whose objects correspond to language-tagged literals. Figure 7(a) shows the distribution of the datatypes and language tags in the sampled triples processed by the crowd. Out of the 341 analyzed triples, 307 triples identified as ‘erroneous’ in this stage were annotated with language tags. As reported on Table 6, the crowd in the Find stage achieved a precision of 0.1466, being the lowest precision achieved in all the microtask settings. Most of the triples (72 out of 341) identified as ‘incorrect’ in this stage were annotated with the English language tag. We corroborated that false positives in other languages were not generated due to malfunctions of the HIT interface: Microtasks were properly displaying UTF-8 characters used in several languages in DBpedia, e.g., Russian, Japanese, Chinese, among others.
In the Verify stage of this type of task, the crowd outperformed the precision of the Find stage, achieving values of 0.5510 for the ‘first answer’ setting and 0.8723 with ‘majority voting’. This major improvement on the precision put in evidence the importance of having a multi-validation pattern like Find-Fix-Verify in which initial errors can be reduced in subsequent iterations. For the ‘majority voting’ setting, the crowd achieved high values for sensitivity (0.9111) and specificity (0.9793) by correctly detecting true positives and true negatives. Congruent with the behavior observed in the first workflow, MTurk workers performed well when verifying language-tagged literals. Furthermore, the high values of inter-rater agreement confirm that the crowd is consistently good in this particular scenario. Figure 7(b) depicts per datatype and language tag the values for precision for both stages as well as sensitivity and specificity values for the ‘majority voting’ setting. We can observe that the crowd is exceptionally successful in identifying correct triples (true negatives) in the Verify stage that were classified as incorrect in the previous stage. This is confirmed by the high values of specificity achieved by the crowd among all the analyzed datatypes/language tags. A closer inspection to the six false positives revealed that in three cases the crowd misclassified triples whose object is a proper noun with no translation into other languages, for instance,
Results: Incorrect links
From the studied sample, the majority of the triples classified as ‘incorrect link’ in the Find stage contained objects that correspond to RDF resources. We analyzed in detail the characteristics of the 169 misclassified triples by the crowd in this stage:
Out of the 223 triples analyzed, the most popular predicate corresponds to
YAGO URIs in DBpedia usually consist of a name and some numerical characters.
35 of the false positives in this stage correspond to triples whose objects are external Web pages.
The predicates of the rest of the misclassified triples correspond to
In the Find stage, the crowd achieved similar values of precision in both settings ‘first answer’ and ‘majority voting’. Furthermore, in this stage the crowd achieved higher precision (0.3442 for ‘majority voting’) than in the Find stage. The ‘majority voting’ setting obtained 1.0000 for sensitivity, since workers did not produce false negatives, i.e., workers did not classify incorrect triples as correct. Another important result is exhibited by the metric specificity; low values of specificity in this task confirms that the crowd has difficulties when processing triples that are correct, thus, generating a large portion of false positives.
In the Verify stage, from the 167 RDF triples with predicate
We took the same set of resources from DBpedia that were assessed in the crowdsourcing experiments, and executed (semi-)automatic approaches for each studied quality issue. The goal of this study is to gain insights about the type of inconsistencies or errors that can be detected (semi-)automatically, and in which cases human contributions are still beneficial. The obtained results are discussed in the following.
Object values, datatypes, and literals
We used the Test-Driven Quality Assessment (TDQA) methodology [27] as our main comparison approach to detect incorrect object values, datatypes and language tags. TDQA is inspired from test-driven development and proposes a methodology to define (i) automatic, (ii) semi-automatic and (iii) manual test cases based on SPARQL queries. Automatic test cases are generated based on schema constraints. The methodology suggests the use of semi-automatic schema enrichment that, in turn, will generate more automatic test cases. Manual test cases are written by domain experts and can be based either on a test case pattern library, or manually specified as SPARQL queries.
RDFUnit32
In these experiments, we re-used the same setup for DBpedia used by Kontokostas et al. [27], but excluding 830 test cases that were automatically generated for
Schema prefixes as defined in Linked Open Vocabularies (
From the 5,146 total test cases, only 138 failed and returned a total of 765 individual validation errors. Table 7 aggregates the test case results and violation instances based on the generation type. Although the enrichment based test cases were generated automatically, we distinguish them from those automatic test cases that were based on the original schema.
Summary of RDFUnit test cases: Aggregation of errors over 850 triples
Aggregation of errors detected with RDFUnit. We provide the pattern, the number of failed test cases per pattern (F. TCs) along with the total violation instances (Total) and based on the test case generation type: automatic (Aut.), enriched (Ern.) and manual (Man.)
In Table 8, we aggregate the failed test cases and the total instance violations based on the patterns the test cases were based on. Most of the errors originated from ontological constraints such as functionality, datatype and domain violations. Common violation instances of ontological constraints were multiple birth/death dates and population values, datatype of
The person height range test resulted in 51 violations. This test case was manually specified as a SPARQL query and is not presented in Table 8. The test case checked whether a person’s height is between 0.4 and 2.5 meters. In this specific case, the unit was meters and the values were extracted as centimeter. Thus, although the results appeared semantically valid to a user, they were actually wrong.
Number and the types of links present in the dataset verified by the experts in the contest
A complete direct comparison with our crowdsourcing results was not possible except for 85 wrong datatypes and 13 failed regular expressions34
E.g., the ISBN value in the triple
And this is very common case for the DBpedia namespace
The results of automatically evaluating RDFUnit elucidate the type of inconsistencies or errors that can be identified exploiting the constraints encoded in ontologies. To detect further logical inconsistencies, RDFUnit relies on domain experts to define custom rules, as in our simple example of human height measurements. Still, semantic correctness of triples cannot always be specified as ontology constraints and therefore might require human judgment. In these cases, crowdsourcing mechanisms can be used in combination with tools like RDFUnit to provide more comprehensive solutions for LD quality assessment.
We implemented a simple baseline that dereferenced, for each triple, the object of the triple. The baseline then searched for occurrences of the
From each Verify stages, 223 links were retrieved. As a result of running this baseline, we detected a total of 161 and 128 links that were not detected to have the title of the resource in the external Web page (link) in the first and second stage respectively. That is, only 48 (in the case of the expert-worker workflow) and 54 (in the case of the worker-worker workflow) of the total 223 links each were detected to be correct by this automatic approach. A precision of 0.2296 and 0.2967 was obtained by the baseline for each of the stages. Thus, the presented baseline illustrated that although some links can be excluded from human judgement, the majority of the examined links could not be properly assessed using naive solutions.
Final discussions
Referring back to the research questions formulated in Section 5, our experiments let us identify the strengths and weaknesses of applying crowdsourcing mechanisms for assessing the studied data quality issues, adapting the Find-Fix-Verify pattern. Regarding the precision achieved in both workflows, we compared the outcomes produced in each stage by the different crowds against a manually defined gold standard. The precision reached by both crowds showed that crowdsourcing is a feasible solution to detect the studied LD quality issues in DBpedia
In each type of task, the LD experts and MTurk workers applied different skills and strategies to solve the assignments successfully
Furthermore, we were able to detect common cases in which none of the two forms of crowdsourcing we studied seemed to be feasible. The most problematic task for the LD experts was the one about discerning whether an external link was related to an RDF resource. Although the experimental data did not provide insights into this behavior, we are inclined to believe that this was due to the relatively higher effort required by this specific type of task, which involved checking an additional site outside the TripleCheckMate tool. Although the crowd outperformed the experts in finding incorrect ‘links’, the MTurk crowd was not sufficiently capable of assessing links that correspond to RDF resources. Furthermore, MTurk workers did not perform so well on tasks about datatypes where they recurrently confused numerical datatypes with time units.
The observed results suggest that LD experts and crowd workers offer complementary strengths that can be exploited not only in different assessment iterations or stages (
One of the goals of our work is to investigate how the contributions of crowdsourcing approaches can be integrated into automatic LD curation processes, by evaluating the performance of two crowdsourcing workflows in a cost-efficient way. In microtask settings, the first challenge is then to reduce the amount of tasks submitted to the crowd and the number of requested assignments (different answers), since both of these factors determine the overall cost of crowdsourcing projects. For the Find stage, Algorithm 1 generated 2,339 HITs to crowdsource 68,976 RDF triples, consistently with the property stated by Proposition 2. In our experiments, we approved a total of 2,294 assignments in the Find stage and, considering the payment per HIT (US$ 0.06), the total cost of this evaluation resulted in US$ 137.58. Furthermore, in the Verify stage, the cost of submitting to MTurk the problematic triples found by the experts was only US$ 43.
In summary, our experimental results confirm that crowdsourcing-based workflows are a feasible solution for detecting the studied LD quality issues. However, since triples are assessed individually, the scalability of the approach is compromised when issuing large datasets. Therefore, we consider that our proposed approach could reach its full potential when it is combined with automatic approaches in two ways: i) Automatic approaches can help to significantly reduce the number of triples that resort to crowdsourcing; ii) The outcome of the crowd can be used as training sets consumed by automatic approaches to detect quality issues in further portions of a given LD dataset. Building hybrid human-machine architectures will allow for devising efficient and effective solutions for LD quality assessment able to scale up to large datasets.
Related work
We focus on investigating two types of related work: crowdsourcing in Linked Data management and Web data quality assessment.
Crowdsourcing in Linked Data management
There is wide agreement in the community that specific aspects of Linked Data management are inherently human-driven [3]. This holds true most notably for those Linked Data tasks which require a substantial amount of domain knowledge or detailed, context-specific insight that go beyond the assumptions and natural limitations of algorithmic approaches.
Like any Web-centric community of its kind, Linked Data has had its share of volunteer initiatives, including the Linking Open Data Cloud itself and DBpedia [6], and competitions such as the yearly Semantic Web Challenge36
From a process point of view, Villazón-Terrazas and Corcho [55] introduced a methodology for publishing Linked Data. The authors discussed activities, which theoretically could be subject to crowdsourcing, but did not discuss such aspects explicitly. Similarly, Luczak-Rösch et al. [33] mapped ontology engineering methodologies to Linked Data practices, drawing on insights from interviews with practitioners and quantitative analysis. A more focused account of the use of human and crowd intelligence in Linked Data management is offered in the work by Siorpaes and Simperl [49]; the authors investigated several technically oriented scenarios in order to identify lower-level tasks and analyze the extent to which they can be feasibly automated. In this context, feasibility referred primarily to the trade-off between the effort associated with the usage of a given tool targeting automation – including aspects such as getting familiar with the tool, but more importantly creating training datasets and examples, configuring the tool and validating (intermediate) results – and the quality of the outcomes. The fundamental question the work by Siorpaes and Simperl [49] attempted to answer was related to ours, though not focused on quality assurance and repair – their aim was come up with patterns for human and machine-driven computation, which could service semantic data management scenarios effectively. This was also at the core of the work by Simperl et al. [47], which took the main findings of this analysis a step further and proposed a methodology to build incentivized Semantic Web applications, including guidelines for mechanism design which are compatible to our Find-Verify workflow. They have also analyzed motivations and incentives for several types of Semantic Web tasks, from ontology population to semantic annotation.
An important prerequisite to any participatory exercise is the ability of the crowd – experts or laymen – to engage with the given data management tasks. This has been subject to several user experience design studies [25,40,45,46,54], which informed the implementation of our crowdsourcing projects, both the contest, and the paid microtasks running on Amazon Mechanical Turk. For instance, microtasks have been used for entity linking in ZenCrowd [10], entity resolution in CrowdER [57], ontology alignment in CrowdMap [43] and completing missing values in RDF data in HARE [1].
At a more technical level, many Linked Data management tasks have already been subject to human computation, be that in the form of Games With a Purpose (GWAP) [34,51,56] or, closer to our work, paid microtasks. GWAP, which capitalize on entertainment, intellectual challenge, competition, and reputation, offer another mechanism to engage with a broad user base. In the field of semantic technologies, the OntoGame series [48] propose several games that deal with the task of data interlinking, be that in its ontology alignment instance (SpotTheLink [51]), multimedia interlinking (SeaFish [52]) or spotting inconsistencies in data (WhoKnows? [56]). Similar ideas are implemented in GuessWhat?! [34], a selection-agreement game which uses URIs from DBpedia, Freebase and OpenCyc as input to the interlinking process. While OntoGame looks into game mechanics and game narratives and their applicability to finding similar entities and other types of correspondences, our research studies an alternative crowdsourcing strategy that is based on a contest and financial rewards in a microtask platform. Most relevant for our work are the experiments comparing games with a purpose and paid microtasks, which showed the complementarity of the two forms of crowdsourcing [12,42].
A similar study is discussed in the work by McCann et al. [35] for ontology alignment. This work investigated a combination of volunteer and paid user involvement to validate automatically generated alignments formulated as natural language questions. While this proposal shares many commonalities with the CrowdMap [43] approach, the evaluation of their solution is based on a much more constrained experiment that did not rely on a real-world labor marketplace and associated work force.
Also in the context of Linked Data management, a human-enabled approach to execute queries against RDF datasets has been proposed. Acosta et al. presented HARE [1], a hybrid SPARQL query processing engine to enhance the quality of query answers. HARE relies on microtask crowdsourcing to complete missing values that are detected during query execution. Experimental results of HARE confirmed that laymen are able to assess RDF data from diverse knowledge domains including Life Sciences. While HARE focuses on data completeness, our approach is tailored for assessing quality issues that affect data accuracy.
Existing frameworks for quality assessment of the Web of Data, including Linked Data, can be broadly classified as automated [13,18,19,32,37,38], semi-automated [8,15,29,53] and manual [5,36].
In particular, regarding the quality issues studied in our work, the approach presented by Guéret et al. [19] performs quality assessment on link sets in an automated fashion based on a set of quality metrics. However, this approach does not take the semantics of the links into account. On the other hand, the framework SWIQA proposed by Fürber and Hepp [18] can be applied for detecting accuracy quality issues including incorrect object values, datatypes and literals. However, these approaches either lack specific syntactical rules to detect all of the errors and require knowledge of the underlying schema by the user to specify these rules. Other automatic solutions rely on clustering or statistical-based algorithms to detect different quality issues in LD sets [13,32,37,38]. Fleischhacker et al. [13] proposed a two-fold approach that relies on unsupervised outlier detection methods to identify numerical errors in objects of RDF triples. Similarly, Li et al. [32] presented a probabilistic framework that predicts arithmetic relations (equal, greater than, less than) between multiple RDF predicates in order to detect inconsistencies in numerical and date values. Other works have also proposed automatic approaches to improve the quality of LD in terms of completeness and accuracy. In this regard, Paulheim and Bizer presented two algorithms SDType [37,38] and SDValidate [38] that rely on statistical distributions of predicates and objects in RDF datasets. SDType predicts classes of RDF resource thus completing missing values of
Semi-automatic approaches to tackle quality assessment have been also proposed. Flemming [15] provides a form-based interface where users can specify the SPARQL endpoint and exemplary URIs of the dataset to obtain an overall quality score of the dataset. However, in this case, the results are difficult to interpret and require the user to specify different weights for different quality metrics at each step of the assessment, which makes it challenging especially when users may not know the dataset in much detail. CROCUS [8] is a clustering-based framework that identify outliers at ontologies’ instance-level to detect inconsistencies in LD sets. Outliers are then assessed by non-experts denominated quality raters. CROCUS is able to detect violations in cardinality constraints or value ranges. In the context of ontology enriching, Lehmann and Bühmann presented ORE [29], a tool to detect ontology modeling problems. ORE implements reasoning as well as semi-automatic supervised learning to provide suggestions to users (knowledge engineers) for enriching ontologies. Töpper et al. [53] proposed an approach to enrich ontologies with class disjointness as well as property domain and range restrictions. The latter approach is able to detect semantic errors that cannot be detected with syntactic validators or reasoners. The outcome of this approach is a set of suggestions to correct inconsistencies that are processed manually. Except for CROCUS, these solutions [29,53] require either domain or ontology experts since implementing changes in ontological constructs could generate further inconsistencies. Unlike the solutions previously described, our approach is tailored to assess the semantic correctness of RDF triples.
In case of manual assessment methodologies or frameworks, the WIQA quality assessment framework [5] consists of a set of software components for filtering information from the Web using a range of different filtering policies or metrics. In case of Sieve [36], the definition of metrics has to be done by creating an XML file, which contains specific configurations for a quality assessment task. Even though these frameworks introduce useful methodologies to assess the quality of a dataset, the results are difficult to interpret and mandate a considerable amount of user prior knowledge and involvement.
Other studies analyzed the quality of Web [7] and RDF [21] data. The latter study focuses on errors occurred during the publication of LD datasets. Furthermore, a study by Hogan et al. [22] looked into four million RDF/XML documents to analyze Linked Data conformance. These studies performed large-scale quality assessment on LD but are often limited in their ability to produce interpretable results, demand user expertise or are bound to a given dataset.
SPARQL Inferencing Notation (SPIN)38
In summary, our work is situated at the intersection of the previously discussed research areas. In Section 7.1, we explained how crowdsourcing in various forms, e.g., contests, games with a purpose, microtasks, have been successfully applied to resolve diverse aspects of LD management. However, our work studies novel applications of crowdsourcing to detect specific LD quality issues with crowds composed by experts and non-experts. Furthermore, unlike the solutions presented in Section 7.2 for assessing the quality of Web Data, our approach solely relies on human intervention to detect semantic errors in LD.
In this paper, we proposed and compared crowdsourcing mechanisms to evaluate the quality of Linked Data (LD); the study was conducted in particular on the DBpedia dataset. Two different types of crowds and mechanisms were investigated for the initial detection of quality issues: object values, datatypes and language tags, and links. We focused on adapting the Find-Fix-Verify crowdsourcing pattern to exploit the strengths of experts and lay workers and leverage the results from the Find-only approaches.
For the first part of our study, the Find stage was implemented with a contest to engage with a community of LD experts. The task of the contest consists in discovering and classifying quality issues of DBpedia resources using the TripleCheckMate tool. Contributions obtained through the contest (referring to flawed object values, incorrect datatypes or language tags, and incorrect links) were submitted to Amazon Mechanical Turk (MTurk), where we asked workers to Verify them. For the second part of our study, only microtask crowdsourcing was used to perform the Find and Verify stages on the same set of DBpedia resources used in the first part.
The evaluation of the results showed that it is feasible to crowdsource the detection of the studied LD issues in DBpedia. In particular, the experiments revealed that (i) lay workers are in fact able to detect certain quality issues with satisfactory precision; (ii) experts perform well in identifying triples with ‘object value’ or ‘datatype’ issues, and lastly, (iii) the two approaches reveal complementary strengths. The empirical results of our experiments could serve as a base for further studies in the area of LD quality assessment using human computation. Our findings could also inform the design of the DBpedia extraction tools and related community processes, which already make use of contributions from volunteers to define the underlying mapping rules in different languages.
The methodology proposed in this work is applicable to other LD datasets and can be expanded to cover different types of quality issues. The TripleCheckMate tool can be configured to assess any LD dataset using different taxonomies of quality issues. In addition, the proposed algorithms to generate microtasks can also be adapted to build different user interfaces that assist workers in assessing further LD issues. However, the scope of our empirical observations is circumscribed to the studied quality issues within DBpedia.
Finally, as with any form of computing, our work will be most useful as part of a broader architecture, in which crowdsourcing is brought together with automatic quality assessment and repair components and integrated into existing data governance frameworks.
Future work will first focus on conducting new experiments to test the value of the crowd for further different types of quality problems as well as for different LD sets from other knowledge domains. In the longer term, we will also investigate on how to efficiently integrate crowd contributions – by implementing the Fix stage – into hybrid human-machine curation processes and tools, in particular with respect to the trade-offs of costs and quality between manual and automatic approaches. Another area of research is the integration of baseline approaches before the crowdsourcing step in order to filter out errors that can be detected automatically to further increase the productivity of the crowd.
Acknowledgements
This work was supported by grants from the European Union’s 7th Framework Programme provided for the projects GeoKnow (GA no. 318159), Aligned (GA no. 644055) and LOD2 (GA no. 257943).