
Abstract
This article provides a comprehensive and up-to-date survey of models and vocabularies for creating linguistic linked data (LLD) focusing on the latest developments in the area and both building upon and complementing previous works covering similar territory. The article begins with an overview of some recent trends which have had a significant impact on linked data models and vocabularies. Next, we give a general overview of existing vocabularies and models for different categories of LLD resource. After which we look at some of the latest developments in community standards and initiatives including descriptions of recent work on the OntoLex-Lemon model, a survey of recent initiatives in linguistic annotation and LLD, and a discussion of the LLD metadata vocabularies META-SHARE and lime. In the next part of the paper, we focus on the influence of projects on LLD models and vocabularies, starting with a general survey of relevant projects, before dedicating individual sections to a number of recent projects and their impact on LLD vocabularies and models. Finally, in the conclusion, we look ahead at some future challenges for LLD models and vocabularies. The appendix to the paper consists of a brief introduction to the OntoLex-Lemon model.
Keywords
Introduction
The growing popularity of linked data, and especially of linked open data (that is, linked data that has an open license), as a means of publishing language resources (lexica, corpora, data category registers, etc.) calls for a greater emphasis on shared models and vocabularies for linguistic linked data (LLD), since these are key to making linked data resources more reusable and more interoperable (at a semantic level). The purpose of this article is to provide a comprehensive and up-to-date survey of such models, while also touching upon a number of other closely related topics. The article will focus on the latest developments in this area and will both build upon and attempt to complement previous works covering similar territory by avoiding too much repetition and overlap with the latter.
In the following section, Section 2, we give an overview of a number of trends from the last few years which have had/are having/are likely to have, a significant impact on the definition and use of LLD models. This overview is intended to help to locate the present work within a wider research context, something that is particularly useful in an area as active as linguistic linked data, as well as helping readers in navigating the rest of the article. Section 3 gives an overview of related work, and Section 4 an overview of the most widely used models in LLD. Next, in Section 5, we take a look at recent developments in community standards and initiatives: this includes a description of the latest extensions of the OntoLex-Lemon model, as well as a discussion of relevant work in the modelling of corpora and annotations and LLD metadata. Finally, the article contains a section dedicated to the use of models in LLD-centered projects, Section 6, and a concluding section, Section 7 in which we look at some potential future trends.
Setting the scene: An overview of relevant trends in LLD
We have decided to focus on three overarching trends in this overview. These are: the FAIRification of data in
FAIR data (defined below, in Section 2.1) plays a central role in a number of prominent initiatives which have recently been proposed for the promotion of open science and data on the part of numerous organisations and especially of research funding bodies. It would be useful to understand therefore how LLD models can contribute to the creation of FAIR language resources, and this is the topic of Section 2.1. Similarly, the Digital Humanities, an area of research which has rapidly gained ground over the last few years, have also become more and more significant as a both a producer and consumer of LLD, something which has inevitably had an impact on LLD vocabularies and models, see Section 2.3.
FAIR new world
It should come as no surprise, given the growing importance of Open Science initiatives and in particular those promoting the FAIR guidelines (where FAIR stands for Findable, Accessible, Interoperable and Reusable) for the modelling, creation and publication of data [179], that shared models and vocabularies have begun to take on an increasingly prominent role within numerous disciplines, and not least in the fields of linguistics and language resources. And although the linguistic linked data community has been active in advocating for the use of shared RDF-based vocabularies and models for quite some time now, this new emphasis on FAIR language resources is likely to have a considerable impact in several ways, not least in terms of the necessity for these models and vocabularies to demonstrate greater coverage with respect to the kinds of linguistic phenomena they can describe, and for them to be more interoperable with each other. We will look at one recent and influential series of FAIR related recommendations for models in Section 4 in order to see how they might be applied to the case of LLD. In the rest of this subsection, we will take a closer look at the FAIR principles themselves and show why their widespread adoption is likely to lead to a greater role for LLD models and vocabularies in the future.
In The FAIR Guiding Principles for scientific data management and stewardship [179], the article which first articulated the by-now ubiquitous FAIR principles, the authors state that the criteria proposed by those principles are intended both “for machines and people” and that they provide “‘steps along a path’ to machine actionability”, where the latter is understood to describe structured data that would allow a “computational data explorer” to determine:
The type of “digital research object” Its usefulness with respect to tasks to be carried out Its usability especially with respect to licensing issues, with this information represented in a way that would allow the agent to take “appropriate action”.
The current popularity of the FAIR principles and, in particular, their promotion by governments, transnational organisations and research funding bodies, such as the European Commission,1
Publishing data using a standardised, general purpose, data model such as the Resource Description Framework2
(RDF) goes a long way towards facilitating the publication of datasets as FAIR data. Indeed RDF, taken together with the other standards proposed in the Semantic Web stack and the technical infrastructure which has been developed to support it, was specifically intended to facilitate interoperability and interlinking between datasets. In order to ensure the interoperability and re-usability of datasets within a domain, however, it is vital that in addition to more generic data models such as RDF there also exist domain specific vocabularies/terminologies/models and data category registries (compatible with the former). Such resources serve to describe, ideally in a machine actionable way, the shared theoretical assumptions held by a community of domain experts as reflected in the terminology or terminologies in use within that community.The following specific FAIR principles are especially salient here (emphasis ours):
F2. data are described with rich metadata.
I1. (meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
I2. (meta)data use vocabularies that follow FAIR principles.
It is important to note here that the emphasis placed on machine actionability in FAIR resources (that is, recall, on enabling computational agents to find relevant datasets and resources and to take “appropriate action” when they find them) gives Semantic Web vocabularies/models/registries a substantial advantage over other (non-Semantic Web native) standards in the fields of linguistics and language resources, such as the Text Encoding Initiative (TEI) guidelines3
[164], the Lexical Markup Framework (LMF) [68] or the Morpho-syntactic Annotation Framework (MAF) [40].For a start, none of these other standards possess a ‘native’, widely-used, widely supported and broadly applicable formal knowledge representation (KR) language for describing the semantics of vocabulary terms in a machine-readable way, or at least nothing as powerful as the Web Ontology Language (OWL)4
or the Semantic Web Rule Language (SWRL).5 This means that in effect there is no standardised way of, for instance, describing the meanings of terms such morpheme, or lemma, etc. in TEI in a machine actionable way. KR languages like OWL allow for precise, axiomatic definitions to be given to terms in a way that permits reasoning to be carried out on them (in the case of OWL there exist numerous, freely available reasoning engines such as Pellet [157]); more generally, they allow for much richer machine actionable metadata descriptions. Furthermore, the use of KR languages like OWL can be allied with already established conceptual modelling techniques and best practises – including the use of top level ontologies such as DOLCE6 or BFO,7 both of which are available in OWL, and ontology validation methodologies such as OntoClean [83] which help to clarify what we mean when we say that one concept is a subtype of another – in order to define vocabularies and models which further enhance the interoperability and machine actionability of linguistic datasets.Moreover, thanks to the use of a shared data model with a powerful native linking mechanism, LLD datasets can easily be integrated with, and therefore enriched by, linked data datasets belonging to other domains, for instance, geographical and historical datasets or gazetteers and authority lists. Indeed, OWL vocabularies, such as PROV-O,8
make it straightforward to add complex, structured information describing when something happened or to make hypotheses explicit9In the latter case for instance we could use the Semantic Web ontology CRMInfhttp://www.cidoc-crm.org/crminf/.
The pursuit of the FAIR ideal has in fact encouraged the definition of new ways of publishing linked data datasets, which offer additional opportunities for the re-use and integration of such datasets in an automatic or semi-automatic way. These include nanopublications, cardinal assertions and knowlets.10
Nanopublications are defined as the “smallest possible machine-readable graph-like structure that represents a meaningful assertion” [128] and consist of publishing a single subject-predicate-object triple with full provenance information; a generalisation of this idea is that of the cardinal assertion where a single assertion is associated with more than one provenance graph. A knowlet consists of a collection of multiple cardinal assertions, with the same subject concept [128] and can be viewed as locating that concept in a rich ‘conceptual space’. For instance, this could be a cloud of predicates centered around a word or a sense.
When it comes to language resources we are faced with a rich array of highly structured datasets arranged into different types (lexica, corpora, treebanks, etc) according to a series of widely shared conventions – something that would seem to lend itself well to making such resources FAIR in the machine-oriented spirit of the original description of those principles. However, in order to ensure the continued effectiveness of linked data and the Semantic Web in facilitating the creation of FAIR resources, it is critical that pre-existing vocabularies/models/data registries be re-used whenever possible in the modelling of language resources. In many instances, these models will not have sufficient coverage to capture numerous kinds of use cases, in which case we will have to define new extensions to these models (an ongoing process and one which is a major theme of this article, see for instance Section 5.1), in other cases it may be necessary to create training materials suitable for different groups of users. Part of the intention of this article, together with the foundational work carried out in [9], is to provide an overview of what exists in terms of LLD-focused models, to look at those areas and use-cases which have so far gained the most attention and to highlight those which are so far underrepresented.
One significant indicator of the success which LLD has enjoyed in the last few years is the variety of newly funded projects which have emerged in this period, and which have included the publication of linguistic datasets as linked data as a core theme. These include projects both at a continental or transnational level – notably European H2020 projects,11
ERCs12 and COST actions13 – as well as at the national and regional levels. Arguably, this recent success in obtaining project funding reflects a wider recognition of the usefulness of linked data as a means of ensuring the interoperability and accessibility of language resources. It also demonstrates the ongoing maturation of the field, as LLD continues to be successfully applied to new domains and use cases within the context of such projects. In addition, these projects also offer us numerous examples of the application of some LLD vocabularies and models, which we look at in this article in the creation of medium to large-scale language resources.We have therefore decided to dedicate a whole section of the present article,
Note, however, that although the projects which we discuss in Section 6 have, in many cases, set the agenda for the development of LLD models and vocabularies, much of the actual work on the definition of these resources was carried out – and is being carried out – within community groups, such as the W3C OntoLex group. We therefore include an update on community standards and initiatives in
Several of the projects discussed in this article fall under the umbrella of the Digital Humanities (DH). For this and other reasons this is the third major trend which we want to highlight here, since it represents a move away (or more precisely a branching off) from LLD’s beginnings in computational linguistics and natural language processing (although these latter two still perhaps represent the majority of applications of LLD), and this we claim is something that is leading to a shift in emphasis in the definition and coverage of LLD models. The overlap between LLD and DH is especially apparent in the modelling of corpora annotation (
One use case which clearly highlights these shared concerns is the publication of retro-digitised dictionaries as LLD lexica (a major theme of the ELEXIS project, see
Encompassing what the TEI dictionary chapter guidelines call the typographical and editorial views. See https://www.tei-c.org/release/doc/tei-p5-doc/en/html/DI.html#DIMV.
For instance we might want to track the evolution of a historically significant lexicographic work over the course of a number of editions, in order to see, for example, how changes in entries reflected both linguistic and wider, non-linguistic trends. This was one of the motivations behind the Nénufar project [6], described in Section 6.1.1.
All of this calls for a much richer provision of metadata categories than has been considered up till now for LLD lexica: both at the level of the whole work and at the level of the individual entry. It also requires the capacity to model salient aspects of the same artefact or resource at different levels of description (something which is indeed offered by the OntoLex-Lemon Lexicography module, see
An additional series of challenges arises in the consideration of resources for classical and historical languages, or indeed, historical stages of modern languages. For instance in the case of lexical resources for historical languages we often come up against the necessity of having to model attestations (discussed in
One extremely important (non RDF-based) standard for encoding documents in the Digital Humanities is
Finally, see
This article is intended, among other things, to both complement and to update a previous general survey on models for representing LLD, published by Bosque-Gil et al. in 2018 [9]. Although we are now only four years on from the publication of that work, we feel that enough has happened in the intervening time period to justify a new survey article. In addition, our intention is to cover a much wider range of topics than the previous article. We also feel that our overall focus is quite different. Broadly speaking, that previous work offered a classification of various different LLD vocabularies according to the different levels of linguistic description that they covered. The current paper concentrates more on the use of LLD vocabularies in practise and on their availability (this is very much how we have approached the survey in The development of new OntoLex-Lemon modules for morphology Section 5.1.2 and frequency, attestations, and corpus Information, described in An important new initiative in aligning LLD vocabularies for corpora and annotation, described in
In what follows, we will assume that the reader already has some grounding in linked data in general – including a basic familiarity with the Resource Description Framework (RDF), RDF Schema (RDFS) and the Web Ontology Language (OWL) – and linguistic linked data in particular. In case the reader is missing this minimal background in linguistic linked data, the recently published Linguistic linked data: representation, generation and applications [36] should provide with a comprehensive introduction to and overview of the field, focusing on more established models and vocabularies and their application rather than on recent developments. Another important new book on the topic of LLD and which has relevance to the current work is the collected volume Development of linguistic linked open data resources for collaborative data-intensive research in the language sciences [132] which aims to describe major developments since 2015. It consists mostly of position papers by linguists and researchers from the language resource communities.
LLD models: An overview
The current section gives an overview of some of the most well known and widely used models and vocabularies in LLD. A summary of the models discussed in the current section (and in the whole article) can be found in
Corpora (and Linguistic Annotations)(Section 4.1)
Lexica and Dictionaries (Section 4.2)
Terminologies, Thesauri and Knowledge Bases (Section 4.3)
Linguistic Resource Metadata (Section 4.4)
Linguistic Data Categories (Section 4.5)
Typological Databases (Section 4.6)
Summary of published LLD vocabularies
Other LLD vocabularies discussed in this paper
We describe our methodology for the rest of the section below. In Section 4.7 we discuss tools and platforms for the publication of LLD.
Our approach to classification As this section is intended to be an overview we will not give detailed descriptions of single models or vocabularies here (several of these models and vocabularies are described in more detail in the rest of the article, or in the case of OntoLex-Lemon in the appendix, and others receive a more detailed treatment in [9] and [36]). Instead, we describe them on the basis of a number of criteria, many of which are related to their status as FAIR models and vocabularies. In doing so we refer to a recent survey on FAIR Semantics [88], the result of a dedicated brainstorming workshop and subsequently an evaluation session of the FAIRsFAIR project.17
This report outlines a number of recommendations and best practices for FAIR semantic artefacts where the latter are defined as “machine-actionable and -readable formalisation[s] of a conceptualisation enabling sharing and reuse by humans and machines”; this term is intended to include taxonomies, thesauri and ontologies.Even though all the recommendations listed in [88] are important, for reasons of space, we have selected the following subset on the basis of their salience to the set of models and vocabularies under discussion:
(P-Rec 2) Globally Unique, Persistent, and Resolvable Identifiers must be used for Semantic Artefact Metadata Records. Metadata and data must be published separately, even if it is managed jointly; (P-Rec 4) Semantic Artefact and its content should be published in a trustworthy semantic repository; (P-Rec 6) Build semantic artefact search engines that operate across different semantic repositories; (P-Rec 10) Foundational Ontologies may be used to align semantic artefacts; (P-Rec 13) Crosswalks, mappings and bridging between semantic artefacts should be documented, published and curated; (P-Rec 16) The semantic artefact must be clearly licensed for use by machines and humans.
Neither of the recommendations (P-Rec 2) and (P-Rec 10) have been implemented by any of the models/vocabularies which we look at below. Following them, however, greatly helps to make these resources (and the datasets which make use of them) more FAIR, and we regard their adoption as desirable future objectives for the models and vocabularies listed below.18
The adoption of foundational ontologies, for instance, would likely help to alleviate some problems raised by the proliferation of independently developed models as described in [9].
We use (P-Rec 16) as a guide in analysing the resources covered in the article. So that we point out cases where licensing information is available as machine actionable metadata, using properties like
Note that the LOV site provides a list of criteria for inclusion on their search engine [171]: https://lov.linkeddata.es/Recommendations_Vocabulary_Design.pdf.
In addition to the textual descriptions of different LLD models given in the rest of this section, we also give a tabular summary of the most well-known/stable/widely available22
Several of the models which are described in the rest of the section and aren’t available publicly but may be interesting for historical reasons.
Every one of the models listed in the table uses the RDFS vocabulary, and each one of them is an OWL ontology. We also list the additional models/vocabularies which they make use of in the table on a case by case basis. These include the following well known ones: XML Schema Definition23
(XSD); the Friend of a Friend Ontology24 (FOAF); the Simple Knowledge Organisation System25 (SKOS); Dublin Core26 (DC); Dublin Core Metadata Initiative (DCMI) Metadata Terms;27 the Data Catalog Vocabulary28 (DCAT), described also in Section 5.3; and the PROV Ontology29 (PROV-O).In addition, the table also mentions the following vocabularies.
Activity Streams(AS): a vocabulary for activity streams.30
GOLD: an ontology for describing linguistic data, which is described in Section 4.5.
MARL: a vocabulary for describing and annotating subjective opinions.31
ITSRDF: an ontology used within the Internationalization Tag Set.32
The Creative Commons vocabulary33
(CC).VANN: a vocabulary for annotating vocabulary descriptions.34
SKOS-XL: an extension of SKOS with extra support for “describing and linking lexical entities”.35
SKOS and SKOS-XL are, along with lemon and its successor OntoLex-Lemon, amongst the most well known ways of enriching linked data taxonomies and conceptual hierarchies with linguistic information. We will look at the use of a SKOS-XL vocabulary in the context of a project on the classification of folk tales in Section 6.Linguistic annotation for the purposes of creating digital editions, corpora, and linking texts with external resources etc, has long been a topic of interest within the context of RDF and linked data. Coexisting with relational databases, XML-based formats (most notably, TEI, see Section 5.2) or simply text-based formats, RDF-based annotation models have been steadily undergoing development and are increasingly being taken up in research and industry.
Currently there are two primary RDF vocabularies which are being widely used for annotating texts. These are
https://lov.linkeddata.es/dataset/lov/vocabs/nif and https://lov.linkeddata.es/dataset/lov/vocabs/oa.
Other vocabularies described in that section include POWLA, CoNLL-RDF and Ligt. The first of these, POWLA,41
is available on archivo,42 the only one of the three that has been made available in this way. CoNLL-RDF43 expresses version info as a string using theThe most well known model for the creation and publication of lexica and dictionaries as linked data is
The URI for OntoLex-Lemon is: http://www.w3.org/ns/lemon/ontolex and the OntoLex-Lemon guidelines can be found at https://www.w3.org/2016/05/ontolex/.
The OntoLex-Lemon model is modular and consists of a core module along with modules for Syntax and Semantics,47
Decomposition,48 and Variation and Translation,49 as well as a dedicated metadata module, lime50 (all of which are described in Appendix x, except for lime which is described in Section 5.3.3).OntoLex-Lemon is available on LOV as is its predecessor lemon.51
All of its individual modules are listed separately: the core;52lime;53vartrans;54synsem;55 the decomp module.56 Three of its modules are available on archivo, the core:57 the lime metadata module58 and the Variation and Translation module.59 All the OntoLex-Lemon modules have their licensing information (they are all CC0 1.0) described with RDF triples using the CC vocabulary60Using the
The OntoLex-Lemon Lexicography module,61
The guidelines for the module can be found at https://www.w3.org/2019/09/lexicog/, the URL for the module is at http://www.w3.org/ns/lemon/lexicog#.
Using
The
In terms of specialised vocabularies or models for the modelling of linguistic knowledge bases – and aside from linguistic data category registries, which will be discussed in Section 4.5 – we can list two prominent ones here. The first is
Although this was down at the time of writing.
See, for example, https://phoible.org/inventories/view/161.
See Section 4.6 below for additional details.
Due to the importance of this topic, we give a more detailed overview in Section 5.3. Here, we consider only accessibility issues for the two models for language resource metadata, which are described in Section 5.3: The METASHARE ontology71
and lime. The latter has been previously introduced and is described in more detail in Section 5.3.3. The former is currently in its pre-release version 2.0 (the last update being 2020-03-20). Its license information (it has a CC-BY 4.0 license) is available as triples usingHistory Looking back to 2010, two major registries were in widespread use by different communities for addressing the harmonization and linking of linguistic resources via their data categories.
In computational lexicography and language technology, the most widely applied terminology repository was
In the field of language documentation and typology, the
The current situation The ‘official’ successor of ISOcat, the CLARIN Concept Registry is briefly discussed in Section 5.3 below, but it is not strictly speaking a linked data vocabulary. Another successor of ISOcat is the
It will be the first version that is compliant with OntoLex-Lemon.
A separate terminology repository for linguistic data categories in linguistic annotation exists: the
Relevant resources and initiatives Linguistic typology is commonly defined as the field of linguistics that studies and classifies languages based on their structural features [63]. The field of linguistic typology has natural ties with language documentation, and accordingly, considerable work on linguistic typology and linked data has been conducted in the context of the GOLD ontology (see above, Section 4.5). We can identify the following relevant datasets.
One of the main contributors and advisors to the scientific study of typology is the
Another collection that provides web-based access to a large collection of typological datasets is the
Finally, another group of datasets relevant for typological research include large-scale collections of lexical data, as provided, for example, by
Data available under https://github.com/acoli-repo/acoli-dicts.
Vocabularies for typological datasets In terms of linked data vocabularies and models which are relevant for the creation of typological databases, we can identify
The availability of tools and platforms for the editing, conversion and publication of LLD resources, on the basis of the models which we discuss in this article, is critical for the adoption of those models amongst a wider community of end users. It can be especially important for users who are unfamiliar with the technical details of linked data and the Semantic Web, and yet who are highly motivated to create and/or make use of linked data resources. Such tools/platforms are helpful, for instance, when it comes to the validation and post-editing by domain experts of language resources which have been generated automatically or semi-automatically.
In terms of existing tools or software which offer dedicated provision for the models which we look at in this article, we can mention
Finally, we should mention
Summary and overview The current section comprises an extensive overview of recent developments in various different LLD community standards and initiatives as they relate to LLD models and vocabularies. In particular, it focuses on three areas that we believe have either been the most active or most prominent over the last few years. These are lexical resources (Section 5.1), annotation and corpora (Section 5.2), and metadata (Section 5.3). We have referred to these as community standards/initiatives because they have been pursued or developed as community efforts rather than within a single research group or project. Membership in these communities is (often) open to all, rather than being limited to members of a specific project or to experts nominated by a standards body. The intention being to allow for the participation of a wider range of stakeholders, as well as encouraging the collection of a wider variety of use-cases than might otherwise be possible.
One of the most notable community efforts in the context of LL
Around the same time, a number of more specialized initiatives emerged for which the Open Linguistics Working Group acted and continues to act as an umbrella organisation, facilitating information exchange among them and between these initiatives and the broader circles of linguists interested in linked data technologies and knowledge engineers interested in language. Currently, the main activities of the OWLG are the organization of workshops on Linked Data in Linguistics (LDL), the coordination of datathons such as Multilingual Linked Open Data for Enterprises (MLODE 2012, 2013) and the Summer Datathon in Linguistic Linked Open Data (SD-LLOD, 2015, 2017, 2019), maintaining the Linguistic Linked Open Data (LLOD) cloud diagram92
and continued information exchange via a shared mailing list93Since early 2020, the mailing list operates via https://groups.google.com/g/open-linguistics. Earlier messages are archived under https://lists-archive.okfn.org/pipermail/open-linguistics/.
Over the years, the focus of discussion has shifted from the OWLG to more specialized mailing lists and communities. At the time of writing, particularly active community groups concerned with data modelling include
the W3C Community Group Ontology-Lexica,94
the W3C Community Group Linked Data for Language Technology,95
with a focus on language resource metadata and linguistic annotation with W3C standardsA discussion of the relationship between community initiatives and projects can be found in Section 6.1.2 below.
Summary In this section we describe some of the most recent work that has been carried out on the OntoLex-Lemon model,96
An introduction to the model is given in Appendix x.
Note that the use of OntoLex-Lemon in a number of different projects is described in Section 6.
As mentioned previously, lemon and its successor OntoLex-Lemon have been widely adopted for the modelling and publishing of lexica and dictionaries as linked data. Both of them have proven to be reasonably effective in capturing many of the most typical kinds of lexical information contained in dictionaries and in lexical resources in general (e.g., [1,8,82,102,105]). However, there are some fairly common situations in which the model falls short, and most notably in the representation of certain specific elements of dictionaries and other lexicographic datasets [7]. This is not surprising, given that (as we have mentioned above) lemon was initially conceived as a model for a somewhat different use case (grounding ontologies with linguistic information).
In order to adapt OntoLex-Lemon to the modelling necessities and particularities of dictionaries and other lexicographic resources, the W3C OntoLex community group developed a new
The idea is to keep purely lexical content separate from lexicographic (textual) content. For that purpose, new ontology elements have been added that reflect the dictionary structure (e.g., sense ordering, entry hierarchies, etc.) and complement the OntoLex-Lemon model. The lexicog module have been validated with real enterprise-level dictionary data [10] and a final set of guidelines have been published as an output of the W3C OntoLex group. We give a description of the main classes and properties of the model below98
Please see the guidelines for a comprehensive description with examples.
In lexicog the structural organisation of a lexicographic resource is now associated with the class
These lexicographic entries are represented in their turn by another new lexicog class, namely, the class
The class
Finally, we need some way of linking together these two levels of representation. This is provided by the lexicog object property
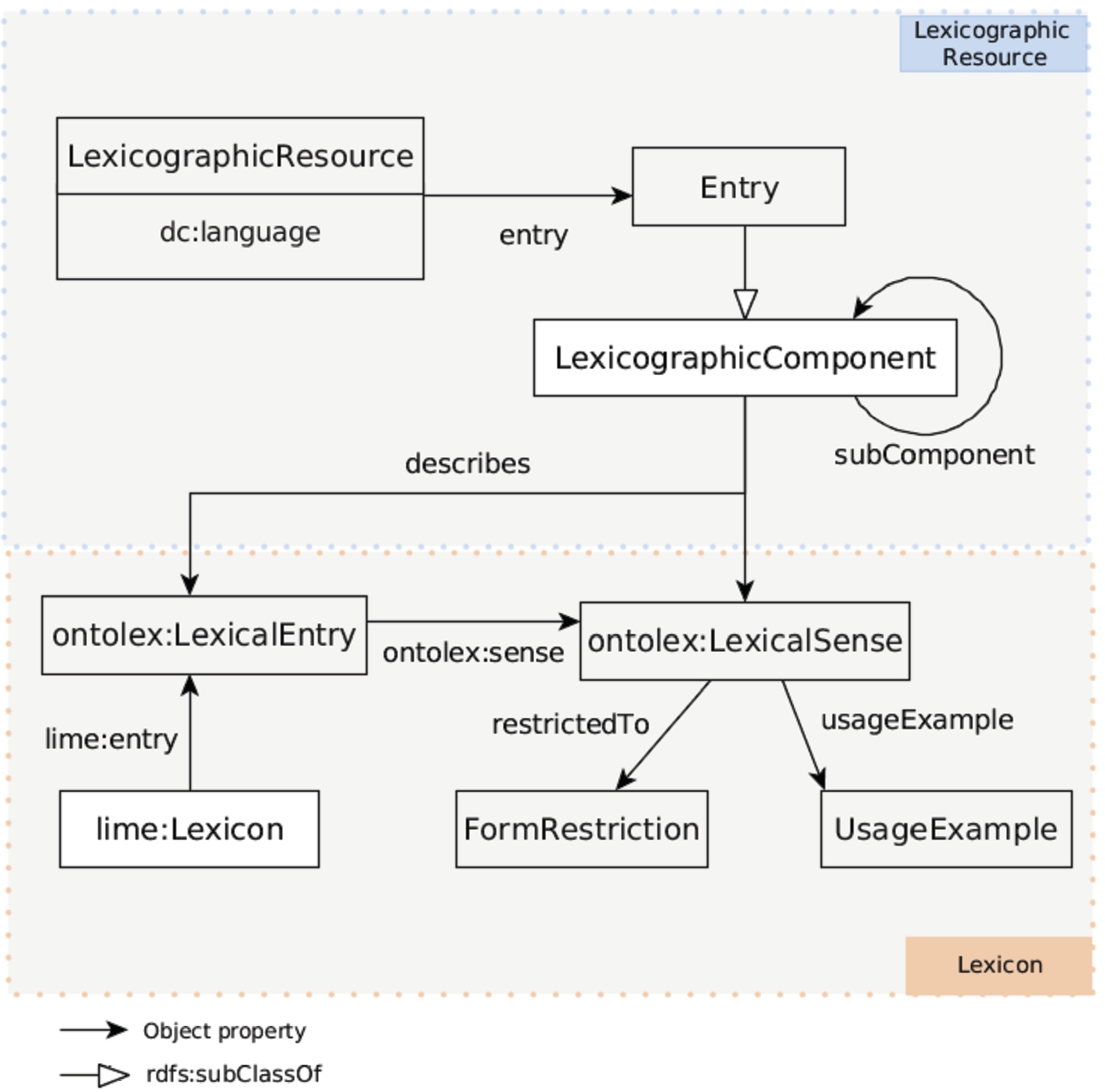
The lexicog module (taken from the guidelines).
As an example, let’s look a lexicog encoding for the entry for the Italian word chiaro ‘clear’ in the popular Italian language dictionary Treccani.104
This latter lists the word an adjective, a masculine noun and an adverb. It also lists the adverb chiaramente ‘clearly’ as a related entry, along with the diminutive chiaretto.More precisely, the first two of the (four) subsenses of the entry are classed as adjectives, the third as a noun, and the fourth as an adverb. We will simplify this for the purposes of exposition by assuming that the first subsense is an adjective, the second a noun, and the third an adverb. This can be represented as follows. First, we represent the encoding of the Treccani dictionary structure itself, and the different sub-components of the entry for chiaro:

Next we encode a lexicon which represents the content of the resource in the last listing.

Finally, we bring the two resources together using the

Morphology often an important role in the description of languages in lexical resources, even if the extent of its presence in can often vary, ranging from the sporadic indication of certain specific forms in a dictionary (e.g. plural form for some nouns) to electronic resources which provide tables with entire inflectional paradigms for every word.105
For example, Wiktionary, https://en.wiktionary.org/wiki/Buch#Declension.
The original OntoLex-Lemon model, together with LexInfo (see Section 4.5), provides the means of encoding basic morphological information. For lexical entries, morpho-syntactic categories such as part of speech can be provided and basic inflection information (i.e., the morphological relationship between a lexical entry and its forms) can be modelled by creating additional inflected forms with corresponding morpho-syntactic features (e.g. case, number, etc.). However, this only covers a small portion of the morphological data to be modelled in many lexical resources. Neither derivation (i.e. morphological relationships between lexical entries) nor additional inflectional information (e.g. declension type for Latin nouns) can be properly modelled with the original model. The new
Representing derivation: for a more sophisticated description of the decomposition of lexical entries;
Representing inflection: introducing new elements to represent paradigms and wordform-building patterns;
Providing means to create wordforms automatically based on lexical entries, their paradigms and inflection patterns.
Figure 2 presents a diagram for the module.
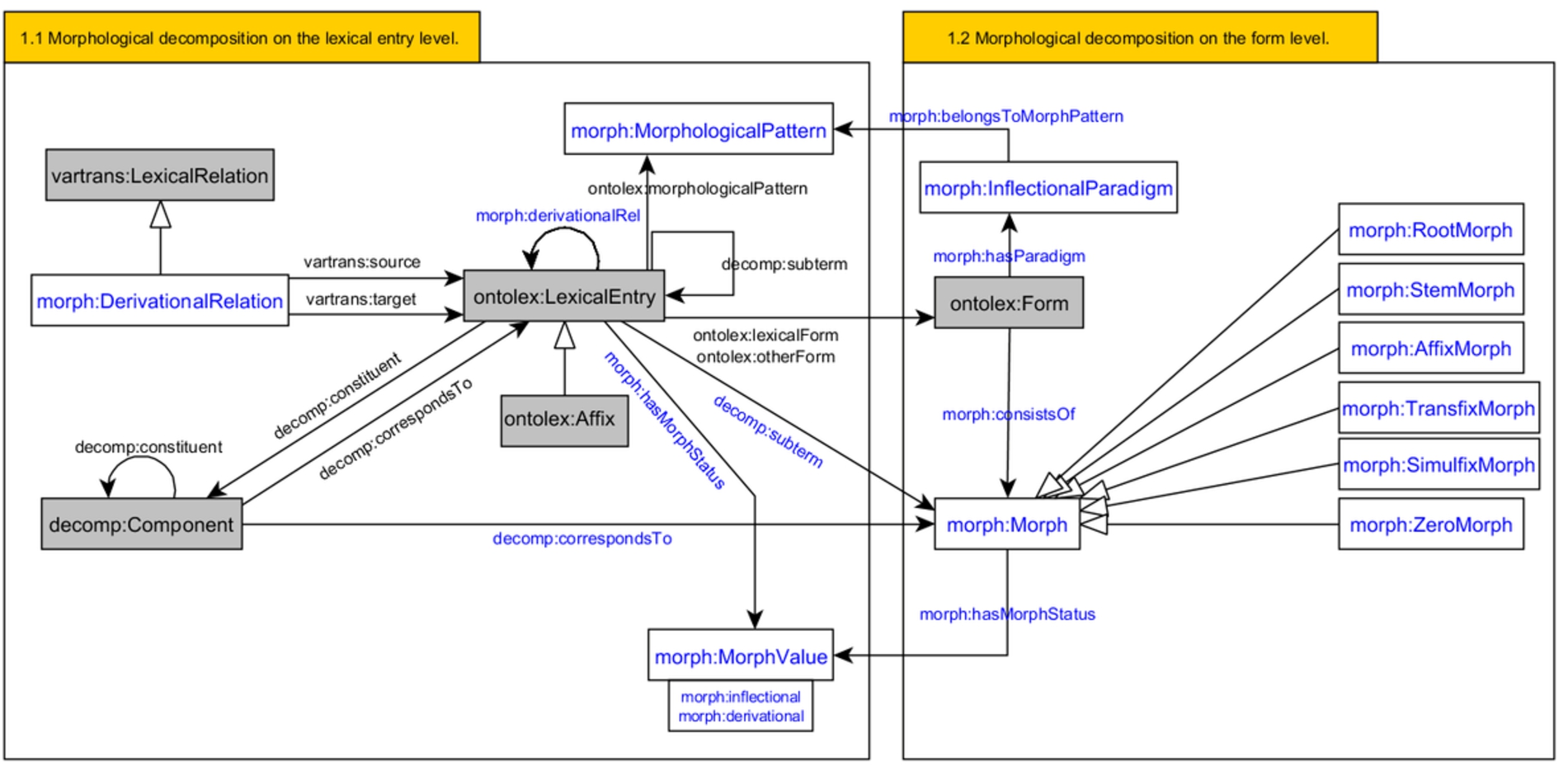
Preliminary diagram for the morphology module.
The central class of the module, used in the representation of both derivation and inflection, is
For derivation, elements from the decomp module are reused. A derived lexical entry has

Inflection is modelled as follows: every instance of
One of the problems with this approach is that the order of the affixes is undefined, there are several possible solutions for this, e.g. a property

The module107
has not yet been published and is still very much under development by the W3C group. At the time of writing, a consensus was reached on the first two parts of the module, and an overview of these has been published in [106]. The third part, which concerns the automatic generation of forms, is currently being discussed, and the next step will be validating the model by creating resources using the module.In parallel with the development of the Morphology Module, the OntoLex W3C group has also started developing a separate module that would allow for the enrichment of lexical resources with information drawn from corpora. Most notably, this includes the representation of attestations (often used as illustrative examples in a dictionary). These latter were originally discussed within lexicog (See 5.1.1), but this discussion quickly outgrew the confines of computational lexicography/e-lexicography alone. Furthermore, it was observed that OntoLex-Lemon lacked any support for corpus-based statistics, a cornerstone not only of empirical lexicography, but also of computational philology, corpus linguistics and language technology, and thus, again, beyond the scope of the lexicog module. Finally, the OntoLex community group felt the need to specifically address the requirements of modern language technology by extending its expressive power to corpus-based metrics and data structures like word embeddings, collocations, similarity scores and clusters, etc.
The development of the module has been use-case-based, which has dictated the order and development for various parts of the FRaC module. The stable parts of the module include the representation of (absolute) frequencies and attestations, and, by analogy, any use case that requires pointing from a lexical resource into an annotated corpus or other forms of external empirical evidence [30]. We will limit ourselves to describing these stable parts in what follows.
The central element which has been introduced in FRaC e is
https://github.com/ontolex/frequency-attestation-corpus-information/blob/master/index.md (Accessed 20/01/2022).
The module provides means to model only absolute frequency, because “relative frequencies can be derived if absolute frequencies and totals are known” [30, p. 2]. To represent frequency, a property
Examples in this section are based on those in [30].

The usage recommendation is to define a subclass of
In FRAC corpus attestations, i.e. corpus evidence in FrAC, are defined as “a special form of citation that provides evidence for the existence of a certain lexical phenomenon; they can elucidate meaning or illustrate various linguistic features”.110
https://github.com/ontolex/frequency-attestation-corpus-information/blob/master/index.md (Accessed 20/01/2022).

The FrAC module does not provide an exhaustive vocabulary and instead promotes reuse of external vocabularies, such as CITO [136] for a citation object and NIF or WebAnnotation (see 5.2) to define a locus.
Another, more recent paper focused on representing embeddings in lexical resources is [20]. It should be noted that the term embedding is used here in a broader sense than is usual in the field of natural language processing, namely as a morphism Y (
An injective structure-preserving map.
The main motivation to model embeddings as a part of this module is to provide metadata as RDF for pre-computed embeddings, therefore a word vector itself is stored as a string with an embedding vector:

As with modelling frequency, the recommendation is to define a subclass for the specific type of embedding concerned in order to make the RDF less verbose.
Figure 3 presents a diagram of the latest version of the module. Note that we will not go into detail on the classes
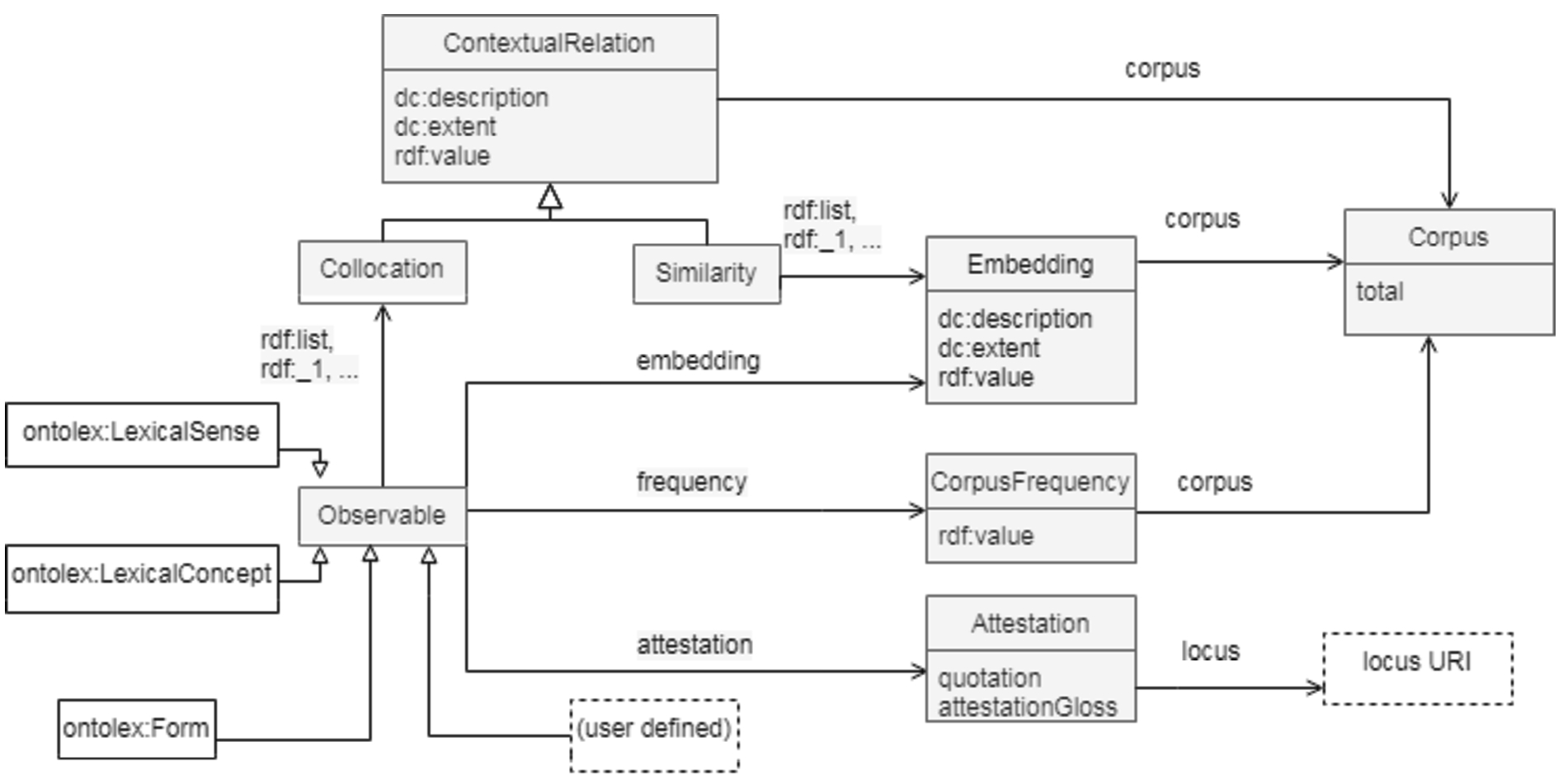
Preliminary diagram for the FrAC module.
At the time of writing, module development is focused on collecting and modelling various use-cases. Among the many use-cases that were proposed during this phase, one stood out in particular and seemed to be more challenging than the others: this was related to the modelling of sign language data. Given the nature of the data (video clips with signs and/or time series of key coordinates for preprocessed data), it was decided that although the use-case was out of the scope of the FrAC module, it did indeed raise serious interest within the community, and therefore discussion on whether it will be developed as a separate module in the future, is now underway. The question of the scope of this new module and, more generally, its connection to OntoLex-Lemon, is currently subject to discussion.
‘Unofficial’ OntoLex-Lemon extensions developed outside the W3C OntoLex Community Group are manifold, and while these are not yet being pursued as candidates for future OntoLex-Lemon modules by the group, they may represent a nucleus and a cumulation point for future directions.
Selected recent extensions include
The lemon-tree specifications can be found here https://ssstolk.github.io/onto/lemon-tree/.
In both of these cases, the RDF data model together with the various different standards and technologies which make up the Semantic Web stack as a whole, allows for the structuring of data that is strongly heterogeneous and integrates together temporal,113
For a discussion of the possibilities of integrating temporal information in OntoLex-Lemon see [101].
Summary In this section, we give an overview of a number of LLD vocabularies for the annotation of texts. Section 5.2.1 constitutes a detailed introduction and general overview of this topic. Then we focus on the two most popular LLD vocabularies for text annotation, the NLP Interchange Format (Section 5.2.2) and Web Annotation (Section 5.2.3). Next, in Section 5.2.4 we look at two domain specific vocabularies, Ligt and CoNLL-RDF. Finally, in Section 5.2.5, we look at the prospects of a convergence between the vocabularies which we have discussed. (Note that in this section, we only discuss vocabularies that define data structures for linguistic annotation by NLP tools and in annotated corpora. Linguistic categories and grammatical features, as well as other information that represents the content of an annotation, are assumed to be provided by a(ny) repository of linguistic data categories (see above))
Introduction and overview
Linguistic annotation of corpora by NLP tools in a way that integrates Semantic Web standards and technologies has long been a topic of discussion within LLD circles, with different proposals grounded in traditions from natural language processing [14], web technologies [173], knowledge extraction [86], but also from linguistics [120], philology [2], and the development of corpus management systems [17,55].
A practical introduction to the various different vocabularies used (by various different communities, for different purposes and according to different capabilities) for linguistic annotation in RDF today is given over the course of several chapters in [36]. In brief, the RDF vocabularies which are most widely used for this purpose are the
In the current section we give an overview of the relationship between RDF and two other pre-RDF vocabularies, then we will touch upon some platform specific RDF vocabularies for annotations that have been developed over the years. Aside from software- or platform-specific formats, a number of vocabularies has been developed that address specific problems or user communities.
Pre-RDF vocabularies Developed by the ISO TC37/SC4 Language Resource Management group, the
Note that in relation to Web Annotation anchors roughly correspond to Web Annotation selectors (or target URIs); markables roughly correspond to annotation elements; values to the body objects of Web Annotation. In Web Annotation, relations as data structures are not foreseen.114
Although Web Annotation lacks any formal counterpart of edges or relations as defined by LAF there have been attempts to define a vocabulary that extends Web Annotation with LAF data categories [173], but this has apparently never been applied in practice.
At the moment, direct RDF serializations of LAF do not seem to be widely used in an LLOD context. The reason is certainly that the dominant RDF vocabularies for annotations, despite their deficiencies, cover the large majority of use cases. One notable RDF serialisation of LAF however is
Others include [17] utilised an RDF graph, with an RDF vocabulary for nodes, labels and edges to express linguistic data structures over a corpus backend natively based on an RDBMS; a prototypical extension of Web Annotation with an RDF interpretation of the LAF described by [173], which and the LAPPS Interchange Format, conceptually and historically an instance of LAF, which has see the discussion below on platform-specific vocabularies.
It is also worth mentioning
This is useful for instance for managing prosopographical, bibliographical or geographical information.
This may not be considered to be drastic for electronic editions of historical manuscripts which one could conceivably complement with information drawn from the LLOD cloud. The situation is quite different for dictionaries whose content could easily be made accessible and integrated with other lexical resources on the LLOD cloud, e.g., for future linking. The situation has begun to change over the last few years, and long-standing efforts to develop technological bridges between both TEI and LOD are beginning to yield concrete results. For instance, different tools for the conversion of lexical resources in different TEI dialects to OntoLex-Lemon have been presented in the last years. Among others, this includes a converter for TEI Dict/FreeDict dialect, https://github.com/acoli-repo/acoli-dicts/tree/master/stable/freedict [25]. For ELEXIS related developments, see Section 6.2.3.
The annotation of rather than within TEI documents, however, has been pursued by Pelagios/Pleiades, a community interested in the annotation of historical documents and maps with geographical identifiers and other forms of geoinformation (though this does not yet run to linguistic annotations). One result of these efforts is the development of a specialised editor called Recogito, and its extension to TEI/XML. In this case the annotation is not part of the TEI document, but stored as standoff annotation in a JSON-LD format, and thus, is in compliance with established web standards and re-usable by external tools and addressable as Linked Data. However, this approach is restricted to cases in which the underlying TEI document is static and no longer changes.118
Otherwise, the efforts for synchronization will by far outweigh any benefit that the use of W3C standards for encoding the annotation brings.
For the current status of the discussion, cf. https://github.com/TEIC/TEI/issues/311 and https://github.com/TEIC/TEI/issues/1860.
Platform specific RDF vocabularies Over the years, several platforms, projects and tools have come up with their own approaches for modelling annotations and corpora as linked data. Notable examples include the RDF output of machine reading and NLP systems such as FRED [74], NewsReader [174] or the LAPPS Grid [90]. We discuss these below.
For the rendering of discourse relations, for example, it produces properties such as
A more recent development in this regard is that efforts have been undertaken to establish a clear relation between LIF and pre-RDF formats currently used by CLARIN [87].
Both LIF and NAF-RDF are, however, not generic formats for linguistic annotations but rather, provide (relatively rich) inventories of vocabulary items for specific NLP tasks.122
Historically, LIF is grounded in LAF concepts and has been developed by the same group of people, but no attempt seems to have been made to maintain the level of genericity of the LAF. Instead, application-specific aspects seem to have driven LIF design.
The NLP Interchange Format (NIF),123
developed at AKSW Leipzig, was designed to facilitate the integration of NLP tools in knowledge extraction pipelines, as part of the building of a Semantic Web tool chain and a technology stack for language technology on the web [86]. NIF provides support for a broad range of frequently occurring NLP tasks such as part of speech tagging, lemmatization, entity linking, coreference resolution, sentiment analysis, and, to a limited extent, syntactic and semantic parsing. In addition to providing a technological solution for integrating NLP tools in semantic web annotations, NIF also provides specifications for web services.A core feature of NIF is that it is grounded in a formal model of strings and that it makes the use of String URIs as fragment identifiers obligatory for anything annotable by NIF. Every element that can be annotated in NIF has to be a string.124
In particular, this includes the classes
As an example, NIF does not allow us to distinguish multiple syntactic phrases that cover the same token. Consider the sentence “Stay, they said.”125
From Stephen Dunn (2009), ‘Don’t Do That’, poem published in the New Yorker, June 8, 2009.
Overall, NIF fulfills its goals to provide RDF wrappers for off-the-shelf NLP tools, but it is not sufficient for richer annotations such as are frequently found in linguistically annotated corpora. Nevertheless, NIF has been used as a publication format for corpora with entity annotations.127
The most prominent example, the NIF edition of the Brown corpus published in 2015, formerly available from http://brown.nlp2rdf.org/, does not seem to be accessible anymore. Attempted to access on Jan 23, 2021.
More recent developments of NIF include extensions for provenance (NIF 2.1, 2016) and the development of novel NIF-based infrastructures around DBpedia and Wikidata [72]. In parallel to this, NIF has been the basis for the development of more specialised vocabularies, e.g., CoNLL-RDF for linguistic annotations originally provided in tabular formats, see Section 5.2.4.
The Web Annotation Data Model is an RDF-based approach to standoff annotations (in which annotations and the material to be annotated are stored separately) proposed by the Open Annotation community.128
The Web Annotation data model and vocabulary were published as W3C recommendations in 2017 [151,152].
The core data structure of the Web Annotation Data Model is the annotation, i.e., instances of
Web Annotation can be used for any labelling or linking task, e.g., POS tagging, lemmatization, entity linking. It does, however, not support relational annotations such as syntax and semantics, nor (like NIF) the annotation of empty elements. The addition of such elements from LAF has been suggested [173], but does not seem to have been adopted, as labelling tasks dominate the current usage scenarios of Web Annotation.
Unlike NIF, Web Annotation is ideally suited for the annotation of multimedia content or entities that are manifested in different media simultaneously (e.g., in audio and transcript). As a result, it has become popular in the digital humanities, e.g., for the annotation of geographical entities with tools such as Recogito [156], especially since support for creating standoff annotations for static TEI/XML documents was added (around March 2018 [37, p.247]).
Interlinear glossed text (IGT) is a notation where annotations are placed, as the name suggests, between the lines of a text with the purpose of helping readers to understand and interpret linguistic phenomena. The notation is frequently used in education and various language sciences such as language documentation, linguistic typology, and philological studies (for instance, it is commonly used to gloss linguistic examples). Moreover, IGT data can consist of different layers, including translation and transliteration layers, and usually contains layers for ensuring morpheme-level alignment. IGT is not supported by any established vocabularies for representing annotations on linguistic corpora. And although there exist several specialised formats which are specifically designed for the storage and exchange of IGT, these formats are not re-used across different tools, limiting the reusability of annotated data.
In order to help overcome this situation and improve data interoperability, the RDF vocabulary
The Ligt vocabulary was developed as a generalisation over the data structures employed by established tools for creating IGT annotations, most notably Toolbox [147], FLEx [16] and Xigt [81].129
One should note that these tools are currently incompatible with each other and information can only be exchanged between them if manual corrections are applied.
Although Ligt was designed for a very specific set of domain requirements, it can be considered a useful contribution to LLD vocabularies for textual annotation. This is because it provides data structures that are relevant for low-resource and morphologically rich languages but which had been neglected by earlier RDF vocabularies for linguistic annotation on the web, in particular, by NIF and Web Annotation.130
However, it would be possible to encode Ligt information with a generic LAF-based vocabulary such as POWLA.
Another domain specific RDF-based vocabulary which aims to provide a serialisation-independent way of dealing with textual annotations is
Indeed in NLP the CoNLL formats have become de-facto standards for the most frequently used types of annotations having been popularised in a long-standing series of shared tasks over the last two decades.
Here, the wordform is provided in the first column, the second column provides a part-of-speech tag. The
The columns
Among other things, a CoNLL-RDF edition of the Universal Dependencies corpora133
is available in the LLOD cloud diagram. The corpora are linked with the OLiA ontologies; further linking with additional LLOD resources, in particular, lexical resources, has not been explored at the time of writing. CoNLL-RDF has also been applied to the linking of corpora to dictionaries [115] and knowledge graphs [163]. It has also formed the basis of work on the syntactic parsing of historical languages [32,33], the consolidation of syntactic and semantic annotations [23], corpus querying [94], and language contact studies [21]. In addition to the storing of syntactic parses as plain strings, a further extension of CoNLL-RDF adds native support for tree structure [26], extending NIF/CoNLL-RDF data structures with POWLA [19]. As a result, the phrase structure of the example above can now be represented as:The CoNLL-RDF tree extension uses a minimal fragment of POWLA, the properties
The large number of vocabularies mentioned above already reveals something of a problem, that is, that applications and data providers may choose from a broad range of options, and depending on the expectations and requirements of their users, they may even need to support multiple different output formats, protocols and service specifications that could potentially be mutually incompatible. So far, no clear consensus on a single Semantic Web vocabulary for linguistic annotations has emerged, albeit NIF and Web Annotation appear to enjoy relatively high popularity in their respective user communities. However, they are not compatible with each other and neither do they support linguistic annotation to the same (or even, what the authors would consider a sufficient) extent, thus motivating the continuous development of novel, more specialised vocabularies. Synergies between Web Annotation and NIF were explored relatively early on [86], and Cimiano et al. [38, p.89–122] describe how they can be used in combination with each other, in conjunction with more specialised vocabularies such as CoNLL-RDF, and more general vocabularies such as POWLA to model data in a way that suits the following criteria:
it is applicable to any kind of primary data, including non-textual data (via Web Annotation selectors); it can also express reference to primary data in a compact fashion (via NIF String URIs); it permits round-tripping between RDF graphs and conventional formats (via CoNLL-RDF and the CoNLL-RDF library); it supports generic linguistic data structures (via POWLA, resp., the underlying LAF model).
However, while the combination of these various components is possible and in principle operational, this also means that a user or provider of data needs to understand and develop a coherent vision of at least five different data models: Web Annotation, NIF, CoNLL-RDF, POWLA and the original or conventional structure of the data. Moreover, the data structures of these formats are parallel, in parts, and then, a principled and consistent choice between, say, a
Generally speaking, this situation is intractable, and thus,
The survey can be accessed via https://github.com/ld4lt/linguistic-annotation/blob/master/survey/required-features.md, also compare the tabular view under https://github.com/ld4lt/linguistic-annotation/blob/master/survey/required-features-tab.md.
LLOD compliance (adherence to web standards, compatibility with community standards for linguistic annotation)
expressiveness (necessary data structures to represent and navigate linguistic annotations)
units of annotation (addressing primary data and annotations attached to it)
sequential data structures (preserving and navigating sequential order)
relations (annotated links between different units of annotation)
support for/requirements from specific applications and use cases (e.g., intertextual relations, linking with lexical resources, alignment, dialogue annotation).
So far, this is still work in progress, but if these challenges can indeed be resolved at some point in the future, and a coherent vocabulary for linguistic annotations emerge, we expect a similar rise in popularity for the adoption of the Linked Data paradigm for encoding linguistic annotations as we have seen in the last years for lexical resources. This latter was largely driven by the existence of a coherent and generic vocabulary, and indeed, the drift in applications that the OntoLex-Lemon model has recently experienced very much reflects the need for consistent, generic data models.
A question at this point may be what the general benefit of modelling annotations as linked data may be in comparison to other conventional solutions, and different user communities may have different answers to that. It does seem, though, that one potential killer application can be seen in the capacity to integrate, use and re-use pieces of information from different sources. A still largely unsolved problem in linguistic annotation is how to efficiently process standoff annotation, and indeed, the application of RDF and/or Linked Data has long been suggested as a possible solution [14,17,19,120], but only recently, have systems that support RDF as an output format emerged [55]. While it is clear that standoff is a solution, it is also true that the different communities involved have not agreed on commonly used standards to encode and exchange their respective data. In DH and BioNLP, Web Annotation and JSON-LD seems to dominate; in knowledge extraction and language technology, NIF (serialised in JSON-LD or Turtle) seem to be more popular; for digital humanities, the TEI is currently revising XML standoff specifications,135
See https://github.com/TEIC/TEI/issues/1745 for pointers.
Summary In the first subsection of the current section, Section 5.3.1, we give an introduction and overview of metadata trends in LLD and other related areas. Next, we give a detailed description of two important metadata resources for LLD. These are META-SHARE, described in Section 5.3.2, and the OntoLex-Lemon lime module, described in Section 5.3.3. The latter section also features a discussion of future metadata challenges for LLD language resources. Finally, in Section 5.3.4 we address the ongoing challenge of language identification, which is an essential part of the metadata of a language resource.
Introduction
The rise of data-driven approaches that use Machine Learning, and in particular recent breakthroughs in the field of Deep Learning, have secured a central place for data in all scientific and technological areas. Cross-disciplinary research has also boosted the sharing of data within and across different communities. Moreover, a huge volume of data has become available through various repositories, but also via aggregating catalogues, such as the European Open Science Cloud136
and the Google dataset search service.137 Metadata play an instrumental role in the discovery, interoperability and hence (re-)use of digital objects, and indeed act as an intermediary between consumers (humans and machines) and digital objects. For this reason, the FAIR principles [179] include specific recommendations for metadata (see also Section 1). Of particular relevance to this section is principle R1.3 which recommends that “(Meta)data meet domain-relevant community standards”. According to this principle, the adoption of community standards or best practices for data archiving and sharing, including “documentation (metadata) following a common template and using common vocabulary” facilitates the re-use of data. In this section we therefore take a closer look at metadata models commonly used for language resources in the linguistics, digital humanities and language technology communities.Although the focus of this section is on community models, we cannot leave the most popular general purpose models for dataset description out of this overview. Language is an essential part of human cognition and is thus present in all types of data; research on language and language-mediated research is carried out on data from all domains and human activities. All of this obviously extends the search space for data to catalogues other than the purely linguistic ones. The three models that currently dominate the description of datasets are DCAT,138
schema.org139 and DataCite.140DCAT profiles are used in various open data catalogues, such as the EU Open Data portal,141
while schema.org is used for the Google dataset search engine; finally, DataCite, a leading provider of persistent identifiers (namely DOIs), has developed a schema with a small set of core properties which have been selected for the accurate and consistent identification of resources for citation and retrieval purposes.There are various initiatives for the collection of crosswalks of community-specific metadata models with these models,142
See, for instance, https://rd-alliance.github.io/Research-Metadata-Schemas-WG/.
Among models for the description of language resources in general (and not just LLD resources), the
The conversion of CMDI metadata records offered in CLARIN into RDF [180] should not be confused with the construction of an RDF model for CMDI profiles.
We should also mention the
The
MS-OWL has been constructed by taking three key concepts into consideration: resource type, media type and distribution. These give rise to the following basic classes:
MS-OWL caters for the description of the full lifecycle of language resources, from conception and creation to integration in applications and usage in projects as well as for recording relations with other resources (e.g., raw and annotated versions of corpora, tools used for their processing, models integrated in tools, etc.) and related/satellite entities.149
The current work discusses only the core part of MS-OWL targeting the description of language resources and leaves aside the representation of satellite entities (persons, organizations, projects, etc.)
The properties recommended for the description of language resources are assigned to the most relevant class. Thus, the
To better illustrate the structure of the MS-OWL, Fig. 4 depicts a subset of the mandatory and recommended properties for the description of a corpus.
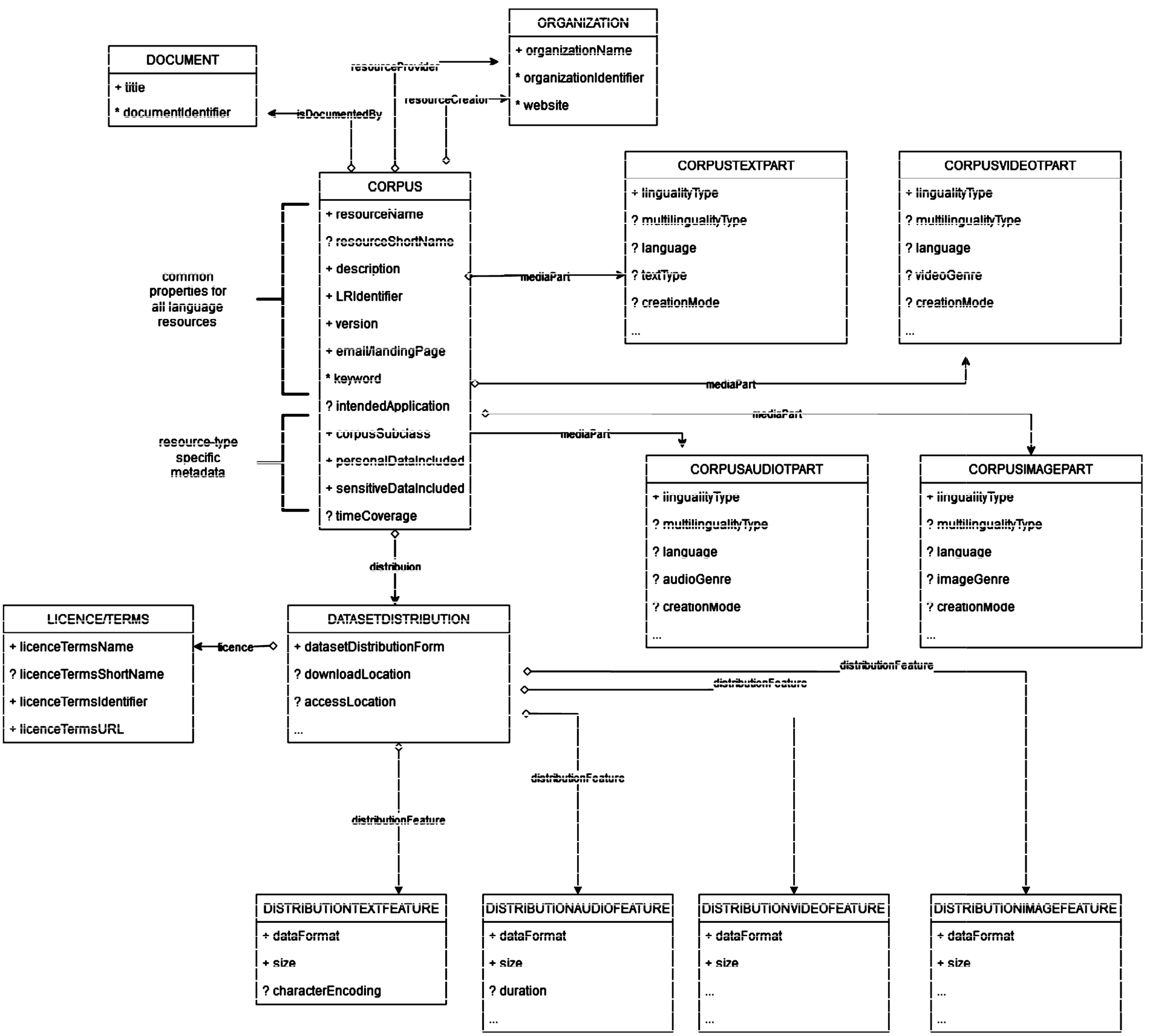
Simplified subset of the MS-OWL for corpora.
Amongst the additions made between the two versions of the MS ontology is the development of an additional vocabulary, again implemented as an OWL ontology,
Both the MS-OWL and OMTD-SHARE ontologies have been published and are currently undergoing evaluation and improvements. They are deployed in the description of language resources in catalogues of language resources. More specifically, the first version of MS-OWL is used in
Another metadata model that is deeply relevant to the current discussion is OntoLex-Lemon’s own dedicated metadata module. The latter, in keeping with the overall citric theme, is called lime, which is short for the LInguistic MEtadata module [65].155
The rest of this section assumes some familiarity with OntoLex-Lemon; an introduction to the model is given in Appendix x.
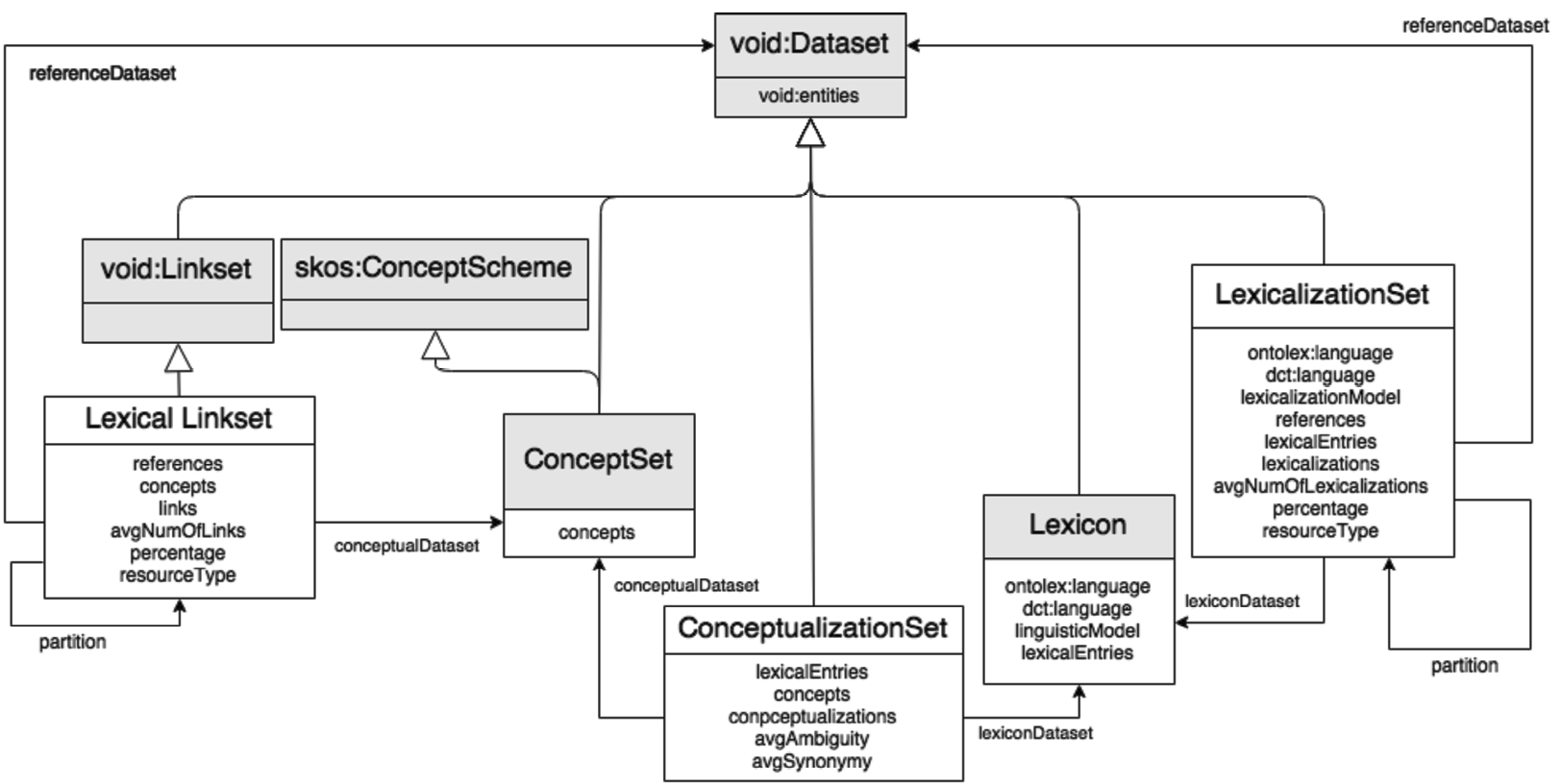
The lime module.
Before we go onto describing lime in more detail, it is worth pointing out that the module focuses on providing metadata descriptions at the “level of lexicon-ontology interface”.156
That is, it concentrates on how ontological concepts in a so-called reference dataset157Here defined as an ontology that describes “the semantics of the domain” [65].
Here viewed as a collection of lexical entries.
The aim of the lime module then is to provide quantitative and qualitative (metadata) information about the relations between the aforementioned kinds of resource. In other words many (though as we will see below not all) of its classes and properties will not apply in cases where OntoLex-Lemon is only used to encode a lexicon, and where entries and their senses aren’t linked to either
More generally, useful classes and properties include the
In order to show the use of these more general lime classes to relate a lexicon together with its entries, we will look at a very simple example taken from the W3C guidelines.160
This can be seen in diagrammatic form in Fig. 6. The diagram corresponds to the following listing.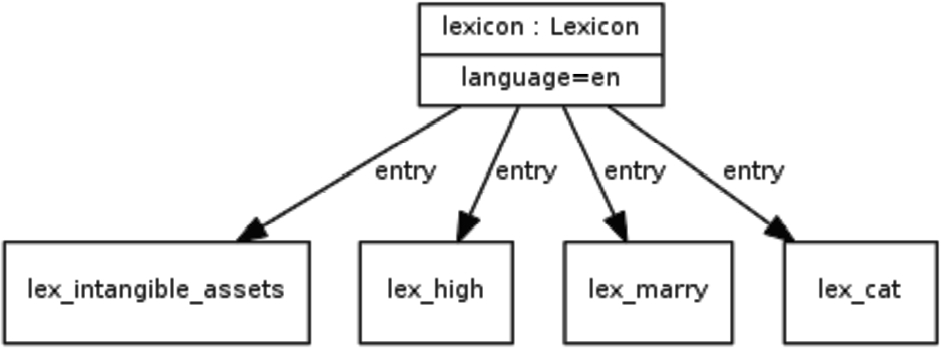
lime example (diagram taken from OntoLex-Lemon guidelines).

As the example demonstrates, lime properties and classes allow for the description of some of the most fundamental lexicon-specific metadata categories of a lexical resource. In addition, we of course use Dublin Core properties such as
The
see https://www.w3.org/2016/05/ontolex/ for a full description.
lime also defines the class
Lastly, the
Metadata for heterogeneous use cases Language Resources are often complex informational objects and as such require their description requires the use of specialised vocabularies in addition to, and in combination with, the general LLD metadata vocabularies we have mentioned above. Take for instance the case of the publication of retrodigitised dictionaries and/or the modelling of historical and scholarly lexical resources as LLD. Here there is a need for extensive metadata provision at both the lexical and the individual entry levels in order, e.g., to encode historic and bibliographic information as well as to explicitly represent scholarly hypotheses as such (as in the case of etymologies, see for instance [100]). In addition, and as mentioned in Section 4.4 above metadata for retrodigitised resources should ideally feature information on the original physical work as mentioned.
In this case, we can use classes and properties belonging to a number of other vocabularies from outside the language resource/linguistic domain. These include the Semantic Publishing and Referencing suite of ontologies for bibliographic information,162
and the CIDOC-CRM family of ontologies for dealing with hybrid informational artefacts. The challenge lies in combining these vocabularies and others together with META-SHARE and lime in creating metadata solutions, and potentially application profiles, each of which is targeted to an individual such kind of use-case. Here, the use of a top level ontology for integrating the disparate kinds of data together can be particularly useful. This however is still a fairly new area of research. A first proposal in dealing with the use-case of retrodigitised dictionaries and using CIDOC-CRM as a framework for bringing together different kinds of information in one complex hybrid object can be found in [103].The reliable identification of languages and language varieties is of the utmost importance for language resources. For applications in linguistics and lexicography it defines the very scope of investigation of the data provided by a language resource; for applications in language technology and knowledge extraction, language identifiers define the suitability of training data or the applicability of a particular tool to the data at hand.
There are two different ways of encoding language identification information currently in use in RDF datasets. The first is via a URI-based mechanism that uses terminology repositories, the other is by attaching a language tag to a literal to indicate its language.
In the latter case, the language tag is treated similarly to a data type. Language information provided in this way does not entail an additional RDF statement and allows for a compact, readable and efficient identification of language information with minimal overhead on data modelling. Note that the original RDF specifications [47] already included provision for the use of language identification via the attachment of language tags to strings. In the former case, the URI-based mechanism, there exist a number of RDF vocabularies which provide the means to mark the language of a resource explicitly using RDF triples, i.e., using properties such as
RDF language codes are defined by BCP47163
and the IANA164 registry on the basis of the ISO 639 standard for language codes.165The need for the provision of machine-readable identifiers for single languages or language varieties is clear from instances where a language has more than one name. For instance, the Manding language Bamanakan (
Yet, with language technology developing into a truly global phenomenon, it became clear that two-letter codes were not sufficient to reflect the linguistic diversity of the world both past and present – and in the present case this diversity is estimated to comprise more than 6,000 language varieties. As a response to this,
For applications in linguistics, SIL International acts as maintainer of
Changes in ISO 639-1 and 639-2 codes are very rare and occur mostly as a result of political changes, e.g., after the split of Yugoslavia, Serbian (
But ISO 639-3 only represents the basis for language tags as specified by BCP47 [137, Best Common Practices 47, also referred to as IETF language tags or RFC 4646] as incorporated into the RDF specifications. BCP47 defines how ISO 639 language tags can be extended with information regarding geographical use, script, among other variables, as follows:

where:
https://www.iana.org/assignments/language-subtag-registry/language-subtag-registry (accessed 10-07-2019).
The W3C provides means for validating BCP 47 language tags, part of the specification is also that language tags should be registered at the Internet Assigned Numbers Authority. The IANA language subtag registry172
currently provides registered language tags in XML, HTML and plain text. As of 2020, discussions about the provision of a machine-readable view in RDF and by means of resolvable URIs are in progress and are expected to bear fruit in the coming years. We expect that, by then, the IANA registry will supersede LexVo as a default provider of ISO 639(-3) language URIs.173 However, it should be noted that the very notion of language tags has been criticised as being both too inflexible and unable to address the needs of linguistics, e.g., recently by [78,168], and alternatives are being explored [79].URI-based language identification represents a natural alternative in such cases, as these are not tied to any single standardization body or maintainer, but allow the marking of both the respective organization or maintainer of the resource (as part of the namespace) and the individual language (in the local name). As a consequence, they would naturally support the shift from one provider to another, if this were required for a particular task.
Finally, another provider of language identifiers relevant to the current discussion is
That is, Glottolog allows for the specification of the phylogenetic relationships between different varieties, specifying English, for instance, as a subconcept of the category ‘Macro-English’ (macr1271), which groups together Modern Standard English and a number of English Pidgins: and relating it in its turn to narrower subconcepts such as Indian English (
Recall Max Weinreich’s famous observation that “a language is a dialect with an army and a navy”.
A Glottolog ID for a languoid, then, consists of a 4-letter alphabetic code followed by a 4-character numerical code; for instance, the Glottolog ID for standard English is
Summary In this section, we give an overview of a range of different projects that have had an impact (or which are currently having an impact) on the use and/or definition of LLD vocabularies; see Table 3 for a summary of the projects discussed in the section. In Section 6.1 we give a detailed overview of this topic; this overview includes a subsection on recent projects which combine LLD and DH (Section 6.1.1) and introduction and description of an LLD project matrix given as Fig. 7 (Section 6.1.2). Next, we describe a series of selected projects in detail. These are (in order of appearance):
LiODi (Section 6.2.1)
POSTDATA (Section 6.2.2)
ELEXIS (Section 6.2.3)
Prêt-à-LLOD (Section 6.2.5)
NexusLinguaram (Section 6.2.6)
Projects discussed in the current article
Projects discussed in the current article
As mentioned in the introduction to this paper, we take the funding, at a transnational (including European), national, and regional level, of an ever-increasing number of projects in which LLD plays a key role as evidence of the success of the latter as a means of publishing language resources. These projects also offer us a crucial snapshot of the application of LLD models and vocabularies across different disciplines and use cases, as well as indicating where future challenges may lie. Therefore, in conjunction with an information gathering task being undertaken as part of the NexusLinguarum COST action (see Section 6.2.6), we decided to carry out a survey of research projects in which a significant part of the project was dedicated to making language resources available using linked data or which had LLD as one of its main themes.
The survey has so far been carried out via queries on
As part of the preparation for the survey, we set up a Wikipedia page on OntoLex, (https://en.wikipedia.org/wiki/OntoLex) and extended another Wikipedia page on Linguistic Linked Open Data (https://en.wikipedia.org/wiki/Linguistic_Linked_Open_Data. We also encouraged partners from our respective networks to contribute and extend those pages, especially with respect to applications of OntoLex-Lemon and LLOD in general. Information retrieved as part of this process was used to complement the survey described above.
Our project survey also included an analysis of influential survey articles as well as anthologies dealing with linguistic linked data (such as [36,132]) along with a study of the programs of the major conferences in the sector of language resources.180
In particular, the Language Resource and Evaluation Conference (LREC) series and associated workshops as well as domain-specific events (workshops on Linked Data in Linguistics (LDL), conferences on Language, Data and Knowledge (LDK), lexicographic events such as EURALEX, ASIALEX, and GLOBALEX as well as the eLex series of electronic lexicography conferences, and associated workshops.
Based on this exploratory work we were able to make a number of observations. Probably the most important of these is that the effort towards the definition of common models for linguistic linked data has never been dependent on any single, large-scale project, but has largely conducted within the confines of a much broader community: a broader community whose initiatives and activities did however overlap with a number of funded projects, often carried out in parallel. Over and above this, the community was also maintained by other kinds of networks and initiatives. What also came through quite strongly, however, both from the research carried out as part of the survey and from the authors’ personal experiences is that international (and especially European level) projects played a crucial role in
The original inspiration of this model can ultimately be traced back to the Lexical Markup Framework (LMF) [69], a conceptual Uniform Markup Language (UML)-based model181
LMF also had an official XML serialization was included as part of the standard. Attempts towards a RDF/OWL serialization were made by Gil Francopoulo and can be found linked under http://www.lexicalmarkupframework.org/, but have not been otherwise published.
Monnet and LIDER were seminal in their impact on the development of LLD models and vocabularies. Other important (European) projects in this regard include the FP7 project
Additional projects with a significant recent impact on the application of LLD vocabularies include: the Horizon 2020 project
The projects which we describe in this section, along with ELEXIS, LiLa and POSTDATA described in their own sections below, are notable for bringing together DH and LLD. As is so often the case with DH projects, they aim to engage with a wide and diverse scholarly community, which includes linguists, philologists, historians, and archaeologists; in the case of the Classics (the case of LiLa in particular Section 6.2.4), there is also a reliance on, and a necessity to engage with, an extensive tradition of past scholarship. However by making it easy to structure data in a way which highlights different kinds of relationships both within and between different past civilisations, their languages and cultures, LLD offers a powerful and effective solution to the challenges of modelling heterogeneous humanities data, making it both findable and interoperable. In particular LLD is well placed to facilitate the integration of historical and geographical with lexicographic and linguistic information as the use of linked data in DH projects such as Pelagios [95], Mapping Manuscript Migrations [15] and in the Finnish Sampo datasets [89], among others, very clearly demonstrates. In the rest of this section we will provide summaries of a number of small and medium scale projects that are at the overlap of LLD and DH.
At a national level, we can list the French project
Despite the best of intentions however the RDF part isn’t currently very well developed.
Many of the projects we have mentioned have used OntoLex-Lemon or its predecessor lemon. However, a lightweight alternative to these vocabularies, and one which enables for the multilingual annotation of conceptual hierarchies, is SKOS-XL. This latter has been used, for instance, in several related projects at the Computational Linguistics lab of the University of Saarland, as part of a major effort towards the transformation of a number of influential classification schemes in the field of folk literature192
The classification schemes in question were those proposed by Vladimir Propp [144], Stith Thompson [165] and Anti Aarne, Stith Thompson and Hans-J. Uther [169].
Another project worth mentioning here, and one that also uses a range of different (L)LD vocabularies is
Based at the University of Bonn, Germany.
It is interesting to note that TDWM stands in a longer tradition of projects in the Digital Humanities that aim to complement a TEI/XML edition with terminology management using an ontology. Similar ideas have already been driving force behind the project Sharing Ancient Wisdoms (SAWS, 2010–2013)(http://www.ancientwisdoms.ac.uk/), a joint project at King’s College London, UK, the Newman Institute in Uppsala, Sweden, and the University of Vienna, Austria, funded in the context of the Humanities in the European Research Area (HERA) program to facilitate the study and electronic edition of ancient wisdom literature. Both projects employ resolvable URIs, but the linking is expressed by means of narrowly defined TEI/XML attributes rather in terms of RDF semantics. In that regard, the data published in accordance with these guidelines does not qualify as Linked Data, but can still be converted to Linked Data with moderate effort.
Finally, another recent project which exploited a range of different LLD vocabularies is
These texts were extracted from CDLI.
CoNLL was chosen, due to its flexibility and robustness, as the storage format for the multi-layer annotations which were produced and worked on as part of the project.198
A derivative internal format, called CDLI-CoNLL is employed to store the data locally – this was an essential step to support the preservation of domain specific annotation which are richer than their counterparts found in linguistic all-encompassing models. But this can be exported in CoNLL-U format, as well in Brat Standalone format, for better compatibility.
Figure 7 provides an overview in the form of a matrix of the contribution made by various different funded projects to a number of LLD vocabularies. We distinguish three kinds of contribution: namely, a project is said to have:
a vocabulary if the development of that vocabulary was a designated project goal,
to a standard if vocabulary development was not a designated project goal, but the project provided a use case or application that was discussed in the process of its development,
a vocabulary if they applied an existing vocabulary, worked with or produced data of that type
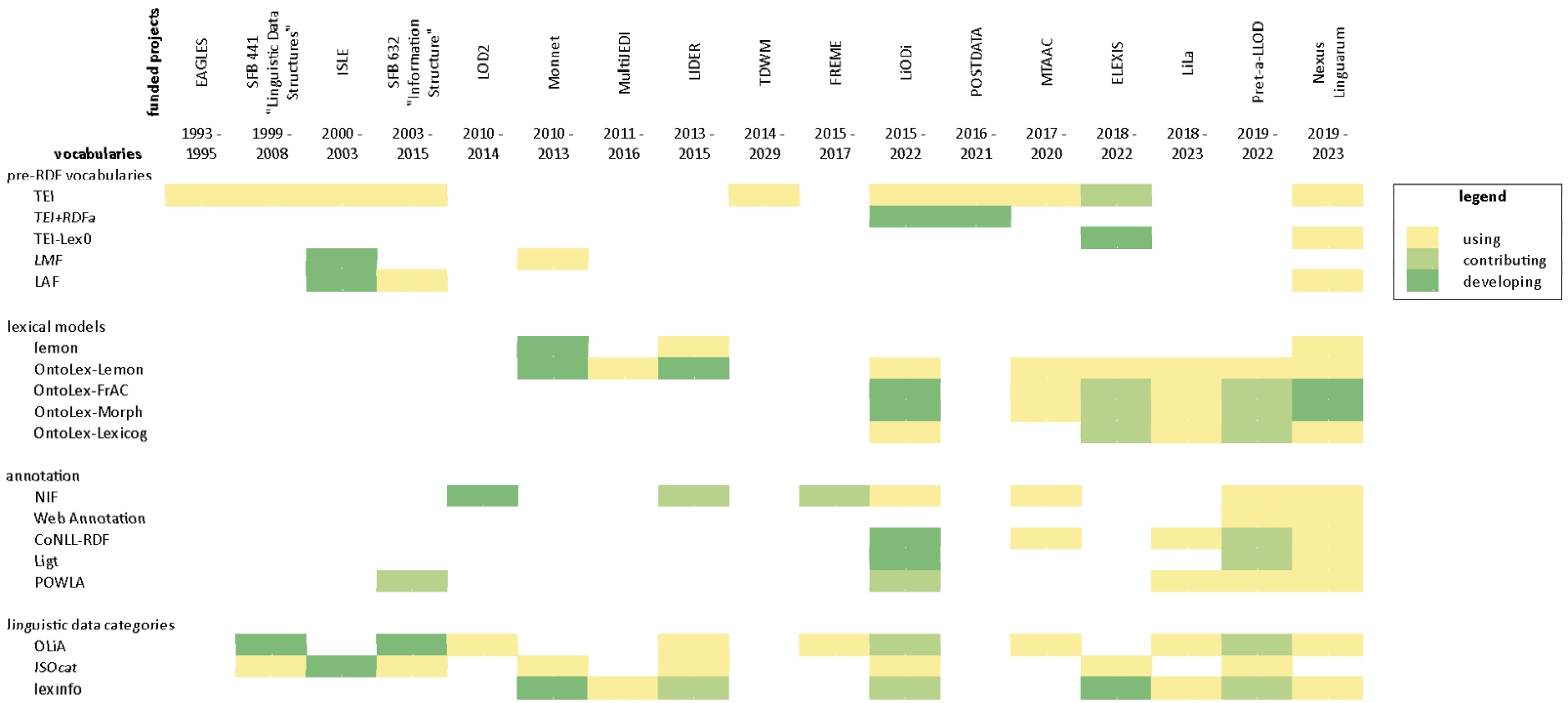
Usage of and contribution to major LLOD vocabularies by selected research projects.
Note that this survey, and indeed any survey which focuses on projects, will provide a partial view only. In particular, contributions by community groups are not explicitly covered in this section (although they are described in some depth in Section 5 and their contribution is also discussed in Sections 2.2 and 6.1). For instance the reader will notice that very few of the projects in Fig. 7 address the area of LLD for linguistic typology. In fact the interaction between linguistic typology and language technology operates primarily on the basis of informal contacts on mailing lists and via workshops and less in terms of large-scale infrastructural projects, and that, thus, the development of standard (computational) models and vocabularies has only rarely a priority in typological projects.202
There are notable exceptions here the
Note also that in this section, we have concentrated on research projects with a specific focus on linguistic linked (open) data – several of them, indeed, featuring the involvement of industrial partners – but which do not, for the most part, directly target industrial applications. More industry-focused LLD projects do exist, however, and are the basis for businesses specialising in text analytics [84], terminology and knowledge management [97] or lexicography [113]. But linked data in these contexts tends to be viewed as a technical facet that has an impact on interoperability, (re)usability and information aggregation rather than being fundamental for to the existing business model. With the increasing maturity of the technology, however, this may change over the longer term, especially in the area of establishing interoperability between AI platforms [146], their providers and users and data provided and exchanged between them [158].
To conclude then, it really has been the combination of open community initiatives and projects that determined the success and then the subsequent maintenance of the LLD models and vocabularies. The importance of funded projects is clear for the development of tools and hosting solutions for Linguistic Linked (Open) Data which are not yet in place; open community initiatives have also proven themselves vital for dissemination and wider community engagement. With the increasing maturity of OntoLex-Lemon and the convergence between existing solutions in linguistic annotation, the necessary requirements for developing large-scale Linguistic Linked (Open) Data infrastructures and their respective linking are in place, now. Note that in Section 7.1.1 below we take a brief look at the prospects for the involvement of research infrastructures in the kinds of initiatives mentioned in this section.
In what follows we will give extended descriptions of six ongoing projects. We have chosen these projects on the basis of their importance in the development of well known LLD models and vocabularies and/or in their innovative use of such. These are
LiODi (2015–2022)
The
The most important contributions of LiODi from a modelling perspective relate to the fact that its members have developed, and are in the course of developing, LLD vocabularies for a wide-range of applications in the language sciences: in particular, vocabularies with an emphasis on the requirements of low-resource languages and especially morphologically rich languages which have so far not been well served by existing formats. These vocabularies include individual, task-specific vocabularies such as Ligt and CoNLL-RDF (see 5.2.4), but also an extension of OntoLex-Lemon for diachronic relations (cognate and loan relations) [1]. In addition to that, the LiODi project (along with Prêt-à-LLOD, see 6.2.5) is the main contributor to the
More significant than lexical resources and novel vocabularies, however, are the contributions of LiODi to the development of community standards for LLD vocabularies. This includes, among other aspects, significant contributions to the emerging OntoLex-Lemon Morphology module (Section 5.1.2), initiating and moderating the development of the OntoLex-Lemon FrAC module (Section 5.1.3) and the LD4LT initiative on harmonizing vocabularies for linguistic annotation on the web.
Furthermore, LiODi has a strong commitment to the dissemination and promotion of linked data approaches to linguistics. As a demonstration of this, the project co-organised two summer schools,
Outside of conjoined activities at summer schools and datathons, the project supports numerous external partners in expertise with data modelling and language resource management. Indeed LiODi has close ties with most of the projects listed here. To mention one notable example here, a collaboration with the POSTDATA project (see the next section) and the Academy of Sciences in Heidelberg, Germany, led to the first practical applications of RDFa within TEI editions in the Digital Humanities [150,166], and ultimately to the development of an official TEI+RDFa customization (see above).
The
As part of its focus on the Semantic Web, POSTDATA is developing a poetry ontology in OWL. This ontology is based on the analysis and comparison of different data structures and metadata arising from eighteen projects and databases devoted to poetry in different languages at the European level [43–46]. The POSTDATA ontology is an encapsulated ontology model, where domain knowledge is implemented in 3 layers:
The POSTDATA metrical layer encapsulates knowledge pertaining to the poetical structure and prosody of a poem by making use of the salient (general) linguistic, phonetic and metrical concepts. From the metrical point of view, a poem is formed by stanzas that contain lines, where individuals of the latter category are understood as a list of words. Although the concept of word is present in OntoLex-Lemon and NIF, in both of these cases its definition is insufficient for capturing all of the knowledge needed for the analysis and description of a word from a metrical point of view. Indeed according to this latter the concept word should be associated both with more general linguistic information (such as its lemma) – information which is captured by the former models – as well as more specific phonetic features such as syllable, foot, feet type onset or coda along other types of metrical information. This led to the definition of a class
The second pillar of POSTDATA, the use of NLP tools, is represented by PoetryLab,214
encompasses the several different levels of poetry scholarship, from the most formal analyses relating to scansion, to more cognitive levels which concern the understanding of metaphor as well as others related to knowledge and subjective perception involving AI techniques. POSTDATA has already implemented the first level of NLP algorithms for poem analysis. These allow for the automated extraction of information from poems at different levels of description and include an Name-Entity Recognition system (NER) for medieval place names and organizations, [56] as well as automatic enjambment analysis and basic metrical scansion tools (which allow for lexical syllabification and the recognition of stressed and unstressed syllables) testing different approaches. These latter range from traditional ruled-based systems to the latest deep learning based techniques, [48–50]. The goal in this case is to use the results of these tools in order to build an RDF knowledge graph that is compliant with Postdada ontology.A follow-up to the European Network for e-Lexicography COST Action,215
the ELEXIS project is in the process of undertaking the construction of a European infrastructure for electronic lexicography [107]. LLD will play a key role in this infrastructure, namely, as means of connecting dictionaries and other lexicographic resources both within and across language boundaries. In fact, the idea of ELEXIS is to eventually construct a network of interlinked electronic lexica and other lexicographic and language resources in several languages, a network that the project calls aThe main models being used in the project are OntoLex-Lemon and the TEI Lex-0 model mentioned above [4]. And here it will perhaps be useful to give a brief description of the latter.
TEI Lex-0 and ELEXIS TEI Lex-0 is a custmomization of the TEI schema216
adapted to the encoding of lexical resources. More precisely, it was designed to enhance the interoperability of such datasets by limiting the range of encoding possibilities (offered by the current TEI guidelines) in the representation of lexical content (for instance, TEI Lex-0 has deprecated elements such asWork is also underway on a crosswalk between TEI Lex-0 and OntoLex-Lemon. The latest version of a proposed TEI Lex-0 to OntoLex-Lemon converter can be found at https://github.com/elexis-eu/tei2ontolex.
TEI Lex-0 is being developed by a special working group which (pre-Covid) organised regular in-person training schools with support from ELEXIS. Both OntoLex-Lemon and TEI Lex-0 have been previously used for smaller lexicography projects, but never in a project with such wide coverage in terms of the languages and kinds of lexicographic resource under consideration. ELEXIS has provided support to the development of both OntoLex-Lemon as well as TEI Lex-0 and a joint workshop was held between these projects at the 2019 edition of the e-lexicography convention eLex.
The project is also promoting the standardisation of OntoLex-Lemon and TEI Lex-0 through the OASIS working group on Lexicographic Infrastructure Data Model and API (LEXIDMA),218
where the intention is to produce a new unifying standard for lexicographic data that will be serialised in both OntoLex-Lemon and TEI Lex-0.The impact of ELEXIS on the use of OntoLex-Lemon ELEXIS aims to provide support for the creation and editing of dictionary resources using OntoLex-Lemon. To this end extensive teaching materials are also being developed as part of the project with the aim of introducing lexicographers to linked data and the OntoLex-Lemon model. It should be noted that the availability of manuals and targeted teaching materials plays an important factor in increasing the uptake of models such as OntoLex-Lemon and technologies such as linked data, (as of course is the case with new technologies and new technological approaches in general), especially amongst users who haven’t had much previous exposure to linked data or conceptual modelling. The original designers of such models are usually unable to take into consideration of every kind of use-case for which the model might be used. Such targeted training materials can help to bridge the gap between a general purpose model as it is presented in some final set of guidelines, and its use or appropriation (along with other pertinent models and vocabularies) in a specialist domain or task (the use of design patterns can also help in this respect, see Section 7.1.2). This is also one of the motivations behind the strong emphasis on training in NexusLinguaram (see Section 6.2.6).
Both the production of training materials and the push to promote OntoLex-Lemon as a common serialisation format for a standard for e-lexicography seems to promise much in terms of the future use of linked data in this domain. It is inevitable that the experiences of lexicographers and linguists in using OntoLex-Lemon (and its lexicographic extension, see Section 5.1.1) both within and outside of the ELEXIS project to create and edit lexicographic resources will have an important impact on the use of the model and also, potentially, on future extensions and/or versions of OntoLex-Lemon.
The
As Latin is characterized by a very rich morphology (where, for instance, a single verb can potentially yield more than 100 forms, excluding the nominal inflection of participles), LiLa focuses on lemmatization as the key task that allows for a meaningful and functional connection between the different layers of annotation and information involved in the project. Indeed, while lemmas are used by lexica to label entries, lemmatization is often performed in digital libraries of Latin texts to index words and is included in most NLP pipelines (like e.g. UDPipe)220
as a preliminary step for more advanced forms of analysis.221For the state of the art in automatic lemmatization and PoS tagging for Latin, see the results of the first edition of
LLD standards such as OntoLex-Lemon (see Section 5.1) provide an adequate framework to model the relations between the different classes of resources via lemmatization, while also offering a robust solution for modelling the information contained in most lexica. The central component in LiLa’s framework, the gateway between different projects, is the collection of canonical forms that are used to lemmatize texts (called the
The lemma bank can be queried using the
The forms in the lemma bank are described in an OWL ontology that reuses several concepts from the LLD standards discussed in the previous sections. The canonical forms are instances of the class
The fact that OntoLex-Lemon forms are allowed to have multiple written representations is a particularly helpful feature for a language which is attested across circa 25 centuries and in a wide spectrum of genres, and which is, moreover, characterised by a substantial amount of spelling variation. Harmonising different lemmatisation solutions adopted by corpora and NLP tools, however, requires practitioners to deal with other kinds of variation as well [117]. In the case of words with multiple inflectional paradigms or forms which may be interpreted as either autonomous words or inflected forms of a main lemma (such as participles, or adverbs built from adjectives: see e.g. English “quickly” from “quick”), different projects may vary considerably in the adopted strategies. For these reasons, the LiLa ontology introduces one sub-class of the
Currently, the canonical forms in the LiLa lemma bank connect lexical entries of four lexical resources. Two lexica provide etymological information, modelled using the OntoLex-Lemon extension lemonEty [100], respectively dealing with the lexicon inherited from proto-Indo-european223
[118] and loans from Greek224 [71]. The polarity lexicon LatinAffectus connects a polarity value (expressed using theIn addition to lexica, two annotated corpora are currently linked to the LiLa lemma bank. The Index Thomisticus Treebank228
provides morpho-syntactic annotation for 375,000 tokens from the Latin works of Thomas Aquinas (13th century CE), while the Dante Search corpus229 includes the lemmatized text of four Latin works of Dante Alighieri (14th century), which are currently undergoing a process of syntactic annotation following the Universal Dependencies annotation style [18].230 The POWLA ontology was used to represent texts and annotations for both corpora. However, the link between a corpus token and a lemma of the LiLa collection was expressed using a custom propertyThe goal of the
In its linking aspect, Prêt-à-LLOD explores technologies to facilitate the linking between and among lexical, terminological and ontological resources. In this context, it has provided significant support to the development of OntoLex-Lemon, including the development of a module for lexicography, a module for morphology, and corpus information (all of which are discussed in Section 5.1). Further extensions for terminologies and linking metadata (Fuzzy Lemon) have been proposed in the context of the project, as well. In addition, the project is contributing models for dataset linking to the Naisc project 232
that provides a toolkit for generic dataset linking.Prêt-à-LLOD provides a generic framework for transforming, enriching and manipulating language resources by means of RDF technology [62]. The idea here is to transform a language resource into an equivalent RDF representation, to manipulate and enrich it with a SPARQL transformation and external knowledge, and to serialize the result in RDF or non-RDF formats. To the extent that different formats can be mapped to or generated from the same RDF representation, they can be transformed one into another. For lexical data, the OntoLex-Lemon model and its aforementioned extensions represent a de facto standard and are being used as such. For linguistic annotations, several competing standards exist, and Prêt-à-LLOD contributes to on-going consolidation efforts within the W3C CG Linked Data for Language Technology with case studies on and support for CoNLL-RDF, NIF, Ligt, POWLA, and OLiA (see Section 5.2).
Prêt-à-LLOD provides a workflow management system, a metadata repository for language resources, and machine-readable license information. In that regard, it also contributes to the development of metadata standards. This work is leading to a new version of the Linghub site [122],233
that is based around the DSpace open source software repository as well as the linking technologies to provide a single authoritative source of information about language resources across a wide range of languages.The key priority of Prêt-à-LLOD, however, is less to develop novel vocabularies, than to develop technical solutions on that basis. Accordingly, Prêt-à-LLOD involves four industry-led pilot projects that are designed to demonstrate the relevance, transferability and applicability of the methods and techniques under development in the project to concrete problems in the language technology industry. The pilots showcase potentials in the context of various sectors: technology companies, open government services, pharmaceutical industry, and finance, details of which are described in [53] As overarching challenges, all pilots are addressing facets of cross-language transfer or domain adaptation to varying degrees. Particularly relevant to LLOD, the project is developing tools that are helpful to practical lexicographic applications, including for the Oxford Dictionaries [153].
Notable project results in the context of this paper are
Christian Chiarcos, Philipp Cimiano, Julia Bosque-Gil, Thierry Declerck, Christian Fäth, Jorge Gracia, Maxim Ionov, John McCrae, Elena Montiel-Ponsoda, Maria Pia di Buono, Roser Saurí, Fernando Bobillo, Mohammad Fazleh Elahi (2020), Report on Vocabularies for Interoperable Language Resources and Services, available from https://cordis.europa.eu/project/id/825182/results.
The
One of the main research coordination objectives of NexusLinguarum is to propose, agree upon and disseminate best practices and standards for linking data and services across languages. In that regard, an active collaboration has been established with W3C community groups for the extension of existing standards such as OntoLex-Lemon as well as for the convergence of standards in language annotation (see Section 5). Several surveys of the state of the art are also being drafted by the NexusLinguarum community covering different salient aspects of the domain (e.g., multilingual linking across different linguistic description levels). A number of activities organised by NexusLinguarum have been planned with the aim of fostering collaboration and communication across communities. These include scientific conferences (e.g., LDK 2021236
), and training schools (e.g., EuroLAN 2021237), where linguistic linked data will take on a central role. Finally, NexusLinguarum is also devoted to the collection and analysis of relevant use cases for linguistic data science and to developing prototypes and demonstrators that will address a selection of prototypical cases. In an initial phase, the definition of use cases will cover Humanities and Social Sciences, Linguistics (Media and Social Media, and Language Acquisition), Life Sciences, and Technology (Cybersecurity and FinTech). The COST action also places a strong emphasis on lesser resourced languages.A NexusLinguarum use case: ReTeRom As an example of the kinds of complex, heterogeneous resources which have been proposed by consortium members as candidates for modelling and publication as linked data with the support of members of the COST action, we will look at the corpora being produced in a Romanian language project.
The ReTeRom (Resources and Technologies for Developing Human-Machine Interfaces in Romanian) project238
is working towards adding the Romanian language to the multilingual Linguistic Linked Open Data cloud.239Note that several Romanian language resources (e.g. Romanian WordNet (RoWN), Romanian Reference Treebank (RoRefTrees or RRT), Corpus-driven linguistic data, etc.) are currently in the process of conversion to LLD. The converter implementation is open source (https://github.com/racai-ai/RoLLOD/).
SINTERO (Technologies for the Realization of Human-Machine Interfaces for Text-to-Speech Synthesis with Expressivity), coordinated by Technical University of Cluj-Napoca (UTCN), primarily aims to implement a text-speech synthesis system in Romanian that allows the modelling and control of prosody (intonation in speech) in an appropriate way of natural speech. Secondly, SINTERO aims is to create as many voices synthesised in Romanian as possible (in this project at least 10 voices), so that they too can be used by an extended community, including in commercial applications [114].
TEPROLIN (Technologies for Processing Natural Language – Text) which is coordinated by the Research Institute for Articifial Intelligence “Mircea Drăgănescu” (ICIA), aims to create Romanian text processing technologies that can be readily used by the other component-projects of ReTeRom. For instance, higher layers of annotation may be performed using TEPROLIN services: on the speech component – the prosodic annotation (e.g. decrease of the fundamental frequency) and on the textual component – sub-syntactic (e.g. clauses) and syntactic annotation (e.g. parsing trees). TEPROLIN works inside a major language processing and text mining platform such as UIMA, GATE or TextFlows [93].
TADARAV (Technologies for automatic annotation of audio data and for the creation of automatic speech recognition interfaces), coordinated by the University Politehnica of Bucharest (UPB), primarily aims to develop a set of advanced technologies for generating transcripts aligned correctly with the voice signal from the body collected in the CoBiLiRo component project. Secondly, TADARAV aims to increase the accuracy of the current SpeeD automatic speech recognition system [76] by requalifying its acoustic model based on the entire body of speech collected and using more powerful language models generated in the TEPROLIN component project.
CoBiLiRo (Bimodal Corpus for Romanian Language), coordinated by the “Alexandru Ioan Cuza” University of Ias,i (UAIC), is working with a large collection of parallel speech/text data [42]. This collection is annotated at different levels of both the acoustic and the linguistic components [77], something which greatly facilitates querying, editing and the carrying out of statistical analysis. Three types of formats pairing speech and text components were identified in the building of the CoBiLiRo repository: (1) PHS/LAB, a format which separates text, speech and alignment in different files; (2) MULTEXT/TEI, a format described initially in the MULTEXT project and later used in the building of various language resources; (3) TEXTGRID, a format supported by a large community of European developers and used in a large set of existing resources. In order to share and distribute these bimodal resources, a standard format for CoBiLiRo has been proposed, inspired by the TEI-P5.10 standard [164] and based on the idea of alignment between the speech and text components, taking into consideration several annotation conventions proposed in 2007 by Li and Zhi-gang [111]. At present, the header of this format includes the following metadata: source of the object stored; speaker’s gender; speaker’s identity (if she/he agreed to this); vocal type (spontaneous or in-reading); recording conditions; duration; speech file type; speech-text alignment level, etc. Moreover, the CoBiLiRo format allows for three types of segmentation (“file” – adequate for resources held in multiple files, “startstop” – adequate for resources that include only one speech file, and “file-start-stop” – a combination of the two types described before) and speech-text alignment, marked using <unit> tags. A <unit> tag includes two child nodes: the <speech> that names the file containing the speech component and the <text> that points to the corresponding textual transcription file.
As we hope the preceding example has demonstrated (and it is only one of numerous case studies within the project straddling several different disciplines, media and technical domains) the NexusLinguaram COST action has enormous potential as a testing ground for many of the new vocabularies and modules mentioned above.
We have attempted, in the present article to give a comprehensive survey and a near-exhaustive243
We were certainly exhausted after writing it.
As we hope that the article has demonstrated, LLD is an extremely active and dynamic an area of research, with numerous projects and initiatives underway, or due to commence in the short term, which promise to bring further updates and improvements in coverage and expressivity in addition to what we have described here. For this reason, and in a vain attempt to stave off the risk of rapid obsolescence, we have attempted throughout this article to situate our descriptions of recent advances in the field within a discussion of more general, ongoing trends. Indeed this was our specific intention with Section 2 and in many other parts of the article: we want this survey to give the reader a good idea both of the future challenges which have yet to be fully confronted in LLD as well as the areas of immense opportunity which currently remain untapped.
In this rest of this section we will summarise the future prospects/challenges described in this paper. In the next and final subsection, Section 7.1, we focus on two particular areas and suggest a possible future trend and a proposal for a further direction of research.
A summary of the present article In Section 4, we gave an overview of the most well known and widely used models for linguistic linked data, emphasising their FAIR-ness, and in particular: their accessibility via ontology search engines, whether and how licensing information is made available, and how versioning is handled; we saw how, in many cases, there still remained work to be done in these areas. We classified these models into different kinds of resource based on the LLOD cloud; this helped us to show how some areas were better served than others. We also briefly discussed the provision of dedicated tools for LLD models; again this is an area which is still very much under development.
Next, in Section 5 we looked at the latest developments in LLD community standards. This section was divided into a subsection discussing OntoLex-Lemon related developments (Section 5.1), a section on the latest developments regarding LLD models for annotation (Section 5.2), and a section on metadata (Section 5.3). Each of these sections features a detailed description of different initiatives in their respective areas (including those still in progress), including in the case of Section 5.2 and Section 5.3 discussions of future trends and prospects (Section 5.2.5 and Section 5.3.3 respectively). The main challenge in the case of LLD vocabularies for annotation is to respond to the need for a convergence of vocabularies. In the case of metadata vocabularies we looked at coverage issues, especially with regard to language identification.
Then in Section 6 we presented an overview of the impact of projects on the definition and use of LLD models and vocabularies. We focused on a number of ongoing projects and looked at their current and potential future contributions to LLD models and vocabularies. In the rest of this concluding section we will look at one important potential future trend, the involvement of research infrastructures alongside community groups and projects in the definition and ongoing development of models and vocabularies (Section 7.1.1. We will also make a proposal for handling the increasing complexity of LLD vocabularies (especially in the domain of language resources), namely, the recourse to ontology design patterns (Section 7.1.2).
Linguistic linked data, projects, and research infrastructures
Throughout this article we have sought to underline the role of research projects alongside that of community groups such as the Open Linguistics Working Group or the W3C Ontology-Lexicon Community Group in driving the development of LLD vocabularies and models. Moving ahead however, the role of SSH research infrastructures (RI) could also begin to play an important role by helping to ensure longer term hosting solutions and the greater sustainability of resources and tools based on these models. RIs could also help to give long term support to the community groups which are developing such models and vocabularies: in addition to and in a complimentary way to the support received from projects and COST actions in the short-to-medium term. In this, inspiration can be taken from cases such as that of TEI Lex-0 (described in Section 6.2.3) an initiative which has been supported both by a number of funded projects and COST actions as well as by the DARIAH “Lexical Resources” Working Group.244
Related to this, RIs could also assist in the dissemination of LLD vocabularies and models, making them more accessible to wider numbers of users and cutting across different disciplinary boundaries via the kinds of training and teaching activities in which they have already established expertise. In other words, the Linguistic Linked Data community could exploit both the technical and the knowledge infrastructures provided by such
A textual summary of the virtual event and recordings of the presentations and discussion can be found here https://www.clarin.eu/event/2021/clarin-cafe-linguistic-linked-data.
Note that although we do not discuss it here (as it would have shifted us too far into the realms of research policy), the role played by the European Open Science Cloud (https://eosc-portal.eu/)will also be crucial here (at the very least for projects and initiatives taking place in Europe) and especially for its promotion of FAIR data.
The OntoLex-Lemon model has come to be used in (or has at least been proposed for) a wide range of use cases belonging to an increasing number of different disciplines and types of resource. As we have seen, the original model is currently being extended to cover new kinds of use cases by the W3C OntoLex-Lemon group through the definition and publication of new extensions each of which carries its own supplementary guidelines. In the long term, however, this has the potential to become very complicated very quickly.
As an example, take the modelling of specialised language resources for such areas as the study of morpho-syntax or historical linguistics (in the former case these are dealt with in in part in the original guidelines and in the new morphology module). In both of these cases, there are so many different types (and sub-types) of resource as well as varieties of theoretical approach and diversities of schools of thought (not to mention language-specific modelling requirements) that it would be difficult to produce guidelines with detailed enough provision for any and all of the exigencies that might potentially arise. Or instead, take the modelling of lexicographic resources (something which falls within the compass of the lexicog extension, Section 5.1.1). This could encompass numerous different kinds of sub-cases – e.g., etymological dictionaries, philological dictionaries, rhyming dictionaries – each of which brings its own specific varieties of modelling challenges. And moreover there often exist distinct technical solutions to given modelling problems without a strong enough consensus on any single one of these to make it the default. Such, for instance, is the case with modelling ordered sequences in RDF.
One way of handling this potential modelling complexity that avoids the drafting of ever more elaborate guidelines in conjunction with the definition of ever more specialised modules is via the publication and maintenance of a repository of
The idea would be to define, promote, and collect OntoLex-Lemon specific design patterns (as well as those pertaining to other similar vocabularies) within the LLD community and beyond. This is not a completely new idea and design patterns had been created for OntoLex-Lemon’s predecessor lemon in the past. These previous patterns are currently available on github247
and offer templates for the creation of nominal, verbal and adjectival lexical entries as well as more specific kinds of these such as Relational Nouns, State Verbs and Intersective Adjectives. They are fairly limited in scope however and so our proposal would be for the creation of patterns covering a far wider variety of different areas/kinds of use cases. These new patterns would deal with the various sections of the W3C OntoLex-Lemon guidelines, such as for example the syntax and semantics and the decomposition sections, along with the lexicography module and the forthcoming Morphology and Frequency Attestation and Corpus (FrAC) modules. Each new pattern would follow the set of criteria proposed in for instance [143] for Content ODPs and would be based on competency questions, e.g., potential SPARQL queries.These OntoLex-Lemon ODPs could then either be hosted on the ontology design patterns site,248
or a special repository, or both. They would provide a bridge between the OntoLex-Lemon guidelines and concrete applications; they would help to prevent those guidelines from becoming overly-complicated and unwieldy and would keep the extensions themselves as simple (and hopefully uncontroversial) as possible.249Although of course the original modules would still need to be revised and extended on the basis of new kinds of use-cases/modelling needs; ODPs would help to keep these to a minimal.
Footnotes
The OntoLex-Lemon model
In order to make the current paper as self-contained as possible, we have decided to include a brief introduction to the OntoLex-Lemon model which constitutes the current appendix. In what follows, we will start by describing the core module of OntoLex-Lemon using an example entry. We will then describe each of its different submodules by developing this example entry. The full guidelines (with additional examples) can be found at: https://www.w3.org/2016/05/ontolex/. Note that this appendix only covers the very basics and can be skipped by those who already have some familiarity with the OntoLex-Lemon model.
Acknowledgements
The authors thank Milan Dojchinovski and Francesca Frontini for several very helpful suggestions. This article is based upon work from COST Action NexusLinguarum – European network for Web-centered linguistic data science (CA18209), supported by COST (European Cooperation in Science and Technology). The article is also supported by the Horizon 2020 research and innovation programme with the projects Prêt-à-LLOD (grant agreement no. 825182) and ELEXIS (grant agreeement no. 731015). It has been also partially supported by the Spanish project PID2020-113903RB-I00 (AEI/FEDER, UE), by DGA/FEDER, and by the Agencia Estatal de Investigación of the Spanish Ministry of Economy and Competitiveness and the European Social Fund through the “Ramón y Cajal” program (RYC2019-028112-I).