
Abstract
BACKGROUND:
This cross-sectional retrospective study utilized Natural Language Processing (NLP) to extract tobacco-use associated variables from clinical notes documented in the Electronic Health Record (EHR).
OBJECITVE:
To develop a rule-based algorithm for determining the present status of the patient’s tobacco-use.
METHODS:
Clinical notes (
RESULTS:
The initial Cohen’s kappa (
CONCLUSIONS:
NLP and the rule-based algorithm exhibited utility for deriving the present tobacco-use status of patients. Current strategies are targeting further improvement in precision to enhance translational value of the tool.
Keywords
Introduction
Despite the fact that tobacco use is the most common preventable cause of death, every year about 480,000 people in the United States (U.S) and about 6 million people globally die from tobacco-related illnesses [1, 2]. Studies have shown that tobacco consumption is the most putative etiological factor in the development of cancers in the oral cavity, lungs and breast and represents a high risk to patients globally [3, 4, 5, 6, 7].
The National Ambulatory Medical Care Survey (NAMCS) defines “tobacco use” as documentation of latest status of tobacco use in the patient’s medical record [8]. Clear and compelling evidence found by the U.S. Preventive Services Task Force (USPSTF) showed that intervention by healthcare providers utilizing strategies such as interview, counselling and documentation of patient’s tobacco use status were effective for tobacco use cessation, prevention and oral cancer surveillance [9, 10].
Historically, healthcare providers have recorded tobacco use status as free-text in clinical notes (corpora) to document patient tobacco use history [11, 12]. Presently, the documentation of tobacco use as a part of Meaningful Use (MU) criteria is entered in a structured format in the Electronic Health Records (EHRs) [13]. The structured data informs whether the patient is a current, former or a nonsmoker while the corpus captures details surrounding frequency, duration and cessation of tobacco use. At every subsequent patient visit, the EHR only shows the latest tobacco use status but not a collective status.
As an aspect of an oral cancer risk assessment research initiative (OCRARI), this study was proposed to develop a pipe-line to mine and include variables related to tobacco use from the EHR for predicting oral cancer risk [14]. The input variables for use in OCRARI required the collective status of the patient’s tobacco use. Marshfield Clinic, a large regional healthcare delivery system serving communities in western, central and northern regions of Wisconsin, implemented structured data collection of tobacco use in 2005 in its home-grown EHR. In addition to the structured data, details including tobacco use history, patient age at time of tobacco consumption and cessation were recorded in the corpora. Thus the structured data captured only some aspects of tobacco use (such as patient’s narrative of tobacco status at the time of visit) while the corpora provided a rich source of supplemental relevant information. This structured information was not available for all the patients, and hence to address this research question, an effort to electronically extract relevant information from the corpora to derive the present tobacco status by applying rule-based algorithm was undertaken in this study.
Related work
Natural Language Processing (NLP) has proven to be very useful in extracting information from the free-text documents and presenting it in a structured format [15, 16, 17, 18]. State-of-the-art NLP systems are efficient at identifying text in medical record documents surrounding symptomology, diagnoses and other aspects associated with health-related conditions [19, 20, 21, 22, 23]. However, limitations such as misinterpreted sentence boundaries, missing terms and word ambiguities have also been identified [24]. Compiling and synthesizing all relevant documents associated with a single patient into a cohesive ‘big picture’ is challenging even when attempted manually [25].
Historically, studies have applied rule-based classifiers to consolidate patient documents surrounding smoking status in order to stratify patients into one of the following four classes: ‘Current smoker’, ‘Past smoker’, ‘Nonsmoker’ and ‘Unknown’ [5, 26, 27]. Liu et al. showed that the patient-level classification could be accomplished by taking into account the frequency of occurrences of ‘Nonsmoker’, ‘Past Smoker’ and ‘Current Smoker’-classified documents in designating the overall classification of the patient [5]. Other studies incorporated temporal relationships by taking dates into consideration during patient-level classification [26]. For example, Nikfarjam et al. extracted dates from the corpora to create a ‘timeline’ of the patient’s medical history and classified the patient accordingly [26]. This was done by association of events to the admission and discharge times mentioned in the corpora.
Research objective
The objective of this retrospective study was to electronically extract relevant information from the corpora to deduce a collective tobacco use status of a patient from the corpus using rule-based algorithm. Moreover, the application of this study will extend to the identification of collective status of tobacco use based on the history of the patient’s tobacco consumption. Findings from this study may have inherent clinical utility based on establishment of capacity to correctly classify tobacco utilization status through data mining, thus enabling researchers and healthcare providers to identify patient cohorts, who may be eligible for tobacco use counselling and ultimately tobacco use cessation.
Materials and methods
The current study was conducted in two phases: first, to utilize NLP to extract tobacco use associated variables from clinical notes documented in the EHR and second, to develop an algorithm for determining the collective status of the patient’s tobacco use. This was contextually derived from the longitudinal history of tobacco usage recorded in corpora, irrespective of whether status was captured as structured data. The methodology presented herein describes a novel deductive strategy that defines collective status of patient’s tobacco use based on history captured in EHR clinical notes.
The study was reviewed and approved by the Marshfield Clinic Research Institute’s Institutional Review Board for research involving human subjects. A cross sectional retrospective study design was applied targeting extraction of data from Marshfield Clinic’s Enterprise Data Warehouse (MC-EDW) which houses clinically collected data surrounding the patient smoking status history among myriad of other patients’ health related data.
Data retrieval
Retrospective data was mined from MC-EDW canvasing the temporal frame of 36 years from 1979 through 2015. We randomly selected 400 patients from a pool of approximately 10 million patients and retrieved their corresponding clinical notes (5,371 documents) for analysis. For every clinical document, there existed a file ID, document ID and patient ID. File ID and document ID are reference identifiers within the electronic medical record documentation database. Patient ID is a number assigned to a patient for identification purposes.
Documents were further tagged with a ‘service date’, which corresponded to the date on which the document was created. The service date provided a temporal trajectory for each patient.
Phase I: Corpus-level classification
The NLP software used was cTakes (Clinical Text Analysis and Knowledge Extraction System), an open-source software hosted by the Apache Software Foundation. Each document was processed by the cTakes software [28]. The sentences in the documents were parsed and tokenized. We used cTakes smoking pipeline to partition and sort patients into one of the following four classes: ‘Current smoker’, ‘Past smoker’, ‘Nonsmoker’ and ‘Unknown’, informed by the historical data in their respective corpora. A 30-day abstinence threshold was defined as a prerequisite for assigning a ‘past smoker’ status where a history of tobacco use was recorded [1, 29, 30]. ‘Current smoker’ status was based on the definition of the National Survey on Drug Use and Health (NSDUH), and based on tobacco use habits reported by the patient over the preceding 30 days [1]. Feature extraction was done by cTakes using sentence boundary detector, tokenizer, part-of-speech tagger, shallow parser and named entity recognizer [28]. The part of speech tagger classified corpora that had features relevant to tobacco consumption in the present tense (e.g. smoking, tobacco chewing, smoking among others) as ‘Current Smoker’. Similarly, corpora which had features mentioned in the past tense (e.g. smoked, chewed etc.) or had a mention of ‘quit smoking’ were classified as ‘Past Smokers’. The ‘Nonsmoker’ status was assigned to corpora where there were specific mentions of the term ‘nonsmoker’ or ‘does not smoke’ or phrases in those lines. The ‘Unknown’ class was defined by the absence of any tobacco use information in a corpus. The output from cTakes was in the form of XML (Extensible Markup Language) documents corresponding to each corpus analyzed. A post-processor (Windows-based application developed in C#) was subsequently used to analyze XML documents (described further in the Post-processing section). The architecture of this process is shown in Fig. 1.
Text analysis architecture.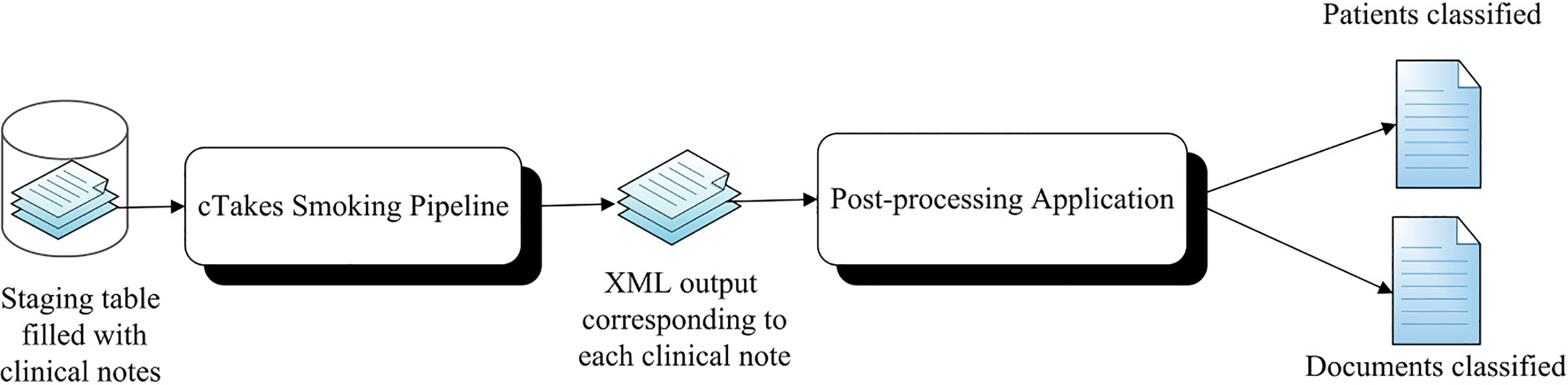
User Interface of the data abstraction tool displaying the annotated corpus.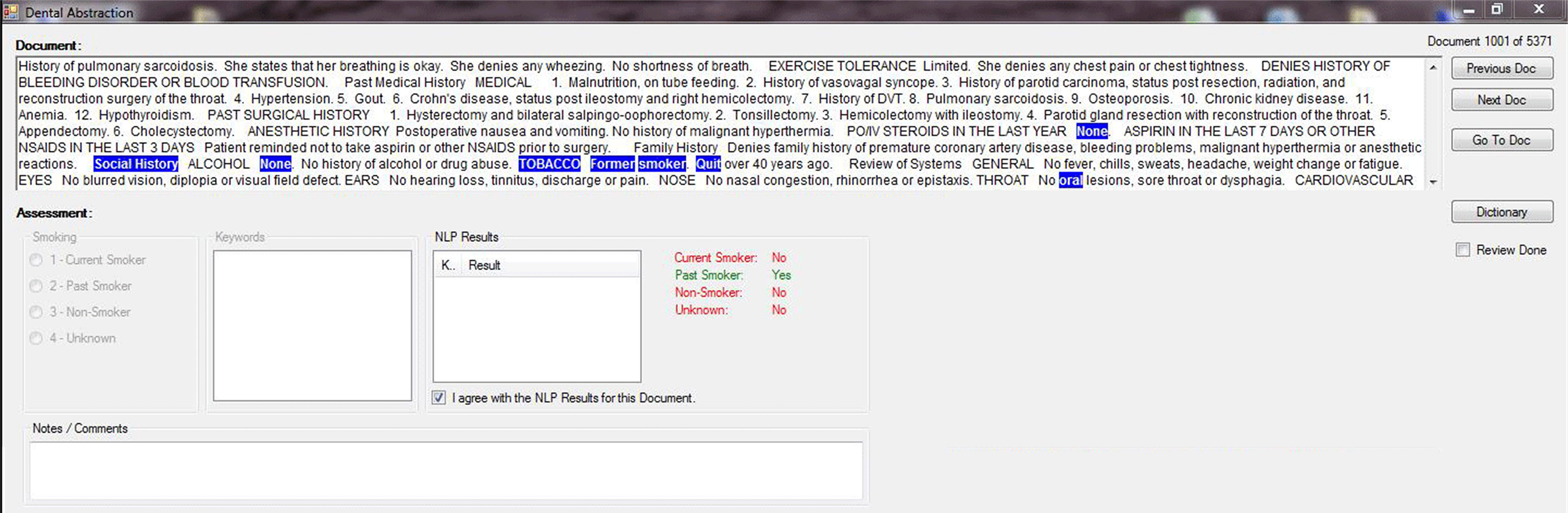
2.1.1.1. Post-processing
The post-processor received the cTakes XML outputs as inputs and carried out further processing. The ‘File Id’ and ‘Document Id’ were captured from the XML files and mapped back to the ‘Patient Id’, thus establishing the association between the clinical note and the corresponding patient. The XML files also provided information about the document’s classification into the previously defined tobacco use classes: Current Smoker, Past Smoker, Nonsmoker and Unknown. After classification of all documents, the rows were arranged first by ‘Patient Id’ (ascending order) and then by ‘Service Date’ (descending order). This helped define the temporal trajectory for each patient.
2.1.1.2. Validation
All 5,371 documents were classified by two coders (NS and HH) using a data abstraction tool (Fig. 2). This tool was developed for the purpose of ascertaining cTakes smoking pipeline reliability with respect to classifying documents into the 4 tobacco-use status classes. The data abstraction tool read each clinical note and highlighted the keywords relevant to tobacco use. An expandable keywords-list was dynamically created which was continually updated by the coders based on recurrence of these words within clinical documents and facilitate their identification during document scans. The main body of the interface contained the clinical note. The top right corner of the interface provided with the document count and navigation buttons were used to scan the document as follows. The ‘Previous Doc (document)’ and ‘Next Doc’ helped navigate to the previous and next documents, respectively. In addition, the ‘Go to Doc’ button could be used to navigate directly to a specific clinical note provided that the document count was known. All terms highlighted in blue were present in the list of keywords (‘tobacco’, ‘smoker’, ‘quit’ etc.). The keywords were added to the software by clicking on the ‘Dictionary’ button. Creation of the glossary expedited identification of relevant terms in the document. Once the annotation was completed, the “Review Done” checkbox was selected by the annotator. The ‘Assessment’ section at the bottom of the interface captured the cTakes’ evaluation result. The output of the cTakes result was displayed on the right side (NLP Results) in green whereas the left side (Smoking) documented manual annotation. If the result from cTakes was in agreement to the coders’ classification of the document, the checkbox, “I agree with the NLP results for this document” was checked by the annotator. If consensus for classification was not achieved, the annotator selected the correct class.
2.1.1.3. Statistical analyses
The two coders each initially classified 1,000 same documents manually to identify any disparities in their logic and to develop a consensus process. The interrater agreement was determined by calculating the Cohen’s kappa derived from SAS proc FREQ with AGREE option, for the classification of these 1,000 documents. The two coders later classified 4,000 documents (2,000 each) based on the rules established during the consensus process. Finally the two coders independently classified the remaining 371 documents. The Cohen’s kappa calculations were compared with the inclusion of a 95% confidence interval which was constructed by applying the exact Binomial Distribution Approach.
Consensus: When inconsistencies in classification of a document between the two coders occurred, another member of the research team (AA) mediated establishment of consensus on for definition of the final classification. This set the classification rules and mitigated any ambiguities, establishing the gold standard for future classification by the coders. The final algorithm was evaluated for precision, recall, specificity, F-measure and accuracy for each tobacco use classification based on the outcomes of manual validation.
Precision was defined as the proportion of the predicted ‘true positive’ cases actually being real positive cases and was calculated by the following formula:
Recall was defined as the proportion of correctly predicted ‘true positives’ and was calculated by the following formula:
Specificity was defined as the proportion of correctly predicted ‘true negatives’ and was calculated by the following formula:
F-measure is defined as the harmonic mean of precision and recall and was calculated by the following formula:
Accuracy was calculated by the following formula:
A ‘True positive’ for a given class corresponded to accurate classification of the document into a given class. Based on this definition, a ‘false positive’ for a class corresponded with incorrect classification of a document into that class. Similarly ‘true negative’ for a class corresponded with a document being correctly classified as not corresponding with a class other than the one for which it was a ‘true positive’, and ‘false negative’ for a class corresponded to a document being incorrectly classified as negative in an index class. A low value for ‘true positive’ and/or high value for ‘false positive’ was associated with low precision.
All available corpora-based data for each patient were analyzed by a rule-based classifier developed as part of this study, which determined the present tobacco-use status of the patient based on the timestamps of the corpus generation.
Rule-based algorithm: The program first arranged all documents by patient and then chronologically with the latest document on top followed by the earlier ones. A 30-day tobacco-use abstinence period was set to distinguish current and past smoker status. If the latest document was classified as ‘Current Smoker’, the patient was classified as ‘Current Smoker’ and preceding history had no impact on the final classification. If the latest document was classified as ‘Past Smoker’, the previous document classifications were examined. If any of the previous documents were classified as ‘Current Smoker’ and was created within 30 days of the latest document, the patient was automatically re-classified as a ‘Current Smoker’. If a patient had just two documents created within 30 days with the latest one classified as ‘Nonsmoker’ and the other one as ‘Current Smoker’, the patient would be re-classified as a ‘Current Smoker’. Using the same example, if the timespan between the dates was
2.1.2.1. Validation
The same two coders manually classified tobacco-use status of 40 randomly-selected patients based on the gold standard document classification as well as the document-level classification derived from cTakes. This process tested and validated the rule-based algorithm developed during the post-processing (Fig. 3). Since the rules for this algorithm were strictly set, there could be no ambiguities between the annotator decisions and hence an inter-rater agreement was not determined at this level.
The classifications for each clinical document were consolidated to form a patient-level classification based on a rule-based algorithm developed by the team.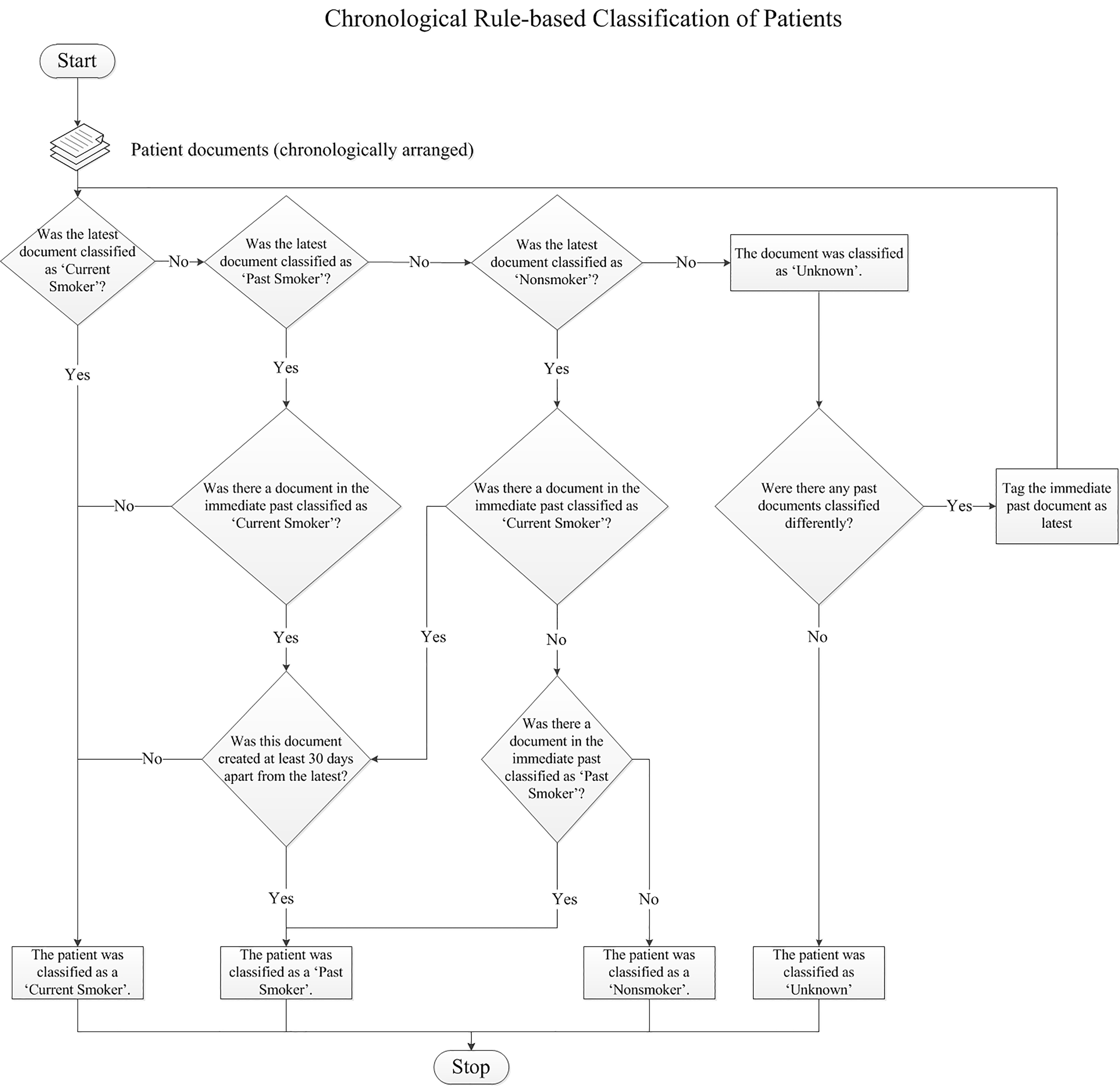
Of the 400 patients randomly selected for the study analysis, 37 patients did not have any clinical notes documented and hence were excluded from the study. Out of these, 363 patients yielded a corpus of 5,371 free-text clinical documents with an average of 15 documents per patient.
Phase I
Cohen’s Kappa for first 1000 common manually validated documents was 0.9448 (95% Confidence Interval (CI)
The gold standard developed by manually classified documents categorized 758 (14.12%), 1401 (26.08%), 1795 (33.42%) and 1417 (26.38%) documents to ‘Current Smoker’, ‘Past Smoker’, ‘Nonsmoker’ and ‘Unknown’ respectively. Consensus for classification by cTakes with manual classification achieved correct classification for each category as follows: 56.51% (694/1228), 92.14% (891/967), 89.47% (1597/1786) and 99.78% (1387/1390) with F-measures of 0.700, 0.753, 0.893 and 0.988 respectively. The overall accuracy of document level classification by the cTakes smoking pipeline was 85.1% (95% CI
Phase II
Patient-level consolidation of the documents using the rule-based algorithm, yielded 51 (14.05%) patients tagged as ‘Current Smoker’, 191 (52.62%) tagged as ‘Past Smoker’, 113 (31.13%) tagged as ‘Nonsmoker’ and 8 (2.2%) patients with ‘Unknown’ information. Consensus for classification by cTakes with manual gold standard patient classification achieved correct classification for each category as follows: Current Smoker: 96.08%; Past Smoker 71.21%; Nonsmoker: 61.07% and Unknown: 87.50% with F-measures of 0.580, 0.771, 0.730 and 0.933, respectively. The overall accuracy of the patient level classification was 71.9% (95% CI
Manual validation of 40 randomly-selected patients undertaken by the two coders matched the results of the rule-based algorithm classification by 100%. Of the 40 patients, one patient belonged to the ‘Current Smoker’ class,
Implications
We analyzed over 5000 documents to extract tobacco-use related information from the clinical notes of patients. When a corpus contained the phrase “Tobacco Use: None”, cTakes would perceive it as 2 sentences “Tobacco Use” and “None” thus classifying the corpus as ‘current smoker’ instead of ‘nonsmoker’. In order to correct this artifact, we pre-processed the corpora by replacing ‘: (colon)’ with a space because cTakes considered ‘:’ as a sentence separator.
Predicted classification for Phase I (cTakes) in form of confusion matrix
Predicted classification for Phase I (cTakes) in form of confusion matrix
Table 1 shows the predicted classification of Phase I in form of confusion matrix. Notably, we observed that the F-measure for the ‘current smoker’ class was lower than for other classes. The low F-measure for the ‘current smoker’ class is likely attributable to its low precision. It was observed during manual validation that the context of language related to smoking introduced challenges for the cTakes software in classifying a document into a ‘current smoker’. For example, one of the clinical notes documented patient exposure to second-hand smoke from a roommate, but no conclusive evidence ascertained that the patient was ever an active smoker. Another instance associated with cTakes misclassification occurred when patients were asked whether they had smoke-detectors in their residence. The presence of ‘smoke’ in the text led to a misclassification of the patient as a ‘current smoker’. A potential solution to improve precision is found in a study by Kang et al., who developed an NLP module (consisting of submodules) to improve precision by targeting reduction of false positives through compilation of terms identified through error analysis that were associated with false positive classification [31]. The study used ‘Filtering’ submodule which consisted of two rules. One of the rules removed a tagged concept (for instance: ‘smoke-detector’ as the example from our study) and ultimately improved precision by 18.7% [31]. In the interest of developing a clinically applicable tool, improvement of precision through this approach is in progress.
Table 2 shows the predicted classification of Phase II in form of confusion matrix. The second lowest F-measure was recorded for the ‘past smoker’ class and was likely attributable to the low recall for the same class. For example, one of the patients misclassified by cTakes as a ‘past smoker’ contained text indicating that the patient had a family history of smoking. This would not classify the patient as a smoker, but presence of terminology alluding to ‘smoking’ and ‘history’ resulted in the ‘past smoker’ classification error. Although cTakes generally classified documents into the 4 classes with high accuracy, certain limitations as provided in the examples above were noted, identifying that contextual framework of statements was critical to accurate classification.
Predicted classification for Phase II (cTakes) in form of confusion matrix
The smoking pipeline in cTakes has previously been used by other studies. In one of the studies the precision, recall and F-measure, respectively for the classes were reported as: current smoker (0.3, 0.81, 0.43); past smoker (0.87, 0.6, 0.71) with a reported overall accuracy of 69% [4]. Another study [5] reported the precision, recall and F-measure, respectively for the classes as: current smoker (0.48, 0.9, 0.63); past smoker (0.9, 0.54, 0.67); nonsmoker (0.93, 0.85. 0.88). Later study [5] did not report accuracy, and data regarding rates of true positive and true negatives were not published so that extrapolation of accuracy was not possible for comparison purposes. Based on the document level results reported, our approach demonstrated improvement in overall accuracy in comparison to those reported in previous studies. The improved outcomes may also be partially attributable to our use of a later version of cTakes (version 3.1.1) compared to outcomes achieved in the other studies in which reported application of earlier versions 2014 (version 2.5) and 2012 (version 1.1.0), respectively. However, irrespective of the cTakes version used, the pattern of the ‘Current Smoker’ class having a low precision compared to the other classes and the ‘Past Smoker’ class having a lower recall than the other classes persisted across all of the studies mentioned above.
The main limitation we noticed in the cTakes smoking pipeline was the ‘smoking’ terminology. The system worked at identifying tobacco use in documents irrespective of route of tobacco exposure (i.e., smoking or chewing.) For example, if a patient had been documented with chewing tobacco exposures, cTakes would automatically classify that document (and ultimately that patient) as a ‘Current Smoker’ applying incorrect terminology. A main study limitation was that the data we analyzed was captured via a single institutional EHR. Additional approaches will need to be defined to distinguish tobacco smokers from tobacco chewers. Another important aspect of smoking history not considered in the current approach to smoking status classification centers around availability of quantitative information documented in the EHR with respect to tobacco use/exposure. For example, ‘cigarette-months’ or ‘cigarette-years’ were captured in some of the patient records. This rule based algorithm could widely assist healthcare providers in determining the present patient’s tobacco use status and in the context of historical tobacco use behavior, provide smoking cessation advice. In the future, this approach may also be extended to symptomology classification associated with other diseases and other classification studies.
The findings of the study conclude that Natural Language Processing and a rule-based algorithm can be employed to determine the latest tobacco consumption status of patients from their clinical-notes. This provides a broad overview of the tobacco use behavior of patients, taking their tobacco use history into consideration instead of the ‘snapshot’ of their status on the day of the appointment. This alleviates the time-consuming process of going through the clinical notes in the patient’s history to manually deduce the latest tobacco consumption status. For example, if the individual was identified as a smoker, the history would provide the clinician information regarding whether the individual was a new smoker, relapsed smoker or had an established smoking history. The present status of tobacco use would help the researchers and healthcare providers to identify the patient cohort through data mining. The study findings will be applied to mine input variables for the OCRARI project. Furthermore, future work would involve more detailed analyses about the tobacco consumption for e.g. exposure type (cigarettes, cigars, pipes, snuff, e-cigarette, etc.), duration and frequency of the indulgence (e.g. smoked for 5 years, twice daily etc.).
Footnotes
Acknowledgments
The authors would like to thank Marie Fleisner from the Office of Scientific Writing at Marshfield Clinic Research Institute for her assistance with reviewing and editing this manuscript. The authors would like to thank Ms. Barbara Bartkowiak, Marshfield Clinic reference librarian, who helped in literature search. The authors would also like to thank Mr. Eric LaRose from Office of Research Computing and Analytics for his contribution towards modifying the abstraction software for the purpose of this study. The authors would like to thank Aloksagar Panny from Center for Oral and Systemic Health for his assistance with formatting of this manuscript. This work was supported, in part, by a grant from Delta Dental of Wisconsin, funds from Marshfield Clinic Research Institute and Family Health Center of Marshfield, Inc., and by the Clinical and Translational Science Award (CTSA) program, through the NIH National Center for Advancing Translational Sciences (NCATS), grant UL1TR000427. Its content is solely the responsibility of the authors and do not necessarily represent the official view of the National Institute of Health (NIH) or Delta Dental of Wisconsin.
Conflict of interest
The authors declare no real or potential conflicts of interest.