
Abstract
BACKGROUND:
One of the most broadly founded approaches to envisage cancer treatment relies upon a pathologist’s efficiency to visually inspect the appearances of bio-markers on the invasive tumor tissue section. Lately, deep learning techniques have radically enriched the ability of computers to identify objects in images fostering the prospect for fully automated computer-aided diagnosis. Given the noticeable role of nuclear structure in cancer detection, AI’s pattern recognizing ability can expedite the diagnostic process.
OBJECTIVE:
In this study, we propose and implement an image classification technique to identify breast cancer.
METHODS:
We implement the convolutional neural network (CNN) on breast cancer image data set to identify invasive ductal carcinoma (IDC).
RESULT:
The proposed CNN model after data augmentation yielded 78.4% classification accuracy. 16% of IDC (
CONCLUSION:
The results achieved by the proposed approach have shown that it is feasible to employ a convolutional neural network particularly for breast cancer classification tasks. However, a common problem in any artificial intelligence algorithm is its dependence on the data set. Therefore, the performance of the proposed model might not be generalized.
Keywords
Introduction
Cancer is an ensemble of diseases with gigantic molecular miscellany between tumors of afflicted patients. Invasive ductal carcinoma (IDC), also known as infiltrating ductal carcinoma, or carcinoma of ‘No Special Type’ (NST) is characterized by hard lumps with asymmetrical borders. The IDC lump typically feels firmer than that of a benign breast protuberance. Invasive breast cancers spread from the origin (either the milk ducts or the lobules) into the adjoining breast tissue. These comprise approximately 70% [1, 2] of all breast cancer cases and have an inferior prognosis compared to the in-situ sub-types [3, 4].
One of the most broadly founded approaches to envisage targeted treatment is based on the visual examination of bio-marker appearance on tissue sections from a tumor by a pathologist. An exemplar in breast cancer is the semi-quantitative evaluation of the appearance of the human epidermal growth factor receptor 2 (HER2) as identified by immuno-histo-chemistry (IHC) which circumscribes patient aptness for anti-HER2 therapies. For patients whose tumor piquantly overexpresses HER2, the addition of treatment besieged against HER2 is chiefly efficient at improving clinical outcomes compared to chemotherapy alone [5].
On a mammogram, IDC typically appears like a mass with spikes radiating from the edges; it may also emerge as a smooth-edged protuberance or as calcification in the tumor area. However, due to the small size and low contrast compared to the background of images, it is challenging and time-consuming for radiologists to make an independent and accurate assessment of micro-calcification. The problem is especially perplexing for inexperienced radiologists when facing a plethora of mammograms generated in widespread screening [6].
Motivation
Substantial diagnostic capriciousness has been reported between pathologists and it is deduced that 4% of negative cases and 18% of positive cases are misdiagnosed [7]. In particular, scoring variability has been publicized to be imperative for cases that demonstrate heterogeneous HER2 expression within the tumor cell population [8]. To ensure diagnostic precision, pathologists and oncologists customarily entreat for second opinions. However, second opinions are not effortlessly available and can take several weeks. This situation is likely to become more challenging in the next decade with the mounting number of biomarkers to be gauged by pathologists for clinical decision-making and the dearth of newly trained pathologists [9]. Consequently, there is a necessity to develop helpful automated tools to overcome these tribulations and convalesce diagnostic performance of breast cancer.
Potential of artificial intelligence
Interest in AI has gone through fluctuating phases of expectation and disappointment since the late 1950s primarily due to limited computational ability. However, the development in computing infrastructure and machine learning algorithm has shifted the AI paradigm. Now adoption of AI technology has accelerated in various arenas.
In healthcare, some research focusing on the role of AI in cancer detection has advocated that by proficiently examining large numbers of images, artificial intelligence (AI)-based methods can curtail intra and inter-observer performance inconsistency AI-aided diagnosis holds great potential to facilitate clinical decision-making in monogrammed oncology. Prospective benefits of using computer-aided diagnosis embrace abridged diagnostic turn-around time and improved bio-marker scoring reproducibility. In the last decade, viable algorithms have been consented by the Food and Drug Administration (FDA) for computer aided HER2 scoring. Moreover, many studies have acknowledged that image analysis improves IHC bio-marker scoring accuracy and reproducibility in tumors [10, 11].
Lately, deep learning techniques have radically enriched the ability of computers to identify objects in images [12, 3] fostering the prospect for fully automated computer-aided diagnosis. Given the noticeable role of nuclear structure in cancer cells, various non-parametric methods such as deep learning have been employed for classifying histopathology images and diagnosing breast cancers [13]. Among deep learning models [14], convolutional neural networks (CNN) is debatably the most studied and validated method in a range of image understanding tasks such as face recognition and character recognition.
Problem statement
As the efficiency and effectiveness of artificial intelligence (AI) in enhancing diverse aspects of healthcare is burgeoning significantly, it becomes likely that AI will soon become an integrated system in a routine clinical process.
This study is driven by the potential role of AI in the recent future. In this study, we propose and implement an image classification technique using convolutional neural networks to identify breast cancer.
Methodology
Data description
The original data was collected by Andrew Janowczyk [15]. It consists of 162 whole mount slide images of breast cancer specimens scanned at 40x. From that, we used 5547 (50.26% IDC and 49.74% non-IDC) patches of size 50
Data sample used for training the model. The positive (green) categorizes refers to IDC
The area confined by green line indicated invasive tumor tissue zone [3].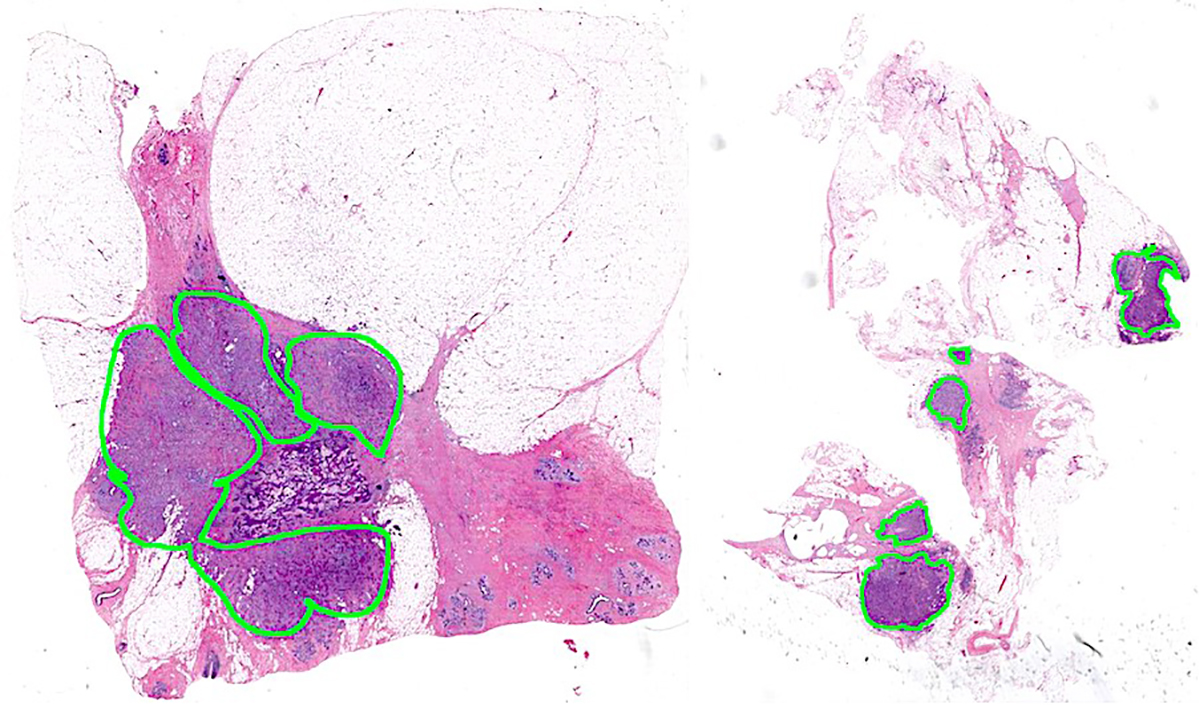
All the analysis were performed using python 2.7.
Data pre-processing involves scaling the image data based on pixel intensities and augmenting the data.
Data scaling is an essential step to ensure every input parameter has a similar data distribution. Data scaling helps to train the data easily. The image data set has three channels of data corresponding to the colors Red, Green, Blue (RGB) and their pixels vary in the range of [0, 255]. These values would be too high for the model to process. So, we scaled the image with a 1/255 factor. The scaled image pixel intensities vary in the range of [0, 1]. The data set was then augmented, in which we randomly rotated the images by 90 degrees to translate images vertically or horizontally (Fig. 3).
Images and its different transformations performed during augmentation.
Convolutional neural network
The convolution network is one of the most efficacious biology-inspired artificial intelligence networks. Though the convolution network has been engaged by various fields, some fundamental design principles of the neural network arise from neural science. The visual structure of mammals is comparable to a convolution operation. For instance, a two-dimensional image “I” is considered as the input, and the convolution kernel is characterized by “K”; the convolution of the input image is, as follows:
Generally, Eq. (1) can be easily applied in a machine learning library. In the above equation, convolution should reverse the convolution kernel, and only then, sum the weights [17]; however, the law of commutation is less performed in a neural network instead, cross-correlation is desirable in a neural network as shown in Eq. (2).
A Convolutional Neural Network (CNN) involves the implementation of filters or feature detectors over an entire image to measure the correspondence between individual image patches and signature patterns within the training set [3]. Then, a pooling function is implemented to minimize the dimensionality of the feature space. The pooling operation can be performed by calculating the maximum or the average of inputs connected from the previous layer to the kernel for a given position. This study uses the Max pooling technique. It is more popular among applications and helps eliminate noise without impacting the activation value of the layer. The image patches collected are then used as inputs to the CNN architecture (Fig. 4) in which two dedicated layers are used for convolution and pooling while the other layers are fully-connected.
Convolutional neural network architecture.
The fully connected layer was used for learning non-linear decision boundaries and consecutively perform the classification task. This step depends on the preceding densely connected layers in a typical feed-forward manner.
The hidden layers are then passed through the ReLU activation layer. It only allows positive activation to pass through the next layer. The output node in this study was set as a sigmoid activation function, which varies between 0 and 1 for input ranging from negative to positive.
Tables 1 and 2 show the configuration of the network, with and without data augmentation, used in this study.
Specification of CNN configuration without data augmentation
Specification of CNN with data augmentation
Model performance before data augmentation
Figure 5 shows that confusion matrix, representing the classification performance of the model before data augmentation. The CNN network achieved 77% accuracy. 23% of IDC (
Here the total number of classification performed were 1,110 (391
Thus, total correct classification were 856 (0.7711) and miss-classification were 254 (0.2288).
Classification matrix of CNN without data augmentation.
Classification matrix of CNN with data augmentation.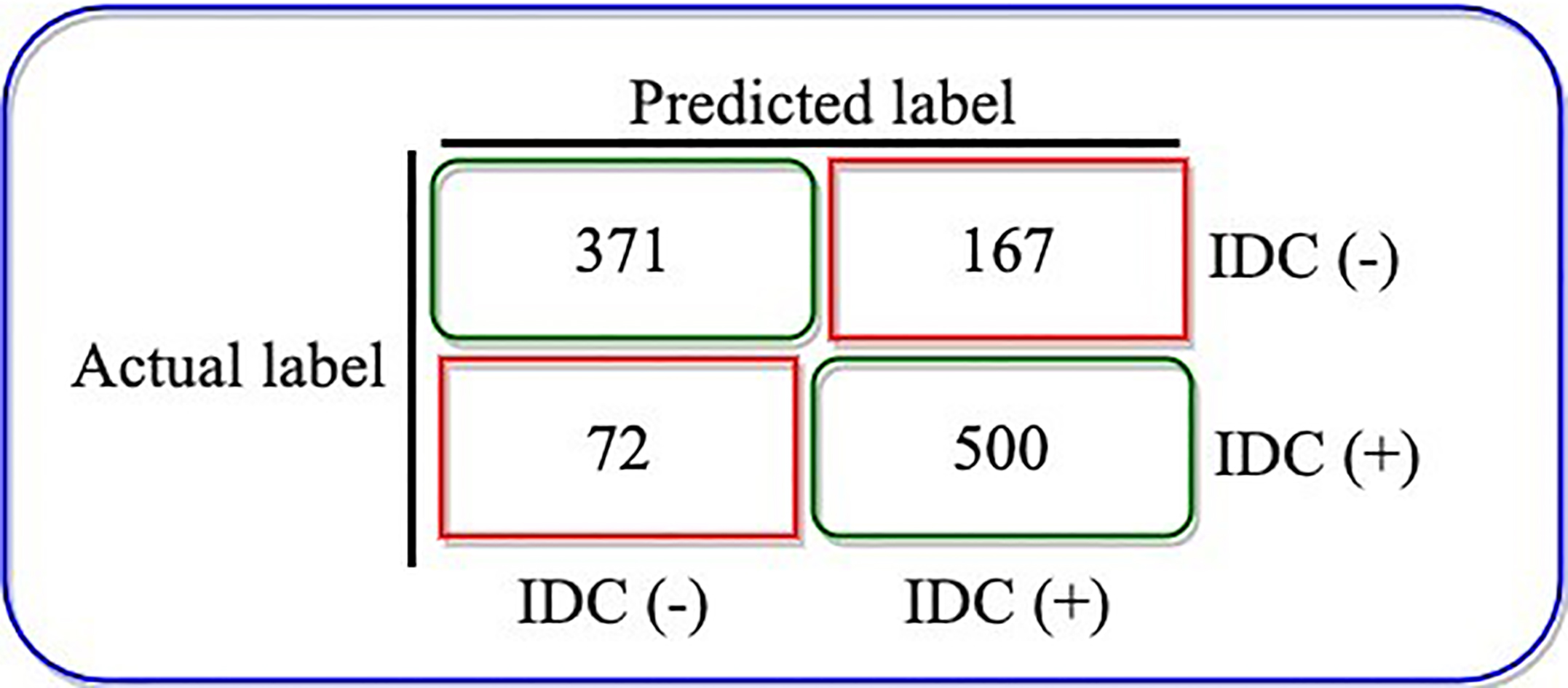
A. Learning curve of CNN model. B. Change in performance with epoch.
Actual versus predicted IDC.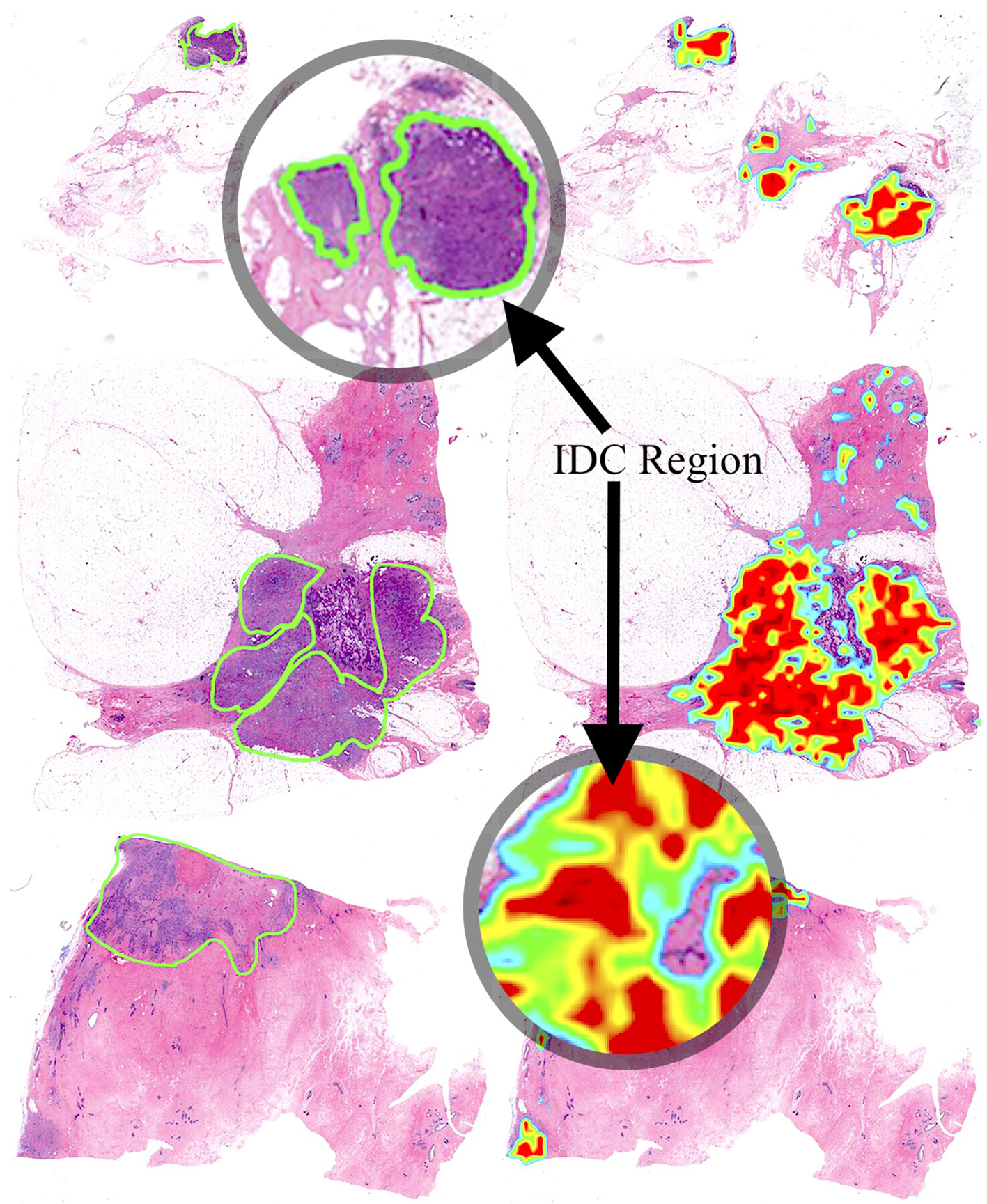
Figure 6 illustrates the confusion matrix, representing the classification performance of the model after data augmentation. The CNN after data augmentation yielded 78.4% accuracy, 16% of IDC (
Here the total number of classification performed were 1,110 (371
Thus, total correct classification were 871 (0.7846) and miss-classification were 239 (0.2153).
Therefore, the model’s miss-classification reduces by approximately 0.0135 after data augmentation. This indicates that model might have generated some bias or over fitting in the prediction. Figure 7A illustrates the learning curve of the model and Fig. 7B shows the model’s performance on validation and training set. Since the classification accuracy of the model on the validation and training set is not significantly different, we can imply that the learning rate and classification accuracy of the CNN model after data augmentation is better and that the network architecture does not over fit. Thus, we recommend data augmentation for this particular data set.
Actual versus predicted
Figure 8 illustrates the actual annotations made by medical expert and the effected area identified by our model. The green perimeter represents the area marked by medical experts as risk prone zone (IDC tissue region).
The heat map on the right side of the figure represents the probability density generated by our model. It shows the highest likelihood of IDC tissue regions in red, orange, and yellow (red being the zone of the highest probability) colors whereas the lowest chance of IDC regions are indicated by green and blue.
Discussion and conclusion
The pathology society is exhibiting amassing interest in deep learning as demonstrated by studies reporting deep learning-based image analysis detecting tumor regions within tissues. Developments in AI methods allow comprehensive and unprejudiced analysis of diagnostic features in micro-calcification and masses. In order to augment the chances of clinical benefit, afresh developed cancer treatments are targeted at exclusive molecular alterations that can be acknowledged in the tumor prior to the commencement of treatment [16]. Through the automatic identification and classification of micro-calcification, computer-based methods can be advised to aid early detection and diagnosis. Table 3 shows the comparative analysis of different models for breast cancer prediction. Our model outperforms several existing methods. Our study outperformed Gail Model by about 4.50% [17]. The Gail Model is a well-known and commonly used breast cancer risk assessment tool. However, it fails to detect breast cancer risk in women with a significant family history [18]. Our study also outperformed other AI models such as LASSO penalized regression [19], CNN [20], CNN
A wide variety of machine learning classifiers have been established for early diagnosis of breast cancer. The widely used practices are based on support vector machines (SVM) [2, 1], k-nearest neighbor (KNN) [22] method and linear discriminant analysis (LDA). However, the predictive and classification power of these methods are restricted due to the computational costs of categorizing absolute features for subset characterization and optimization. In this study we propose CNN model that not only overcome the limitations of classical machine learning algorithms but also produce the comparable predictive accuracy without over-fitting.
The results achieved by the proposed approach have shown that it is feasible to employ convolutional neural network as a decision support system, particularly for breast cancer classification task. However, a common problem in any artificial intelligence algorithm is its dependence on data set. Therefore, the performance of the proposed model might not be generalized. Moreover, provided low number of samples in such a kind of data sets, training a CNN is not feasible. In the future, we intend to use the activation layers of a CNN trained on other data sets to extract patches based on class-activated regions.
Comparative analysis of predictive models
With deep learning algorithms meeting expectations, and in some occasions surpassing, the performance of clinicians, the promise is already apparent. However, despite AI’s good performance, as demonstrated in this study, particularly in cancer diagnosis, substantial challenges, not limited to ethical and regulatory concerns [23], act as a hurdle to the adoption and integration of AI in health care. Healthcare devices or systems augmented by AI or machine learning algorithms have an ability to independently learn from given data and real-world use and can consecutively improve the performance of the care providers over time [24]. This uniqueness of AI distinguishes it from the bundle of other software used in health care and thus impose novel regulatory concerns.
As proposed and advocated in our previous work [25, 26], it is one of the primary responsibilities of the FDA and other stakeholders not limited to health services, and clinicians to ensure patient safety and quality of care. Black box models such as deep learning algorithms are un-explainable in their functioning and has the potential to evolve with time-based on new data. Such models may require special policies and guidelines to ensure safety. For instance, in the context of this study. If our proposed model is exposed to data that is incorrectly labeled for a sufficient period of time, will generate wrong classifications. Concerns also emerge about patient safety, interpretation of AI output, and latent risks associated with it. AI systems and software are not typically align with current models of care delivery. Thus, most clinicians are trained to operate or interpret AI systems. Clinicians must also be made aware of the false negative classification.
Additionally, future research must focus on developing Regulatory standards to measure and scrutinize AI algorithmic safety and impact [25]. Consecutively, address the issues of liability. For instance, “there is the question of who is responsible when errors result from the use of AI software or AI-augmented devices in the clinical context” [24]. Existing medico-legal guidelines are also superficial and inefficient in defining the boundary distinguishing the responsibility of clinicians and AI system when AI agents guide clinical care [25, 27]. Given these limitations of AI, its implications in the domain of healthcare and diagnostics is yet to be seen.
Footnotes
Conflict of interest
None to report.