
Abstract
BACKGROUND:
The traditional meal assistance robots use human-computer interaction such as buttons, voice, and EEG. However, most of them rely on excellent programming technology for development, in parallelism with exhibiting inconvenient interaction or unsatisfactory recognition rates in most cases.
OBJECTIVE:
To develop a convenient human-computer interaction mode with a high recognition rate, which allows users to make the robot show excellent adaptability in the new environment without programming ability.
METHODS:
A visual interaction method based on deep learning was used to develop the feeding robot: when the camera detects that the user’s mouth is open for 2 seconds, the feeding command is turned on, and the feeding is temporarily conducted when the eyes are closed for 2 seconds. A programming method of learning from the demonstration, which is simple and has strong adaptability to different environments, was employed to generate a feeding trajectory.
RESULTS:
The user is able to eat independently through convenient visual interaction, and it only requires the caregiver to drag and teach the robotic arm once in the face of a new eating environment.
Keywords
Introduction
Activities of daily living (ADLs), such as drinking and eating, have an essential impact on the quality of personal life [1]. However, many people with disabilities caused by illness or accidents have to rely on family members or caregivers to complete such daily activities. Therefore, it is of great significance to develop a device that can assist disabled patients to eat independently. Although there are many commercial meal assistance robots available on the market, such as the well-known Obi, My Spoon and Mealtime Partners, they all adopt the only preset fixed feeding tracks in response to different eating environments [2].
In recent years, various types of feeding robots have been reported by different research groups. Perera et al. proposed an EEG interaction-based meal assistance robot which is extremely helpful to patients with upper limb disability [3], whereas it affects patients’ comfort since the EEG interaction equipment requires to contact their heads. Kumar Shastha et al. devised an autonomous drinking robot on the basis of reinforcement learning [4], which is capable of feeding liquid food for users through cups. Nevertheless, the development of this drinking robot not only comes at a high cost but also relies on excellent programming technology.
In this study, we adopt a visual human-computer interaction method based on deep learning. Specifically, when the camera detects that the user’s mouth is open for 2 seconds, the feeding command is turned on, and then, the feeding is temporarily conducted when the eyes are closed for 2 seconds. This interaction method not only exhibits high accuracy and strong robustness but also does not affect the comfort of users. Furthermore, the feeding robot can generate a new feeding trajectory in response to different eating environments simply by dragging. Notably, this developmental process does not require any programming techniques.
Composition of the feeding system.
Structure of the mechanical arm
The 7bot, a multi-functional and programmable metal joint manipulator with six degrees of freedom, was used as a feeding manipulator. It employs the Arduino Due as the control core and a steering gear to drive the mechanical arm. Additionally, the 7bot weighs 2.5 kg with a maximum load of 500 g. We modified the original end structure of the mechanical arm and added a spoon. Figure 1 shows the composition of the feeding system. According to the mechanical structure of the 7bot, taking the central base as the center, the performance of the manipulator is shown in Table 1.
Performance index of the 7bot robot arm
Performance index of the 7bot robot arm
Methods. (a) Yolov4-tiny architecture. (b) Trajectory of robot learning.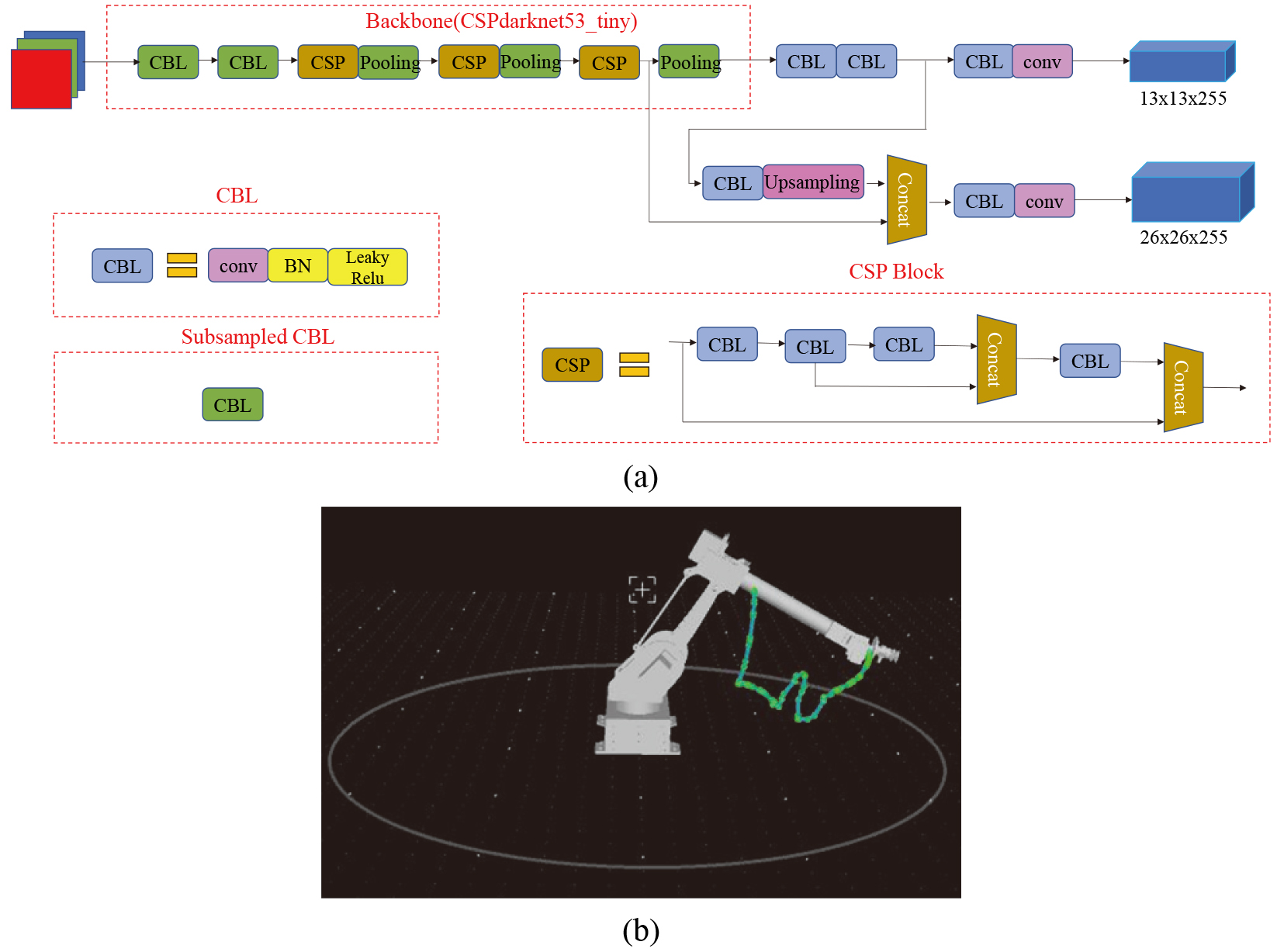
The Yolov4 [5] is an improved version of Yolov3, whose mean average precision (mAP) is significantly improved without decreasing FPS. The Yolov4-tiny is a simplified version of Yolov4, whose running speed is greatly increased although mAP is slightly reduced. In general, Yolov4 has about 60 million parameters, while Yolov4-tiny only has six million parameters. Figure 2a shows the Yolov4-tiny network structure.
One hundred and ninety-three appropriate face images containing different eye and mouth states were collected in different feeding scenes, and 603 images were obtained after image data augmentation as the dataset. After labeling the generated dataset, we used the deep learning framework (Darknet) to train the divided set for 20,000 iterations. Then, the optimal model was deployed on the TX2 platform to perform real-time eyes and mouth state detection. When a preset specific state is detected, TX2 will send the result to the main controller of the 7bot to perform the corresponding task.
Results. (a) Results of eye and mouth state detection. (b) Confounding matrix for model evaluation. (c) Successful execution of the feeding task.
The purpose of learning from the demonstration is to make the robot acquire eximious adaptability to the new environment. In addition, this method can obtain the appropriate robot movement trajectory by observing human behaviors without requiring the user to program the expected behavior [6, 7].
The 7bot has six degrees of freedom, which allows the feeding trajectories to be obtained by dragging and guiding. During dragging, the encoder will record the angle of each joint axis, followed by the MCU transmitting the acquired data to the superior machine through the communication protocol. Figure 2b shows the trajectory of robot learning. Once the data is received, the upper computer will carry out angle conversion and data optimization. Finally, the generated code will be imported into the robot motion controller in file format through coordinate transformation, realizing the robot trajectory reproduction.
Results
Evaluation of detection accuracy and response rate
The results of eyes and mouth state detection are shown in Fig. 3a. To evaluate the performance of the detection model more accurately and objectively, we tested 50 images of each category, and finally obtained the confusion matrix as shown in Fig. 3b. Meanwhile, we also tested the response rate of the feeding robot (Table 2) when executing the corresponding instructions under certain eyes and mouth states.
Response rate test (30 times per state)
Response rate test (30 times per state)
To verify the practicability of the feeding robot integrating visual interaction and learning from demonstration, we evaluated the feeding robot in a real feeding scenario. Figure 3c shows the flowcharts of feeding system implementation.
Discussion and conclusion
The confusion matrix in Fig. 3b shows that the eye and mouth state detection model has achieved satisfactory results and Table 2 demonstrates that the meal assistance robot exhibits an excellent response rate when a specific status is detected. Moreover, Fig. 3c reveals that the robot can successfully complete the feeding task in the different eating environments, verifying the effectiveness of the proposed feeding method which integrates vision and learning from demonstration technology. In future work, we plan to develop an intelligent feeding robot that can accurately deliver food from the spoon to the user’s mouth without hurting them. This way, disabled patients are able to eat the food on the spoon without moving their heads.
Footnotes
Acknowledgments
The work reported in this paper was sponsored by the Shanghai Pujiang Program, no. 16PJC063.
Conflict of interest
None to report.