
Abstract
BACKGROUND:
Medical patients can be diagnosed early, however it is difficult to extract effective features in medical image segmentation based on semantic information.
OBJECTIVE:
A deep learning based image pixel block feature learning technology is studied in this paper.
METHODS:
The unlabeled image block sample training stack noise reduction automatic encoder is used to learn and extract the deep features of the image, and construct the initial depth neural network model. The labeled samples are used to fine-tune the initial depth neural network model, the deep features of the image correspond to the category, and the depth neural network model with classification function is obtained. The model is used to classify the pixel block samples in the segmented image and detect the initial segmentation region of brain tumor tissue. Finally, threshold segmentation and morphological methods are used to optimize the initial results to obtain accurate segmentation results of brain tumor tissue.
RESULTS:
The results show that this method can effectively improve the accuracy and sensitivity of segmentation. The running speed is also greatly improved compared with the traditional machine learning method.
Introduction
Image segmentation is an essential key link in medical image processing and medical image analysis. It is widely used in the pre-processing to peel off the equipment projection, skull and other unrelated tissues, or in the later analysis to extract different organs, tissues and pathological structures, and directly affects the results of subsequent processing and analysis tasks [1].
Convolutional neural network (CNN) is a representative algorithm of supervised learning. Since Hinton et al. proposed the AlexNet network to win the ILSVRC image classification competition in 2012, deep learning has become a hot research topic. CNN is composed of input layer, convolution layer, activation function, pooling layer and full connection layer [2]. Convolution neural network uses the convolution layer and pooling layer to automatically learn image features of various scales. Firstly, it understands image color and brightness, then local information such as edge and line, then texture, shape and other more complex structural information, and finally high-level semantic information of the whole image.
Some scholars use particle swarm optimization convolution kernel (PSO-ConvK) to identify lung tumor images [3]. The random initialization of convolution kernel and gradient descent method to train CNN are easy to fall into the local minimum value, which is solved to a certain extent. Parameter transfer method is used to construct CNN, convolution kernel is extracted, and particle velocity and position are updated continuously by PSO [4]. The global optimal value is found by initialization convolution kernel, and is then transferred to CNN, and the weight is modified by the gradient descent method. The results show that the recognition rate of PSO optimized convolution kernel is always higher than that of random convolution kernel and Gaussian convolution kernel, and the recognition rate is as high as 92.3%.
From the initial manual segmentation, to the coarse segmentation based on gray threshold, and then to a variety of automatic segmentation methods, researchers have been pursuing more efficient, more accurate and more intelligent segmentation technology [5]. Image segmentation based on semantic information is of great significance in medical image processing. By recognizing the semantic information of different physiological tissues in medical images, more accurate segmentation results can be obtained. It is an important analysis method, especially suitable for the detection of structural brain lesions (such as brain tumor, brain injury, cerebral infarction, etc.) and subsequent qualitative analysis.
Because of the complexity of medical images, the key problem of the segmentation method based on semantic information is how to search and extract the features which can fully describe the semantic information of image or pixel. The proposed deep learning brings a new solution [6]. Using the deep learning framework, we can automatically learn the potential deep features and corresponding categories from the samples, and classify the target by trained neural network, thus solving the problem of feature description difficulty in semantic information segmentation.
In this paper, stack noise reduction automatic encoder is used to construct the depth neural network: firstly, fixed size image block samples are extracted from the preprocessed training image set, and then the initial parameters of each layer network are trained by feature learning of unlabeled image block samples, and then the depth neural network has classification function through further fine-tuning the labeled image block samples. Then, the image block samples in the segmented image are classified, and the central pixel of the image block marked as tumor tissue is mapped to the black-and-white binary image as the initial segmentation result; finally, the accurate segmentation result of tumor tissue in brain MRI image is obtained by optimizing the results by using threshold segmentation method and morphological processing method. Figure 1 shows the technical route of this method [7].
Medical image segmentation method based on the deep neural network.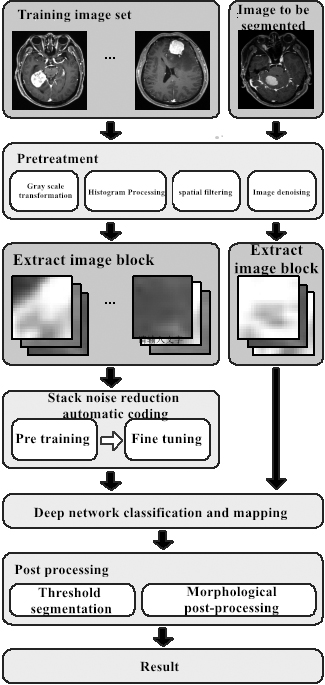
The basic concept of deep learning comes from the early artificial neural network research [8, 9, 10]. The relevant team improved the relevant theory in 2006 and won the Imagenet competition in 2012. After that, it quickly occupied the mainstream research direction in the field of computer vision. In essence, deep learning can be regarded as a feature learning process. By inputting a large number of image data into the deep network and iterating repeatedly, the image features and corresponding categories can be automatically summarized.
In this paper, a deep neural network is constructed by using stacked automatic encoder (SAE) [11]. The model is composed of many layers of automatic encoder (AE) in series. Each layer of automatic encoder is a simple neural network including input layer, intermediate layer and output layer. The principle and implementation method of the automatic encoder and its improved structure are discussed in the next sections.
Automatic encoder
The standard automatic encoder is a simple neural network with only one intermediate layer, and its structure can be simply summarized into two parts: encoding and decoding [12]. In this process, in order to ensure the integrity of data information, the output results are required to be consistent with the input.
Figure 2 shows the simple structure of an automatic encoder. It can be seen that the automatic encoder is essentially a process of encoding before decoding. Firstly, a large number of unlabeled original data are input, and then the encoder is used to encode the input data to get the dimensionless middle layer data. Then the decoder is used to decode the middle layer data and reconstruct the original data as the output [13]. In this process, if the input data and the output data are completely consistent, the corresponding intermediate data can be regarded as an abstract representation of the original data, that is, the “shallow features” of the original data.
The parameter adjustment process of the automatic encoder is shown in Fig. 3. In order to achieve the purpose that input is output, the parameters of encoder and decoder need to be adjusted continuously according to the error between input data and output data until the error is eliminated.
Single layer automatic encoder.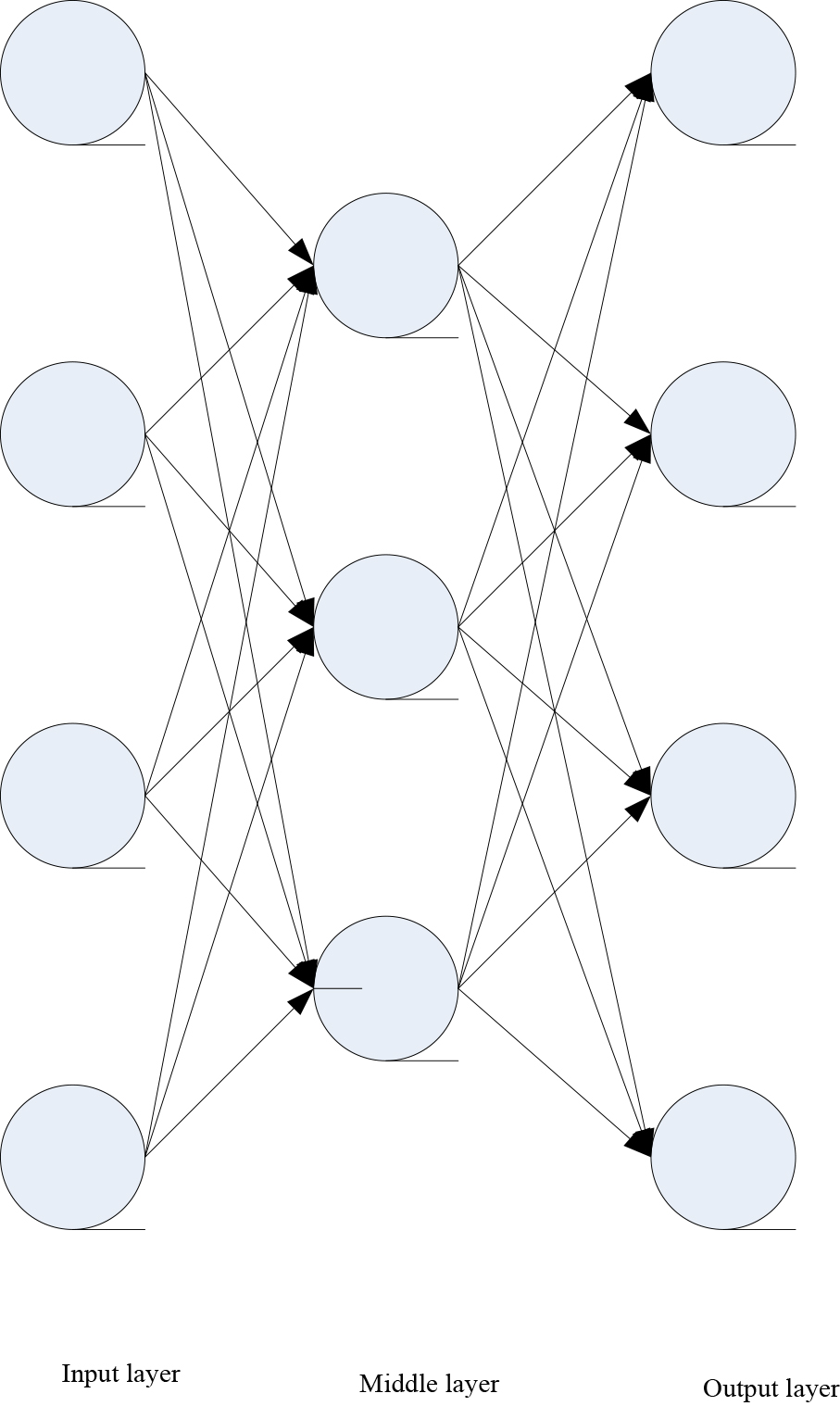
Single layer automatic encoder.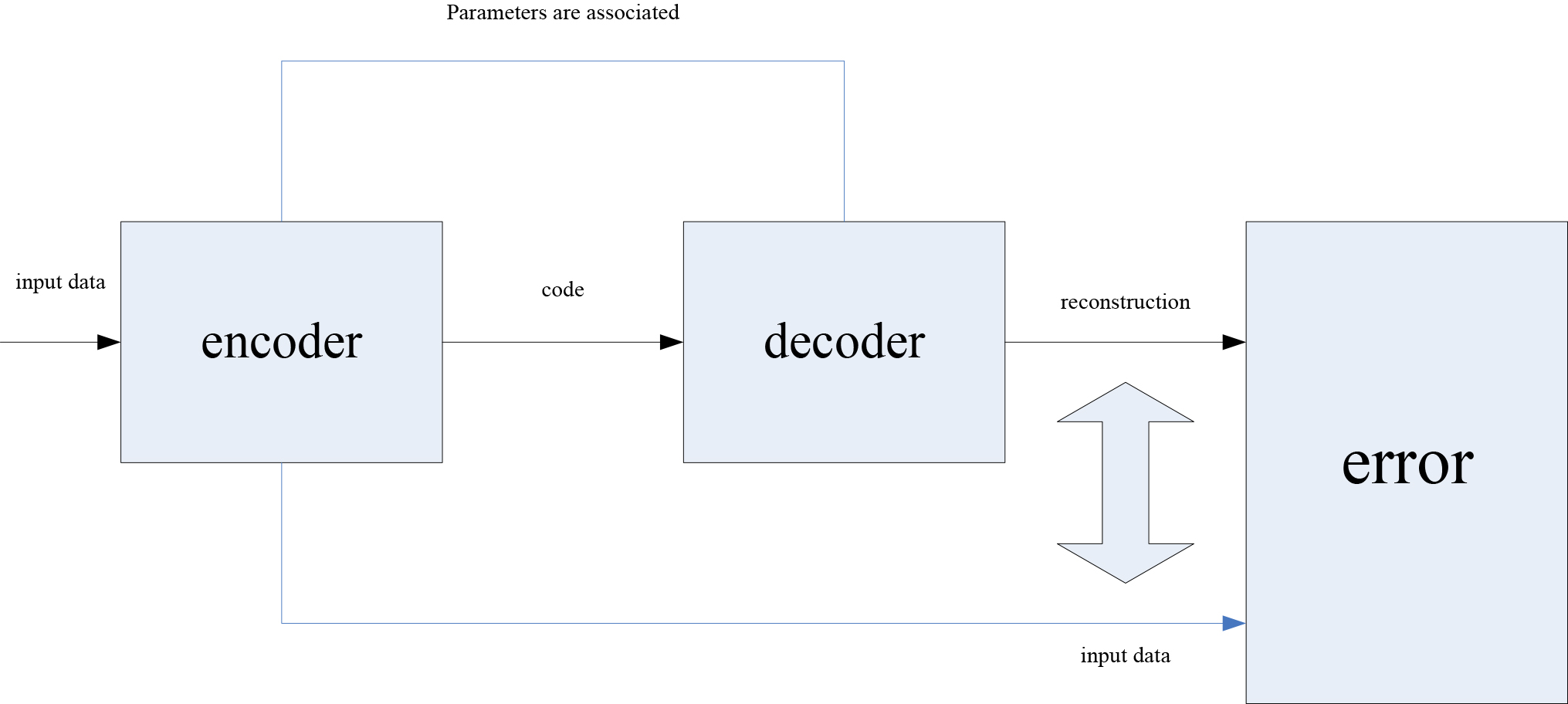
In the specific implementation process, the original data of the input layer is set as
Where: sigm refers to the sigmoid activation function,
Then, the decoder
Where:
In order to make the input data consistent with the output data, the associated parameters of the encoder and decoder can be adjusted:
The reconstruction error
When the reconstruction error reaches the minimum, the intermediate data
When using the automatic encoder to extract image features, it is also necessary to optimize the automatic encoder to improve its robustness in processing image data with noise. Some scholars have proposed a noise reduction automatic encoder, as shown in Fig. 4. Its principle is to partially destroy the original data when input, and then let the automatic encoder learn how to reconstruct the original data that has not been damaged before input, so that the generalization ability of the encoder will be enhanced.
Noise reduction automatic encoder.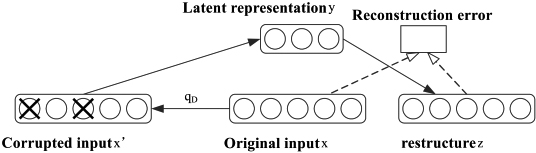
The specific implementation process is as follows: first, the original data
Then, the parameters of encoder and decoder are trained until the reconstruction error
It is worth noting that. The biggest difference between the noise reduction automatic encoder and the automatic encoder in the calculation process is that the output data
The image features extracted by the automatic encoder and noise reduction automatic encoder are shown in Fig. 5. The left picture is the feature block output by the middle layer of the automatic encoder, and it can be seen that the information in the image is relatively messy and difficult to identify; the image on the right is the feature extracted by the automatic noise reduction encoder, which obviously contains more useful information.
Comparison of the feature extraction of the automatic encoder and noise reduction automatic encoder. a. The characteristics of the output of the intermediate layer of the automatic encoder; b. The characteristics of the output of the intermediate layer of the noise reduction automatic encoder.
After getting the classification result of each pixel in brain MRI image, the image can be segmented accordingly. In order to eliminate the noise and edge error, the initial segmentation results need to be optimized. In this chapter, the expansion and corrosion of morphological methods are used to obtain more accurate segmentation results.
A stack noise reduction automatic encoder with depth structure can be obtained by connecting several layers of noise reduction automatic encoders in series. The specific method refers to the unsupervised greedy layer by layer training mechanism proposed by scholars, that is, only one automatic encoder is trained at a time, and the middle layer of each layer of automatic encoder is used as the input of the next layer until each layer of automatic encoder is obtained.
First, the original sample data is generated. The final purpose of constructing the deep neural network in this paper is to classify the image pixels, and then use the classification results to achieve tumor tissue segmentation in brain MRI images. Considering the adjacent relationship of similar pixels in the segmentation task, an image block with 25
Where: max and min represent the maximum and minimum values of gray values respectively.
In order to obtain robust learning network, the original sample data need to be polluted by noise to a certain extent, and then the polluted data is used as the input of the first layer learning network. According to the training method of noise reduction automatic coding machine mentioned above, the first layer network is trained to minimize the error between the output reconstruction result and the original data without pollution.
Using the trained parameters, the output of the hidden layer (middle layer) in the first layer network is calculated and trained as the input of the second layer. The second layer network is generated by using the new parameters, and then the output of the hidden layer in the second layer network is taken as the input of the third layer. The above process is repeated until the whole deep neural network is generated. Figure 6 shows the first intermediate layer of stack noise reduction automatic encoder, in which the input samples damaged by noise can be clearly seen.
Visualization results of the first hidden layer feature of stack noise reduction automatic encoder.
In this process, the hidden layer output of each layer network is the “depth feature” of the image. In order to make the deep neural network have the classification function, we need to use supervised learning to fine-tune the whole network to make the features correspond to the category. The specific method is to use the parameters of each layer before to build a complete deep neural network, and add an output layer at the end of the whole network to build a feedforward deep neural network, and then compare the output results with the data true value. The network parameters are adjusted according to their differences, so that the input samples can output their corresponding categories after a series of network mapping, that is, they have the ability to classify and identify samples.
Figure 7 shows a complete training process of stacker. On the left is the process of pre-training with unlabeled samples to construct the initial deep neural network; on the right is the process of fine-tuning the initial depth neural network with labeled samples to make it have the classification function.
Depth neural network based on stack noise reduction automatic encoder. a. Pre-training; b. Fine-tuning.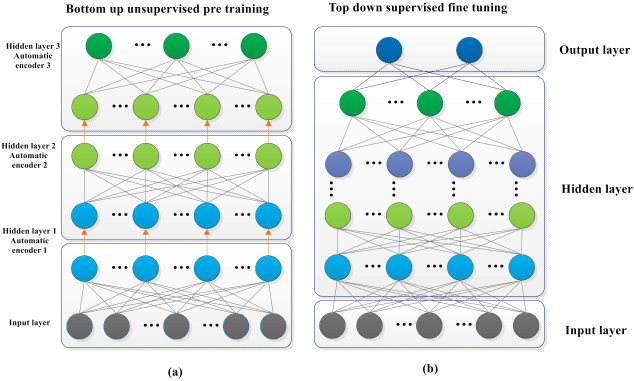
The fine-tuning depth neural network can be used to classify the samples. In the input layer, the sample data to be classified is input (there is no need to pollute the initial data in the classification task). After a number of preset intermediate layers, the sample features are automatically analyzed, and finally the classification results are output through the output layer. The target of the classification task in this paper is a result of dichotomy to detect whether the pixels corresponding to the input image block samples belong to brain tumor tissue.
After the classification results of image blocks are obtained, the corresponding center pixels can be mapped to the corresponding categories according to the category label of each image block, so as to obtain the initial segmentation results. However, due to the use of the regional gray level of the image block as the classification basis, there may be false segmentation. As shown in Fig. 8, some normal brain tissues are also divided into the brain tumor regions with green marks.
Initial segmentation results.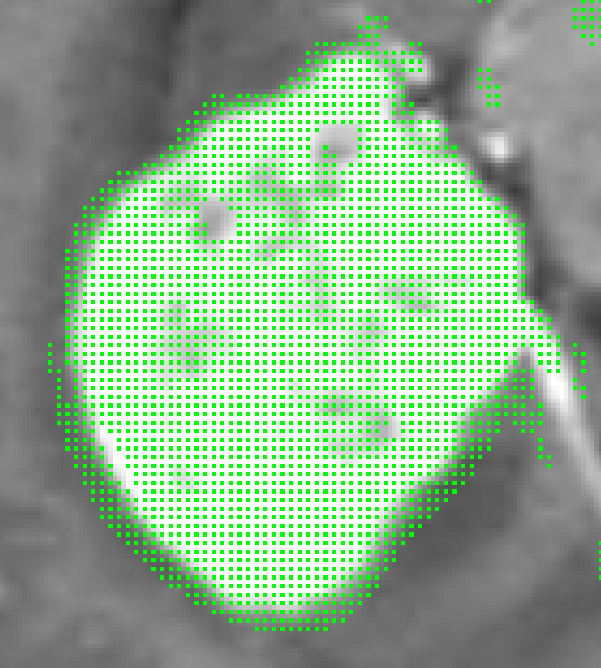
In order to eliminate the phenomenon of false segmentation, the initial segmentation results can be preliminarily processed by threshold segmentation. The threshold value is set according to the gray distribution of all the pixels classified as brain tumor tissue, and then the pixels that obviously do not belong to tumor tissue are deleted.
Figure 9 shows the results of threshold segmentation, Fig. 9a is the original image to be segmented; Fig. 9b is the binary image generated by the original image space by using the stacking automatic encoder, and the classification result is mapped to the original image space, that is, the initial segmentation result; Fig. 9c is the result of optimization processing by using the threshold segmentation method.
The segmentation results were optimized. a. Original image; b. Initial segmentation result; c. Optimized result of threshold segmentation method.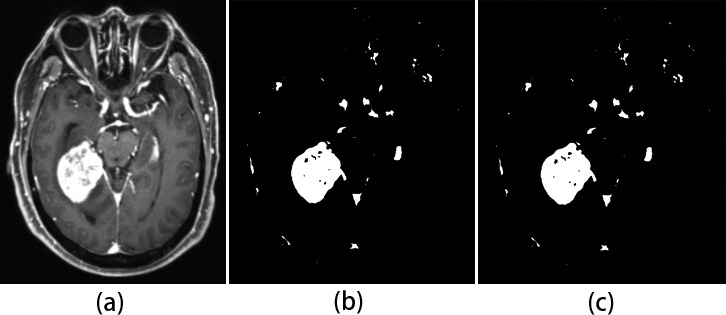
Morphological optimization results. a. The results of threshold segmentation optimization; b. Morphological processing optimization results.
As can be seen in Fig. 9c, after optimization of the threshold segmentation method, the larger isolated patches in the initial segmentation results are basically eliminated. However, there are still some spots isolated outside the tumor area and interspace in the tumor area. According to the integrity and continuity of tumor tissue, it can be judged that these spots and spaces are obviously misclassification, which needs further optimization.
In order to get better segmentation results, we use the open and close operations of morphological processing methods to optimize the segmentation results. The main function of the open operation is to eliminate the bulge and isolated spots on the edge of the image, while the main function of the closed operation is to fill the gap and concave edge in the image. In this paper, in order to optimize the segmentation results of tumor tissue, the above two morphological operation methods will be combined. The results of morphological segmentation optimization are shown in Fig. 10.
Parameter setting and experimental data
The experimental data in this study were provided by our hospital, including brain MRI cross-sectional images from 10 patients with brain tumors. All images have been processed by data format conversion, brightness enhancement and noise reduction [14]. Neurosurgery and imaging doctors manually depict the true value region of brain tumor as the reference standard for training sample labels and comparative experiments.
In the semantic based image segmentation, it is necessary to classify and identify the pixels of the image. Considering the integrity of brain tumor tissue, the gray value of corresponding region pixels should be continuous. Therefore, in the detection process, we take the pixel as the center, extract the gray value of all the pixels in the adjacent 25
Schematic diagram of the image block extraction principle.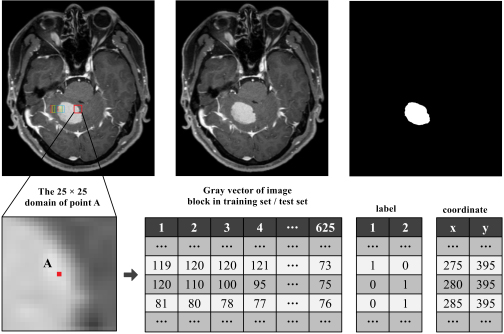
In the process of image block sampling, in order to save calculation cost and keep sample balance, different sampling rules are applied to the normal brain tissue and brain tumor area in the training samples. The normal brain tissue area is sampled every four pixels, and the brain tumor area is sampled once every other pixel. The category label and coordinates of the sampling points are recorded for each sampling.
In addition, considering that the construction of deep neural network requires a large number of training samples, in order to expand the number of training samples, and also to test the results of different brain tumor images segmentation by the method in this chapter, the experiment will use the “leave one” method for ten fold cross validation. Among the ten MRI images of brain tumor, one image is selected for testing in each round, and the other nine images are used as training set. The number of training samples and test samples collected in each round of experiment are shown in Table 1.
Number of samples per round
Through the above sampling method, each image block can get a 625 dimensional vector. As shown in Fig. 12, each dimension data in all image blocks is sorted, and 625 input layer nodes of stack noise reduction automatic encoder are input successively to generate the first layer neural network.
Schematic diagram of the input form of the input matrix.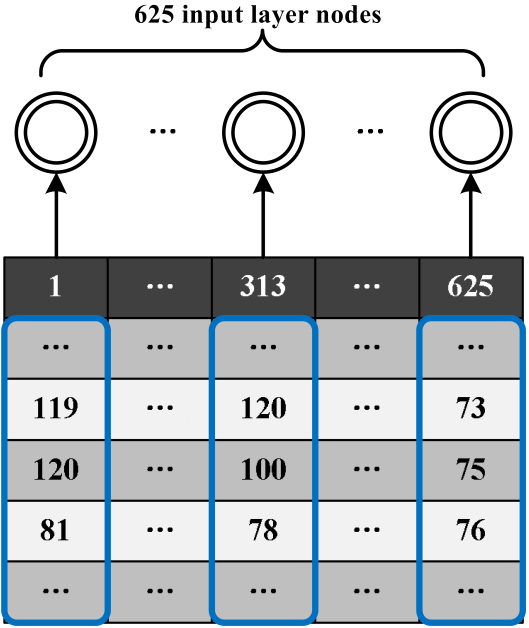
The random noise ratio of the initial input layer is set to 50% in order to enhance the robustness of the neural network after noise data reconstruction. In the process of further constructing the deep neural network, the following key parameters need to be set.
First of all, the number of intermediate layers and the number of nodes in each layer need to be determined. According to the empirical value, we give an assumed value of 100 for the number of nodes in each layer in advance, and then test the classification by setting different number of intermediate layers. Figure 13 shows the classification accuracy of each group of samples with different number of intermediate layers.
Number of intermediate layers test.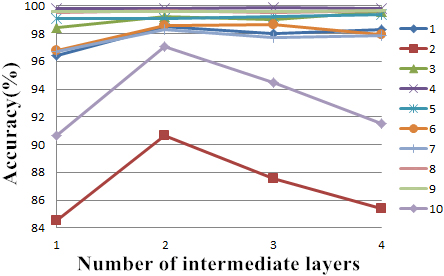
The lines with different colors in the figure represent different patient samples. Obviously, when the number of intermediate layers is set to 2, the recognition rate of most patient samples can reach a high level, especially for patient 2 and patient 10 with the lowest overall recognition rate. If we continue to increase the number of intermediate layers to 3 or 4 layers, the recognition rate of some patient samples can continue to improve, but the corresponding computational complexity will also increase. Therefore, in the subsequent experiments, the number of intermediate layers of deep neural network is set to 2 layers.
Second, three interrelated parameters need to be set: batch size, iteration and epoch (the Chinese translation names are batch size, iteration and period. Considering that the current Chinese translation is difficult to accurately express the meaning of parameters, the original English name is used for description later). Batchsize represents the number of samples in each training. Due to the problem that the number of samples is too large and the computer memory is insufficient in the training process of deep neural network, the running efficiency and utilization rate of memory can be effectively improved by limiting the number of samples participating in each training. Iteration is the number of iterations using batch size samples, while epoch represents a complete training using all samples in the training set. Therefore, the larger the value of batchsize set in training, the smaller the number of iterations (i.e. iteration value) required for a single epoch, and the total processing time and stability rate can be improved accordingly. However, with the increase of batchsize, the memory capacity required for a single iteration will also increase. Accordingly, more epochs are needed to obtain the best results. Therefore, the value of batchsize is very important. It needs to be tested according to the actual sample data and experimental environment, and then select a middle value that can balance the memory efficiency and memory capacity. Set the number of intermediate layers to 2 and the number of nodes to 100. Figure 14 shows the test results of training time under different values of batch size.
Different batch training times for size value.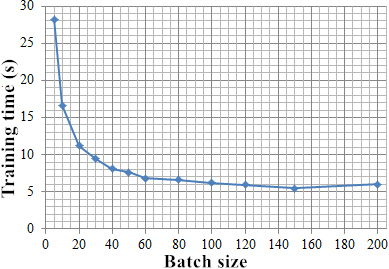
It can be seen that with the increase of the value of batchsize, the required training time decreases correspondingly. However, if the batchsize is too large, the memory overflow may not be calculated. Moreover, as the number of iterations required for a single epoch is reduced, more epochs are needed to obtain the same precision, but the overall running time is increased. Therefore, we choose a moderate batchsize value of 100 to limit the number of samples in a single training.
The value of iteration can be obtained automatically according to the total number of samples and the value of batch size. Next, we need to determine the number of epoch. When the value of batchsize is 100, Fig. 15 shows the influence trend of different epoch times on accuracy.
Influence of different epoch values on accuracy.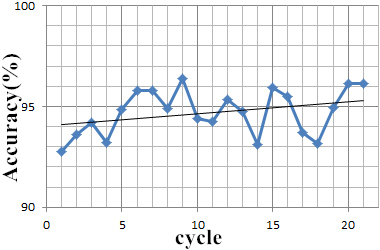
Generally speaking, the more epoch times, the higher the accuracy. However, with the increase of epoch times, the calculation time will also increase by multiple, and it is easy to over fit. Therefore, the range of values is generally limited to 10
In addition, according to the suggestions in the literature, we add dropout parameter (loss rate) in the training process of deep neural network. Its function is to make a certain proportion of neural nodes stop working at each training time, so as to reduce the complexity of neural network, and prevent over fitting phenomenon. The parameter of dropout suggested in the literature is 0.5, that is, 50% of the neuron nodes are randomly closed in each training. But after the actual test, we found that the dropout parameter set to 0.4 can achieve better classification accuracy. Figure 16 shows the classification accuracy with different dropout parameter values [16].
Dropout parameter test.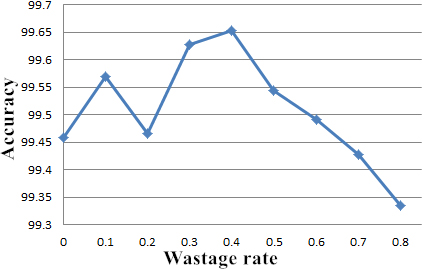
To sum up, in this experiment, we set the number of intermediate layers of deep neural network as 2 layers, the number of nodes in each intermediate layer is 100, and the number of single training samples is 100. In the pre-training process, the total number of training rounds for all samples is 15, and the number of fine-tuning is 20. In addition, the initial input layer noise ratio of stack noise reduction automatic encoder is 50%, and 40% nodes are randomly selected to stop responding in each training. Through pre-training and fine-tuning, the depth neural network based on stack noise reduction automatic encoder is obtained, and then the image block samples are classified.
In the previous chapter, stack noise reduction automatic encoder to build a depth neural network is used to classify all the image blocks in the MRI image to be segmented. Then, according to the category label of each image block, the central pixel points are mapped to the coordinate space of the original image one by one, and the binary image is reconstructed as the initial segmentation result.
Then, in order to get more accurate segmentation results, the initial segmentation results need to be further optimized. As mentioned above, the accurate segmentation of brain tumor tissue can be divided into three steps. Firstly, the depth neural network is used to detect the pixels belonging to brain tumor tissue, and the initial segmentation results of brain tumor are reconstructed in the original coordinate space. Then, the initial segmentation results are processed by threshold segmentation to remove the abnormal areas with large gray difference. Finally, the morphological processing method is used to optimize, eliminate the discontinuous small noise, fill the small space in the tumor area, and get the accurate segmentation results of brain MRI image. Figure 17 shows the results of each stage.
The segmentation results of the three stages. a. Initial segmentation results; b. Threshold segmentation optimization results; c. Morphological processing optimization results.
In order to more intuitively compare the changes of segmentation results in each step of processing, we list the segmentation accuracy of each patient sample in three stages, as shown in Table 2.
Segmentation accuracy of different stages
The result of segmentation compared with the true value
Figure 18 shows the comparison between the true value segmentation results of brain tumor regions of three patients and the segmentation results of this chapter. Among them, the real brain tumor area is manually described by neurosurgeons, as shown in Fig. 18b; the real brain tumor area manually labeled by doctors is mapped into a binary image as the true value segmentation result, as shown in Fig. 18c; the automatic segmentation results after secondary optimization in this method are compared, as shown in Fig. 18d. It can be seen that the brain tumor image segmented by the method proposed in this chapter is very close to the real result drawn by doctors.
Comparison of the segmentation results. a. The image to be segmented; b. Manually labeled tumor area; c. True value segmentation result; d. Automatic segmentation result.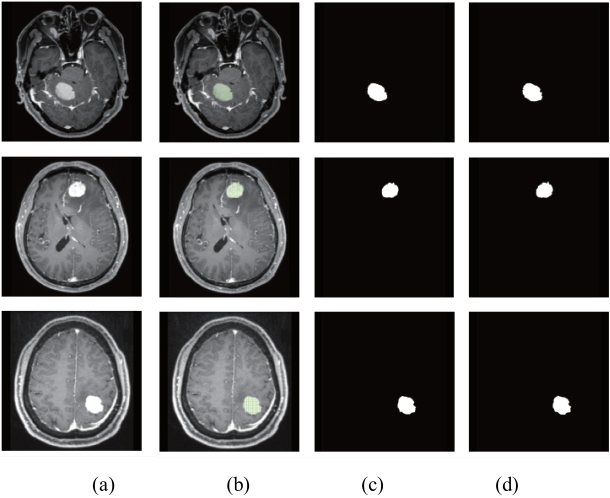
In order to more accurately calculate the approach degree between the method in this chapter and the true value, the segmentation results will be further evaluated by numerical evaluation index. Let the set of all pixels in the real brain tumor region be GT, and the set of all pixels in the brain tumor region segmented by this method is dl. The detection results are shown in Table 3.
The values in the table represent the number of pixels in the set. It can be seen that the number of DL and GT of all patients are very close. However, it should be noted that in the segmentation result DL, both the correct segmentation results belonging to the true value GT region and the wrong segmentation results not belonging to the GT region may exist. In the true value GT region, there are not only the regions correctly segmented by the method DL in this chapter, but also the regions not segmented. According to the interaction between the true value GT and the segmentation result DL, three evaluation indexes can be obtained.
Among them, true positive (TP) represents the correct pixel set of segmented tumor region, which is used to measure the correct number of segmentation results.
False positive (FP) represents the pixel set of non tumor areas determined as tumor tissue, which is used to measure the number of false positives in segmentation results.
False negative (FN) represents the set of pixels whose tumor area is determined as non tumor tissue, which is used to measure the number of missed judgments in segmentation results.
The performance of the segmentation algorithm can be measured more intuitively, and the proportion of the correctly detected tumor area in the actual tumor area can be measured by calculating the sensitivity, which is also called true positive rate or detection rate.
Table 4 shows the calculation results of each evaluation index. Among them, the higher the true positive value, the better, and the less false positive and false negative value, the better. It can be seen that the segmentation results obtained by the method in this chapter are very close to the true value, and the average detection rate is 96.24%.
The result of segmentation compared with the true value
The experimental results show that the proposed method has high sensitivity and good stability in the automatic segmentation of brain tumor tissue.
In this paper, we use deep learning method to solve the problem of semantic based medical image segmentation. A deep neural network is constructed by stacking automatic noise reduction encoder (SDA) to learn and classify image pixel blocks, and then realize automatic segmentation of regions of interest. Firstly, the unlabeled image block samples are used to train the stacked noise reduction automatic encoder, and the deep features of the image are learned and extracted to construct the initial depth neural network model; then, the labeled samples are used to fine-tune the initial depth neural network model, and the deep layer features of the image are corresponding to the category to obtain the depth neural network model with classification function; then, the depth neural network model with classification function is obtained. Finally, threshold segmentation and morphological methods are used to optimize the initial results to obtain accurate segmentation results. The experimental results show that the average segmentation accuracy is improved to 98.04% (before optimization) and 99.84% (after optimization), and the sensitivity is increased to 96.24%. At the same time, the running speed is also greatly improved compared with the traditional machine learning method.
Footnotes
Conflict of interest
None to report.