
Abstract
BACKGROUND:
Diabetes Mellitus (DM) is a significant risk, mostly causing blindness, kidney failure, heart attack, stroke, and lower limb amputation. A Clinical Decision Support System (CDSS) can assist healthcare practitioners in their daily effort and can improve the quality of healthcare provided to DM patients and save time.
OBJECTIVE:
In this study, a CDSS that can predict DM risk at an early stage has been developed for use by health professionals, general practitioners, hospital clinicians, health educators, and other primary care clinicians. The CDSS infers a set of personalized and suitable supportive treatment suggestions for patients.
METHODS:
Demographic data (e.g., age, gender, habits), body measurements (e.g., weight, height, waist circumference), comorbid conditions (e.g., autoimmune disease, heart failure), and laboratory data (e.g., IFG, IGT, OGTT, HbA1c) were collected from patients during clinical examinations and used to deduce a DM risk score and a set of personalized and suitable suggestions for the patients with the ontology reasoning ability of the tool. In this study, OWL ontology language, SWRL rule language, Java programming, Protégé ontology editor, SWRL API and OWL API tools, which are well known Semantic Web and ontology engineering tools, are used to develop the ontology reasoning module that provides to deduce a set of appropriate suggestions for a patient evaluated.
RESULTS:
After our first-round of tests, the consistency of the tool was obtained as 96.5%. At the end of our second-round of tests, the performance was obtained as 100.0% after some necessary rule changes and ontology revisions were done. While the developed semantic medical rules can predict only Type 1 and Type 2 DM in adults, the rules do not yet make DM risk assessments and deduce suggestions for pediatric patients.
CONCLUSION:
The results obtained are promising in demonstrating the applicability, effectiveness, and efficiency of the tool. It can ensure that necessary precautions are taken in advance by raising awareness of society against the DM risk.
Keywords
Introduction
Diabetes Mellitus (DM) is a disease about elevation of blood glucose level that occurs when the pancreas does not produce enough insulin hormone or when the insulin hormone cannot be used effectively [1]. DM can be caused by many factors including genetic and environmental factors, such as age, gender, obesity, sedentary lifestyle, and smoking [1].
Diabetes comprises many disorders characterized by hyperglycemia. According to the clinical classification, there are two major types of DM: Type 1 and Type 2 diabetes. The distinction between the two types has historically been based on age at onset, degree of loss of
The term diabetes describes a group of metabolic disorders characterized and identified by the presence of hyperglycemia in the absence of treatment [4]. The long-term specific effects of diabetes include retinopathy, nephropathy, and neuropathy, among other complications. People with diabetes are also at increased risk of other diseases including heart, peripheral arterial and cerebrovascular disease, obesity, cataracts, erectile dysfunction, and non-alcoholic fatty liver disease. They are also at increased risk of some infectious diseases, such as tuberculosis [4]. Many people who do not show the symptoms of DM have not been diagnosed yet. These people continue their lives without be noticed of their risk. In this case, medical diagnosis is essential, which is the process by which physicians/health practitioners diagnose their patients’ risk based on observed symptoms and laboratory test results.
With the evolution of technology, the applications of Decision Support System (DSS) have evolved significantly since the early 1970s. Numerous technological and organizational developments have employed an impact on this evolution. DDS combines data and information from different fields and sources to provide users with the information they need. Thus, it aims to help individuals make informed decisions. DSS comprises both human knowledge and technology to assist and improve decision-making [5]. In the medical field, DSSs have become popular computer-aided tools especially in medical diagnosis [6].
Furthermore, a Clinical Decision Support System (CDSS) enhances the effectiveness of health systems while saving costs and eliminating medical test duplication, eliminating possible risks, and recommend less costly but equally effective treatments [6]. A CDSS uses a domain knowledge base and a set of predefined medical rules on a patient’s data to produce a diagnostic result for physicians or health practitioners [6, 7]. Therefore, physicians or health practitioners using a CDSS can have a second opinion in the diagnosis and treatment of diseases by avoiding/minimizing medical errors and using data collected from patients’ past/current medical conditions [6].
In this study, an ontology knowledge based CDSS is developed as a clinical tool for healthcare professionals, general practitioners, hospital-based clinicians, health educators, and other primary care clinicians. The aim of the proposed system is to assist health practitioners and professionals, especially in the conduct of primary health care, preventive health practices and facilitating early diagnosis. First, the system takes a set of necessary information (e.g., patient profile, available medical conditions, certain blood laboratory test results) of a patient, then calculates a risk score and attempts to predict the DM risk at an early stage and deduces a set of personalized supportive treatment suggestions. For inferencing mechanism of the system, an ontology knowledgebase is built around medical knowledge in the form of rules and extensive conceptual information about diagnosing DM risk. Thanks to the semantic rules in the ontology developed, the system can infer a set of personalized supportive treatment suggestions to healthcare practitioners or professionals before making any decision for a particular patient.
The remained of the paper is structured as follows: Section 2 covers the background about recent diagnosing methodologies used in DM risk. Section 3 explores the technologies used in developing DSSs and the similar studies published in literature. Section 4 presents the components and features of the proposed CDSS. Section 5 presents the development of ontology knowledgebase and semantic medical rules of the system. Section 6 presents a case study and Section 7 discusses the evaluation of experimental results conducted and the contributions of the system. Finally, Section 8 presents the summary and conclusions.
Background
Diabetes mellitus
DM is a metabolic disease characterized by hyperglycemia due to the inability of the pancreas to produce enough insulin hormone. DM can be classified in different depending on the type and conditions [8]. In clinical classification of DM, there are two major types: (1) Type 1 diabetes (T1DM) and (2) Type 2 diabetes (T2DM). In addition, DM can be observed depending on physical or medical conditions of individuals: (3) Prediabetes and (4) Gestational Diabetes.
(1) T1DM is a type of DM, which occurs when the pancreas cannot produce enough insulin in blood. Genetic and environmental factors are generally effective in the development of T1DM, but many risk factors have not yet been identified and remain a big challenge.
(2) T2DM is another type of DM, in which insulin is produced but is defective and cannot transport glucose into cells. T2DM has more risk factors than T1DM. In general, age, obesity, family history of diabetes, history of gestational diabetes, impaired glucose metabolism, physical inactivity, and race/ethnicity, etc. factors are highly associated with T2DM. In literature, T2DM accounts for approximately 90.0% to 95.0% of all diabetes cases diagnosed in adulthood [2, 8].
(3) Prediabetes is a condition in which individuals have high blood sugar or hemoglobin A1C levels but not high enough to be classified as DM. People with prediabetes have a higher risk of developing T2DM over time [8].
(4) Gestational Diabetes is diagnosed in the second or third trimester of pregnancy. It is known as a type of glucose intolerance that usually disappears once the pregnancy is over. Between 5.0% and 10.0% of women with gestational diabetes continue to have high blood sugar levels, and then diabetes often develops into T2DM. In addition, the children of these women are at risk of developing obesity and diabetes later in life [2, 8].
Diagnosing DM in asymptomatic adults
Many candidates of DM do not show any symptoms in the early stages. In this case, occasional medical screening is necessary especially in asymptomatic cases with the following risk factors:
(1) Testing should be considered in adults with overweight or obesity related to Body Mass Index (BMI) [9] who have (BMI
First-degree relative with diabetes, High-risk racial/ethnicity (e.g., African American, Latino, Native American, Asian American, Pacific Islander), Presence of cardiovascular disease, Hypertension ( HDL cholesterol level Women with polycystic ovary syndrome, Physical inactivity, Other clinical findings associated with insulin resistance (e.g., severe obesity, acanthosis nigricans).
(2) Patients with prediabetes {A1C
(3) Women who were diagnosed with gestational DM should have lifelong testing at least every 3 years [10].
(4) For all other patients, testing should begin at age 35 [10].
(5) If results are normal, testing should be repeated at a minimum of 3-year intervals, with consideration of more frequent testing depending on initial results and risk status [10].
(6) People with HIV [10].
If there is no BMI risk and the factors given above, a person should have continuous screening after the age of 45. If results are normal, screening should be repeated at least every 3 years [10, 11]. Alternative screening for DM can be identified by the medical blood tests detailed below.
Comparison of T1DM and T2DM
As it is mentioned before, DM falls into two major categories: T1DM and T2DM [2, 8]. T1DM and T2DM may cause different symptoms in the human body. The comparison of T1DM and T2DM is detailed in Table 1 [10, 11].
T1DM is caused by an immune attack in which the body’s immune system destroys the pancreas’ insulin-producing cells. The body generates little or no insulin. People with T2DM should get daily insulin injections to keep their glucose levels within the normal range and survive. However, they may continue their lives normal or reduce the consequences of DM with daily insulin dosing, periodic blood glucose testing, knowledge, and care [11]. Hyperglycemia in T2DM is caused by the body’s cells’ failure to respond sufficiently to insulin. It is known as insulin resistance. In that case, the hormone is ineffectual and causes the increment of insulin levels and pancreas cannot produce demand enough insulin for the cells. Typically, it occurs in adult people who are usually above 30 years. Recently, it started to be seen in children and young adults due to increased obesity and inefficient daily activities.
Prediabetes occurs when blood sugar level is higher than normal but not yet high enough to be T2DM.
DM can be diagnosed in a variety of ways. Major tests used for diagnosing DM are (1) Fasting Plasma Glucose (FPG), (2) Random Plasma Glucose (RPG), (3) Oral Glucose Tolerance Test (OGTT), and (4) HbA1c and only one of the criteria is sufficient to diagnose DM [1, 2, 11].
The limit values of FPG, RPG, OGTT, and HbA1c in diagnosing of DM
The World Health Organization (WHO) recommends the HbA1c test to use in diagnosing DM [4]. OGTT and HbA1c, which are highly used in diagnosis of DM, have no superiority over each other in terms of diagnostic value [2, 12]. The limit values of these tests are shown in Table 2.
As mentioned before, prediabetes is a condition defined as blood sugar levels above normal but below the defined diabetes threshold [2, 12]. The same tests (given in Table 2) are also used to identify individuals with prediabetes. Furthermore, to diagnose prediabetes, two other medical tests are possible to check to diagnose prediabetes, which are Impaired Fasting Glucose (IFG) and Impaired Glucose Tolerance (IGT). WHO and IDF currently propose a 2-hour OGTT for the testing of IGT and IFG [2]. Physicians may identify prediabetes as IFG or IGT based on the test used to diagnose it. The ranges determined to define prediabetes according to IFG, IGT and HbA1c values are shown in Table 3 [1, 2, 10, 11]. Individuals diagnosed with prediabetes are potential DM patients.
The ranges for diagnosing “prediabetes”
For decades, indicating if a person has DM, prediabetes, or not is based on glucose criteria, either FPG or the 75-g OGTT [1]. When the HbA1c test is applied, it is possible to say that patient has DM, if the value of HbA1c is 6.5% or higher. When it is measured between 5.7% and 6.4%, the patient is detected as prediabetes, and when it is less than 5.7%, the patient is called normal.
Another common test is FPG and if its result is 126 mg/dl or higher, it is possible to say that the patient has a risk of DM. If the FPG result is less than 100 mg/dl and the patient has no symptoms, then it is called normal. Otherwise, a 2-hour plasma glucose test should be performed in order to detect IGT and/or IFG for prediabetes. The general algorithm based on FPG in diagnosing DM is shown in Fig. 1.
Diagnosis algorithm of DM by IDF [2].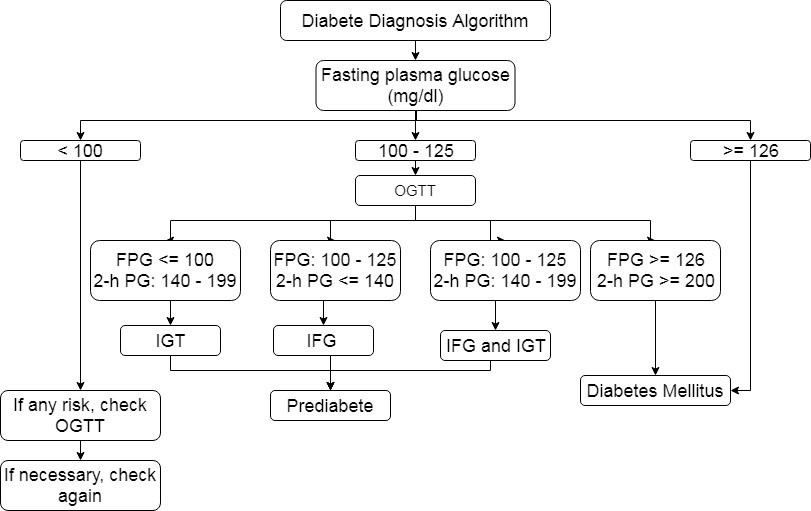
Prospective studies have revealed that lifestyle behaviors such as poor diet, alcohol consumption, insufficient physical activity and sedentary life, smoking are highly associated with having DM [13]. To evaluate lifestyle related risk factors and assess the prevalence of glucose metabolism disorders, a risk assessment questionnaire is obtained and used in DM evaluation [14]. In this questionnaire, each response option has a different weight in the DM’s assessment model. At the end of the assessment, a total risk score of a person having DM is calculated which gives the risk of developing T2DM within 10 years [14]. This questionnaire was used to determine a person’s DM risk score in the CDSS developed in our study and the questions with its options are given in Appendix A [14]. If the total score is lower than 7, the risk of having DM within the next 10 years is low. If it is between 7 and 11, the patient has slightly elevated DM risk. If it is higher than 11 but less than 15, then having such a risk is moderate. If it is between 15 and 20, this risk is high. If the score is higher than 20, the patient is under very high risk to have DM within next 10 years [14].
As a conclusion, it is required regular medical check-ups, continuing good self-care, and enough knowledge to prevent the severe complications of DM and reduce its long-term complications. Every patient with T2DM should have access to a well-structured lifestyle change program that helps achieve and maintain a BMI in the appropriate range, an accurate physical activity routine, and control of cardiovascular risk factors, as well as glycemic index. The CDSS proposed, is a sophisticated health information technology tool, can be used to ease and manage these activities, and assess its long-term complications over time. Diagnosing and predicting of the DM based on lifestyle and/or blood test results for a patient with the help of a systematic computerized CDSS tool is possible.
Methodology and related works
Technologies used in developing of DSS
Knowledgebase is an information collection that can be used in decision-making tasks. An expert system also known as a knowledge-based system is a computer program that involves the knowledge and analytical skills of one or more human experts in a specific problem domain (e.g., medical diagnosis) [15]. As mentioned before, DSS concept is a wide that covers various areas of assisting people with decision-making and offering automated intelligent help when needed. A DSS, for example, can assist a physician in deciding which prescription to recommend based on a patient’s past health records and a drug company repository, whereas a recommender system is able to advise identical products by evaluating previous user behaviors and immediately making recommendations with a product database [5].
By using knowledge bases and considering Information Retrieval and Natural Language Processing (NLP) methods, a DSS can be developed that could be smarter and effective in the decision-making tasks. Semantic Web is an extension of the existing web and is also a sub-branch of artificial intelligence [16]. Semantic Web promotes improved collaboration between user and computer and let users to figure out the answers to their questions through ontologies. Ontology is the systematic representation of a domain knowledge such as classes (or sets), attributes (or properties), and relationships (or relations among class members) [17]. It is used for sharing knowledge. In ontology, class represents the sets such as patients, symptoms, and disease. Attributes refers to the relationship between the classes or sets. Instance represents an element of a class.
Many ontological languages, such as Resource Description Framework Schema (RDFS) and Web Ontology Language (OWL), have recently been suggested and standardized by W3C for modelling ontologies [18, 19]. OWL is a family of knowledge representation languages used for reasoning on ontologies, according to the World Wide Web Consortium (W3C). OWL can be categorized into three species or sub-languages: OWL Lite, OWL DL and OWL Full [16].
The rules language of the Semantic Web is intended to be the Semantic Web Rules Language (SWRL) [20, 21]. SWRL is used to define rules as well as logic, combining OWL DL or OWL Lite with a subset of the Rule Markup Language. The rules are used to infer new knowledge from existing knowledge on an OWL knowledgebase.
In this study, a CDSS based on ontology knowledge was developed as a clinical tool, consisting of the following components: (1) a database, (2) an ontology knowledge base, (3) semantic medical rules, (4) an inference engine module, and (5) portal user interface.
The database is a collection of patients’ data and domain related information. The ontology knowledge base of the system is developed by using OWL and comprises domain information of DM, and its semantic medical rules on diagnosing and treatment of DM. The semantic medical rules represent the knowledge of healthcare professionals who specialize in DM management and the directives in Clinical Practice Guidelines, which are conditional statements systematically developed to assist health practitioners/professionals in making decisions about appropriate health care under certain circumstances [10, 22]. The reasoning component is an Inference Engine, which is Java module used to send a patient’s data collected to the system ontology and execute its proper semantic rules on a patient’s instance (e.g., observed symptoms and signs, physical activities, risk factors, and blood test results) to deduce a set of personalized and supportive treatment suggestions and obtain a DM risk score. The portal user interface manages the entire operations on the patient data, provides access to the ontology knowledge base for inferencing tasks, and maintains the entire relationship between a user and the system.
There have been similar efforts on CDSSs that use the ontology knowledge base and have semantic medical rules [23, 24, 25, 26, 29, 30, 31, 33]. As in similar studies, we have developed an ontology to model key concepts and relationships of clinical practice in DM diagnosis to allow for clinical knowledge sharing, updating, and reuse. This section discusses the similar studies in the designing and developing ontology based CDSSs proposed in literature on diagnosis and management of DM and other risks.
Chen et al. proposed a recommendation system that suggests the most appropriate drugs for DM patients. They analyzed 51 medicines’ nature attributes and side effects to build anti-diabetic drugs ontology and patient data ontology [24, 25]. They built 96 rules related anti-diabetic drugs by using SWRL and Java Expert System Shell (JESS) was used for reasoning to select the most proper prescription for the patients [27]. Twenty (20) patient test data were used to check the precision of the system and the recommend drugs rate. The recommended medicines were derived from user information parameters such as HbA1c value, the liver function, renal function, gastrointestinal dysfunction, heart failure and hypoglycemia. Their system was evaluated by a physician. According to their results, their system was successful since the recommendation system agreed doctor requirements.
Mahmoud and Elbeh proposed an individualized recommendation system for T2DM medication [27]. They built two different ontologies. One was for anti-diabetic drugs, and one was for patient knowledge. Their system provided the HbA1c target, drug selection and its dose. They used SWRL and Jess inference engine. Their system was evaluated by doctors for 30 patient records. Precision was calculated as 100.0% for all test cases.
Sappagh and Elmogy designed a fuzzy case base ontology that could model different types of features like text, ordinal, semantic, numerical, and fuzzy types [28]. Their model had 63 OWL Classes, 54 Object Type Property, 138 Data Type Property and 105 Fuzzy Data Types and 60 cases. They applied different evaluation methodologies which are consistency checking, comparison against a gold standard, user-based or criteria-based evaluation, lexical, vocabulary or data level evaluation and vagueness evaluation. Their results showed that their system was accurate, consistent, and addressed the concept and reasoning of diabetes mellitus diagnosis.
Sappagh et al. introduced DM Treatment Ontology (DMTO) about treatment of T2DM patients [29]. Their system diagnosed the patients’ current situations, lab results, symptoms, family, and medical background. They also provided to monitor the previous treatment plans if a patient already had T2DM, treatment plans based on the patients’ drugs, complications and offered some advice for diet and exercise if necessary. They included more than 10700 classes, 277 relations, and 214 semantic rules in their ontology. They asserted that DMTO could be used as a knowledge base to analyse the most appropriate medicines, foods, and exercises for T2DM patients.
Putra et al. developed a system that diagnoses DM risk by using a weighted ontology and weighted tree [30]. Two ontologies were built on the DM knowledge and classification. JENA reasoner was used in implementation of inferencing task. According to patients’ data, their system performs a similarity matching. Hundred patient data were used, and their system was evaluated by doctors. Consistency of their system was performed as 93.0%. Based on information fusion and the construction of a context ontology, Chen et al. presented a personalized RS of antihypertensive medicines [31]. Their system can detect the users’ context in real-time using wearable and medical smart sensors, and it gives dependable antihypertensive medicine prescriptions. They employed Semantic Web and ontology engineering tools to assess user interests. SWRL was used to develop the rules for reasoning of their system to recommend medicines. The researchers also used three types of information suggestion rules that corresponded to different priority levels.
The proposed system is compared with others
The proposed system is compared with others
The researchers also used three types of information recommendation criteria that correspond to various priority levels, as well as a sorting algorithm to enhance the suggestions provided. The SWRL rules were executed by researchers using the fastest rule engine JESS developed by Ernest Friedman to infer new knowledge. To match patterns, the engine employs the Rete algorithm [32].
Chandra et al., using Optical Character Recognition (OCR) and Natural Language Processing (NLP) methods, aimed to infer the named entities required for name, age, gender, test parameters, complications, etc. These extracted assets were then used to create the system ontology with OWL technology. Next, the researchers created 37 SWRL rules to provide constraints on their ontology. Researchers claimed that information such as disease, diagnosis, treatment, drugs from patient documents can be searched and edited with OCR. Researchers have focused on developing an appropriate treatment plan according to the needs of the patient and developing a clinical decision support system for this. The outputs of the study; (1) DM diagnosis and management ontology, (2) provide necessary guidelines for diagnosing T1DM, T2DM, and GDM and recommending care, (3) SWRL guidelines for diagnosis and treatment of DM. Their proposed approach was tested on a character recognition dataset and the OCR used effectiveness was 94.0% accuracy, while the system success was evaluated as 84.0% on 38 DM patients [33].
The proposed system and all similar studies discussed above are compared in Table 4.
The system developed utilizes the following units and presents returned results to the physician or health practitioners via its user interface. The system consists of the following components: (1) Diabetes Mellitus Diagnosis and Support Ontology (DMDSOnt), (2) Semantic Web Rule Knowledgebase (SWRL rules), (3) Inference Engine module, (4) System Database, and (5) Portal User Interface Framework of the CDSS developed. The components of the system are shown in Fig. 2 and its functionalities are given below.
Components and functioning of the proposed system.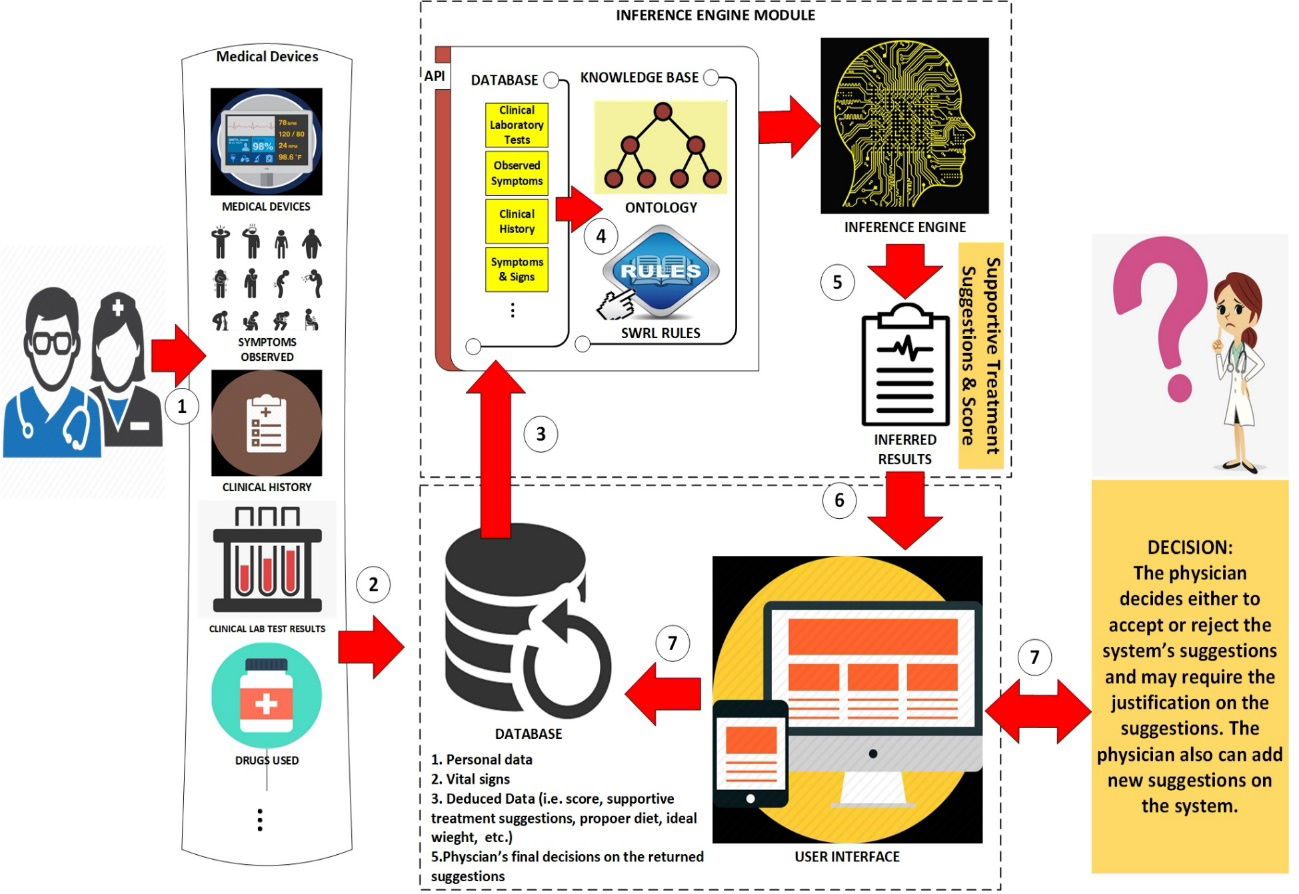
(1) and (2) DMDSOnt and SWRL Rules: IDF Clinical Practice Recommendations for the management of T2DM in primary care aim to summarize the available evidence for optimal management of people with T2DM [2, 10]. The guide is intended to be a decision support tool for general practitioners, hospital-based clinicians, and other primary care clinicians working in the DM field [2, 10]. For this reason, in this study, an ontology database, called Diabetes Mellitus Diagnosis and Support Ontology (DMDSOnt) has been developed using OWL 2.0 ontology language according to the directions determined in the IDF’s guidelines [2, 10]. As required and directed in the guidelines of IDF, DMDSOnt contains metadata about the signs and symptoms observed in DM, active lifestyle criteria expected from patients, patient genetic status possibilities, physical activities to be followed, necessary laboratory tests, other factors/criteria in the diagnosis of DM, and recommendations for the proper management of DM risk [2, 10].
(3) Inference Engine (IE), often known as the ontology reasoner, is a crucial component of the proposed system. IE is written in Java that executes SWRL rules on the data of a patient instance and produces certain inferencing results for the experts to verify the patient’s DM risk. Many other forms of reasoners are accessible in the literature, including Pellet [34], Hermit [35], FaCT
(4) Database consists of various medical records that are collected from registered patients (e.g., profile, observable symptoms, blood test results, genetic history, etc.).
(5) Portal User Interface Framework is a web/mobile application, which provides the interaction between the user and system, is enabled through an application user interface. The interface displays the patient information to its user (e.g., a healthcare professional, general practitioner, hospital-based clinician, health educator, and other primary care clinician) who utilizes the information to diagnose a patient with DM. The application presents: (1) the estimation result of a patient case as DM risk level and (2) a set of appropriate supportive treatment suggestions inferred by the system. Table 5 summarizes the main features of the system.
Characteristics of the proposed system
The development of the system and ontology reasoning via its semantic medical rules will be discussed in detail in the following sections.
DMDSOnt is the systematic modelling of domain knowledge, such as concepts (or classes), attributes (or properties), and relationships (between class members) of methods used in the diagnosis and management of DM. In addition, a set of semantic medical rules using SWRL has been implemented on DMDSOnt [20] DMDSOnt is developed by using OWL and SWRL languages and built with the Protégé editor [21].
A portion of the system ontology – DMDSOnt.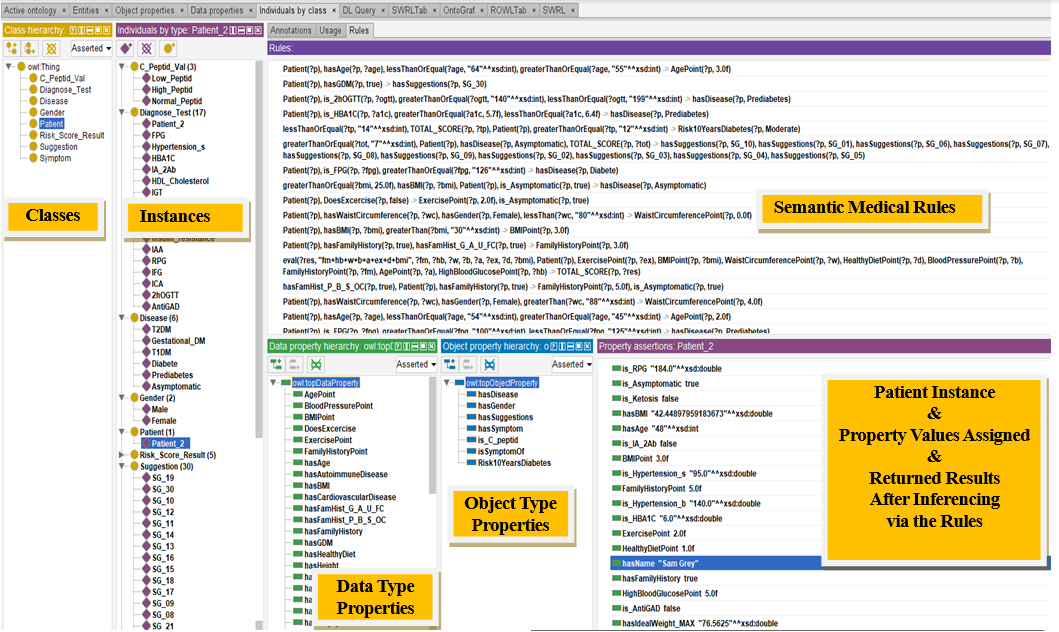
Figure 3 shows a portion of the DMDSOnt developed using Protégé. In DMDSOnt 8 high-level classes have been created: “Disease”, “Patient”, “Suggestion”, “Symptom”, “Gender”, “C_Peptid_Val”, “Diagnose_Test”, and “Risk_Score_Result”.
“C_Peptid_Val” class contains 3 instances, which are “Low_Peptid”, “Normal_Peptid” and “High_Peptid”. “Risk_Score_Result” class is created for listing the risk of having T2DM within 10 years and has 5 categories: “Low”, “Slightly_Elevated”, “Moderate”, “High”, and “Very_High”. “Disease” class is created for listing the 5 types of DM risk: “Diabetes” {(1) “T1DM”, (2) “T2DM”}, (3) “Prediabetes”, (4) “Asymptomatic”, and (5) “Gestational_DM” as instances (or as OWL individuals). “Patient” class is used for keeping patient case as an instance on the DMDSOnt. “Symptom” class includes all potential symptoms known and observed in DM as sign and symptom instances. “Gender” class involves gender types (female/male). “Suggestions” class contains various medical suggestions assigned to the patients analysed after inferencing. “Diagnose_Test” class contains the types of laboratory medical tests applied in diagnosing of DM, which are proposed by IDF [10].
Data type properties
To keep variety of patient data and obtain a risk score on DMDSOnt, various Data Type Properties (DTP) have been created as relationships between classes and data types. In a two-sided DTP relationship, a domain indicates an OWL class, while a range indicates a data type. The domain value restricts the class of subject in triple of the extension of the DTP and the range value restricts the range of the DTP value. Table 6 provides some of DTPs created on DMDSOnt with their domain and range.
Object type properties (OTP) developed
Object Type Properties (OTP) represents a relationship established between two instances of two classes. There are 7 OTPs created on DMDSOnt that are listed in Table 7. The first column represents the name of an OTP, the second column represents the domain class of that OTP, and the third column represents its range class.
Object type properties
Object type properties
The semantic medical rules developed represent the knowledge of healthcare professionals working in the field of DM and the directives defined in Clinical Practice Guidelines [1, 2, 4, 9, 10, 11]. These directives are conditional statements systematically developed to assist health practitioners/professionals in making decisions about appropriate health care under certain circumstances. As mentioned earlier, SWRL is used to develop semantic medical rules that allow to predict DM risk at an early stage based on a risk score and to derive a set of personalized supportive treatment recommendations. In this study, 60 SWRL rules are designed based on the directives given in the research studies [1, 2, 4, 9, 10, 11] and a few of them are detailed in Table 8. For example, to determine the Prediabetes category, FPG, 2hOGTT or HbA1c values should be checked, as mentioned earlier. Accordingly, Rule #22 is developed to identify the prediabetes by considering the availability of FPG level between 100 and 125 (as depicted in Table 3). In addition, Rule #1 calculates a patient’s BMI, while Rule #18 calculates a patient’s total DM risk score to estimate the risk of having T2DM within 10 years based on responses given to the questionnaire of CDSS developed.
An example set of semantic rules developed on DMDSOnt using SWRL
An example set of semantic rules developed on DMDSOnt using SWRL
To run the semantic medical rules on the DMDSOnt, the inference engine module of the system connects to the ontology knowledge base and executes the entire SWRL rules based on the data of a patient instance (e.g., profile details, the symptoms and signs observed, availability of physical activities, other risk factors, and recent blood test results) to evaluate a risk score and deduce a set of personalized supportive treatment suggestions for that patient. Based on the risk score obtained, the system can determine whether the patient instance has DM risk or what the risk level is of developing DM within 10 years.
The next section discusses the system usage via a case study. All rules developed are given in Appendix B.
The user interface where patient data and laboratory results are collected on the left. The system calculates a risk score and deduces a set of personalized supportive treatment suggestions using the SWRL rules on the DMDSOnt for the patient.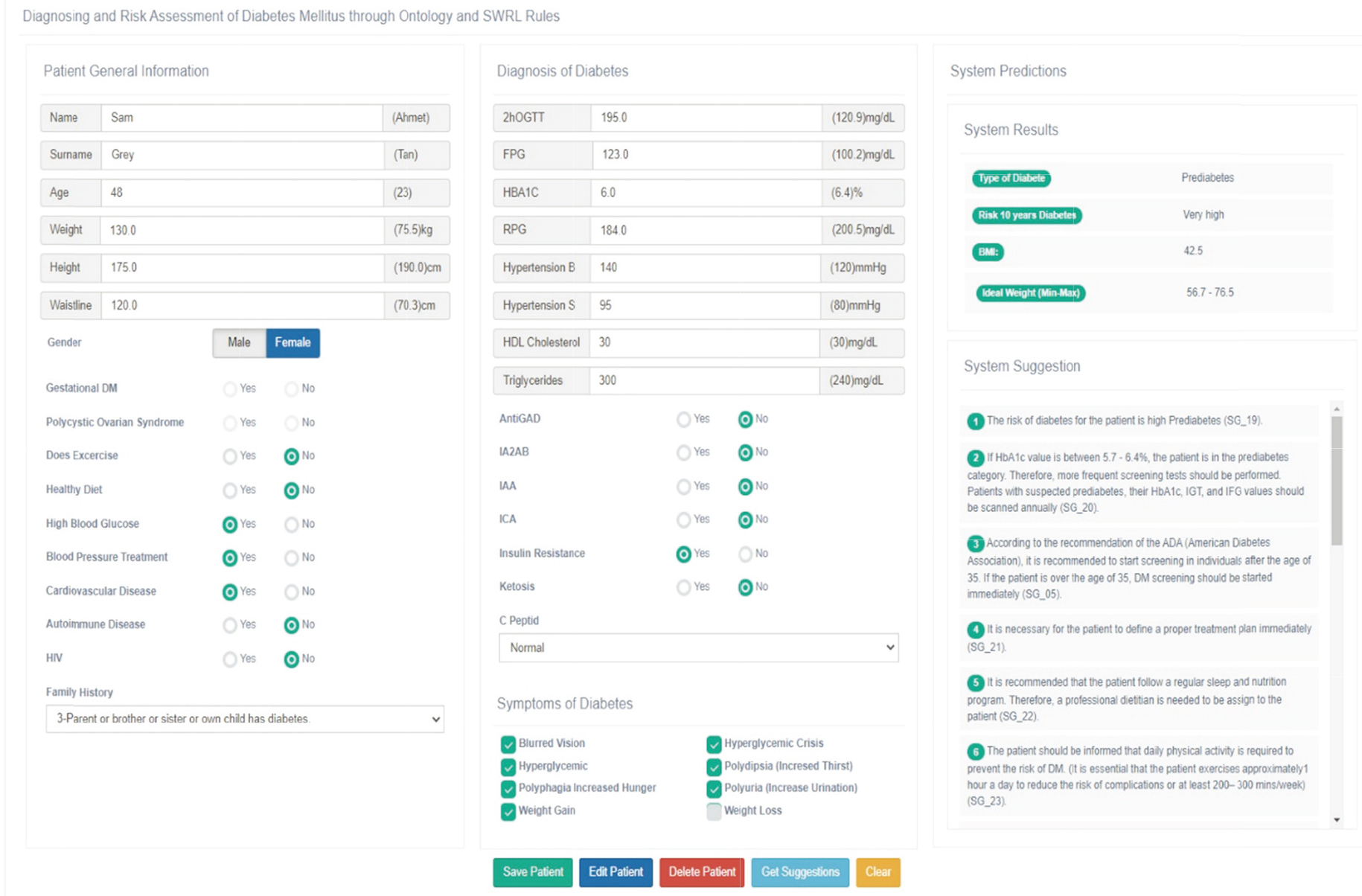
Mobile application interface of the system developed.
Used tools
The system was developed on NetBeans platform with Java Script, JSP and Java languages. As mentioned earlier, the Semantic Web technologies such as OWL and SWRL have been used as they not only help to understand the meanings of words in a document, but also help extract new data from existing data through its semantic rules involved. To execute the SWRL rules on a Java class, the OWL API [39], Pellet Reasoner API [34], and SWRL API [38] were used. For development of DMDSOnt, the Protégé ontology editor [40] is used. Both the OWL API and the SWRL API are Java-based and allow to connect to DMDSOnt and execute various operations through the system’s Java classes using existing Java libraries. While the OWL API performs various operations on the ontology (e.g., connect, search, insert, delete, update) via Java classes, the SWRL API runs OWL-based SWRL rules built into the system ontology to infer new data from existing data and uses SQWRL in query operations on the ontology.
System evaluation from healthcare workers through a case study
Figure 4 illustrates a user screen (e.g., a healthcare professional, general practitioner, hospital-based clinician, health educator, other primary care clinician), which allows to the user enter his/her patient’s data during diagnosing and assessment DM risk in the clinical or home environment. As shown in Fig. 4, the system user fills first his/her patient’s data (e.g., name, date of birth, gender, physical activities, family medical history, etc.) using the profile form on the left, symptoms observed (e.g., blurred vision, hyperglycemic crisis, weight gain) on the right corner, and recent laboratory test results (e.g., 2hOGTT, FPG, HBA1c) in middle of the form to obtain a DM risk score and deduce a set of supportive treatment suggestions for that patient. After the user collects the required data of that patient, the system sends all the patient data to the DMDSOnt. The next step after sending the patient data collected to DMDSOnt is to determine a total DM risk score based on the responses to the questionnaire the system sends to that user. The purpose of this step is to determine the total risk score for that patient, taking into account the patient’s lifestyle and habits in addition to the information collected in the previous step. The questionnaire used in this step regarding the lifestyle of the patients is given in Appendix A.
As shown in Fig. 4, the profile details, daily lifestyle, signs and symptoms observed, and recent laboratory test results of the patient case (“Sam Grey”) were filled to the required fields on the form. Furthermore, as shown in Fig. 4, the patient that needs to be evaluated can be searched and retrieved in the database. In the next step, the “Get Suggestions” button must be enabled by the user to initiate the inferencing of the appropriate supportive treatment suggestions on the DMDSOnt for that patient. After inferencing task is complete, the system automatically deletes the patient data processed lastly from the system ontology to ensure that the DMDSOnt does not swell over time. The inferencing outcomes are always kept in the patients table in the database. Figure 5 shows the same case study on the mobile application interface.
Table 9 shows all input data collected from this discussed case (“Sam Grey”). Based on these data, the suggestions inferred by IE for that patient are presented in the “System Predictions” panel of the patient form shown on the right in Fig. 4. The system inferred that the patient was at high risk of prediabetes. In addition, it inferred a set of personalized supportive treatment suggestions (21 suggestions) considered suitable for that patient and presents them to assist the physician/health practitioner user (seen on the Fig. 4).
Asserted data to the DMDSOnt for a case study focused
Asserted data to the DMDSOnt for a case study focused
In conclusion, the results deduced from the DMDSOnt for one questioned patient: “Type of Diabetes” “Risk of Diabetes in 10 Years” “BMI” “Min. Ideal Weight” “Max. Ideal Weight”, and “Personalized Supportive Treatment Suggestions”. The suggestions inferred by the IE of the system for the patient case (“Sam Grey”) are shown on Table 10.
Results returned from DMDSOnt
In addition, system users can search and edit previously assessed and saved patient results, initiate new inference processes for the new/existing patients, insert/delete patients to/from the system database, etc. Traditional database operations except inferencing operations have not been discussed on the case study focused with details in this section due to page limitation constraints. All supportive treatment suggestions (30 suggestions) created in the system ontology according to the five main DM risk definition categories and patient risk score ranges are given in detail in Appendix C.
Machine learning models can be used to classify diabetes and cardiovascular diseases early such as the Artificial Neural Network and Bayes Network [41, 42]. According to some effective research studies in the literature, it has been stated that a higher accuracy result can be obtained when Artificial Neural Networks are applied, with the possibility of obtaining better accuracy in both DM and cardiovascular disease classification. Classification through Artificial Neural Network techniques as in machine learning is not under the assessment of knowledge and rule-based expert systems. To achieve better system accuracy, the accuracy is calculated by considering the match between the recommendation deduced by an expert system and the ground-truth value. Therefore, accuracy determines how accurate the system is and how accurate the recommendations suggested by the system are. The following sections discuss the accuracy-based performance of the system, considering the domain knowledge, the recommendations inferred by IE, and the expected recommendations.
Validation of rules on the domain knowledge
In rule-based systems, each rule modelled on the rule-base is expected to be able to maintain the integrity of the domain knowledge and process each circumstance of the domain knowledge, so that accuracy is determined for that rule. Whether a rule represents all that part of/only that part of the domain knowledge that it is supposed to be modelled, gives us a notation of the accuracy of the rule [43]. If a rule that does not meet this issue, will not perform exactly as the domain knowledge that it claims to represent, and can, in turn, lead to inaccurate responses from the system. Thus, the rule would be inaccurate [43]. For instance, let us consider the combination of RULE #32 and RULE #33 in our rule base and rename it as a new rule,
and, the knowledge item
Apparently, the
A sample universe
A sample universe
Therefore, the rules should contain a complete model of the domain knowledge and be created in a way that does not impair the integrity and accuracy of the domain knowledge. This may require, in some special circumstances, the creation of individual but interoperable rules. In our case, the presence of any of these three conditions (high systolic hypertension, high diastolic hypertension, high triglyceride) is sufficient to automatically place the patient in the asymptomatic category [10, 22].
Consequently, these rules are handled separately in our rule base. Other rules that process the outputs of these rules as inputs maintain the integrity of our domain (see Appendix B).
In this study, while modelling the rules, the integrity of the domain knowledge, the interoperability of the rules and the correct modelling of the rules based are collaborated with a DM specialist. The rules were verified with test studies on 30 patient cases on the Protégé tool, and the accuracy of each rule was ensured after the necessary corrections were made. Other test studies belong to these patient cases are presented in the next section.
In experimental studies, thirty (30) anonymous patient records from Near East University Faculty of Medicine were collected retrospectively by the collaborating physician to evaluate the system results. Each record uses similar inputs as shown in Table 9 and executes its inferences. The evaluation of the system was applied by considering the following approaches:
Matching tests on inferred results by IE and expected results
The data of each patient case was entered into the system by the collaborating physician using the application interface. The “Get Suggestion” button on the application interface was enabled for each patient case. Next, the system loaded each patient’s input data (as shown in Table 9) into the ontology to initiate the inferencing task.
After the inference task is complete, the obtained system inference data for each case are: “Type of Diabetes” “Risk of Diabetes in 10 Years” “BMI” “Min. Ideal Weight” “Max. Ideal Weight”, and “Personalized Supportive Treatment Suggestions”, for each. The results obtained for each patient case were the same as expected results, as formulated in predefined rules in the systems ontology.
Manual verification by the collaborating physician
Medical supportive treatment suggestions inferred by the system for each patient were then discussed with the collaborating physician for verification. The collaborated physician manually evaluated each of supportive treatment suggestions deduced and went through standard diagnosis and treatment processes on the same data set collected and used professional reasoning to verify each patient’s conditions and needed medical/physical activities.
In the verification studies conducted with the collaborating physician, when data of the 30 patient cases were considered, no errors were observed in the determination of the formularized and score-based results (i.e. “Type of Diabetes”, “Risk of Diabetes in 10 Years”, “BMI”, “Min. Ideal Weight”, “Max. Ideal Weight”) by the IE. However, in our first-round test studies, in the personalized supportive treatment suggestions for 30 patients, the system produced a total of 8 missing suggestions and 6 incorrectly classified suggestions. Therefore, the consistency of the developed system was performed as 965%. The missing suggestions have been added to the appropriate SWRL rules on the DMDOnt. Additionally, 6 misclassified suggestions were inserted into the correct SWRL rules.
After all corrections were conducted, 30 already enrolled patients on the system database were reprocessed by the IE in the second-round tests. It was observed that the suggestions produced by IE for each of the 30 patients were produced as correct and complete suggestions. The accuracy of the system increases as the rules are corrected and validated, so the system accuracy was found as 100.0% after the second round of tests and all the corrections made.
Overall results after the second-round tests show that the personalized and supportive treatment suggestions deduced by the system on the 30-patient case are in line with the manual evaluation of the collaborating physician. Moreover, the results obtained also show that, the DMDSOnt can deliver accurate reasoning while preserving knowledge base shareability and extensibility. As a result, as the number of patient cases increases, the DMDSOnt will be enhanced and advanced by adding the missing supportive medical treatment suggestions to the system ontology over time by the ontology engineers.
System contributions summary
The contributions of this system developed for the management and delivery of health services are as follows:
Most people live with DM risk without realizing it, and this risk manifests itself in later ages. With this CDSS developed, it is possible to predict and prevent DM risk in the early years by monitoring the health signs and conditions of individuals. With this CDSS, it is possible to identify T1DM, T2DM, Prediabetes, Asymptomatic and Gestational Diabetes patients in adults. The system does not currently examine the pediatric group. Since BMI should be evaluated according to percentiles for pediatric group, the system is designed for use by individuals over the age of 18. Integration of percentile assessment into the system and adaptation of childhood assessment to the CDSS developed are planned as future studies. With this CDSS, it is possible to make required changes in their lifestyle of individuals by taking certain precautions by recognizing and treating the DM risk in the early stage. With this CDSS, the incidence of DM risk in society can be followed through continuous evaluations and public awareness of this risk can be increased. It can be used to develop and apply Clinical Practice Guidelines of DM [22], which is useful to formalized statements, and include recommendations intended to create best practices and optimize public healthcare. With this CDSS, it is possible to facilitate preventive health practices especially in primary health care services. With this CDSS, medical students and lecturers studying in this field can be supported. The processing of the information collected in the clinical environment and its reinforcement with theoretical knowledge can be supported. Therefore, it can be used for educational purposes by those studying in DM diagnosis and DM health care management (e.g., those who want to become experts in DM management and decision making, such as medical students, nurses, health practitioners, general practitioners, health educators, and other primary care clinicians). With this CDSS, feedback can be obtained on the follow-up of the treatment processes of the patients who are currently receiving DM treatment.
DM is a chronic disease that can cause various severe damage to our body by affecting various crucial organs in our body such as the heart, eyes, kidneys, skin and feet. DM requires ongoing medical check-ups and self-care and education to prevent its severe complications and reduce the risk of its long-term complications. CDSS is a sophisticated health information technology component, can be used to facilitate this effort and assess the risk of long-term complications. In this study, an ontology based CDSS is engineered as a tool that provides to deduce a DM risk in an early stage and return a set of personalized supportive treatment suggestions for a patient. With this system, it is aimed to facilitate preventive health practices and early diagnosis, especially in primary health care services.
The system consists of five parts: (1) Diabetes Mellitus Diagnosis and Support Ontology (DMDSOnt), (2) semantic medical rules (SWRL rules), (3) inference engine module, (4) system database, and (5) portal user interface.
Ontology knowledge bases provide a major step towards the development of smarter clinical systems for disease assessment. In this study, the DMDSOnt developed contains various information (e.g., symptoms and signs, physical activities, clinical history of patients, frequently used clinical laboratory tests and other risk factors) and relationships used in the diagnosis and treatment of DM risk. In addition, the system has its own semantic medical rules on the DMDSOnt which are executed by an inference engine of the system to deduce a DM risk score and a set of proper supportive treatment suggestions for a patient.
The rules are built on the SWRL to enable high-level context reasoning and information evaluation. The rules are created from valid relationships between ontology classes (concepts) to diagnose DM risk and estimate its type. Thanks to the reasoning ability of the system’s inference engine, it helps physicians/health practitioners diagnose DM risk at an early stage and provides feedback to understand progress in DM treatment, thus ensuring proper management of the treatment process and accelerating recovery. Currently, the semantic medical rules of the system can only predict Type 1 and Type 2 DM in adults, while current guidelines do not yet make recommendations for DM risk estimation and support for pediatric patients. This part is planned as future work.
Funding
The authors report no funding.
Ethics statement
Due to the nature of this study, no formal consent was required.
Supplementary data
The supplementary files are available to download from https://dx-doi-org.web.bisu.edu.cn/10.3233/THC-230237.
Footnotes
Acknowledgments
The project was completed with the collaboration of the Department of Pediatric Endocrinology, Faculty of Medicine, Near East University, and the Department of Computer Engineering, Engineering Faculty, Eastern Mediterranean University in North Cyprus, Turkey. The project was completed with the technical contribution of a research team comprised of four computer engineers and one DM physician. An updated version of the OWL form of DMDSOnt is provided on the Bio portal repository: https:// bioportal.bioontology.org/ontologies/DMDSONT.
Conflict of interest
The authors declare that they have no conflict of interest.