
Abstract
BACKGROUND:
The morbidity and mortality of heart disease are increasing in middle-aged and elderly people in China. It is necessary to explore relationships and interactive associations between heart disease and its risk factors in order to prevent heart disease.
OBJECTIVE:
To establish a Bayesian network model of heart disease and its influencing factors in middle-aged and elderly people in China, and explore the applicability of the elite-based structure learner using genetic algorithm based on ensemble learning (EN-ESL-GA) algorithm in etiology analysis and disease prediction.
METHODS:
Based on the 2013 national tracking survey data from China Health and Retirement Longitudinal Study (CHARLS) database, EN-ESL-GA algorithm was used to learn the Bayesian network structure. Then we input the data and the learned network structure into the Netica software for parameter learning and inference analysis.
RESULTS:
The Bayesian network model based on the EN-ESL-GAalgorithm can effectively excavate the complex network relationships and interactive associations between heart disease and its risk factors in middle-aged and elderly people in China.
CONCLUSIONS:
The Bayesian network model based on the EN-ESL-GA algorithm has good applicability and application prospect in the prediction of diseases prevalence risk.
Introduction
Cardiovascular diseases are the leading cause of morbidity and mortality worldwide [1]. Studies [2] have indicated that aging is the major risk factor for cardiovascular diseases. Due to the large population and the very fast aging rate, China is facing the great challenge of the rapid increase in the number of cardiovascular diseases and deaths. As the main type of cardiovascular diseases, heart disease will seriously affect the labor force of patients. Therefore, it is absolutely necessary to explore the influencing factors of heart disease and the interactions between those influencing factors in middle-aged and elderly people in China so as to provide countermeasures for the prevention and management of heart disease in middle-aged and elderly people in China and better realize “healthy aging”.
The relevant studies [3, 4] showed that risk factors associated with heart disease included hypertension, diabetes, dyslipidemia, obesity, lack of physical activity, smoking and poor diet habits. However, these risk factors often are not independent, but influence each other and work together in the occurrence and development of heart disease. In this case, traditional statistical methods such as logistic regression with the independence between variables as the premise are difficult to identify the interactions of independent variables on prevalence of heart disease. The Bayesian network is a very effective tool for dealing with uncertain knowledge expression and reasoning. By organically combining the knowledge of probability theory and graph theory, it can not only identify the complex interactions between variables, but also reveal the strengths of the dependency relationships between variables from a quantitative perspective [5]. It has been widely applied in the prediction and diagnosis of diseases [6, 7, 8, 9]. Constructing the Bayesian network model mainly includes three parts: structure learning, parameter learning and inference. Among them, it is the first and key task to obtain the Bayesian network structure which can accurately express the correlation between variables. In this study, an improved hybrid structure learning strategy for Bayesian networks based on ensemble learning named EN-ESL-GA was used to learn the Bayesian network structure. The EN-ESL-GA algorithm is a kind of Bagging ensemble method based on an elite-based structure learner using genetic algorithm (ESL-GA) [10], and the Bayesian network structure established by it is more accurate and reliable. Parameter learning and reasoning analysis were completed in Netica software.
Materials and methods
Data materials
Data sources
CHARLS which contains the basic data of families and individuals of middle-aged and elderly people aged 45 and over in China provides good data support for analyzing the aging problem of China’s population [11]. In order to understand the complex relationships between heart disease and its risk factors in middle-aged and elderly people in China so as to carry out appropriate intervention on the modifiable risk factors of heart disease and better realize “healthy aging”, this study selected 12 relevant variables to form the research data set variables based on the 2013 national tracking survey data in CHARLS database.
Data processing and variable definition
After processing the outliers and missing values of the research data set and discretizing the continuous variables, 11091 cases of qualified data were obtained as the data set for establishing Bayesian network model.
The data set involved 12 variables including gender, age, registered residence, education level, smoking, drinking, BMI, depression, hypertension, diabetes, dyslipidemia and heart disease (Heart disease here is a general term for any of various structural or functional abnormalities or diseases of the human heart including myocardial infarction, coronary heart disease, angina pectoris, congestive heart failure or other heart problems.). The CESD-10 scale was used in the CHARLS survey to investigate the risk of depression in middle-aged and elderly people, and the depression score ranged from 0 to 30 points. This study defined that if the depression score was greater than or equal to 10, it was depression, otherwise it was no depression. The classification and assignment of all variables are shown in Table 1.
Description of node variables of Bayesian network
Description of node variables of Bayesian network
Firstly, by virtue of the Bayesian network toolbox BNT in MATLAB, this study used the elite-based structure learner using genetic algorithm based on ensemble learning (EN-ESL-GA) algorithm to learn the structure of the Bayesian network for data related to heart disease and its possible risk factors in middle-aged and elderly people in China. Then we input the data and the learned network structure into the Netica software for parameter learning and inference analysis.
The EN-ESL-GA algorithm is a hybrid Bayesian network structure learning method, featuring strong optimization search ability and more accurate and reliable optimization results. The EN-ESL-GA algorithm and its performance analysis have been described in detail in the manuscript [12]. The EN-ESL-GA algorithm is a kind of bagging ensemble method based on the ESL-GA algorithm, in which the number of sample sets is set to 20 and the weighted average method is selected as the fusion strategy. The algorithm equates the process of Bayesian network structure learning to learning the adjacency matrix of the directed acyclic graph. Firstly, 20 adjacency matrices learned by the ESL-GA algorithm are weighted and averaged and the weight is the normalized BDeu score [13] of the Bayesian network represented by each adjacency matrix. Secondly, a fusion matrix is obtained by filtering out the edges with weak dependence according to a given threshold. Finally, the fusion matrix is revised by the operations of removing loops and the maximum number control of parent nodes to obtain the final Bayesian network structure. Figure 1 shows the flow chart of the EN-ESL-GA algorithm.
The flow chart of the EN-ESL-GA algorithm.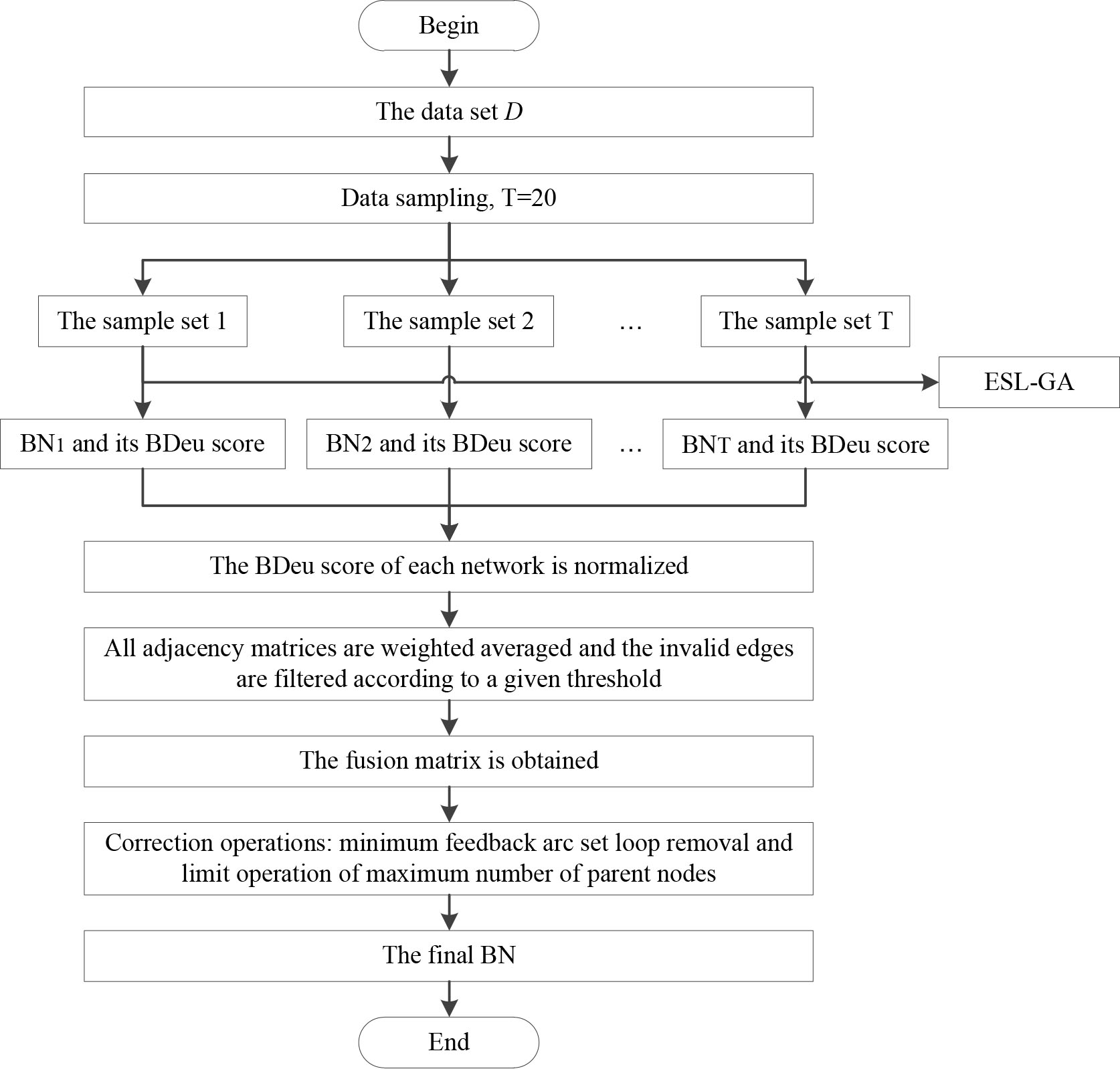
The Bayesian network structure.
Structure learning
When the EN-ESL-GA algorithm was used to learn the Bayesian network structure of the data related to heart disease and its risk factors of middle-aged and elderly people in China, the maximum number of parent nodes of the network was not known in advance. Here, the maximum node degree 4 of the Bayesian network structure obtained by the Maximum Weight Spanning Tree (MWST) algorithm [14] was set to the maximum number of parent nodes during the network construction and other parameters were adjusted appropriately. Specifically, the maximum CPU time was set as 600 s, the population size N was set as 200, the maximum iteration number M was set as 50 and the weight threshold of the integration result was set as 0.1. In addition, considering the actual causality, the learning results after each application of single ESL-GA algorithm were modified and the directed edges between gender, age and registered residence node variables and other node variables could only be pointed to other node variables by gender, age and registered residence node variables. Only education pointed to other node variables except gender, age and registered residence. If there were directed edges between smoking (drinking) and variables including gender, age, registered residence and education, the directions of directed edges could only be directed to smoking (drinking) by these variables, while the directions of the relationships between smoking (drinking) and other variables except drinking (smoking) were opposite. Only BMI pointed to other node variables except gender, age, registered residence, education, smoking and drinking.
As shown in Fig. 2, a Bayesian network structure with 12 nodes and 27 directed edges was finally constructed. It can be seen that gender, BMI, diabetes and dyslipidemia were directly related to heart disease while other factors were indirectly related to heart disease through these direct factors. Smoking and drinking indirectly affected the occurrence of heart disease through the intermediary node BMI. Registered residence was indirectly linked to heart disease through BMI and diabetes. Hypertension and depression indirectly affected heart disease by directly affecting dyslipidemia. At the same time, it is observed that gender, age and registered residence were directly correlated with education, and education further affected smoking, drinking and depression, thus indirectly correlated with heart disease.
Parameter learning and reasoning
The above Bayesian network structure and data set were input into Netica software for parameter learning. Table 2 lists the conditional probability distribution table of heart disease after the rank of heart disease prevalence from large to small. In order to more intuitively describe the difference in the incidence of heart disease in different gender, the line chart of conditional probability distribution of heart disease as shown in Fig. 3 was drawn according to Table 2.
The conditional probability distribution table of heart diseases
The conditional probability distribution table of heart diseases
Line charts of conditional probability distribution of heart disease by gender (Note: The legend shows the status of the parent nodes of heart disease including diabetes, dyslipidemia and gender in order. For example, the broken line of ‘yes-yes-male’ reflects the change in the prevalence of heart disease in men with diabetes and dyslipidemia with the change of BMI.)
As can be seen from Fig. 3, the prevalence of heart disease among the middle-aged and elderly in China generally showed the following characteristics: the more obese BMI tended to be, the more likely it was to suffer from heart disease; People with diabetes and dyslipidemia were more likely to develop heart disease. However, the rates of heart disease when BMI was underweight in ‘y-y-m’ and ‘n-y-m’ were as high as 66.7% and 43.8% respectively, both exceeding the rates of heart disease when BMI was obese (53.6% and 32.1%). This makes us naturally want to carry out the diagnostic reasoning to see what factors have a clear gender difference dominating this situation.
Set Diabetes
The Bayesian network model constructed in this study was used to reveal the complex network relationships between heart disease and its influencing factors. The results of the study showed that the prevalence of heart disease in middle-aged and elderly people in China was 13.9%. Gender, BMI, diabetes and dyslipidemia were directly related to heart disease, while other factors were indirectly related to heart disease through these direct influencing factors. The results of this study indicated that there was a gender difference in the prevalence of heart disease, women (16.4%) were more likely to suffer from heart disease than men (11.3%). The more obese a person tended to be, the more likely it was to suffer from heart disease, and the rate of heart disease among obese people was 24.5%. Li et al. [4] also pointed out that high BMI was a key risk factor for cardiovascular diseases when studying the potential impacts of time trends of lifestyle factors on the burden of cardiovascular diseases in China. Patients with diabetes had a higher risk of heart disease (28.2%). The relevant study [15] showed that the risk of the coronary heart disease and its death would increase by 1.38 and 1.86 times respectively with each 10-year increase in the course of diabetes. The prevalence rate of heart disease in patients with dyslipidemia was 32.1%, indicating that patients with dyslipidemia were more vulnerable to heart disease, which was consistent with the research results in literature [16, 17].
There was also the certain interaction between gender and BMI which affected heart disease. Both the proportions of overweight and obesity in females (33.3% and 7.9%) were higher than that in males (26.9% and 3.9%), which might be one of the reasons for the higher prevalence of heart disease in females. The smoking rate of males was extremely high (79.2%). In the previous inference analysis of the Bayesian network model, we had found that smoking was very likely to lead to a higher risk of heart disease in men with low weight. This was consistent with the results of a previous study [18] which pointed out that smoking was a key risk factor of the coronary heart disease, and the weight change caused by smoking had no obvious mediating effect on the risk of the coronary heart disease. In addition, BMI, diabetes and dyslipidemia interacted with each other on heart disease. BMI directly affected diabetes and dyslipidemia which in turn affected diabetes. In the case of obese patients with diabetes and dyslipidemia, the rates of heart disease in men and women were 53.6% and 47.4% respectively. This was consistent with the conclusions of previous studies. For example, the meta-analysis [19] found that obese adults at the onset of diabetes had a higher risk of morbidity and mortality of the cardiovascular disease. Rao et al. [20] found that there was a dose-response non-linear relationship between BMI and hyperlipidemia when studying the cross-sectional relationship between BMI and hyperlipidemia in adults in the northeast China, and the odds ratio tended to increase significantly as per 1 kg/m2 increased in BMI. A cohort study [21] found that dyslipidemia was the most important factor affecting type 2 diabetes.
This study also found that registered residence was indirectly related to heart disease through BMI and diabetes. It can be inferred from the network reasoning that people with non-agricultural registered residence tended to be more obese and had a greater risk of diabetes than those with agricultural registered residence, which thus increased the probability of heart disease by 1.0%. Literature [22] that studied the difference in the prevalence of diabetes between rural and urban areas in Tanzania also showed that the prevalence of diabetes in urban areas was higher than that in rural areas in Tanzania and this trend could be explained by the difference in obesity and overweight rates. Depression indirectly affected the occurrence of heart disease by directly affecting the occurrence of dyslipidemia. Literature [23] also pointed out that patients with dyslipidemia with depression had an increased risk of the cardiovascular disease. The two direct factors that affected hypertension included age and BMI, and the older the age was and the greater the BMI was, the more likely they were to suffer from hypertension. It can be inferred by the inference learning that the probability of suffering from hypertension in the elderly with obesity was 67.3%, which had exceeded twice of the general prevalence of hypertension (30.1%). In combination with the Bayesian network structure, inference and the analysis mentioned above, it could be found that BMI was a common direct influencing factor of hypertension, diabetes, dyslipidemia and heart disease, and obesity, hypertension, diabetes and dyslipidemia all increased the risk of heart disease and there were significant interactions between them. Therefore, the comorbidity of heart disease and obesity, hypertension, diabetes and dyslipidemia deserved high attention [24]. In addition, it was observed that gender, age and registered residence were directly correlated with education, and education further affected smoking, drinking and depression, thus indirectly correlated with heart disease.
Conclusions
It is thus clear that the Bayesian network model constructed in this paper which can not only discover the key influencing factors of heart disease and the interaction mechanisms among these key influencing factors but also deeply dig out certain intermediate links in the occurrence and development of heart disease has good applicability in the risk prediction of diseases. However, due to the complexity of practical problems, it is necessary to adjust the directions of some edges of the network structure according to some professional knowledge when using the EN-ESL-GA algorithm to learn the structure of Bayesian networks, which further increases the number and difficulty of network learning. This is the deficiency of the EN-ESL-GA algorithm in practical application, which needs to be further discussed.
Data availability statement
The datasets used in the experiments are publicly available at
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Ethics approval
As the data sets included in the study were downloaded from public databases, the study did not need the approval of an ethics committee.
Footnotes
Acknowledgments
The authors thank all participants of this study and the publicly available data set from http://charls.pku. edu.cn/.
Conflict of interest
All the authors declared no conflict of interest.