
Abstract
BACKGROUND:
Cardiac diseases are highly detrimental illnesses, responsible for approximately 32% of global mortality [1]. Early diagnosis and prompt treatment can reduce deaths caused by cardiac diseases. In paediatric patients, it is challenging for paediatricians to identify functional murmurs and pathological murmurs from heart sounds.
OBJECTIVE:
The study intends to develop a novel blended ensemble model using hybrid deep learning models and softmax regression to classify adult, and paediatric heart sounds into five distinct classes, distinguishing itself as a groundbreaking work in this domain. Furthermore, the research aims to create a comprehensive 5-class paediatric phonocardiogram (PCG) dataset. The dataset includes two critical pathological classes, namely atrial septal defects and ventricular septal defects, along with functional murmurs, pathological and normal heart sounds.
METHODS:
The work proposes a blended ensemble model (HbNet-Heartbeat Network) comprising two hybrid models, CNN-BiLSTM and CNN-LSTM, as base models and Softmax regression as meta-learner. HbNet leverages the strengths of base models and improves the overall PCG classification accuracy. Mel Frequency Cepstral Coefficients (MFCC) capture the crucial audio signal characteristics relevant to the classification. The amalgamation of these two deep learning structures enhances the precision and reliability of PCG classification, leading to improved diagnostic results.
RESULTS:
The HbNet model exhibited excellent results with an average accuracy of 99.72% and sensitivity of 99.3% on an adult dataset, surpassing all the existing state-of-the-art works. The researchers have validated the reliability of the HbNet model by testing it on a real-time paediatric dataset. The paediatric model’s accuracy is 86.5%. HbNet detected functional murmur with 100% precision.
CONCLUSION:
The results indicate that the HbNet model exhibits a high level of efficacy in the early detection of cardiac disorders. Results also imply that HbNet has the potential to serve as a valuable tool for the development of decision-support systems that aid medical practitioners in confirming their diagnoses. This method makes it easier for medical professionals to diagnose and initiate prompt treatment while performing preliminary auscultation and reduces unnecessary echocardiograms.
Keywords
Introduction
Valvular heart disease (VHD) is a predominant cause of death and truncated life. Due to the elevated prevalence and mortality rate of VHD, it remains a trending research subject. The number of cardiac patients is increasing yearly, covering almost 41 million globally [2]. One of the ways to limit the increasing number of cardiac cases is through the timely detection and treatment of the disease. Heart auscultation is the most straightforward and non-invasive method for initially diagnosing heart disease. However, the doctor’s experience and expertise determine whether the diagnosis is accurate. The hearing capability is not the same among individuals, and we cannot fully rely on cardiac auscultation for the diagnosis. The gold standard used for disease detection is an echocardiogram. Echocardiography is an expensive, lengthy diagnosis procedure, and there is a waiting period to get an appointment, which delays the diagnosis of the disease. Another valuable alternative is phonocardiography, a non-invasive method for obtaining recordings of cardiovascular sounds.
A phonocardiogram (PCG) is a visual depiction of heart sounds captured using an electronic stethoscope. The intensity, rate, and inter-relationship among the heart cycles can depict the heart conditions. So, analysing the heart sounds is the best way to detect whether a person has a healthy heart. PCG signals and the assistance of artificial intelligence (AI) can objectively decode cardiac sounds to complement the traditional diagnosis method using an echocardiogram.
This work uses deep learning algorithms to categorise heart sounds. These algorithms can learn complex patterns and extract crucial information from the data. Ensemble learning enhances a model’s efficacy by minimising the variance and bias of weak base learners and increasing the accuracy of strong base learners [3]. Soft voting, a method used in bagging, can reduce variance, whereas weighted average, a boosting method, can reduce bias. The blended ensemble model [4] improves efficiency by increasing the accuracy of the base learners. This work proposes a blended ensemble model, HbNet, consisting of Convolutional Neural Network – Long Short Term Memory (CNN-LSTM) and CNN-Bidirectional Long Short Term Memory (BiLSTM) as base learners and softmax regression as a meta-learner. The PCG signals are preprocessed and feature-mapped using MFCC before being applied to base learners. The data sets used for the study are the GitHub dataset [5] for 5-class adult PCG classification and a self-collected 5-class paediatric dataset to analyse the effectiveness and adaptability of the model for a different dataset. The GitHub dataset comprises the heart sounds of Aortic stenosis (AS), Mitral Regurgitation (MR), Mitral Stenosis (MS), Mitral Valve Prolapse (MVP), and Normal (N). The paediatric dataset consists of Atrial Septal Defect (ASD), Functional Murmur (F), Normal, Pathological (P), and Ventricular Septal Defect (VSD). This work also studies the performance of other prominent ensemble models, soft voting and weighted average ensemble models. The significance of the study is summarised as follows:
The work is the first study in its field to classify PCG signals into 5 distinct categories using a novel method that incorporates a blended ensemble model with hybrid deep learning models and softmax regression. HbNet is a pioneering model that classifies paediatric heart sounds into more than three classes using a deep learning algorithm. Existing studies categorised PCG data into either two (normal/pathological) or three (ASD, VSD, Normal) categories, whereas the proposed method classifies paediatric PCG into 5 classes (ASD, F, N, P, VSD). Accurate detection of functional murmurs aids in minimising unnecessary echocardiograms, while the precise detection of diseases facilitates the timely initiation of treatment. The proposed model outperformed all seven evaluated metrics compared to the existing state-of-the-art methodologies. This achievement underscores the significance and relevance of the study. The study collected and organised a new paediatric PCG dataset comprising data in five categories. The HbNet model predicted the functional murmur, the most misdiagnosed murmur, with 100% precision and specificity, exemplifying the model’s exceptional performance.
Artificial intelligence (AI) based Cardio Vascular Disease (CVD) detection is carried out using either deep learning or machine learning [6] techniques, as mentioned in the introduction. AI methods involve denoising, segmentation, feature extraction, and classification. The primary denoising techniques are: 1) Adaptive Algorithms to eliminate the lung sounds [7, 8, 9]. 2) Blind Source Separation Techniques [10, 11], which use the resemblance of spectral information to identify the noise. 3) Wavelet Transforms (WT) with various thresholding techniques [12, 13, 14, 15, 16, 17]. 4) The AR-based Kalman method [18], in which AR tries to find the coefficients, and Kalman uses the coefficients for denoising. This method improves the signal-to-noise ratio.
The most common computer-aided segmentation techniques used to recognise the first heart sound (S1) and second heart sound (S2) are 1) Wavelet Transform, which provides excellent results even in a noisy environment. The wavelet-based segmentation techniques are Adaptive Wavelet Decomposition [19], Mel-Scaled Wavelet Transform (MSWT) [20], DWT with the Fano Factor and Normalised Average Shannon Energy [21], a combination of Empirical Wavelet Transform [22, 23] and Shanon Entropy Envelope (SEE) [24, 25, 26], and Continuous Wavelet Transform [27]. 2) Hilbert Transform exhibits good segmentation accuracy for progressive waves. Recent works [28, 29, 30] use the Hilbert Transform to segment heart sounds. 3) The Hidden Markov Model (HMM) based approach [31, 32, 33, 34] explores non-stationary statistical properties for the segmentation. 4) Deep Learning based segmentation methods involve deep Recurrent Neural Networks (RNN) [35], Bidirectional LSTM (BiLSTM) with Attention [36], and deep Convolutional Recurrent Neural Networks (CRNN) [37]. Deep learning methods provide more excellent results than manual segmentation methods for accurate training data.
The feature extraction process involves the efficient representation of the raw data in another form. Localisation of S1, S2, systole, and diastole, spectrograms using various transforms, MFCC [38], and Gammatone Frequency Cepstral Coefficients (GFCC) [31] are the commonly used feature extraction techniques. Classification is the final stage and can be done using machine learning approaches like K-Nearest Neighbour (K-NN) [39], Support Vector Machine (SVM) [22, 40, 41, 42, 43], Random Forest (RF) [44], and Artificial Neural Network (ANN) [45, 46, 47]. In [48], a comprehensive study was conducted which utilised classification methods such as K-Nearest Neighbors (KNN), Support Vector Machines (SVM), Multilayer Perceptron (MLP), and Deep Neural Network (DNN). The results showed that DNN outperformed the other machine learning algorithms significantly. This finding strongly emphasises the advantages of deep learning algorithms over traditional machine learning methods. Classifying data using machine learning algorithms is a meticulous process requiring data segmentation and crafting intricate features manually. Though this process helps improve classification models’ overall performance for small datasets, it is time-consuming and labour-intensive. Deep learning models, in contrast, autonomously extract relevant features from data. The prominent deep learning algorithms used are CNN [49, 50, 51, 52, 53, 54], RNN [51, 55, 56], Gated Recurrent Unit (GRU) [51, 57], a combination of CNN and RNN, generally known as CRNN [58, 59, 60, 61, 62, 63], Transfer Learning [64, 65, 66] and Convolutional Transformers [67]. The hybrid models (CRNN) performed better than stand-alone deep learning models. These models were lightweight and exhibited great results without segmentation. Ensemble learning enhances classification accuracy over the use of a single classifier by combining multiple classifiers [68, 69, 70, 71, 72]. In [26],
Summarised studies on the recent adult and paediatric PCG
Summarised studies on the recent adult and paediatric PCG
majority voting utilising Random Forest (RF) and AdaBoost is employed to categorise the paediatric cardiac sounds into two categories, yielding impressive outcomes. Roy et al. [73] proposed a CNN-RF ensemble model and achieved 99.37% accuracy for adult PCG classification. These works not only validate the effectiveness of the ensemble approach but also highlight the potential of utilising ensemble models to achieve superior performance. So, this study combines the merits of hybrid deep learning models and ensemble models to propose HbNet, a novel blended ensemble model that integrates two hybrid models, CNN-BiLSTM and CNN-LSTM, using a softmax regression as a meta-learner.
Recent works on adult and paediatric PCG are showcased in Table 1. Unlike the previous paediatric papers that classified the PCG into normal and pathological [25, 26, 54, 58, 74, 75, 76], this study classifies it into five different classes such as ASD, Functional murmur, Normal, Pathological and VSD, making the work novel. HbNet facilitates the early identification of VHD from heart sounds.
The work proposes a blended ensemble model, HbNet, incorporating CNN-BiLSTM and CNN-LSTM as base learners and softmax regression as a meta-learner for detecting cardiovascular anomalies. Before finalising the base models, we conducted experiments using various deep learning architectures, including CNN, LSTM, GRU, BiLSTM, and hybrid models like CNN-LSTM, CNN-GRU, and CNN-BiLSTM. Notably, the CNN-BiLSTM and CNN-LSTM configurations demonstrated exceptional performance, which led to their selection as the base models. Since the study uses a not-so-large dataset of one-dimensional heart sounds, it would be ideal to introduce feature mapping along with deep learning feature extraction. The acoustic feature mapping employed is MFCC. The mapped features are given to HbNet for classification. The HbNet model is depicted in Fig. 1. In addition to the blended ensemble model, the possibilities of the soft voting method [77] and the weighted average ensemble model [78] have also been explored. Both of these models are implemented using the same two base models.
HbNet model.
GitHub dataset
The data utilised in this study are acquired from a publicly available database [5]. The PCG signals available in the dataset are collected from various medical websites, such as OpenMichigan, the University of Washington Department of Medicine, and auscultation tutorial CDs available in medical textbooks. The dataset is structured into five categories: N, AS, MR, MS, and MVP. Each category comprises 200 PCG samples, amounting to a cumulative count of 1000 samples. The duration of heart sounds varies from 1.12 s to 2 s. The dataset has been validated by consulting with an expert clinical cardiologist from TMM Hospital.
Paediatric dataset
The Paediatric dataset was collected from Thiruvalla Medical Mission Hospital (TMM) after receiving approval from the local institutional ethics committee. The data was collected between 26 August 2022 to 20 April 2023. A total of 2322 data samples were collected from 391 subjects in the age range of newborns to 13 years old. Heart sound recordings were done from four auscultation points: the aortic, pulmonary, mitral, and tricuspid. The time span of the recordings is between 3 and 30 seconds. Data collection was conducted by an expert cardiologist in a clinical environment using Eko Littmann’s electronic stethoscope. It is an unbalanced dataset comprising 254 ASD, 218 functional, 821 normal, 674 pathological, and 355 VSD PCG recordings.
Preprocessing
The audio files in the GitHub dataset vary in duration, ranging from 1.12 seconds to 30 seconds. To make them identical in duration, the PCG signals have been truncated to 1.12 s, the shortest heart sound duration available in the dataset. Then, the files are resampled to 8000 Hz and normalised between
Feature mapping
The features are represented using MFCC [79]. It is a very efficient representation technique for speech and low-frequency signals. Since heart sound occupies a low-frequency range, MFCC is one of the best methods for representation [80]. 13 MFCC coefficients are considered in this work. The steps to obtain the MFCC features are shown in Fig. 2.
Steps involved in MFCC feature mapping.
First, the time-domain PCG signal is modified into the frequency-domain signal by the Eq. (1):
where
A statistical inference test called Analysis of Variance (One-Way ANOVA) was performed to demonstrate the relevance of the obtained MFCC features. The Python statsmodel package was used to run the test and received the F-statistic value of 50 with the associated
HbNet model
HbNet, a blended ensemble model, can provide consistent predictions with greater accuracy than the individual models. In blended architecture, one base model will be proficient at identifying a set of features, and the other model will recognise a different set of features. Combining them will make the ensemble model benefit from the merits of the base models. The two base models employed in this work are CNN-BILSTM and CNN-LSTM. CNN can model time and frequency-domain components in a signal, whereas BiLSTM and LSTM uncover the long and short-term temporal dependencies of features among and within PCG signals. LSTM considers only past information, while BiLSTM preserves past and future temporal information. Incorporating LSTM and BiLSTM in a single model can facilitate a more accurate classification of PCG. In this study, the initial predictions are generated by applying MFCC outputs to the base models. The meta-learner is Softmax Regression, as HbNet is designed for multiclass classification problems. The architecture is intended for accurately classifying short PCG recordings that are not segmented.
Base model architecture.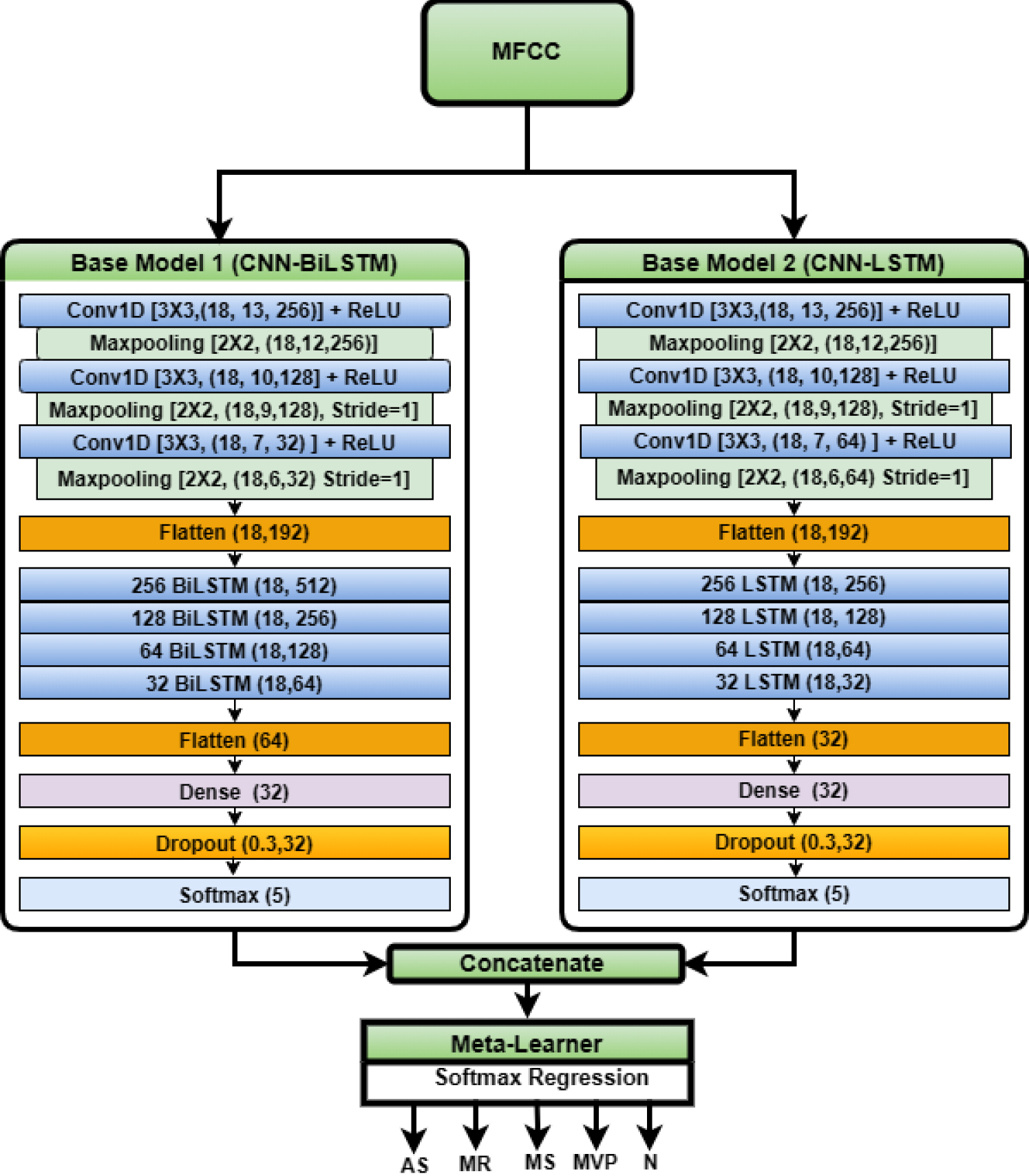
The base models that constitute the HbNet are CNN-BiLSTM and CNN-LSTM. Rigorous hyperparameter tuning [81] has been performed to determine the optimum base model architecture, which can enhance the total performance of HbNet. The CNN-LSTM comprises three convolutional (Conv) layers subsequently succeeded by max-pooling and 4 LSTM layers, as shown in Fig. 3. Each Conv layer output (C) is represented by Eq. (4).
Where
For both base models, the kernel size employed for CNN layers is 3
HbNet comprises two hybrid deep learning models that excel in classifying PCG signals, demonstrating remarkable performance. Therefore, as the meta-learner, we require a simple and efficient algorithm that does not involve complex training procedures. Softmax regression is a simple model that can handle multiple classes with minimal training and produce maximum output. Another advantage of softmax regression is its reduced susceptibility to overfitting, especially when working with a small and low-dimensional dataset. This work involves a not-so-large one-dimensional dataset with two effective base models. This characteristic makes Softmax Regression an excellent choice for this work. The softmax regression meta-learner can be modelled by Eq. (7).
Where
The penalty applied in this work to obtain an accurate model is L2 regularisation. L2 penalty also helps in reducing the model complexity. The L-BFGS solver has been selected as it requires less memory space and converges fast for small and medium datasets. The other solvers that have experimented with developing an accurate HbNet model are newton-cg and sag.
The datasets are divided into train, validation, and testing. The testing dataset takes up 10% of the total, while validation also takes up 10%, and the remaining 80% is used for training. The number of hidden layers and units in each layer were determined by a trial and error approach. The base model’s hyperparameters, including the activation function, optimiser, batch size, and learning rate were selected through careful tuning using a Grid search algorithm. The hyperparameters considered and the optimal parameters selected after the Grid search are consolidated in Table 2.
Optimised hyperparameters
Optimised hyperparameters
The model was designed to run for 100 epochs, but the results demonstrated no further improvement in model accuracy after 40 epochs, so the number of epochs engaged was reduced to 40. The output of the base models is concatenated and given to Softmax Regression. Then, the HbNet model is trained for a hold-out set and evaluated using test data to analyse its effectiveness. The entire model is validated using 10-fold cross-validation. The hardware for developing the HbNet model is an Intel Core i7 processor with Nvidia GeForce GTX 1060 Graphics processing and 6 GB RAM. The model architecture was designed using Python 3.7.10 and built using TensorFlow and Keras.
The effectiveness of the HbNet model is demonstrated through evaluation metrics such as average class accuracy, precision, recall, specificity, F1 score, Mattews Correlation Coefficient (MCC), AUC-ROC score and AUPRC score. The ROC curve was plotted to comprehend how well HbNet performed.
Results and discussion
GitHub dataset
The proficiency of the HbNet for the GitHub dataset has been compared with existing methodologies, the soft voting ensemble model and a weighted average ensemble model. HbNet outperformed all the existing models with an average class accuracy of 99.72%, precision, recall, and F1 scores of 99.3%, specificity of 99.8%, MCC of 99%, an AUC-ROC score of 99.9%, and an AUPRC score of 99.65%. The performance metric values of HbNet are shown in Table 3. Based on the data presented in Table 3, it is clear that HbNet consistently demonstrated exceptional performance across all 10 folds. The findings demonstrate the efficiency of the HbNet model.
Performance evaluation of HbNet for GitHub dataset
Performance evaluation of HbNet for GitHub dataset
The accuracy of different models experimented with in this work using GitHub
Table 4 contains the accuracy of the base models, the soft voting, the weighted average ensemble, and HbNet. Since the CNN-LSTM and CNN-BiLSTM showed the top accuracies, these models were chosen as base models for HbNet. The CNN-GRU model has the same architecture as CNN-BiLSTM with 3 CNN layers (256,128,32) and 4 GRU (256,128,64,32) layers. Table 4 proves that the soft-voting ensemble could not enhance the overall performance compared to the base model CNN-BiLSTM.
The soft voting ensemble performs predictions on base models, sums all the output class probabilities, and chooses the category having the highest summed probability as the outcome. Each base model is an equal part of the final prediction. The model can be depicted by an equation.
Where
Examining the outcomes of the weighted average ensemble model from Table 4, it is apparent that the model’s efficiency has been enhanced compared to base learners. The weighted average ensemble model combines the soft voting ensemble with a weighted score, in which the base model’s performance weights each member’s contribution to the final results. Instead of summing with equal weights, different weights of importance were applied to each base model in the ensemble. Then, the output probabilities are multiplied with weights and summed. The model can be described by the equation.
The weights (w) are selected by the grid search method. For each base model, the weights are varied from 0 to 0.5. All combinations of weights are considered so that total weights are added up to 1. The final model will select the weight combination that provides the highest accuracy. The weighted ensemble model gained an average class accuracy of 99.68%, surpassing the accuracy of the base models and outperforming other established methodologies.
Class-wise analysis of evaluation metrics on the Github dataset
AUC-ROC Curve for Github dataset. 4(a) AUC-ROC curve for highest and 4(b) for lowest yielded iterations. 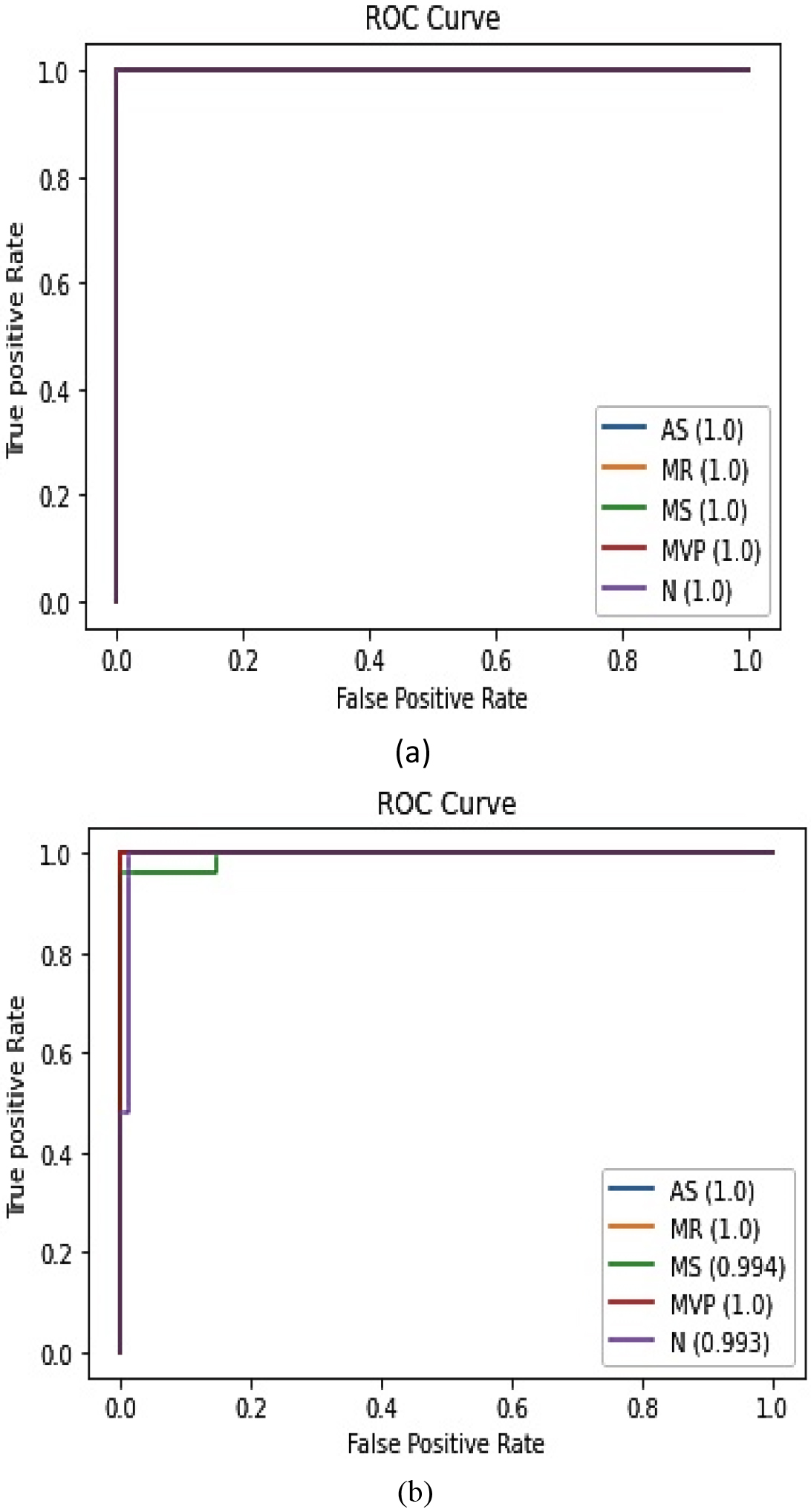
Table 5 demonstrates the class-wise performance of the model. HbNet could recognise each class with great accuracy and precision. The improved accuracy can be attributed to the fact that the blended ensemble model undergoes two rounds of training.
The AUC-ROC curve for the iterations that yielded the highest and lowest accuracy is demonstrated in Fig. 4a and b. The very high AUC-ROC score, almost equal to one, confirms that the model can effectively discriminate the different classes.
The paper presents a detailed comparison of the HbNet with all the state-of-the-art studies that used the same GitHub dataset employed in this study, as demonstrated in Table 6. Compared with the existing work, HbNet achieved better results for all the metrics evaluated. None of the existing papers has analysed the precision-recall score. This work has achieved a very high precision-recall score of 99.65%. It is evident from Table 6 that HbNet outperformed all the existing works in all aspects.
Comparison of HbNet with existing works on GitHub dataset
Comparison of HbNet with existing works on GitHub dataset
The HbNet model performed well on the paediatric dataset as well. In order to optimise the results, the number of epochs has been increased to 50 from 40 while training the paediatric dataset. The HbNet achieved a maximum accuracy of 87.6% with a mean accuracy of 86.5% across the 10 folds. The detailed performance evaluation of the HbNet on the paediatric PCG is shown in Table 7. The class-wise analysis of evaluation metrics is given in Table 8. Table 8 shows that the most misdiagnosed functional murmur is identified with 100% precision and specificity.
Evaluation results of the HbNet model on the paediatric dataset
Evaluation results of the HbNet model on the paediatric dataset
Class-wise evaluation of the paediatric dataset
AUC-ROC Curve for the paediatric dataset. 5(a) AUC-ROC curve for highest and 5(b) for lowest performing iteration.
Table 9 displays the performance of ensemble models on the paediatric dataset. The accuracy of all three ensemble models was higher than that of the base models, out of which the HbNet model excelled with an average accuracy of 86.5%.
Accuracy of different ensemble models for the paediatric dataset
The AUC-ROC curves for the iterations with maximum and minimal accuracy are presented in Fig. 5a and b.
From the result analysis of the HbNet performance on Github and paediatric datasets, it is evident that there is a significant performance difference. The difference is that both datasets handle a distinct set of diseases, and the real-time paediatric dataset is much noisier than the GitHub dataset due to the crying and movements of paediatric subjects. Also, the heart rate is a varying parameter for paediatric subjects.
Comparing our study directly with other paediatric studies is challenging for significant reasons. Firstly, most earlier studies have focused on binary classification scenarios and relied on their self-gathered datasets, which are not publicly available. In contrast, this study is designed to classify PCG into five distinct categories. The comparison is given in Table 10.
Comparison of HbNet with existing works on paediatric pcg classification
Comparison of HbNet with existing works on paediatric pcg classification
Although Aziz et al. [22] achieved a remarkable accuracy rate of 95% for 3 class classifications, it’s important to note that the study considered a quite small sample size of only 56 participants. This limited sample size may raise questions about the broader reliability and generalizability of the results. Kai et al. [82] also performed 3 class classifications but could only achieve 85% accuracy and 76% sensitivity. As the number of classes increases, the PCG classification gets tricky as functional murmurs and many other pathologies such as ASD, VSD, and Pulmonary Stenosis (PS) have systolic murmurs, and the chances of misdiagnose are high. Despite these limitations, the proposed model achieved 86.5% accuracy, 85% sensitivity and 87.6% precision, much higher than the cardiologist’s accuracy (less than 80%).
The limitation of HbNet is that it is a model with large computational complexity and demands an extensive training period than CardioXNet [59]. HbNet requires 102 seconds to train the model and comprises 3M parameters. However, it’s essential to note that this limitation is somewhat mitigated by the substantial performance enhancements achieved compared to existing methods. Another drawback is that it fails to recognise the noises that fall in the same frequency range as heart murmurs. AI models for medical applications prioritise the model’s proficiency in accurately distinguishing the various diseases over the complexity of the model, as misdiagnosis can cause life-threatening situations and even fatalities [83]. In that perspective, HbNet is superior to all the existing works that employed the GitHub dataset, as it gained high accuracy and a remarkably low miss classification rate.
Conclusion and future scope
This study introduces a novel blended ensemble model, HbNet, for categorising heart sounds into normal and pathological categories. The innovative aspect of HbNet lies in its application of a unique blended ensemble model featuring the integration of CNN-BiLSTM and CNN-LSTM for the classification of heart signals. This research also explores the performance of soft voting and weighted average ensembles using the same base models. Upon analysing results and comparison with existing methods, soft voting and weighted average model, it is evident that HbNet excels in classifying PCG signals with remarkable accuracy (99.72%) and precision (99.3%). The weighted ensemble model also outperformed the existing methodologies. The HbNet has been evaluated using a real-time paediatric dataset, and the HbNet model delivered adequate results even without denoising and segmentation. Functional murmur, the category which poses the most diagnostic challenges among physicians and paediatricians, was identified with cent-percent precision. The results indicate that the model holds up well across various datasets.
In future, it is planned to incorporate other clinical features, such as auscultating points where the murmur is predominant and the subject’s heart rate, along with MFCC features, to improve accuracy. To address the challenge of reducing model complexity and the number of parameters, incorporating an attention mechanism is currently under investigation. It is also envisioned to develop a mobile application that can be used by the cardiologist as a diagnostic aid during auscultation.
Funding
The Centre for Engineering Research and Development (CERD), A.P.J Abdul Kalam Technological University, Kerala, India, funded this study (Fellowship Grant Number: 547/2019/KTU).
Author contributions
Ann Nita Netto: Conceived and designed the study and methodology, implemented the software, analysed the results and prepared the draft manuscript.
Lizy Abraham: Supervised the study and critically reviewed the manuscript.
Saji Philip: Data collection, interpretation and guidance in the research area as a medical expert.
Ethical approval
The ethical principles of this research were upheld by adhering to the Declaration of Helsinki. Ethical committee approval was obtained from the local ethical committee ECR/975/Inst/KL/2017 with study reference number 05/08/2022.
Informed consent
Informed parental consent was obtained from all participants included in the study.
Footnotes
Acknowledgments
The first author acknowledges CERD, A.P.J Abdul Kalam Technological University, Kerala, India, for supporting the work.
Conflict of interest
The authors report no conflict of interest.