
Abstract
BACKGROUND:
The local field potential (LFP) signals are a vital signal for studying the mechanisms of deep brain stimulation (DBS) and constructing adaptive DBS containing information related to the motor symptoms of Parkinson’s disease (PD).
OBJECTIVE:
A Parkinson’s disease state identification algorithm based on the feature extraction strategy of transfer learning was proposed.
METHODS:
The algorithm uses continuous wavelet transform (CWT) to convert one-dimensional LFP signals into two-dimensional gray-scalogram images and color images respectively, and designs a Bayesian optimized random forest (RF) classifier to replace the three fully connected layers for the classification task in the VGG16 model, to realize automatic identification of the pathological state of PD patients.
RESULTS:
It was found that consistently superior performance of gray-scalogram images over color images. The proposed algorithm achieved an accuracy of 97.76%, precision of 99.01%, recall of 96.47%, and F1-score of 97.73%, outperforming feature extractors such as VGG19, InceptionV3, ResNet50, and the lightweight network MobileNet.
CONCLUSIONS:
This algorithm has high accuracy and can distinguish the disease states of PD patients without manual feature extraction, effectively assisting the working of doctors.
Keywords
Introduction
Within the past two decades, deep brain stimulation (DBS) has been widely recognized as an effective therapy for treating Parkinson’s disease (PD) [1, 2, 3]. Bilateral subthalamic nucleus deep brain stimulation (STN-DBS) is commonly employed for PD treatment [4, 5]. While STN-DBS serves as an effective therapeutic option for advanced PD [6], continuous DBS may still be associated with some side effects, such as language difficulties, sensory abnormalities, and mood changes [7]. Compared with traditional DBS, adaptive deep brain stimulation (aDBS) is based on a closed-loop pattern, which automatically adjusts stimulus parameters in response to feedback signals that can represent symptoms, aiming to reduce side effects and improve therapeutic efficacy [8]. Researchers have identified local field potential (LFP) signals as valuable for gaining insights into the mechanisms of DBS and potential feedback signals for aDBS [9]. It had been confirmed that LFPs collected at the subthalamic nucleus in PD patients exhibit significantly enhanced beta band oscillations (13–30 Hz) [10], which were believed to be related to motor impairments in PD. Recent reports suggest that the application of levodopa and DBS can attenuate this activity, suppressing beta oscillations in LFP and accompanying improvements in clinical symptoms [11].
In the current research on LFP signals, Wang et al. [12] used correlation analysis to identify and distinguish the abnormal state of LFP in PD patients. Wang et al. [13] used bispectral analysis to study the nonlinear interaction of neural oscillation in the LFP of the subthalamic nucleus of PD patients in tremor and resting state and effectively distinguished different pathological states of PD. Zhang et al. [14] extracted LFP signals frequency domain features and combined them with a naive Bayes classifier to identify LFPs of PD patients before and after medication. Sun et al. [15] used the improved empirical mode decomposition (EMD) method to separate the frequency bands containing abnormal oscillating signals from LFP. They extracted the envelope characteristics of the abnormal oscillating signals. Peter Brown’s team [9] used threshold stimulation strategies to control the pulse stimulation time of DBS after filtering, noise reduction, smoothing, and other processing of LFPs of PD patients and studied other potential feedback markers to improve the current adaptive DBS framework. In the above literature, LFP signal feature extraction usually relies on experts’ subjective judgment and experience for algorithm design, which leads to the subjective and knowledge limitation of features. At the same time, when combining traditional machine learning classification methods such as the Naive Bayes (NB) [14], support vector machine (SVM) [16], and random forest (RF) [17] for signal identification, the classification effect is likely to be unsatisfactory due to the small amount of data, inaccurate feature selection or too high or too low feature dimension. In contrast, a deep convolution neural network (DCNN) can automatically extract features from input signals without manual intervention, and meet the requirement of automatic feature extraction through semi-supervised or unsupervised means. However, the small amount of biomedical signal data limits the advantages of the DCNN algorithm [18].
Transfer learning (TL) [19] solves problems such as data scarcity, domain adaptation, feature representation learning, and model initialization by applying previously learned knowledge and experience from one task to another [20]. This technique is gradually being used in different fields of machine learning. The core idea is to use the knowledge learned on a task to speed up or improve learning on new data or tasks through trained models. Mainstream pre-trained models for image tasks include VGGNet, ResNet, MobileNet, InceptionNet, etc. These models are pre-trained on the ImageNet dataset, which contains millions of images, and the trained model can accurately classify 1000 different classes of objects. By adjusting the weight of the pre-trained model, it can be used to solve the problems of classification and segmentation in different fields. There are two main strategies for transfer learning [21]: The feature extraction strategy utilizes a DCNN model pre-trained on a large dataset to be used as a feature extractor in a new target domain. Typically, this strategy involves selectively freezing the convolutional layer of the DCNN model, removing the fully connected layer, and leaving the rest to be used as a fixed feature extractor to accommodate new tasks, such as electrocardiogram (ECG) signal classification tasks [22]. Another one is fine-tuning, which typically involves setting the convolutional layer weights of a pre-trained model to be trainable, allowing the weights to be updated during training, or adding new layers to the top of the model to fit a specific task. In the process of fine-tuning, the weight of the whole network will be updated in the training process [23]. Previous studies have applied transfer learning technology to the early diagnosis of PD. Naseer et al. [24] designed a deep transfer learning classification model based on AlexNet feature extraction and fine-tuning by handwriting image data of patients. The proposed method effectively diagnosed PD with an accuracy of 98.28%. Karaman et al. [25] developed a deep convolutional neural network classifier with a transfer learning-based model for detecting patients suffering from PD by utilizing sustained vowels as voice biomarkers. It investigated three different fine-tuning architectures DenseNet-161, ResNet-50 and SqueezeNet1_1. The results revealed that DenseNet-161 presents the highest accuracy value 89.75% amongst the other architectures. Most researches has focused on handwriting and voice data to identify PD, yet there has been limited exploration into the patterns of electrophysiological signals data that can represent the pathological state of patients.
Based on the gaps in existing research, our study uses LFP signals in the STN of PD patients, and on the basis of the transfer learning feature extraction strategy, the present study attempted to use the pre-trained model VGG16 as a feature extractor and combined it with the RF classifier to identify the disease state of PD patients receiving DBS stimulation (on-stimulation) and without getting stimulation (off-stimulation). By designing an RF classifier to replace the three fully connected layers used for classification tasks in the VGG16 model, the Bayesian optimization algorithm was used to optimize the decision tree number (n_estimators), maximum depth (max_depth), and minimum sample number of leaves (min_samples_leaf), further improved the model performance and generalization ability.
Materials and methods
Data
The data of LFP signals of PD patients came from the public data set of Peter Brown’s team at Oxford University [9]. All subjects underwent DBS surgery, where stimulation electrodes were implanted at the STN of patients and their LFP signals were recorded. The experiment was approved by the local ethics committee. A total of 52 groups of data were collected on the states of on-stimulation and off-stimulation for 26 PD patients. The sampling time of each group was about 60 s. The sampling frequency of signals off-stimulation and on-stimulation states was 2048 Hz and 4096 Hz respectively, and was uniformly downsampled to 1000 Hz, and the sampling points of each group were 60000.
The amount of data obtained from hospitals is limited, not enough to train an effective deep learning model, and increasing the amount of data in a clinical setting is not practical [26]. To solve this problem, our study enriches the data set by slicing operations. Each LFP signal segment with a length of 60000 is divided into 60 parts, that is, each segment contains 1000 sampling points and lasts for 1 s. These segments are independent signals for generating deep learning models. As a result, the dataset was expanded from 52 to 3120, with 1560 on- and off-stimulation data sets.
Signals preprocessing
In the present study, the collected LFPs were pre-processed, including denoising, filtering, and downsampling, to improve the quality of the signals, reduce interference, highlight the characteristics of the target frequency band, and provide more accurate and reliable input for subsequent analysis and model building. Firstly, a 50 Hz notch filter was used to remove power frequency interference. Then a 4-order IIR bandpass filter of 3–50 Hz was used to filter the low-frequency noise in the LFP. The filtered signal was downsampled, sliced, and converted into two-dimensional gray-scalogram images and color images using continuous wavelet transform (CWT). The converted images contain sufficient disease information, which is conducive to the status classification of PD patients. Both these distinct forms of images are used as inputs for a deep neural network to conduct a comparative analysis for the classification of LFPs. The detailed process is as follows:
Firstly, the one-dimensional LFPs are subjected to CWT. CWT performs an inner product operation between the signal
Where,
To comply with the VGG16 model’s specifications, all input images must be resized to a fixed dimension of 224
The conversion process of LFP signal to images.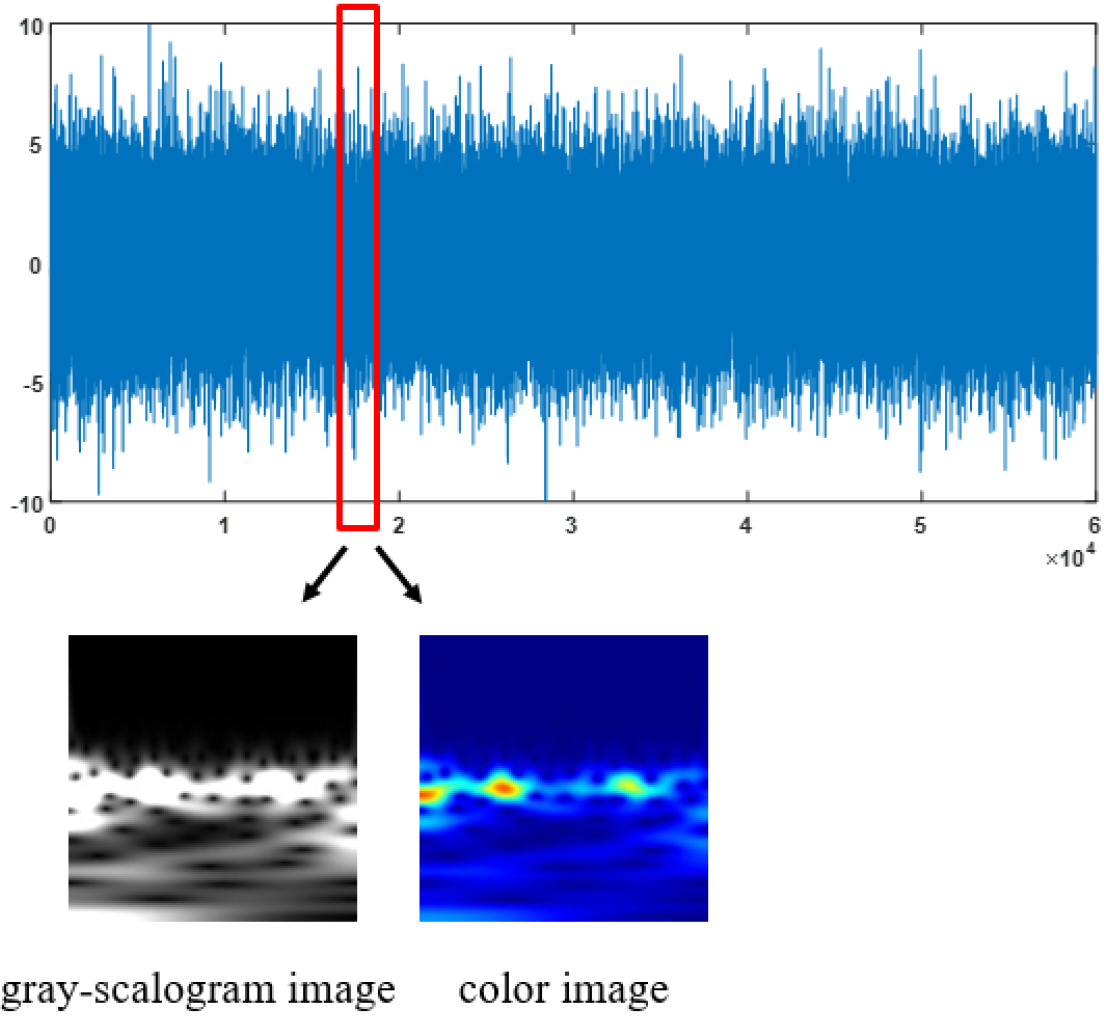
TL utilizes models pre-trained on large-scale datasets, allowing the migration of their robust feature extraction capabilities to medical image tasks. Benefiting from training on extensive data, transfer learning is widely applied in medical image classification, identification, and segmentation models, consistently demonstrating high accuracy. In the present study, a DCNN based on VGG16 is employed, which has a smaller convolutional kernel and a deeper network structure, and can effectively extract image details and semantic information. Generally, the full connection layer of VGG16 uses the sigmoid activation function to solve the image binary classification problem. In our study, due to the lack of electrophysiological signal data, it is difficult to meet the training requirements of the classifier. In addition, the sigmoid function is prone to saturation when the input value is large or small, which makes it difficult for the model to converge or learn features effectively during training, and thus performs poorly in unbalanced [28, 29, 30].
RF classifier is an integrated learning algorithm based on a decision tree, which has nonlinear modeling ability and can effectively capture complex nonlinear features in electrophysiological signals. Besides, RF has a strong anti-interference ability to noise. By integrating the results of multiple decision trees and reducing the influence of noise, the accuracy and generalization performance of the classifier can be improved, and it is not easy to overfit electrophysiological signals [31]. Therefore, this study constructs an improved VGG16 classification model by adding an RF classifier to replace the three fully connected layers used for classification tasks in the VGG16 model.
The classification model of the PD state proposed is shown in Fig. 2. First, LFPs are converted into 224
Improved VGG16 random forest classification model.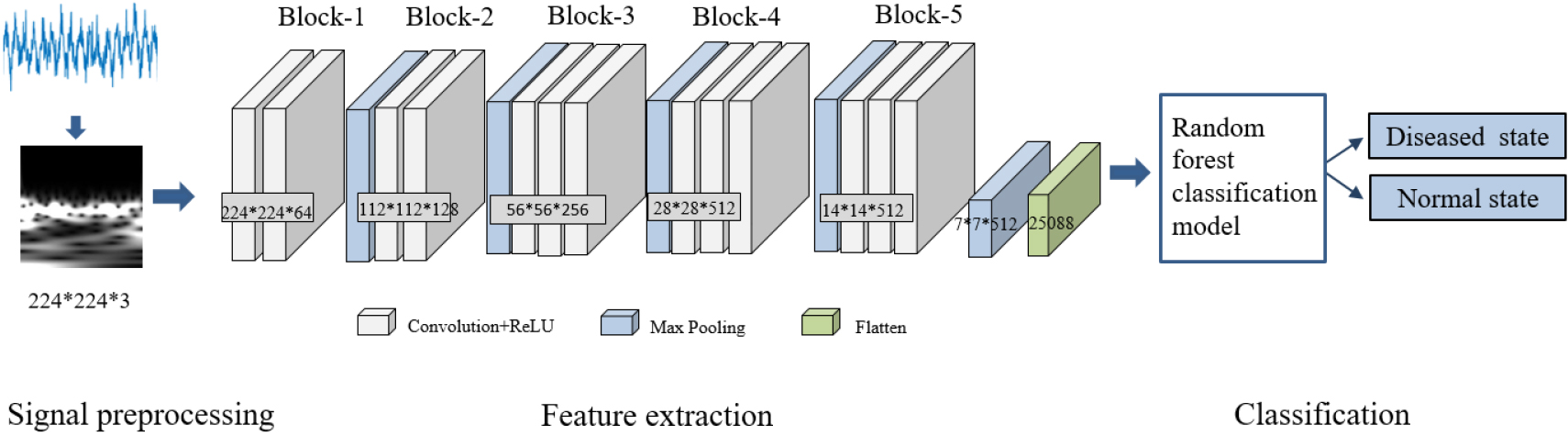
Experimental settings
To verify the effectiveness of the proposed method in this study, we conduct in-depth experiments and comparative analyses using a variety of strategies:
Construct deep neural network VGG16 and use sigmoid activation function to complete binary classification task; Other mainstream DCNN architectures such as VGG19, InceptionV3, ResNet50, and lightweight MobileNet serve as feature extractors and combine different classifiers; Compared with traditional feature extraction methods, the power spectral density (PSD) features of LFP signals are extracted according to experience. The expression of gray-scalogram images and color images in different feature extraction networks.
Evaluation indexes
In classification tasks, commonly used indexes for assessing model performance include accuracy (ACC), precision (PRE), recall (REC) and F1-score, defined as follows:
where TP, FP, TN, and FN denote the number of samples for true positives, false positives, true negatives, and false negatives, respectively. The F1-score is the reconciled mean of precision and recall, which measures the comprehensive performance of the classification model.
In this study, we used different networks to automatically extract features combined with different classification methods to recognize the disease state of PD patients and whether they are stimulated by DBS. The results listed in the table are averages of 10 experiments performed on the test set. Firstly, two image types of LFP signals, gray-scalogram image, and color image, are fed into different classification networks respectively for feature extraction and classification. The results of the accuracy of the two types of image are shown in Table 1, and Fig. 3. It can be found that the classification accuracy of gray-scalogram image is always higher than that of color image, and it can better retain the key information in the time domain, which helps the model focus more on effective feature extraction. On the contrary, although the color image can clearly reflect the amplitude intensity and other information, it may also lead to the introduction of some noise or redundant information, increasing the risk of overfitting and making the model training accuracy unsatisfactory.
Test set accuracy of two types of image
Test set accuracy of two types of image
The results of different classification models based on gray-scalogram images
The results of the traditional feature extraction algorithm
The corresponding accuracy of two types of image.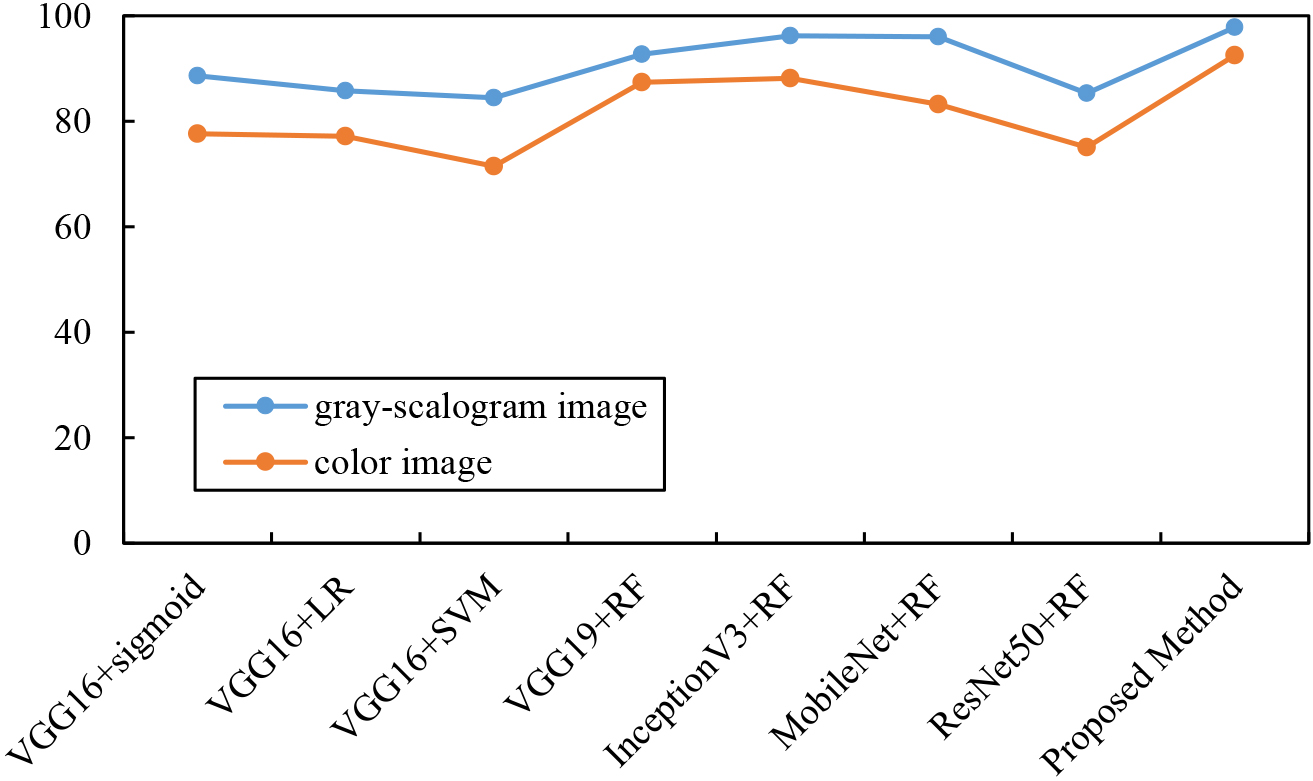
The results of the proposed method in our study with networks such as VGG19, InceptionV3, lightweight MobileNet, and ResNet50 as feature extractors to classify the target task are shown in Table 2. The experimental findings reveal that the suggested approach outperforms the rest of the deeper DCNN architectures in terms of test set classification accuracy, and the Bayesian-optimized RF classifier achieves the best results in Accuracy, Precision, Recall, and F1 score evaluation indices, which reach 97.76%, 99.01%, 96.47%, and 97.73%, respectively. At the same time, the classification performance difference of the RF classifier for feature vectors extracted from different DCNN architectures is compared. The differences in the classification performance of the RF classifier on the feature vectors extracted from different DCNN architectures are also compared, and it outperforms VGG19, InceptionV3, ResNet50, and MobileNet in the Accuracy index by 5.13%, 1.61%, 12.5%, and 1.77%, respectively. In addition, the VGG16
We compared the proposed method with traditional feature extraction algorithms, as shown in Table 3. Based on the empirical design algorithm extracted the power spectral density features of LFP signals from PD patients, constructed SVM, and RF classifiers, normalized the feature data, and trained the patient data as a whole. The experimental results indicate that traditional feature extraction algorithms have suboptimal recognition performance, while transfer learning models based on deep learning exhibit more powerful feature extraction capabilities, surpassing traditional feature extraction algorithms.
In this work, a transfer learning classification algorithm based on the combination of pre-training model VGG16 and RF is investigated to address the two key problems of using electrophysiological signals for disease state identification of PD patients in the clinic, i.e., feature extraction and small and unbalanced data volume. By transferring the knowledge or patterns learned in a certain domain to different but related domains or problems, it can not only solve a series of problems brought by small datasets but also improve the learning effect in the target domain or task.
In this paper, after performing a 1D to 2D image conversion of LFP signals, we have investigated by experimentally comparing the two types of time-frequency images for feature extraction and classification using several pre-trained models. The experimental results show that a high level of accuracy can be obtained for both gray-scalogram and color images. However, the gray-scalogram image has low information complexity because it contains more layers of time-frequency information, which makes it easier for the model to capture key features that help in classification.
Compared to other DCNN models, VGG16 shows better feature extraction capability on the target domain studied in this paper. Although the deep structure can better capture the complex features of the image, the results show that in the feature extraction task of non-smooth signals such as electrophysiological signals, the deeper network structure may lead to overfitting or computational burden, on the contrary, VGG16’s relatively shallow network structure and moderate model complexity make it show better performance in the medium-sized image classification task. This shows that the VGG16 network outperforms other models in terms of feature extraction capability and has been well transferred in the field of medical signaling. The existing studies [32, 33] based on the VGG16 deep migration learning algorithm usually pass the extracted features to the softmax classifier for training, and fine-tuning the fully-connected layer of the model to improve the accuracy of the target task. Therefore, in practical applications, since the characteristics of different tasks and datasets may affect the effectiveness of the model, the solution for a specific problem still needs to be evaluated and selected in detail according to the actual situation.
Traditional machine learning relies on the knowledge and experience of domain experts and requires the design of algorithms to extract features of relevant information, such as time- domain and space-domain information [34], Lyapunov exponents [16], etc. This approach suffers from difficulties in feature engineering and requires a lot of time and effort to select and construct appropriate features. The models used are usually linear or statistically based with limited expressive power to capture complex nonlinear relationships in the data. In contrast, the deep transfer learning algorithm proposed in this study can use multi-layer neural networks for feature learning, thus learning higher-level abstract feature representations without any manual extraction. The powerful representational ability of deep learning to capture complex nonlinear relationships in data makes it perform well on tasks in many domains.
The amount of data for electrophysiological signals such as LFP is too small to meet the training requirements of large-scale deep learning models. To address this problem, this study, based on the idea of transfer learning, utilizes a model that has been trained on a large-scale dataset and migrates its knowledge to a small dataset to improve the classification performance on the small dataset, based on which an RF classifier is added to solve the overfitting problem related to unbalanced data. In addition, the selection of the RF classifier’s hyperparameters is very important to the model performance, and the setting of the hyperparameters directly affects the model’s complexity, generalization ability, and fitting degree to the training data. Compared with traditional methods such as manually adjusting parameters or grid search, the Bayesian optimization algorithm can automatically search the parameter space, reducing the workload of manual parameter tuning. By establishing a probabilistic model between the parameters, the correlation between the parameters can be taken into account, and the optimal parameter combination can be found more efficiently, which in turn improves the performance of the RF classifier.
Conclusion and future work
STN-DBS is an effective treatment for advanced PD patients, LFP signals recorded by electrodes implanted at the STN contain rich information related to the disease as well as the patient’s state. In this paper, we proposed a new deep migration learning method for identifying the disease state of PD patients whether they are stimulated by DBS or not, which does not need to extract features manually and effectively solves the overfitting problem associated with too small or unbalanced data. Compared with other deep pre-trained models, the proposed method has good classification accuracy, and the evaluation metrics in all aspects are better than other experimental strategies with DCNN architecture as a feature extractor. In the field of medical signaling, the superposition of deep learning’s automatic feature extraction and RF classifier yields a better classification accuracy, which effectively solves the performance of the classifier under small data volume and far surpasses the traditional machine learning methods. In addition, the experimental process found that the conversion to gray-scalogram images is more suitable for classification studies of electrophysiological signals.
The lack of human electrophysiological data for technical and ethical reasons, which is prone to overfitting, is one of the reasons for the lower classification accuracy, so data expansion [35] is a key focus for the next steps. We intend to further explore and validate techniques such as synthetic data and generative adversarial networks (GANs) in our subsequent work to augment the sample dataset. On the other hand, multimodal feature fusion [36] is also a research direction for studies related to the disease state of PD. Apart from the LFPs, other multimodal data can be utilized, such as brain images, motion data, etc. Fusing LFPs with other data can provide more comprehensive and accurate identification and monitoring of the PD state.
Footnotes
Acknowledgments
Thanks to Peter Brown from the University of Oxford for providing the open-access dataset.
Conflict of interest
The authors declare that they have no conflict of interest.
Funding
The authors report no funding.