
Abstract
BACKGROUND:
The widespread use of antibiotics has led to a gradual adaptation of bacteria to these drugs, diminishing the effectiveness of treatments.
OBJECTIVE:
To comprehensively assess the research progress of antibiotic resistance prediction models based on machine learning (ML) algorithms, providing the latest quantitative analysis and methodological evaluation.
METHODS:
Relevant literature was systematically retrieved from databases, including PubMed, Embase and the Cochrane Library, from inception up to December 2023. Studies meeting predefined criteria were selected for inclusion. The prediction model risk of bias assessment tool was employed for methodological quality assessment, and a random-effects model was utilised for meta-analysis.
RESULTS:
The systematic review included a total of 22 studies with a combined sample size of 43,628; 10 studies were ultimately included in the meta-analysis. Commonly used ML algorithms included random forest, decision trees and neural networks. Frequently utilised predictive variables encompassed demographics, drug use history and underlying diseases. The overall sensitivity was 0.57 (95% CI: 0.42–0.70;
CONCLUSION:
This meta-analysis provides a current and comprehensive evaluation of ML models for predicting antibiotic resistance, emphasising their potential application in clinical practice. Nevertheless, stringent research design and reporting are warranted to enhance the quality and credibility of future studies. Future research should focus on methodological innovation and incorporate more high-quality studies to further advance this field.
Introduction
Antibiotic resistance is a formidable challenge in today’s global medical landscape. The widespread use of antibiotics has led to a gradual adaptation of bacteria to these drugs, diminishing the effectiveness of treatments. The epidemiological trends of antibiotic resistance have garnered widespread attention, posing serious challenges to public health and clinical practice [1]. Over the past decades, the misuse and irrational use of antibiotics have accelerated the development of resistance, rendering the treatment of infections more complex and challenging. Traditionally, the clinical detection of antibiotic resistance relies heavily on bacterial culture and sensitivity testing, a process that typically takes 2–5 days. Such delayed diagnostic procedures not only postpone the initiation of treatment but also increase the difficulty of obtaining effective treatment in the early stages of infection [2]. Currently, physicians are constrained to empirical antibiotic therapy, and with the escalating bacterial resistance, the efficacy of such empirical treatments has markedly decreased, leading to unpredictable treatment outcomes for patients [3]. Against this backdrop, there is an urgent need for the early prediction of antibiotic resistance. The establishment of prediction models can assist healthcare professionals in obtaining early insights into the antibiotic sensitivity of patient infections, thereby providing more targeted recommendations for treatment planning. Timely intervention not only improves patient prognosis but also helps mitigate the progression of antibiotic resistance by avoiding the overuse of ineffective antibiotics [4].
With the rapid advancement of technology, the application of artificial intelligence and machine learning (ML) algorithms in the medical field has become a research hotspot [5, 6]. Compared with traditional clinical judgment, ML algorithms offer significant advantages, particularly in predicting antibiotic resistance. This advantage stems from the efficient processing of large-scale data and the sensitivity to complex relationships [7]. Traditional clinical judgment is often based on experience and professional knowledge, but when faced with vast amounts of patient information, particularly including extensive data such as genetic sequencing, the judgment of clinicians may be challenged. These data are not only vast and complex but also involve interactions among multiple variables, exceeding the limits of human processing. With their powerful computational and learning capabilities, ML algorithms can discover potential patterns and trends in this huge amount of data, thereby providing more accurate predictions. One of the main characteristics of ML algorithms is their adaptability, as they can learn from data and adapt to new information, making them better suited to handle emerging data and knowledge in the medical field [8]. Additionally, ML can perform nonlinear modelling, identifying complex relationships crucial for the multifactorial and multilayered nature of antibiotic resistance. In medical applications, ML algorithms have been applied successfully in disease diagnosis, genomics, drug development and other fields [9, 10]. In the context of predicting antibiotic resistance, these algorithms can construct predictive models by analysing patients’ genetic information, clinical manifestations, medical records and other multi-source data, providing more accurate treatment recommendations for clinicians.
Despite the flourishing trend in research on ML predictions of antibiotic resistance in recent years, there remain some gaps in the research domain. Notably, although some systematic reviews have summarised and synthesised related studies, these reviews may be outdated in the rapidly evolving research field. A plethora of new studies and models has emerged in the last two years, offering fresh perspectives on our understanding of ML predictions for antibiotic resistance [11, 12]. Therefore, we conducted this updated meta-analysis, consolidating the latest research findings, to provide insights for the future clinical use of ML algorithms in predicting antibiotic resistance.
Methods
This meta-analysis adheres to the preferred reporting items for systematic reviews and meta-analyses guidelines [13].
Search strategy and literature selection
The search period of this study extends from the establishment of the database to 30 December 2023. Three electronic databases – PubMed, Embase and the Cochrane Central Register of Controlled Trials (CENTRAL) – were selected for comprehensive searches with no language restrictions. A combination of controlled vocabulary terms (MeSH or Emtree) and free-text terms was employed. Key terms mainly included antimicrobial resistance, ML and prediction. The full search strategy for each database is described in the supplementary material (Table S1). Additionally, manual screening of relevant references in reviews or meta-analyses within this field was conducted. The search process was performed independently by two researchers. Initially, duplicate records were removed using reference management software, followed by manual exclusion. Subsequently, articles were screened based on titles and abstracts to exclude studies unrelated to the topic. Finally, full-text reading was conducted to determine the ultimately included literature. In the case of disagreement between the two researchers, a third researcher facilitated resolution.
Inclusion and exclusion criteria
The PICOS principles were applied to define inclusion and exclusion criteria. Studies meeting the following conditions were included: 1) populations requiring antibiotics without obtaining susceptibility test results before prediction; 2) prediction of antibiotic resistance using ML algorithms; 3) no mandatory requirement for a control diagnostic method, and traditional risk scoring models could be used; 4) systematic reviews requiring diagnostic evaluation parameters, such as C-statistic, sensitivity and specificity, and meta-analyses requiring studies to calculate false negative, false positive, true negative and true positive data; and 5) observational study design. The exclusion criteria included the following: 1) studies with irrelevant outcomes; 2) studies not using ML algorithms; and 3) studies of irrelevant types, such as research letters, conference abstracts or reviews that did not report diagnostic evaluation parameters or did not focus on ML models.
Data extraction and bias risk assessment
Based on a standard data extraction table, two independent researchers extracted data, including study author, publication year, study design, region, data time span, data source, sample size, event occurrence rate, validation methods, specific algorithms used, number of input variables, types of predictive variables, observed outcomes, infection sites, diagnostic parameters and area under the receiver operating characteristic curve (AUC) value range. In cases where multiple algorithms were used in the same study, the model with the best performance (i.e. the highest AUC value) was prioritised in the meta-analysis. The prediction model risk of bias assessment tool (PROBAST) was employed for the methodological assessment of prediction model studies [14]. The PROBAST framework categorises potential bias into four domains: study participants, predictors, outcomes and analysis, with the assessment of the prediction model’s applicability covering the first three domains. Each domain that is assessed as ‘low risk’ is required to categorise the overall risk as ‘low risk’. If one domain is assessed as ‘high risk’, the overall risk is categorised as ‘high risk’. If one domain is assessed as ‘unclear’ while the other domains are assessed as ‘low risk’, the overall categorisation is ‘unclear’. Disagreements between the two researchers were resolved by a third senior researcher.
Statistical analysis
Data synthesis was performed using Stata SE 15.0 software. Sensitivity and specificity were calculated through 2
Results
Literature search
The search and selection process for this study are illustrated in Fig. 1. A total of 3,210 records were obtained after searching three electronic databases, including 636 from PubMed, 2,565 from Embase and nine from CENTRAL. After removing duplicate literature, 2,893 independent electronic records were obtained. Based on the review of titles and abstracts, 2,848 irrelevant literature items were preliminarily excluded, leaving 45 articles for full-text reading and further screening. Due to reasons such as irrelevant outcomes (
PRISMA flow diagram of study selection. PRISMA: Preferred reporting items for systematic reviews and meta-analyses.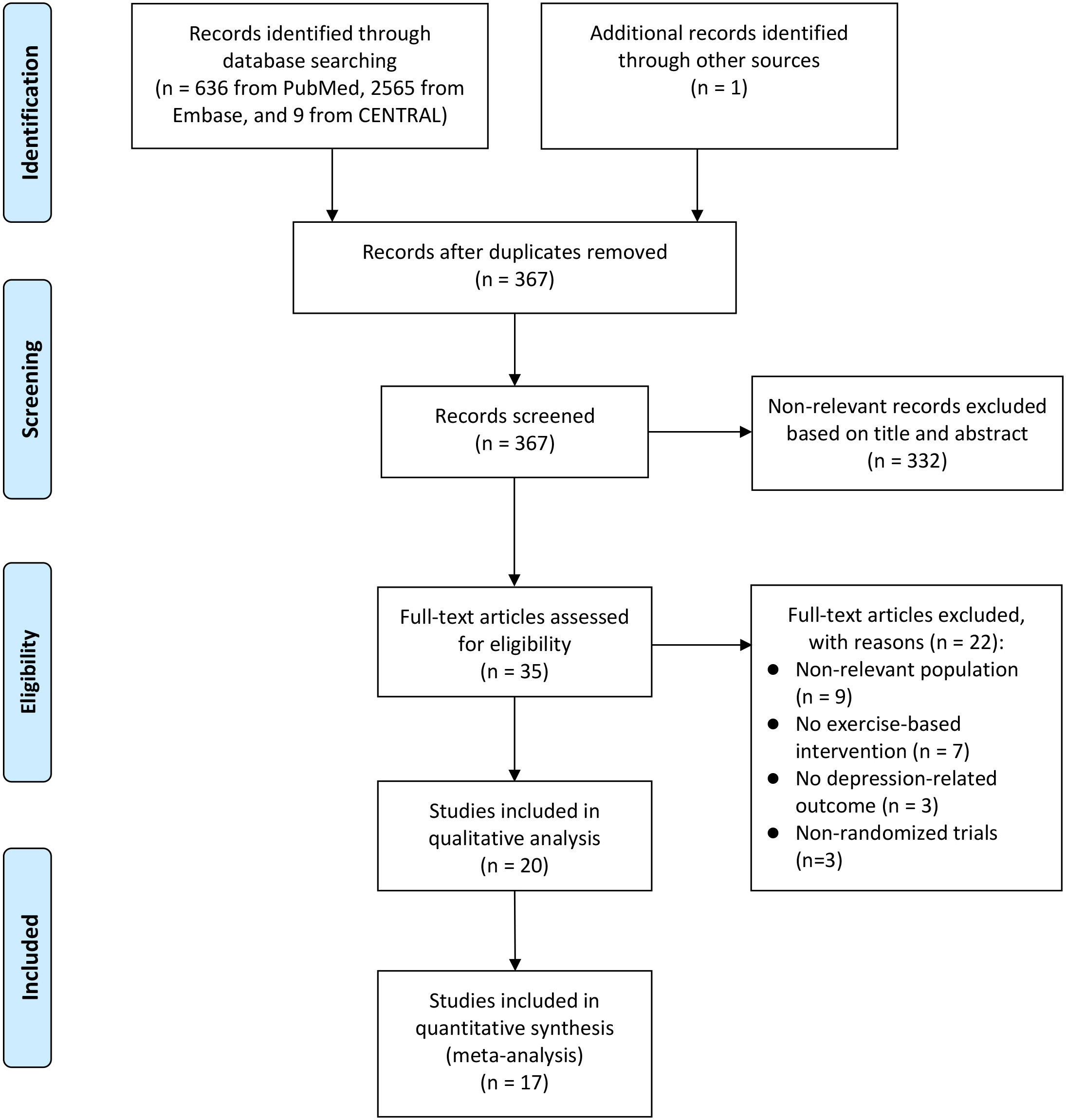
Table 1 presents the basic characteristics of the 22 studies included in the systematic review. The total sample size across these studies was 43,628. Most studies were conducted in the United States (
Main characteristics of the included studies
Main characteristics of the included studies
NA: non-applicable; USA: the United States of America; MICU: medical intensive care unit; SOT: solid organ transplant; UK: the United Kingdom; NCBI: national center for biotechnology information; PATRIC: PAThosystems Resource Integration Center; DRIAMS: Database of Resistance Information on Antimicrobials and MALDI-TOF Mass Spectra.
Characteristics of machine learning-based prediction models for sepsis
NA: non-applicable; SVC: support vector clustering; SMO: sequential minimal optimization; KNN: k-NearestNeighbor; J48: RF: random forest; RIPPER: repeated incremental pruning to produce error reduction; MLP: multi-layer perceptron; TP: true positive; FP: false positive; MCC: a correlation coefficient calculated from all four values of the confusion matrix; AUC: area under the curve; PRC: The Precision-Recall Plot; LR: logistic regression; GBM: gradient boost machine; PPV: positive predictive value; NPV: negative predictive value; DT: decision tree; ESBL: extended spectrum
Table 2 provides detailed information on the construction of the ML prediction models. For the 22 studies that met the criteria, various ML algorithms were used, including random forest (40.9%), decision tree (50%) and neural network (36.4%). Thirteen studies used demographics, 12 used underlying disease, 12 used drug use history, 10 used clinical variables, five used microbiological data and six used whole genome sequence or mass spectrometry data. The number of input variables in the models varied from 3 to 136. Thirteen studies defined the outcome as antibiotic resistance (mixed), whereas the remaining studies specified individual antibiotics. Regarding infection sites, the majority of studies (36.4%) focused on blood, six included mixed sites, one focused on urine, one on perirectal and six did not specify. There were variations in evaluation parameters, with four studies not reporting AUC; the AUC range was 0.47–0.928.
Methodological evaluation of included studies by PROBAST
PROBAST
Table 3 presents the bias risk assessment and applicability evaluation of the 22 included studies under the PROBAST framework. At the participants level, 11 studies were defined as ‘unclear’ due to unclear study design descriptions, and seven studies were defined as ‘high risk’. At the analysis level, the lack of use of a calibration plot for model evaluation in most studies resulted in high risk, leading to an overall higher risk assessment for the studies. In the applicability assessment, only one study raised concerns at the predictor level.
Forest plot of machine learning-based models for the prediction of antimicrobial resistance.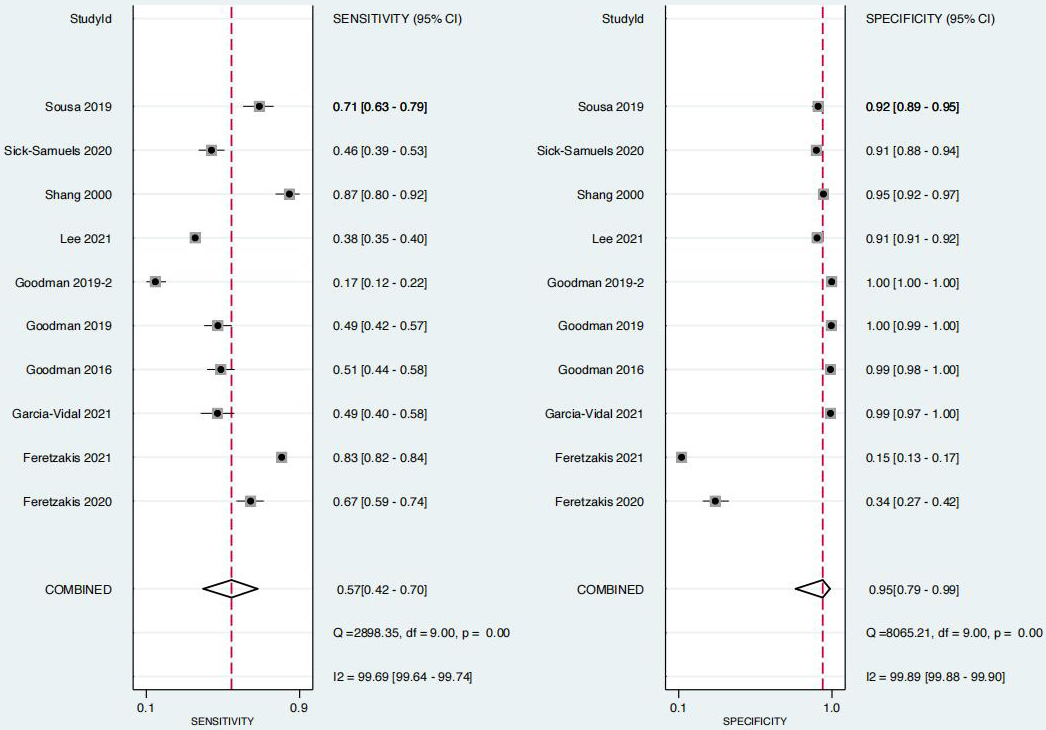
The combined results of the 10 studies with available data are shown in Fig. 2. Overall, the sensitivity was 0.57 (95% CI: 0.42–0.70;
SROC curve of ML-based models for the prediction of antimicrobial resistance. SROC: summary receiver-operating characteristic; ML: machine learning.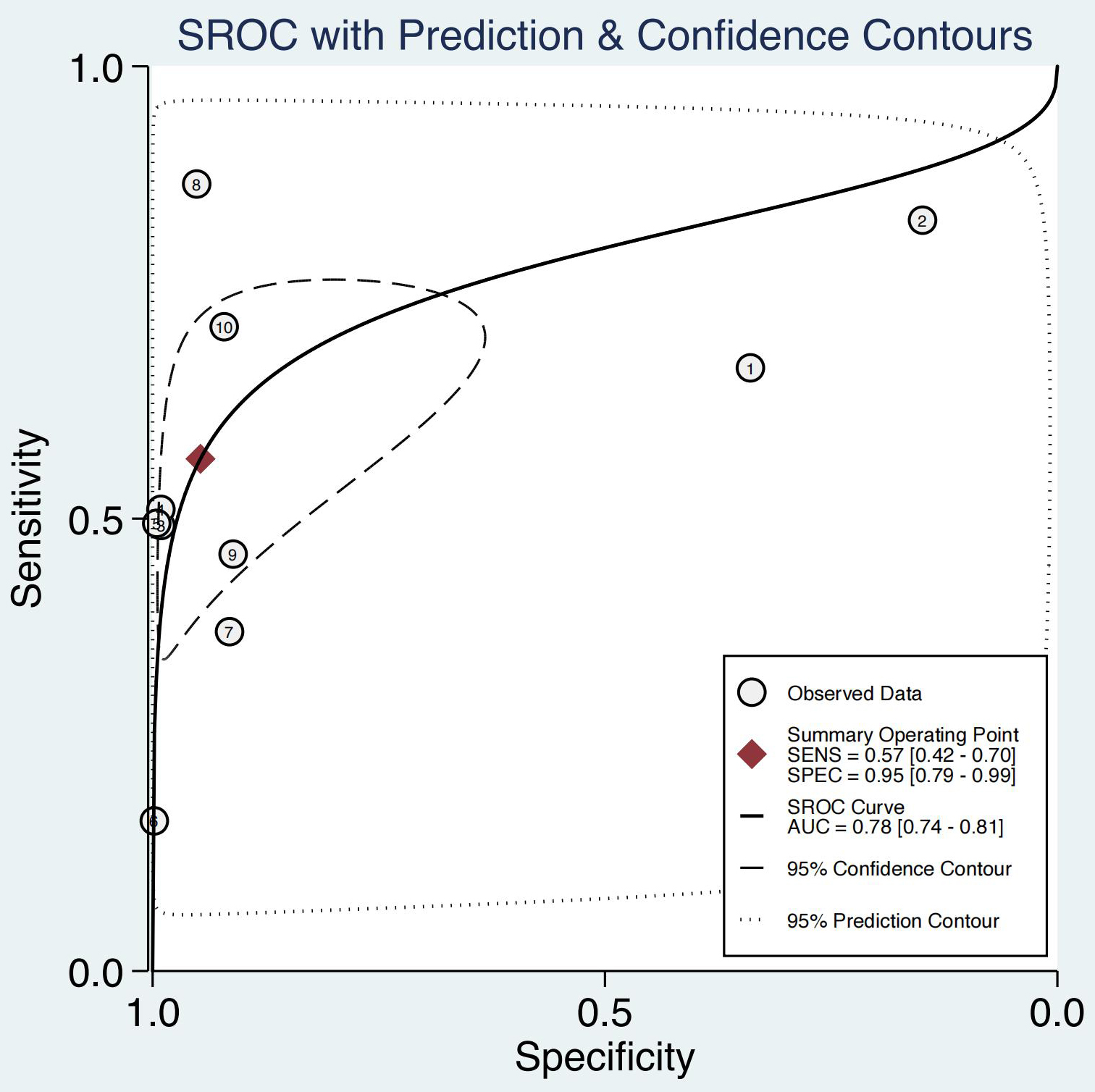
Funnel plot of ML-based models for the prediction of antimicrobial resistance. ML: machine learning.
The results of the publication bias analysis are shown in Fig. 4, where the Deeks’ funnel plot asymmetry test indicated a certain publication bias in the included studies (
Clinical utility
After using ML algorithm-based antibiotic resistance prediction models, the post-test probability increased from 50% to 91% when the pre-test was positive, with a positive likelihood ratio of 11. Post-test probability for positive likelihood ratio was 91% (95% CI: 88%–93%); conversely, when the pre-test was negative, the post-test probability decreased from 50% to 31%, with a negative likelihood ratio of 0.46. Post-test probability for negative likelihood ratio was 31% (95% CI: 28%–34%) (Fig. 5).
Fagan plot of ML-based models for the prediction of antimicrobial resistance. ML: machine learning.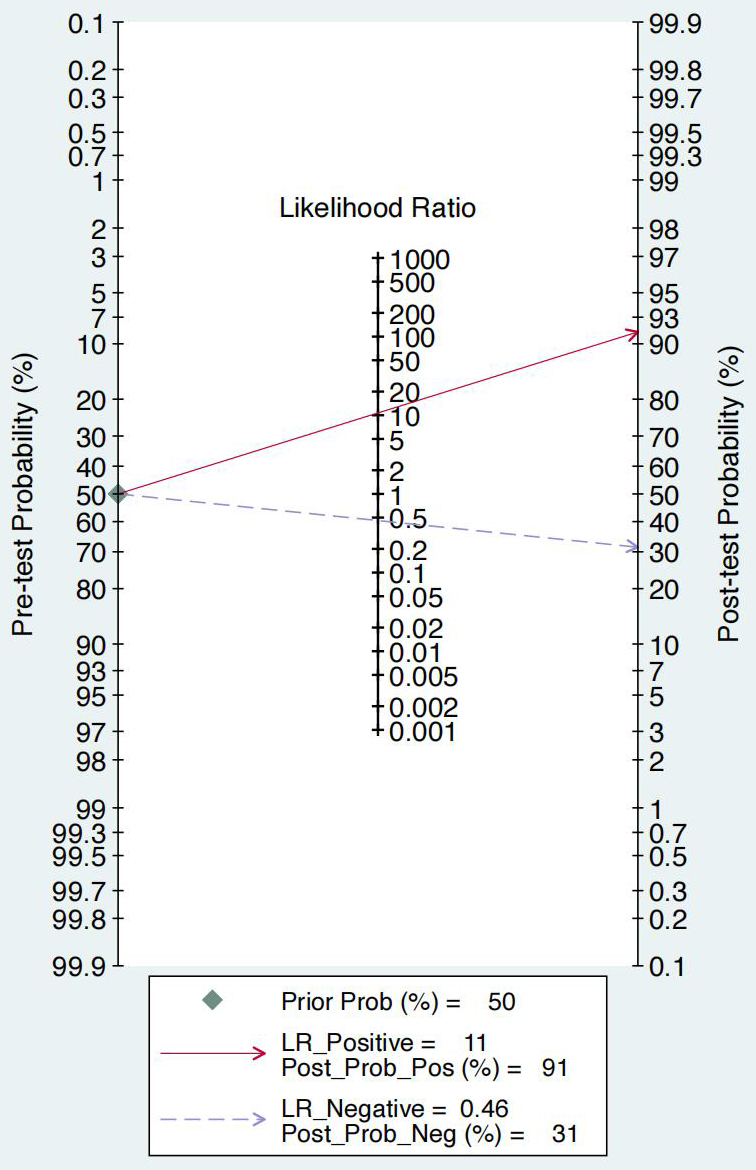
This study conducted a systematic review and meta-analysis to analyse the latest relevant research, evaluating the performance of ML algorithms in predicting antibiotic resistance. The main findings are as follows: 1) machine learning algorithm models exhibit good discriminative ability for antibiotic resistance, with weaker sensitivity but strong specificity; and 2) methodological assessment using the PROBAST criteria indicates that the included studies have a higher risk of bias due to factors such as lack of calibration and low event per variable, emphasising the need for high-quality studies to validate the results. In summary, this study affirms the potential application of ML algorithms in predicting antibiotic resistance, providing valuable decision support for clinicians.
In the context of predicting antibiotic resistance, the prolonged time required for traditional blood culture and susceptibility testing has become a significant obstacle to early intervention in infections by clinicians. Blood culture takes several days to confirm the bacterial species, and susceptibility testing requires additional time to assess antibiotic sensitivity, resulting in delayed treatment plans [37]. In this context, ML has shown significant advantages in predicting antibiotic resistance in recent years. One of the enormous advantages of ML is its ability to handle and analyse large-scale data, a task that is challenging for humans to accomplish in a short time. By utilising extensive patient data, clinical information and biochemical indicators, ML models can more comprehensively establish a patient’s infection status, providing more accurate predictions for early infection intervention [38]. Another advantage of ML in predicting antibiotic resistance lies in its ability to process microbiological data, such as sequencing data, which are crucial for predicting antibiotic resistance. Machine learning models can extract patterns and rules from these complex microbiological data, providing clinicians with more comprehensive infection information [39]. In contrast, traditional methods often struggle to handle such vast and complex datasets, whereas ML, with its powerful computing capabilities and algorithmic advantages, can better exploit this information, enhancing the predictive accuracy of antibiotic resistance. Moreover, ML possesses inherent adaptability, continuously learning and adjusting models to adapt to new microbiological changes and antibiotic resistance mechanisms. This flexibility makes ML more adaptive to addressing new challenges in infectious diseases, providing robust support for individualised treatment plans [40]. Overall, the ability of ML to predict antibiotic resistance is primarily derived from its processing capabilities for large-scale data and microbiological information, as well as its flexibility in model adaptability. This offers clinicians the possibility of earlier intervention in infections and more precise formulation of treatment plans, with the potential to improve the effectiveness of antibiotic use and reduce the risk of resistance development in the future.
Despite the potential advantages shown by ML in predicting antibiotic resistance, its practical application still faces a series of challenges and difficulties. Potential issues include the following. 1) Clinical complexity: clinical decision-making is an extremely complex process involving multiple factors, including individual differences, preferences, economic status and accessibility to medical services. Machine learning models may struggle to consider these complexities comprehensively, as some factors may be challenging to incorporate into the model or difficult to extract from big data sets. 2) Decision interpretability: machine learning models are often presented as black boxes, making it difficult to interpret their decision-making processes. In clinical decision-making, doctors and patients typically need to understand and trust the predictive results of the model. Poor interpretability may affect the acceptance of model recommendations by healthcare professionals, making it a crucial challenge to improve model interpretability. 3) Data quality and standardisation: machine learning models require high-quality and standardised input data. Healthcare data are often dispersed across different systems and formats, with missing values and errors, which can affect model performance; standardising and integrating this data is a time-consuming task. 4) Patient prognosis outcomes: despite some studies suggesting the impact of ML algorithms on patient prognosis [41, 42], the prognosis effect of these algorithms on predicting antibiotic resistance is currently unknown. Further research is needed to verify the feasibility, accuracy and actual clinical effects of these models before applying them in clinical settings. 5) Ethical and regulatory issues: applying ML algorithms to clinical decision-making involves ethical and regulatory issues. Issues such as privacy and security of patient data, as well as the review and regulation of ML algorithms, require the establishment of a robust legal and ethical framework. 6) Model generalisation ability: machine learning models are typically trained on specific datasets during development. The model’s ability to generalise to other clinical environments is a critical issue, as clinical data may vary significantly due to regional and population differences. 7) Acceptance by doctors and patients: the acceptance of ML models by doctors and patients is a key factor in the successful application of these models. If healthcare professionals and patients lack trust or have low acceptance of model recommendations, the actual effectiveness of the model may be limited. Therefore, although ML shows potential benefits in predicting antibiotic resistance, these challenges need to be addressed in practical clinical applications. Continuous research and innovation are necessary to gradually overcome these obstacles and achieve the sustainable and effective application of ML in antibiotic treatment decisions.
This study demonstrates significant novelty, primarily as the most recent and updated systematic review and meta-analysis. Although there were previous relevant studies, the rapidly increasing number of studies in the past 2 years, particularly in predicting antibiotic resistance, has rendered previous reviews unable to comprehensively reflect the current progress in the field [11, 12]. The use of ML algorithms for predicting antibiotic resistance has several advantages over traditional methods, such as faster and more accurate results, better handling of large-scale and complex data and more flexibility and adaptability to new information and scenarios. Machine learning algorithms can provide clinicians with timely and reliable predictions of antibiotic resistance, which can help them choose the most appropriate antibiotics and improve patient outcomes. However, the use of ML algorithms also poses some challenges and limitations, such as data quality and availability, model interpretability and explainability, ethical and regulatory issues and acceptance by doctors and patients. Therefore, future research should address these challenges and limitations and explore the best practices and standards for applying ML algorithms in clinical settings.
The advantages of our study as an updated meta-analysis are that we provide the most comprehensive and up-to-date evidence on the performance of ML algorithms for predicting antibiotic resistance and that we use rigorous methods and tools to assess the quality and heterogeneity of the included studies. Our study can help clinicians, researchers and policymakers to understand the current state and progress of ML applications in antibiotic resistance prediction and to identify the gaps and directions for future research.
However, we must carefully consider the limitations of the study to provide a more accurate interpretation of the results and guidance for future research. First, there is insufficient data in the studies included in this meta-analysis, with only a few studies providing adequate data for the combined analysis. This limitation restricts our assessment to only certain ML algorithms in predicting antibiotic resistance, failing to comprehensively reflect the current status of the entire field. Additionally, the results of the publication bias test suggest the possibility of selection bias, indicating that published studies are more likely to provide sufficient data, while unpublished studies may be excluded due to insufficient data, affecting the completeness of the results. Second, there is high heterogeneity in the meta-analysis of this study. The presence of heterogeneity may originate from various aspects, including differences in study design, sample characteristics and the diversity of the ML algorithms themselves. This suggests the need for a cautious interpretation of the results of combined effects in the meta-analysis, as heterogeneity may reflect the diversity of data sources and also indicate that existing data analysis methods may not be very applicable to the complexity of ML algorithms and predictive models. A meta-regression analysis to investigate the potential sources of heterogeneity in our meta-analysis, such as region, study design, data source, sample size, event rate, validation type, algorithm, number of variables, predictor types, outcome of interest and infection site is an important direction for future research, as it can help us understand how the performance of ML models for predicting antibiotic resistance may vary depending on the characteristics of the studies, the data and the models. Third, we must recognise the higher risk of bias in the included studies. In the methodological assessment, we used the recently developed PROBAST framework but still found a certain risk of bias in the studies. The main risk arises from insufficient descriptions of study cohorts and the lack of calibration, among other factors. Finally, a network meta-analysis is needed to compare the performance of different ML algorithms for predicting antibiotic resistance, such as logistic regression, random forest, gradient boosting, decision tree, support vector machine, k-nearest neighbour, multi-layer perceptron and deep neural network. This is an important direction for future research, as it can help us rank the algorithms based on their sensitivity and specificity and identify the most suitable algorithm for the prediction task. This indicates that in future research, stricter adherence to the transparent reporting of a multivariable prediction model for individual prognosis or diagnosis guidelines [43] is needed to ensure the quality and credibility of the studies.
Conclusion
In summary, this study indicates that the use of ML algorithms in predicting antibiotic resistance demonstrates robust discriminative capabilities, coupled with excellent specificity but relatively weaker sensitivity. Undoubtedly, this provides a new decision-making tool for the future application of antibiotics. However, given the high heterogeneity observed, further high-quality research in this field is essential to advance the clinical application of ML algorithms.
Availability of data and materials
All data generated or analyzed during this study are included in the article.
Author contributions
Conception and design of the work: Lv GD; Data collection: Wang YT; Analysis and interpretation of the data: Lv GD, Wang YT; Statistical analysis: Lv GD, Wang YT; Drafting the manuscript: Lv GD. All authors critically revised the manuscript and approved the final version.
Funding
The authors did not receive financial support for the research, authorship, or publication of this manuscript.
Supplementary data
The supplementary files are available to download from https://dx-doi-org.web.bisu.edu.cn/10.3233/THC-240119.
Footnotes
Acknowledgments
None to report.
Conflict of interest
None of the authors have any personal, financial, commercial, or academic conflicts of interest.