
Abstract
This paper presents a simple model for representing and evaluating the behavior of users participating in a decentralized data-sharing system. The aim is to explore alternatives to current Web 2.0 systems which suffer from trust attacks, bias, administrative overhead and brittleness. In our model, users get to share documents that they like and they follow other users who are more likely to share documents that they will like. Since there is no central authority, the users also use local and independent means of discovering and ranking documents. We show, using a simulation of the model, that this scheme provides an incentive for users to contribute to the system, and it makes the system more resistant to attacks.
Introduction
Online communities, forums, collaboration tools, product rating sites, and more generally most Social Machines [14,22] relying on the contribution of end users depend on a central authority to store, calculate user contributions such as files, ratings, rankings, and deal with abuses. This is problematic as the goals and incentives of the central system may not be aligned with those of its users. There could be much overhead involved with the administrative tasks required to run these sites at the central point of authority: the number of full-time staff required to moderate forums and deal with abuses, the hardware resources, and the complexity of algorithms required to help them with these tasks. There could be biases in the rankings (malicious or not), potential for censorship, and more importantly, the fact that if this central authority goes away, so does the entire system and the result of the many man-hours contributed by the users. We want to explore decentralized alternatives where no management tasks are required of a central authority, i.e., where users contribute their own resources and perform their own way of ranking comments and aggregating ratings. This is in line with Tim Berners-Lee’s recent call for re-decentralizing the web.1
For such a system to be successful, one problem to overcome is that of “free-riding”, where users don’t have any incentive to contribute to the system [1,15,16]. In peer-to-peer file-sharing systems, many users may not want to share their own documents with others. In rating systems such as those used by Yelp or TripAdvisor, there is again no real incentive to act honestly, and aggregated ratings are not able to filter out dishonest ones. Collaborative filtering systems (such as Netflix or Amazon’s product recommendation) work by using the user’s own purchases, choices and preferences, and by correlating them with other users’ to offer personalized ratings and recommendations [20]. Here there is an incentive for the user to state their preference honestly, since this leads to better recommendations.
We want to model and simulate document-sharing or rating systems. Our model must take into account the subjective nature of “quality” and “relevance” of a document or recommendation, and allow for the diversity of tastes among the participants. Simply retrieving documents based on how they fit certain search queries is not sufficient. In our model, users can participate by producing and “liking” documents and by “following” other users. Indeed, the idea is to provide a social networking overlay for the document sharing or recommendation system. We want to see under which conditions there is an incentive for users to participate in this way. This requires us to define a payoff scheme for users that is intrinsic to the system (as opposed to external rewards, such as the personal satisfaction of having many followers (Twitter) and “likes” (Facebook) or the benefits of having a good professional resume (by maintaining a well-connected LinkedIn network, or by contributing to GitHub or StackOverflow)). Since we are focusing on rating systems or document-sharing systems, one essential intrinsic payoff for the user is the number of high-quality documents or ratings she can retrieve from the system. Hence, a scheme where the user’s own participation can help improve the quality and quantity of what she can retrieve, and of the participants she can retrieve these from, is not only beneficial to the user but also, as a side-effect, to other users and to the system’s viability as whole.
We also want to evaluate the resiliency of such a decentralized system to malicious behavior, and to observe the evolution of the system where diverse populations with various payoff schemes (some potentially nefarious) may coexist. We want to be able to set up experiments to discover attack-resistant ranking systems and behaviors, and find the breaking points for these schemes. In this paper, we provide the basic minimal formalism for our model, and we present results obtained by running simulations of our model. We find that the results confirm our intuitions that collaborative filtering schemes perform better than popularity-based ones (especially in the presence of attacks), and that there is a clear advantage in actively participating in the system rather than free riding.
Basic definitions
We will strive to keep the model as minimal as possible. Our model is close to, and expands on, [6,12].
We consider a set P of peers, and a set D of documents. We then consider a relation in
Next, we consider a relation in
While the name of this relation is meant to capture and evoke the “like” functionality in Facebook, it goes far beyond. In decentralized data-sharing networks, e.g., a peer-to-peer music-sharing system, there is no central count of user votes or opinions. Instead, the fact that a given user has decided to share a given document, and be known for sharing it, is what stands for the user’s vote. The popularity of a document is thus indicated by the number of times a document is shared, and is, as a consequence, linked in such systems to its availability (and so again, as in the “follow” relation, the decision to “like” has a concrete, positive consequence for the availability of the document). Therefore, our “likes” relation is also synonymous to “shares”. It can also capture an “upvote” in an online forum like Reddit or a question-answering site like StackOverflow.
To address the changing nature of documents over time, we are going to assume that the “likes” relation applies to a single snapshot of a document at a time. Indeed in decentralized data-sharing systems, such as distributed hashtables, the identity of a document is based on the hash of its content, and so with a every change a new document and therefore a new identity is generated. The “likes” attached to the earlier version do not carry over to the new one. This makes sense, since the user may not like the change made to the new version.
The above two relations are general enough to capture a great range of concepts in centralized and decentralized data-sharing social systems. We could have introduced variations such as “dislikes”, “downvotes”, “favorites”, or added further varieties of “likes” to express finer user sentiment such as humor or anger. However, doing so would restrict the generality of the purpose, limit the scope of the impact of the results, and introduce more parameters that would contribute to the combinatorial explosion of the simulation parameters. We leave such explorations for future work.
Next, we need to capture the inherent properties of a document that may make it suitable or “likeable” for a given user and unsuitable for another one. These properties may be hidden and only apparent to the user after the document has been consumed. To this end we introduce a set L of labels. A document can then be “tagged” by a set of labels, via a relation in
Peer behavior
With the above definitions and notations in place, we can now define the general pattern of peer behavior that we want to simulate. During each simulation cycle, peers will act in the following order of steps:
search for relevant documents, rank them according to some metric, and select the top k for consumption; calculate the payoff of consuming the above top k documents, based on whether they ultimately proved relevant to the peer; decide whether to “like” or “unlike” the documents in the top k (or do nothing); decide whether to “follow” or “unfollow” the peers associated to the documents in the top k (or do nothing); optionally, publish a new document; decide whether to stay or leave the system.
In each of the above steps there are many policies that may be followed, and the payoff function may also differ from one peer to another. In what follows, we will describe the various policies and payoff functions that we will consider.
Ranking metrics
We will make the assumption that all documents in D are a priori potentially relevant to a given user, i.e., we can view D as the subset of all available documents which matched some search criteria. Remember again that the tags we introduced earlier are only a means to determine a posteriori whether the file was a good match. The ranking metric is used to help find and select these good matches without knowing their tags.
One simple ranking metric is document popularity.
For a given document
The above metric can be used to rank the documents from most popular to least popular. This metric is very often used in existing data and file-sharing systems. The number of Facebook “likes” or Twitter “retweets” on a given web site is often made prominent and is used to highlight or filter information deemed relevant to the user. Peer-to-peer file-sharing systems rank search results based on the number of copies of the given file available in the system. Forums such as Reddit, HackerNews or StackOverflow use the number of “upvotes” to rank user posts based on their popularity.
Documents may also be ranked according to the properties of the peers that “like” them. Given the set of “likers” of a given document d defined as follows:
Then this metric can be applied to only the peers who liked a given document d, and we obtain the following ranking metric:
Note that in the above formula the rank of the document is based on the most popular peer who liked the document. It is possible to substitute the max function with the average popularity, the minimum popularity, etc.
Our metrics so far have been absolute, i.e. they leverage the wisdom of crowds and do not take into account the peer who is performing the search. Such metrics are vulnerable to sybil attacks [8], i.e., the possibility of malicious peers (formed potentially by a small number of users and a large number of alter egos) entering the system and collectively liking a given document or following a given peer to bias the search results. These metrics are also less helpful when the quality of the document is subject to taste or opinion; that is when peer a has taste
(The similarity calculations make use of the Jaccard distance metric). Then, for a given searching peer p, we can apply any of the above relative metrics to rank the documents. For example:
Using a ranking based on peer similarity basically corresponds to classical collaborative filtering, such as in [23]. Once a ranking criterion has been chosen, it can be used to return the top k documents in D.
Note that the above calculations can also easily accommodate a dislikes relation as well. Indeed one would be similarly able to calculate the set of “dislikers” of a given document, and therefore the document’s unpopularity, and scores such as two peers’ dislike similarity. Then the separate like- and dislike-based scores could be combined into a weighted average, but, more interestingly, new scores reflecting the degree of controversy of a document could be obtained, which would provide very helpful information to an end user. We leave these investigations for future work.
Let us apply the metrics we introduced above to the example in Fig. 1. As per our notations, P represents the set of peers, and D the set of documents. The dashed arrows represent the “follow” relationship between peers, while the solid arrows represent the “likes”. Using document popularity, the documents would be ranked:

Example.
For the relative rankings, we first need to pick a peer from whose point of view we are going to perform the search and therefore the ranking. Using peer distance, from peer 1’s point of view, peers are ordered
Using the peers’ “like” similarity instead of distance, we first obtain that:
and
and so peers are ranked
Finally, using “follow” similarity, we first obtain that:
and
and so peers are ranked
The above example clearly shows how different, yet all seemingly reasonable, ranking metrics can yield widely different results.
We will mostly consider two different types of payoffs, depending on the main motivations that peers may have.
The peer receives a positive payoff for each document appearing in the top k ranking that has a tag matching one of the peer’s tastes (one variation here is that the payoff could be applied only for documents that aren’t already “liked” by the peer). Therefore, the ideal top k should provide a balance between relevance and diversity. Peers with such a payoff scheme can be described as having a consumer profile. The peer receives a positive payoff for each document appearing in the top k ranking of other peers that has a tag matching one of the peer’s tastes. Peers with such a payoff scheme can be described as having a producer profile.
Strategies
From the previous section, it follows that a rational consumer should seek “like” and “follow” strategies consistent with the document ranking metric that she has chosen. For instance, when using a document similarity metric, a consumer should be truthful in “liking” the documents she actually likes, to increase similarity with peers with similar tastes (as mentioned in the Introduction, this is the basis of recommender systems). When using a peer distance metric, the consumer should “follow” peers who yield the most documents tagged with her tastes.
A rational producer should align her “like” and “follow” strategies with the ranking metrics of the consumers. For instance, she can “like” documents she has produced, to increase their popularity and to help them appear in ranking metrics that rely on document popularity (a sybil attack would consist of doing this with multiple identities). She can also “target” a consumer, and copy his “likes” (resp. “follows”) to artificially increase their “like” (resp. “follow”) similarity and ensure that her own documents figure in the target’s similarity-based ranking metric. Note the difficulty for a producer to pursue both strategies simultaneously, as one strategy might defeat the other.
Experiments
We have simulated the model described in this paper2
Available at: https://github.com/alirezafarid/network-simulation.
establish properties of our model and the parameters of our simulations;
perform a comparative performance of ranking strategies;
see how these performances are affected when multiple profiles of users are participating;
observe the effect of “like” and “follow” strategies: this would establish whether there is an incentive for users to contribute in these manners;
evaluate the performance of producers, and the effect of their strategies on the performance of consumers;
observe the evolution of the social network of users, and their self-organization, over time.
During each iteration of the simulation, all the peers are asked to perform as per the actions described in Section 2.2. The order in which they act is random. In the first set of experiments, we focus on users with a consumer behavior, i.e. one in which they like documents in the top k that match their taste, and follow peers who liked those same documents. The payoff for a document in the top k of a consumer whose tag matches the taste of the consumer is arbitrarily set at +2, and −0.5 otherwise. We will only be using 2 different labels (0 and 1) and only a single tag per document (resp. a single taste per peer), to ease the analysis of the results. Documents only appear once in the top k of a given user, and are excluded in later iterations. This means that eventually, after
We also set the number of documents to 400, the number of peers to 60, k is set to 5, and the total number of iterations is 80.
Ranking strategies in isolation
We first look at the cumulative payoff of various ranking strategies when the population unanimously adopts the same strategy with a 50–50 split of their tastes. We ran the

Performance of ranking strategies when adopted unanimously (
The first thing to observe in Graph 2 is that, indeed as anticipated above, the cumulative payoff for all strategies eventually reaches the same expected value, obtained when all the documents have been visited. But we also observe that

Performance of

Performance of
To study the performance of the

Performance of ranking strategies given a 70–30 split in tastes (Taste 1 belongs to the majority).
We obtain similar results with
Some early conclusions we could draw from the above experiments are the fact that the performance of popularity-based, “wisdom of the crowd”, ranking strategies, as used in file-sharing communities where files are ranked based on the number of downloads, in online forums such as Reddit or StackOverflow where comments are “upvoted”, or in rating sites such as TripAdvisor or Yelp where ratings are aggregated, are vulnerable to the distribution of opinions and tastes among users. They will work fairly well for users sharing the taste of the majority but not for the minority. In contrast, sites using a collaborative filtering system based on the similarity of tastes among users, such as Netflix, will be immune to the vagaries of these distributions and will outperform the popularity-based strategies. We are aware that we cannot draw such broad conclusions solely based on the results of our simple simulations. But the above results are fairly intuitive, and they give us confidence in the correctness of the implementation of our simulation and the appropriateness of our model. This allows us to move ahead with more complex experiments.
We now want to observe the effect of mixes of strategies: a certain population of consumers with a given strategy should see their performance affected by the presence of another population using a different strategy. In the first experiment setting, the majority, with taste 1 in a 70–30 split, uses the

Mix of populations: the majority has taste 1 and uses

Mix of population: this time, the majority has taste 1 and uses
In a second experiment setting the roles are reversed (Fig. 7), i.e., the majority uses
Figure 8 shows, for the experiment of Fig. 6, the rate of growth of document “likes” based on their tags, and it further confirms that the popularity of documents matching the optimal strategy grows quasi-optimally early on.

Growth of the number of document “likes” for each tag.
We observe the same results when mixing the
These experiments can be viewed and summarized as games between the majority taste and the minority taste, and the results show that a ranking strategy using
Majority vs minority game: peer-like-similarity dominates doc-popularity

Free-riders (“leeches”) vs contributors, both with the same taste and same strategy.
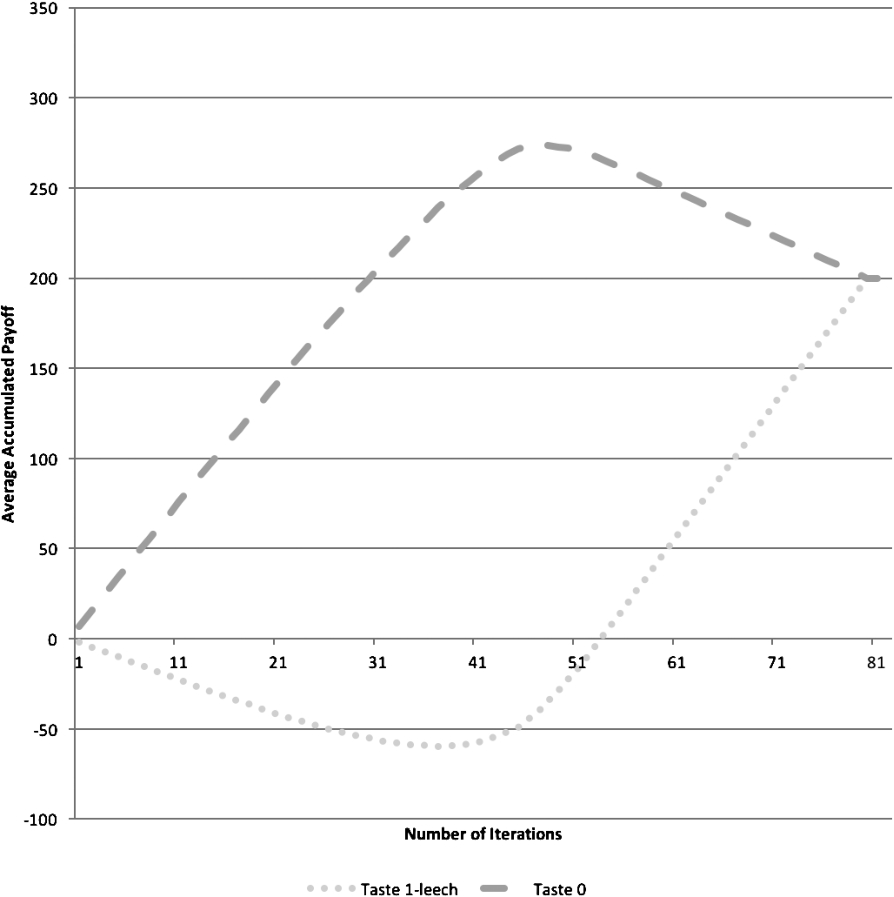
A majority of free-riders (“leeches”) vs a minority of contributors, with the same strategy but different tastes.
In our model, free-riders can be simply modelled as peers that do not bother “liking” documents or “following” peers, and hence do not contribute to the collaborative filtering or the wisdom of crowds. When these free-riders share the same taste as the rest of the peers, they benefit from the work the rest does, see Fig. 9. But if the free-riders don’t have the same taste as the rest, even if they are the majority of the peers, they have very poor results, see Fig. 10. If the free-riders use a peer like similarity ranking strategy, since they will have zero similarity with the non-free riders, the payoff of the free riders will be equivalent to random, see Fig. 11. In summary, in the game where a peer should choose between participating or free-riding, when the tastes are different, participation dominates free riding, see Table 2.
This is all of course assuming that participation comes at no cost. In future work we should include a cost to participation and find the tipping point at which it is better to free ride.
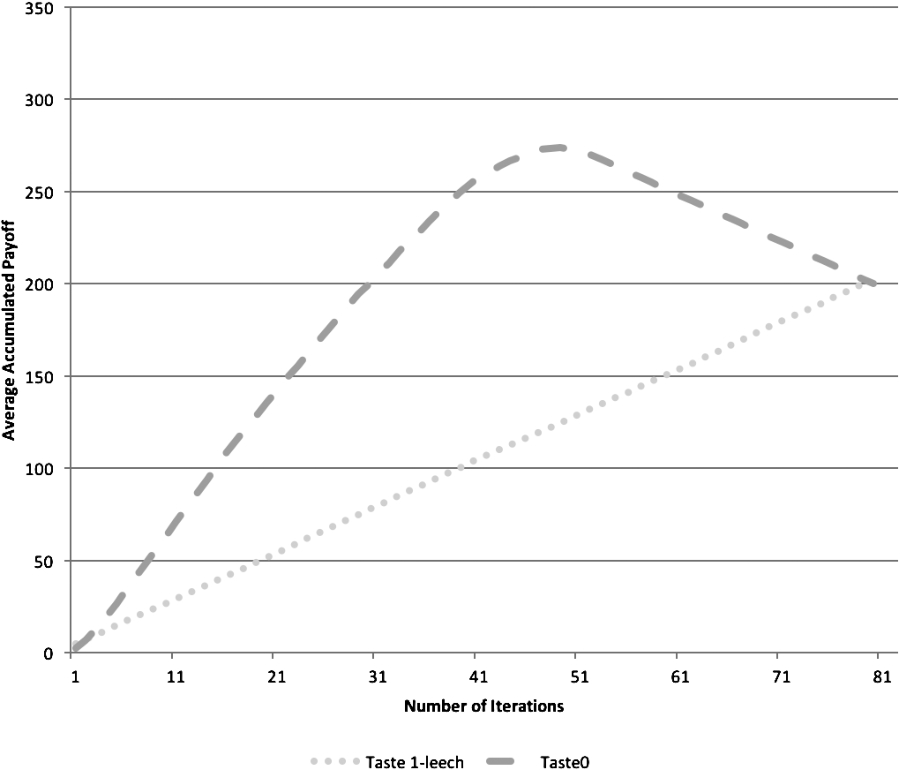
Free-riders (“leeches”) vs contributors, both using peer-similarity but with different tastes.
Majority vs minority game (both using doc popularity): contributing (“liking” documents) dominates free-riding (not “liking”)
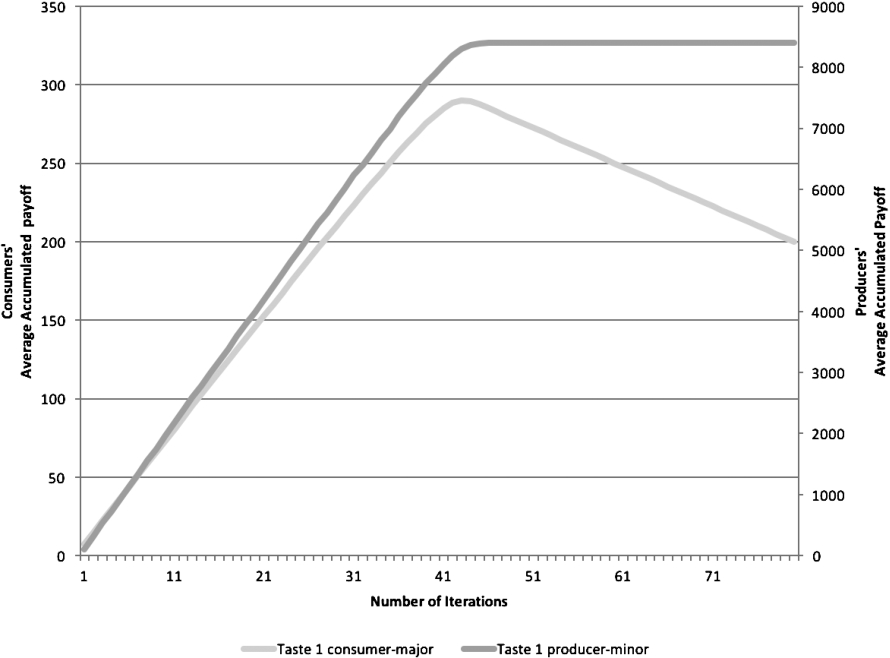
Performance of consumers and producers when sharing the same taste, both using
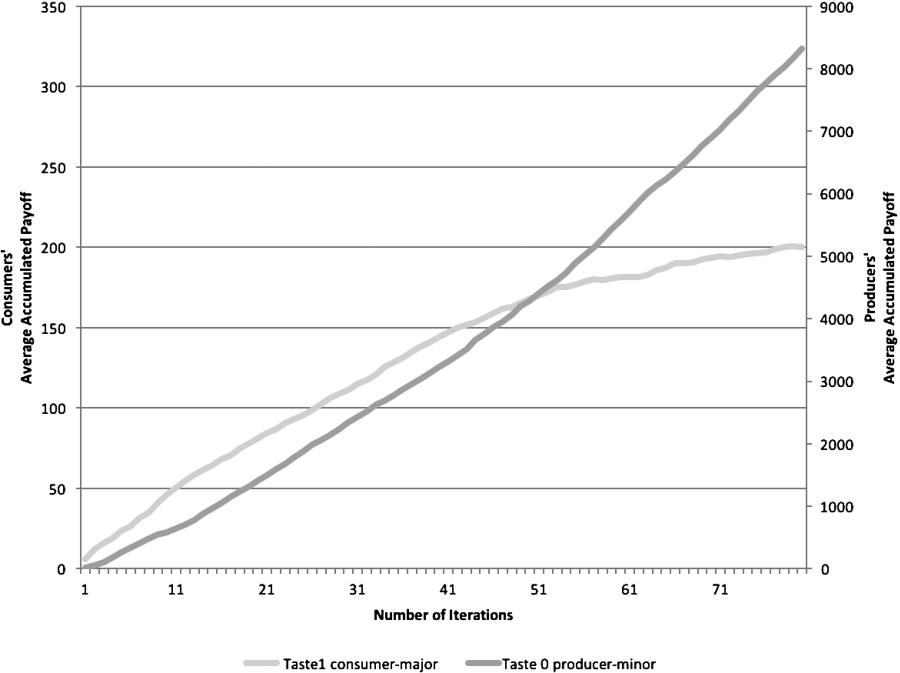
Performance of consumers and producers when both using
Recall from Section 2.4 that producers receive a positive payoff every time a document that matches their taste appears in the top k of another peer.3
In our experiments we did not make the producers actually produce any documents during the simulation, since we believe it easier to reason with a fixed number of documents created at the beginning of the simulation.
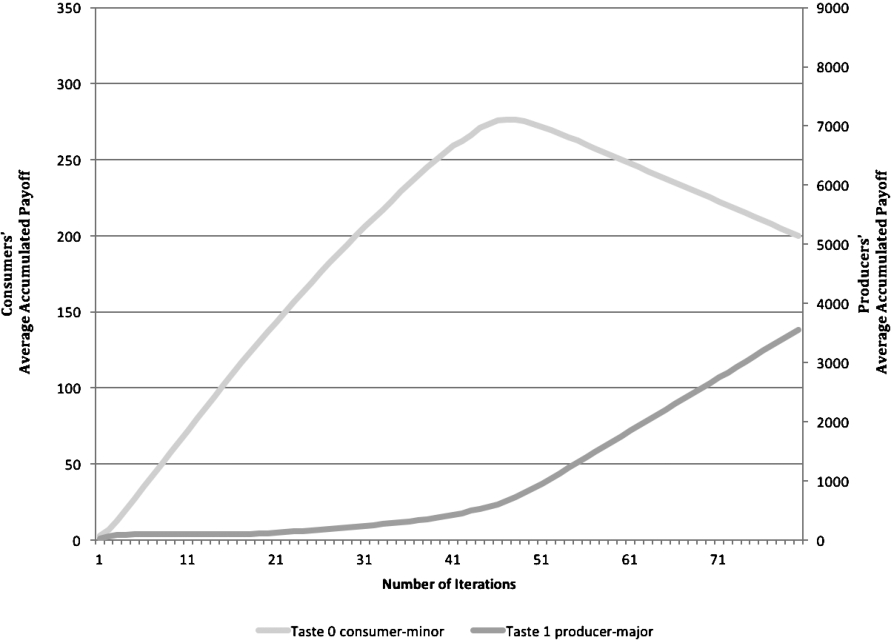
Consumers vs producers of different tastes, when consumers use
If there is no cost to creating sybils to attack the popularity strategies (i.e. increasing the number of producers with the “wrong” taste), or to creating artificial “likes” or “follows” to attack the peer similarity strategies, producers could mount an attack on both fronts. Intuitively, the cost of a successful two-pronged attack should be equal to the product of the costs for each separate attack: indeed each sybil would have to perform social exploitation. It is our intention to incorporate a cost model in our simulation to validate this hypothesis in the future.
Decentralizing social web applications has garnered a great deal of interest recently, mostly in the open source community, with projects such as IPFS or Gnu Social. Solid [21] is a recent academic initiative. Free-riding in peer-to-peer systems is a well-known and well-studied problem, see [11]. Resistance to sybil attacks has also been studied in various settings, such as Distributed Hashtables (DHTs) [4]. Our similarity-based ranking is not to be confused with routing schemes that use similarity as a way to optimize routing in peer-to-peer networks, such as in [9]. A means to perform similarity-based queries has also been proposed in [10]. Self-organization of peers in a file-sharing network has been recommended in [2], studied in [13,19] and [24], and a social layer for a peer-to-peer file sharing network has been implemented [18]. In [13], a “tag” model (the term is unrelated to our use) is studied that determines the social mobility of the nodes, and it is shown that this mobility, coupled with the selfish utility-maximizing behavior of nodes tends to combat free-loading. In [24], peers build a Bayesian trust model of the peers they are interacting with, based on past transactions. [19] show that advice-seeking is beneficial for peers, and that the effect of self-organization is a clustering along their similarity of interest. Unfortunately, the schemes that were studied in the above papers depend on very specific models and behaviors that cannot be adapted for evaluation in our very simple model. Decentralized recommender systems and collaborative filtering schemes were proposed in [25,26]. In previous work, we implemented our ranking metrics in the context of a distributed wiki system [3] and validated them in a user study [5]. We also evaluated the merits of using a social network overlay in online rating systems [7].
Conclusion and future work
We proposed a simple model for decentralized data-sharing systems, where users are provided various means to rank documents and incentives to participate. This simple model proved useful by confirming our intuitions that a collaborative filtering approach, i.e. one where peers are recommended documents based on their similarity with other peers, performs better than a popularity-based approach where recommendations and rankings are based on the sheer number of peers who endorse a given document, or on the popularity of those peers. This in turn gives a clear and objective incentive for peers to contribute to the system by endorsing documents, since the benefit is better performance of the ranking system. In a collaborative filtering approach where peers rely on the similarity of who they follow, the result is that peers have an incentive to contribute and self-organize. The resulting topology of such rational self-organizing peers is that similar peers are grouped together, and are immune from dissimilar, and potentially malicious, peers. This reduces the need for a moderation system, which would be especially hard to implement in a decentralized setting.
For future work, the model needs to be extended to take into account the cost of contributions (production, likes, follows). Such costs should reduce the disadvantage of being a free-rider, while also providing a higher barrier for successful attacks. For example we want to study how the costs increase when an attacker wants to attack popularity- and similarity-based metrics at the same time.
We also need to try out complex adaptive strategies. Indeed, we expect that a regular user may want to initially use a strategy like document popularity to deal with the cold start problem, but to shift gradually to a peer similarity or peer distance strategy as she starts contributing and discovering like-minded peers. Similarly, producers can shift their strategies to adapt to the consumers and/or to target a particular group of consumers.