
Abstract
Recently, studies have been performed for speech emotion recognition. However, little research focused on the emotion of the elderly, especially the lonely elderly. In this paper, we propose a six layer Wavelet Packet Coefficients Model for speech emotion recognition of the Chinese elderly. Six layer Wavelet Packet Coefficients, Mel Frequency Cepstrum Coefficient and the Fourier Parameter features are extracted from speech emotion database of Chinese elderly, respectively. Experimental results show that the six layer wavelet packet coefficients features are effective for recognizing emotions from speech. In particularly, when combining these three features, the recognition rates of the elderly can be improved.
Keywords
Introduction
Social computing has a rapid development in recent years as a new interdisciplinary field of social science, management science and computational science [7,15,24]. The percentage of the elderly using social media has increased substantially in recent years [9], yet little research has been done to understand the emotion underlying social media. As we all know that the elderly, especially the lonely elderly, need to receive more attention. It is significant to do some researches for recognizing their emotions. Speech emotion recognition is an important task in understanding each other of speech in social media [16]. However, recognizing emotion from speech, especially for the elderly, is a very challenging problem [31]. Although there has a growing interest of researching speech emotion recognition [22,25,27,29,31] in the last decade, most researches focus on the children or the youth. Nowadays, researchers have established some kind of corpora such as the children emotional corpora [26], young peoples emotional corpora [6] and make some researches on these emotions. However, little research has focused on the emotional corpora of the elderly and emotion recognition of the elderly, especially of the Chinese elderly. Therefore, in this paper, we make a deep research and analysis of emotional recognition of Chinese elderly people. The following are the particularities of this paper:
We established our own speech emotion corpora of Chinese elderly, which expanded the research field of emotional topic of Chinese elderly.
We built a model of six wavelet packet coefficient for emotional speech signal.
The six layer Wavelet Packet Coefficients (WPC) [30], the Mel Frequency Cepstrum Coefficient (MFCC) [22], and the Fourier Parameter (FP) features [29] of the Chinese elderly were extracted for speech emotion recognition, respectively.
The structure of this paper is reproduced below. First, we briefly introduce the related works in this paper in section second. Then, we detail three major types of feature extraction (WPC, MFCC and FP) and the multiple feature fusion for speech emotion of Chinese elderly in section three. Then, the experimental results are discussed in the fourth section. Finally, conclusions are drawn in the fifth section.
Related work
In speech recognition research, feature extraction and selection is very important for the effect of the recognition. If the extracted features are not representative, it can’t get good recognition results. While the effective ones can achieve better effort.
At present, lots of literatures do much research on how to extract the feature parameters from the emotional speech, which mainly consider in time, amplitude, frequency and formant structure etc. In 1972, Withams [14] found that emotion has a great influence on the pitch contour. In 1981, Williams and Steven [32] summed up the different emotional states by analyzing the mechanism of speech production, the physiological role of the nervous system and the corresponding physiological response. In 1996, Dellaer [5] proposed a classification method based on pitch frequency correlation information. In 2003, Kwon [13] used SVM and HMM to recognize the speech emotion, and found that the pitch frequency and energy are affective parameters. The classification accuracy of the four kinds of emotion is 70%. In 2006 Dimitri [28] et al. found that the regional characteristics of the vocal tract have a definite influence on emotion and achieve good results. In 2010, Guven [8] et al. considered SVM as a classifier to recognize emotion on the German corpus, and the experimental results were better than those of previous studies on the basis of the extraction of prosodic features. In [10], both acoustic and lexical features were extracted for emotion recognition. Their experimental results showed that late fusion of both acoustic and lexical features achieves recognition accuracy of 69.2% for four emotions. Despite these contributions, most of the existing speech emotion recognition mainly focus on children and young people, which is rarely involved in that of the elderly.
In this paper, we propose sixth layer wavelet packet method to extract features from the Chinese elderly. MFCC and FP features are also extracted. In particular, we propose a combination of these features for speech emotion recognition. Applying the proposed methods for extracting multiple features from the speech emotion database of Chinese elderly, the recognition results of combined features are verified to be better than signal ones.
Multiple feature parameter extraction
Experimental database
In this paper, we introduce a new speech emotion database of Chinese elderly people (SECEPDB) [31]. The sampling frequency is 16 kHz, 16 bit quantization. There are a total of 480 emotional speeches signals, which are composed of 11 actors in different emotional states. It contains seven types of emotion (angry, anxiety, boredom, disgust, happy, neutral and sad). Emotional distribution of the database is shown in Fig. 1.

Distribution of emotion in SECEPDB.
Before the feature extraction, we need to preprocess the emotional speech. The transfer function of the pre emphasis process is,
Emotional feature extraction
Emotional features of WPC, MFCC and FP are extracted for speech emotion recognition of Chinese elderly people. The following is the characteristics of three emotional feature extractions.
Wavelet Transform [3] is a modern spectral analysis tools, which can study the frequency characteristics of local domain, time domain features and effects of local frequency process, so even for non-stationary process, processing and hand. Due to the orthogonal wavelet transform only low-frequency part of the signal can do further decomposition, while the high frequency part can’t do. However, wavelet packet transform can provide a finer decomposition of the high-frequency part, and this decomposition is neither redundant, nor omissions. So, signals through wavelet packet transform show better time-frequency analysis which contain a large number of middle and high frequency information. The definition of a subspace In the formula, In resolution analysis, scaling function Wavelet packet is defined as orthogonal scaling function Wavelet packet reconstruction algorithm is as Eq. (5).
Now, we study the relevance of every wavelet packet coefficient feature in speech emotion recognition of Chinese elderly people. We use Daubechies wavelet filter Db2 with 6 levels of decomposition. 64 wavelet packet coefficients are obtained in 6 levels of decomposition. Here, 6 statistical values of each wavelet packet coefficient were extracted, the WPC feature vector is comprised of amplitude, first-order difference and second-order difference. These mean, maximum, minimum, median and standard variation which led to a 5760-dimensional WPC feature vector in total.
Structure of speech emotion recognition system. MFCC was first introduced and applied to speech recognition in [4]. It has been popularly used in speech emotion recognition [2,11,12,18] too. By considering the reaction of human ears to different frequencies, the Mel frequency is determined according to the characteristics of human audition. In this study, MFCC features were extracted for comparison with the proposed WPC features. For emotion recognition, MFCC features usually include mean, maximum, minimum, median, and standard deviation. All speech signals were first filtered by a high-pass filter with a pre-emphasis coefficient of 0.97. Here, the first 12 harmonic coefficients were extracted. MFCC feature vector is comprised of amplitude, a first-order difference and second-order difference. These mean, maximum, minimum, median, and standard variation led to a 180-dimensional MFCC feature vector in total. We extracted a set of FP features from speech signals as detailed in [29]. Here, the first 120 harmonic coefficients were extracted. The FP feature vector is comprised of amplitude (H), first-order difference (

Speech emotion recognition system structure
In this paper, the structure of speech emotion recognition system is shown as Fig. 2, feature extracted from the sample data are six layer wavelet packet coefficients (WPC), Mel-Frequency Cepstral Coefficients (MFCC) and Fourier Parameter (FP). Principal Component Analysis (PCA) method [19] is used for feature dimension reductions and SVM is selected as classification. We first preprocess voice signal, and then extract the WPC, MFCC and FP speech feature, respectively. All the data sets of the extracted features are normalized. Because of the higher features dimension, we use PCA to reduce the dimension, and finally use SVM to recognize emotions [17].
Support Vector Machine
During the process of speech emotion recognition, classification process is quite important during the process of speech emotion recognition. So far, there are a variety of classification techniques used in the field of speech emotion recognition including Hidden Markov Model (HMM) [1], Gaussian Mixture Model (GMM) [20], Artificial Neutral Networks (ANN) [23], and Support Vector Machine (SVM) [17], etc. Speech emotion recognition belongs to pattern recognition problem. GMM and HMM methods require a large number of emotional speech samples in the training process of all kinds of emotion models. ANN method is limited to improve the robustness and accuracy of emotion recognition. SVM has good generalization ability because of its better solution to small sample, nonlinear and high dimensional pattern recognition problem of machine learning [17]. Many researches [10,17,29] applied SVM as classifier and achieved better performance. Therefore, We selected SVM as classifier for speech emotion recognition.
The SVM method is able to transform the sample space into a high dimension or even a dimension (Hilbert space) using a mapping function which is known as kernel function. So, in this case, it is possible to solve a Non-Linear problem in a higher dimensional space. The most common kernel functions are RBF Kernel and Gaussian Kernel. The key to solving the nonlinear separable problem is to construct the optimal classification hyperplane. The structure of the optimal hyperplane is transformed into the optimal weight and bias. Set up training samples
The limit bar is
We tried SVM classifiers for ten times cross validation [21] (training set and validation set are randomly separated each time but the ration remains the same) and computed the average values as the ultimate results of speech emotion recognition.
Speech emotion recognition based on SVM
Speech emotion recognition based on SVM
In the paper, we study seven types of emotions (angry, anxiety, boredom, disgust, happy, neutral and sad) in speech emotion database of Chinese elderly people (SECEPDB). We Extract common features such as six layer Wavelet Packet Coefficients, Fourier Parameter and the Mel Frequency Cepstrum Coefficient, and fuse them. The recognition results are shown in Table 1.
As it is shown in Table 1, the recognition rates of WPC, MFCC and FP were 73.77%, 42.55% and 71.24% respectively. The recognition rate of WPC is higher than those of MFCC and FP, which shows that the features of WPC are more suitable for the emotional recognition of the old people, and its confusion matrix of the speech emotion recognition is shown in Table 2. In addition, the recognition result of WPC + MFCC is the best, and it has a recognition rate of 79.99%. The recognition rate of WPC + MFCC is higher than WPC + FP + MFCC and WPC + MFCC. That’s to say, it is not the more features, the higher emotional recognition rate.
Table 2, Table 3 and Table 4, show the confusion matrixes of speech emotion recognition of WPC, MFCC and FP features, respectively. From the three confusion matrix, we find that the emotional recognition rates of angry and neutral emotion are higher, and those of boredom and disgust emotions are lower. In addition, we can find that angry are easier to mix with anxiety and boredom.
Average confusion matrix of WPC (%)
Average confusion matrix of WPC (%)
Average confusion matrix of MFCC (%)
Average confusion matrix of FP (%)
Figure 3 shows the performance of seven emotion types by using WPC, MFCC and FP features on the Chinese elderly databases. It is shown that recognition rates of anxiety, boredom, happy, neutral and sad are the best when using WPC features. The recognition rates of anxiety, happy and neutral emotions are higher which are 72.82%, 98.67% and 82%, respectively. In addition, the highest recognition rate is angry emotion when using FP features, which is 82.11%, and the recognition rate of angry emotion is 73.98% using MFCC features.
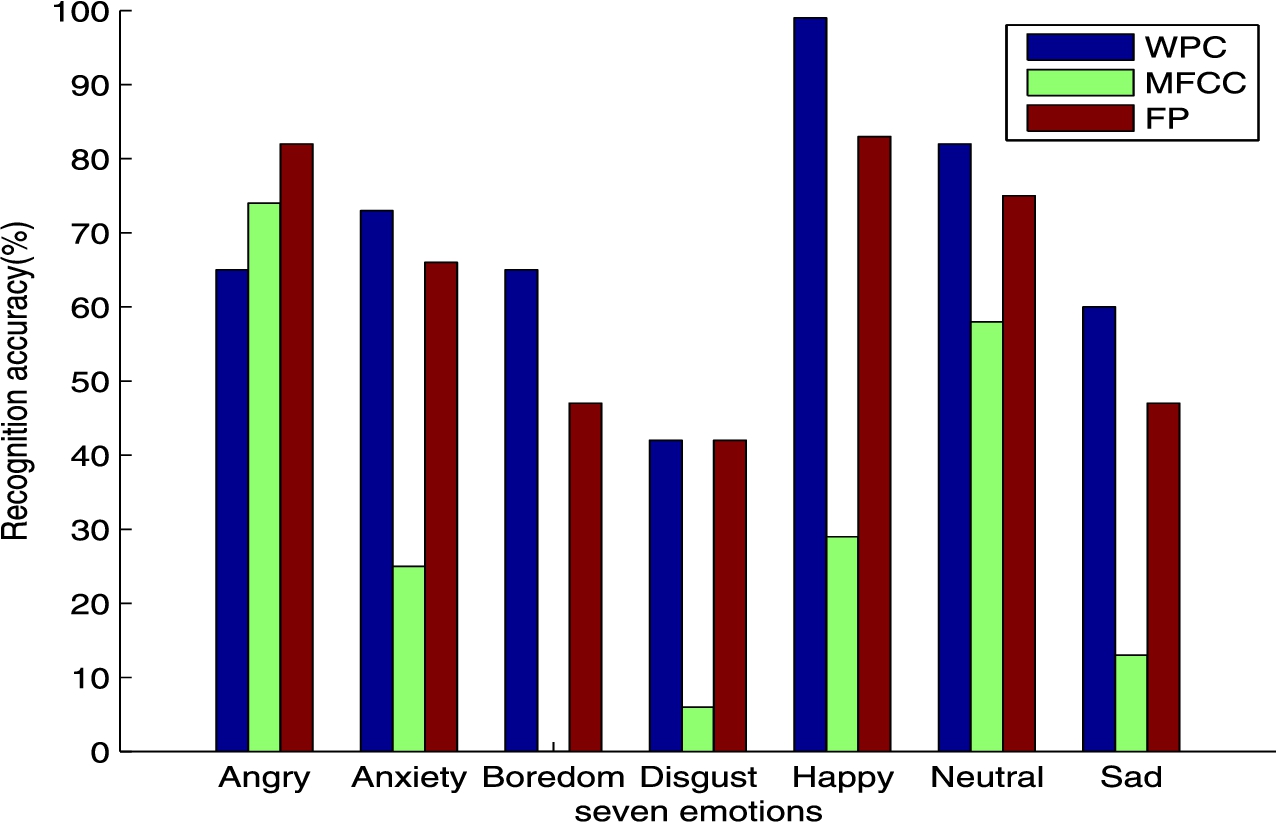
Speech emotion recognition results of different features on seven emotion.
As it is shown in Fig. 4, FP + MFCC can gain the best performance of recognition for angry emotion, WPC + MFCC can gain the best recognition rate for anxiety emotion, and WPC + FP + MFCC can gain the best recognition rate for boredom emotion. The recognition rate of happy emotion is best while that of disgust emotion is the lowest. The recognition rate of happy emotion achieves more than 98% by using WPC + FP, WPC + MFCC and WPC + FP + MFCC, respectively. The best recognition rates of neutral and sad emotion can achieve by WPC + MFCC feature set. The combination of WPC + MFCC features can get the best average performance for recognizing the emotion from the database of Chinese old people.
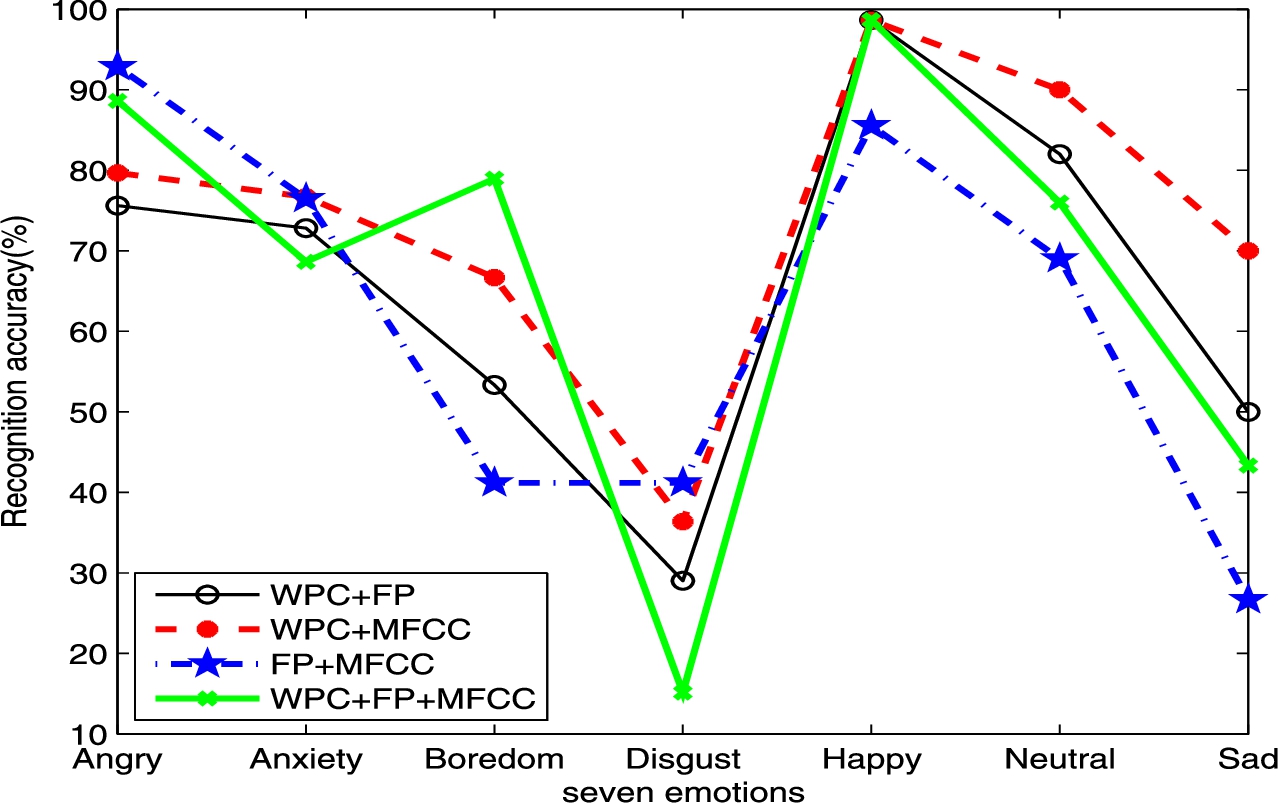
Speech emotion recognition results of different feature combination on seven emotion types.
The above is a emotional analysis for Chinese old people. We obtain different emotion recognition results according to different emotional features. In the emotional domain of the elderly, there are still many directions that need us to explore such as the emotions of the elderly for different genders, the emotions of the elderly for different regions, the emotions of the elderly for different races and etc. Here, because of the limitations of the conditions, we have only made some exploration of the emotions of the elderly for different genders in the existing database. As it is shown in Fig. 5, the effect of emotion recognition of women is generally better than that of men. On the one hand, this may be because emotional statements of older women in the database are more, on the other hand, the emotional expression of elderly women in daily life is more legible. In addition, Fig. 5 also shows that the recognition results of angry and happy emotions for elderly men are better, while those of anxiety and neutral emotions for elderly women are better. This accords with the characteristics that the emotions of men are stronger and those of women are more moderate.
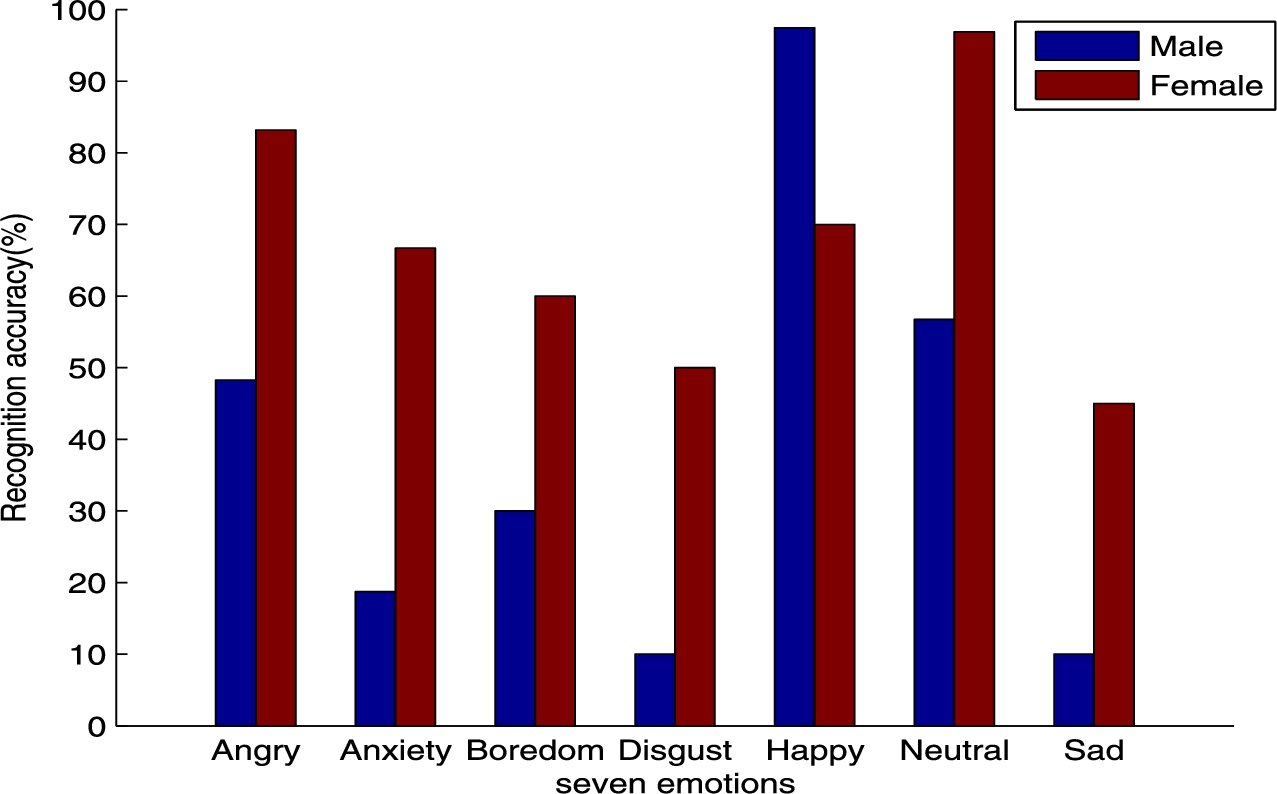
Speech emotion recognition result of different genders based on the wavelet packet coefficients of six layers.
In this paper, We proposed six layer Wavelet Packet Coefficient (WPC) features for speech emotion recognition of the Chinese elderly. Besides WPC, Mel-Frequency Cepstral Coefficients (MFCC) and Fourier Parameter (FP) were also extracted. Experimental results show that the proposed WPC features can attain better performance for emotion recognition. Furthermore, The combination of these three features can attain better performance than single feature. In the future, we will extract more and more helpful emotion features for the old peoples.
Footnotes
Acknowledgements
This work was supported by the Open Project Program of the National Laboratory of Pattern Recognition (NLPR) (No. 201700014), Anhui Provincial Natural Science Foundation (No. 1708085MF167), Fundamental Research Funds for the Key Research Program of Chongqing Science & Technology Commission (No. cstc2017rgzn-zdyf0064), the Chongqing Provincial Human Resource and Social Security Department (No. cx2017092), the Central Universities in China (No. CQU0225001104447) and the National Natural Science Foundation of China (No. 61672157). Any correspondence should be made to Kunxia Wang.