
Abstract
The ultimate goal of recommender systems is to suggest appealing items that users are interested in. Traditional recommender systems are built based on a general consensus that users’ preferences reflect their underlying interests. Therefore, various collaborative filtering techniques have been proposed to discover items that best match users’ preferences through estimating ratings for items accurately. However, determining the interestingness of items based on user preferences alone is not sufficient. In human psychology, researchers have found an important intrinsic motivation, i.e., curiosity, for seeking interestingness in social context. Instead of focusing on users’ preferences, curiosity highlights the impact of the unknown and unexpectedness on a person’s feeling of interestingness. In light of this, we propose a novel recommendation model which recommends items by taking consideration of the target users’ curiosity in addition to their personal preferences. To model user curiosity, we adopt a psychologically inspired approach and transpose Berlyne’s theory of curiosity into a computational process. Three key curiosity-stimulating factors, including surprise, uncertainty and conflict, are modelled to estimate user’s curiosity for each item. The proposed recommendation model is evaluated with two large-scale real world datasets and the experimental results highlight that the consideration of social curiosity significantly improves recommendation precision, coverage and diversity.
Introduction
With the rapid development of the Internet, the information available online has become overwhelming for the vast majority of the Internet users, which is generally known as the information overload problem [24]. To cope with this problem, recommender systems have been developed to provide users with recommendations of useful online information. They are gaining increasing popularity in recent years as they have shown superiority in allowing users to filter through an enormous number of items and in helping businesses increase their sales. Recommender systems have been successfully adopted by a number of influential companies, including Amazon, Yahoo!News, Apple iTunes, Facebook and so on.
The ultimate goal of recommender systems is to suggest users with particularly interesting items, in addition to indicating those that should be filtered out [28]. Traditional recommender systems attempt to achieve this goal by discovering items that best match users’ preferences. Accordingly, various Collaborative Filtering (CF) techniques have been proposed for discovering such items, through estimating ratings for items accurately [11]. However, determining interestingness based on user preferences alone may not be sufficient. For example, traditional recommender systems tend to recommend popular items, due to the wide usage of similarity measures in collaborative filtering [2]. However, it is highly possible that users have already learnt about those popular items from multiple sources, e.g., advertisements, news, or their friends. Hence, recommending those items may not interest users as they already knew them. Even though these items match the users’ preferences (with high estimated ratings), the users still lack the motivation to explore.
In order to build a recommendation model that is able to predict interesting items for the users, a good understanding on the factors impacting humans’ interest in some particular items is necessary. According to the psychological study of interest, the appraisal of interestingness in human beings is closely related to curiosity, which is an intrinsic motivation driving explorative behaviours [33]. Curiosity is not generally centred around a person’s preferences but is more focused on the unknown and unexpectedness in the environment [41]. For example, in real life, we often get curious about the surprising behaviors of our friends. If a friend who hates horror movies suddenly gave good comments to a horror one, we are likely to be surprised by the friend’s rating behaviour and become curious about the movie. Alternatively, our curiosity may be aroused due to the feeling of uncertainty when our friends offer greatly varied opinions about a movie. This phenomenon is generally known as social curiosity [27], which is the desire to acquire new information about how other people behave, think, and feel. In light of this, we take a new angle to look at the interestingness of recommendations and introduce social curiosity as a novel dimension of information into recommender systems. To the best of our knowledge, we are the first group to work in this direction.
In order to model user curiosity in the context of social recommendation, we follow Berlyne’s theory of curiosity from psychology. Berlyne [5] interprets curiosity as a process of stimulus selection, which means that curiosity can be stimulated externally by stimuli with certain properties. These properties are characterized by a set of variables, including surprise, uncertainty and conflict, etc. Specifically, surprise arises when a person’s expectation is violated; uncertainty arises when a person has difficulty selecting a response to a stimulus; and conflict occurs when a stimulus arouses two or more incompatible responses in a person. We transpose this psychological theory of curiosity into a computational process and determine the value of surprise, uncertainty and conflict for each item. Note that the modeling of surprise and uncertainty has been evaluated in our previous works [39,40], respectively. In this work, Fuzzy Logic [35] is adopted to combine all of the three different sources of stimulation for estimating user curiosity. The interestingness of an item is then evaluated based on both user curiosity and user preference, wherein Weighted Borda Count [8] is adopted to consolidate user curiosity with user preference for producing the final personalized ranking of items.
We explore the impact of social curiosity on personalized ranking of recommended items using three important dimensions of evaluations, including precision, coverage and diversity. More specifically, precision evaluates the ability of a recommender system to recommend items that users will likely to explore [6]; coverage reflects the ability of a recommender system to recommend long-tail items [11]; and diversity measures the ability of a recommender system to recommend idiosyncratic items [7]. To evaluate the performance of our proposed model on these metrics, we conduct extensive experiments on two large-scale real world datasets, i.e., Douban [24] and Flixster [14] with both user-item rating information and social network knowledge (i.e., the friend relationships). The experimental results highlight that the incorporation of social curiosity significantly improves performance on all three metrics, i.e., precision, coverage, and diversity, in comparison to the state-of-the-art methods.
The remaining of the paper is organized as follows: Section 2 discusses the related works to this research from three different perspectives. Section 3 introduces the proposed social curiosity inspired recommendation model in detail. Section 4 presents the experiments with two large-scale real world datasets and discusses the experimental results. Finally, the conclusions are drawn in Section 5.
Related work
In this section, we review existing works related to this research in three aspects: (1) traditional versus social recommendation techniques, (2) accuracy versus metrics beyond accuracy, and (3) computational curiosity.
Traditional vs. social recommendation
Traditional recommender systems usually make use of the user-item rating information for recommendation. One popular idea is Collaborative Filtering (CF), which recommends items based on the similarities between users or items. CF approaches can be classified into two main categories: heuristics-based approaches and model-based approaches. Heuristics-based approaches utilize the ratings of similar users or items to generate predictions, which can be further categorized into user-based [10] and item-based [21] approaches. In contrast, model-based approaches use the observed ratings to train a predictive model, typically through statistical or machine-learning methods, which is then used to predict unknown ratings. One of the model-based approaches, Matrix Factorization, has recently gained popularity in recommender system applications due to high recommendation accuracy and efficiency in dealing with large-scale user-item rating matrices [38].
In real life, we often get recommendations from our friends. However, traditional recommender systems omit the abundant social information among users. With the recent prevalence of social network augmented sites, such as Epinions and Douban, more and more attention has been paid to social recommendations. Recent research in social recommendation utilizes the social relationships among users to improve the recommendation accuracy [14,24,25,34]. Social recommendation approaches can also be classified into heuristics-based approaches and model-based approaches. Heuristics-based approaches usually measure the similarity between two users using the degree of social trust [25]. It is shown to increase the number of predictable ratings without decreasing the overall accuracy. Model-based approaches usually make use of social information to constrain the matrix factorization objective function. In [24], Ma et al. propose social regularization terms to enhance the performance of the matrix factorization algorithm on recommendation accuracy.
Existing social recommendation methods mainly consider two types of social information: trust [25] and friend taste similarity [24]. However, the abundant social information is not limited to these two aspects. In our previous works [39,40], we have introduced another interesting dimension of social information that may impact the performance of a recommender system: social curiosity. Social curiosity focuses on the unknown and unexpectedness in the social contexts, which is closely related to a person’s appraisal of interestingness [33]. We specifically use social information to model surprise [40], uncertainty [39], and combines surprise or uncertainty with user preferences to get users’ interest for the items in order to make recommendations accordingly.
Accuracy vs. metrics beyond accuracy
Typical recommender systems attempt to estimate ratings of items accurately based on users’ rating history. Accordingly, most researchers focus on improving the recommender systems’ prediction accuracy [3,18,22]. However, accuracy alone may not be sufficient to meet users’ satisfaction and hence, in recent years, researchers have shown growing interest in studying other metrics beyond accuracy [11].
Many studies have pointed out that one of the goals of recommender systems is to provide users with highly idiosyncratic or personalized items [2,7,46,48]. With this goal in mind, a lot of works have been proposed to increase the diversity of recommendation lists, usually measured by the dissimilarity between all pairs of recommended items while maintaining an acceptable level of accuracy. Ziegler et al. [48] propose a topic diversification method to balance and diversify personalized recommendation lists in order to reflect users’ complete spectrum of interest. Zhang and Hurley [46] treat the goal of maximizing the diversity of the recommendation lists while maintaining an adequate level of similarity to the user’s query as a binary optimization problem and explore a solution strategy to this optimization problem by relaxing it to a trust-region problem. Accuracy in many cases grows with the amount of data available. However, when there are huge amounts of data, many algorithms can provide recommendations with high quality, but only for a small portion of the items [11]. In other words, many long-tail items that users may also be interested in can never be recommended. To address this issue, a lot of works have been proposed to improve recommendation coverage, which refers to the percentage of items for which a recommender system is able to generate recommendations [9]. Lekakos and Caravelas [20] use a hybrid approach which combines content-based filtering with collaborative filtering to enhance coverage in a movie recommendation system. Sieg et al. [32] propose a recommendation method with ontology-based user profiles to enhance recommendation coverage. Adomavicius and Kwon [1] propose a set of ranking-based techniques that can generate broader recommendations across all users.
Recent research also shows growing popularity in studying other factors such as novelty and serendipity for recommender systems [13,17,31]. Novel recommendations are usually defined as recommendations of items that are interesting but unknown to the users [10]. In [12], the system explicitly asks users what items they already know to derive novel recommendations in a collaborative filtering framework. Weng et al. [37] adopt taxonomy-based topic detection methods to improve the novelty and quality of recommendations. However, novelty only emphasizes the fact that an item is unknown; it does not consider items that are known but unexpected [1]. Serendipity introduces the concept of unexpectedness and measures how surprising the recommendations are [31]. Iaquinta et al. [13] enhance serendipity in a content-based recommender system by recommending items whose description is semantically far from users’ profiles. Kawamae [17] estimates the surprise of each user when presented recommendations by predicting their purchasing trend based on the purchase history of users with similar preferences. However, the concepts of novelty and serendipity only consider the information with respect to a person’s own historical ratings. They do not consider the rating information in a broader social context, which is the focus of our work.
Computational curiosity
In psychology, curiosity is commonly recognized as a critical motivation associated with exploratory behaviors such as exploration, investigation and learning. It is an intrinsic drive towards novelty and interestingness [41]. According to Kashdan [16], curiosity benefits human beings at two levels: at the individual level, curiosity drives personal growth, as an innate love for learning; at the social level, curiosity promotes interpersonal relationships, through infusing passion into social interactions.
Motivated as above, researchers have shown growing interests in modeling a “curious” mechanism similar to human beings in artificial beings, in order to bring about the “curious” effect. Schmidhumber models artificial curiosity in reinforcement learning framework to speed up agent learning and to build unsupervised developmental robotics [30]. Oudeyer et al. develop a curiosity mechanism for robots, which acts as intrinsic motivation to motivate robots to explore into regions with new knowledge [26]. Saunders and Gero develop a curious design agent that can arrange art exhibits to elicit the curiosity of their viewers and provide them with an aesthetically pleasing experience [29]. Wu et al. model curiosity for various types of application agents such as virtual learning companions [42,44], game companions [45] and extreme learning machine classifiers [43], and show positive impact of curiosity on both agents’ and human users’ learning behaviors. A survey on computational curiosity is available in [41].
Although computational curiosity has been widely studied in various applications, it has not been explored for the social recommendation task. By considering social curiosity in a recommender system, we will better predict a user’s interests and recommend items more meaningfully. In this work, we introduce social curiosity as a novel dimension of social information for recommendation tasks and study its impact on the recommendation results through various evaluation criteria, including precision, diversity and coverage.
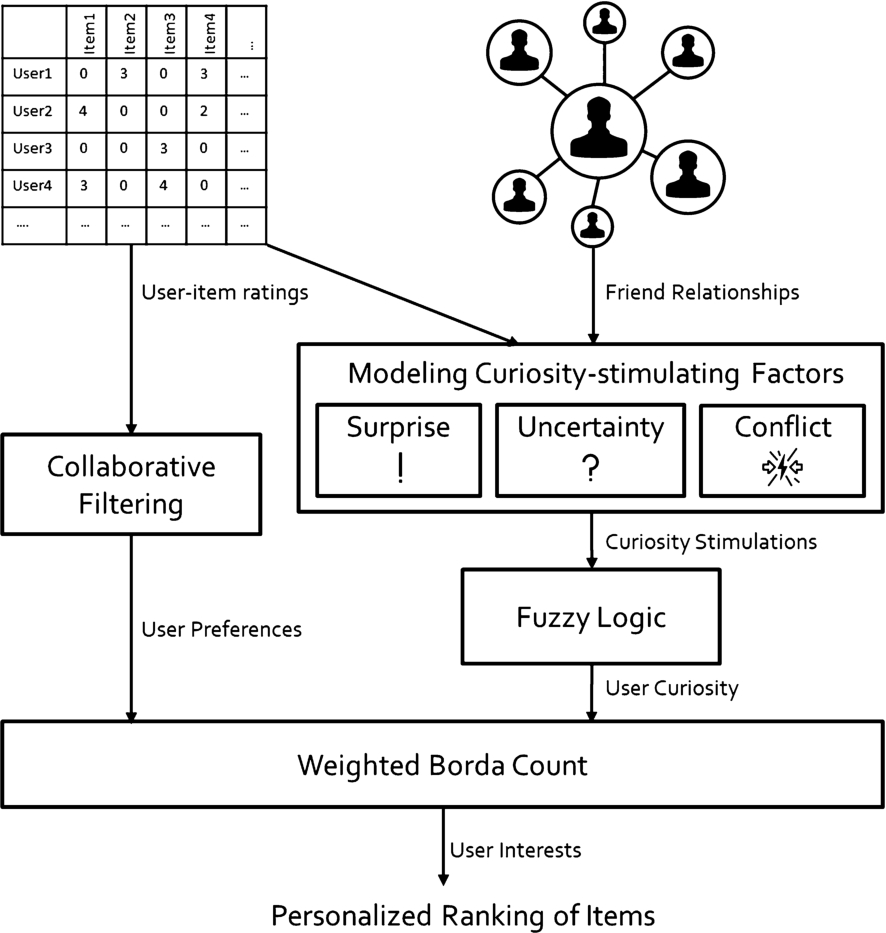
Overview of the proposed recommendation model.
An overview of the proposed recommendation model is shown in Fig. 1. This model takes two inputs: users’ historical ratings for items and their friend relationships. Firstly, user preferences are evaluated based on their historical ratings using collaborative filtering. User preferences are estimated as the predicted rating scores for unexperienced items. Secondly, user curiosity is evaluated based on users’ own historical ratings and their friends’ ratings (supported by friend relationships). To estimate user curiosity, three curiosity-stimulating factors, i.e., surprise, uncertainty and conflict, are evaluated to generate curiosity-stimulating scores, which are then combined to generate curiosity scores for unexperienced items using Fuzzy Logic [35]. Thirdly, user interests are evaluated by consolidating user preferences with user curiosity through weighted Borda count [8]. Finally, personalized ranking of items are recommended to users based on the descending order of interest scores.
User preferences: Predicted rating score
As reviewed in Section 2.1, various recommendation methods have been proposed to predict user preferences for unexperienced items, e.g., neighborhood based collaborative filtering [10] and matrix factorization [19,23]. In this work, we adopt the Matrix Factorization (MF) method for measuring user preferences, due to its high recommendation accuracy and its efficiency when dealing with large-scale user-item rating matrices. It should be noted that our model could use a different prediction method, if such a method would yield a more accurate result. In other words, our model is not dependent on MF.
The basic MF model maps both users and items to a joint latent factor space of dimensionality d, such that user-item interactions are modelled as inner products in that space. Accordingly, each user u is associated with a vector
The preference of target user u towards an unexperienced item i is measured by a predicted rating score, denoted by
The values in
Here, γ is the learning rate and λ is a regularization parameter to minimize overfitting. The algorithm iterates until an accuracy threshold is reached.
User curiosity: Curiosity score
In this section, we will first introduce the modeling of the three key curiosity-stimulating factors, i.e., surprise, uncertainty and conflict and then discuss a Fuzzy Logic based method for combining the three different sources of stimulation to generate the estimation of user curiosity for unexperienced items.
Surprise
Surprise, arising when an expectation is violated, is one of the key factors that stimulate curiosity [5]. This can be readily applied to the social recommendation context: a friend’s unexpected rating behaviours create a feeling of surprise, which may then lead to curiosity. For example, if Alice knows that her friend Bob hates horror movies, the incidence of Bob giving a high rating to a horror movie (e.g., House of wax) will likely catch Alice’s attention. In order to find out why Bob gave this surprising rating, Alice may become curious to watch this horror movie. Putting this generally, a user u will be surprised if a friend v’s rating for an item i significantly differs from u’s expectation of v’s preference towards i. Hence, surprise could be modelled as the difference between a friend’s observed rating for an item and the target user’s expectation of the friend’s rating for that item.
The target user’s expectation of a friend’s preference towards an item can be estimated by the predicted rating
In this work, we focus on the surprises from directly linked friends. In social network, most users have many friends and it is possible that multiple friends give surprising ratings for the same item. Hence, to model the target user’s surprise, two issues should be addressed: (1) how to model a user’s responses to the surprising ratings of different friends and (2) how to evaluate a user’s surprise when multiple friends give surprising ratings to the same item.
To address the first issue, we propose a surprise correlation between two users who are mutual friends, denoted by
To address the second issue, we propose the following strategy for evaluating the target user’s surprise towards an item i, denoted by the surprise score
Uncertainty
In social recommendation context, a user’s feeling of uncertainty is often elicited by the variety of ratings given by his/her friends. This kind of uncertainty can be modelled by Shannon entropy [4]. Specifically, suppose a user u has a finite set of friends
According to Shannon entropy, u’s feeling of uncertainty for item i due to the diverse ratings provided by u’s friends is given by:
A higher value of
A lower value of
Therefore,
Conflict
Uncertainty evaluates the variety of ratings given by friends for a movie through observing the rating distribution over all rating scales. Conflict, on the other hand, evaluates the variety of ratings given by friends for a movie through the amount of variations among those ratings. For example, assume movie i received ratings of 1 and 5 from two friends and movie j received ratings of 3 and 4 from two friends, according to Eq. (11), the uncertainty scores for i and j are equal. However, it can be seen that friends’ dispute for i is much higher than j since the ratings given for i is more polarized.
We use standard deviation of friends’ ratings to model their conflict. In statistics, standard deviation is used to quantify the amount of variation or dispersion of a set of values, which captures the variety of ratings among friends. Hence, we define the conflict score
Curiosity
We have modelled three curiosity-stimulating factors, i.e., surprise, uncertainty and conflict. In this section, the three curiosity-stimulating factors are combined to estimate a user’s curiosity for an item. As curiosity is a psychological concept, determining the contributing weight for each curiosity-stimulating factor is not a simple task. We propose to use Fuzzy Logic to estimate curiosity from the three sources of stimulation, as Fuzzy Logic has the advantage of incorporating human knowledge into the machine inference process, by allowing human to define a set of fuzzy rules that are understandable to both human and machines. For example, a fuzzy rule is given as follows: IF the surprise is HIGH AND the uncertainty is HIGH AND the conflict is HIGH, THEN the curiosity of the user is VERY HIGH. With a set of such rules, the fuzzy inference system can make fairly reasonable inference without a precise description of the real world.
A typical Fuzzy Logic system with fuzzifier and defuzzifier is shown in Fig. 2. Firstly, a crisp (real-valued) input value x is transformed into fuzzy sets in the input space X through a fuzzifier. Then, based on predefined rules, the fuzzy inference engine transforms the fuzzy sets in X into fuzzy sets in the output space Y, which are eventually transformed into a crisp output y through the defuzzifier.
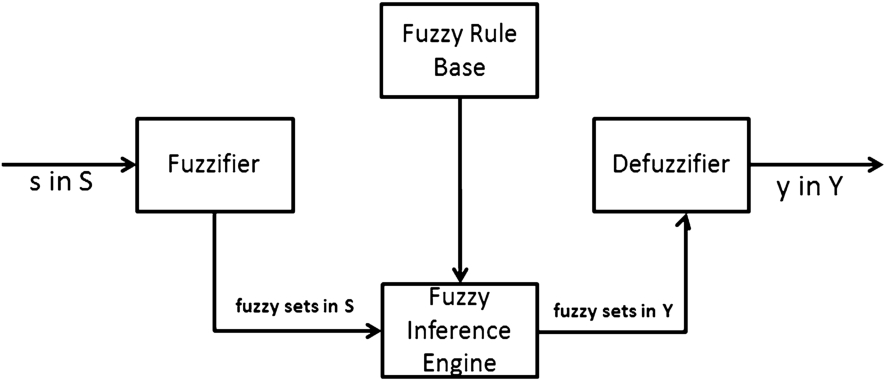
Fuzzy logic system with fuzzifier and defuzzifier [36].
Fuzzy Logic system is adopted in this work to estimate user’s curiosity for an unexperienced item using the three sources of stimulation. Therefore, the input for the fuzzy logic system is represented by a 3-tuple, denoted as
For a Fuzzy Logic system to work, firstly, we need to define the fuzzy sets in the input and output space. Each fuzzy set is associated with a Membership Function (MF), which describes how much a real-value input belongs to a fuzzy set. Currently, each
The output y, representing curiosity in our case, is associated with 5 fuzzy sets: very low (VL), low (L), medium (M), high (H), and very high (VH). The corresponding Gaussian MFs for the 5 fuzzy sets are as follows:
Next, we need to define the rules following which the Fuzzy Logic system makes inference. We currently define 27 rules as shown in Table 1. Each combination of
Fuzzy inference rules
Once the fuzzy sets and rules are defined, the fuzzy logic system works as follows. Firstly, the fuzzy logic system receives a real-valued input
Then, the product fuzzy inference engine is equipped to infer the output fuzzy set
Finally, the widely used center average defuzzifier is adopted to transform the output fuzzy set
A highly curiosity-stimulating item may not finally elicit a user’s interest unless the user is in favor of that item to some extent. For example, a user who is scared to watch horror movies may be indifferent to a horror movie no matter how surprisingly discussed among his/her friends. Hence, it is necessary to generate a recommendation list that consolidates both users’ preference and curiosity.
To reflect both user preference and user curiosity in the recommendation lists, we assume two voters, one ranking items solely based on user preference and the other ranking items solely based on user curiosity. Then, we adopt a weighted Borda count [8], a classic election method, to combine the rankings provided by the two voters. Specifically, suppose there are n items that have not been experienced by the target user u.
A weighted sum of
Experiments
In this section, we evaluate the proposed social curiosity inspired recommendation model using two large-scale real world datasets in comparison with the state-of-the-art methods.
Datasets
For our experiments, we use two popular publicly available large-scale datasets: Douban [24] and Flixster [14]. Both datasets include user-item ratings as well as the social network connecting users. The statistics of the two datasets are summarized in Table 2.
Statistics of the datasets
Statistics of the datasets
Douban is a Chinese website for providing ratings for movies, books and music (integer rating scale from 1 to 5). We use the Douban movie dataset published in [24]. This dataset contains 129,490 unique users, 58,541 unique movies and 16,830,839 ratings. The friend network contains 1,692,952 undirected friend links between users. In this dataset, each user gives an average of 129.98 ratings and each item receives 287.51 ratings on average. The average number of friends per user is 13.07.
Flixster is an English website for providing ratings for movies (integer rating scale from 1 to 5). The Flixster dataset was published in [14]. This dataset contains 1,049,508 unique users, 66,726 unique movies and 8,196,077 ratings. The friend network contains 7,058,819 undirected friend links between users. We preprocessed the Flixster dataset by removing the large portion of users who have social relations but no expressed ratings because our algorithm is interested in friends’ rating behaviors. After preprocessing, the Flixster dataset contains 147,612 unique users, 66,726 unique movies and 8,196,077 movie ratings. The total number of undirected friend links between users is 2,538,640. In the processed dataset, the average number of ratings given per user is 55.52 and the average number of ratings received per item is 122.83. The average number of friends per user in the social network is 17.20.
To evaluate the ability of the proposed method on recommending interesting items, we focus on studying the properties of the personalized ranking of recommended items. More specifically, we adopt precision, coverage, and diversity for evaluation. The definition for each metric is given below.
Precision evaluates the ability of a recommender system to recommend items that users will explore, which is defined as the percentage of top-N items that have observed rating in the testing set [6]. Here, a historical rating for an item can be treated as an evidence showing that the user indeed got interested to explore the item [47]. A higher precision indicates a higher chance that the user will explore the recommended items and finally give ratings for them. Therefore, precision can reflect to what extent the recommended items interest the user. Precision of a recommendation list is given by
Coverage is defined as the percentage of items in the database that is covered by the top-N recommendations for all the target users. It is a system-level measure that reflects the ability of a recommender system on recommending those long-tail items [11]. Coverage is also known as the aggregate diversity [1], given by:
Diversity is defined as the average dissimilarity between all pairs of the top-N items [7]. Let
Methods and parameter settings
In the experiments, the following methods are compared, including the baseline MF method [38], the ranking methods [2], and the social curiosity method proposed in this work, which are explained as below:
Parameters of Gaussian MFs
Parameters of Gaussian MFs
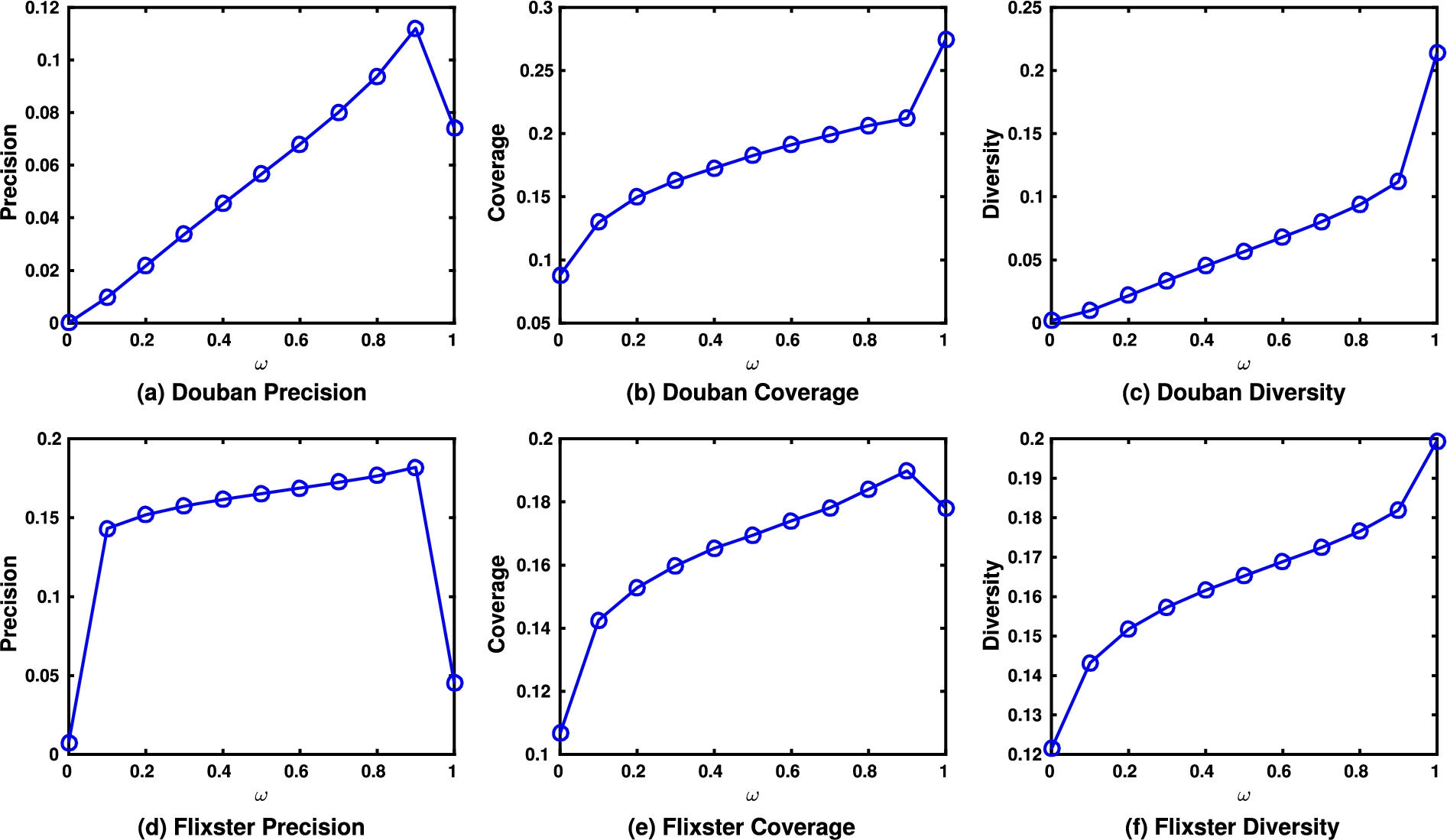
Impact of ω on the performance of
For the MF parameters, we set the learning rate γ to 0.001, the regularization parameter λ to 0.02, and the latent factor dimension d to 10. For the ranking methods, the ranking threshold
In this experiment, we empirically study the impact of the weight ω for Borda count on the performance of the proposed method
The experimental results are shown in Fig. 3. It can be observed from Fig. 3 that the best performing ω differs for different metrics. Taking the Douban dataset for example (Fig. 3(a)(b)(c)), the best performing ω for precision is 0.9, while for coverage and diversity is 1. This means that the impacts of curiosity on the three metrics are not equally strong. For Douban dataset, curiosity has a strong impact on coverage and diversity as its value increases monotonously when ω increases. In contrast, the trend for precision first climbs upwards and then goes downwards, which means that the best performing values could only be achieved when there is a balanced consideration between user preferences and user curiosity. Based on the above observations, in the following experiments, we report the results by the best performing ω.
Performance comparison with the state-of-the-art methods
Performance comparison with the state-of-the-art methods
In this experiment, we compare the performance of the proposed curiosity inspired recommendation model with the state-of-the-art methods in terms of precision, coverage and diversity. The results are shown in Table 4, wherein the best performing values are highlighted in bold.
From Table 4, we can observe that the proposed social curiosity inspired method
Impact of friend degree
As the proposed method is closely related to the behavior of the target user’s friends, it is worth analyzing the impact of the number of friends, i.e., friend degree, on the recommendation results. In our experiments, we separate users into 6 degree groups: the first group consists of users with degrees from 1 to 20, the second group from 21 to 40, the third group from 41 to 60, the fourth group from 61 to 80, the fifth group from 81 to 100, and the sixth group above 100. We do not continue dividing users with degree above 100 into groups because users with degree above 120 represent less than 1% of the total number of users in the dataset. Since the number of users decreases in larger degree groups, to make the comparisons fair, we randomly select 1000 users from each degree group to report the coverage value.
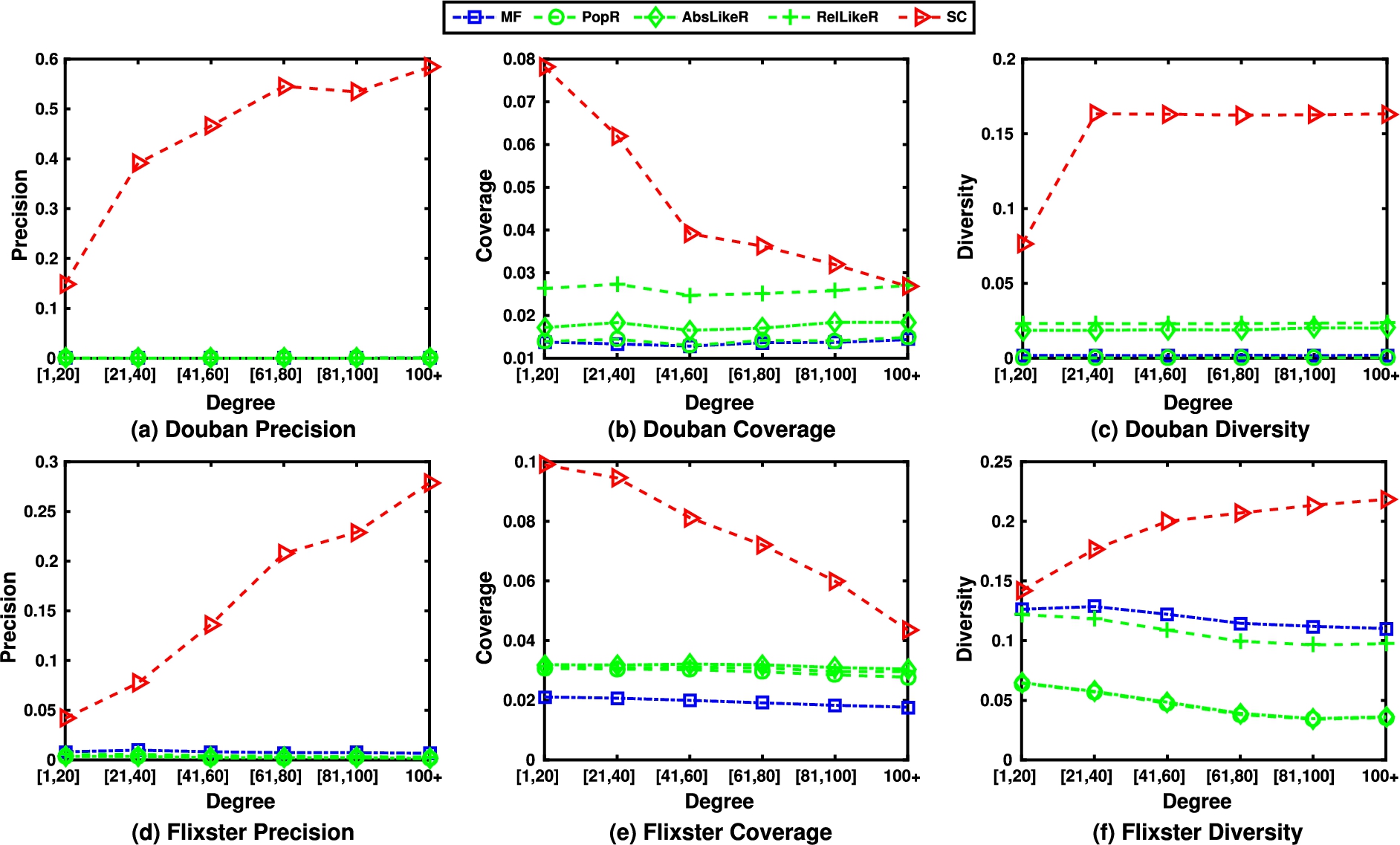
Impact of friend degree on algorithm performance.
The experimental results are shown in Fig. 4. It can be observed from Fig. 4 that the social curiosity methods consistently outperform all the other methods in terms of all the three evaluation metrics across all the degree groups for both datasets. It confirms the superior performance of the social curiosity methods on recommending interesting items that users may want to explore and finally give ratings to. It can be clearly seen from Fig. 4(d) that the ranking methods even perform worse than the baseline method for precision in Flixster dataset. By comparing Fig. 4(c) and 4(f), it can be also seen that the performance of ranking methods on diversity depends on the datasets being used. For example, the
Let us analyze the impact of friend degree. It can be observed from Fig. 4(a)(c)(d)(f) that there is a general increasing trend for the precision and diversity of
The experimental results empirically show that the proposed approach remarkably enhance recommendation precision, coverage and diversity. From an intuitive point of view, the proposed approach can achieve such improvements because it not only relies on the similarity information as commonly adopted by traditional recommendation techniques but also considers the social curiosity information for recommendation. The incorporation of such curiosity information makes the items that elicit the user’s interests rather than the ones best match the user’s usual preferences be ranked at top.
This paper first highlighted the importance for recommender systems to recommend interesting items that are able to elicit users’ motivation to explore. Traditional recommender systems did not consider user motivation when making recommendations and thus may recommend items that matches users’ preferences but may not be interesting enough to motivate them to explore. In this work, we study the interestingness of recommendations through the lens of social curiosity, an intrinsic motivation that drives human beings to actively explore in a social environment. We proposed a recommendation model that evaluates the interestingness of an item through the combination of both users’ personal preferences and their social curiosity. To achieve this goal, we proposed a novel computational model for estimating user curiosity, by modeling three curiosity-stimulating factors, including surprise, uncertainty and conflict. The experimental results highlighted that the proposed recommendation model significantly enhances precision, coverage and diversity in comparison with other state-of-the-art methods.
For future work, we plan to study the impact of data sparsity on the performance of the proposed social curiosity inspired recommendation model. As data sparsity may lead to inaccurate rating predictions, it may then affect the accuracy of our curiosity estimation model. To investigate the impact of social curiosity on cold start problem is another possible direction. For cold start problem, as there is little information available to predict users’ interest, social curiosity can be an important source to make recommendations for new users to a system.
Footnotes
Acknowledgements
This research is supported by the National Research Foundation, Prime Minister’s Office, Singapore under its IDM Futures Funding Initiative. This research is also partially supported by the NTU-PKU Joint Research Institute, a collaboration between Nanyang Technological University and Peking University that is sponsored by a donation from the Ng Teng Fong Charitable Foundation.