
Abstract
Current crowdsourcing platforms such as Amazon Mechanical Turk provide an attractive solution for processing numerous tasks at a low cost. The number of workers who process crowdsourcing tasks is increasing along with the expansion of domains in which crowdsourcing is utilized. However, there is insufficient support for crowdsourcing workers, such as education and improvement of their work environment. This problem may be due to crowdsourcing workers being numerous and unspecified, which also makes them easy to employ and terminate. Poor worker management could lead to declining quality of worker records and unjustified worker termination. In this study, we propose a grade-based training method for workers. Our training method utilizes probabilistic networks to estimate correlations between tasks based on worker records for 18.5 million tasks, then allocates pre-learning tasks to workers to raise the accuracy of target tasks according to task correlations. In an experiment, the method automatically allocated 31 pre-learning task categories for 9 target task categories, and after pre-learning task training, we confirmed that target task accuracy increased by 7.8 points on average. This result was comparatively higher than those for pre-learning tasks allocated using other methods, such as decision trees. We therefore confirmed that task correlations can be estimated from a large number of worker records, and that these are useful for grade-based training of low-quality workers.
Introduction
Crowdsourcing is an outsourcing service in which many tasks are processed by many unspecified people, and it is used in various domains such as analyzing and compiling large datasets. The number of workers who process crowdsourcing tasks is increasing along with the expansion of domains in which crowdsourcing is utilized. Therefore, the way in which work is performed in crowdsourcing is expected to become common practice. However, there is insufficient support for crowdsourcing workers, such as education and improvement of their work environment. This problem may be due to crowdsourcing workers being numerous and unspecified, which also makes them easy to employ and terminate. Poor worker management could lead to declining quality of worker records and unjustified termination of workers. Some crowdsourcing workers have demanded improved work environments through organizations such as DYNAMO [19].
Education may appear to be an effective means of minimizing unjustified dismissal of workers. If workers produce high-quality task results, requesters have no need to terminate workers. However, education for crowdsourcing workers is subject to several problems. For example, it is difficult to individually educate numerous and unspecified workers. In addition, personalized education for crowdsourcing workers undermines the merits of microtask crowdsourcing, such as low cost and rapidity.
We propose a grade-based training method for educating microtask crowdsourcing workers based on the method proposed in [24]. In this method, workers process appropriate pre-learning tasks prior to processing difficult tasks to improve their skill. Pre-learning task allocation is performed by analyzing correlations between tasks and worker records using a Bayesian network. However, worker control and task allocation methods in existing crowdsourcing services are insufficient for development of a grade-based training method, so it is difficult for them to incorporate new training method mechanisms. We therefore developed the Private Crowdsourcing System (PCSS) [3]. PCSS has been in operation since 2011. There are currently 2454 PCSS workers, and the system has processed 18.5 million tasks.
The main contribution of this paper is its proposal of a set of methods for improving result quality without requiring requester knowledge. Our system improves result quality by educating workers without unjustified termination.
The remainder of this paper is organized as follows. Section 2 reviews existing research on machine-learning methods for education and crowdsourcing. Section 3 shows the importance of a grade-based training method for crowdsourcing workers. Section 4 discusses the advantages of creating grade-based pre-learning tasks. Section 5 presents our conclusions and comments on future directions for this research.
Related work
Many machine-learning methods for education have been proposed in the literature. These methods can be classified into three categories: (1-1) research on the influence of learning methods on students, (1-2) estimations of factors in student records from student status, and (1-3) classification of student methods to produce learning plans.
Research on the influence of the learning method on students includes: estimating the influence of a learning test [28], estimating the influence of the learning pattern of students [10], estimating and comparing the influence of the many learning methods and graphically presenting their correlations [9].
Estimation of the cause of students’ record from the students’ status includes: estimating the socioeconomic index from the students’ learning status [15] and estimating the students’ lifestyle from the students’ family status and income [11].
Classifying the students’ methods in order to produce a learning plan includes: Classifying students by the students’ skill [2,17].
Furthermore, the intelligent tutoring system (ITS) proposed by Ueno [24] is a computer system that aims to provide learners with immediate and customized instruction or feedback, usually without intervention from a human teacher. ITS is very useful for grade-based training methods, and can be used for many purposes, such as computer programming [7].
PCSS regards workers as students. Its grade training methods correspond to category (1-2) because PCSS estimates influences on worker quality from worker records.
Many machine-learning methods for crowdsourcing have been proposed in the literature. These methods can be classified into four categories: (2-1) classifying workers by worker records, (2-2) obtaining final task results by merging partial task results, (2-3) classifying task results, and (2-4) estimating the quality and difficulty of task design from task results.
Classifying workers by workers’ records include: classifying workers by a worker’s quality [16,20,25,27], finding low-quality workers by analyzing the workers’ records [26], ranking workers’ methods and scoring workers’ methods from the workers’ records [6,18,20], and estimating the most suitable reward from workers’ records [29].
Obtaining the final task by merging several task results includes: methods of merging many task results from many workers [8,13,22,23] and merging the labels from workers’ tweets and sentences in SNS by calculating the rate of concordance [21].
Classifying task results includes: classifying task results from many workers [5,12,23].
Estimating the quality and difficulty of task design from the task results includes: creating a task difficulty model from a worker’s quality and skill [4] and estimating the task quality from workers’ error rates.
Thus, there has been a considerable amount of research on machine-learning methods for education and crowdsourcing. However, there is currently a lack of research on improving worker quality by applying machine-learning methods to analyze worker records, such as in our research. Methods for excluding low-quality workers are very popular, but poor management of workers can lead to their unjustified termination because the way in which crowdsourcing work is performed is expected to become common practice.
The grade-based training method
Worker education is very important because attempts to process difficult tasks with no preparation are difficult for low-quality or inexperienced workers. Many people start training with tasks that are easier than the target tasks. The efficacy of grade-based training methods has been demonstrated in school education. We therefore propose a method for upgrading worker skill by using pre-learning tasks allocated in stages.
School education involves teachers who can create perfect educational plans from a wide range of resources according to the purpose of study. Teachers can furthermore create a cohesive curriculum based on their students’ accumulated educational experience. Created curricula are studied by many students and can be improved using their feedback.
However, such grade-based training methods are costly. It is difficult to automatically create subjects and curricula in a crowdsourcing system because the tasks vary and there are many unspecified workers. Creating subjects and curricula is furthermore costly for both the task requester and system manager. Crowdsourcing systems therefore typically utilize only basic training and simple explanations of tasks. Our proposed method emulates experienced teachers in that it creates task categories according to task goals and contents, and allocates tasks by analyzing individual worker records.
The proposed method automatically allocates pre-learning tasks by re-using existing tasks. If workers processing task A before task B are superior to workers who do not, task A can be defined as a pre-learning task for task B. Accordingly, to upgrade workers’ task B skill, the system allocates task A to workers before they process task B. We implemented the proposed method in PCSS because it is difficult to implement grade-based training methods in existing public crowdsourcing systems.
The ITS proposed by Ueno [24] is a computer system that aims to provide learners with immediate and customized instruction or feedback, usually without human intervention. ITS is very useful for grade-based training methods and is used for many purposes, such as computer programming [7].
Methods for representing learner models in ITS using a predicate logic representation have been popular for many years. However, a predicate logic representation has some problems, such as difficulty in handling exceptions to rules and inconsistent worker records. For example, in the case of a rule that a worker who archives correct results in a ‘spell checking’ task can archive correct results in a ‘put phonetics data to words’ task, there are workers who cannot archive correct results in a ‘spell checking’ task but can archive correct results in a ‘put phonetics data to words’ task. This is attributable to careless mistakes and guesswork. However, these cases often arise in microtask crowdsourcing. A stochastic method, such as a Bayesian network can treat such exceptions to rules and inconsistent worker records. A Bayesian network is a probabilistic network model that represents a set of random variables and their conditional dependencies with a task network. PCSS analyzes correlations between task categories using Bayesian networks.
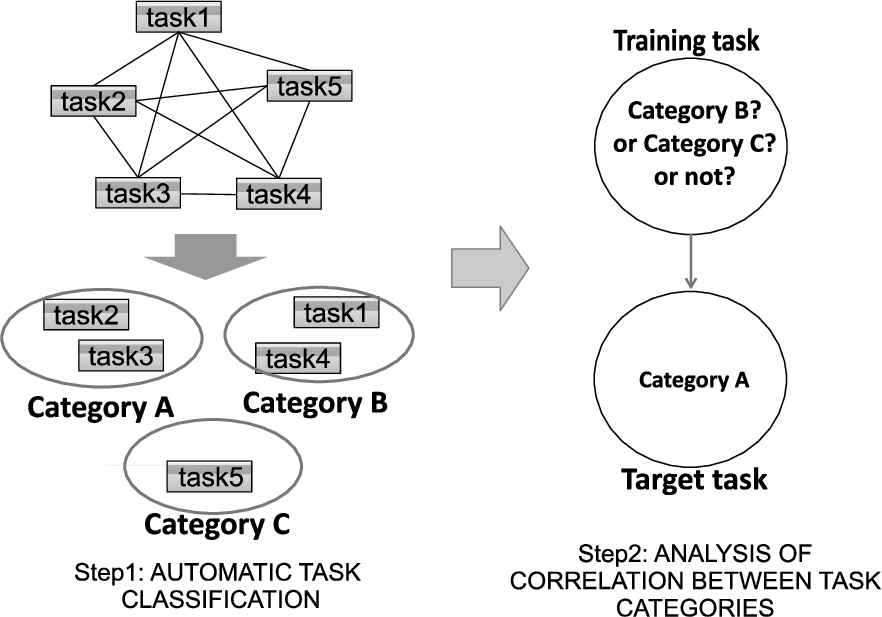
Steps for allocating pre-learning task categories.
To allocate pre-learning tasks by reusing existing tasks, it is necessary to analyze the correlations between tasks. However, because PCSS has many tasks, the analysis of each task is costly in terms of both time and calculation. In the method of representing a learner model in ITS with a Bayesian network [24], the nodes of the network are defined manually. We thus propose a method that creates the nodes of the network automatically and then verifies the network using the workers’ records collected since 2011 in PCSS. First, PCSS automatically classifies tasks to task categories and then allocates pre-learning tasks by analyzing correlations between task categories using Bayesian networks as shown in Fig. 1.
PCSS requesters set a group of tasks of the same kind when registering. The task groups in PCSS have titles and descriptions described by requesters. The system manager checks titles and descriptions. In the case that an error exists in titles and descriptions, the system manager requests that requesters make a revision. PCSS calculates the tf-idf of each task group using keywords extracted from the title and description using morphological analysis.
PCSS calculated 17.2 million patterns of the cosine similarity between 4153 task groups of 18.5 million tasks in total. In order to check the accuracy of the calculated cosine similarity, we manually checked task similarities by randomly selecting task group pairs from a fixed range of cosine similarity. There were 76 dissimilar task group pairs in 100 pairs with a cosine similarity of 0 or more and less than 0.1; there were 35 dissimilar task group pairs in 100 pairs with a cosine similarity of 0.1 or more and less than 0.2; there were 9 dissimilar task group pairs in 100 pairs with a cosine similarity of 0.2 or more and less than 0.3; there were 4 dissimilar task group pairs in 100 pairs with a cosine similarity of 0.3 or more and less than 0.4; and all task pairs are similar in 100 pairs with a cosine similarity of 0.4 or more.Thus, we classified task groups with a cosine similarity of 0.4 or more into the same task category in the following experiment. As a result, PCSS classified 4153 task groups from 18.5 million tasks into 138 task categories.
11 tasks for which all calculated cosine similarities were under 0.4 do not have similar tasks. PCSS excluded these 11 tasks.
Step 2: Analysis of correlation between task categories
To allocate pre-learning tasks using existing task categories, PCSS analyzed task correlation between task categories.
The Bayesian network is used for learning and inferencing. For example, a network such as that shown in Fig. 2 can be created from Bayesian network learning. In the figure, task A influences task B and task B and C influence task D. Therefore, if the workers processing tasks B and C before task D are superior to the workers who do not, task B and C can be defined as pre-learning tasks for task D. Accordingly, in order to upgrade the workers’ skill for task D, the system allocates tasks B and C to workers before processing task D.
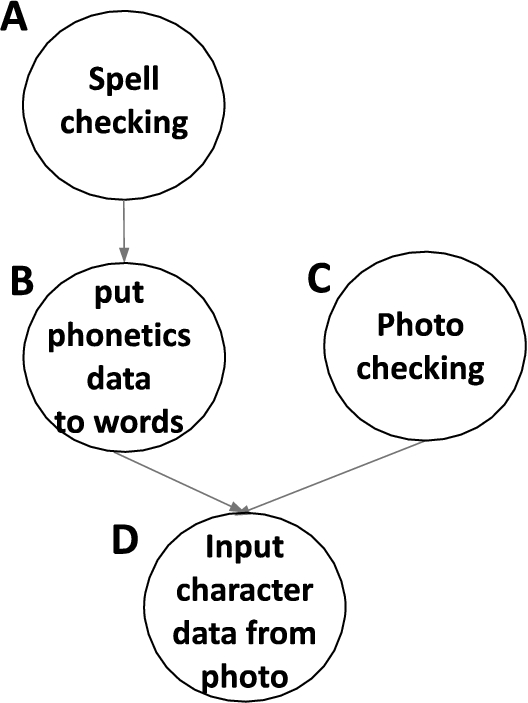
Example of a network in PCSS.
Task categories of low quality
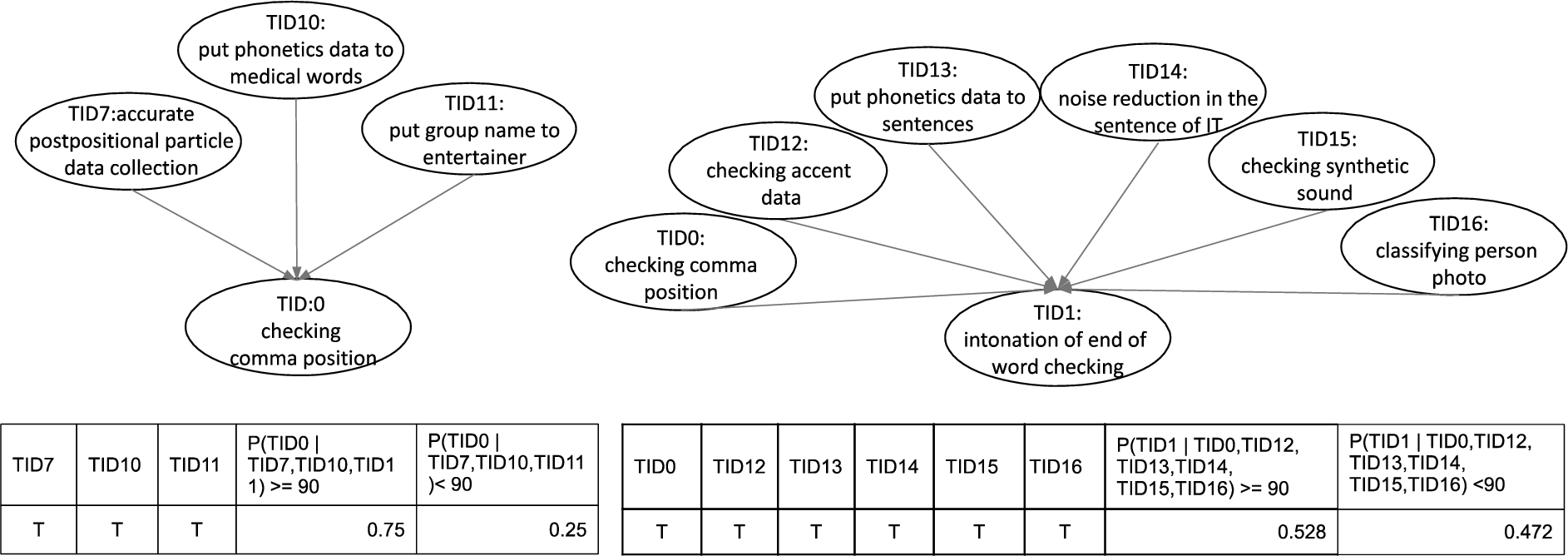
Directed acyclic graph for target task categories.
For example, in order to find a pre-learning task for task A, PCSS calculates the probability
If
In order to use a Bayesian network in crowdsourcing, PCSS calculates the average accuracy of workers’ records in each task category as described in Sect. 3.2. The Bayesian network learns from the calculated average accuracy and creates a probabilistic task network. We selected task categories for which upgrading of the accuracy of workers’ records was required. The target task categories are listed in Table 1 in ascending order of accuracy.
Target task categories and pre-learning task categories
As a result, we created task networks for all target tasks. Some of the networks are shown in Fig. 3. This figure shows the task networks for Task Category ID (TID) 0: ‘checking comma position’ and TID1: ‘checking intonation of end of word’. The created task network shows the correlations between target task categories and pre-learning task categories. The network on the left in Fig. 3 shows that a worker who processed TID7: ‘accurate postpositional particle data collection’, TID10: ‘put phonetics data to medical words’ and TID11: ‘put group name to entertainer’ can process TID0 with high accuracy. In this case, task B corresponds to TID7, TID10 and TID11. Therefore, the network on the left in Fig. 3 shows that PCSS can handle these three tasks as pre-learning tasks for TID0. The created networks have multiple stories. Target task categories and pre-learning task categories are shown in Table 2. In this paper, we used task categories that had a direct influence (link) on the target task category. In PCSS, workers, who processed less than 50 tasks in a task category are regarded as workers, who have not processed the task category.
In the present work, we used Waikato Environment for Knowledge Analysis1
Parameters of simulated annealing
For comparison, we also allocated pre-learning tasks using decision tree. The decision tree method divides data into subsets by finding the most effective attribute and its threshold. When allocating the pre-learning tasks using a decision tree, PCSS first creates a decision tree for target task category A, and then finds the upper nodes as the pre-learning tasks. The decision tree method creates tree-classifying tasks at each junction node, and thus allocates the task to effectively classify target task A as the upper nodes. For example, if workers, who processed task category B with more than 90% accuracy processed target task category A with high accuracy as in Fig. 4, task category B is regarded as a pre-learning task for task category A. The decision tree was created using J48 algorithm without binary splitting. The confidence threshold for pruning is 0.25, the minimum number of instances per leaf is 2, and the number of hierarchies is not limited.
The correlations between the target task category and the pre-learning task obtained by Bayesian networks and decision trees are shown in Table 2.
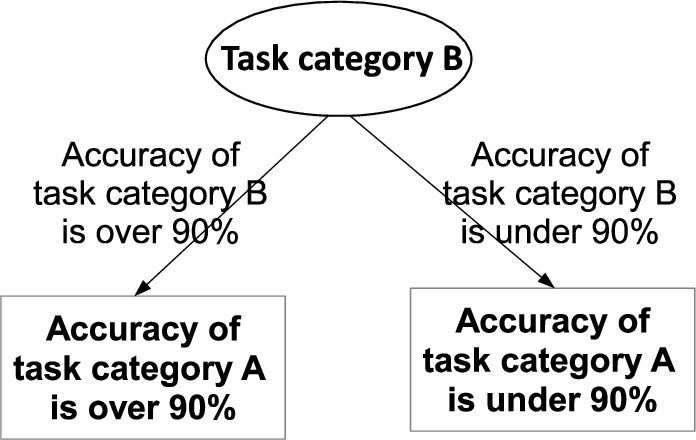
Example of a decision tree for the task category A.
Checking the effectiveness of the grade-based training.
Evaluation method
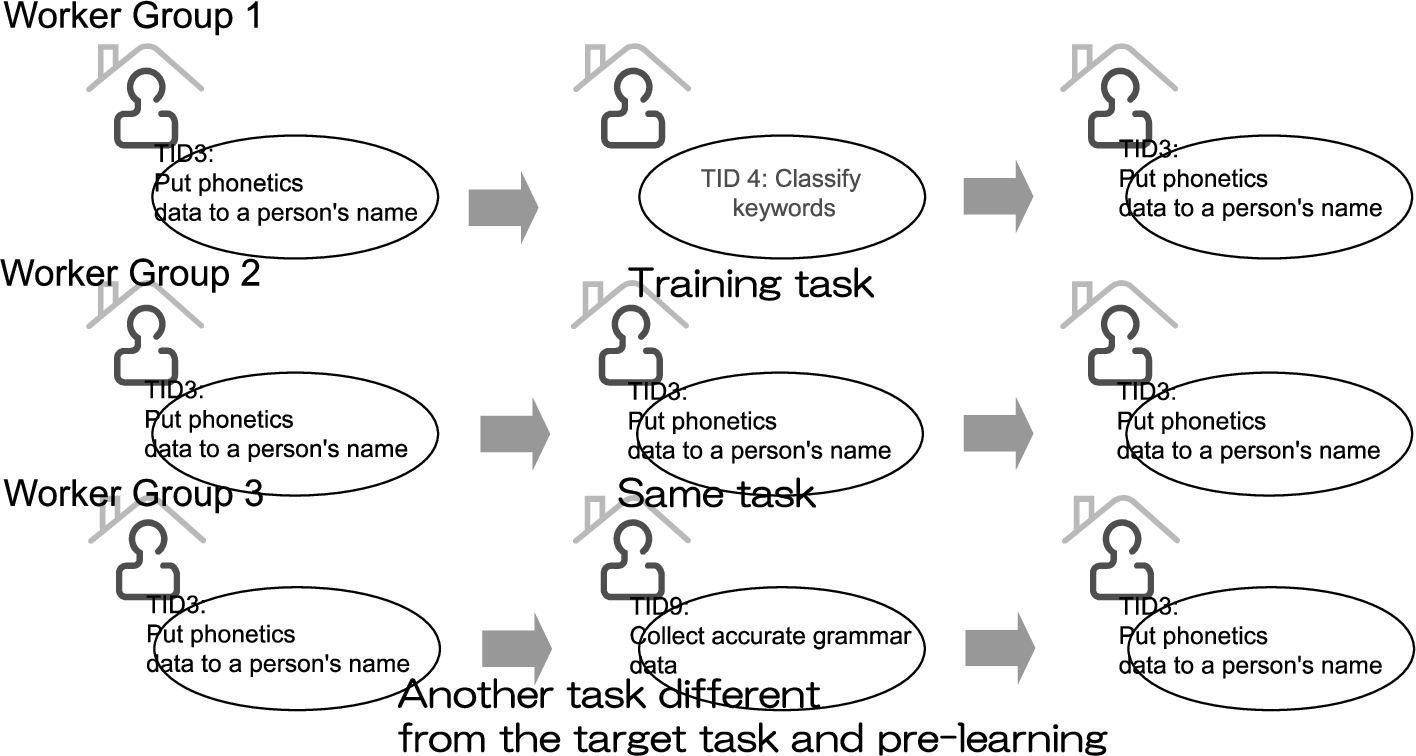
In order to check the effectiveness of the task network, we tested target task TID0: ‘checking comma position’, TID1: ‘checking intonation of end of word’, TID2: ‘checking conversation’, TID3: ‘put phonetics data to person’s name’ and TID4: ‘classifying keywords’ as follows:
Assign 50 tasks from a target task category to check the initial accuracy of all workers. The workers, who had more than 60%, but less than 90% accuracy participated in the following experiment, because PCSS excludes any worker whose accuracy rate for target tasks is under 60% from processing target tasks [3] and the workers who had more than 90% are already high quality. Workers who processed a target task in (1) are grouped into the following three groups: Worker group 1 processes 10 tasks in each pre-learning task category. Worker group 2 processes other tasks in the target task category. The number of tasks is 10 × the number of pre-learning task categories compared with (a). Worker group 3 processes tasks in task categories different from the target task and pre-learning categories. The number of task is 10 × the number of pre-learning task categories compared with (a). Reassign 50 tasks in the same target task category to the workers who are trained by the above to check the improvement of the accuracy. Repeat 3 times from (2) to (3). Compare the accuracy of the workers’ records in (1) and the accuracy of the final records in (3). The workers are prohibited from executing any other tasks during the experiment.
These evaluation methods are shown in Fig. 5. These evaluated tasks are selected from the top of Table 1. The 5-task limit is attributable to budget restrictions. The workers in the evaluation are paid at the same rate as for normal tasks to ensure fairness. Moreover, task allocation is controlled to compel the workers to process the evaluation tasks.
Effect of pre-learning task from Bayesian network
Effect of pre-learning task from Bayesian network
Effect of pre-learning task from decision tree

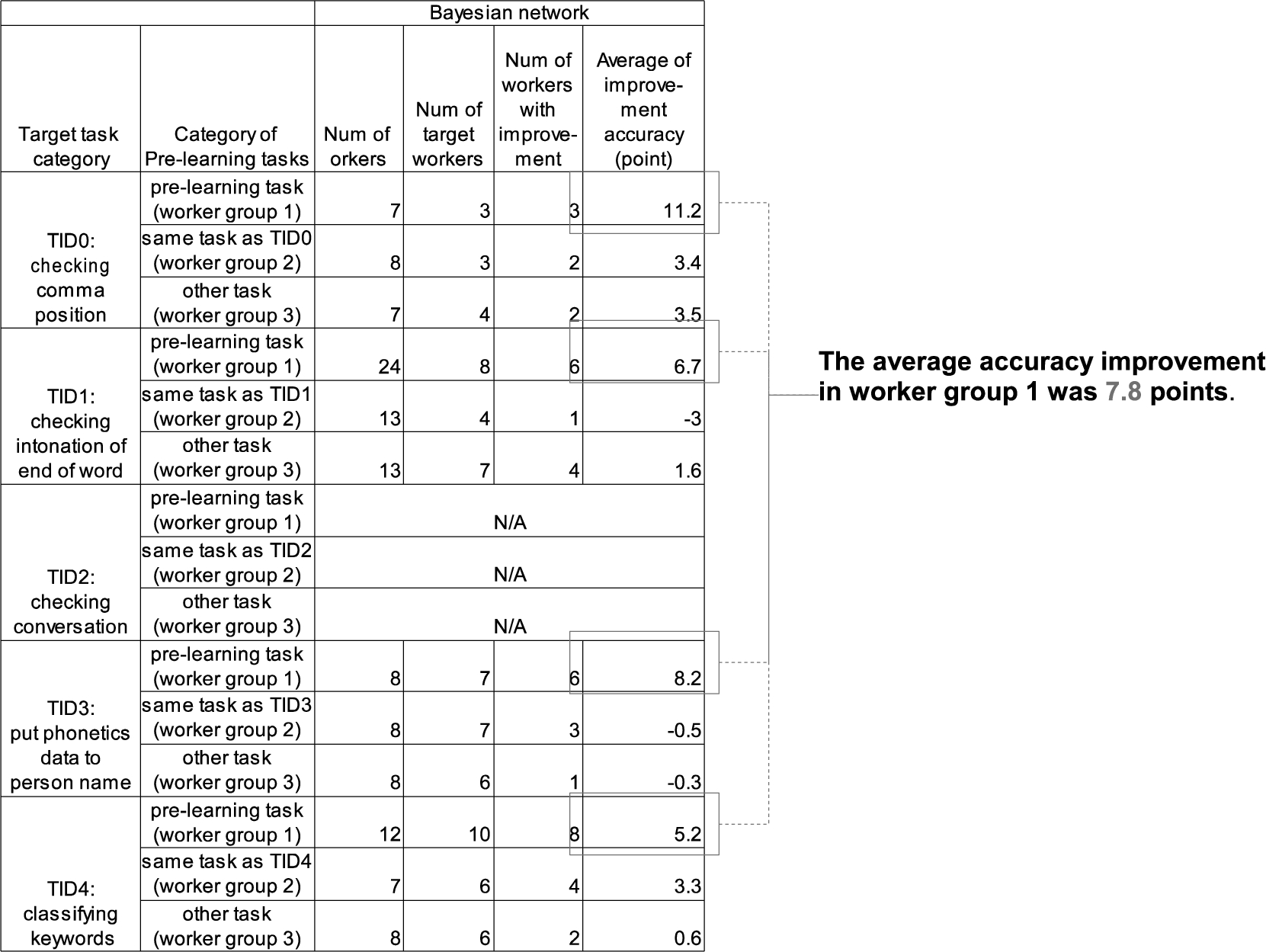
The results of the experiment are shown in Table 4. In this experiment, 40 workers selected from all workers randomly are allocated to each worker group. However, some workers did not process target task categories for certain reasons. ‘Num of workers’ in Table 4 is the number of workers who process the target task category in 40 workers. ‘Num of target workers’ in Table 4 is the number of workers who had more than 60%, but less than 90% accuracy in ‘Num of workers’ in Table 4. In addition, target workers did not process any tasks more than target task categories.
In the case of Bayesian networks, accuracy improvement in worker group 1 was 11.2 points in the case of TID0, 6.7 points in the case of TID1, 8.2 points in the case of TID3, and 5.2 points in the case of TID4. The accuracy is calculated by majority vote. Points in Table 4 indicate incremental difference in accuracy. For example, in the case that 80% accuracy increased to 90% accuracy, the accuracy improvement is 10 points. The average accuracy improvement in worker group 1 was 7.8 points. The average accuracy improvement shown in Table 4 (7.8 points) is the average of improvement accuracy in worker group 1 using the Bayesian network result (
In order to check the statistical significance of the grade-based training method in crowdsourcing, we analyzed the Bayesian network result in Table 4 with the chi-square test is shown in Table 6. The
Discussion
The results of this evaluation show that pre-learning tasks automatically allocated by Bayesian networks effectively improve worker development and thus accuracy in micro-task crowdsourcing.
In order to analyze task category
In this evaluation, nodes of decision tree for task category
Statistical analysis with chi-square test
Statistical analysis with chi-square test

The relation between tasks.
A decision tree classifies target task category A and other task categories by workers’ records. If there are many workers, who have high accuracy for task A and task B, task category A and the task category including task B are classified into the same class, and the node for task B is located at the upper node in a tree as a pre-learning task. However, the above means that the class
Moreover, a decision tree method deterministically classifies influential factors. However, the workers’ records includes a large number of abnormal or biased values attributable to by workers’ careless mistakes and guesswork. These also reduced the accuracy compared with the probabilistic approach.
Furthermore, this experiment only uses task categories, which directly influence target task category, as pre-learning task categories. For example, task categories B and C are allocated as pre-learning task categories for target task category D in Fig. 2. In contrast, task category A is not allocated as a pre-learning task, because task category A has weaker influence than task categories B and C. Evaluation of the grade-based training method using all influential task categories is a subject for future work.
In addition, there is a possibility of a case that a target task category becomes a pre-learning task in a directed acyclic graph. We speculate that this case is the same as that of worker group 2 in Table 4. Evaluation of this case is a subject for future work, because this case has not been generated yet.
Some pre-learning task categories appear to be irrelevant to target task categories. However, target task categories and pre-learning task categories have certain attributes in common, e.g., task design and knowledge.
The ideal pre-learning task is easier than the target task category and requires knowledge that is a subset of the target task. However, the cost of creating the perfect pre-learning task is very high. Many target tasks do not have ideal pre-learning tasks, because many calculated pre-learning tasks contain imperfect knowledge of their respective target task categories. In this paper, we confirmed the benefit of low-cost education for workers that utilizes imperfect knowledge of the target task category.
For example, ‘TID4: classifying keywords’, ‘TID11: put group name to entertainer’ and ‘TID14: noise reduction in the sentence of IT’ are good pre-learning tasks for ‘TID3: put phonetics data to a person’s name’ because both TID4 and TID3 require knowledge of Japanese grammar, both TID11 and TID3 require knowledge of entertainers and both TID14 and TID3 require knowledge of the latest news about current trends. These relations are shown in Fig. 6. And ‘TID17: checking accent data of idiom’ is a good pre-learning task for ‘TID4: classifying keywords’ because both TID4 and TID17 require knowledge of Japanese grammar. This knowledge is higher than that required for speaking Japanese. Additionally, TID17 involves judging whether accent data are correct or incorrect, but TID4 involves selecting a correct word class from many options. Thus, TID17 is easier than TID4. Therefore, TID17 was selected as a pre-learning task for TID4.
In addition, many pre-learning task categories and target task categories have interface and task design in common. For example, TID0 and TID7 have an interface for selecting from Japanese grammar candidates, TID1 and ‘TID12: checking accent data’ have an interface for selecting correct sounds from some sounds heard, TID3 and TID11 have an interface for inputting Japanese names, and TID4 and TID17 have an interface for selecting correct data.
In this way, the task relations that were automatically created can be semantically explained with specific domain expertise. In intelligent tutoring systems, experts tailor these relations, but to achieve scale in the crowdsourcing system we tried to probabilistically connect the tasks and evaluated them.
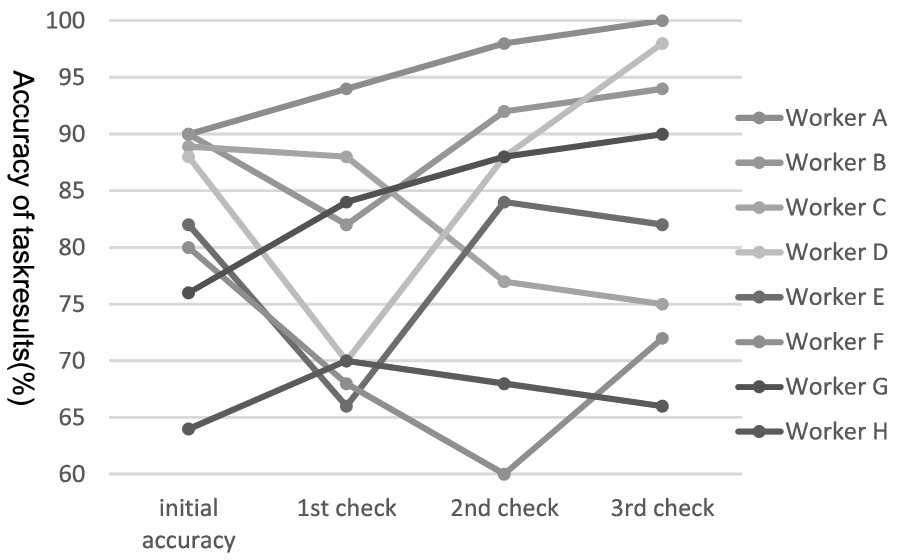
The workers growth patterns in ID1 (in the case of pre-learning task ID1).
Task categories that may be detrimental
Effect of task categories that may be detrimental
In addition, the reduction of worker motivation leads to deterioration in the quality of workers’ records. Worker motivation is controlled by the reward and interest associated with task contents [14]. Since workers could not perform other tasks during this experiment, fluctuations in performance may be attributable to boredom associated with the repeated tests. Development of an experiment that maintains workers’ interest is a subject for future work.
The workers’ performance has several patterns as shown in Fig. 7. Those are classified into the following four patterns: (1) Continuous improvement (worker A, G), (2) fluctuation with eventual improvement (worker B, D, E, H), (3) fluctuation with eventual deterioration (worker F), and (4) Continuous deterioration (worker C). A grade-based training method is regarded as effective, since the total number of workers categorized as (1) and (2) is greater than the total number of workers categorized as (3) and (4). For example, in the case of TID1, the total number of workers categorized as (1) and (2) (6 persons) is greater than the total number of workers categorized as (3) and (4) (2 persons). We conjecture that individual worker profiles may affect these patterns. Development of a pre-learning task method that uses the worker profiles is a subject for future work.
In this experiment, the task network was created from all target task categories. However, for the target task category TID2, we could not obtain a pre-learning task, since the target task category is located at the top of the network. In our previous work [3], only two networks were created for target task categories. The difference between the current work and previous work is the number of processed tasks. That of the previous work is 50 task categories of 882 task groups including 7 million tasks, and that of the current work is 138 task categories of 4153 task groups including 18.5 million tasks. Hence, the volume of tasks obviously influences the allocation of pre-learning tasks.
In this paper, we propose that if the workers processing task A before task B are superior to the workers who do not process task A before task B, task A can be defined as a pre-learning task for task B. On the other hand, we speculate if the workers processing task A before task B are inferior to the workers who do not process task A before task B, task A has a bad influence on the workers. In order to verify this case, we created directed acyclic graph for TID0, TID1 and TID2 in Table 2. In these directed acyclic graphs,
Finally, pre-learning tasks are allocated in accordance with worker records. However, worker records change with grade training. Thus, PCSS must frequently analyze worker records to appropriately allocate pre-learning tasks, but this imposes high calculation costs. Research on worker training according to changes in worker skill is a subject for future work.
In this paper, we proposed a grade-based training method for PCSS. PCSS automatically allocates pre-learning tasks.
Worker skills for the target task are upgraded by processing pre-learning tasks before assigning the target task. PCSS first classifies tasks into task categories by comparing task similarity, then obtains those tasks that influence the target task as pre-learning tasks by calculating task correlations using a probabilistic approach. To evaluate the effectiveness of the proposed grade-based training, we created a task network from 138 task categories. The results showed that the pre-learning tasks improved performance accuracy for target tasks by 7.8 points on average.
However, pre-learning tasks did not improve the accuracy of some low-quality workers with task motivation and concentration problems. Game mechanics provide rules and methods for effectively controlling user motivation [1]. The development of a method combining grade-based training methods with game mechanics is a subject for future work.
As mentioned, the scope of this work was limited to data analysis in natural language processing, such as voice recognition, voice synthesis, and conversation systems. Exploration of other domains is a subject for future work.