
Abstract
Chinese couplets, as one of the traditional Chinese culture, is the treasure of Chinese civilization and the inheritance of Chinese history. Given a sentence (namely an antecedent clause), people reply with another sentence (namely a subsequent clause) equal in length. Because of the complexity of the semantic and grammatical rules of couplet, it is not easy to create a suitable couplet that meets the requirements of sentence pattern, context, and flatness. With the development of neural models and natural language processing, automatic generation of Chinese couplets has drawn significant attention due to its artistic and cultural value, most of these works mainly focus on generating couplet by given text information, while visual inspirations for couplet generation have been rarely explored. In this paper, we design a Chinese couplet generation model based on NIC (Neural Image Caption), which can compose a piece of couplet suitable to the artistic conception in an image. At first, we use the improved VGG16 model to predict the input image. The content of the image can be automatically recognized and the corresponding description are generated and translated into Chinese keywords. Then, the encoder-decoder framework is used repeatedly to process these keywords, and finally the couplet can be generated. Moreover, to satisfy special characteristics of couplets, we incorporate the attention mechanism into the encoding-decoding process, which greatly improves the accuracy of couplets generated automatically.
Introduction
The Chinese couplet is also called “Duizi”. It consists of two sentences which are identical in form and interrelated in meaning. The first sentence is called “antecedent clause”, which is put up or hung on the right side of the door, and the other is called “subsequent clause” which is placed on the left side. Not only are the two sentences required to have an equal number of characters, but also the words standing in the same position in each of the two sentences must be antithetic in form and harmonious in tone. Besides, these two antithetic clauses should be relevant in content and express similar meanings. Otherwise, they are not counted as a qualified couplet or even not counted as a couplet.
Chinese couplets can be inspired by many things, among which vision (and images) is certainly a major source. Indeed, in Chinese traditional culture, people prefer to use ancient poems or couplets to express their feelings, which is called ‘Lyric Expression Through Scenery’. As shown in Fig. 1, we illustrate a traditional Chinese couplet that fits with the artistic content of the image and translate the couplet into English character-by-character. We mark the character-wise translation under each Chinese character of the couplet so as to illustrate that each character from the same position of the two clauses has the constraint of certain relatedness. In this couplet, “clear” is paired with “bright”, “spring” is associated with “moon”, and “rock” is coupled with “pine”. Besides, the implied meaning of both clauses is consistent. The antecedent clause of this couplet describes the scenery that a bright moon is shining between the pine branches. Accordingly, the subsequent clause of the couplet shows the picture that the spring water is flowing over rocks.

A Chinese couplet illustrates an image.
Generating couplet from image is a special task of text generation from image. With the recent advances in neural models and natural language processing [4,5,24], there have been many studies in this area. However, most of them focus on image captioning rather than literature creation. Visual inspirations for couplet generation have been rarely explored. There have also many studies and systems for automatic couplet generation [11,13,14]. In most cases, a system is provided with a few keywords and is required to compose a couplet containing or relating to these keywords. In comparison with couplet generation from keywords, generating couplet from images is much more challenging than generating it from text, since images contain very rich visual information and a good couplet should convey the image accurately. Besides, compared with asking users for providing keywords, uploading an image is a much simpler and more nature way to interact with a system nowadays.
In this paper, we propose an encoder-decoder framework to generate Chinese couplet from images, which integrates direct visual information with semantic topic information in the form of keywords extracted from images. We consider couplet generation as a sequence-to-sequence learning problem. Our method is based on an attention-based recurrent neural network, which accepts a set of keywords as the theme and generates couplet by looking at each keyword during the generation.
Generating natural language descriptions from visual data has long been studied in computer vision, but mainly for video [10,29]. This has led to complex systems composed of visual primitive recognizers combined with a structured formal language, e.g. And-Or Graphs or logic systems, which are further converted to natural language via rule-based systems. Such systems are heavily hand-designed, relatively brittle and have been demonstrated only on limited domains, e.g. traffic scenes or sports.
Image to caption has been a popular research topic in recent years. Researches have made remarkable progress on image description with natural texts. According to the three categories classified by Bernardi et al. [1], our work can be categorized as “Description as Generation from Visual Input”, which takes visual features or information from images as input for text generation. Kiros et al. [17] proposed neural networks for caption generation from an image. They first present a multimodal log-bilinear model that was biased by features from the image. Then they built a joint multimodal embedding space by a computer vision model and an LSTM (Long Short-Term Memory) that encodes text [16]. Patterson et al. [22] and Devlin et al. [7] regard descriptions as retrieved results in the visual space. Although they can retrieve grammatically correct sentences and be applicable to novel images, the quality greatly depends on the training dataset. Inspired by the work in machine translation and object detection, Xu et al. [27,31] present an attention-based model that can automatically learn to describe the contents of images. Karpathy and Li [15] and Donahue et al. [8] apply either LSTM architecture or alignment of image and sentence models for further improvement.
Researches on the automatic generation of classical poetry began in 1959 when Theo Lutz produced the first German poem by computer. Since then, the automatic poems generation by machine starts from the simple word stack method, and then gradually developed to the current case-based reasoning method and also other emerging methods, which can be classified as phrase search based approaches [12,25,26], template-based generation methods [21,34], genetic algorithm based methods [2,19], and text summarization [28]. Combined with computer vision and natural language processing, Xiaobing,1
Although automatic poetry generation is a popular research topic in artificial intelligence, there are very few studies focused on Chinese couplet generation. The Chinese couplet generation task can be viewed as a reduced form of 2-sentence poem generation. Given the first line of the poem, the generator ought to generate the second line accordingly, which is a similar process as couplet generation. However, there are still some differences between couplet generation and poetry generation. The task of generating the subsequent clause to match the given antecedent clause is more well-defined than generating all sentences of a poem. Moreover, not all of the sentences in the poems need to follow couplet constraints.
So far, some Chinese scientists have conducted formal research in the field of computer-aided couplet generation. For example, Yi Yong et al. used the hidden Markov model, the probabilistic language model and the conversion-error-rate driven sequence learning method to establish the generation models respectively, which can get fluent and antithetical couplets [30]. With the method of neural network, Fei Yue et al. constructed the semantics on the level of image thinking, and took advantage of the knowledge and experiences in the field of couplets to generate computer couplets within 6 characters [9]. A couplet generation system developed by Zhang Kaixu et al. [33], adopted both maximum matching participle model and maximum entropy Markov model. They first used the maximum matching model to divide the input antecedent clause into words, and then used the maximum entropy Markov model to generate the fitting subsequent clause. By introducing the antithesis between the antecedent and subsequent clauses, it greatly optimizes the model training.
The overview of our solution is shown in Fig. 2, for the image recognition, we use VGG16 model for ImageNet1000 to predict the category about the input image. VGG16 model has been well-trained and its training results are accepted by the industry. Since VGG16 model is published on the internet, anyone can download the model easily. Given an input image, object and sentiment detection technologies are used to extract appropriate nouns or adjectives as labels. However, the labels generated from image is in English due to the lack of Chinese database. We have to translate the label of ImageNet1000 into Chinese and only one output is allowed and reserved. Next, we accept the result as initial keywords for the antecedent clause generation process. Finally, an attention-based encoder-decoder model is used to generate suitable subsequent clause based on the antecedent clause.
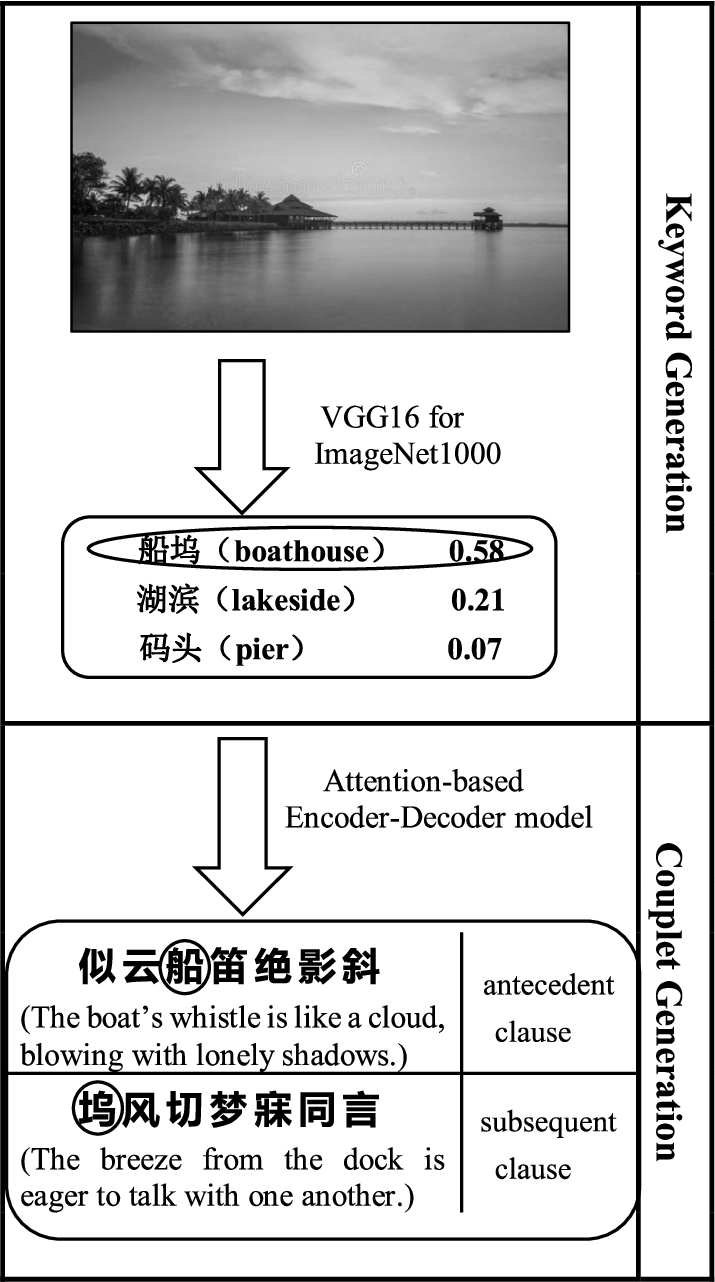
Illustration of the image to couplet framework.
VGG16 model is used to predict the category of images. VGG is a convolutional neural network model proposed by K. Simonyan and A. Zisserman from Oxford University in their paper “Very Deep Convolutional Networks for Large-Scale Image Recognition” [23]. This model achieves 92.7% top-5 test accuracy in ImageNet. ImageNet is an image database organized according to the WordNet hierarchy (currently only the nouns), in which each node of the hierarchy is described by hundreds and thousands of images. For researchers around the world, this is an easily accessible but authoritative image database that covers more than 14 million images across 1,000 categories.
The macro-architecture of VGG16 model can be seen in Fig. 3. The network is 16 layers deep and is trained on more than a million images from the ImageNet database. It can classify images into 1000 object categories, such as keyboard, mouse, pencil, and many animals. As a result, the network has learned rich feature representations for a wide range of images.

Macro-architecture of VGG16.
During training, the input image size is a fixed-size 224 × 224 RGB image. The only preprocessing of the image is subtracting the mean RGB value, computed on the training set, from each pixel. The image is passed through a stack of convolutional layers, where a very small receptive field: 3 × 3 (which is the smallest size to capture the notion of left/right, up/down, center) is utilized as convolutional filters. The convolution stride is fixed to 1 pixel; the spatial padding of convolutional layer input is such that the spatial resolution is preserved after convolution, i.e. the padding is 1 pixel for 3 × 3 convolutional layers. Spatial pooling is carried out by five max-pooling layers, which follow some of the convolutional layers (not all the convolutional layers are followed by max-pooling). Max-pooling is performed over a 2 × 2-pixel window with stride 2. A stack of convolutional layers (which has a different depth in different architectures) is followed by three Fully-Connected (FC) layers: the first two have 4096 channels each, the third performs 1000-way ILSVRC classification and thus contains 1000 channels (one for each class). The final layer is the soft-max layer. The configuration of the fully connected layers is the same in all networks. All hidden layers are equipped with the rectification non-linearity.
We propose detecting objects from each image with a convolutional neural networks (CNN), which learns to describe objects by the output of noun words. The CNN is pre-trained on VGG16 model for ImageNet1000. In order to reduce the training time, the well-trained VGG16 model is established in keras framework to realize the image recognition and classification. Before image processing, we first import the trained image features and image subtitles into the RNN/LSTM model, and then make the model study these subtitles. In this way, at the stage of image processing, we can obtain understandable subtitles, that is, the prediction results for an image.
From all the prediction results, the top-3 words are reserved and then translated into Chinese. We utilize Google online dictionary to complete the translation work and then crawl down the translation result through the program. For 1000 categories in the database, only one translation result is reserved for each category.
In order to create couplets matching with input image, we use the Chinese translation result generated by VGG16 model as an input for the couplet generation section. We take advantage of the recurrent neural network language model (RNNLM) [20] to predict text sequences. Each word is predicted sequentially by the previous word sequence:
Generation subsequent clause with antecedent clause
As we all know, Chinese couplets has strict requirements on antithesis in form and harmony in tone. This rigorous one-to-one antithesis contains a strong mapping regularity, which can take advantages of RNN and encoder-decoder model. Therefore, the basic idea of automatic couplet generation is to build a hidden representation of the antecedent clause, and then generate the subsequent clause accordingly with encoder-decoder model. The units of couplet generation are Chinese characters.
Encoder-decoder model
The encoder-decoder model is a framework for solving sequence to sequence (seq2seq for short) problems. Seq2seq has many applications, such as machine translation, document extraction, question answering system and so on.
The task of Encoder-decoder model can be interpreted as the process of “encoding-> storage-> decoding”. For our automatic couplet generation, we defined the encoder as an RNN that first reads each character of an input sequence
After reading the end of the sequence (marked by EOS, an end-of-sequence symbol), the hidden state of the RNN is a summary c of the whole input sequence.
The decoder of our model is another RNN, which is trained to generate the output sequence by predicting the next character
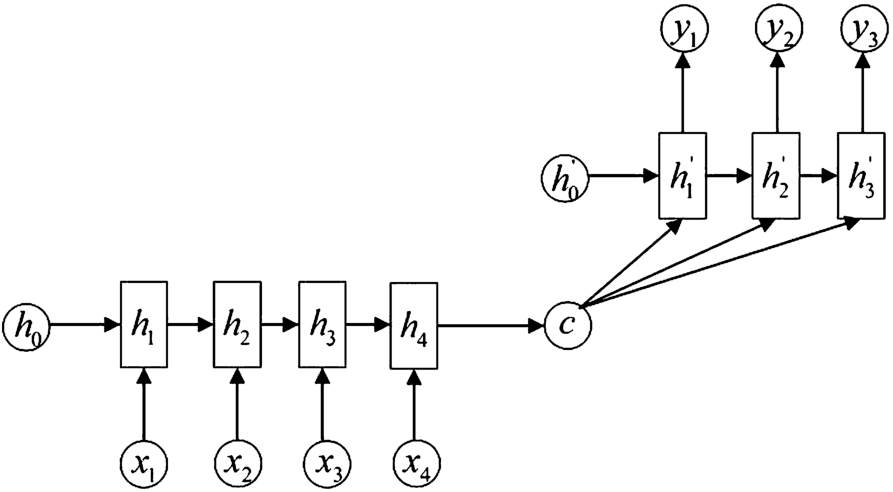
Couplets generation with the encoder-decoder model.
See Fig. 4. for a graphical depiction of the structure of automatic couplets generation with the encoder-decoder framework.
In the above model, the semantic vector c, which is generated by encoding input sequence
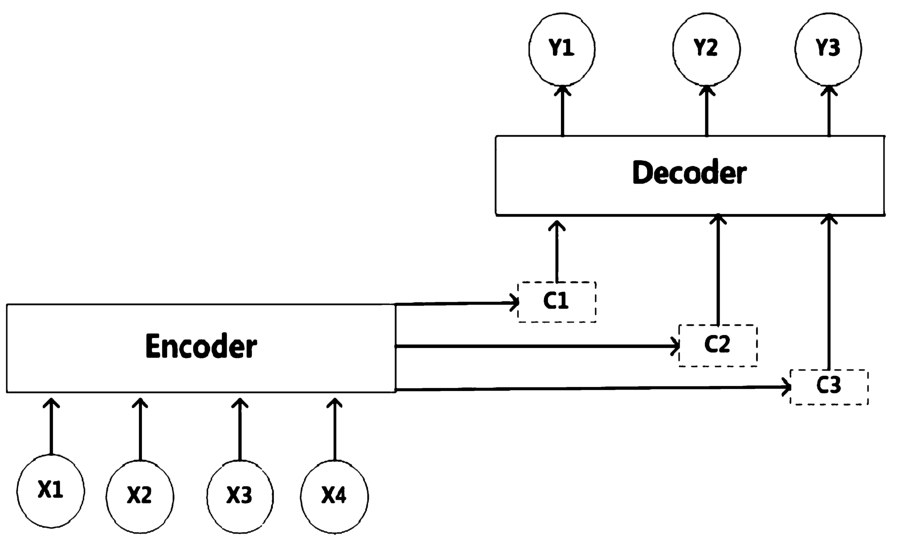
Recently, the attention mechanism is proposed to allow the decoder to dynamically select and linearly combine different parts of the input sequence with different weights. Basically, the attention mechanism models the alignment between positions between inputs and outputs, so it can be viewed as a local matching model. Moreover, the tonal coding issue can also be addressed by the pairwise attention mechanism.
Therefore, we introduce the attention mechanism to improve the accuracy of the encoder-decoder model [32]. In particular, the input of decoder is no longer limited to the only semantic vector c with a fixed length. Instead, it encodes the input sequence
Introduction of the attention mechanism.
Encoder-decoder model with attention mechanism.
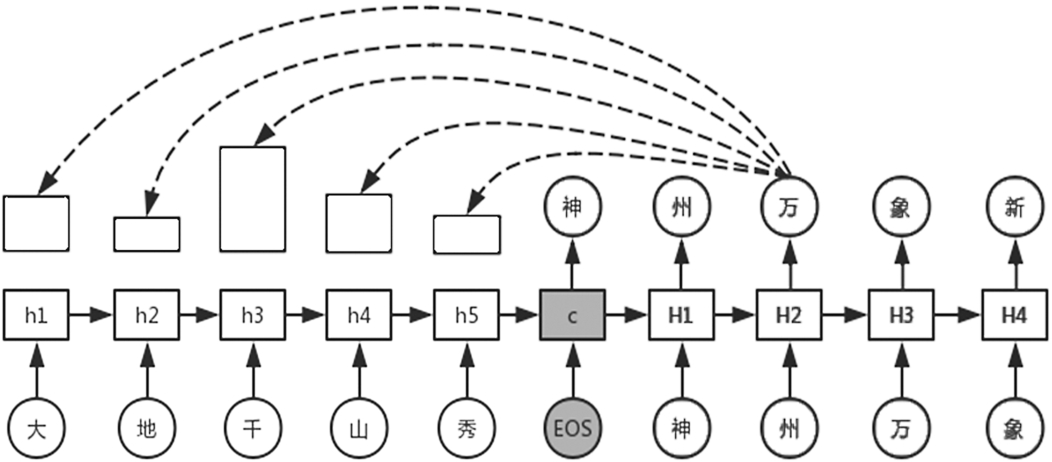
Since the generation of couplets requires strict antithesis, it is undoubtedly useful to find and refer to the corresponding character in the antecedent clause while generating the subsequent clause. Therefore, it can obviously improve the quality of characters in the subsequent clause generated by the encoder-decoder framework with attention mechanism. For example, according to the character “ (thousand)” in the antecedent clause, as shown in Fig. 6, when generating the corresponding character “
(thousand)” in the antecedent clause, as shown in Fig. 6, when generating the corresponding character “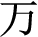 (ten thousands)” in the subsequent clause, we not only pay attention to the global semantic vector c, but also to make it as much attention as people’s eyes, to particularly refer to the character “
(ten thousands)” in the subsequent clause, we not only pay attention to the global semantic vector c, but also to make it as much attention as people’s eyes, to particularly refer to the character “ (thousand)”. then it is easy to find out, they are all digital and they often match up in a pair of couplets.
(thousand)”. then it is easy to find out, they are all digital and they often match up in a pair of couplets.
Data sets
Our work contains two data sets. One is image database, ImageNet1000, which can recognize 1000 categories of different things. The other one is couplet database.
Nowadays there is no such big couplet data sets available. But to some extent, Chinese ancient poetry, especially Tang poetry, conforms to the antithetical rules of couplets. Therefore, in this experiment, we first preprocessed the huge database downloaded from the Tang poetry website and finally we got over 77 thousand couplets and randomly selected 4000 couplets for testing.
For the complex couplets of Tang poetry, we delete all the poetry’s title, author and redundant spaces. Then we split each poetry into two parts: “the antecedent clause”, the input for encoder, and “the subsequent clause”, the input of both decoder and the loss calculation function.
Training
Since our research consists of two parts, the training of models also includes two separate processes. For image recognition, we use the public VGG16 model for training. In addition, we do check the training results. As for couplet generation, the attention-based encoder-decoder model is proposed for training.
Encoder: In Encoder layer, we use embed sequence function to embed the input tensor and letters. Then input the embedding vector to the LSTM layer.
Decoder: Embed target data to build a multilayer LSTM unit; construct an output full connection layer to get the result of each time sequence’s RNN; Training decoder is constructed by directly input the elements of the sequence in target data into encoder; Construct predicting decoder. In the predict stage, there is no target data, so the prediction result of the previous stage will serve as the input for the next stage.
Adding Attention Mechanism: Connect the encoder and decoder parts to build the seq2seq model. The attention mechanism is mainly used to wrap cell in decoder. Define the cell; Encapsulating the attention wrapper.
Training parameter settings
Training parameter settings
Training parameter settings: The batch data is for validation and the other data is for training. After training, each batch data obtained should be saved for subsequent invocation and testing. Training parameters are shown in Table 1. The value of epochs directly affects the accuracy of the couplets generation and the total time of model training. The size of batch which affects training speed. And the rate of learning affects the speed of learning.
Training results: Fig. 7 is the screenshot of partial training results, and each line represents a different clause:
the original antecedent clause
predicted subsequent clause created by our model
the original subsequent clause

Example training results.
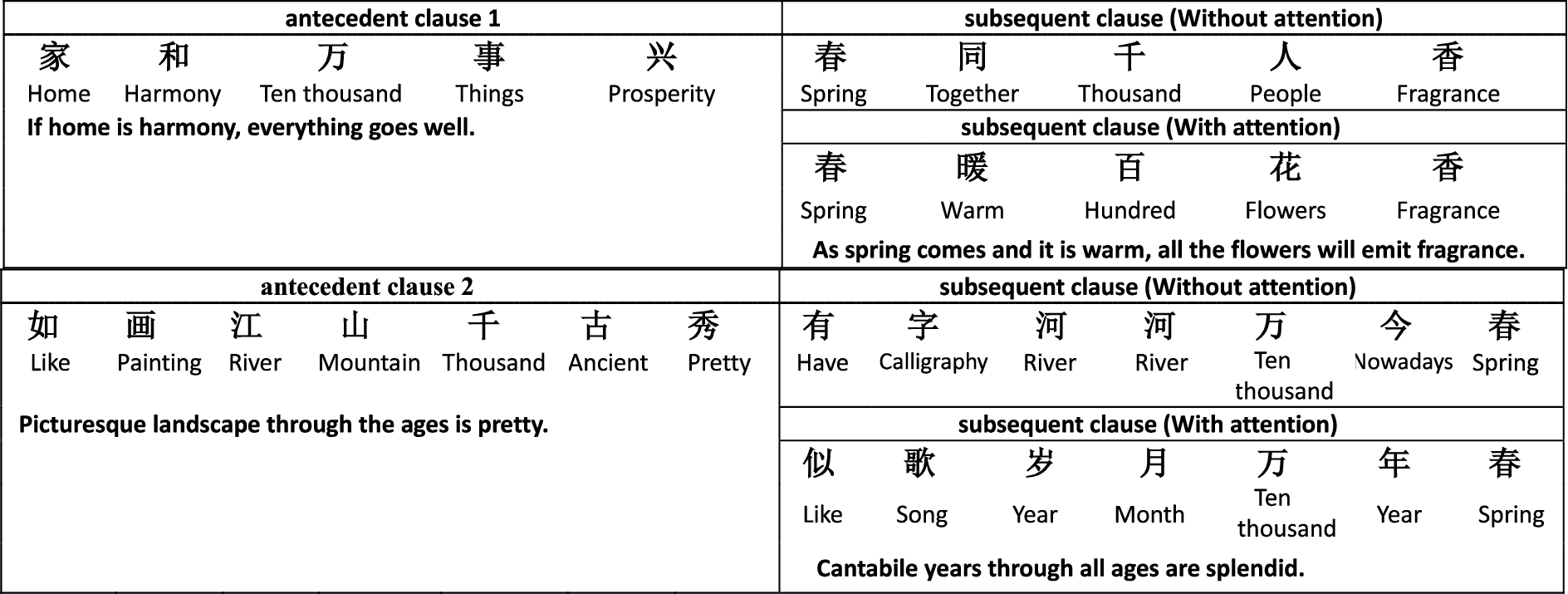
Model Comparison: We compare the subsequent clause’s generation before and after the introduction of attention mechanism, as shown in Table 2.
For the first given antecedent clause, the subsequent clause (in blue characters) created by encoder-decoder model strictly comply with the antithesis rule of couplets. So “ (Ten thousand)” is paired with “
(Ten thousand)” is paired with “ (Thousand)”, “
(Thousand)”, “ (Harmony)” corresponds to “
(Harmony)” corresponds to “ (Together)” and so on. However, for the subsequent clause generated without attention mechanism, its content is of no real meaning.
(Together)” and so on. However, for the subsequent clause generated without attention mechanism, its content is of no real meaning.
For the same antecedent clause, the subsequent clause (in green characters) created by attention-based encoder-decoder model is not only a neat antithesis, but also completely consistent with the entire artistic conception. “ (Ten thousand)” is paired with “
(Ten thousand)” is paired with “ (hundred)”, “
(hundred)”, “ (Things)” corresponds to “
(Things)” corresponds to “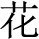 (Flowers)” and so on. The mood expressed by antecedent clause is “
(Flowers)” and so on. The mood expressed by antecedent clause is “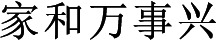 (If home is harmony, everything goes well.)”, which is paired with “
(If home is harmony, everything goes well.)”, which is paired with “ (As spring comes and it is warm, all the flowers will emit fragrance.)”.
(As spring comes and it is warm, all the flowers will emit fragrance.)”.
Obviously, it is the attention mechanism that optimizes the subsequent clause’s generation and makes the subsequent clause more neat and beautiful. Therefore, the following evaluation and analysis are based on the introduction of attention mechanism into encoder-decoder model.
The generation of subsequent clause
The generation of subsequent clause
Evaluation: For the general task of text generation in natural language processing, there exist various metrics for evaluation including BLEU and ROUGE. However, it has been shown that the overlap-based automatic evaluation metrics have little correlation with human evaluation [18]. Thus, we conduct user studies to evaluate our method.
A pair of couplet can be divided into nine categories according to its quality. The evaluation standard can be summarized:
A neat and antithesis structure A suitable and stable tone The same artistic conception and purpose Conform to the objective facts and phenomena Be novel and unique, creative Fancy, clever Expression
We invited 15 graduate students majored in Chinese literature to conduct a manual evaluation of the generated couplet through scoring.
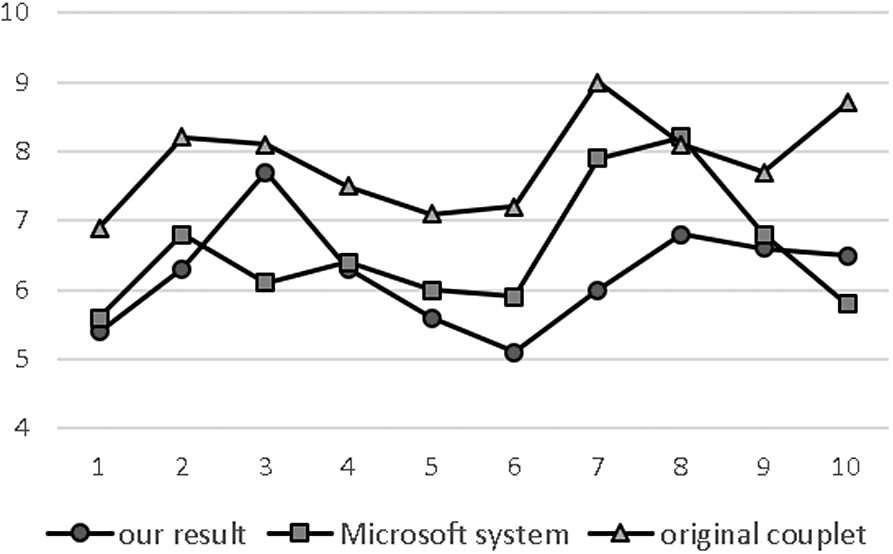
Line chart for scores.
The manual scoring criteria has two parts: semantic relevance (including conflict, mood, etc.), and grammatical correctness (including structure, flatness, etc.). Each part covers 5 points. So, the full score of each subsequent clause generated is 10 points. The independent scoring process is ensured and obviously perfunctory scores are excluded. After removing both the highest and the lowest score, the average of all the scores is the final score of the generated subsequent clause.
We randomly select 10 pairs of unpopular couplets. The subsequent clause generated by our model is compared with the one generated by the Microsoft couplet system [35] and the original couplet respectively. For each subsequent clause generated, it has a final score. Figure 8 shows the line chart of scores in comparing our generated subsequent clauses with the original ones.
The average score of the three subsequent clause generation systems can be calculated as follows:
The average score of our result = 6.23
The average score of the Microsoft system = 6.55
The average score of the original couplet = 7.85
Among these 10 pairs of generated couplets, the score of the subsequent clauses generated by our model is higher than that from Microsoft system twice. The score of the subsequent clauses generated from Microsoft system is higher than the original one once.
After all, the subsequent clauses generated by our model are mostly smooth and beautiful. Although in some cases, it is not as good as Microsoft couplet system possibly due to the inadequate training time.
Chinese couplet requires not only a neat structure and semantic antithesis, but also the consistency of contents and emotion expressed by both antecedent clause and subsequent clause. Evaluating the automatic generation of couplets is undoubtedly a very challenging task, let alone the generation of couplets to interpret the artistic conception of an image.
Test Image Data: Instead of randomly crawled images from the existing images from the training dataset described above, we choose images from the book “Sketch of Tang Poetry (collection edition)”, in which each picture has a matching Tang poem.
Model Variants: As far as we know, there is no prior work on generating Chinese couplets from images. Therefore, for the baselines we compare our model with both the Ctrip application and the original poems from “Sketch of Tang Poetry (collection edition)”.
Sketch of Tang Poetry. It is a book that contains nearly 300 pictures. For each picture, there is a traditional poetry created during Tang dynasty, describing the Artistic conception of the picture.
CTRIP. CTRIP has released a traditional poetry generation application on 2017 [6], which can generate poems based on the landscape photos uploaded by users, with the image recognition technology, LSTM model, optimized translation algorithm and genetic algorithm on massive database. While we cannot find the corresponding publication, since it has a similar goal, we choose their released service as the baseline in the comparison experiment.
Evaluation Metrics: The evaluation criteria is based on the following metrics, in the scale from 1 to 10:
Compliance: if the sentences conform to semantic antithesis and its structure is neat;
Rhythm: if the sentences read fluently and convey reasonable meaning with metre (in verse);
Consistence: if all the sentences adhere to a single theme and in the same mood;
Fitness: if the sentences match with the artistic conception and purpose of the image;
Performance: In the experiments, we invited 25 graduate students majored in Chinese literature to conduct a series of scoring evaluations. They were asked to rate the original poem for the image with couplet generation of our model, and the other comparative application, CTRIP.
Human evaluation results of our method and two other baselines. Evaluation
Human evaluation results of our method and two other baselines. Evaluation
Table 3 presents the results. See from the final average scores, there is a certain gap between products generated by the two methods and the original poems in the “Sketch of Tang Poetry (collection edition)”.
∙ In terms of Compliance, the scores of our couplets and Ctrip’s ancient poems are the highest ones among the four evaluations and also, very close to the original poems. As the couplets or ancient poems are produced by well-trained models, they basically conform to the semantic antithesis and have a neat structure.
∙ In terms of rhythm, obviously the original poem scored the highest for its good rhythm, and the better one is Ctrip application. Our method is the worst. For sake of time constraints, we do not study rhyming rules of the couplet. Therefore, in some occasions, we happen to be able to obtain couplets with good rhymes.
∙ In terms of Consistence, the original poems is much better than the couplet generated by our method, except that we surpassed the original poems once. As for Ctrip application, its performance is almost the same as our method, because both image recognition results are not accurate enough.
∙ In terms of Fitness, the couplets generated by our system are not as aesthetic and complete as what expressed by the original poem, but occasionally they can provide a new interpretation of the picture from other angles. For example, as shown in Fig. 9, the original poem depicts a picture of leisure and tranquil, while our couplets express a lonely and desolate mood.

Example products by different methods.
In conclusion, it is feasible and successful to automatically generate couplets using VGG16 and attention-based encoder-decoder model. Experimental results show that in some cases, our system is inferior to Ctrip, which may be due to insufficient training frequency. However, most of the couplets generated by our method are smooth and beautiful, and have a certain correlation with the input image, which is still of great reference value.
In this paper, we propose a novel approach for Chinese couplet generation from an image based on computer vision and natural language processing technology. For the input image, we first use improved VGG16 model to obtain the category label, and then use the Google online dictionary to translate it into Chinese keywords. An attention-based encoder-recorder model is used to generate a pair of couplets that related to artistic conception of the input image.
This study is our first attempt to generate Chinese couplet from an image. In this study, while some connection between image and couplet is leverage, more can be done. For example, we can provide a new polishing schema to refine the subsequent clause generated by our attention-based model. Our models can generate couplets that match the artistic conception of the input image. To some extent, it is difficult for ordinary people to distinguish them from the real couplets.
Existing technology cannot help machine training or machine learning the human’s thoughts and emotion expressed through poetry or couplets. Therefore, although the result generated by our method seems to be couplets, it is still a lack of certain flavor of poetry, and further research is needed to produce better couplets. We will investigate approaches for this in the future.