
Abstract
A parsimonious convolutional neural network (CNN) for text document classification that replicates the ease of use and high classification performance of linear methods is presented. This new CNN architecture can leverage locally trained latent semantic analysis (LSA) word vectors. The architecture is based on parallel 1D convolutional layers with small window sizes, ranging from 1 to 5 words. To test the efficacy of the new CNN architecture, three balanced text datasets that are known to perform exceedingly well with linear classifiers were evaluated. Also, three additional imbalanced datasets were evaluated to gauge the robustness of the LSA vectors and small window sizes. The new CNN architecture consisting of 1 to 4-grams, coupled with LSA word vectors, exceeded the accuracy of all linear classifiers on balanced datasets with an average improvement of 0.73%. In four out of the total six datasets, the LSA word vectors provided a maximum classification performance on par with or better than word2vec vectors in CNNs. Furthermore, in four out of the six datasets, the new CNN architecture provided the highest classification performance. Thus, the new CNN architecture and LSA word vectors could be used as a baseline method for text classification tasks.
Keywords
Introduction
Text classification is a classic problem where the objective is to assign a set of categories to documents. Studies in text classification vary from developing a sophisticated document feature representation [11,34] to implementing simple document representations in efficient classifiers [6]. A common approach in text classification is the bag-of-word as ngrams representation, where documents are represented with a vector of words that appear in each document [22]. Ngrams are very simple to generate, however it results in very large and sparse vectors. The sparsity in ngrams are due to the length of the text and the use of different words with the same meaning in the corpus vocabulary. Understanding the sparsity and semantics arising from text documents representation is a major challenge in text categorization [17,30].
Recent studies [13] have applied 1-dimensional convolutional layers (1D-CNNs) directly to one-hot vector representations of text documents obtained from bag-of-words. Typically this is not well-suited for convolution networks, wherein dense data is preferred. To mitigate this issue, an embedding layer prior to the convolutional layers is used to densify the one-hot vectors [3,14,18,32]. An embedding layer takes a large vocabulary and projects the full representation into smaller dimensional space [18]. CNNs with an embedding layer are similar to long short-term memory (LSTM) models [10], which also have an embedding layer when used in document sentiment analysis [7,8]. However, LSTMs are known to be difficult to train since they are sensitive to hyperparameters such as batch size, hidden dimensions, and learning rate [28].
Recently, word vectors obtained from an unsupervised neural network language model (word2vec [27]) have been successfully used as pretrained weights to initialize an embedding layer in CNNs for text classification [18]. The word2vec (w2v) word vectors are trained on 100 billion words of Google News. The goal of using w2v vectors with a CNN in Kim [18] was similar to Razavian et al. [29], which showed that for image classification, pretrained features from a different domain can be fine-tuned to domain specific-tasks. However, if the domain of the document classification task is very different from the pretrained vectors, classification accuracy may not reach its full potential, since the purpose of unsupervised pretraining is to provide relevant features that can improve accuracy [2].
Furthermore, there are limitations for training w2v models locally. First, w2v models require large datasets for training. For satisfactory performance, a minimum of 10 million words should be in the training corpora [1]. A curated dataset of such a large size may not always be available for a given dataset. For smaller datasets, LSA word vectors were found to provide better performance in semantic similarity tasks [1]. Second, there are a number of hyperparameters that need to be carefully chosen to obtain meaningful word vectors from the w2v model [24].
Related work
Recent studies have proposed various CNN architectures for document classification. One of the first studies to demonstrate the use of CNNs for document classification was Kim [18], which used pretrained w2v vectors for the embedding layer and window sizes of 3, 4, and 5 words. These widow sizes represented tri, quad, and pentagrams in the CNN model [18]. The CNN based on the w2v vectors were effective on a number of document classification tasks. Johnson and Zhang [13,14] demonstrated that using pairs of window sizes in the range of 2, 3, 4, and 20 words on the one-hot vector representation (derived from bag-of-words) of documents could provide classification improvement on the model by Kim [18]. However, Johnson and Zhang [13,14] did not use any pretrained vectors for their model. Zhang et al. [36] have used combinations of window sizes ranging from 3, 5 and 7 words, where the input data was embedded in to character space (based on the alphabet) rather than word space in the corpus vocabulary. Conneau et al. [4] further deepened the number convolutional layers in the model from Zhang et al. [36], but limited the window size to only 3 words.
Although CNNs are effective in document classification tasks, their main drawback is that they can be designed using various architectures and include many hyperparameters. This may make their implementation difficult, since there is no clear architecture or guiding principle to follow. Also, the issue of hyperparameter tuning can be further compounded when the CNN is initialized using pretrained word vectors obtained from neural network models, such as w2v. The reason is that word vectors would need to be trained from scratch for a given task. As a result, there is no clear consensus for a baseline CNN architecture and the type of word vectors to be used for initializing the word embedding layer in a CNN.
Current study
Data transformed with ngrams (typically using uni, bi, and trigrams) and term-frequency inverse-document-frequency (TFIDF) weighting, are still considered effective baseline models for many document classification tasks [33,36]. Especially when used with linear classifiers, such as logistic regression (LR), on smaller datasets with about 500K observations [36]. Furthermore, it has been shown that word vectors obtained from matrix factorization can produce better embeddings than neural network methods [23,24].
Thus in this study, to address the difficulty of training CNNs for document classification, a new CNN architecture that uses parallel 1D convolutional layers with small window sizes, ranging from 1 to 5 words is presented. These small windows sizes are equivalent to using uni, bi, tri, quad, and pentagrams for linear classifiers. Also, locally trained word vectors obtained by LSA are used to initialize the weights in the embedding layer of the CNN models. The LSA vectors are easily obtained by singular value decomposition (SVD) on unigram and TFIDF weighted data [19].
This is the first study to: (1) use LSA word vectors with CNNs and (2) to propose small window sizes (specifically, combining uni and bigrams) in CNN text classification. The new CNN model has two advantages. First, it includes pretrained word embeddings without the onerous hyperpameter search and extensive training time of neural network methods, such as w2v. Second, it leverages the success of combining uni, bi, and trigrams in linear classifiers by applying a similar architecture within CNN models.
In the following section we highlight how to set up the LSA based CNNs and demonstrate its effectiveness against baseline linear classifiers and against CNN models initialized with random and pretrained w2v vectors.
Materials and methods
Below, we describe the implementation of the baseline linear classifier, the new CNN architecture that leverages LSA, and the CNN model designed for w2v vectors. Document datasets for all models used the same preprocessing steps.
Datasets
The models were evaluated on three benchmark datasets (IMDB, AGNews, DBP) containing balanced class distributions. These three datasets were chosen because they were shown have to very high classification accuracies using linear classifiers on ngram transformed and TFIDF weighted data, even beating deep CNN architectures [33,36]. The AGNews and DBP datasets are from [36]. A summary of the datasets and the size of training and test data are presented in Table 1. Brief information regarding each of the datasets is given below:
The following datasets (as listed in Table 1) were used to determine the effect of imbalanced class distribution on the best performing CNN architecture and word vector combinations:
For all six datasets, punctuation, hypertext, and stopwords are removed, follwoed by a conversion to lowercase letters. The vocabulary is limited to 30K.
Summary of the text document datasets
Summary of the text document datasets
To construct the TFIDF weighted

Schematic of the proposed model. In this example, a single sentence of a preprocessed movie review is input into a model where there is a vocabulary size of 5 in the dictionary. The word vector embedding layer reduces the dimensionality of the dictionary to 3. Then 3 parallel 1D-convolutions are applied, using 3 different filter sizes, on which
CNNs are feed-forward neural networks, where the features generated by the neural networks layers are convolved with each other until a final classification is applied. Typically, the features are extracted from small 2D patches of an image. For instance, for a 32 × 32 grayscale image, 5 × 5 regions are extracted from which the features are learned. However, for text documents this 2D region is simplified down to 1D patches.
The core CNN architecture for the text document classification presented in this study employs a 1D-CNN model [3]. A sentence can be defined by a sequence of n concatenated k-dimensional word vectors,
Embedding layer
The word vectors in the CNN model are represented by the embedding layer
In this study, three types of word vectors are used to initialize the embedding matrix. First, as a baseline, random word vectors from
Finally, the word2vec word vectors pretrained on 100 billion words of Google News are used to form
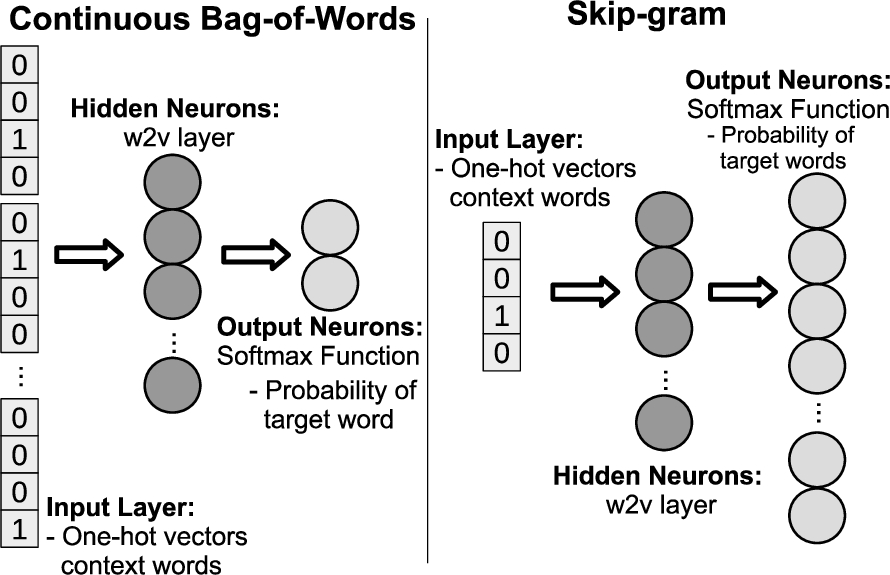
Training of word2vec word vectors. The two models of word2vec architectures are shown here.
The random word vectors in
To successfully apply LSA in a CNN model, three different architectures were developed to take advantage of the LSA word vectors. Specifically, networks with ngram filter sizes
A summary of the architecture is shown for the
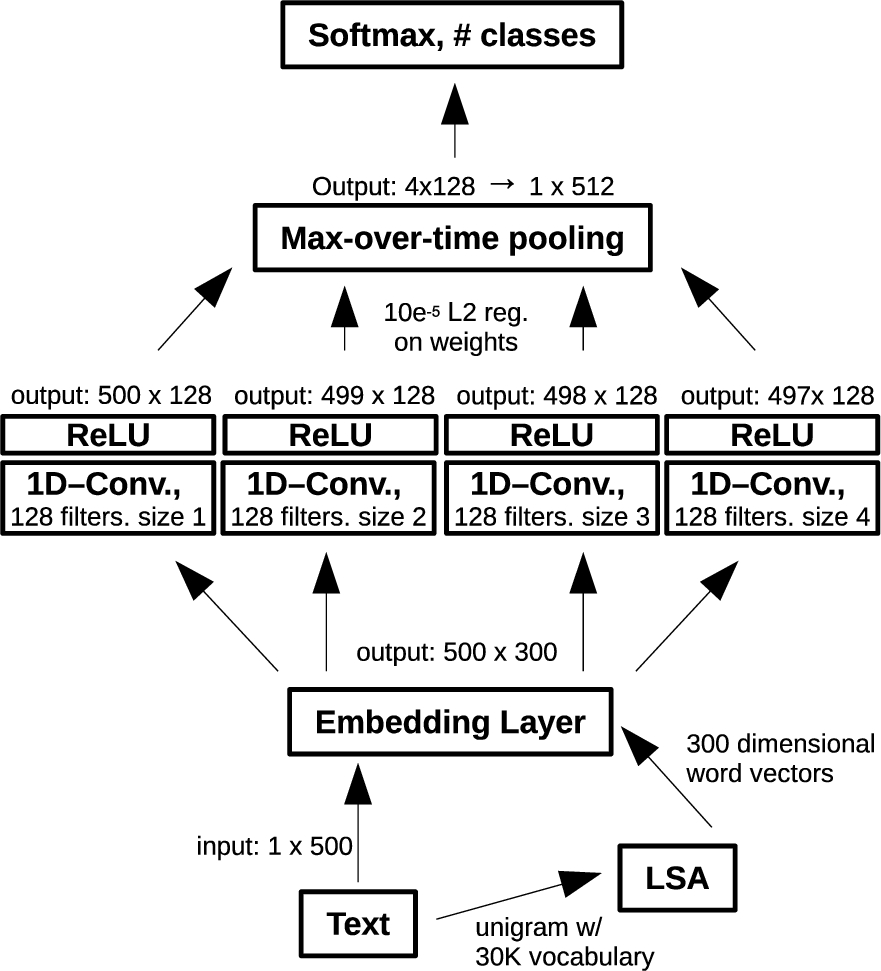
Sample CNN model architecture. The above setup shows the architecture and parameters for the top performing LSA-based CNN model.
The 1D-CNN architecture from Kim [18] was also used to compare against the CNN architecture developed to leverage LSA vectors. The CNN architecture developed for w2v vectors uses larger filter sizes since the word2vectors are designed to capture long distance relationships among words [27]. The w2v-based CNN model was shown to be an effective classifier compared to linear and other state-of-the-art classifiers such as RNN’s and LSTM’s [18]. For the w2v-based CNN architecture, the following parameters as given in [18] were used: filter sizes
Experimental setup
For all six datasets, the vocabulary size of the training corpus was limited to 30K words for the linear and CNN based models. To test the effectiveness of the LSA and w2v specific CNN architectures, the
For all balanced datasets, the traditional accuracy metric (ratio of true positive and negative documents to the number of all documents) was reported on the testing samples. On the imbalanced datasets, the best average performing LSA-based CNN architecture was used to compare against the w2v-based CNN architecture. Furthermore, on the imbalanced datasets the macro-averaged F-score (the unweighted F-score across all classes) was used to report the classification performance, since it is not skewed by the larger class sizes. The F-score itself is the harmonic mean between the recall and precision metrics.
Results
Classification accuracy for text documents on the balanced datasets. Bold face indicates best accuracy for a dataset
Classification accuracy for text documents on the balanced datasets. Bold face indicates best accuracy for a dataset
a Mean is the average accuracy across the different datasets.
bThe logistic regression is performed with
cThe following name convention is used, “{ngram range}-
Table 2 presents the experimental results of the proposed CNN architecture for LSA word vectors against the baseline linear model and the CNN architecture designed for w2v word vectors on the balanced datasets. On average, the best performing CNN architecture and word vector type across all balanced datasets was the
On the IMDB dataset, the
For the IMDB and AGNews datasets, the w2v vectors reached their maximum accuracy using the
When the

Classification accuracy of the CNN models on the balanced datasets. The effect of the different architectures and word vectors is shown here.
On the balanced datasets, an analysis of variance (ANOVA) with a 3 (embedding type) × 4 (filter architecture) random effects design showed that there was no significant interaction between the filter architecture and word vector used in the embedding layer (Fig. 4). However, there were significant differences among the filter architectures (
Specifically, Tukey post-hoc tests showed that the
Comparison of classification accuracies of the LSA-based CNN to character-based CNN models. Accuracy values of the character-based CNNs are taken from their respective studies. Bold face indicates best accuracy for a dataset
Since the
Comparison of F-score values for the new
For the imbalanced datasets, the
An ANOVA with a 3 (embedding type) × 2 (filter architecture) random effects design showed that there was no significant interaction between the filter architecture and word vector used in the embedding layer across the imbalanced datasets. Nor was there a significant difference between the two filter architectures. However, there was a significant main effect of the word vectors (
This study has shown that locally trained LSA word vectors can be used as an alternative to pretrained w2v word vectors in a CNN model for text document classification. In two balanced (IMDB and DBP) and one imbalanced (20News) dataset, the LSA vectors provided the maximum classification performance. In the AGNews balanced dataset, the highest classification accuracy for the LSA vectors was lower by a very small margin against the w2v vectors. Also, a novel architecture using small word window sizes for CNN classification of text documents was introduced. The new small windowed CNN architecture provided the maximum classification performance on all three balanced (IMDB, AGNews, and DBP) and in one imbalanced (HSI) dataset. The combination of the new CNN architecture and LSA word vectors was also shown to perform the better than all other character-based CNN models on the AGNews dataset and third best on the DBPedia dataset.
Most CNN architecture for document classifications have used combinations of window sizes ranging from 3, 5 and 7 words [36]. Although, the goal was to model short and long distance relationships among words [36], smaller window sizes of 1 or 2 words have not been analyzed, as in this current study. As shown in Johnson and Zhang [13], effective linear classification with
Thus, the success of the LSA-based CNN model architecture could be attributed to the use of the smaller filter sizes together with the LSA word vectors. Since the LSA word vectors are extracted using unigrams, the LSA only encodes short distance relationships among words. Thus, using filter sizes larger than quadgrams should not be able to capture meaningful semantic relationships among words. Whereas the w2v word vectors perform better in a CNN with larger filter sizes, since w2v word vectors are trained with large windows sizes ranging from 5 and 10 words in length [24]. Also the results show that carefully tuning traditional methods, such as LSA word vectors, gives equivalent results to neural network methods, such as w2v, as shown in Levy et al. [23].
A limitation of linear models is that they cannot use ngram representations that are not present in the training dataset [13]. CNNs are able to find and use ngrams that are not wholly in the training set, which is why CNN based ngram models perform better than linear ngram models. For instance, CNN based ngrams can learn a general trigram “best X-positive ever”, where X-positive represents a positive word. This general trigram can then be used to classify the testing data as long as it follows the general form [13].
One limitation of the LSA-based CNN model and the related small word window architecture, can be that in datasets with long documents (i.e., many and long sentences per document), the model may begin to perform worse against models that take advantage of larger window sizes. In this case, CNN architecture based on w2v word vectors or character-based models may perform better, since they are more likely to capture long distance semantic relationships among words.
Another limitation was demonstrated when the majority of the imbalanced document datasets were better classified using the w2v inspired CNN architecture, which has the larger window sizes. This could be due to the fact that small window sizes are not able capture the higher level word relationships, which could then be used to offset the lack of relationships obtained from the smaller document classes.
Conclusion
This study has shown that LSA word vectors using CNNs with small window sizes can be used as a baseline classifier for document classification. One reason for this, is that the LSA word vectors can be more domain specific than pretrained w2v word vectors and that small window sizes can leverage the embedding of LSA vectors. Furthermore, LSA word vector dimensionality can be easily adjusted to any size. Whereas the pretrained w2v word vectors are set to a dimensionality of 300, unless a costly pretraining process is undertaken. For future studies, we would like to analyze the effect of using different LSA word vector dimensions. Also, we would like to implement other types of traditional word vectors, which could have an effect on larger text datasets.