
Abstract
Recent advancements in computer-assisted learning systems have caused an increase in the research in knowledge tracing, wherein student performance is predicted over time. Student coursework can potentially be structured as a graph. Incorporating this graph-structured nature into a knowledge tracing model as a relational inductive bias can improve its performance; however, previous methods, such as deep knowledge tracing, did not consider such a latent graph structure. Inspired by the recent successes of graph neural networks (GNNs), we herein propose a GNN-based knowledge tracing method, i.e., graph-based knowledge tracing. Casting the knowledge structure as a graph enabled us to reformulate the knowledge tracing task as a time-series node-level classification problem in the GNN. As the knowledge graph structure is not explicitly provided in most cases, we propose various implementations of the graph structure. Empirical validations on two open datasets indicated that our method could potentially improve the prediction of student performance and demonstrated more interpretable predictions compared to those of the previous methods, without the requirement of any additional information.
Introduction
Recent advancements in computer-assisted learning systems have led to an increase in research on knowledge tracing [8], in which student performance in coursework exercises is predicted over time. Accurate predictions help students identify content suitable to their individual knowledge level, thereby facilitating more efficient learning. This is particularly important for e-learning platforms and teachers, as it helps increase student engagement and reduce dropout rates. Although various knowledge tracing methods have been proposed, Piech et al. [22] reported that a method called deep knowledge tracing (DKT), which leverages recurrent neural networks (RNNs) [31], performs significantly better than any previously reported method.
In terms of data structure, coursework can potentially be structured as a graph. The requirements for mastering the coursework are divided into knowledge concepts, known as nodes, and these concepts share dependency relationships, known as edges. Consider an example where coursework knowledge is divided into three concepts
To incorporate the graph-structured nature of coursework knowledge into knowledge tracing models, we reformulate knowledge tracing as a graph neural network (GNN) [12] application in this work. Recently, research on GNNs, which handle graph-structured data by deep learning, has been garnering attention. Although operation on irregular domain data has been challenging for existing machine-learning approaches, various generalization frameworks and important operations have been developed successfully [3,11,30] in various research areas. Battaglia et al. [3] explained the expressive power of GNNs from the perspective of relational inductive biases, which improve the sample efficiency of machine-learning models by incorporating prior human knowledge about the nature of data. To incorporate such benefits into knowledge tracing, we reformulate it as a GNN application and propose a novel model that can predict coursework proficiency by considering the latent knowledge structure.
A challenge encountered when performing knowledge tracing using a GNN is the definition of the latent graph structure. GNN has considerable expressive power for modeling graph-structured data; however, in several cases of knowledge tracing settings, the graph structure itself, i.e., the related concepts and the strength of the relationships, is not explicitly provided. It is possible for human experts to heuristically and manually annotate the content relationships. However, this requires deep domain knowledge and a substantial amount of time, so it is difficult to define the graph structure for all of the content in an e-learning platform in advance. We call this problem the implicit graph structure problem. A straightforward solution to this is to define the graph structure using simple statistics that can be automatically derived from data, such as the transition probability between answered concepts by students. Another solution is to learn the graph structure itself in parallel with the optimization of the primary task. A relevant topic in the recent GNN literature is edge-feature learning, for which several methods have been proposed. Although these techniques cannot be directly applied to our problem, they can be extended to allow their application in our case.
In this study, we propose a GNN-based knowledge tracing method, i.e., graph-based knowledge tracing (GKT). Our model reformulates knowledge tracing as a time-series node-level classification problem in the GNN. This formulation is based on three assumptions: 1) Coursework knowledge is decomposed into a certain number of knowledge concepts. 2) Students have their own temporal knowledge state, which represents their proficiency in the concepts of the coursework. 3) Coursework knowledge is structured as a graph, which affects the updating of the student knowledge state: if a student answers a concept, correctly or incorrectly, his/her knowledge state is affected, not only regarding the answered concept, but also other related concepts that are represented as neighboring nodes in the graph.
Using a subset of several open datasets of math exercise logs, we empirically validated our method. In terms of prediction performance, our model outperforms previous deep-learning-based methods, which indicates that our model possesses high potential to improve the prediction of student performance. In addition, by analyzing the prediction patterns of the trained model, student proficiency, i.e., the concepts which the students gained an understanding of, and the time required to do so, can be clearly interpreted from the model’s predictions, whereas the previous methods demonstrated inferior interpretability. This means that our model provides predictions that are more interpretable compared to previous models. The obtained results verify the potential of our model to improve the performance and applicability of knowledge tracing for application in real educational environments.
Our contributions are as follows:
We demonstrated that formulating knowledge tracing as an application of GNNs improves performance prediction, without requiring any additional information. Students can master the coursework more efficiently based on more precisely personalized content, while e-learning platforms can provide a higher quality of service to maintain high user engagement. Our model improves the interpretability of the model’s predictions. Teachers and students can recognize the students’ knowledge states more precisely, and the students can be more motivated to work on the exercises by understanding why they are recommended. E-learning platforms and teachers can redesign the coursework curriculum more easily by understanding the points where students fail. To solve the implicit graph structure problem, we propose various implementations and empirically validate their effectiveness. With our results, researchers can benefit from a performance boost without requiring a costly manual annotation process to track the relationships between concepts. Educational experts can obtain new criteria to improve curriculum design that can help in finding a good knowledge structure.
Related work
Knowledge tracing
Knowledge tracing [8] is the task of predicting student performance over time based on coursework exercises, and can be formulated as follows:
DKT
Since Piech et al. [22] first proposed a deep-learning-based knowledge tracing method, i.e., DKT, and demonstrated the considerable expressive power of RNNs, many researchers have adopted RNN or its extensions as the
Example of DKT input
Example of DKT input
DKT is a simple RNN-based model that has demonstrated a remarkable performance compared to traditional methods [8]. However, DKT represents the temporal knowledge state
Knowledge structure in knowledge tracing
As mentioned previously, coursework can potentially be structured as a graph. It is known that incorporating prior knowledge about the graph-structured nature of data into models improves their performance and interpretability [3]. Thus, incorporating the graph-structured nature of coursework knowledge can be effective in improving knowledge tracing models; however, previous deep-learning-based methods, such as DKT, do not consider this nature.
One of the few studies which use knowledge structure for deep-learning-based adaptive learning is Liu et al. [20]. They first estimated student knowledge levels using DKT, then applied reinforcement learning algorithms to identify the appropriate learning items, reducing the search space of recommended items based on the predefined knowledge structure. However, they do not incorporate the knowledge structure information into the former knowledge tracing stage, and they use a plain DKT model, failing to use fully the latent knowledge structure for student proficiency modeling. Another problem is that they take the human-predefined knowledge structure information [4] as given. Manually annotating the content relationships requires deep domain knowledge and a substantial amount of time, and it is difficult to define the structure in advance for all the coursework. Thus, in many cases of real-world knowledge tracing settings, the graph structure is not explicitly provided, which hinders the application of frameworks like [20].
GNN
GNNs [12] are a type of neural networks that can operate on graph-structured data that represents objects and their relationships as nodes and edges, respectively. Although operating on such irregular domain data has been challenging for existing machine-learning approaches, the considerable expressive power of graphs has led to increasing research on GNNs. In recent years, various generalization frameworks and important operations have been developed [3,11,30] with successful results in various research areas, such as social science [13,18] and natural science [2,10,23], and in areas relevant to this work, like time-series recommendation [32].
Our primary motivation for using GNN is the success of convolutional neural networks (CNNs) [19]. Using a local connection, weight sharing, and multilayer architecture, a CNN can extract multiscale local spatial features and use them to construct expressive representations as it has resulted in breakthroughs in various research areas such as computer vision. However, CNNs can only operate on regular Euclidean data, such as images and text, whereas applications in the real world often generate non-Euclidean data. A GNN, on the other hand, regards these non-Euclidean data structures as graphs and enables the same advantages of the CNN to be reflected on these highly diverse data. Battaglia et al. [3] explained the expressive power of the GNN and CNN from the perspective of relational inductive biases, which improve the sample efficiency of machine-learning models by incorporating prior human knowledge about the nature of data.
Edge feature learning
Among the research topics in GNNs, edge feature learning [2,5,11] is the most relevant to our work. Graph attention networks [28] apply the multi-head attention mechanism [27] to the GNN and enable learning edge weights during training without requiring their predefinition. Neural relational inference [17] leverages a variational autoencoder (VAE) [16] to learn the latent graph structure in an unsupervised manner. Our method assumes a latent graph structure underlying the knowledge concepts of coursework and models the temporal transitions of student proficiency in each concept using graph operators. However, the graph structure itself is not explicitly provided in many cases. We address this problem by designing models that learn the edge connection itself in parallel with the optimization of the student performance prediction by extending these edge feature learning mechanisms. We explain this in detail in Section 3.3.
Methods
Problem definition
Here, we assume that the coursework is potentially structured as a graph
Proposed method

Architecture of GKT. When a student answers a concept, GKT first aggregates the node features related to the answered concept, then updates the student’s knowledge states for the related concepts, and finally predicts the probability of the student answering each concept correctly at the next time step.
GKT applies a GNN to the knowledge tracing task and leverages the graph-structured nature of knowledge. We present the architecture of GKT in Fig. 1. The following paragraphs explain the processes in detail.
First, the model aggregates the hidden states and embeddings for the answered concept i and its neighboring concepts
Update
Next, the model updates the hidden states based on the aggregated features and the knowledge graph structure:
Predict
Finally, the model outputs the predicted probability of a student answering each concept correctly at the next time step:
We can use the edge information to collect the knowledge state from the neighboring concepts. We confirmed that it was better to predict
Implementation of latent graph structure and
GKT can leverage the graph-structured nature of knowledge for the purpose of knowledge tracing; however, the structure itself is not explicitly provided in most cases. To implement the latent graph structure and
Statistics-based approach
The statistics-based approach implements the adjacency matrix
Learning-based approach
In this approach, the graph structure is learned in parallel with the optimization of the performance prediction. Here, we introduce three approaches for learning the graph structure.
The learning-based approach is close to the concept of edge feature learning [2,5,11], and MHA and VAE were motivated by the graph attention network [28] and neural relational inference [17], respectively; however, we modify them based on two aspects. First, we calculate the edge weights based on static features, such as the embeddings of concepts and responses, instead of dynamic ones. This enables the learning of the knowledge graph structure invariant to the students and time steps, which is more natural considering the actual knowledge tracing settings. Second, for the VAE, we limit the edge-type inference for nodes related to the answers at each time step. This fits the knowledge tracing situation wherein students answer only a small subset of concepts at each time step, thereby reducing the computational cost from
Comparison with previous methods
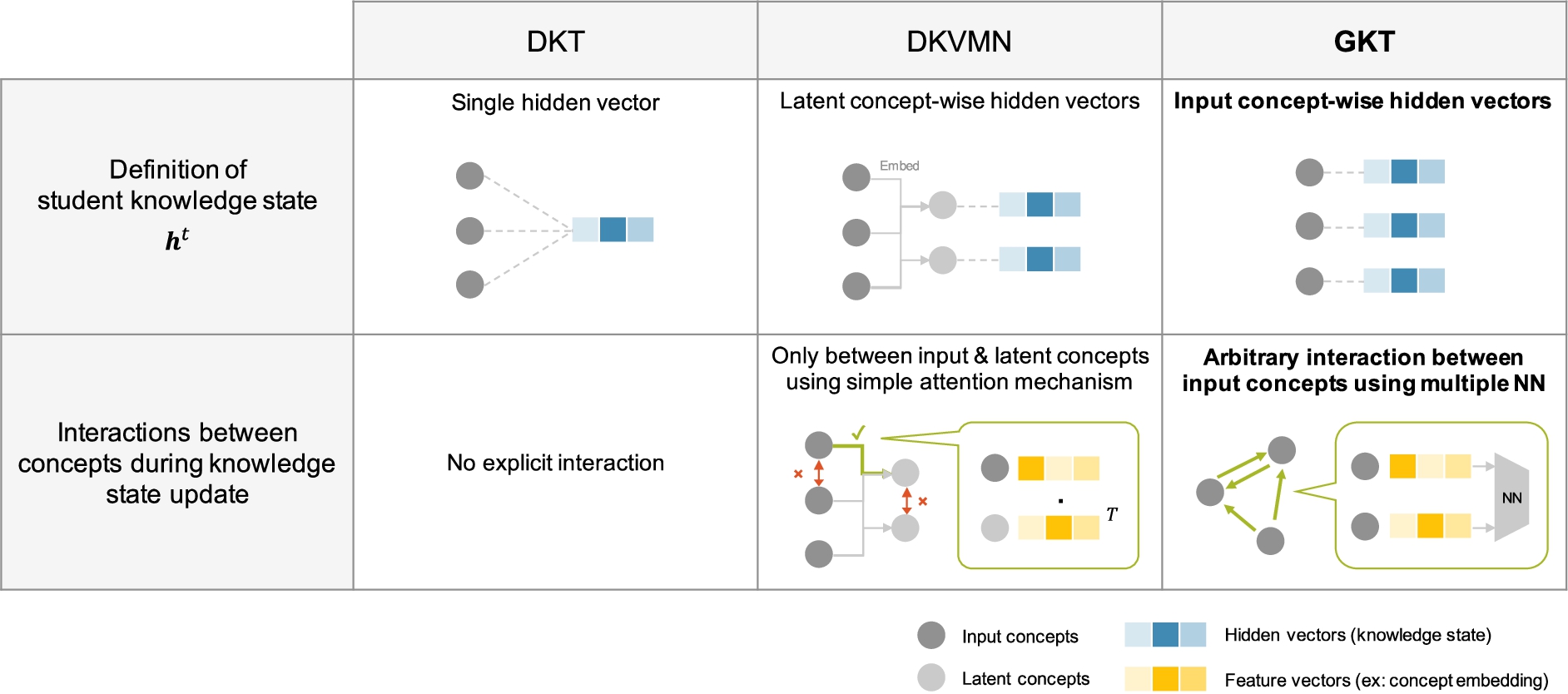
Comparison of GKT with previous methods.
A comparison of the proposed method with the previous ones can be performed using two criteria. We present the comparison in Fig. 2.
The first criterion is the definition of the student temporal knowledge state,
The other criterion involves the interactions between concepts during knowledge state updating. In a DKVMN, the relation weights between the original input concepts and latent concepts are calculated using a simple dot-product attention mechanism, which can be insufficient for modeling the complex and multiple relationships between knowledge concepts. Meanwhile, GKT models the relation weights, or the edge weights, between input concepts using K different neural networks for K edge types. This enables the modeling of multiple and complex relationships between concepts.
Datasets
For the experiments, we used eight open datasets of student math exercise logs. We provide overviews of each dataset below. The parenthesis after the dataset names contain abbreviations that will be used in the tables of our experimental results.
ASSISTments
ASSISTments1
The datasets used in the KDD Cup 2010 Educational Data Mining Challenge are also used as benchmark datasets for knowledge tracing. We used the following three development datasets for our experiments.
Junyi academy
Junyi Academy2
All of the datasets have the students’ time-series exercise logs, in which each exercise is associated with one or more human-predefined knowledge concept tags that are required to solve the exercise. We provide examples of the knowledge concept tags in Table 2. In the following, we describe the preprocessing procedures for these datasets. We show the statistics of the datasets after the preprocessing in Table 3.
Concept tags
Concept tags
Some datasets have invalid concept tags that are noise for experiments, for example, unnamed tags or tags containing “DO NOT TRACK ME” strings in the KDD Cup datasets. We exclude these tags from our analysis.
Combine simultaneous answer logs
Because some datasets have multiple concept tags for one exercise, answers for each tag can be recorded separately, even if those tags are answered at a single time step. Using these records directly could cause unfairly high prediction performance because of the frequently co-occurring tags. Thus, we combine simultaneous answer logs into a single time-step answer vector or tensor, which is input into the knowledge tracing models.
Randomly sample users (optional)
Because some datasets have many logs, we randomly sample up to 1,000 users’ logs for analysis to perform exhaustive validations efficiently. However, this process can hinder the accurate validation of our method, so we also performed experiments using all users’ logs for some datasets in Section 4.5.2 and ensured that this user sampling has little impact on our analysis.
Threshold concept tags based on the number of answers
Because some concept tags have few user answer logs, we excluded such tags to remove noise. We extracted only the logs associated with concept tags answered at least 10 times.
Dataset statistics
Dataset statistics
For each dataset, we applied a user-wise five-fold split, trained and evaluated the models’ performance for each split, and took the average of the five-fold results. In each split, we took 10% of the training data as validation data and trained the model for up to 50 epochs while adjusting the hyperparameters using the validation data. We used an Adam [15] optimizer with a learning rate of 0.001 for all models. In each iteration of training, we randomly sampled a partial sequence with a length of 100 from the whole sequence of each student to enable efficient computation and large batch sizes. In testing, we used the whole sequence for each student.
Prediction performance
First, we evaluated the prediction performance of GKT. For evaluation metrics, we used the area under the curve (AUC) score, which is commonly used in previous studies [22,33]. It is calculated by comparing the predicted probability of a student answering each exercise correctly and his/her actual response, and reflects a model’s ability to discriminate correct responses from incorrect ones. We list the results in Table 4. The highest scores are denoted in bold for each dataset, and their relative improvements from the baselines’ best scores are also shown. In all datasets, GKT achieved the highest AUC score, and its relative improvement was 6.25% at best. This suggests that GKT can trace the student knowledge state better than the previous deep-learning-based methods, which do not sufficiently consider the knowledge graph structure.
Focusing on the definition of the graph structure of GKT, the statistics-based approaches and PAM in the learning-based approaches showed better performance on average; however, the performance difference between other graph-structure-based GKTs was minor. We discuss this in Section 5.2
Prediction performance
Prediction performance
Impact of the model size
To determine the model size, we referred to the original papers for the baselines and set both the hidden layer size and the embedding size as 32 for GKT. Using these settings, GKT showed better performance than the baselines. However, we found that the number of parameters of GKT with the above hyperparameter is nearly 10 times smaller than that of baseline DKT. To further investigate this gap in the model size and its effect on the models’ performance, we performed additional experiments. First, for DKT, which required a large number of parameters with the original settings (hereinafter called “DKT (large)”), we experimented with a smaller version with a hidden layer size of 32 (hereinafter called “DKT (small)”). Then, for GKT, which required a small number of parameters with the original settings (hereinafter called “GKT (small)”), we experimented with a larger version with the hidden layer size and the embedding size set to 128 (hereinafter called “GKT (large)”). For simplicity, we selected the statistics-based approach with the dense graph as the GKT model, which is the simplest variant of GKT. The small and large version pairs have almost the same number of parameters to each other in most of the datasets; thus, we can align the model size and compare their performance.
We show the results in Table 5. The numbers below the AUC scores represent the number of trainable parameters, where the numbers are rounded to thousands. In both the small and the large versions, GKT showed better performance than DKT. Furthermore, “GKT (small)” also outperformed “DKT (large),” as shown in Section 4.4. These results indicate that our method can achieve better performance with fewer parameters. This can be partly explained by the efficient hidden representation of GKT that handles the hidden states of each concept separately, whereas DKT needs to represent hidden states for all the concepts in single hidden states.
Prediction performance using different model sizes
Prediction performance using different model sizes
As described in Section 4.2.3, for efficient experiments, we randomly sampled up to 1,000 users’ logs for analysis in each dataset. However, this process can hinder accurate validation of our method, so we also performed experiments using all users’ logs for some datasets. We used “DKT (small)” and “GKT (small)” mentioned in Section 4.5.1 as benchmarks. As shown in Table 6, in all the datasets, our model also outperformed baseline models in the full data as well as in the user-sampled data. This ensures that the user sampling has little relation to the performance improvement of our method, and therefore the validity of the experiments in Section 4.4 and 4.5.1 can be confirmed.
Prediction performance on full data
Prediction performance on full data
Next, we visualize how the model predicts the student knowledge state to change over time and evaluate the interpretability of its prediction. The visualization helps students and teachers recognize the former’s knowledge state efficiently and intuitively, and consequently its interpretability is of importance. Here, we evaluate interpretability based on the following two points: 1) Whether the model updates only the concepts related to the answered concepts at each time step. 2) Whether the update is reasonable with the given graph structure. Although previous works [22,33] performed a similar analysis, our study extends this approach as follows, to analyze the temporal transitions more precisely:
Randomly sample a student log until time step T. Remove bias vectors from the output layers in a trained model. Input the student answer logs Normalize the output values at each time step from 0 to 1.
The objective of removing the bias vectors and normalizing the values at each time step is to remove the concept-specific and time-step-specific biases, so that the knowledge state transitions can be clearly visualized as a heatmap.
Figures 3(a) and 3(b) depict a randomly sampled student’s knowledge-state transition to a subset of concepts in ASSISTments2009. The x-axis and y-axis show the time steps and concept indices, respectively, and the cell color shows the extent to which the proficiency level changed at each time step. Green denotes an increase and red denotes a decrease. We fill the elements answered correctly and incorrectly with “✓” and “×,” respectively. As shown in Fig. 3(a), GKT updates the knowledge state of only the related concepts, whereas DKT updates the state of all the concepts indistinctly and cannot model the change in the related concepts. In addition, Fig. 3(b) shows that although concept 29 is not answered, its knowledge state is clearly updated at
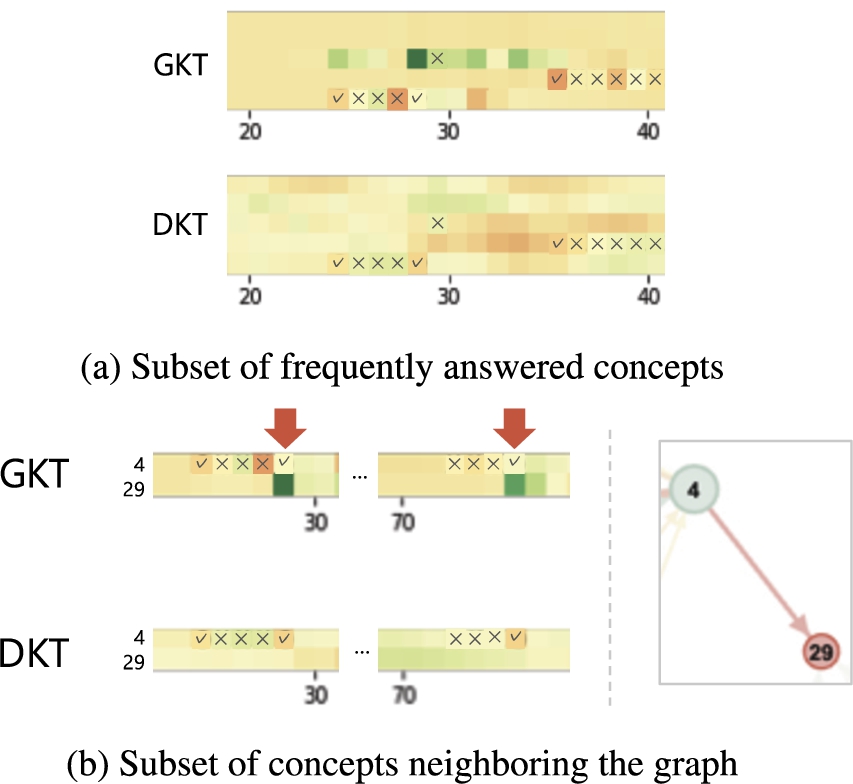
Transitions of predicted knowledge states for concept subsets.
Finally, we extracted the learned graph structure from the trained GKT model and analyzed it. In the learning-based approaches, GKT learns the graph structure that helps predict student performance. Thus, analyzing and comparing the graphs extracted from the models can provide insights into how the models learn the relationships between concepts.
The process of extracting the graph structure from each of the leaning-based models is as follows:
For a given dataset, train the models on each of the five-split folds. Create the adjacency matrix from each of the five models. Extract edge connections common in at least n of the five models.
We used the “Bridge to Algebra 2006–2007” dataset as an example. Extracting the edge connections common in n models enables us to remove noise specific to each split and obtain the structure learned by multiple models in common. We set
The networks are depicted in Fig. 4, where the top of the figure shows the network overview, and the bottom of the figure shows the local connections. We used Gephi [1] for network visualization. The color of the nodes is graded from blue to red, where the earlier an exercise is answered, the bluer the shade. The size of the nodes is proportional to their out-degree, implying that larger nodes affect more other nodes.
First, we focus on the global structure of the graphs. In the PAM graph, the nodes are forming small clusters, and they are split from other clusters. In the MHA graph, although the nodes are forming clusters like the PAM graph, they are sparsely connected with other clusters. In the VAE graph, although most of the nodes are forming small clusters, some nodes are forming a large cluster, where the nodes are densely connected with each other. Although each model shows the different structure influenced by their model architecture, the difference in prediction performance was small as shown in Section 4.4. Thus, we cannot determine which of the structure better represents the student knowledge structure.
On the other hand, focusing on the local connections, we found that some similar connections on related concepts appear in all the three models, as shown in the bottom of the figure. This indicates the potential of the GKT to learn important concept relationships purely from students’ exercise logs, independent of the detailed architecture of learning the graph structure.
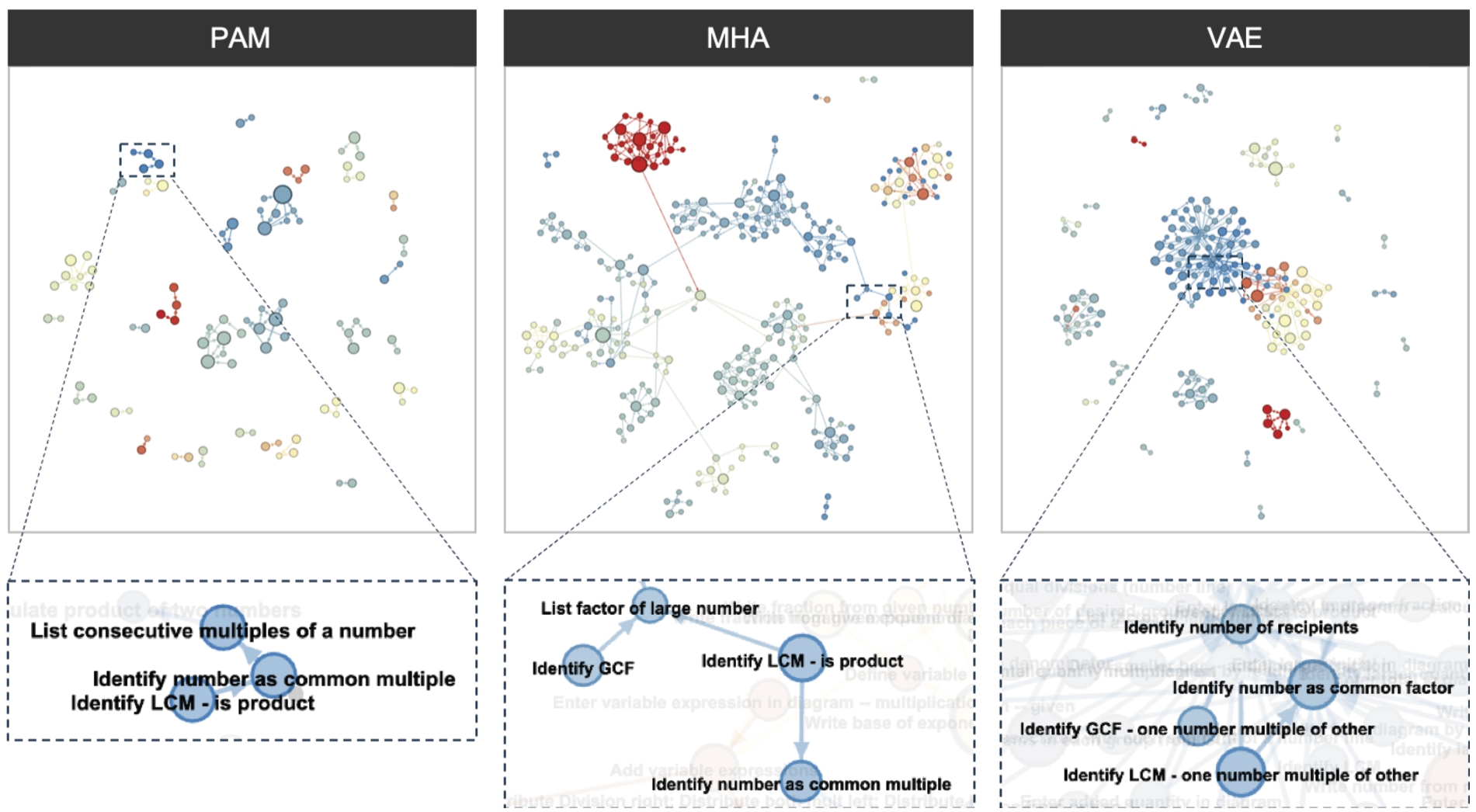
Network visualizations of graphs derived from GKT models.
Benefits of GNN-based reformulation of knowledge tracing
In this paper, we proposed a GNN-based knowledge tracing method, and empirically validated that our method improves the prediction of student proficiency (Table 4–6) and its interpretability (Fig. 3) compared with previous deep-learning-based methods [22,33]. These results support our assumption that coursework is potentially structured as a graph; therefore, incorporating such a nature into a knowledge tracing model improves its performance, thus working as a relational inductive bias. The improvements in prediction performance and its interpretability provide benefits to various aspects of real-world educational environments: accurate predictions help students identify content suitable for their individual knowledge level, thereby facilitating more efficient learning; moreover, such predictions help e-learning platforms and teachers to increase student engagement, and thus reduce dropout rates.
Solving the implicit graph structure problem
In reformulating knowledge tracing as a GNN application, we pointed out the problem that the graph structure itself is unknown in many practical cases. Further, we proposed and empirically validated various implementations of the graph structure as shown in Table 4 and Fig. 4. This enables researchers to benefit from a performance boost without requiring a costly manual annotation process to track the relationships between concepts. In addition, it facilitates educational experts to set a new criterion for improving curriculum design; this in turn, would help them to determine a good knowledge structure.
On the other hand, focusing on the implementation of the latent graph structure of GKT, there are small differences in prediction performance between different implementations as shown in Table 4; therefore, it is not possible to conclude which approach is the best. One reason for this phenomenon could be that the neural networks used to represent edges have a strong expressive power. Thus, the model could sufficiently optimize by adjusting the parameters without adjusting the edge weights, and the contribution of the latter became relatively small. The differences can be expanded by applying some constraints on edge-weight distribution or information propagation between nodes, for example, sparse edge connections or edge direction-aware propagations, so that the models have to leverage the edge weights more. Further investigation into incorporating the constraints into models and analyzing the relationships between the graph structure and prediction performance is planned for future work.
Dataset generalizability
In the experiments, we conducted an exhaustive validation on a diverse set of mathematical datasets and confirmed that the performance improvement of our method is not limited to specific datasets, as shown in Table 4–6. Although the subject of the datasets is limited to Mathematics and given that there exists a report of DKT applications to programming education [29], GKT can also be effective in various subjects. Moreover, GKT is a generic algorithm that completes previous algorithms such as the DKT. Because the proposed method can learn the latent graph structure from data without expensive manual annotation, our method can also be easily applied to and validated on other subject datasets. In addition, it is expected to learn different graph structures on different subject datasets, which could impart novel information on human knowledge structure. One limitation is that there exist few public datasets for subjects other than Mathematics, and the validation on other subjects is fundamentally difficult. Collecting student exercise logs on various subjects and validating various methods, including GKT, with them will be a common theme for knowledge tracing research. This would extend the application of knowledge tracing to wider educational environments.
Potentials by incorporating richer GNN architectures
In this work, we proposed the first GNN-based knowledge tracing method and validated relatively simple architectures. In the following, we discuss three future directions that can be pursued to improve our model by incorporating richer GNN architectures.
One is to impose appropriate constraints for information propagation between nodes based on their edge types. In this study, for a fair comparison, we defined two types of edges for both the statistics-based and learning-based approaches. However, we did not impose any constraint on each node type; therefore, the meaning of each node type such as dependency direction and causality may be slight, especially for the learned edges. A solution to this is to impose some constraints for information propagation between nodes based on their edge types, e.g., defining directions for edges and limiting propagation to only one direction, from source nodes to target nodes. Additionally, this can serve as a relational inductive bias and improve the sample efficiency and interpretability of GKT.
Another direction is to incorporate a hidden state common to all concepts, such as that of DKT, into GKT. Although adopting only a single hidden vector to represent the knowledge state complicated the modeling of complex interactions between concepts in DKT, as described in Section 3.4, adding these representations to GKT could improve the performance because they could serve as global features [3]. The term “global features” indicates features common to each node, and these features can represent knowledge states that are common across variable concepts or the student’s original intelligence and are invariant to individual concept understandings.
The third possible solution is to implement multi-hop propagation. In this study, we limited the propagation to a single hop, i.e., the information from answering a certain node is propagated only to its neighboring node in one time step. However, to effectively model the complex human learning mechanism, using multiple hops will be more effective. Additionally, this can enable the model to learn sparse edge connections because the model can propagate features to distant nodes without having any direct connections to the nodes.
Conclusions
We proposed a GNN-based knowledge tracing method called GKT, which considers a latent knowledge structure that has been ignored by previous deep-learning-based methods. Casting the knowledge structure as a graph, we reformulated the knowledge tracing task as an application of a GNN. Because the knowledge graph structure is not explicitly provided in many cases, we proposed various implementations of the graph structure. Empirical validations on eight open datasets indicated that our method could potentially improve the prediction of student proficiency and demonstrated more highly interpretable predictions than those of the previous methods. These results confirmed the potential of our method to enhance knowledge tracing performance and its applicability to real educational environments. We believe this work could help improve the learning experience of students in diverse settings.