
Abstract
The Semantic Web (Web 3.0) is an advancement of the existing web in which knowledge is given well-defined importance, allowing people and machines to operate better. The Semantic Web is the next step in the evolution of the Web. The semantic web improves online technologies in need of generating, distributing, and linking material. In literature, multiple surveys have been done on the semantic web (Web 3.0), but those surveys are limited to some specific topics. According to the best of our understanding, none of the surveys provides a comprehensive study about the applications, challenges, and future of the semantic web along with its relationship with the Internet of things (IoT). The previous surveys focused on the Web 3.0 without touching on applications or challenges or focused on only the application prospect of the web 3.0, focused on the just the challenges, or focused on web 3.0 relationship with either internet of things or knowledge graphs but failed to touch the other important factors i.e., failed to provide comprehensive web 3.0 survey. This survey paper covers the gaps created from the previous survey papers in the same field and provides a comprehensive survey about web 3.0, a comparison between web 1.0, 2.0, and 3.0, the study of application and challenges in web 3.0, the relationship between web 3.0 with IoT and knowledge graph. Moreover, it focuses on the evolution of the web, and semantic web along with an explanation of the various layers, ontology tools, and semantic web tools with their comparison and semantic web service search. Despite all the shortcomings and challenges, the semantic web is moving in the right direction, and it is the future of the web.
Introduction
Web 1.0 corresponds to the initial stage of the evolution of the World Wide Web. Previously, there were only a small number of writers in Web 1.0, with the bulk of people being information users. Private websites seemed to be popular, primarily consisting of static websites hosted on Internet service servers or free web hosting. The ads were banned in Web 1.0. Static pages, server file system-based content, page creation using a common gateway interface, and tables/frame-based GUI were the basic four design requirements of Web 1.0 [50,53,69].
Web 2.0 implies that the overall websites that emphasize customer information, accessibility, and connectivity for end customers. Web 2.0 is also identified as the participatory social web. It doesn’t relate to a change in any scientific standard, but rather to a change in the way web pages are built and utilized. The shift is advantageous, but it does not appear to be when the changes take place. Web 2.0 allows communication and coordination with one another in social media discourse as the creation of consumer material in an online world [50,69]. Web 2.0 is an improvement of Web 1.0. Some key features include classification of information, easy retrieval of information, creating dynamic content, easy information flow between users, more control over websites, more security, etc. The online World includes a variety of web-based tools and venues where individuals may communicate their ideas, views, feelings, and encounters. Web 2.0 programs regularly engage with the end-user significantly more. The user can become a participant using tagging, social networking, social media, podcasting, web content voting, feedback, bookmarking, curating, and blogging [50,69]
The current web (Web 2.0) has many limitations and administrative problems. The main limitation is that the current web lacks a proper form, in its contents, regarding the interpretation of information. This causes ambiguity in information which in turn results in the poor interconnection of information. Due to the lack of general format, machines are incapable to understand the provided information and automatic information transfer is lacking. To solve these issues, Tim Berners-Lee [10] introduced the semantic web (web 3.0) which is a conceptual model for enhancing the web contents to make them readable and usable by both humans and intelligently by machines.
The Semantic web (Web 3.0) is an advancement of the existing web in which knowledge is given well-defined meaning, allowing people and machines to operate better. Web 3.0 relates to the progression of online usage and engagement, including the conversion of the Web into a repository. It enables the web’s back end to be improved after a prolonged term of concentrating on the front end. Web 3.0 is a concept used to represent multiple transformations of internet activity and communication among various pathways. Information is not controlled in this case but rather pooled, with companies presenting diverse perspectives for the same web/data. The semantic web claims to create the world’s knowledge in a more rational way than Google’s drive train architecture can. This is especially accurate in the case of machine cognition as opposed to natural understanding. The Semantic Web needs the use of a descriptive epistemological framework, such as OWL, to create context ontologies that algorithms would use to think about data and bring in new findings, rather than merely commonly involving [10,50,69]. The Semantic Web is the next move in the development of the Web. The semantic web enhances online technologies in need for generating, distributing and linking material via query and retrieval based on the power to interpret the meaning of the phrase rather than words or statistics [50,69]. Using this skill in conjunction with NLP, computers in the Semantic web can discriminate data as individuals in an attempt to grant quicker and more precise information. They grow progressively smart to serve the needs of humans [50,69]. Because of meaningful data, data is more connected in Web 3.0. Therefore, the customer journey grows to a greater degree of connectedness that makes use of all available data. In Web 3.0, the 3D shape is frequently utilized in sites and apps. Exhibition tours, video games, geographical settings, and other applications that utilize 3D visuals are all examples.
The basic motivation behind this survey paper is to cover the gaps created by the previous survey papers in the same field. In literature, multiple surveys have been done on the semantic web (Web 3.0), but those surveys are limited to some specific topics. According to the best of our understanding, none of the surveys provides a comprehensive study about the applications, challenges, and future of the semantic web along with its relationship with the Internet of things (IoT). The previous surveys focused on the Web 3.0 without touching on applications or challenges or focused on only the application prospect of the web 3.0, focused on the just the challenges, or focused on web 3.0 relationship with either internet of things or knowledge graphs but failed to touch the other important factors i.e., failed to provide comprehensive web 3.0 survey.
This survey paper focuses on the evolution of the web, semantic web along with an explanation of the various layers, ontology tools, and semantic web tools with their comparison and semantic web service search are discussed. Moreover, various applications of the semantic web in multiple domains, challenges that have risen with web 3.0, the prospects of the semantic web, and the relation of web 3.0 with the internet of things (IoT) and knowledge graphs have been described in this paper. Despite all the shortcomings and challenges, the semantic web is the future of the web.
The contributions of the survey paper are as follows:
Providing a comprehensive survey about web 3.0 The development of the web and the comparison between web 1.0, 2.0 and 3.0 Comprehensive study of application and challenges in web 3.0 The relationship between web 3.0 with IoT and knowledge graph
Comparison with existing survey papers
In literature, multiple surveys have been done on the semantic web (Web 3.0), but those surveys are limited to some specific topics as shown in Table 1. According to the best of our understanding, none of the surveys provides a comprehensive study about the applications, challenges, and future of the semantic web along with its relationship with the Internet of things (IoT). Some of the latest surveys have been thoroughly compared with our survey paper in Table 1. In [45], pascal explains the semantic web, ontologies, and knowledge graphs. Brett et al. [31] have explained the technologies of the semantic web for agriculture. Ahlem et al. [82] have given a survey covering the relationship of the semantic web with the internet of things. Information extraction approaches have been discussed by Jose et al. [66].
Arne et al. [88] provide a survey of the semantic web for machine learning models. Darko et al. [4] discuss the relationship between the internet of things and the semantic web. Fabien [37] explains the first 20 years of the semantic web along with its relationship with linked data. Kazheen et al. [95] provide a survey of the relationship between semantic web and cloud computing. Senthil et al. [1] discuss the applications of the semantic web in healthcare, processing systems, and virtual societies. Yahya et al. [107] explain the relationship between knowledge graphs and the semantic web for the industry. Tsvetanka et al. [39] provide a review of semantic web approaches for big data modeling. Ajaj et al. [79] give a review of semantic web technologies for handling big data. Kenza et al. [52] provide the advantages and limitations of semantic schema. Archana et al. [72] provide a survey of the present and future of web 3.0. Kurteva et al. [62] provide a survey of semantic approaches to implementing consent. Han et. al [43] provide the survey for engineering design in the field of semantic networks. Cassia et al. [99] illustrate the challenges in ontology matching approaches and their future. Chanmee et al. [91] provide a survey of domain ontologies. Konstantinos et al. [89] provide a survey for feature selection centered on ontology in the semantic web.
Comparison with other existing survey papers in the recent years
Comparison with other existing survey papers in the recent years
The structure of the paper is as-is: Section 2 discusses the evolution of the web. Section 3 describes the semantic web in detail. In Section 4, ontology tools are discussed. Section 5 explores semantic web tools and their comparison. In Section 6, semantic web service search is discussed. Section 7 explores applications of the semantic web. In Section 8, the challenges that the semantic web faces are discussed. In Section 9, the future of the semantic web is discussed. Section 10 explores the relation of the semantic web with IoT. Section 11 describes the relationship between semantic web and knowledge graphs. In Section 12, the conclusion and future work is described.
Today internet is very common, and one can’t think of living without the internet these days. World Wide Web (WWW) helps in sharing, reading, and writing data with the help of computers or laptops, or other mobile devices. The progress in WWW is admirable. We will discuss mainly semantic web i.e., web 3.0 as it’s the future that is waiting for us. So firstly, we will discuss the evolution of WWW from web 1.0 to web 3.0. There are different challenges the web faces in all its versions, which are mainly security. Firstly, it is important to differentiate between the two terminologies i.e., internet and web. The Internet is the connection of computers all over the world so that computers can interact with each other so basically if all the computers are connected it makes the internet. On the web, the data on the internet is being accessed and it is done through browsers, etc. The comparison is described in Table 2.
Comparison between Web 3.0, 2.0 and 1.0
Comparison between Web 3.0, 2.0 and 1.0
It is the first version of the web. It involves connecting, reading of web pages, and sharing information on the websites as shown in Fig. 1. It is created by Tim Berners-Lee [10]. It is also called as read-only web. There are producers and customers, producers create pages i.e., web pages, and a little number of producers are there in the circuit as compared to the customers who are there to read the data. Customers read the web pages through the internet. Now it only allows users to read the data of web pages, it is just like static pages where users can only read data and cannot do anything else like publishing a comment or giving feedback or filling a forum, etc. HTTP, HTML, URL, CSS, etc. are the technologies that are used in Web 1.0. Web 1.0 involves both client and server-side coding and the following technology are used mostly, PHP, PERL, ASP, JS, JSP, flash, etc. Web 1.0 corresponds to the very initial stage of the evolution of the World Wide Web. Previously, there were only a few writers in Web 1.0, with the bulk of people being information consumers. Private websites seemed to be popular, primarily consisting of static websites hosted on Internet service servers or free web hosting. The ads were banned in Web 1.0. Static pages, server file system-based content, pages creation using a common gateway interface, and tables/frame-based GUI were the basic four design requirements of Web 1.0 [50,69].
The issues with web 1.0 are as follows [50]: Firstly, it’s the unavailability of automatic refreshing of web pages when the new data is added to the web page. So, users must refresh the page manually and it increases the time to access data which makes it slow. The second flaw in the technology is that it does not support two-way communication, so the only client can kick start it. As far as search is considered in web 1.0 it does not handle the relevance as it only emphasizes the index size. As the number of producers is very less as compared to customers so due to this the network becomes slow, and this effect is called the power of network effect. Due to this effect, customers find it very hard to get the desired data. Another flaw is the unavailability of a customer’s contribution, as it is read-only so no contribution can be done by customers. So, it does not use this as a service, it uses software as an application [69].
One way platform (Web 1.0) [32].
In web 2.0 we can write as well as read [68], so it carries the web to a whole new level as shown in Fig. 2. Users can not only read the data available on the web pages but also can write, change, and make updates to the website contents. It provides association and intelligence as well. Data can be shared through different websites like Wikipedia and lots of blog websites and users can make changes to the content of available data on the internet. Web 2.0 implies that the overall websites that emphasize customer information, accessibility, and connectivity for end customers. Web 2.0 is also identified as the participatory social web. It doesn’t relate to a change in any scientific standard, but rather to a change in the way web pages are built and utilized. The shift is advantageous, but it does not appear to be when the adjustments take place. Web 2.0 allows communication and coordination with one another in social media discourse as the creation of consumer material in an online world [50,69].
Following are the reasons which make Web 2.0 a much better technology than Web 1.0 [69,103]:
Increasing user interaction as users can provide lots of resources and this can contribute to the web. The idea is to increase the re-usability of data or information on the web. User data can be collected and then combined in new ways to make useful information. The web 2.0 architecture is very helpful to users as it allows the construction of cooperative knowledge. It is open source, basically it provides open access. More users are connected so the resources are increased as well.
The technologies which used in Web 2.0 are AJAX, XHTML, CSS, DOM, REST, XML, RSS [69,103]. Web 2.0 also has lots of security challenges as it is open source and dynamically generated so anyone can access and change the data [69,84]. Web 2.0 has lots of weaknesses like SQL injection, cross-site scripting, cross-site request forgery, information leakage, authentication, and authorization flaws [63,84].
Two way platform (Web 2.0) [32].
Significance, allowing people and computers to operate better [12] as shown in Fig. 3. Web 3.0 aims to enhance the data, already existing on the web, using system understandable metadata. This allows for better integration, automation, reuse, and discovery across applications. The semantic web is in some ways similar to a worldwide database. The approach of the semantic web is to develop languages for communicating knowledge in a machine-understandable form. The semantic web stack explains its elements and their interactions as shown in Fig. 4 [18].
The following sections will further elaborate on the selected layers [18,22].
Unicode and URI
On the semantic web, a unique uniform resource identifier a.k.a. URI is assigned to each object that identifies it. URI’s have various sub-classes such as Uniform Resource Locator (URL) and Uniform Resource Name (URN) [11]. Unique URLs are assigned to resources on the [22]. It is critical to understand that the semantic web will comprise not just assets like as Web sites, photographs, sound, and video files, but also things such as individuals, activities, or regions. Although Hosting companies have distinct URLs, there is no primary way for allocating URI’s to individuals or activities. Unicode is a behavior characteristic that can handle a range of individual languages [11,22].

Semantic web (Web 3.0).
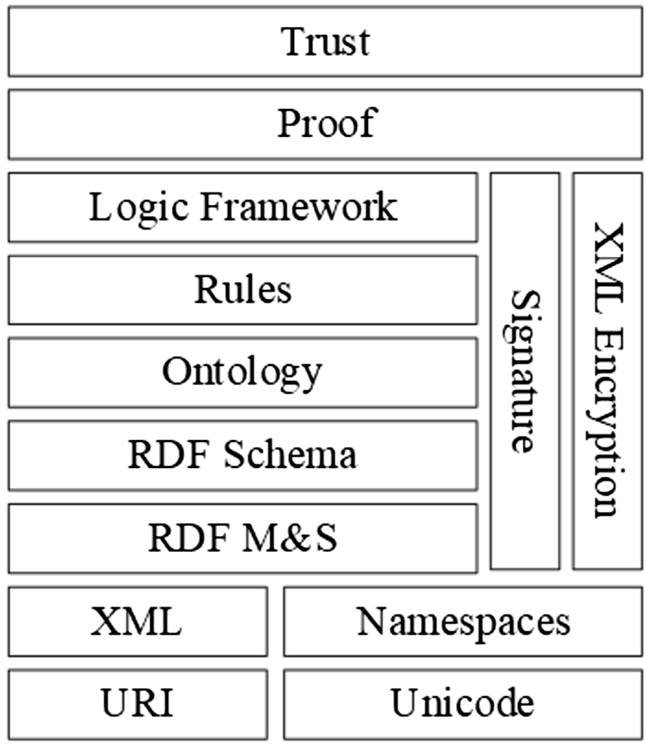
Semantic web stack [18].
The metadata for the semantic web is written in Extensible Markup Language (XML). XML is a textual language that uses elements to tokenize data. XML has been there for nearly 10 years, and there are various research areas and techniques for XML data analysis available [14]. XML [14] syntax is used by the semantic web metadata. XML uses tags for serializing data, and it is a standard for text formatting. An extension to XML is XML name-spaces [13]. A vocabulary consisting of XML element types along with attribute names can be uniquely identified using XML name-spaces. Problems of recognition and collision may occur due to overlapping vocabularies in multiple XML documents. Thus, a URI is defined by the name-space mechanism to suggest the vocabulary and an element name is also defined to specify the element in the vocabulary.
Resource description framework
Information on the web can be represented using a general-purpose language known as RDF [9]. Basically, the RDF graph is the RDF model. RDF URI references represent its nodes; arcs and blank nodes or literals are marked with RDF URI references. Figure 5 illustrates an instance of an RDF graph. In the example, it is shown that triples make up an RDF graph; each triple consists of a subject, an object, and a predicate. Each triple interprets into a statement about a source. The meaning of the example of the triple is the following: The object identified by URI
RDF schema
It is merely the semantic extension of RDF. RDF schema [16] is simply a language to describe RDF vocabularies. RDFS allows us to give labels to URIs, describe class and property hierarchies, etc. Even though XML schema and RDF schema are both schemas, they are intended for different reasons. XML schema [34] is for validation whereas RDF schema is for inference.
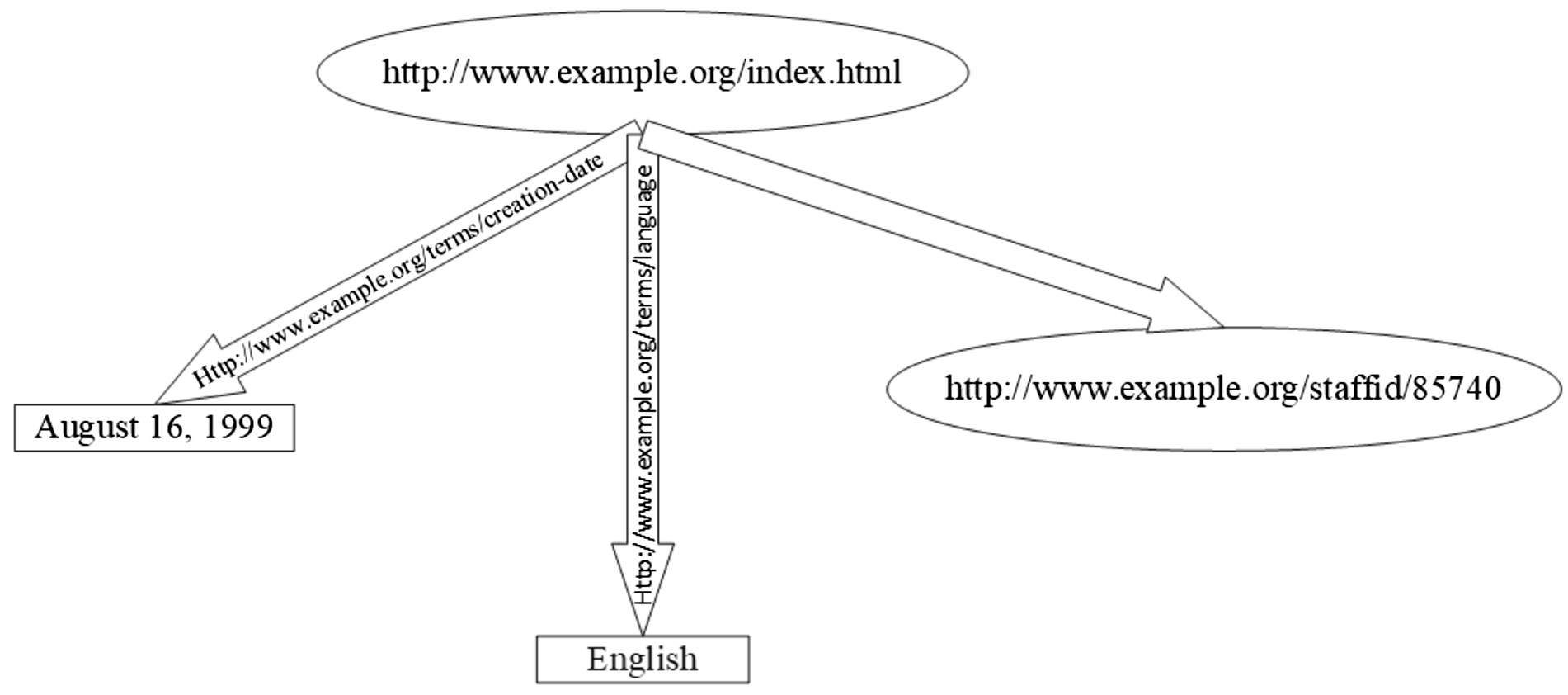
Graph example [18].
Ontologies [22,90] are used to represent the “meaning” of web resources. It is a document that is defined in a formal language, and it describes concepts and terms, and their relationships, used within a certain specific domain. Ontologies serve as the backbone of the semantic web. They enable sharing, reusing, and accessing web content among different applications. The ontology Interface Layer (OIL) is an extension of the RDF Scheme. OIL exists to maximize the integration of ontologies with current Web standards such as RDF and its applications. RDF processors can partially understand most OIL ontologies, 100% compatibility is still not possible since ontology language normally contains new aspects and vocabulary not known by RDF processors.
DAML+OIL and OWL provide capabilities to define ontologies. They are ontology languages. We will focus our discussion on OWL since it is the successor DAML+OIL. OWL provides features such as property characteristics, ontology mapping, property restrictions, complex class definitions, etc. RDFS is extended by OWL due to these features.
Rules
The term Rules refers to statements that can be used to infer expressions. For the semantic web, there are no guidelines on how to establish rules. No special structure to define rules exists in the current version of OWL. Although simple rules can be designed [24]. Using rules is not a new concept. The concept of rule declarations is not novel. In logical computer languages (especially Prolog), the rule states “male(Y): son(Y,-)” may signify that an item is a male if it is the son of another item. For argumentation, Prolog employs backward chaining [22]. A similar concept is utilized in “deductive databases,” in which reasoning principles are expressed in data log protocols with Prolog-like semantics. The Closed World Machine (cwm) is an example of a data processor for the SW. It is a forward chaining reasoner that may be used to search, verify, modify, and analyze information. Its main language is RDF, which has been modified to incorporate rules, and it serializes using RDF/XML or RDF/N3 [22].
Ontology tools
Various tools have been developed for the implementation of metadata for ontologies, in ontology languages like DAML+OIL, XML, OWL, and RDF(S). In this section, a variety of selected tools are described and discussed briefly [109]. The comparison between basic and additional features of some of the ontology tools is mentioned in Table 3.
Comparison between ontology tools
Comparison between ontology tools
Users can use protégé for the construction of domain ontology, entry forms, customize data and enter data. It is easily extendable to access other embedded applications that are knowledge-based. Other applications can also use protégé to access the data. Protégé-2000 is designed in a way to guide domain experts and developers through the procedure of system growth. It also allows developers to reuse problem-solving methods and domain ontologies. The Classes tab is being used to establish classes and the class structure, space and slot-value limitations, connections between classes, and relationship characteristics. The ‘Instances’ tab may be used to obtain occurrences of ontology classes. The forms are used to obtain replicas depending on the type of slots you provide. The standard form may then be modified by reordering the elements on the display, as well as modifying the shape, description, and characteristics for each slot [109].
OilEd
It is a straightforward editor that can be used to edit and create OIL ontologies. It is not meant to be a full ontology-based development environment thus it does not provide for large-scale ontology development, the primary motivation behind is to stimulate the user’s interest in DAML+OIL [7]. OilEd [8] has been developed by the Department of CS, University of Manchester. It is not designed to be a comprehensive ontology development platform. It should, though, give enough just to support basic OIL ontology development and illustrate the strength of the FaCT reasoner link [109].
Apollo
Based on primitives such as instances, classes, relations, and functions. Apollo is s a knowledge modeling tool that is quite user-friendly. The class system is modeled in accordance with OKBC, in Apollo. Thus, the knowledge base consists of hierarchically organized ontologies where an ontology can succeed in other ontologies and then use its classes. In Apollo, all ontologies at least inherit one ontology which is a default ontology containing all primitives. The classes include list, int, float, bool, etc. There are template and non-template slots in every class. Multiple instances can be created in every class.
RDFedt
Complex and structured RDF documents can be built in a fast and easy way using RDFedt. RDFedt is only available on the Windows platform; it is not platform-independent. It supports OIL, RDF(S), SHOE, and DAML. It also does not support multi-users. It does, however, provide support for Dubin Core Element Set and RSS modules. It only works in the OS i.e., windows, also it is entirely dependent on the platforms and it’s not based-on Java.
OntoLingua
This tool provides an environment to create, browse, edit, use, and modify ontologies. WWW interface and translation into various formats are supported by this tool which is an ontology library and server. A library of reusable and modular ontologies is also provided. Its environment is provided as a WWW service. It is aimed at authoring ontologies by extending and assembling ontologies from the library. A standards web browser can be used to access the ontolingua server [59]. It has many services including chimaera, webster, ontology editor, CML model fragment editor, and data structure inspector [109].
KAON
It is an open-source ontology management system that is mainly targeted toward business applications. It is a complete suite of tools that allows for the creation and management of ontologies and provides a framework for developing ontology-based applications. OilModeler and KAON PORTAL are two user-level applications provided by KAON. OilModeler is an editor for ontologies and is the tool used for their creation and maintenance, whereas KAON PORTAL is a framework for searching and navigating ontologies through the web browser. Ontology-based applications can be created using KAON, as it provides a framework to create applications. KAON has a front-end, core of KAON, and different libraries to provide support to build ontology-based applications [109].
WebOnto
It is a tool which has created by the Knowledge Media Institute in England. It allows the collaborative editing and creation of ontologies. Ontologies are exemplified in OCML which is a knowledge modeling language. The main aim of the tool is to offer an easy-to-use interface with scalability up to large ontologies. It provides a graphical interface for the management of ontologies, automation of instance editing forms, checking the consistency, multi-user support, support to create annotations, and elements inspection [109]. It is composed of a Java-based central server and clients [28,29].
Semantic web tools and their comparison
Knowledge extraction is said to be key for the semantic web. As time passes the interest in knowledge extraction from text increased in the Semantic Web community. After a lot of research in Natural Language Processing (NLP) using Semantic web resources, several tools appeared for the useful and precise learning of Semantic Web in different ways like tagged named entities, etc. These instruments are considered the bulk of the set in this field of study [38]. With time, the semantic web community realized that complex knowledge extraction tasks like logical relation induction, event recognition, etc. cannot be handled by learning basic semantic data structures. So, more tools are found to try a deeper knowledge extraction by rule-based methods and trained models.
Despite the increased usage of NLP techniques for the Semantic Web. The disparity between data structures of lexical and NLP data is still very large and therefore still formal semantics are heavily used for ontologies in SW. For the landscape analysis, we considered those tools which share certain characteristics of the Semantic Web. These tools are easily available as online downloaded code, and APIs [38]. There are also open-domain knowledge extraction tools which mean we do not need training for some specific domain. The practice to reuse knowledge extraction tools is very common. So, our study has not expanded to those tools which produce Semantic Web output.
The basic usage of the tools has been mentioned in Table 4. The following tools have been selected for knowledge extraction in the semantic web [38,65].
Tools for knowledge extraction in semantic web
Tools for knowledge extraction in semantic web
AIDA is an online tool or framework mostly used for resolution. If we pass it as natural language text or Web text. The ambiguous names have been mentioned by it and then map on some entities (like individual places or people). It is also used for tagging sense. It is online available as a Java service and prototype web application [67].
Alchemy API
It analyzes web or text content for sense tagging, and topics using natural language parsing and machine learning. Direct RDF encoding is not provided by this API. It is online available as a REST web service or a prototype web application [3]. It is also available as mobile SDKs.
Apache Stanbol
It [93] helps CMS developers to enhance the unstructured text with semantic ontologies to link documents with their related topics. It is available as an open-source HTTP service. It is also available as a Rest web service and downloadable file. Latest services include direct RDF encoding of results gained from related images, text span confidence, and grounding.
DBpedia Spotligh
DBpedia [92] resources in the random text have been mentioned automatically by it. It is also available as a Rest web service and the downloadable file.
CiceroLite
It is also known as extractive. It is used in Arabic, Chinese, English, and in many more European language texts for named entity recognition. It is also used for many other purposes like tagging of sense, semantic labeling, and information extraction. It is accessible as a Rest web service and downloadable file as well as a prototype web application [23].
Fox
It is one of the main tools of knowledge extraction mainly used for merging [36]. It focuses on results that include term extraction, relation extraction, and sense tagging. The sense tags provided by the merge tools have been generalized by their provided ontology. It is accessible as a prototype web application.
FRED
The linked data from text and RDF ontologies has been produced automatically by this tool. The methodology of this tool is based on semantic parsing as an implemented box. The results obtained from this tool contain much NER from wikifier. It is accessible as an online web application and as a web service (e.g. REST). The output of this tool is gained in the form of graphics or encoding form (Turtle). Its output is also available in the form of intermediate specifications. Which is later reconfigured to meet the type of text that has been analyzed [106].
NERD
It is one of the merging tools of knowledge extraction [70]. In the previous tools, we see that during writing their focus is on those results that include knowledge extraction, named entity recognition, information extraction, and resolution. The sense tags in the merge tools have been generalized by providing the ontologies from this tool. It also uses NIF. It is available as a web service and Java and python services. It is also available as a REST service [70].
Open Calais
It is open source and available as a web service and application [19]. It is a knowledge extraction tool that is used for extracts entities from the content with their related topics, facts, and tags. It has been used as a web application with different tools for homogeneity. There is also an open-source plugin available for this tool which automatically produces an RDF file. The schema used by this tool has a lot of semantics of different types. This schema must be reconfigured for formal output which is relevant to the text-domain.
PoolParty Knowledge Discoverer
This tool [27] is based on linked data and different models. It is used for information extraction and text mining. It has an additional feature, if we used controlled vocabularies as our initial knowledge model then tags, images, and different categories have been recommended automatically by this tool. So, in simple words, there exists a dependency of the knowledge discoverer with the initial knowledge that is derived from some controlled vocabularies. If we control one vocabulary instead of another, then the results would be completely different. For testing purposes, we have done two configurations with this tool that is economy and all kinds of topics. It is available as a prototype application and is totally open source for the testing environment.
ReVerb
This tool [81] is specifically used for the identification and extraction of binary relationships in English sentences. It is designed in such a way to extract the information from a web-scale, where we have no idea about the target relations, nor it is specified. It runs a model that is trained from a big data set. It takes input in the form of text and then output triples on the base of that input. It rejects the bulk text; it can be downloaded free in the form of a web application but did not use for any kind of study purposes.
Wikimeta Semiosearch Wikifier
It [104] integrates several components to resolve multiple named entities or terms. Components include an entity recognizer, an index of different Wikipedia pages, and some relevant matching strategies. It is accessible as an open-source web application.
Wikimeta
It [105] is used for sense tagging and multiple entity recognition. It uses a linked open data network with the help of various sources like Geonames, DBpedia, Wikipedia, or the web if there is no other resource available. It is accessible as a REST service and a prototype web application. It can also be downloaded free and used for different types of testing.
Zemanta
It [110] provides a lot of content to bloggers for articles and for different websites. The content which is publicly available is used by this tool and it matches the text with those contents and shows the result in the creation tool in which it is being initially written. It is available as an API for CMS (Content Management System) and as a demo application available in the form of the web. Overall, the tools for knowledge extraction give good results for the basic tasks and we must set room temperature for the NLP integrated applications which we use for the result of the Semantic Web. The testing has been done in two phases. Firstly, the result of measure for the merge ontologies is very good, and to filter the results coming from the worst tools for a specific task we imagine some optimization methods. Secondly, to automate the creation of merged ontologies we use appropriate transformation patterns. Merging different components is on the right track and to customize the output we reconfigured some components. This output should be appropriate enough for the reasoning on the web.
Semantic web service search
There are a vast number of web services available at present for a vast variety of applications, which can be accessed by web users in a variety of heterogeneous formats. High-precision scalable search of services has become essential for the advancement of service-based applications. The existing systems and tools for web service search; mostly XML-based WSDL, WSDL, or REST API-based; lack formal service semantics [56,83].
On the contrary, the semantic web community has developed some solutions for searching for semantic web services in different languages and formats, and applications. The main concept behind semantic web services is the annotation of web services with concepts. Concepts are specified using formal logic-based ontologies in a way that service-based applications and intelligent agents can perform reasoning on such formal service semantics. This allows for semantic interpretation between services, a more precise service search, and their computerized logic-based composition planning. Though the use of a combination of logic-based and non-logic-based semantic service selection can outperform both types of selection in precision, the cost is higher response times [57].
The pursuit of semantic web services technologies has been used in various application fields such as smart health care, smart factories, service-based business process management, social media, and virtual 3D web environments. It has been observed that trade-offs between the advantages and the additional efforts required to achieve them in various applications and infrastructures need to be further investigated. Semantic services are basically web services in which non-functional and functional semantics are specified in a machine-understandable form using formal ontology-based annotations. A semantic service comprises a semantic process model and a semantic profile, which describes the semantics of the service, as in how it works and what it does, respectively [61].
Semantic service description models differ in their formal logic-based organization and the possible extent of service annotation [61]. Following are leading languages and frameworks for semantic service:
Linked USDL
OWL-S (Web Ontology Language for Web Services)
SAWSDL; the W3C standard (Semantic Annotations for WSDL and XML Schema)
WSML (Web Service Modeling Language)
USDL (Unified Service Description Language)
hRESTS
SA-REST
MicroWSMO
Semantic service search can be represented in various ways depending on how the services in the examined search area are represented, the method of service selection employed, and the structure of the search space. Existing approaches to semantic web service search can be characterized as centralized or decentralized directory-based, or as decentralized and directory-less. Directory-based searching telecommunications companies will register with index nodes, and consumers will learn about these products through network service nodes [58].
Semantic services may be searched via centralized directory-based search in one of three ways: utilizing a standard search engine, a specific semantic web service search engine, or a specialized semantic web service directory with a specialized query interface. This strategy may have a single point of failure and may also have a performance bottleneck. A structured P2P technique with query routing may be used to execute a decentralized directory-based search. The bottleneck and central individual of failure issues have been resolved. However, this comes at a substantial cost in terms of communication overhead whenever peers leave or join the network [58]. A directory-less search is conducted on unorganized P2P networks without any overlay structure.
All approaches to semantic service search depend on a method used for the selection of semantic services identified as semantic service matchmaking. The matchmaking process consists of:
Pairwise semantic matching of each service which is registered to the matchmaker on its local service directory with the given service request.
Ranks of services ranked by their semantic relevance.
The matchmaker returns a ranked list of relevant services and related provenance information. The interaction with the selected services is not managed by the matchmaker. Depending on the nature of reasoning means that are used, semantic service matching approaches can be classified as follows:
Non-logic based semantic matching
Logic-based
Hybrid semantic matching
Evaluation of semantic service search can be based on the five following standards [55]:
Number of different languages and service description formats it supports.
Usability and the required effort spent on its configuration.
The services data privacy policy.
The services support for service composition planning.
The services support for service composition planning.
Over given test sets, the service retrieval performance in terms of correctness and average query response.
There is a range of systems and tools available for semantic service search that are central directory-based. The majority of these tools use hybrid semantic selection in SAWSDL, OWL-S, or WSML. The following are some popular semantic service matchmakers [58]:
iSeM, a hybrid, and adaptive semantic selection is performed in OWL-S services.
XAM4SWS, a LOG4WSW based hybrid adaptive matchmaker supporting RESTful and Micro-WSMO services.
MDSM, uses PIM4SWS which is a meta-model for semantic services and resolves queries across OWL-S, WSML, and SAWSDL services.
iServe, unfies RESTful and SOAP-based web service descriptions by giving an RDFS vocabulary. In this way, it can perform matching on WSML, OWL-S, WSMO-Lite, SAWSDK, MicroWSMO and SA-REST services.
There are also other ways for decentralised searching for semantic services, the majority of which support the service models OWL-S, SAWSDL, and WSML. The AGORA-P2P system searches for OWL-S services in organized P2P networks using a directory-based and decentralised search [61]. In unstructured P2P networks, the RS2D technology is utilised to execute an unstructured directory-less search. For hybrid semantic service selection, the OWLS-MX matchmaker is employed [6]. JXTA may be used to search for suitable WSML, OWL-S, and SAWSDL services in hybrid P2P networks. Similarly, in service model PS-WSDL, PYRAMID-S does a hybrid P2P search across WSDL annotated services [102].
Applications of semantic web
With semantic web and intelligent agents (IAs), the process will be automated, information which will be faster and more precise. IAs autonomously obtain data from the WWW and analyze them in a meaningful way. The utilization of the web is increased due to the IAs that can work human-like and give more accurate and more time-effective results [17]. The following are the possible uses of semantic web [17,65,86,98].
Search engine capabilities
As the documents and information are linked through hyperlinks which is not a problem for a person but a definite problem for the system, so it results in two problems i.e., Relevancy and reliability. So, in the semantic web, the context of documents is also considered [41].
Increased re-usability of information: By increasing in re-usability of info, the quality and consistency are also increased and the cost of updating, creation, and maintenance is also decreased. Advanced co-operation and expert findings: Customers can write a query in the natural language after that the query which was entered by the user will be converted into its semantic representation. After that engine will search semantic resources to check the query. And as far as ambiguity is concerned, the cooperation between broader choices of resources will make sure that it never came. This results in increased accuracy and relevancy. Knowledge exchange and time-saving: At quick speed, a huge amount of data will be converted into info and after user queries it will be converted into knowledge and that knowledge will be available all over the internet.
Web service
Web service is a service which connects one device to another device through WWW. And in this context web service provide static information and allow devices to connect with another main feature and that is to create web services depending on preferences of user [47]. Following are the steps of automatic web services [47]:
Automatic web service: It is the capacity to obtain information about web services. Semantic web records semantic representations of web services on a universal library, allowing intelligent agents to get these descriptions and move across multiple sources to locate the needed web service specified by the operator. Automatic web service invocation: Depending on the parameters which are fixed for the agent, the IAs can do basic tasks for the user if semantic metadata is available and web service is defined by it and it is in machine-readable form. Automatic web service inter-operation and composition: Libraries of web services are provided by OWL tech, which is quite complex. And by manipulating these libraries with the clearly mentioned objectives, the web services can be automatically created to fulfill these objectives.
Big data
To improve decision making the conversion of raw data into info is known as big data or business intelligence. As the data is increasing day by day, it become a huge problem to organize and analyze the huge amount of data. To use a massive amount of semantic information NLP tools play a key role. Though Semantic web ontology is used as a unified structure, semantics are denoted generally, and resources are in heterogeneous order. So, in big data, the collection of ontology languages and metadata plays important role [44].
Reduced cost of IT infrastructure: Redundant extraction processes are done by experts and investment-intense data warehouses are eliminated to decrease the cost Opportunity to increase the effectiveness of e-commerce: It will be used for targeted marketing like specific advertisements according to users taste by tracking their browsing history where users’ view the advertisements while surfing the web according to their likings. Lessening of information bottlenecks and reducing time for data suppliers and users: Users will be able to get reports without any help from the IT person or any person specialized in doing these kinds of stuff. Now users can get reports exactly according to their requirements which the help of ontology Timely and informed decision making: IAs will do their work on their own and with great precision, accuracy, and within a good amount of time. Also, they can be programmed to get specific info, so it will help establishments in decision making
Inbound marketing
Instead of outbound marketing which includes the marketing of products to all types of customers regardless of their interests and regardless of what their need is and regardless of what is required by the customer, there comes the inbound marketing which targets the customers who give importance to the trust between the organization and the buyer. It marks the customers depending upon the semantically related market segments of the customers, whether they have the information about the product or not. the advertisement method is electronic and can be done through e-newspapers, e-books, blogs, podcasts, physical products, SEO, etc. [111].
The following are the advantages of the inbound marketing in semantic web:
Brand awareness and credibility: As more means are used for the advertisement of products, there is more chance that users or buyers will be able to view that advertisement and similarly more chance of product being sold. And as the rank of the product increases, the trust of users will also increase. Cost reduction benefits: The cost will also be reduced as now we are using inbound marketing instead of outbound marketing. This is because of the cost which is being paid to the 3rd party marketing. Time effective: People time is important, which is also reduced due to inbound marketing.
Agent-based information harvesting and distribution
It describes the change in computing standard to info obtained and distributed separately by IAs from info distributed through a client/server system [47].
Following are the advantages of agent-based information harvesting and distribution:
Reduction in network load: The package of data will be transferred to the host through the network. the communication to complete the task is done on the host instead of the network. Overcomes network latency: In real time system, the time required to transfer data from one place to another is very crucial, IAs are pretty much helpful in catering to that problem. Dynamic adaption: Intelligent systems have the ability to adapt autonomously to changes and in order to solve problems, they also update their configurations. Heterogeneous characteristics: Intelligent agents are not dependent on transport layers and systems, and it allows nonstop system integration. Robust and fault tolerant system: If hosts halt due to any reason in a distributed system, all the agents are cautioned about that so that they can shift to other hosts.
Knowledge management
Using the understanding of specific info and the experience of the user, the new information is created which is knowledge management. Through this organization can analyze its own experience. When we deploy the knowledge management system the main problems arise only then and those problems include the obtaining of data from different resources, creating repositories with the least management of content, and not making the system work according to the requirements. Through the semantic web, intelligent agents with specific parameters are assigned to do the job. As it is automated work it will increase the accuracy and data and then it is further converted into knowledge [42,83].
The advantages we have from the knowledge management are as follows:
Reduced research time: With the semantic web, the intelligent agents are doing the work i.e., obtaining the relevant information from different sources in an automated way. Now as the work is done by intelligent agents so it will decrease the required time and, the cost of the overall process is decreased. And the results (relevant information) will be available in quick time by just writing some queries. Business benefits: It will greatly help the business as the management is improved due to knowledge management effective implementation. Resulting in the reduction of cost, the increment in productivity, the increased customer satisfaction, the improvement in sales, the betterment of the department of employees, and much more.
eLearing
It is an important and exciting feature of the semantic web; with this, we can have hypermedia systems. It is a hyperlink feature with the addition of sounds and videos instead of only text. But mostly here they behave like a stack of info with the capability of adapting to the changes that happen in the environment. For example, if the database adapts, it will with a lot in e-learning. It will help the learners a lot during their learning process [51].
The advantages are described as follows:
The time in developing LMS will be decreased.
It will adjust according to the learner explicit properties.
More effective and better research can be done
The pattern of different teachers can be divided between the authors and more effective learning patterns can be formed.
E- learning 2.0 deals mostly with the interaction of users and their teamwork with each other so obviously, it has some drawbacks. The semantic web provides more connectivity and more intelligence. So, now the web will be more unified and inter-operable. With the semantic web, the concept of e-learning 3.0 becomes more relative. In the semantic web, artificial intelligence is the key feature. As the semantic web is still in the working phase so we don’t know for sure what e-learning 3.0 will bring to the whole game of the web. Goroshko et al. [85] say that e-learning 3.0 is going to be intelligent and cooperative.
In E-learning 3.0 the meaning will be contextually reinvented and socially created. Now the main work is “how to learn” instead of “what to learn”. This technology will be very crucial, but all the work will be done in the background and the users will not know anything about it. According to Rubens et al. [85] “Technology will connect the knowledge, support knowledge brokering, and enable the translation of knowledge to beneficial applications”.
Rubens el al. [85] and Rego et al. [80] say, there will be at least four key drivers of e-learning, which are as follows:
Collaborative intelligent filtering
It allows customers or users to do their work in a more intelligent environment and encourage them to work in more collaboration [85]. It is performed by IA’s.
Distributed computing
In this, a specified task can be handled by several computers and every computer deals with its own task [30]. So according to scientists, the web will behave as a huge brain, which is able to think.
3D visualization and interaction
3D provides a whole new level of visualization to the users. It is easy to understand in 3D as compared to 2D, as 2D doesn’t consider depth factors, and as we all know we live in 3D so it is not easy to understand 2D as well as we can understand 3D. Users can copy other people by using a different kinds of avatars.
Negrila et al. [64] say “This opens new perspectives to teaching as it encourages collaboration, role-playing, and group work and makes learning more interesting and different from traditional education”. It also helps in learning by making it easier, this also includes virtual space exploration, dealing with virtual objects, etc. [85]. Padma et al. [71] in 2011, explains that “the two major components in the semantic web is the 3D tutor and leaner”. The tutor is basically an IA that provides useful and collective information to the learner, whereas the learner is the user or human who wants to get information about in a particular area.
Smart mobile technology
Padma et al. [71] explains that the semantic web increases the user’s interaction to a whole new level as it not only includes users from laptops, computers, or mobile devices but also can be reached out through electronic appliances, clothing, and vehicles [15]. As e-learning provides the concepts of “anytime, anywhere, and anybody”, it also provides the concept of “anyhow” which means that there is no compatibility issue on any device [80]. The peak of e-learning is being able to control “anything, anytime and anywhere” all the available resources through mobile devices [26]. The combination of distributed computing and smart mobile technology will be of great help in getting “anytime and anywhere” learning. Users can also learn by themselves through this, and the tools and other services will be available to users easily [85].
In Semantic web there are exists new technology and concepts which can be used as change agents of e-learning environments, and are as follows:
AI
Semantic web
Data driven science
Cloud computing
The challenges e-learning 3.0 will face due to users which are unwilling to use technology are as follows [49]:
Users don’t like change.
Users avoid new techs.
Users are not very aware with techs.
Users don’t like VR.
Users have issues in information as they don’t trust that.
Users want to take their decisions by themselves.
Users have problems with security.
Users are not very creative.
User can’t have enough money to buy devices.
Users don’t like virtual assistants.
Users think that they are losing control over process.
Users feel comfortable in dealing with people rather than virtual agents.
So, with the evolution of the web the challenges increase too so do the challenges in e-learning 3.0. So, new solutions will be required to deal with these problems [48,64,85], discussed the challenges of e-learning as follows:
As the data is available in various parts of the world and the laws of countries are different from each other which makes it difficult for the users who are bothered about the privacy of data. It is difficult to provide the data to the users with special requirements. Unavailability of server-side checks and due to lots of rights to different users, security risks increase. According to Rubens and his fellow researcher’s, “e-learning is affected by uncertainty, deceit, vastness, inconsistency and vagueness” [85]. E-learning will increase the importance of ethical problems and will encourage to adapt the extension of 3P’s i.e., productivity, personalization, participation, and ethics of learner’s, lecturer’s and organization [85]. As data is to be shared between different systems, which can become a difficult task due to lack of standards. Existing standards like LTSC (leaning technology standards committee), IMS (Instructional management systems project) and SCORM (shareable course object reference model) need changes to cope with the new tech. As the data is available in different languages and there is no feasible translation available on the web also the absence of interoperability of models makes it very hard for users to utilize them. Also, taking the cost of translation into account and the level of expertise required in order to translate makes it more difficult to deal with a multilingual web.
Challenges of semantic web
The challenges which we still have in the linked data web, semantic web, semantic web, the web of data or whatever you call it have various challenges that needed to be dealt with [69]. According to Rudman the challenges are incremental [17].
Some of these regular vulnerabilities are [17]:
Due to malicious attacks the loss of private and confidential info.
Unauthentic electronic interruption.
Not full usage of resources in the organization.
Too much confidence on 3rd party services or over-reliance on server-side security.
Non-stop updates of applications causing the performance to decrease.
Lack of experienced engineers or workers to deal with the different operations and monitoring of applications and system which are complicated.
Likelihood of loss due to legal activity and non-cooperating with the domination.
Precision resistors and capacitors.
Despite the evolution of the web from 1.0 to 3.0, it still has lots of issues regarding its security and scalability, and performance and it’s a big challenge for people with IT expertise. The semantic web become more interactive and common due to the huge amount of private and public data, not only among users (web users) but also among hackers as well [32,69].
The semantic web is also vulnerable due to the absence of data standards for monitoring metadata and data confidentiality. Unified Resource Identifiers (URI) are used to present data that can be exchanged without trust boundaries or without declaring any access policy as it is held in the database. So, hackers can change the data and thus generate the wrong services [50,69]. In the semantic web, data privacy is of main concern, and it is one of the big issues for IT experts. As the contents are getting bigger and bigger and people share them among groups or among the community of people. What if anyone gets the full access to anyone’s private data, it can be used illegally, making it very tough for the users, also this increases the illegal data on the internet and now due to the availability of multiple copies, making it difficult for the people cope with the situation [69,74].
Following are the detailed negative impacts or challenges we have on semantic web [17].
Unauthorized access to delicate information
To automate the web experience, we need to collect the browser history and personal information, and other personal things, so the privacy concerns have increased [50].
The unauthorized access has been divided further into four groups [50]:
Unauthorized access: Without verification, seizing of sensitive information on a system. In semantic web verification vulnerabilities occur when no verification is used or when verification exists, but it passed through SOAP headers in plain text format. Also, if the data is transferred over non-encrypted channels, then verification vulnerabilities can occur regardless of the implementation of authentication. Parameter manipulation: While the data is being transferred over the network, data changes. These vulnerabilities occur as the data is not encrypted or not tampered proof or not digitally signed. Network eavesdropping: By using monitoring software’s, the privileged data is obtained which happens to be in SOAP headers. These vulnerabilities occur due to a lack of encryption at both ends and due to the data is kept in plain text in SOAP headers. Message relay: An unauthorized person can interfere with the data and can change the information which is being sent over the network and can transmit it back to the producer. These vulnerabilities occur since the system contains messages without ID’s, which can be used to prevent non-encrypted and duplicated messages.
Identify theft and social phishing
Identify theft is the process of obtaining personal info by misusing information available on electronic medium with fraudulent intent. Similarly, in phishing personal information is obtained by an illegal party mimicking a trusted 3rd party. The key danger is the skill of scriptwriters to exploit personal info spread over metadata. The capacity of programmers to leverage critical data provided in the metadata, characterized by computer intelligible ontologies, and gathered independently by IAs is the key concern. Researchers outlined an ongoing vulnerability of inference attack, a type of aggressive data analysis in which private data is captured and revealed by combining non-sensitive material with metadata. Users will lose sight of sensitive information available on the Internet and how it will be kept as metadata incorporation increases, leading to a rise in the accuracy and quantity of deduction assaults [17]. As the integration of metadata is increased, users will lose the track of information, and this will result in an increase in inference attacks [32].
Hyper-targeted spam
Spam is defined as the distribution of a huge amount of content to users without consulting them. Spam can carry various type of sick scripts which includes viruses, malware, and adware. Their method and intensity are changed due to the introduction of the semantic web, but they can still carry infected scripts [74].
The methods of exploitation are as follows [74]:
Application pollution: As the semantic web uses the whole web’s resources as a database, the spammers can now contaminate universal resources which behave as a database for different applications, so now they can affect the running application. Improved Ranking: Search engine capabilities are empowered by the Semantic web, giving a chance to spammers to alter the ranking of malicious resources by changing the values of term-based metrics. Spammers can also change those algorithms which are used to compute the rank of the resource by creating fake resources to increase their page ranks. Hiding: The Semantic web is an open source, allowing IAs to collect info about anti-spam computer software and allow spammers to enhance their way of concealing malicious matter from the anti-spam computer software. Personalization of web content: It will allow spammers to collect precise and confidential information about users and attack them.
Development of ontologies
Ontologies explain the meaning of knowledge on the web, and it is necessary to make them be able to understand information obtained from unlimited sources. The major concerns are the establishment of kernel ontologies that behaves as a unified top-level dictionary. Their creation also requires technical, methodological, and management support [17,87]. A sufficient framework must be established to facilitate ontology construction, modeling, and annotations linking them; monitoring over changes; and the production of new ontologies [17]. The main issue that must be tackled is the development of kernel ontologies. To govern the generation of multiple editions of ontologies and to control the relationship between ontologies and annotations, the ontology agile methodology will also require the requisite scientific and technical assistance, as well as system integration [17]. The development of new technologies, particularly ontologies, raises the risk of exploitation owing to insufficient topic expertise. Programmers like any innovation in its early stages will try to exploit flaws caused by familiarity with the software. As this technology is in the beginning phase so scriptwriter will try to exploit the vulnerabilities of this inexperienced technology [87].
Proof and trust standardization
Semantic web can alone obtain and integrate data and convert it into info. Now, these can only be considered as claims and cannot be trusted until the source of info and policies available on the source are analyzed. Now, Intelligent agents (IAs) will determine whether the source can be trusted or not by analyzing the context and reputation of the sources and they will communicate with themselves without any human interference. Now this will allow attackers to write scripts that allow IAs to do illegal actions [17]. Intelligent agents can utilize the contextual as well as the quality of resources to decide the amount of confidence that can be placed in them. IAs will be able to interact with themselves without the need for human involvement to assess whether a resource can be trustworthy [17]. This allows cyber hackers to build programs that imitate a reputable agent, allowing them to conduct illegal activities or insert destructive programs. Semantic tagging will be actively used in Web 3.0 platforms. By giving incorrect information, programmers can influence semantic labeling and increase their web-page rating [17].
Malicious script injections and autonomous initiation of instructions
Semantic web uses a different type of languages, the most common is SPARQL and the attackers can now update languages or attack the subset of the query [35].
There are three query injections, which are as follows [35]:
SPARQL injections: It is a method by which attackers take benefit of weaknesses by taking the access to back-end layer of the database by entering wrong SPARQL queries, which gives them the opportunity to obtain private data from the application. Blind SPARQL injections: In this technique, the attacker enters queries and gets the results in Boolean form, so by querying again and again an attacker can get the required info through true and false messages printed by the system. SPARUL injections: It is a revised form of SPARQL, which not only allows reading but also writing. Allowing the attackers to modify the data itself.
Internationalization
Many latest technologies are going to be influenced by the bad effects of Internationalization, hence multilingualism affects Semantic web technologies [17]. It will affect the following fields as given below. Ontologies will be a key component of Web 3.0, and they now need to be coded in native languages. Annotation and material characterization will be more difficult, as most the web platform will participate in tagging their own material. For Web technologies to be realized, these annotations must be detailed and exact. So, the annotation (comments) and content are not an easy thing to deal with, now the level of detail of annotation will be of great use and now users can contribute if proper support is available for them to annotate in their own language.
Semantic web in next decade
In this section future of the semantic web is discussed. As web researchers continue to fuel new demands. Thus, we must formulate a set of new research challenges for these trends. So, the objective of the next decade is to make vast heterogeneous data to use for intelligent applications. Researchers are working to achieve this objective. Moreover, the research must be less dependent on logic-based methods and more dependent on evidence-based ones. There can be many important scenarios for the future in different domains of applications, the following are the discussion of some [73].
Internet of things (IoT)
The variety in IoT systems is very high and therefore it needs to be controlled. Till now, some of the lower levels of IoT designs have been standardized. Unstructured data, fuzziness, speed, and streaming are not addressed properly on Semantic Web. There is a need to control complex IoT systems to solve the above-uncovered characteristics for the future. Researchers [77] expect entire cities to be smart and run by semantic technologies in the next 10 years [5].
Computational linguistics
The semantics in computational linguistics still need to be improved. Significant progress can be made in traditional approaches (which are more rules-driven) using semantic approaches (logic-based, or probability-based). Till now, only low-level semantic approaches are being used. In the future, the semantics will have to be extremely involved in text understanding and machine translations. Nowadays, the need to understand text is getting higher day by day. The trend is shifted from simple text mining toward deeper text understanding. In the future, semantics can play a major role to attach bits and human language properly [111].
Heterogeneity, quality, and provenance
Data in the web is extremely heterogeneous. Also, the size, semantics, and quality of the web resources vary. One data-set may not be precisely used for many purposes. Provenance is also a recognized critical to applications using data on the web. There are still many questions to be answered like how to integrate heterogeneous data on various websites and how to evaluate the quality of a particular source. The semantic Web can provide the answer to these questions in the future.
Latent semantics
The web is dense with meanings. Usually in the form of language or data that computers cannot correctly comprehend. To comprehend the created ontologies, we must first comprehend latent extract and scientific proof models (which show the way that how users structure their knowledge implicitly). As a result, we must have answers to the following questions. How much semantics do we naturally learn and how do comparable or dissimilar reasoning processes apply to ontologies [111]? Again, the Semantic Web can provide the answer to these questions in the near future.
High volume and velocity data
The most typical issues that researchers face are the huge volume and velocity of data streaming over the Web [77,111]. Now, the semantic web must solve the following questions: how to organize data in motion to choose what to preserve and what to discard, how to install decision-making agents in various applications, and what semantics are required for these agents [111].
The semantic web can be the answer these questions in the future.
Semantic web gets closer to Internet of things (IoT)
Additional 30 billion devices are linked through the internet, and it is expected that around 50 billion devices will communicate through the internet by 2020 [5]. It can provide interoperability between things on the IoT. It is the most basic requirement to support discovery, object addressing, information representation, exchange, tracking as well as storage. Technologies lying in the semantic web are ontologies, linked data, semantic annotation, and semantic web services. These technologies are used as a fundamental solution for the purpose of realizing IoT. Semantic description and ontology make it inter-operable for stakeholders and other communities that use and share the same ontology. There are several challenges in terms of research when applying semantic technologies to IoT. It makes this technology exciting to the scientists and the research community.
Semantic Smart Gateway Framework that supports semantic interoperability among types of heterogeneous IoT entities is the key technology for semantic registration and abstraction for such entities. Distributed entities such as objects, identity, embedded devices, services, actuating, and software applications can be globally connected with the real world with a help of IoT. Internets of Things connect not only people or places but also real-time available data to the community of the current web.
The word ‘Things’ in IoT contains several physical entities of human interest such as a package to track and measure the air temperature of the room, a heater to control, monitoring industrial machines, and motion detection. To connect these ‘Things’, different technologies can be used in IoT including identity devices (barcodes, RFID tags), embedded electronics (home electronics, wearable devices having embedded systems like data storage, processors, actuators, industrial machinery), actuating and sensing devices (cameras, temperature, and other sensors, remotely controlled door lock systems and windows blind control systems).
There is a large diversity of billions of devices so allocation of storage devices and data analysis tools to handle huge amounts of data requires multiple levels. These kinds of problems need to be addressed to handle the capability mismatch among internet hosts and small devices. Processing capabilities and communications in different devices also need to be addressed. The interface between network domains and devices, IoT gateway provides a common interface for several heterogeneous networks and devices. Other IoT devices such as home appliances can be connected to the internet without any kind of middle-boxes. There is a gap in the interface between the communication of heterogeneous IoT devices and products for automated deployment of the latter. Devices’ descriptions in third-party applications are generic applications that can run in many IoT devices. A semantic gap between the type of heterogeneous data causes such inability. This gap can be covered by aligning the data of both types of entities and then the use of these configurations for the matchmaking of semantics.
Heterogeneous and distributed IoT entities should be explicitly, formerly, and consistently managed (aligned, discovered, registered, and composed) and represented through appropriate technologies of abstraction. These management and representation capabilities enable integration in several application domains of IoT such as ambient assisted living, smart homes, and transportation’s. In this way, third-party application deployment for end-users who are not experts in IoT, this setting will be achieved automatically with less participation of both expert and non-expert users.
The use of semantic technologies for automated placement of distributed and heterogeneous IoT entities support three different tasks: 1) alignment of IoT entities’ data and matchmaking is used through these alignments, 2) alignment of semantic registration of IoT entities and 3) messages for semantic data which are exchanged among these IoT entities during communication from deicing to application. In these situations, the deployment of generic apps for third parties can be considered as an automated procedure that hides the complexity of operations from end-users, such as semantic matching and ontology alignment of IoT things. Such complex tasks should not be performed by inexperienced end-users, but rather by a third-party expert service provider of that area, such as IoT semantic interoperability as a service, also known as Security Infrastructure as a Service (SIaaS), which acts as an interface between IoT application providers and end-users by placing the semantic matchmaking and ontology alignment task for the deployment process of IoT entities in a cloud.
Rapid manufacturing of products, real-time optimization, and supply chain networks are enabled by IoT intelligent systems by networking, control, and sensors systems simultaneously. Digital control systems are used to automate process controls, service information systems, and operator tools to optimize plant security and safety within the preview of IoT. IoT also extends itself for managing assets through predictive maintenance, measurements for maximizing reliability, and statistical evaluation. In Smart Grid, the smart industrial management system is also integrated by enabling energy optimization in real-time. Plant optimization, measurements, automated control systems, safety, and health management are also provided by a huge amount of network sensors.
In the manufacturing industry, the phrase Industrial Internet of Things (IoT) refers to the industrial subset of IoT. Industrial IoT in manufacturing will most likely provide corporate value, paving the way for the fourth industrial revolution, often known as Industry 4.0. It is expected that successful firms will be able to boost their income with the aid of IoT in the future by inventing new business models, increasing efficiency, transforming their workforce, and using analytics for innovation. Implementing Industrial IoT has the potential to create 13 trillion dollars in GDP by 2030 [5,15,25].
There are many similarities when it comes to Data Science for IoT but there are also some significant differences (e.g., in the use of radio and hardware networks). The most exciting improvement is the fact that IoT powers new and exciting domains such as self-driving cars, cloud robotics, drones, enterprise AI and many more.
Applications of semantic web in relation with IoT
In this section, actual applications in several sectors are discussed. The application like disaster management, precision agriculture infrastructure management, healthcare, public events, intelligent transportation, and building are discussed briefly [21].
Innovative industry
There are several possibilities in the corporate world for managing online media. In conjunction with the V4Design framework, an ontology-based structure called V4Ann was created [21]. Its primary goal was complete understanding, lexical synthesis from numerous sources, and the merging of annotations available in digital material modal findings [21]. MindSpaces’ goal for architectural elements in urban places is to give solutions for generating technically and psychologically appealing surroundings. Moreover, the i-Treasures system, which is built on multi-sensory fusion and semantic information understanding, has established an accessible and expandable platform that encompasses a diverse set of recorded ethereal local identities that are now available in electronic form [21]. Lastly, the IoT area covers worn gadgets, wherein the WEAR Sustain platform examined concerns of sustainably and principles across all innovative players in the sector and compiled them into a uniform body of knowledge [21].
Transportation
As towns’ populations rise, network architectures become increasingly important for standard of living, wealth generation, and environmental sustainability. Video surveillance, which entails watching a driving or immobilized automobile as well as transportation activities to assume traffic inside downtown streets, is a critical problem for smart vehicular networks. Diverse gadgets, such as webcams, generate media material in the IoT domain, facilitating worldwide interchange between both the real and virtual worlds [21]. Multiple architectures have been developed to cope with the issues. The Multimedia Web Ontology Language (MOWL) is used to collect data from different sensors like webcams, Wireless sensors, Global positioning, and other elements, therefore embedding smart transportation domain expertise [40]. An ontology for cooperative route optimization based on input from positioning devices was created in [94]. The ST4RT initiative [20] intends to provide ontology-based translation between multiple standards and frameworks, resulting in increased interoperability among disparate legacy applications of transportation companies.
Smart cities
The smart city idea is by far the most popular and rapidly increasing in computer technology. The notions used to describe a smart city, on the other hand, are as many as the towns itself. The term “smart city” has been used with varied meanings since there is no one explanation that fits all of these. In reality, a metropolitan area is defined as the network of embedded devices that must be interconnected, coordinated, and sentient. Many totally obvious encoding techniques are utilized to promote compatibility among such big and varied systems [21]. A variety of initiatives, such as FixMyStreet [54], SeeClickFix [108], and ImproveMyCity [100], have been established with the goal of giving the public and government bodies with an interactive platform that connects every problem inside its local territory. In [76], a taxonomy called “Smart City Services Ontology” is created to define smart urban settings. It was built around four smart urban applications: “Smart Parking, Smart Garbage Control, Smart Streetlight, and Smart Complaint”. The Open Traffic Lights project [101] presents a system for posting traffic signals that makes use of an ontologies as the information model based.
Smart Cities also continually assist the shift to sustainable and efficient power systems by promoting energy-efficiency rules that promote clean energy and smart power efficiency and supply. Efficient urban flood control is also becoming more difficult due to rising density and conflicting demands for sustainable, which are tied not just to water saving but also to energy consumption [21], presents a revolutionary internet system that combines clean and trash technologies to provide demanding reactive flood control. This is accomplished by combining various sensory and analytic elements through a semantics body of knowledge [21].
Smart homes
The paper by Ramparany and Cao [78] addresses the problem of information uniformity in IoT systems. The literature offers a system for combining IoT data from a smart home using semantic technologies. The idea is to use the data to detect the existence of an aberrant activity. Huang et al. [46] concentrate on home automation software security services and present a linguistic framework for identifying danger occurrences. An Annotation paradigm for wearable sensors is proposed by Zolfaghari et al. [112]. The Echolocation framework is made up of two techniques that employ taxonomies for situationally gesture recognition. The first method recognizes actions using Semantic Internet Language for thinking. The second strategy integrates ontology, analytics, and Adaptive Control to distinguish more complicated behaviors while overcoming scalability and measurement noise concerns.
Earth observation
Using linguistics and machine learning algorithms to analyze Planet Measurements have been a popular issue in recent years. The fundamental reason for this trend is because, although Earth Observed results are continuously rising, semantics provides an intelligent integration of data from diverse sources and elevated answers to judgment challenges, as well as enhancing deep learning. Most of the issues are related to natural resources planning, environmental conservation, and surveillance. Earth science data taxonomies are linked to rainfall data and pollution monitoring data. Intelligent Interaction Image Information Retrieval is a system that uses data archives to do latent semantic findings.
Health and well-being
INTER-Health is a medical system that is a combination of two pre-established diverse IoT systems, BodyCloud and UniversAAL [21]. This combination aimed to deliver features that the independent systems were unable to provide. The platform depends on the human who has dietary and physical difficulties and monitors their habits to avoid health concerns. A detailed clinical mode (DCM) is an information model that combines clinical ideas and clinical data needs. The study explores the benefits of DCMs over other techniques such as two-level modeling [21]. A method for decentralized e-health data was proposed by [2]. The system is a three-layered integrated cognitive compatibility platform that uses fuzzy taxonomy [21]. Each level does the following procedures in turn: (a) storing disparate health information, (b) connecting local ontologies to global ones using suitable algorithms or insights, and (c) providing a UI via which specialists may send questions [21].
Manufacturing
Industry 4.0 integrates automation and digitization in industrial processes [21]. Many of the prior mechanical gadgets are now allegedly being replaced by new equipment and automated vehicles [21]. Technologies are becoming increasingly intelligent, and AI capabilities are now being embedded in things, machines, and places, allowing them to perceive their surroundings and reasoning, understand and adapt. As the amount and intellect of “things” grow, there’s any need to transition from statistically interrelated IoT nodes to independent and cooperative units in the marketplace to hitch intellect and support real-time interconnection, interactive content, and judgment, thereby supplementing the company’s exact calculation [21]. The integration of Semantic Web and AI technologies results in a resolution to a variety of complex challenges linked to inter-operable, automation, and self-configurable processes, such as those seen in Industry 4.0 [21]. A strategy is provided for incorporating IoT into Multi-Agent Systems which are based on the manufacturing environment, cognitively enriching the appropriate ontologies, and validating it using a gaming system in an Equipment simulator. The SAREF ontology was expanded with the development of the SAREF4INMA concept to describe the Intelligent Enterprise and Factory domain [21].
Similarly, IoT combined with the semantic web to deal with the issues in security, safety, cultural heritage, an agriculture [21].
Semantic web and knowledge graphs
Knowledge graphs are used to improve access through uniform interfaces, renew-ability, server data, and, therefore, improved analytics and automation on top of their current data [33]. It mostly represents real-world things and their interrelationships in the form of a graph, in a schema, describes possible classifications and relations of things, provides for the eventual interconnection of arbitrary entities, and covers a variety of thematic categories [33]. A knowledge graph may be built and operated using a variety of technologies. One method is to use Semantic Web principles and technology, thus a database that meets those criteria and uses Semantic Web standards is known as a Semantic Web Knowledge Graph [33].
These criteria are founded on the following principles [33]:
Use of defensible URIs to refer to objects, i.e., URIs that lead to Web-pages.
RDF is used to represent the graph.
The graph schema is represented using RDF Schema and/or OWL.
Due to technology improvements, the notion of Industry 4.0 has attracted considerable attention in recent years, while posing significant technical problems that are being addressed by both the scholars and business research groups [107]. Web Of things, including Knowledge Representation, is a potential technology that helps realize Industrial revolution 4.0 deployments [107], offers a survey that demonstrates the application of the Semantic Web and Knowledge Graphs from several viewpoints, such as monitoring maintenance information, resource planning, and the delivery of being on and then on manufacturing and distribution [107]. Furthermore, it has suggested an upgraded reference generalized ontological model (RGOM) based on the Reference Architecture Model for Industry 4.0 to address the difficulties of restricted extent and complexity in existing ontologies. RGOM may help with a variety of Industry 4.0 ideas such as better asset management, productivity improvements, capacity re-configuring, system efficiencies, item ordering and supplies, and supply-chain management. RGOM may be used to construct a knowledge graph able to respond to any true query.
Because of the expansion in the volume of Web content, it is now difficult for all users to collect contextually relevant information through the Internet [96], proposed a knowledge-based approach for Web data collection. The model acquires user-profiles and captures user data demands using a global knowledge base and user localized example libraries [96]. By contrasting it to a manually developed user design model, the knowledge-based framework was effectively assessed [96]. Its paradigm aids in the development of more effective knowledge-based and tailored Web data collecting systems [96].
Using Pearson correlation and semantic connections to create a standardized data graph to design a classification model has improved the accuracy of forecasting the state of health concerns significantly [75]. [75] proposed the strategy that was employed, which combined knowledge of the healthcare area with the application of Pearson’s correlation coefficient and semantics in the development of a classification algorithm for identification. The study mined knowledge taken from MEDLINE titles and abstracts to learn ways to analyze the relationships between items relevant to medical ideas [75]. A knowledge-based HIG model was then created to forecast a patient’s health state [75].
Knowing human intellect, particularly brain intellect, is critical to achieving the ideal AI [60]. In this study, an examination of the historical relationships between AI and brain research, as well as the future vision of AI in a connected world was done [60]. Specifically present and integrate two fast-expanding topics in Web Intelligent (WI, AI in the Digital Age) and Neural Informatics to hasten the emergence of a biological AI civilization was studied [60]. Moreover, by merging AI and brain science with big data, this combination generates a new perspective from methodical central nervous system information processing to a new AI industry sector in the established network domains [60]. On media and social networks, knowledge discovery and its handling are studied by [97].
Conclusion and future work
The Semantic Web (Web 3.0) is an advancement of the existing web in which knowledge is given well-defined meaning, allowing people and computers to operate better. According to the best of our knowledge, none of the surveys provides a comprehensive study about the applications, challenges, and future of the semantic web along with its relationship with the Internet of things (IoT). This survey paper covers the gaps created from the previous survey papers in the same field and provides a comprehensive survey about web 3.0, a comparison between web 1.0, 2.0, and 3.0, the study of application and challenges in web 3.0, the relationship between web 3.0 with IoT and knowledge graph. Moreover, it focuses on the evolution of the web, semantic web along with an explanation of the various layers, ontology tools, and semantic web tools with their comparison and semantic web service search. We explored that Web 3.0 is quite useful in web service, in enhancing search engine capabilities, in the field of big data, marketing, knowledge management, and eLearning. Moreover, w.r.t to information access, elimination of central point of control, uninterrupted service Web 3.0 plays an important role. Web 3.0 has many applications in relation to IoT especially in the field of disaster management, precision agriculture infrastructure management, healthcare, public events, intelligent transportation, etc., and also using knowledge graphs. In future the web 3.0 can revolutionize the mentioned fields with the IoT and the future will look totally different. However, as their applications increase the challenges increase as well, especially in the aspect of security. To make the web smarter and to make the semantic web a reality, new kinds of semantics are needed as additional semantics and structure of the data on the web can benefit the scientists and developers. Computational Linguistics and the Internet of Things also need significant developments to make Web 3.0 a reality. Despite all the shortcomings and challenges, the semantic web is moving in the right direction, and it is the future of the web.
Footnotes
Acknowledgements
This work wouldn’t have been possible without the support of my lovely fiancé Wesam Ahmed Ali.