
Abstract
This paper presents an automatic facial micro-expression recognition system (FMER) from video sequence. Identification and classification are performed on basic expressions: happy, surprise, fear, disgust, sadness, anger, and neutral states. The system integrates three main steps. The first step consists in face detection and tracking over three consecutive frames. In the second step, the facial contour extraction is performed on each frame to build Euclidean distance maps. The last task corresponds to the classification which is achieved with two methods; the SVM and using convolutional neural networks. Experimental evaluation of the proposed system for facial micro-expression identification is performed on the well-known databases (Chon and Kanade and CASME II), with six and seven facial expressions for each classification method.
Keywords
Introduction
Emotion is a reaction to an emotional, environmental or psychological stimulus. The emotion felt in relation to a situation is unique to each individual. Human beings can express their emotions in different ways such as by facial expressions, language or even through body gestures. These different ways of expressing emotions can be well used simultaneously, and may be exploited in a multimodal communication [17].
Facial expressions can be classified into two categories:
Basic expressions such as anger, fear, disgust, sadness, joy, surprise, and neutral state, which can be represented by a single face image as defined by Ekman [6]. Dedicated processing approaches are then referred as static domain methods.
Facial micro-expressions which are brief and unconscious reactions that translate the emotional state of a person. It is very difficult to feign or limit. A micro-expression occurs in a very short time. Also, the detection of such expressions requires the consideration of successive images. Processing involves time and thus falls within the dynamic domain.
Despite of the different ethnic and gender origins, the face has similarities that allow its analysis in order to extract the information sought. The peculiarities of the face have led to the development of automatic processing systems in various fields such as in human-machine interaction, psychology for patient monitoring, and security applications.
Unlike facial expressions, which have been the subject of several researches [1,5] for several years, facial micro-expression recognition (FMER) is a relatively new and challenging field for the scientific community. Few systems are yet proposed [2,8,23].
FMER systems must consider that the perception of micro expression requires more than one frame and must also deal with his short duration. The time dimension is an essential aspect in any FMER system
We present in this article a new automatic micro-expression identification system which establishes the expression identification based on three successive frames. The method begins with a localization and extraction of the face region of interest, followed by the elaboration of the Euclidean distance map of the successive frame contours, used as input features, to finally make the classification.
The novelty in our approach consists in the fact of considering, at each time, three successive frames of the face, and using the Euclidean distance map of their contours to encode the face expression pertinent information over time. Use of contours rather than the original face images has impact in emphasizing the lines that appear in particular regions of the face, and that characterize the emotion state. This corresponds also to a simplification of the complex information reflected by a face image, which may improve the classification task.
The classification is established by three ways: SVM, Alexnet and CNN10, which is a proposed configuration of convolutional network with a reduced number of layers compared to Alexnet. This reduction justifies by the fact that deeper is neural network, bigger should be the amount of data required to achieve acceptable results. And, at the moment, existing databases are quite limited.
Facial micro-expressions The human face expresses succinct and unconscious expressions according to the emotions experienced. These generally appear in situations where the resulting stakes are high, like when people have something to gain or to lose. Unlike conventional facial expressions, it is very difficult to fake or limit a micro-expression. As micro-expressions occur in a very short time (between 1/25 and 1/3 second), these are more difficult to detect and be captured by our naked eyes. Examination of successive frames of a video may however reveal the subtle changes on the face that define and translate the micro-expression.
State of art
Facial micro-expression recognition (FMER) is a challenging task. It constitutes however an active area of the recent research. The development of dedicated systems is mainly tied to appearance of specific databases and the advances in artificial intelligence techniques. The proposed systems, in majority, are extensions of methods used for the facial expression recognition (FER), by integrating the time aspect in some way. We mention in the following some most known FMER systems.
G. Zhao and M. Pietikainen [23], developed a facial micro-expression system that uses the three orthogonal plane Local Binary Patterns as features, and the Support Vector Machine (SVM) for classification. The evaluation of the system is done on CASME II database [22]. An accuracy of 63.41% is achieved. Wang, Yandan et al. [21], proposed an improved system by associating an Eulerian magnification technique to spatio-temporal LBP features on three orthogonal planes (LBP-TOP). The evaluation on CASME II database led to an accuracy of 75.3%. L. Adegun and H. Vadapalli [2], proposed a system for micro-expression recognition in video sequences using LBP-TOP features. They use the SVM and the ELM (Extreme Learning Machine) classification. Evaluation is performed on CASME II database. Results with SVM produced an average accuracy of 96.26% while results with ELM led to an average accuracy of 97.65%. With the advance of deep learning, many systems integrate the convolutional neural network (CNN) in the FMER. Jing Li et al. [8] proposed a 3D flow-based CNNs model for video-based micro-expression recognition, which extracts deeply learned features that are able to characterize fine motion flow arising from one minute facial movement. The evaluation, done on three databases, provides an accuracy of 54.44% for CASME, 59.11% for CASME II, and 55.49% for SMIC [13]. Trang Thanh Quynh et al. [12] present a compact framework where a rank pooling concept called dynamic image is employed as a descriptor to extract informative features on certain regions of interest. A convolutional neural network is deployed on elicited dynamic images to recognize micro-expressions there in. Particularly, facial motion magnification technique is applied on input sequences to enhance the magnitude of facial movements in the data. Subsequently. The experiment is evaluated on three databases with an accuracy of 78.5% for CASME II, 72.65% for SMIC.
Proposed system of facial micro-expression identification
The system proposed here is inspired from the static system [9] and consists of three parts:
Location of the region of interest and extraction of the facial contours from each frame.
Measure of the Euclidean distance map between three consecutive frames.
Classification of micro-expressions using the Euclidean distances as input features.
The global structure of the proposed facial micro-expression identification system is illustrated in Fig. 1.
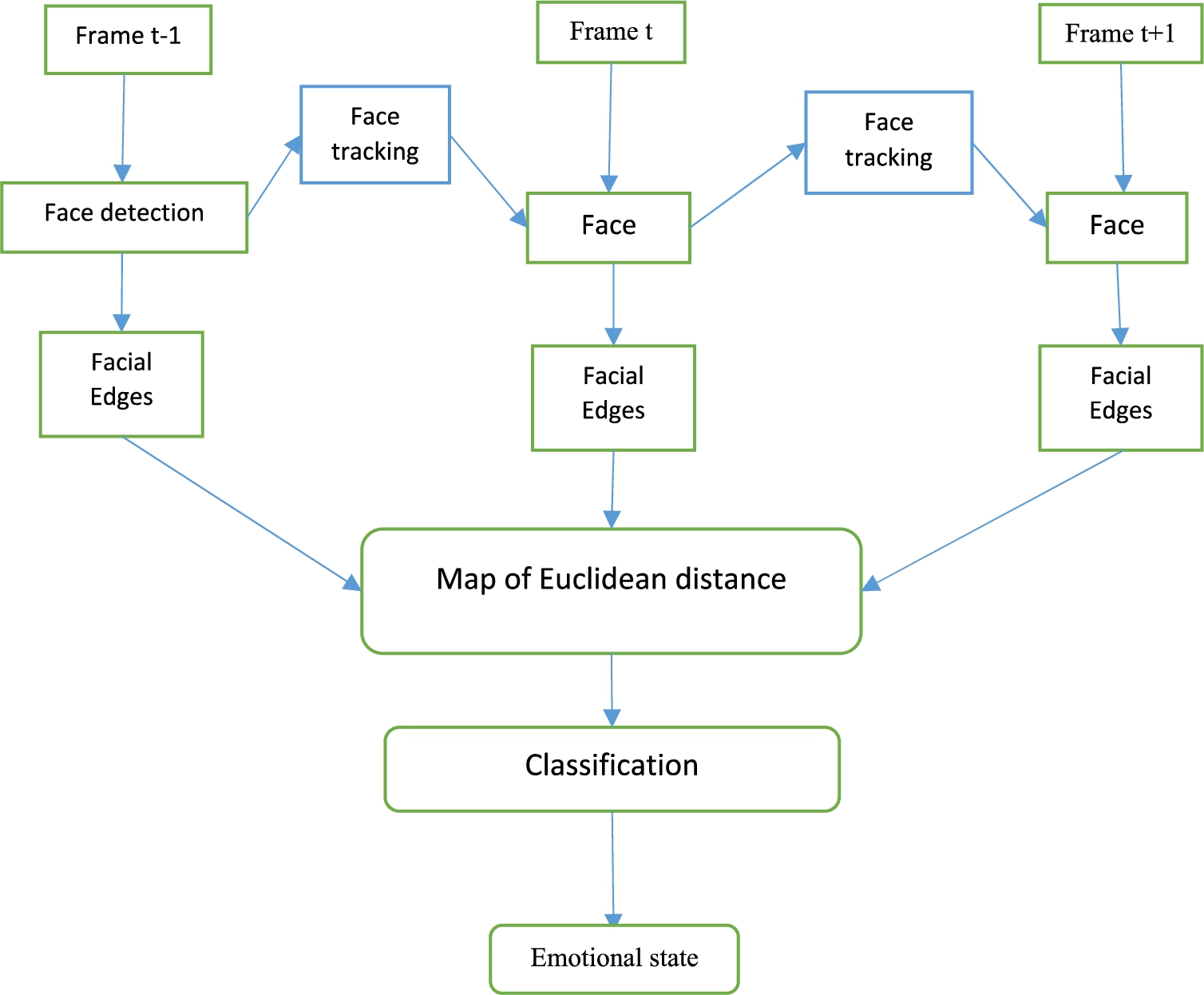
Synoptic of proposed system.
The localization of facial regions of interest is based on the method of Viola and Jones [19,20], as used in the static domain system based on the Euclidean distance [9].
The emotional state of the person is reflected through the face by variations in expression lines, like the contours around the eyes and the mouth, and also the appearance of expression lines on the forehead. This fact justifies our approach of basing the proposed system on edges rather than on the face image. This has impact in simplifying the complex face information and emphasising emotional state related features. For this, we apply the Canny edge detector [4] on the face region of interest. The thresholds are selected to locate the main edges of the face and most of the edges lines of facial expressions. Then the Euclidean distance map between three consecutive frame contours is calculated.
Canny contour detector
The Canny Edge detector [4] is an edge detection operator that uses a multi-step algorithm to detect a wide range of edges in images [18]. The process of edge detection algorithm can be broken down into five steps:
Apply Gaussian filter to smooth the image in order to remove the noise
Find the intensity gradients of the image.
Apply gradient magnitude thresholding or lower bound cut-off suppression to get rid of spurious response to edge detection.
Apply double threshold to determine potential edges.
Track edges by hysteresis: Finalize the detection of edges by suppressing all the edges that are weak and not connected to strong edges.
Hysteresis rules, based on the magnitude of the gradient, are:
Below the low threshold, the point is rejected. Greater than the upper threshold, the point is accepted as forming a contour. Between the low threshold and the high threshold, the point is accepted if it is connected to a point already accepted.
Measure of the Euclidean distance between three consecutive frames
Unlike the static system presented in [9] where the Euclidean distance was measured only between the pixels within a single face image, this proposed system measures a distance between three consecutive frames as illustrated on Fig. 2, as at frames
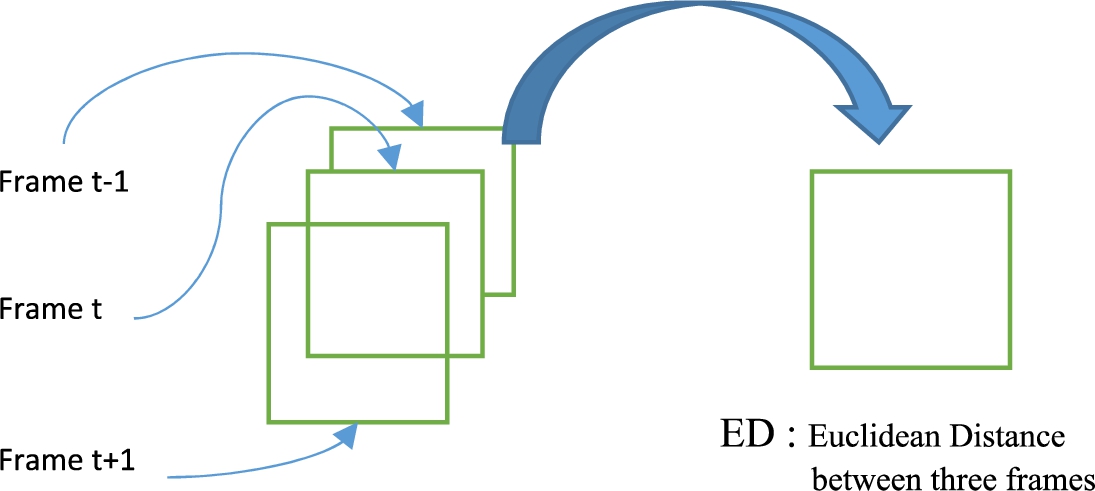
Calculation of the map of Euclidean distance between three consecutive frames.
For the system presented here we made the choice to make the classification by two methods the first is the SVM [15,16], and the second is through the convolutional neural networks. Two convolutional networks were used; the first is the famous Alexnet [11], and the second is CNN10 (Section CNN10).
Support vector machines
A support vector machine is a discrimination technique proposed by Osuna, Freund, and Giros [15]. It is a supervised learning method used for classification and regression, and is widely applied in pattern recognition [3,15]. The Support Vector Machine consists of separating two or more sets of points by a hyperplane. Depending on the case and the configuration of the points, the performance of the support vector machine may be superior to that of a neural network or a Gaussian mixture model.
Convolutif neural netwoks
We considered the following two convolutional networks for the classification step in our system. The Euclidean distance-maps are the input to the network to identify the micro facial expressions.
Alexnet AlexNet is the name of a convolutional neural network designed by Alex Krizhevsky et al. [11]. This neural network had a significant impact on the field of machine learning, especially in the application of deep learning to machine vision.
AlexNet contains eight layers; the first five are convolutional layers, some of them followed by maximum pooling layers, and the last three are fully connected layers. Alexnet uses the ReLU activation function. We used the Alexnet network in transfer learning mode, because we use the knowledge gained from a general classification problem to apply it again to our particular problem of facial expressions recognition according to the database used.
CNN10 CNN10 is the second convolutional network used for the classification of the FMER system based on Euclidean distance. CNN10 is a convolutional neural network of our configuration comprising ten layers with only three convolution layers, combined with normalisation, pooling and softmax layers, as shown on Fig. 3. Training is performed on either three-quarters or two-thirds of the samples of the two databases used. The remaining quarter or third of whole samples is used for evaluation.

CNN10 architecture.
The padding is the amount of pixels added to image when it is being processed by the kernel of a CNN. For normalization of the data, two methods may be considered. The easiest method is to scale the data to a range of 0 to 1.
The other technique of normalization is to transform the data to have a zero mean, and a unit standard deviation, using the following formula:
Where mean and σ are respectively the mean and standard derivation of the original data.
Evaluation of our system is done in terms of facial micro-expression identification rates, and confusion matrices. Three widely used databases are considered for this purpose, namely the Cohen–Kanade [14], and CASME II [22] databases.
CK database
The Cohn–Kanade AU-Coded Facial Expression Database [14] is intended for research on automatic analysis and synthesis of facial images and perceptual studies. Cohn–Kanade database is available in two versions and a third is in preparation.
CK contains 486 sequences from 97 subjects. Each sequence begins with a neutral expression and progresses to a maximum expression. The expression peak of each sequence is fully encoded in FACS and receives an emotion tag.
CK+ includes both posed and spontaneous expressions, and additional types of metadata. For the posed expressions, the number of sequences is increased by 22% compared to the initial version of the database, and the number of subjects by 27%. As for the initial version, the target expression of each sequence is fully encoded in FACS. Additionally, validated emotion tags have been added to the metadata. Thus, sequences can be analyzed for units of action and prototypical emotions.
We considered for our evaluation 36 individuals distributed over the six basic emotional states. Knowing that each sequence in this database begins with the neutral expression, we considered the first three frames of each sequence as samples for the neutral emotional state. The assessment for this database was carried out on the principle 3/4 for learning and 1/4 for testing and assessment (Table 1).
Organisation of CK database samples training / testing
Organisation of CK database samples training / testing
CK database with seven emotional states
The results obtained for each of the three classifiers are quite interesting (Table 2). And, in terms of rates of identification, we can notice an advance for the classification by SVM, followed by the convolutional network CNN10. In the third position comes the famous CNN Alexnet. The expression Neutral has a lot of false detections, followed by the anger expression.
CK database for six emotional states
The rates obtained with six facial expressions (Table 3) are better than those obtained for seven emotional states. The CNN10 convolutional neural network had the best rate, followed closely by SVMs. The classification by the Alexnet network had a rate lower by more than 2%.
The expressions, surprise and sad, have the highest number of false identifications.
Identification rates by facial expression and classification method
From the results in Table 4, we can see that in the case of seven emotional states, the emotional states anger and disgust show very good identification rates for all three classification methods, followed by the expressions joy, surprise, fear, and sad. We notice that the neutral state has the lowest rates with only 16.16% with CNN10. The Alexnet network provided the best rates among the three classifiers used. It presents also the most stable results for all of the emotional states considered for the CK database.
It appears also that removing the neutral state and then considering only six emotional states leads to significantly improved identification rates. This is an expected result since neutral state induces more ambiguities in identification. Also, lower is the number of states considered, better they will be resolved.
CASME II is a database with a temporal resolution of 200 fps and spatial resolution of approximately 280x340 pixels on the facial area. The facial expressions of the participants were obtained in a well-controlled laboratory environment, with appropriate experimental design and lighting. From nearly 3000 facial movements, 247 micro-expressions were selected for the database with Action Unit (AU) labeled. The CASME II database has the following characteristics:
Samples are spontaneous and dynamic micro-expressions. The basic frames (generally neutral) are kept before and after each micro-expression, which makes it suitable for evaluation of different detection algorithms.
CASME II provides five classes of facial expressions.
The CASME II database is one of the most widely used databases for the evaluation of FMER systems. We have used it for the three emotional states D: disgust, H: joy and S: surprise.
The evaluation of the FMER system on this basis was carried out according to the principle 2/3 for training and 1/3 for testing and evaluation. Table 5 gives the number of individuals and samples used for training and for evaluation.
Organisation of CASME II database samples for training / testing
Organisation of CASME II database samples for training / testing
CASME II database with three emotional states
The results obtained on Casme II database (Table 6) are more satisfactory since we obtain an identification rate of 100% for the three classification methods. This performance is also due to the fact that only three states are considered in this database. This, inherently, improves the distinction between the considered classes. It is worth to mention that this limitation to only three states is dictated by the great imbalance of data observed in CASME II database. Considering all the states would need to implement a suited technique to deal with imbalanced data or have sufficiently bigger database.
In Table 7, we show rates obtained by our system and other FMER systems. The effective comparison between existing systems would however need considering not only the identification rates on common databases, but also their implementation complexity and processing time.
Comparison of FMER systems
The system was developed on the Matlab® environment, and evaluated on Intel® core™ i5-3210M CPU 2.50 GHz with 8 GB of RAM. The processing time of the FMER system, as given in Table 8, covers the elaboration of the distance map of the three frames and the classification. This shows the potential of use for real applications, as we know that this processing time may be reduced through the implementation in faster environments or dedicated architectures. We may however notice that neural networks considered are faster than SVM.
Processing time of the presented FMER system
Processing time of the presented FMER system
The presented system is intended for the identification of facial micro-expressions. Evaluation of the system on the two of the most used databases in the field gives very interesting results. The performances of the three classifiers are good and quite close, with a slight advance for SVM and CNN10 compared to the Alexnet network.
Considering a high number of emotional states increases the proximity between the states, and limiting to only a reduced number allows the system to be more accurate, as we have seen with the CASME II database.
We may notice that the performance of this system depends on the precision of the different processing phases, starting with the detection of the face and edge extraction. These aspects should be well solved for real application contexts. The system performances can also be improvement trough the expansion of the training data. Bigger databases are needed to fully attain the potential rates offered by deep learning approaches.
Facial expressions with more subtle situations need also be taken into account. The study of the effect of age and disease will also be an interesting extension.
The proposed system can be integrated as part of a multimodal system, as proposed in [13]. And other classification strategies, such as long short-term memory (LSTM) networks and temporal convolutional networks [7,10,21], can be considered and evaluated in the future.