
Abstract
In order to solve the problems of high node loss rate, high time overhead and high risk of privacy disclosure in network node privacy information protection, an ultra dense network node privacy information protection algorithm based on edge computing is proposed. The weight update algorithm is used to detect the security vulnerabilities of ultra dense network nodes. According to the detection results, the characteristics of node vulnerabilities are obtained, the sensitive label information of node vulnerabilities is protected through the weighted graph, and the k-anonymity technology is used to anonymize the privacy information of ultra dense network nodes; Finally, edge computing is used to protect the privacy information of nodes. The experimental results show that the node loss rate of the proposed method is always less than 2%, the time overhead is small, and the risk coefficient of privacy disclosure is small.
Keywords
Introduction
In recent years, with the acceleration of the development of Internet technology, the type and quantity of information in the network are changing with each passing day [16]. A survey report pointed out that: at present, the number of Internet users in China has reached a considerable scale, and the network has gradually become the main place for people to share information and the main channel for people to obtain information [11]. The information content in the network involves all aspects of people’s work and life, and has the characteristics of wide range and many kinds [7]. Although the network has brought great convenience to people’s life, due to the impact of network node attack and network intrusion, it will cause the leakage of private information. Therefore, in order to improve the security of user information, we must protect the security of private information through reliable means [15].
LV Yarong [12] proposed a method to protect the privacy location information of source nodes in wireless sensor networks in order to ensure that the location of network nodes is not leaked. The panda Hunter location privacy protection model and the six tuple system defense attack model are constructed. The number of network nodes is obtained by using the above two models, and the nodes are forwarded through probabilistic forwarding routing. Through the above steps, the node overlap probability is reduced, so as to improve the security of network node information. The experimental results show that this method reduces the node overlap rate and the network energy consumption, but there is the problem of high node loss rate. Zhou Yihua [14] and others proposed a social network privacy protection method based on clustering. Firstly, cluster the user’s social relationship information, cluster the nodes into super points containing multiple nodes, and anonymize the network nodes at the same time; The above steps can effectively reduce the impact of network attacks on node privacy. On this basis, the clustering algorithm is used to select the initial nodes, calculate the spacing between nodes, and apply the adaptive idea to node privacy protection according to the calculation results to reduce the loss rate of information. The experimental results show that this method effectively reduces the loss rate of node information, but it has the problem of large time overhead. Jiang Zhanjun [17] and others proposed a protection method to optimize the location privacy intensity of the source node, which uses the dynamic random number generated by the source node to layer the node information, so as to ensure the safe distance between nodes; The nodes with the same distance and the smallest number of hops form a node set to form a virtual ring. If the data packets in the network reach the ring, the node transmission direction needs to be selected, and the hop by hop transmission form is adopted to improve the diversity of node transmission paths, so as to improve the attacker’s tracking time and improve the effect of privacy information protection. The experimental results show that this method improves the comprehensiveness of node privacy information protection due to the preprocessing of nodes, but there is still a risk of privacy disclosure.
In order to solve the shortcomings of the above privacy protection methods, this paper designs a new edge computing based privacy protection algorithm for ultra dense network nodes. The overall research technical route of the algorithm is as follows:
Firstly, the weight updating algorithm is used to detect the security vulnerabilities of ultra dense network nodes.
Secondly, according to the results of security vulnerability detection, the characteristics of node security vulnerabilities are extracted.
Finally, the sensitive label information of node vulnerability is protected by weighted graph, and k-anonymity technology is used to anonymize the privacy information of super dense network nodes. According to the result of anonymization, edge computing is used to protect the privacy information of nodes.
Privacy information protection algorithm for dense dense network nodes
Security vulnerability detection of ultra dense network nodes
In case of attack threat or node security vulnerability threat, ultra dense network is prone to information disclosure risk. Therefore, before node privacy information protection, it is necessary to detect the security vulnerability of network nodes, get the threatened nodes in the network through detection, and then focus on the security protection of these nodes [9]. Usually, the traditional methods judge whether the node is under security threat according to the temporal and spatial variation characteristics of the node. However, this method has poor detection effect on hidden nodes. Therefore, this paper uses the weight update algorithm [1] to effectively detect the security vulnerabilities of ultra dense network nodes [2].
Assuming that at time T, the set of ultra-dense network nodes is
In the formula,
Establish a distribution sequence to determine the spatial orientation of vulnerability nodes. In this step, it is necessary to analyze the distribution of multiple angle nodes: first, all vulnerability nodes are independent, do not interfere with each other, and the distribution is relatively uniform; Second, different vulnerability nodes exist in multiple network levels and have duplicate nodes. The larger the scope of network vulnerabilities, the more such nodes.
Denote the position of the node in the distributed sequence space as
In the formula, a and b represent node position coordinates;
According to formula (1) and formula (2), in the security vulnerability detection of ultra dense network nodes, the node characteristics in case of network vulnerabilities are expressed as:
In the formula,
In the formula, X represents the common attributes between nodes; Y represents the heterogeneous attributes between nodes.
According to the vulnerability characteristics obtained by formula (3), find network nodes with this law [3], classify nodes with similar characteristics into a set
In the formula,
Through the above steps, we can obtain the vulnerability characteristics of ultra dense network nodes, and realize the node security vulnerability detection according to the characteristics. According to the detection results, we can provide preconditions for the privacy information protection of network nodes, so as to reduce time consumption and improve the efficiency of privacy information protection [10].
Privacy protection of nodes in ultra dense networks based on edge computing
According to the detection results of node security vulnerabilities in the ultra-dense network, the node vulnerability characteristics are obtained. Since some node vulnerabilities will have sensitive label information, the sensitive labels in them should be protected before privacy security protection. The sensitive label information is represented by the weighted graph [8], H is used to represent any node in the weighted graph, and
In the formula,
In the formula,
For any node in the weighted graph, it has its unique sensitive attributes. In fact, the tag information of the vulnerability node contains not only sensitive attributes, but also identification attributes. In order to simplify the information anonymization process and reduce the computational difficulty, this paper only focuses on the sensitive attributes, and hides the identification attributes before anonymizing the privacy information of dense dense network nodes.
After obtaining the sensitive attributes of ultra dense network nodes, k-anonymity technology [4] is used to anonymize the privacy information of ultra dense network nodes. Establish a k-anonymous set, which has a large number of records, each record has a representation, and each record with identification has
Taking a certain kind of privacy information as an example, an anonymous processing example is given. Table 1 shows the original data records and Table 2 shows the data records after anonymous processing.
Original data record
Original data record
Anonymization of raw data records
According to Table 1 and Table 2, taking Jack as an example, K-anonymization is performed on his name and date of birth. According to the principle of K-anonymity technology, it can be seen that there are
When using traditional methods to protect the privacy information of network nodes, it can not meet the needs of real-time processing and protection of privacy information, which is easy to cause the risk of large node loss rate. Therefore, this paper applies edge computing technology [13] to the privacy information protection of network nodes. Edge computing refers to the network equipment with computing and storage capabilities from the terminal data source to the cloud server. According to this technology, an ultra dense network node privacy information protection model [5] is established. The schematic diagram of the model is shown in Fig. 1.

Privacy information protection model of ultra dense network nodes.
According to Fig. 1, the privacy information protection model of ultra dense network nodes based on edge computing technology takes the network nodes as the object, divides the network nodes into different entities, and then assigns n edge computing nodes to different entities through the cloud server, and encrypts these nodes to realize privacy information protection. Each module in the model is analyzed below:
Network node privacy information collection module: collect the information to be protected and transmit the information to the edge computing device.
Node feature extraction module: Combined with the numerical attribute features of network node vulnerabilities obtained in Section 2.1, these features are processed in the edge computing device, and a feature vector that is more in line with the actual situation of the node is further obtained to form a feature vector set A:
Attribute encryption module: This module also runs on the edge computing device, inputs the ciphertext, compares the cosine similarity of the feature vector under the ciphertext, and transmits the encryption results to the child cloud server.
Information management module: divide the encrypted feature vector into data with the same dimension, distribute these data to edge computing nodes, and manage these nodes through edge computing devices.
Through the above analysis, it can be seen that the edge computing model can not only obtain the feature vector of network nodes, but also realize the privacy protection processing of node information, and effectively improve the security of information.
In order to verify the effectiveness of the privacy information protection algorithm of ultra dense network nodes based on edge computing, experimental analysis is carried out.
Experimental data
In this experiment, in order to ensure the accuracy of the experimental results, the experimental verification will be carried out in a unified experimental environment.
The proposed method, the method in literature [12] and the method in literature [14] are used to verify the privacy information protection experiment of ultra dense network nodes. The data sets involved in the experiment mainly include three. Table 3 shows the specific experimental data set parameters.
Parameters of experimental data set
Parameters of experimental data set
Under the above experimental environment and experimental parameter settings, the experimental verification is carried out. By comparing the privacy information protection effects of the three methods, the application effects of different methods are analyzed.
According to the above experimental environment and parameter configuration results, taking the node loss rate, time cost and privacy disclosure risk coefficient as experimental indicators, the application effects of the proposed method, the method in literature [12] and the method in literature [14] are compared. The results are analyzed as follows.
Analysis of experimental results
Node loss rate analysis of network node privacy information protection
Node loss rate is a key index to measure the effect of privacy information protection of network nodes, which can reflect the network performance. Therefore, taking node loss rate as an experimental index, the application effects of the proposed method, literature [12] method and literature [14] method are compared, and the results are shown in Fig. 2.

Comparison results of node loss rate of different methods.
According to Fig. 2, the node loss rate of the proposed method, the method of literature [12] and the method of literature [14] remain at a low level. Among them, the node loss rate of the method of literature [12] fluctuates relatively large, indicating that it has the problem of poor stability. By analyzing the specific result data, it can be seen that the node loss rate of the proposed method is always lower than 2%, while the maximum value of the node loss rate of the method in literature [12] is 5.8%, and the maximum value of the node loss rate of the method in literature [14] is also 5.0%, although it is lower than the method in literature [12]. Through comparison, it can be seen that the methods of literature [12] and literature [14] will lose a large number of nodes in the privacy information protection of network nodes, which is not conducive to improving the performance of network nodes. Through the above comparison, it can be seen that the privacy information protection ability of the proposed method is better than that of the traditional method.
The time cost is mainly used to measure the efficiency of network node privacy information protection methods. The shorter the time cost, it shows that it can realize privacy protection in a shorter time and improve users’ information security. Therefore, taking the time cost as the experimental index, the application effects of the proposed method, literature [12] method and literature [14] method are compared. The results are shown in Table 4.
Time cost comparison results of different methods/(s)
Time cost comparison results of different methods/(s)
By analyzing the experimental results data in Table 4, it can be seen that when three methods are used to protect the privacy information of network nodes, the time consumption increases with the increase of the number of experiments. The time consumption of the proposed method is between 13.1 s and 17.3 s; The time consumption of the method in literature [12] is between 16.9 s–29.0 s; The time consumption of the method in literature [14] is between 16.5 s and 29.5 s. Comparing the time cost of the three methods, the proposed method has the least time cost, which shows that it can effectively improve the efficiency of privacy information protection of network nodes and avoid the risk of information disclosure caused by time delay to a great extent.
In order to further verify the effect of privacy information protection, the privacy disclosure risk coefficient is taken as the experimental index to compare the application effects of the proposed method, the method in literature [12] and the method in literature [14]. The results are shown in Fig. 3.
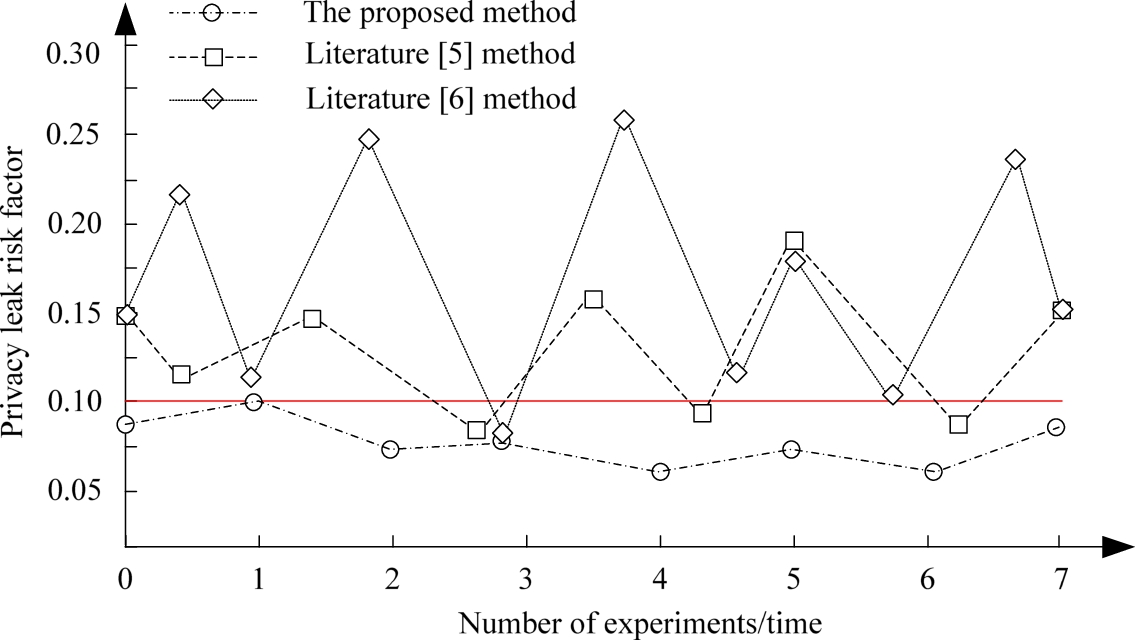
Comparison results of privacy disclosure risk coefficients of different methods.
In Fig. 3, the red line indicates the acceptable privacy disclosure risk coefficient. According to Fig. 3, the privacy disclosure risk coefficient of the proposed method is always lower than the red line standard, while the methods in literature [12] and literature [14] only meet the standard and lower than the standard in a few experiments, but still higher than the red line standard in most experiments. According to the above results, the privacy disclosure risk coefficient of the proposed method is lower, which shows that it can ensure the privacy information security of network nodes to the greatest extent.
In order to improve the reliability and security of the network, a privacy information protection algorithm for ultra dense network nodes based on edge computing is proposed. The weight update algorithm is used to detect the security vulnerabilities of ultra dense network nodes. The characteristics of node vulnerabilities are obtained through detection. The nodes with similar characteristics are classified into a set, and a weighted graph is established to protect the sensitive label information of node vulnerabilities and improve information security. K-anonymity technology is used to anonymize the privacy information of ultra dense network nodes, and edge computing is used to further protect the anonymization processing results, so as to further improve the security of privacy information. The experimental results show that the node loss rate of the proposed method is always less than 2%, the time consumption is between 13.1 s-17.3 s, which is lower than the traditional method, and the risk coefficient of privacy disclosure is small, indicating that this method has a good effect on the protection of network node privacy information.